

A maioria dos dados de raspagem da web provém de sítios web dinâmicos, como o a Amazon e o YouTube. Estes sítios web proporcionam uma experiência de usuário interativa e reativa com base nos contributos dos usuários. Por exemplo, quando o usuário acede à sua conta de YouTube, o conteúdo de vídeo apresentado é adaptado às suas entradas. Consequentemente, a raspagem da web de sítios dinâmicos pode ser mais difícil, uma vez que os dados estão sujeitos a modificações constantes devido às interações dos usuários.
Para extrair dados de sítios dinâmicos, é necessário utilizar técnicas avançadas que simulem a interação de um usuário com o sítio web, naveguem e selecionem conteúdos específicos gerados por JavaScript e lidem com pedidos assíncronos de JavaScript e XML (AJAX).
Neste guia, você aprenderá a raspar dados de um sítio dinâmico usando uma biblioteca de Python de código aberto chamada Selenium.
Raspar dados de um sítio web dinâmico com Selenium
Antes de começar a raspar dados de um sítio dinâmico, você precisa entender o pacote de Python que você usará: Selenium.
O que é Selenium?
Selenium é um pacote de Python de código aberto e estrutura de teste automatizada que permite executar várias operações ou tarefas em sítios web dinâmicos. Estas tarefas incluem coisas como abrir/fechar caixas de diálogo, procurar consultas específicas no YouTube ou preencher formulários, tudo no seu navegador web preferido.
Quando utiliza o Selenium com Python, pode controlar o seu navegador web e extrair automaticamente dados de sítios web dinâmicos, escrevendo apenas algumas linhas de código de Python com o pacote Selenium de Python.
Agora que já sabe como funciona o Selenium, vamos começar.
Criar um projeto em Python
A primeira coisa que precisa de fazer é criar um projeto em Python. Crie um diretório chamado data_scraping_project onde todos os dados coletados e ficheiros de código-fonte serão armazenados. Este diretório terá dois subdiretórios:
scriptsconterá todos os scripts de Python que extraem e coletam dados do sítio web dinâmico.dadosé onde serão armazenados todos os dados extraídos de um sítio web dinâmico.
Instalar os pacotes de Python
Depois de criar o diretório data_scraping_project, é necessário instalar os seguintes pacotes de Python para o ajudar a raspar, coletar e guardar dados de um sítio web dinâmico:
- Gestor do Webdriver
- pandas
Pode instalar o pacote Selenium de Python executando o seguinte comando pip no seu terminal:
pip install selenium
O Selenium utilizará o driver binário para controlar o navegador web da sua escolha. Este pacote de Python fornece drivers binários para os seguintes navegadores web suportados: Chrome, Chromium, Brave, Firefox, IE, Edge e Opera.
Em seguida, execute o seguinte comando pip no seu terminal para instalar o webdriver-manager:
pip install webdriver-manager
Para instalar pandas, execute o seguinte comando pip:
pip install pandas
O que vai raspar
Neste artigo, vai extrair dados de dois sítios diferentes: um canal do YouTube chamado Programming with Mosh e o Hacker News:
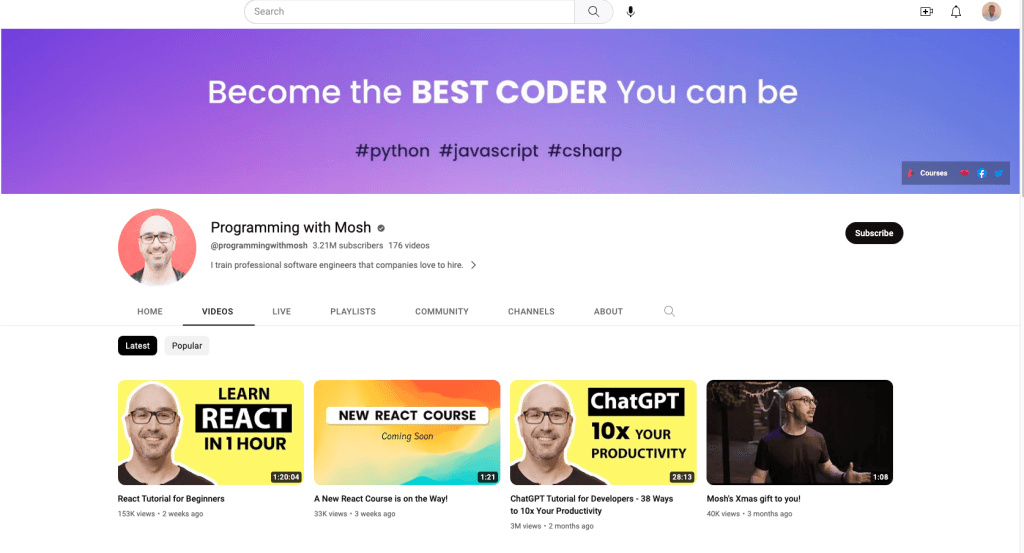
A partir do canal de YouTube Programming with Mosh, raspará as seguintes informações:
- O título do vídeo.
