

Neste guia, você aprenderá:
- Por que você deve saber a diferença entre conteúdo estático e dinâmico
- O que é conteúdo estático, como detectá-lo, quais ferramentas usar para extraí-lo e os desafios envolvidos
- O que é conteúdo dinâmico, como identificá-lo, quais ferramentas são mais adequadas para raspá-lo e os obstáculos que você pode encontrar
- Uma tabela de comparação de conteúdo estático vs. dinâmico no contexto de raspagem da Web
Vamos mergulhar de cabeça!
Uma introdução ao conteúdo estático e dinâmico na raspagem da Web
Quando se trata de raspagem da Web, há uma diferença significativa na abordagem, dependendo se o conteúdo que você deseja extrair é estático ou dinâmico. Essa distinção afeta muito a forma como você lida com a análise, o processamento e a extração de dados.
Como regra geral, as seções ou páginas otimizadas para SEO tendem a ser estáticas. Em vez disso, as seções altamente interativas ou aquelas que exigem atualizações ao vivo geralmente são dinâmicas. Entretanto, na maioria dos casos, a realidade é mais complexa do que isso.
As páginas da Web modernas geralmente são híbridas, o que significa que incluem conteúdo estático e conteúdo dinâmico. Portanto, rotular uma página inteira como simplesmente “estática” ou “dinâmica” geralmente é impreciso. É mais preciso dizer que um conteúdo específico da página é estático ou dinâmico.
Para complicar ainda mais a situação, mesmo que uma página em um site seja estática, outra página no mesmo site pode ser dinâmica. Assim como uma única página da Web pode conter os dois tipos de conteúdo, um site pode ser uma coleção de páginas estáticas e dinâmicas.
Portanto, com isso em mente, prepare-se para se aprofundar na seguinte comparação entre conteúdo estático e dinâmico!
Conteúdo estático
Vamos examinar tudo o que você precisa saber sobre conteúdo estático em páginas da Web e como extraí-lo.
O que é conteúdo estático?
O conteúdo estático refere-se a todos os elementos de uma página da Web que são incorporados diretamente ao documento HTML retornado pelo servidor. Em outras palavras, ele não requer renderização no lado do cliente nem recuperação adicional de dados pelo navegador. Portanto, tudo já está presente na resposta HTML inicial.
Isso normalmente inclui elementos da interface do usuário, texto, imagens e outros conteúdos que não mudam a menos que o código-fonte do servidor seja atualizado. Mesmo que o servidor busque dinamicamente dados de bancos de dados ou APIs antes de gerar o documento HTML para enviar ao cliente, o conteúdo ainda é considerado estático do ponto de vista do cliente. O motivo é que nenhum processamento adicional é necessário no navegador.
Como saber se uma página da Web usa conteúdo estático
Conforme mencionado na introdução, é raro que os sites modernos sejam 100% estáticos. Afinal de contas, a maioria das páginas da Web inclui algum nível de interatividade no lado do cliente. Portanto, a verdadeira questão não é se uma página é totalmente estática ou dinâmica, mas sim quais partes da página usam conteúdo estático.
Para determinar se um conteúdo é estático, você precisa inspecionar o documento HTML bruto retornado pelo servidor. Observe que isso não é o mesmo que você vê em seu navegador. O navegador mostra o DOM renderizado, que pode ser modificado pelo JavaScript após o carregamento da página.
Há duas maneiras simples de verificar se uma página usa conteúdo estático e de identificar quais elementos são estáticos:
- Exibir fonte da página
- Usar um cliente HTTP
Para aplicar a primeira abordagem, clique com o botão direito do mouse em uma área em branco da página e selecione a opção “Exibir origem da página”:

O resultado será o HTML original retornado pelo servidor:

Por exemplo, nesse caso, você pode dizer que os elementos de citação já estão presentes nesse HTML. Portanto, você pode presumir com segurança que eles são estáticos.
