

A rotação de IP usando proxies é essencial em web scraping, especialmente ao lidar com sites modernos que podem impor restrições. Distribuir suas requisições por vários endereços IP é crucial para evitar bloqueios ou limites de taxa. Rotacionar os endereços IP torna mais desafiador para os sites rastrearem e restringirem sua atividade de scraping. Isso aprimora a eficiência e confiabilidade do seu processo de web scraping, permitindo extrair dados de forma mais eficaz. Usar proxies e rotacionar endereços IP durante o web scraping permite evitar proibições e penalidades baseadas em IP, superar limites de taxa e acessar conteúdo restrito por geolocalização.
Este artigo explica como implementar proxies em seu fluxo de trabalho de web scraping para rotacionar os endereços IP usados. Você explorará onde obter proxies eficazes, quais são as dicas para rotação de IP e ccomo evitar ser bloqueado pelo site de destino.
Rotação de IP com Python
Um processo de scraping regular com Python geralmente utiliza uma biblioteca Python como Requests ou Scrapy para acessar um site e analisar seu conteúdo. Você pode então filtrar o conteúdo do site para as informações que deseja extrair. Veja a seguir um exemplo de um processo típico de scraping:
import requests
url = 'http://example.com'
# Make requests
response = requests.get(url)
print(response.text)
Esse processo fornece as informações necessárias e é adequado para casos de uso único ou casos em que você só precisa extrair dados uma vez. No entanto, ele usa o IP do seu sistema para fazer requisições e pode enfrentar problemas com requisições repetidas ou contínuas, onde o site limita o acesso ao longo do tempo.
Os resultados do exemplo de processo de scraping são os seguintes:
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans",
…
A maioria das bibliotecas Python, como Requests ou Scrapy, destinadas a scraping ou fazer requisições web, tem uma forma de trocar o endereço IP usado nessas requisições. No entanto, para aproveitar isso, você precisa de uma lista ou fonte de endereços IP válidos. Essas fontes podem ser gratuitas ou comerciais, como os proxies da Bright Data.
Opções comerciais garantem validade e fornecem ferramentas úteis para gerenciar e rotacionar seus proxies, garantindo nenhum tempo de inatividade em seu processo de scraping. Por exemplo, a Bright Data possui várias categorias de proxies , dependendo do caso de uso, escalabilidade e garantia de acesso desbloqueado aos dados solicitados:
Usando proxies gratuitos, você pode criar uma lista em Python contendo proxies válidos que pode rotacionar ao longo do seu processo de scraping:
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
Com isso, tudo o que você precisa é de um mecanismo rotativo que selecione diferentes endereços IP da lista ao fazer várias requisições. Em Python, isso se pareceria com a seguinte função:
import random
import requests
def scraping_request(url):
ip = random.randrange(0, len(proxies))
ips = {"http": proxies[ip], "https": proxies[ip]}
response = requests.get(url, proxies=ips)
print(f"Proxy currently being used: {ips['https']}")
return response.text
Este código seleciona um proxy aleatório da sua lista cada vez que é chamado. O proxy é usado em requisições de scraping.
Incluir um caso de erro para lidar com proxies inválidos resultaria no código de scraping completo parecendo com isso:
import random
import requests
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
def scraping_request(url):
ip = random.choice(proxies)
try:
response = requests.get(url, proxies={"http": ip, "https": ip})
if response.status_code == 200:
print(f"Proxy currently being used: {ip}")
ip = random.randrange(0, len(proxies))
ips = {"http": proxies[ip], "https": proxies[ip]}
response = requests.get(url, proxies=ips)
try:
if response.status_code == 200:
print(f"Proxy currently being used: {ips['https']}")
print(response.text)
elif response.status_code == 403:
print("Forbidden client")
elif response.status_code == 429:
print("Too many requests")
except Exception as e:
print(f"An unexpected error occurred: {e}")
scraping_request("http://example.com")
Você também pode usar essa lista rotativa de proxies para realizar suas requisições com qualquer outro framework de scraping, como Scrapy.
Scraping com Scrapy
Com Scrapy, você precisa instalar a biblioteca e criar os artefatos do projeto necessários antes de poder rastrear com sucesso a web.
Você pode instalar o Scrapy usando o gerenciador de pacotes pip em seu ambiente habilitado para Python:
pip install Scrapy
Uma vez instalado, você pode gerar um projeto Scrapy com alguns arquivos de modelo em seu diretório atual usando os seguintes comandos:
scrapy startproject sampleproject
cd sampleproject
scrapy genspider samplebot example.com
Esses comandos também geram um arquivo de código básico que você pode preencher com um mecanismo de rotação de IP.