- O link ou URL do vídeo.
- O link ou URL da imagem.
- O número de visualizações do vídeo em particular.
- A hora a que o vídeo foi publicado.
- Comentários de um determinado URL de vídeo do YouTube.
E a partir do Hacker News, irá coletar os seguintes dados:
- O título do artigo.
- O link para o artigo.

Agora que já sabe o que vai coletar, vamos criar um script de Python (ou seja, data_scraping_project/scripts/youtube_videos_list.py).
Importar pacotes de Python
Em primeiro lugar, é necessário importar os pacotes de Python que irá utilizar para raspar, coletar e guardar dados num ficheiro CSV:
# import libraries
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pandas as pd
Instanciar o Webdriver
Para instanciar o Webdriver, é necessário selecionar o navegador que o Selenium irá utilizar (neste caso, o Chrome) e, em seguida, instalar o driver binário.
O Chrome tem ferramentas de desenvolvedor para exibir o código HTML da página web e identificar elementos HTML para raspar e coletar os dados. Para exibir o código HTML, você precisa clicar com o botão direito do rato numa página web no navegador Chrome e selecionar Inspecionar elemento.
Para instalar um driver binário para o Chrome, execute o seguinte código:
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
O driver binário para o Chrome será instalado no seu computador e instanciará automaticamente o Webdriver.
Raspar dados com Selenium
Para raspar dados com o Selenium, você precisa definir o URL do YouTube em uma variável de Python simples (ou seja, url). A partir deste link, você coleta todos os dados que foram mencionados anteriormente, exceto os comentários de um URL específico do YouTube:
# Define the URL
url = "https://www.youtube.com/@programmingwithmosh/videos"
# load the web page
driver.get(url)
# set maximum time to load the web page in seconds
driver.implicitly_wait(10)
O Selenium carrega automaticamente o link do YouTube no navegador Chrome. Além disso, é especificado um período de tempo (ou seja, dez segundos) para garantir que a página web está totalmente carregada (incluindo todos os elementos HTML). Isto ajuda-o a raspar dados que são processados por JavaScript.
Raspar dados usando ID e etiquetas
Uma das vantagens do Selenium é o facto de poder extrair dados utilizando diferentes elementos apresentados na página web, incluindo o ID e a etiqueta.