A segunda abordagem envolve a execução de uma solicitação GET simples para o URL da página usando um cliente HTTP:

Novamente, isso mostra o HTML bruto retornado pelo servidor. Como os clientes HTTP não podem executar JavaScript, você não precisa se preocupar com alterações no DOM. Ainda assim, como abordaremos em breve, sua solicitação pode ser bloqueada pelo servidor devido a proteções anti-bot. Portanto, usar o método “View page source” é a abordagem recomendada.
Ferramentas para raspagem de conteúdo estático
A extração de conteúdo estático é simples porque está incorporada diretamente na fonte HTML da página. Veja abaixo uma visão geral básica do processo:
- Recupere o documento HTML executando uma solicitação GET para o URL da página usando um cliente HTTP simples.
- Analisar a resposta usando um analisador de HTML.
- Extraia os elementos desejados usando seletores CSS, XPath ou estratégias semelhantes fornecidas pelo analisador HTML.
Se estiver procurando ferramentas para usar na raspagem de conteúdo, confira nossos guias detalhados sobre:
Você pode encontrar um exemplo completo relacionado ao site “Quotes to Scrape”, cujo HTML foi mostrado em uma seção anterior, em nosso tutorial sobre web scraping com Python.
Algumas pilhas de raspagem populares para recuperação de conteúdo estático incluem:
- Python: Requests + Beautiful Soup, HTTPX + Beautiful Soup, AIOHTTP + Beautiful Soup
- JavaScript: Axios + Cheerio, Node Fetch + Cheerio, Fetch API + Cheerio
- PHP: cURL + DomCrawler, Guzzle + DomCrawler, cURL + analisador simples de HTML DOM
- C#: HttpClient + HtmlAgilityPack, HttpClient + AngleSharp
“O BeautifulSoup é mais rápido e usa menos memória que o Selenium. Ele não executa JavaScript, nem faz nada além de analisar HTML e trabalhar com seu DOM.” – Discussão no Reddit
Desafios na raspagem de conteúdo estático
O principal desafio na extração de conteúdo estático é fazer a solicitação HTTP correta para recuperar o documento HTML. Muitos servidores são configurados para fornecer conteúdo somente para navegadores reais, portanto, eles podem bloquear sua solicitação se ela não tiver determinados cabeçalhos ou não passar nas verificações de impressão digital TLS.
Para evitar esses problemas, você deve definir manualmente os cabeçalhos HTTP adequados para raspagem da Web. Como alternativa, use um cliente HTTP avançado que possa simular o comportamento do navegador, como o cURL Impersonate.
Caso contrário, para obter uma solução profissional que não dependa de truques ou soluções alternativas incômodas em seu código, considere usar o Web Unlocker. Esse é um ponto de extremidade que retorna o HTML de qualquer página da Web, independentemente dos mecanismos de defesa implementados pelo servidor.
Além disso, se você enviar muitas solicitações do mesmo endereço IP, poderá acionar a limitação de taxa ou até mesmo uma proibição de IP. Para evitar isso, integre proxies rotativos para distribuir suas solicitações entre vários IPs. Consulte nosso guia sobre como evitar proibições de IP com proxies.
Conteúdo dinâmico
Vamos continuar este guia de conteúdo estático vs. dinâmico explorando como o conteúdo dinâmico é carregado ou renderizado pelas páginas da Web e como extraí-lo.
O que é conteúdo dinâmico?
Em páginas da Web, o conteúdo dinâmico refere-se a qualquer conteúdo que seja carregado ou renderizado no lado do cliente, seja durante o carregamento inicial da página ou após a interação do usuário. Isso inclui dados obtidos por meio de tecnologias como AJAX e WebSockets, bem como conteúdo incorporado em JavaScript e renderizado em tempo de execução no navegador.
Em particular, o conteúdo dinâmico não faz parte do documento HTML original retornado pelo servidor. Isso ocorre porque ele é adicionado à página após a execução do JavaScript. Isso significa que ele não estará visível a menos que a página seja renderizada em um navegador, que é o único tipo de ferramenta que pode executar JavaScript.
