

Os proxies são endereços IP de um servidor proxy que se liga à Internet em seu nome. Em vez de transmitir diretamente os seus pedidos ao sítio web que visita, quando se liga à Internet através de um proxy, os seus pedidos são encaminhados através do servidor proxy. A utilização de um servidor proxy é uma ótima forma de proteger a sua privacidade em linha e aumentar a segurança:
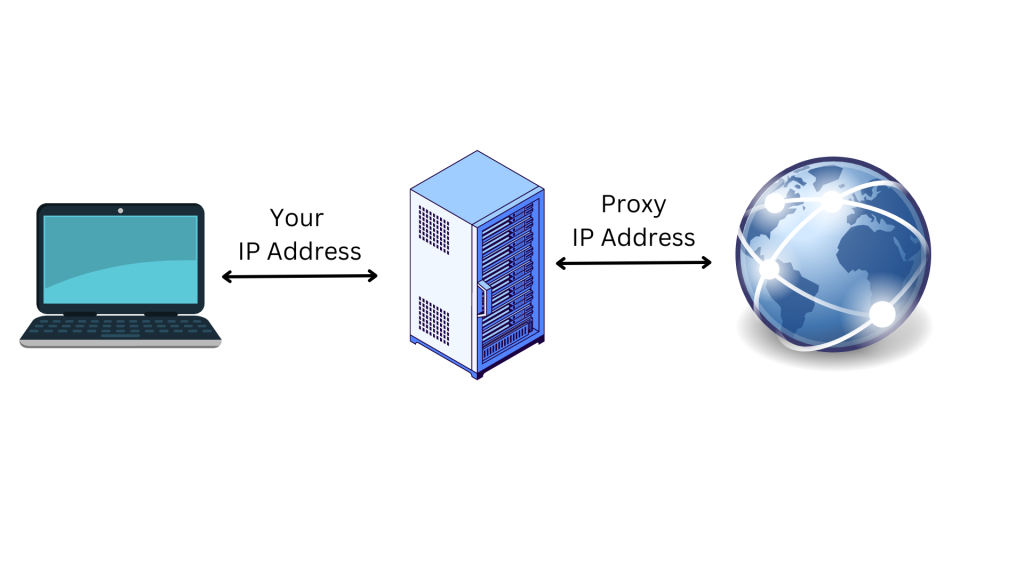
O servidor proxy atua como um computador intermediário, o que significa que o seu endereço IP original e a sua localização são ocultados do sítio web. Isto ajuda a protegê-lo do rastreio em linha, da publicidade direcionada e de ser bloqueado pelo sítio web a que está a tentar aceder. Os proxies também oferecem uma camada adicional de segurança, encriptando os seus dados à medida que estes viajam entre o seu dispositivo e o servidor proxy.
Neste artigo, você aprenderá mais sobre proxies e como usá-los com Requests de Python. Aprenderá também porque é que isto pode ser útil quando se trabalha num projeto de raspagem da web.
Porque é que precisa de proxies quando faz raspagem da web
A raspagem da web é um processo automatizado de extração de dados de sítios web para diferentes fins, incluindo agregação de dados, pesquisa de mercado e análise de dados. No entanto, muitos destes sítios web têm restrições que dificultam o acesso às informações pretendidas.
Felizmente, os proxies podem ajudá-lo a contornar as restrições baseadas no IP e na localização. Por exemplo, em alguns casos, os sítios web fornecem informações diferentes para locais específicos, como um país ou um estado. Se não estiver localizado nesse local específico, não poderá aceder às informações que procura sem um proxy, que pode contornar o IP e alterar a sua localização.
Além disso, a maioria dos sítios web bloqueia os endereços IP dos dispositivos que estão envolvidos em atividades de raspagem da web. Nesta situação, pode implementar um proxy para ocultar o seu endereço IP e a sua localização, tornando mais difícil para o sítio web identificá-lo e bloqueá-lo.
Também é possível utilizar vários proxies ao mesmo tempo para distribuir as atividades de raspagem da web por diferentes endereços IP e acelerar o processo de raspagem, permitindo que o “raspador” faça vários pedidos em simultâneo.