Por exemplo, pode utilizar o elemento ID (ou seja, post-title) ou as etiquetas (ou seja, h1 e p) para raspar os dados:
<h1 id ="post-title">Introduction to data scrapping using Python</h1>
<p>You can use selenium python package to collect data from any dynamic website</p>
Ou, se você quiser raspar dados do link do YouTube, você precisa usar o ID apresentado na página web. Abra o URL do YouTube no seu navegador web e, em seguida, clique com o botão direito do rato e selecione Inspecionar para identificar o ID. Em seguida, utilize o rato para visualizar a página e identificar o ID que contém a lista de vídeos apresentados no canal:
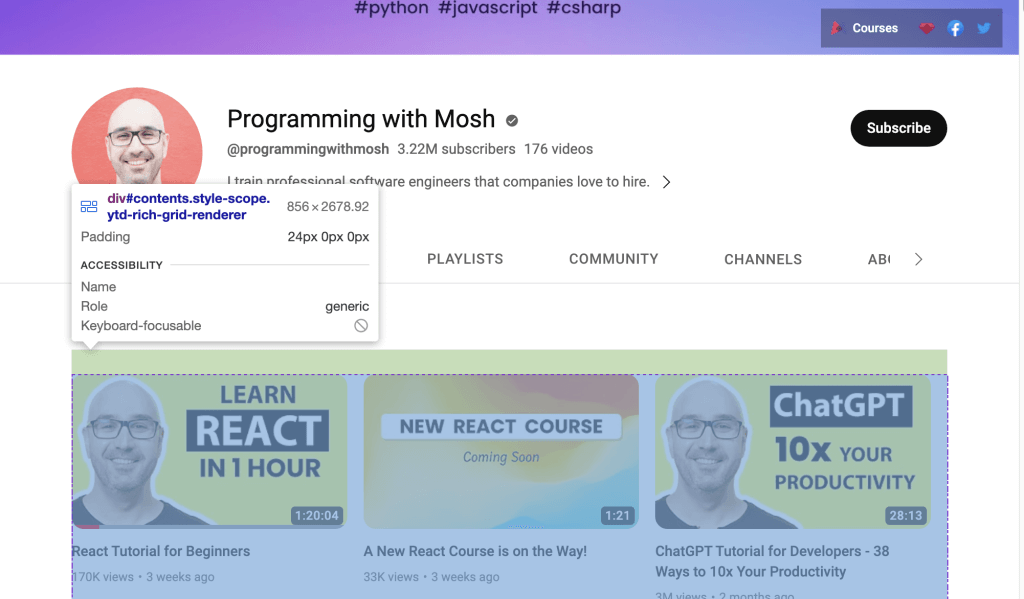
Use o Webdriver para raspar dados que estão dentro do ID identificado. Para localizar um elemento HTML pelo atributo ID, chame o método find_element() do Selenium e passe By.ID como o primeiro argumento e ID como o segundo argumento.
Para coletar o título do vídeo e o link do vídeo para cada vídeo, você precisa usar o atributo de ID video-title-link. Como você coletará vários elementos HTML com esse atributo ID, precisará usar o método find_elements():
# collect data that are withing the id of contents
contents = driver.find_element(By.ID, "contents")
#1 Get all the by video tite link using id video-title-link
video_elements = contents.find_elements(By.ID, "video-title-link")
#2 collect title and link for each youtube video
titles = []
links = []
for video in video_elements:
#3 Extract the video title
video_title = video.get_attribute("title")
#4 append the video title
titles.append(video_title)
#5 Extract the video link
video_link = video.get_attribute("href")
#6 append the video link
links.append(video_link)
Este código executa as seguintes tarefas:
- Coleta dados que estão dentro do atributo ID
contents. - Coleta todos os elementos HTML que têm um atributo ID
video-title-linkdo objeto WebElementcontents. - Cria duas listas para anexar títulos e links.
- Extrai o título do vídeo utilizando o método
get_attribute()e passa otitle. - Anexa o título do vídeo à lista de títulos.
- Extrai o link do vídeo utilizando o método
get_atribute()e passahrefcomo argumento. - Anexa o link de vídeo à lista de links.
Neste ponto, todos os títulos e links de vídeo estarão em duas listas de Python: titles e links.
Em seguida, é necessário raspar o link da imagem que está disponível na página web antes de clicar no link do vídeo do YouTube para ver o vídeo. Para raspar esse link de imagem, você precisa encontrar todos os elementos HTML chamando o método de Selenium find_elements() e passando By.TAG_NAME como o primeiro argumento e o nome da etiqueta como o segundo argumento:
#1 Get all the by Tag
img_elements = contents.find_elements(By.TAG_NAME, "img")
#2 collect img link and link for each youtube video
img_links = []
for img in img_elements:
#3 Extract the img link
img_link = img.get_attribute("src")
if img_link:
#4 append the img link
img_links.append(img_link)
Esse código coleta todos os elementos HTML com o nome da etiqueta img do objeto WebElement chamado contents. Também cria uma lista para anexar os links das imagens e extrai-as utilizando o método get_attribute() e passa src como argumento. Finalmente, acrescenta o link da imagem à lista de img_links.