Como saber se uma página da Web usa conteúdo dinâmico
A maneira mais simples de saber se uma página é dinâmica ou não é seguir a abordagem oposta usada para detectar conteúdo estático. Se o documento HTML retornado pelo servidor não contiver o conteúdo que você vê na página, então existe algum mecanismo para recuperar ou renderizar esse conteúdo dinamicamente no cliente.
O contrário não necessariamente funciona. Se algum conteúdo estiver presente no HTML retornado pelo servidor, isso não significa que a página seja totalmente estática. Esse conteúdo pode estar obsoleto e o cliente pode atualizá-lo dinamicamente uma vez ou periodicamente após o carregamento da página. Esse é geralmente o caso de páginas que exibem atualizações ao vivo, por exemplo.
Em geral, para ver se uma página inclui conteúdo dinâmico, você pode recarregar a página ou repetir a ação do usuário que faz com que o conteúdo apareça enquanto inspeciona a seção “Rede” no DevTools do navegador:
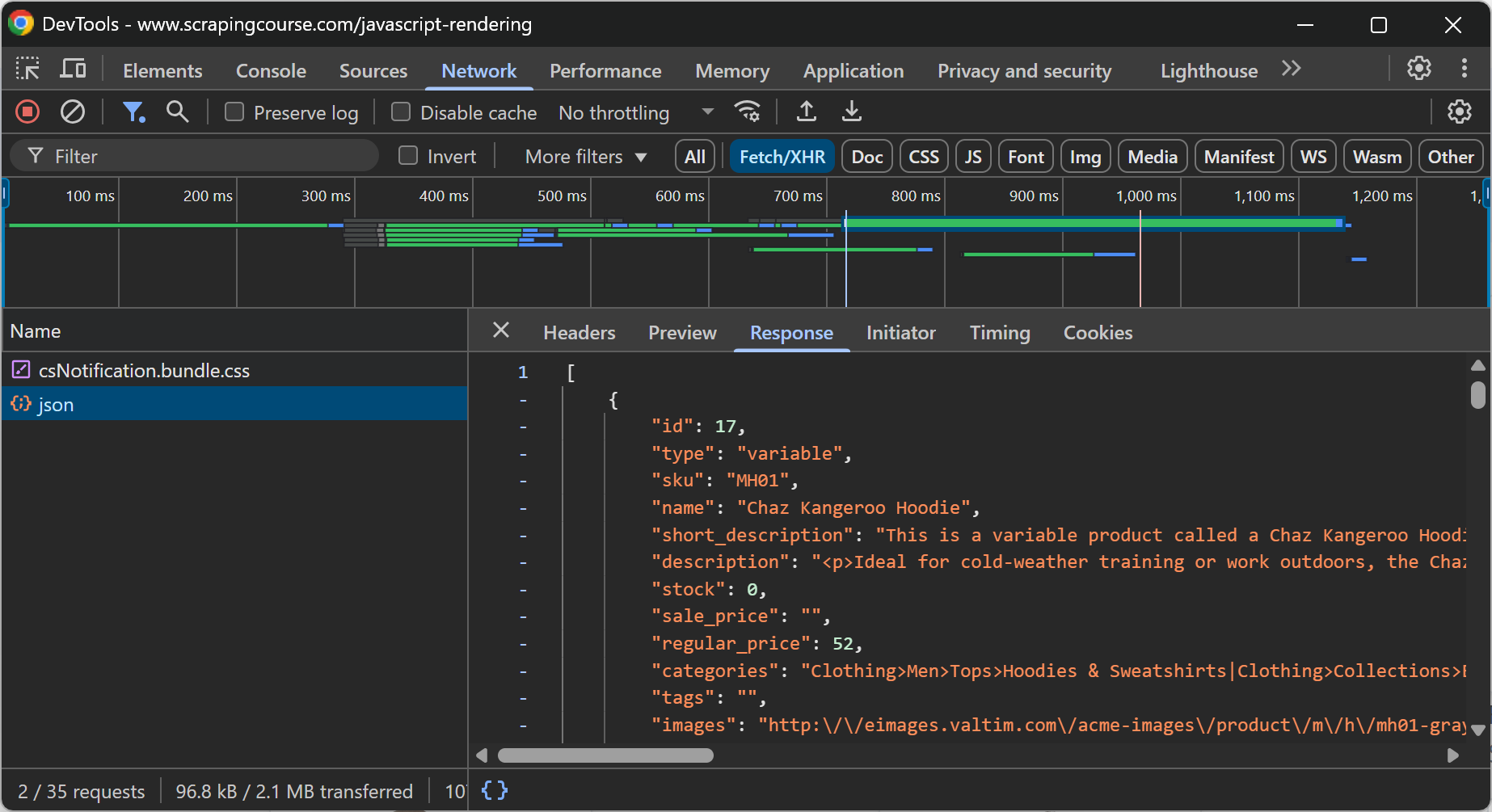
Por exemplo, na página da Web acima, fica claro que os dados do comércio eletrônico são recuperados dinamicamente no cliente por meio de uma chamada de API realizada via AJAX.
Outra possível fonte de conteúdo dinâmico são os aplicativos da Web criados como SPAs(aplicativos de página única). Eles são alimentados por tecnologias de front-end, como o React, que dependem muito da renderização de JavaScript. Portanto, se o DOM que você vê no DevTools for muito diferente do HTML retornado pelo servidor, então a página é dinâmica.
Ferramentas para raspagem de conteúdo dinâmico
O conteúdo dinâmico requer a execução de JavaScript para ser renderizado ou recuperado. Como somente os navegadores podem executar JavaScript, suas opções para extrair conteúdo dinâmico geralmente se limitam a ferramentas de automação do navegador, como Playwright, Selenium e Puppeteer.