Agora que já sabe como os proxies podem ajudar no que diz respeito a projetos de raspagem da web, vai aprender a seguir como implementar um proxy no seu projeto utilizando o pacote Requests de Python.
Como utilizar um proxy com um pedido de Python
Para utilizar um proxy com um pedido de Python, é necessário criar um projeto Python no seu computador para escrever e executar os scripts de Python para a raspagem da web. Crie um diretório (ou seja, web_scrape_project) onde irá armazenar os seus ficheiros de código-fonte.
Todos os códigos para este tutorial estão disponíveis neste repositório do GitHub.
Instalar pacotes
Depois de ter criado o seu diretório, precisa de instalar os seguintes pacotes de Python para enviar pedidos à página web e coletar as ligações:
- Beautiful Soup
Componentes do endereço IP de proxy
Antes de utilizar um proxy, é melhor compreender os seus componentes. Seguem-se os três componentes principais de um servidor proxy:
- O protocolo indica o tipo de conteúdo a que pode aceder na Internet. Os protocolos mais comuns são HTTP e HTTPS.
- O endereço mostra onde o servidor proxy está localizado. O endereço pode ser um IP (por exemplo,
192.167.0.1) ou um nome de host DNS (por exemplo,proxyprovider.com). - Porto utilizado para direcionar o tráfego para o processo de servidor correto quando vários serviços são executados numa única máquina (ou seja, porto número
2000).
Usando todos esses três componentes, um endereço IP de proxy teria a seguinte aparência: 192.167.0.1:2000 ou proxyprovider.com:2000.
Como definir proxies diretamente em Requests
Existem várias formas de definir proxies em Requests de Python e, neste artigo, irá analisar três cenários diferentes. Neste primeiro exemplo, aprenderá a definir proxies diretamente no módulo Requests.
Para começar, é necessário importar os pacotes Requests e Beautiful Soup no seu ficheiro Python para a raspagem da web. Em seguida, crie um diretório chamado proxies que contenha informações sobre o servidor proxy para ocultar o seu endereço IP quando estiver a raspar a página web. Aqui, é necessário definir as ligações HTTP e HTTPS para o URL do proxy.
Também precisa de definir a variável Python para definir o URL da página web a partir da qual pretende raspar os dados. Para este tutorial, o URL é https://brightdata.com/
Em seguida, é necessário enviar um pedido GET para a página web utilizando o método Em seguida, é necessário enviar um pedido GET para a página web utilizando o método request.get(). O método recebe dois argumentos: o URL do sítio web e os proxies. Em seguida, a resposta da página web é armazenada na variável de resposta.
Para coletar as hiperligações, utilize o pacote Beautiful Soup para analisar o conteúdo HTML da página web, passando response.content e html.parser como argumentos para o método BeautifulSoup().
Em seguida, utilize o método find_all() com a como argumento para encontrar todas as ligações na página web. Finalmente, extraia o atributo href de cada ligação utilizando o método get().
Segue-se o código-fonte completo para definir proxies diretamente em Requests:
# import packages.
import requests
from bs4 import BeautifulSoup
# Define proxies to use.
proxies = {
'http': 'http://proxyprovider.com:2000',
'https': 'http://proxyprovider.com:2000',
}
# Define a link to the web page.
url = "https://brightdata.com/"
# Send a GET request to the website.
response = requests.get(url, proxies=proxies)
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
Quando executa este bloco de código, envia um pedido para a página web definida utilizando o endereço IP do proxy e, em seguida, devolve a resposta que contém todas as ligações para essa página web:

Como definir proxies através de variáveis de ambiente
Por vezes, é necessário utilizar o mesmo proxy para todos os pedidos a diferentes páginas web. Neste caso, faz sentido definir variáveis de ambiente para o seu proxy.
Para tornar as variáveis de ambiente do proxy disponíveis sempre que executar scripts no shell, execute o seguinte comando no terminal:
export HTTP_PROXY='http://proxyprovider.com:2000'
export HTTPS_PROXY='https://proxyprovider.com:2000'
Aqui, a variável HTTP_PROXY define o servidor proxy para pedidos HTTP, e a variável HTTPS_PROXY define o servidor proxy para pedidos HTTPS.