Também pode utilizar o ID e o nome da etiqueta para raspar mais dados para cada vídeo do YouTube. Na página web do URL do YouTube, deve ser possível ver o número de visualizações e a hora de publicação de cada vídeo listado na página. Para extrair estes dados, é necessário coletar todos os elementos HTML que tenham um ID de metadata-line e, em seguida, coletar dados dos elementos HTML com um nome de etiqueta span:
#1 find the element with the specific ID you want to scrape
meta_data_elements = contents.find_elements(By.ID, 'metadata-line')
#2 collect data from span tag
meta_data = []
for element in meta_data_elements:
#3 collect span HTML element
span_tags = element.find_elements(By.TAG_NAME, 'span')
#4 collect span data
span_data = []
for span in span_tags:
#5 extract data for each span HMTL element.
span_data.append(span.text)
#6 append span data to the list
meta_data.append(span_data)
# print out the scraped data.
print(meta_data)
Este bloco de código coleta todos os elementos HTML que têm um atributo ID de metadata-line do objeto WebElement contents e cria uma lista para acrescentar dados da etiqueta span que terá o número de exibições e o tempo publicado.
Também coleta todos os elementos HTML cujo nome de etiqueta é span do objeto WebElement chamado meta_data_elements e cria uma lista com esses dados de span. Em seguida, extrai os dados de texto do elemento HTML span e acrescenta-os à lista span_data. Finalmente, anexa os dados da lista span_data a meta_data.
Os dados extraídos do elemento HTML span terão o seguinte aspeto:

Em seguida, é necessário criar duas listas em Python e guardar o número de visualizações e o tempo de publicação separadamente:
#1 Iterate over the list of lists and collect the first and second item of each sublist
views_list = []
published_list = []
for sublist in meta_data:
#2 append number of views in the views_list
views_list.append(sublist[0])
#3 append time published in the published_list
published_list.append(sublist[1])
Aqui, cria duas listas em Python que extraem dados de meta_data e anexa o número de visualizações de cada sub-lista a view_list e a hora de publicação de cada sub-lista a published_list.
Neste ponto, você raspou o título do vídeo, a URL da página do vídeo, a URL da imagem, o número de visualizações e a hora em que o vídeo foi publicado. Estes dados podem ser guardados num DataFrame de pandas utilizando o pacote pandas de Python. Use o código a seguir para salvar os dados da lista de títulos, links, img_links, views_list e published_list no DataFrame de pandas:
# save in pandas dataFrame
data = pd.DataFrame(
list(zip(titles, links, img_links, views_list, published_list)),
columns=['Title', 'Link', 'Img_Link', 'Views', 'Published']
)
# show the top 10 rows
data.head(10)
# export data into a csv file.
data.to_csv("../data/youtube_data.csv",index=False)
driver.quit()
Este é o aspeto que os dados raspados devem ter no DataFrame de pandas:

Estes dados guardados são exportados de pandas para um ficheiro CSV chamado youtube_data.csv utilizando to_csv().
Agora pode executar youtube_videos_list.py e certificar-se de que tudo funciona corretamente.
Raspar dados usando o Seletor de CSS
O Selenium também pode extrair dados com base em padrões específicos nos elementos HTML utilizando o seletor de CSS na página web. O seletor de CSS é aplicado para direcionar elementos específicos de acordo com o seu ID, nome da etiqueta, classe ou outros atributos.