Abra o arquivo sampleproject/spiders/samplebot.pysamplebot.py e atualize-o com o seguinte código:
import scrapy
import random
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
ip = random.randrange(0, len(proxies))
class SampleSpider(scrapy.Spider):
name = "samplebot"
allowed_domains = ["example.com"]
start_urls = ["https://example.com"]
def start_requests(self):
for url in self.start_urls:
proxy = random.choice(proxies)
yield scrapy.Request(url, meta={"proxy": f"http://{proxy}"})
request = scrapy.Request(
"http://www.example.com/index.html",
meta={"proxy": f"http://{ip}"}
)
def parse(self, response):
# Log the proxy being used in the request
proxy_used = response.meta.get("proxy")
self.logger.info(f"Proxy used: {proxy_used}")
print(response.text)
Execute o seguinte comando no diretório principal do projeto para executar este script de scraping:
scrapy crawl samplebot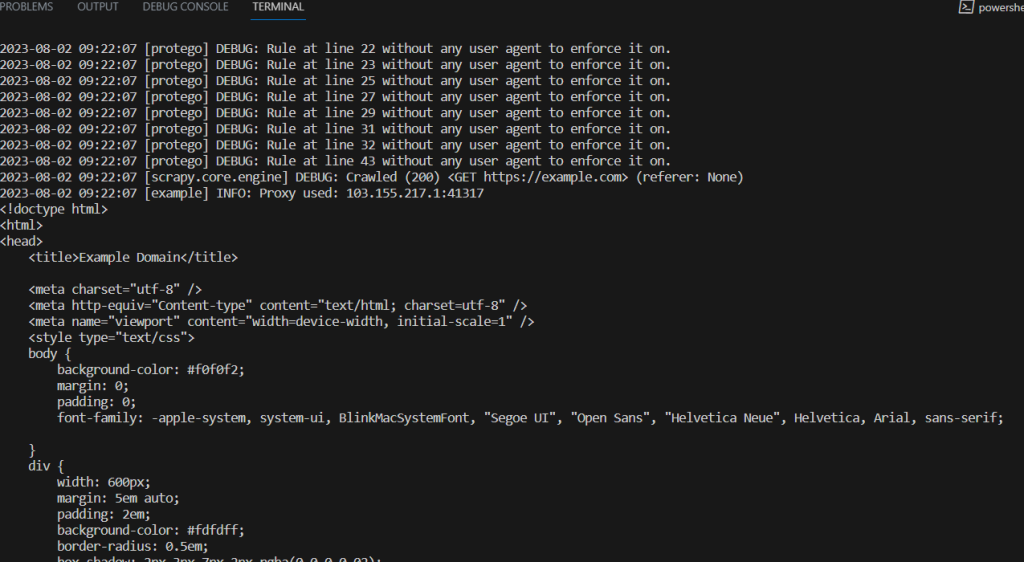
Dicas para Rotação de IP
O web scraping evoluiu para uma forma de competição entre sites e scrapers, com scrapers desenvolvendo novos métodos e técnicas para obter os dados necessários e sites encontrando novas maneiras de bloquear o acesso.
A rotação de IP é uma técnica que visa contornar as limitações impostas pelos sites. Para maximizar a eficácia da rotação de IP e minimizar as chances de ser bloqueado pelo site de destino, considere as seguintes dicas:
- Garanta um pool de proxies grande e diversificado: Ao usar rotação de IP, você precisa de um pool significativo de proxies com um grande número e uma ampla variedade de endereços IP. Essa diversidade ajuda a alcançar uma rotação adequada e reduz o risco de uso excessivo de proxies, o que poderia levar a limites de taxa e proibições. Considere o uso de vários provedores de proxies com faixas e locais de IP diferentes. Além disso, varie o tempo e os intervalos entre suas requisições com diferentes proxies para simular melhor o comportamento natural do usuário.
- Tenha mecanismos robustos de tratamento de erros: Durante o processo de web scraping, você pode encontrar vários erros devido a problemas temporários de conectividade, proxies bloqueados ou alterações no site de destino. Implementando tratamento de erros em seus scripts, você pode garantir a execução suave do seu processo de scraping, capturando e lidando com exceções comuns, como erros de conexão, tempos limite e erros de status HTTP. Considere configurar disjuntores de circuito para pausar temporariamente seu processo de scraping se ocorrer um grande número de erros em um curto período.
- Teste seus proxies antes do uso: Antes de implantar seu script de scraping em produção, use uma amostra do seu pool de proxies para testar a funcionalidade de rotação de IP e os mecanismos de tratamento de erros em diferentes cenários. Você pode usar sites de amostra para simular condições do mundo real e garantir que seu script possa lidar com esses casos.
- Monitore o desempenho e eficiência dos proxies: Monitore regularmente o desempenho de seus proxies para detectar quaisquer problemas, como tempos de resposta lentos ou falhas frequentes. Você deve acompanhar a taxa de sucesso de cada proxy para identificar os ineficientes. Provedores de proxies, como a Bright Data , oferecem ferramentas para verificar a saúde e o desempenho de seus proxies. Ao monitorar o desempenho dos proxies, você pode alternar rapidamente para proxies mais confiáveis e remover aqueles com baixo desempenho do seu pool de rotação.
O web scraping é um processo iterativo, e os sites podem alterar sua estrutura e padrões de resposta ou implementar novas medidas para evitar o scraping. Monitore regularmente seu processo de scraping e adapte-se a quaisquer mudanças para manter a eficácia de seus esforços de scraping.
Conclusão
Este artigo explorou a rotação de IP e como implementá-la em seu processo de scraping com Python. Você também aprendeu algumas dicas práticas para manter a eficácia do seu processo de scraping com Python.
A Bright Data é sua plataforma única para soluções de web scraping. Ela fornece proxies de alta qualidade e éticos, um Navegador de Web Scraping, um IDE para o desenvolvimento do seu bot de scraping e processos, conjuntos de dados prontos para uso e várias ferramentas para rotação e gerenciamento de proxies durante o scraping.