Nesta altura, o seu código em Python tem algumas linhas de código e utiliza as variáveis de ambiente sempre que faz um pedido à página web:
# import packages.
import requests
from bs4 import BeautifulSoup
# Define a link to the web page.
url = "https://brightdata.com/"
# Send a GET request to the website.
response = requests.get(url)
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
Como rotar proxies utilizando um método personalizado e uma matriz de proxies
A rotação de proxies é crucial porque os sítios web bloqueiam ou restringem frequentemente o acesso a bots e raspadores quando recebem um grande número de pedidos do mesmo endereço IP. Quando isto acontece, os sítios web podem suspeitar de atividade de raspagem maliciosa e, consequentemente, implementar medidas para bloquear ou limitar o acesso.
Ao alternar entre diferentes endereços IP de proxy, pode evitar ser detetado, aparecer como vários usuários orgânicos e contornar a maioria das medidas antirraspagem implementadas no sítio web.
Para rotar proxies, é necessário importar algumas bibliotecas de Python: Requests, Beautiful Soup e Random.
Em seguida, crie uma lista de proxies para utilizar durante o processo de rotação. Esta lista deve conter os URLs dos servidores proxy no seguinte formato: http://proxyserver.com:port:
# List of proxies
proxies = [
"http://proxyprovider1.com:2010", "http://proxyprovider1.com:2020",
"http://proxyprovider1.com:2030", "http://proxyprovider2.com:2040",
"http://proxyprovider2.com:2050", "http://proxyprovider2.com:2060",
"http://proxyprovider3.com:2070", "http://proxyprovider3.com:2080",
"http://proxyprovider3.com:2090"
]
Em seguida, crie um método personalizado chamado get_proxy(). Este método seleciona aleatoriamente um proxy da lista de proxies utilizando o método random.choice() e devolve o proxy selecionado em formato de dicionário (chaves HTTP e HTTPS). Utilizará este método sempre que enviar um novo pedido:
# Custom method to rotate proxies
def get_proxy():
# Choose a random proxy from the list
proxy = random.choice(proxies)
# Return a dictionary with the proxy for both http and https protocols
return {'http': proxy, 'https': proxy}
Depois de criar o método get_proxy(), é necessário criar um ciclo (loop) que envia um determinado número de pedidos GET utilizando os proxies rotativos. Em cada pedido, o método get() utiliza um proxy escolhido aleatoriamente, especificado pelo método get_proxy().
Em seguida, é necessário coletar as ligações do conteúdo HTML da página web utilizando o pacote Beautiful Soup, tal como explicado no primeiro exemplo.
Finalmente, o código Python captura quaisquer exceções que ocorram durante o processo de pedido e imprime a mensagem de erro na consola.
Aqui está o código fonte completo para este exemplo:
# import packages
import requests
from bs4 import BeautifulSoup
import random
# List of proxies
proxies = [
"http://proxyprovider1.com:2010", "http://proxyprovider1.com:2020",
"http://proxyprovider1.com:2030", "http://proxyprovider2.com:2040",
"http://proxyprovider2.com:2050", "http://proxyprovider2.com:2060",
"http://proxyprovider3.com:2070", "http://proxyprovider3.com:2080",
"http://proxyprovider3.com:2090"
]
# Custom method to rotate proxies
def get_proxy():
# Choose a random proxy from the list
proxy = random.choice(proxies)
# Return a dictionary with the proxy for both http and https protocols
return {'http': proxy, 'https': proxy}
# Send requests using rotated proxies
for i in range(10):
# Set the URL to scrape
url = 'https://brightdata.com/'
try:
# Send a GET request with a randomly chosen proxy
response = requests.get(url, proxies=get_proxy())
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
except requests.exceptions.RequestException as e:
# Handle any exceptions that may occur during the request
print(e)
Usar o serviço de proxy de Bright Data com Python
Se está à procura de um proxy fiável, rápido e estável para as suas tarefas de raspagem da web, então não procure mais do que a Bright Data, uma plataforma de dados da web que oferece diferentes tipos de proxies para uma vasta gama de casos de utilização.