Por exemplo, aqui, a página HTML tem alguns elementos div, e um deles tem um nome de classe "inline-code":
<html>
<body>
<p>Hello World!</p>
<div>Learn Data Scraping</div>
<div class="inline-code"> data scraping with Python code</div>
<div>Saving</div>
</body>
</html>
Pode utilizar um seletor de CSS para encontrar o elemento HTML numa página web cujo nome de etiqueta seja div e cujo nome de classe seja “‘inline-code”. Pode aplicar esta mesma abordagem para extrair comentários da seção de comentários dos vídeos do YouTube.
Agora, vamos utilizar um seletor de CSS para coletar os comentários publicados neste vídeo do YouTube.
A seção de comentários do YouTube está disponível com a seguinte etiqueta e nome de classe:
<ytd-comment-thread-renderer class="style-scope ytd-item-section-renderer">...</tyd-comment-thread-renderer>
Vamos criar um script (ou seja, data_scraping_project/scripts/youtube_video_
comments.py). Importe todos os pacotes necessários como antes e adicione o seguinte código para iniciar automaticamente o navegador Chrome, navegar pelo URL do vídeo do YouTube e raspar os comentários usando o seletor de CSS:
#1 instantiate chrome driver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#2 Define the URL
url = "https://www.youtube.com/watch?v=hZB5bHDCmeY"
#3 Load the webpage
driver.get(url)
#4 define the CSS selector
comment_section = 'ytd-comment-thread-renderer.ytd-item-section-renderer’
#5 wait until element matching the given criteria to be found
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, comment_section))
)
except:
driver.quit()
#6. collect HTML elements within the CSS selector
comment_blocks = driver.find_elements(By.CSS_SELECTOR,comment_section)
Este código instancia o driver do Chrome e define o link do vídeo do YouTube para raspar os comentários que foram postados. Em seguida, carrega a página web no navegador e aguarda dez segundos até que os elementos HTML correspondentes ao seletor de CSS estejam disponíveis.
Em seguida, coleta todos os elementos HTML comment usando o seletor de CSS chamado ytd-comment-thread-renderer.ytd-item-section-renderer e guarda todos os elementos de comentários no objeto WebElement comment_blocks.
Em seguida, é possível extrair o nome de cada autor utilizando o ID author-text e o texto do comentário utilizando o ID content-text de cada comentário no objeto WebElement comment_blocks:
#1 specify the id attribute for author and comment
author_id = 'author-text'
comment_id = 'content-text'
#2 Extract the text value for each comment and author in the list
comments = []
authors = []
for comment_element in comment_blocks:
#3 collect author for each comment
author = comment_element.find_element(By.ID, author_id)
#4 append author name
authors.append(author.text)
#5 collect comments
comment = comment_element.find_element(By.ID, comment_id)
#6 append comment text
comments.append(comment.text)
#7 save in pandas dataFrame
comments_df = pd.DataFrame(list(zip(authors, comments)), columns=['Author', 'Comment'])
#8 export data into a CSV file.
comments_df.to_csv("../data/youtube_comments_data.csv",index=False)
driver.quit()
Este código especifica a identificação do autor e do comentário. Em seguida, cria duas listas em Python para anexar o nome do autor e o texto do comentário. Coleta cada elemento HTML que tenha os atributos de ID especificados do objeto WebElement e anexa os dados às listas em Python.
Finalmente, guarda os dados raspados num DataFrame de pandas e exporta os dados para um ficheiro CSV chamado youtube_comments_data.csv.
Este é o aspeto dos autores e comentários das primeiras dez linhas num DataFrame de pandas:

Raspar dados usando o Nome da Classe
Para além de raspar dados com o seletor de CSS, também pode extrair dados com base num nome de classe específico. Para encontrar um elemento HTML pelo seu atributo de nome de classe utilizando o Selenium, é necessário chamar o método find_element() e passar By.CLASS_NAME como primeiro argumento, e é necessário encontrar o nome da classe como segundo argumento.