Essas ferramentas expõem APIs que permitem controlar programaticamente um navegador real. Como resultado, a raspagem dinâmica de conteúdo da Web requer estas três etapas:
- Instrua o navegador a navegar até a página de destino.
- Aguardar a exibição de conteúdo dinâmico específico na página.
- Selecione e extraia esse conteúdo usando as APIs de seleção de nós e extração de dados que eles fornecem.
Para obter mais orientações, leia nosso artigo sobre como fazer scraping de sites dinâmicos em Python.
Desafios na raspagem de conteúdo dinâmico
A extração de conteúdo dinâmico é inerentemente muito mais desafiadora do que a extração de conteúdo estático. Primeiro, porque talvez seja necessário simular as interações do usuário em seu código para replicar todas as ações necessárias para acessar o conteúdo. Isso pode ser um problema quando se trata de sites com navegação complexa.
Em segundo lugar, porque as páginas dinâmicas da Web geralmente implementam medidas avançadas antirrastreamento e antibot, como CAPTCHAs, desafios de JavaScript, impressão digital do navegador e muito mais.
Além disso, lembre-se de que as ferramentas de automação do navegador devem instrumentar o navegador para controlá-lo. Essas alterações nas configurações do navegador podem ser suficientes para que os sistemas antibot avançados detectem você como um bot. Isso é particularmente verdadeiro quando se controla o navegador no modo headless para economizar recursos.
Uma solução alternativa de código aberto para esses problemas é usar bibliotecas de automação de navegador com recursos integrados de evasão antibot, como SeleniumBase, Undetected ChromeDriver, Playwright Stealth ou Puppeteer Stealth.