A Bright Data tem uma grande rede de mais de 400M+ monthly de IPs residenciais e mais de 770.000 proxies de centros de dados que ajudam a fornecer soluções de proxy fiáveis e rápidas. As suas ofertas de proxy foram concebidas para o ajudar a ultrapassar os desafios da raspagem da web, verificação de anúncios e outras atividades em linha que requerem uma coleta anónima e eficiente de dados da web.
Integrar os proxies da Bright Data nos seus pedidos de Python é fácil. Por exemplo, utilize os Proxies do centro de dados para enviar um pedido para o URL utilizado nos exemplos anteriores.
Se ainda não tem uma conta, inscreva-se para obter um teste gratuito da Bright Data e, em seguida, adicione os seus dados para registar a sua conta na plataforma.
Quando tiver terminado, siga estes passos para criar o seu primeiro proxy:
Clique em Ver produto proxy na página de boas-vindas para ver os diferentes tipos de proxy oferecidos pela Bright Data:
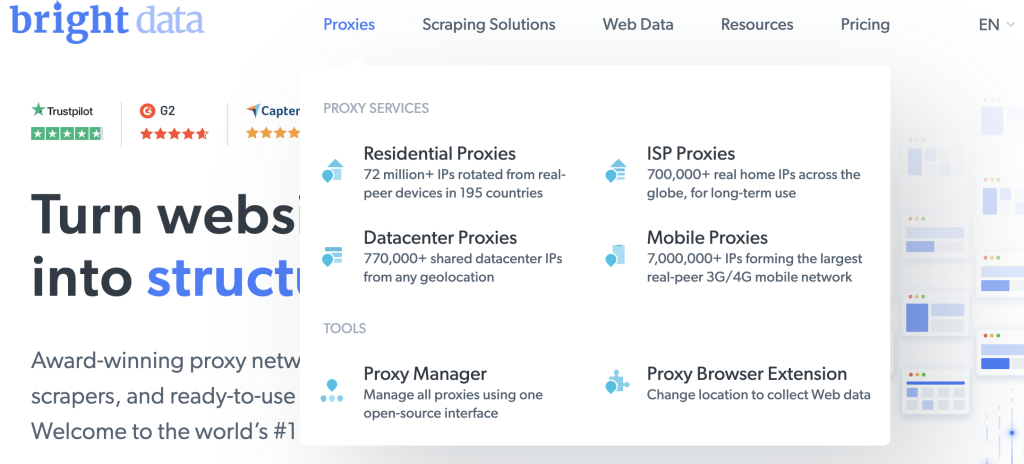
Selecione Proxies de Centro de Dados para criar um proxy e, na página seguinte, adicione os seus detalhes e guarde-o:

Uma vez criado o seu proxy, pode visualizar os parâmetros importantes (ou seja, host, porto, nome de usuário e palavra-passe) para começar a aceder e a utilizá-lo:
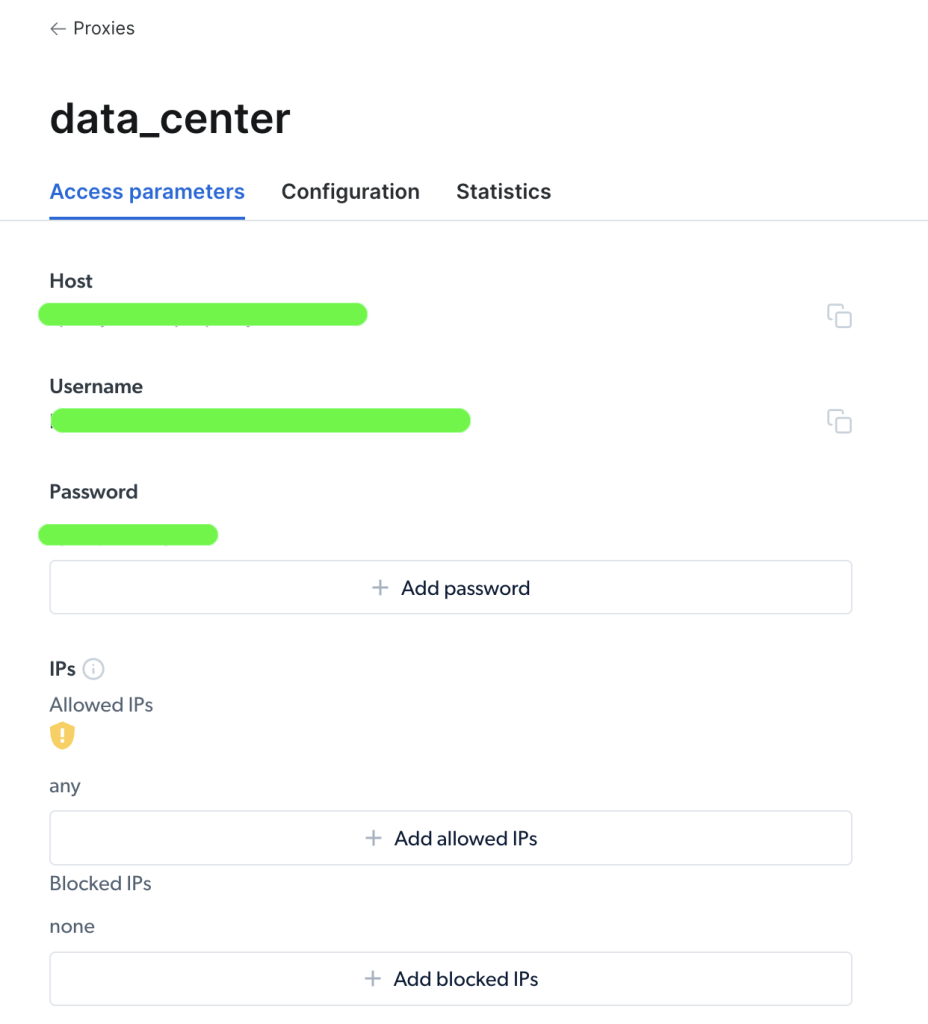
Depois de aceder ao seu proxy, pode utilizar as informações dos parâmetros para configurar o URL do proxy e enviar um pedido utilizando o pacote Requests de Python. O formato do URL do proxy é username-(session-id)-password@host:port.
Nota: O
session-idé um número aleatório criado através de um pacote de Python chamadorandom.
Segue-se o aspeto do exemplo de código para definir o seu proxy a partir de Bright Data num pedido de Python:
import requests
from bs4 import BeautifulSoup
import random