Nesta seção, você usará o nome da classe para coletar o título e o link dos artigos publicados no Hacker News. Nesta página web, o elemento HTML que tem o título e o link de cada artigo tem um nome de classe titleline, como se pode ver no código da página web:
<span class="titleline"><a href="https://mullvad.net/en/browser">The Mullvad Browser</a><span class="sitebit comhead"> (<a href="from?site=mullvad.net"><span class="sitestr">mullvad.net</span></a>)</span></span></td></tr><tr><td colspan="2"></td><td class="subtext"><span class="subline">
<span class="score" id="score_35421034">302 points</span> by <a href="user?id=Foxboron" class="hnuser">Foxboron</a> <span class="age" title="2023-04-03T10:11:50"><a href="item?id=35421034">2 hours ago</a></span> <span id="unv_35421034"></span> | <a href="hide?id=35421034&auth=60e6bdf9e482441408eb9ca98f92b13ee2fac24d&goto=news" class="clicky">hide</a> | <a href="item?id=35421034">119 comments</a> </span>
Crie um script de Python (ou seja, data_scraping_project/scripts/hacker_news.py), importe todos os pacotes necessários e adicione o seguinte código de Python para raspar o título e o link para cada artigo publicado na página Hacker News:
#1 define url
hacker_news_url = 'https://news.ycombinator.com/'
#2 instantiate chrome driver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#3 load the web page
driver.get(hacker_news_url)
#4 wait until element matching the given criteria to be found
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'titleline'))
)
except:
driver.quit()
#5 Extract the text value for each title and link in the list
titles= []
links = []
#6 Find all the articles on the web page
story_elements = driver.find_elements(By.CLASS_NAME, 'titleline')
#7 Extract title and link for each article
for story_element in story_elements:
#8 append title to the titles list
titles.append(story_element.text)
#9 extract the URL of the article
link = story_element.find_element(By.TAG_NAME, "a")
#10 appen link to the links list
links.append(link.get_attribute("href"))
driver.quit()
Este código definirá o URL da página Web, iniciará automaticamente o navegador web Chrome e, em seguida, navegará no URL de Hacker News. Aguarda dez segundos até que os elementos HTML que correspondem ao NOME DA CLASSE estejam disponíveis.
Em seguida, cria duas listas em Python para anexar o título e o link de cada artigo. Também coleta cada elemento HTML que tenha um nome de classe titleline do objeto driver WebElement e extrai o título e o link para cada artigo representado no objeto WebElement story_elements.
Finalmente, o código acrescenta o título do artigo à lista de títulos e coleta o elemento HTML que tenha um nome de etiqueta a do objeto story_element. Extrai o link usando o método get_attribute() e acrescenta o link à lista de links.
Em seguida, é necessário utilizar o método to_csv() de pandas para exportar os dados raspados. Você exportará os títulos e links para um ficheiro CSV hacker_news_data.csv e guardará os dados no diretório:
# save in pandas dataFrame
hacker_news = pd.DataFrame(list(zip(titles, links)),columns=['Title', 'Link'])
# export data into a csv file.
hacker_news.to_csv("../data/hacker_news_data.csv",index=False)
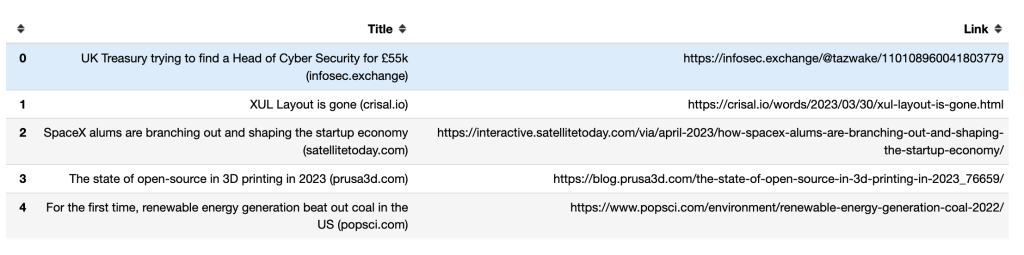
É assim que os títulos e links das cinco primeiras linhas aparecem num DataFrame de pandas:
Como lidar com a rolagem infinita
Algumas páginas web dinâmicas carregam conteúdo adicional à medida que o usuário rola até a parte inferior da página. Se você não navegar até a parte inferior, o Selenium pode apenas raspar os dados que estão visíveis na tela.