Ainda assim, essas soluções abordam apenas a ponta do iceberg e estão sujeitas a todos os problemas destacados na raspagem de conteúdo estático, como proibições de IP, problemas de reputação de IP e muito mais. Aqui está o motivo pelo qual a abordagem mais eficaz é usar uma solução como o Scraping Browser da Bright Data, que:
- Integra-se com Puppeteer, Playwright, Selenium e qualquer outra ferramenta de automação de navegador
- Funciona na nuvem e é dimensionado infinitamente
- Funciona com uma rede proxy de mais de 150 milhões de IPs
- Opera no modo headful para evitar a detecção de headless
- Vem com recursos integrados de resolução de CAPTCHA
- Possui recursos de desvio anti-bot de primeira linha
Conteúdo estático vs. dinâmico para raspagem da Web: Tabela de comparação
Esta é uma tabela de resumo que compara conteúdo estático e dinâmico para raspagem da Web:
| Aspecto | Conteúdo estático | Conteúdo dinâmico |
|---|---|---|
| Definição | Conteúdo incorporado diretamente na resposta HTML inicial do servidor | Conteúdo carregado ou renderizado via JavaScript após o carregamento da página |
| Visibilidade em HTML | Visível no documento HTML bruto retornado pelo servidor | Não visível no documento HTML inicial |
| Local da renderização | Renderização no lado do servidor | Renderização no lado do cliente |
| Métodos de detecção | – Opção “Exibir código-fonte da página – Inspecionar HTML em um cliente HTTP |
– Verificar as diferenças entre o HTML de origem e o DOM renderizado – Inspecionar a guia “Network” (Rede) do DevTools |
| Casos de uso comuns | – Conteúdo orientado para SEO – Listagens de informações simples |
– Atualizações ao vivo – Painéis de controle específicos do usuário – Conteúdo do SPA |
| Dificuldade de raspagem | Fácil | De médio a difícil |
| Abordagem de raspagem | Cliente HTTP + analisador HTML | Ferramentas de automação do navegador |
| Desempenho | Rápido, pois não há necessidade de renderização de JS | Lento, pois envolve a renderização de páginas no navegador e a espera pelo carregamento dos elementos |
| Principais desafios da raspagem | – Impressão digital de TLS – Limitação de taxa – Proibições de IP |
– CAPTCHAs – Fluxos complexos de navegação/interação – Desafios de JS |
| Ferramentas recomendadas para evitar bloqueios | Proxies, Web Unlocker | Navegador de raspagem |
| Exemplo de pilha | Pedidos + Sopa bonita | Playwright, Selenium ou Puppeteer |
Para obter uma lista de ferramentas de raspagem em linguagens de programação específicas que abrangem ambos os cenários, dê uma olhada nos guias abaixo:
- As melhores bibliotecas JavaScript de raspagem da Web
- Melhores bibliotecas de raspagem da Web em Python
- As 7 principais bibliotecas PHP de raspagem da Web
- As 7 principais bibliotecas de raspagem da Web em C#
Conclusão
Neste artigo, você entendeu as diferenças entre conteúdo estático e dinâmico em páginas da Web, com foco em raspagem da Web. Você aprendeu o que são esses dois tipos de conteúdo, como eles se diferenciam e como lidar com ambos ao analisar dados da Web.
Independentemente de estar lidando com conteúdo estático ou dinâmico, as coisas podem se complicar devido às medidas anti-raspagem e anti-bot. É aí que entra a Bright Data, que oferece um conjunto abrangente de ferramentas para atender a todas as suas necessidades de raspagem:
- Serviços de proxy: Vários tipos de proxies para contornar restrições geográficas, com mais de 150 milhões de IPs[1].
- Navegador de raspagem: Um navegador compatível com Playright, Selenium e Puppeter com recursos de desbloqueio incorporados.
- APIs do Web Scraper: APIs pré-configuradas para extrair dados estruturados de mais de 100 domínios principais.
- Web Unlocker: Uma API tudo em um que lida com o desbloqueio de sites com proteções antibot.
- API SERP: Uma API especializada que desbloqueia os resultados dos mecanismos de pesquisa e extrai dados SERP completos de todos os principais mecanismos de pesquisa[2].
Crie uma conta na Bright Data e teste nossos produtos de raspagem com uma avaliação gratuita!