# Define parameters provided by Brightdata
host = 'zproxy.lum-superproxy.io'
port = 22225
username = 'username'
password = 'password'
session_id = random.random()
# format your proxy
proxy_url = ('http://{}-session-{}:{}@{}:{}'.format(username, session_id,
password, host, port))
# define your proxies in dictionary
proxies = {'http': proxy_url, 'https': proxy_url}
# Send a GET request to the website
url = "https://brightdata.com/"
response = requests.get(url, proxies=proxies)
# Use BeautifulSoup to parse the HTML content of the website
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website
links = soup.find_all("a")
# Print all the links
for link in links:
print(link.get("href"))
Aqui, você importa os pacotes e define o host do proxy, o porto, o nome de usuário, a palavra-passe e as variáveis session_id. Em seguida, você cria um dicionário de proxies com as chaves httpv e https e as credenciais de proxy. Finalmente, passa o parâmetro proxies à função requests.get() para efetuar o pedido HTTP e coletar as ligações do URL.
E pronto! Acabou de efetuar um pedido bem-sucedido utilizando o serviço de proxy da Bright Data.
Conclusão
Neste artigo, aprendeu porque é que precisa de proxies, bem como as diferentes formas de os utilizar para enviar um pedido a uma página web utilizando o pacote Requests de Python.
Com a plataforma web de Bright Data, pode obter proxies fiáveis para o seu projeto que cobram qualquer país ou cidade do mundo. Oferecem múltiplas formas de obter os dados de que necessita através de vários tipos de proxies e ferramentas de raspagem da web para satisfazer as suas necessidades específicas.
Se deseja reunir dados de pesquisa de mercado, monitorar avaliações em linha ou rastrear preços de concorrentes, a Bright Data possui os recursos necessários para realizar o trabalho de maneira rápida e eficiente.