Para raspar mais dados, você precisa instruir o Selenium a rolar até a parte inferior da página, aguardar até que o novo conteúdo seja carregado e, em seguida, raspar automaticamente os dados desejados. Por exemplo, o seguinte script de Python percorrerá os primeiros quarenta resultados de livros em Python e extrairá os seus links:
#1 import packages
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
#2 Instantiate a Chrome webdriver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#3 Navigate to the webpage
driver.get("https://example.com/results?search_query=python+books")
#4 instantiate a list to keep links
books_list = []
#5 Get the height of the current webpage
last_height = driver.execute_script("return document.body.scrollHeight")
#6 set target count
books_count = 40
#7 Keep scrolling down on the web page
while books_count > len(books_list):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
#8 Wait for the page to load
time.sleep(5)
#9 Calculate the new height of the page
new_height = driver.execute_script("return document.body.scrollHeight")
#10 Check if you have reached the bottom of the page
if new_height == last_height:
break
last_height = new_height
#11 Extract the data
links = driver.find_elements(By.TAG_NAME, "a")
for link in links:
#12 append extracted data
books_list.append(link.get_attribute("href"))
#13 Close the webdriver
driver.quit()
Este código importa os pacotes de Python que serão utilizados e instancia e abre o Chrome. Em seguida, navega para a página web e cria uma lista em Python para anexar o link a cada um dos resultados da pesquisa.
Obtém a altura da página atual executando o script de retorno document.body.scrollHeight e define o número de links que você deseja coletar. Em seguida, continua a rolar para baixo desde que o valor da variável book_count seja maior do que o comprimento do book_list e aguarda cinco segundos para carregar a página.
Calcula a nova altura da página web executando o script de retorno document.body.scrollHeight e verifica se atingiu a parte inferior da página. Se for esse o caso, o ciclo é terminado; caso contrário, atualiza a last_height (última altura) e continua a deslocar-se para baixo. Finalmente, coleta o elemento HTML que tenha um nome de etiqueta a do objeto WebElement e extrai e acrescenta o link à lista de links. Depois de coletar os links, fechará o Webdriver.
Atenção: Para que seu script termine em algum momento, você deve definir um número total de itens a serem raspados se a página tiver rolagem infinita. Se não o fizer, o seu código continuará a ser executado.
Raspagem da web com Bright Data
Embora seja possível raspar dados com raspadores de fonte aberta como o Selenium, eles tendem a não ter suporte. Além disso, o processo pode ser complicado e demorado. Se procura uma solução de raspagem da web potente e fiável, deve considerar Bright Data.
A Bright Data é uma plataforma de dados da web que lhe permite raspar dados públicos da web, fornecendo diferentes ferramentas e serviços que incluem soluções de raspagem da web, proxies e conjuntos de dados pré-coletados. Você pode até mesmo usar o IDE para Raspador da Web alojado para projetar seus próprios raspadores num ambiente de codificação JavaScript.
O IDE para Raspador da Web também é alimentado por funções de raspagem pré-construídas e modelos de código para diferentes sítios dinâmicos populares, incluindo modelos de raspador do Indeed e raspador do Walmart. Isto significa que é fácil acelerar o desenvolvimento e escalar rapidamente.
Bright Data oferece uma gama de opções para formatar seus dados, incluindo JSON, NDJSON, CSV e Microsoft Excel. Também está integrado em diferentes plataformas para que possa fornecer facilmente os seus dados raspados.
Conclusão
Embora seja possível extrair dados com o Selenium, é demorado e complicado. É por isso que se recomenda a raspagem de sítios web dinâmicos com o IDE para Raspador da Web. Com as suas funções de raspagem pré-construídas e modelos de código, pode começar a extrair dados imediatamente.
Embora seja possível extrair dados com o Selenium, é demorado e complicado. É por isso que se recomenda a raspagem de sítios web dinâmicos com o IDE para Raspador da Web. Com as suas funções de raspagem pré-construídas e modelos de código, pode começar a extrair dados imediatamente.




