

Aprenda a construir um raspador da web em Python que rasteje um sítio web inteiro e extraia todos os dados importantes através do raspador da web.
A Raspagem da Web consiste na extração de dados da web. Especificamente, um raspador da web é uma ferramenta que efetua raspagem de web e é geralmente representado por um script. Python é uma das mais fáceis e fiáveis linguagens de scripting disponíveis. Além disso, vem com uma grande variedade de bibliotecas para raspagem da web. Isto faz de Python a linguagem de programação perfeita para a raspagem da web. Em particular, a raspagem da web com Python leva apenas algumas linhas de código.
Neste tutorial, aprenderá tudo o que precisa de saber para construir um simples raspador com Python. Esta aplicação passará por todo um sítio web, extraindo dados de cada página. Depois, guardará todos os dados que raspámos com Python num ficheiro CSV. Este tutorial irá ajudá-lo a compreender quais são as melhores bibliotecas de Python para raspagem de dados, quais adotar, e como utilizá-las. Siga este tutorial passo-a-passo e aprenda a construir um script Python de raspagem da web.
Tabela de conteúdos:
- Pré-requisitos
- Melhores Bibliotecas de Python para Raspagem da Web
- Construir um Raspador da Web em Python
- Conclusão
- Perguntas Frequentes
Pré-requisitos
Para construir um raspador da web com Python, são necessários os seguintes pré-requisitos
Se não tiver o Python instalado no seu computador, pode seguir o primeiro enlace acima para o descarregar. Se for um usuário do Windows, certifique-se de marcar a caixa de verificação “Adicionar python.exe ao PATH” durante a instalação de Python, como abaixo indicado:
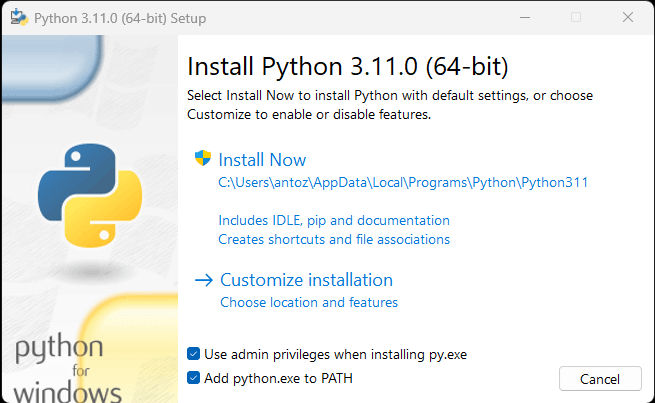
Desta forma, o Windows reconhecerá automaticamente os comandos python e pip no terminal. Em detalhe, pip é um gestor de pacotes para pacotes de Python. Note-se que o pip está incluído por defeito na versão Python 3.4 ou posterior. Portanto, não é necessário instalá-lo manualmente.
Está agora pronto para construir o seu primeiro raspador da web com Python. Mas primeiro, é preciso obter uma biblioteca de Python para raspagem da web!
Melhores Bibliotecas de Python para Raspagem da Web
Pode construir um script de raspagem a partir do zero com Python vanilla, mas esta não é a solução ideal. Afinal de contas, Python é bem conhecida pela sua vasta seleção de bibliotecas disponíveis. Em resumo, existem várias bibliotecas de raspagem da web à escolha. Vejamos agora as mais importantes!
Requests
A biblioteca Requests permite-lhe realizar pedidos HTTP em Python. Em particular, Requests facilita o envio de pedidos HTTP, especialmente em comparação com as bibliotecas HTTP padrão de Python. Requests desempenha um papel chave num projeto de raspagem da web com Python. Isto é porque para raspar os dados contidos numa página web, primeiro tem de os recuperar através de um pedido HTTP GET. Além disso, poderá ter de efetuar outros pedidos HTTP ao servidor do sítio web alvo.
Pode instalar Requests com o seguinte comando pip:
pip install requestsBeautiful Soup
A biblioteca Beautiful Soup de Python torna mais fácil raspar informação de páginas web. Em particular, Beautiful Soup funciona com qualquer analisador de HTML ou XML e fornece tudo o que é necessário para iterar, pesquisar e modificar a árvore de análise. Note que pode usar Beautiful Soup com html.parser, o analisador que vem com a biblioteca padrão de Python e permite analisar os ficheiros de texto HTML. Em detalhe, pode usar Beautiful Soup para atravessar o DOM e extrair os dados de que necessita.
Pode instalar Beautiful Soup com o pip da seguinte forma:
pip install beautifulsoup4Selenium
Selenium é uma estrutura de testes automatizada, avançada e de código aberto que lhe permite executar operações numa página web num navegador. Em outras palavras, pode usar Selenium para instruir um navegador a realizar certas tarefas. Note que também pode usar Selenium como biblioteca para raspagem da web por suas capacidades de navegador sem cabeça. Se não estiver familiarizado com este conceito, um navegador sem cabeça é um navegador web que funciona sem uma GUI (Interface Gráfica de Usuário). Se configurado em modo sem cabeça, Selenium executará o navegador atrás da cena.
Assim, as páginas web visitadas em Selenium são renderizadas num navegador real, que pode executar JavaScript. Como resultado, Selenium permite-lhe raspar sítios web que dependem de JavaScript. Tenha em mente que não pode conseguir isto com Requests ou nenhum outro cliente de HTTP. Isto é porque um navegador é necessário para executar JavaScript, enquanto Requests simplesmente permite executar pedidos HTTP.
Selenium equipa-o com tudo o que necessita para construir um raspador da web, sem a necessidade de outras bibliotecas. Pode instalá-lo com o seguinte comando pip:
pip install seleniumConstruir um Raspador da Web em Python
Vamos agora aprender como construir um raspador da web em Python. O objetivo deste tutorial é aprender a extrair todos os dados de citações contidos no sítio web Citações para Raspar. Para cada citação, aprenderá como raspar o texto, autor, e lista de etiquetas.
Mas primeiro, vamos dar uma vista de olhos ao sítio web alvo. É este o aspeto de uma página web de Citações para Raspar:

Como pode ver, Citações para Raspar nada mais é do que uma caixa de areia para raspar a web. Especificamente, contém uma lista paginada de citações. O raspador de Python que vai construir irá recuperar todas as citações contidas em cada página e as devolverá como dados CSV.
Agora, é tempo de compreender quais são as melhores bibliotecas de Python para raspagem da web para atingir o objetivo. Como pode observar no separador Rede da janela de Ferramentas de Desenvolvimento de Chrome abaixo, o sítio web alvo não executa nenhum pedido Fetch/XHR.

Noutros termos, Citações para Raspar não depende de JavaScript para recuperar dados apresentados em páginas web. Esta é uma situação comum para a maioria dos sítios web renderizados em servidores. Uma vez que o sítio web alvo não depende de JavaScript para renderizar a página ou recuperar dados, não é necessário Selenium para o raspar. Ainda pode utilizá-lo, mas não é necessário.
Como já sabe, Selenium abre páginas web num navegador. Uma vez que isto leva tempo e recursos, Selenium introduz uma sobrecarga de desempenho. Isto pode ser evitado utilizando Beautiful Soup juntamente com Requests. Vamos agora aprender como construir um simples script de raspagem da web com Python para recuperar dados de um sítio web com Beautiful Soup.
Começar
Antes de começar a escrever as primeiras linhas de código, é necessário criar o seu projeto Python de raspagem da web. Tecnicamente, só é necessário um único ficheiro .py. Contudo, a utilização de um IDE (Ambiente de Desenvolvimento Integrado) avançado tornará a sua experiência de codificação mais fácil. Aqui, vai aprender como montar um projeto Python em PyCharm 2022.2.3, mas qualquer outro IDE serve.
Primeiro, abra PyCharm e selecione “Ficheiro > Novo Projeto…”. Na janela emergente “Novo Projeto”, selecione “Pure Python” e inicialize o seu projeto.

Por exemplo, pode chamar ao seu projeto python-web-scraper. Clique em “Criar” e terá agora acesso ao seu projeto Python em branco. Por defeito, PyCharm inicializará um ficheiro main.py. Por uma questão de clareza, pode renomeá-lo para scraper.py. Este é o aspeto que o seu projeto terá agora:
Como pode ver, PyCharm inicializa automaticamente um ficheiro Python para você. Ignore o conteúdo deste ficheiro e apague cada linha de código. Desta forma, começará do zero.
Agora, é tempo de instalar as dependências do projeto. Pode instalar Requests e Beautiful Soup executando o seguinte comando no terminal:
pip install requests beautifulsoup4Este comando irá instalar ambas as bibliotecas de uma só vez. Aguarde que o processo de instalação esteja concluído. Está agora pronto a usar Beautiful Soup e Requests para construir o seu rastejador e raspador da web em Python. Certifique-se de importar as duas bibliotecas adicionando as seguintes linhas ao topo do seu ficheiro de script scraper.py:
import requests
from bs4 import BeautifulSoupPyCharm mostrará estas duas linhas em cinza porque as bibliotecas não são utilizadas no código. Se as sublinha em vermelho, significa que algo correu mal durante o processo de instalação. Neste caso, tente instalá-las novamente.
Este é o aspeto que o seu ficheiro scraper.py deve ter agora. Está agora pronto para começar a definir a lógica de raspagem da web.
Ligação ao URL de destino para raspar
A primeira coisa a fazer num raspador da web é ligar-se ao seu sítio web alvo. Primeiro, recupere o URL completo da página a partir do seu navegador web. Certifique-se de copiar também a seção do protocolo HTTP http:// ou https://. Neste caso, este é o URL completo do sítio web alvo:
https://quotes.toscrape.comAgora, pode utilizar requests para descarregar uma página web com a seguinte linha de código:
page = requests.get('https://quotes.toscrape.com')Esta linha atribui simplesmente o resultado do método request.get() à página variável. Nos bastidores, request.get() realiza um pedido GET usando o URL passado como parâmetro. Em seguida, devolve um objeto Response contendo a resposta do servidor ao pedido HTTP.
Se o pedido HTTP for executado com sucesso, page.status_code conterá 200. Isto porque o código de resposta de estado HTTP 200 OK indica que o pedido HTTP foi executado com sucesso. Um código de estado HTTP 4xx ou 5xx representará um erro. Isto pode acontecer por várias razões, mas tenha em mente que a maioria dos sítios web bloqueiam pedidos que não contêm um cabeçalho de Usuário-Agente válido. Especificamente, o cabeçalho de pedido de Usuário-Agente é uma sequência que caracteriza a aplicação e a versão do sistema operativo de onde provém um pedido. Saiba mais sobre Usuários-Agentes para raspagem da web.
Pode definir um cabeçalho de Usuário-Agente válido em Requests como se segue:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
page = requests.get('https://quotes.toscrape.com', headers=headers)Requests executará agora o pedido HTTP com os cabeçalhos passados como um parâmetro.
O que deve ter em atenção é a propriedade page.text. Esta conterá o documento HTML devolvido pelo servidor em formato de string. Alimente a propriedade do texto à Beautiful Soup para extrair dados da página web. Vamos aprender como.
Extração de dados com o raspador da web de Python
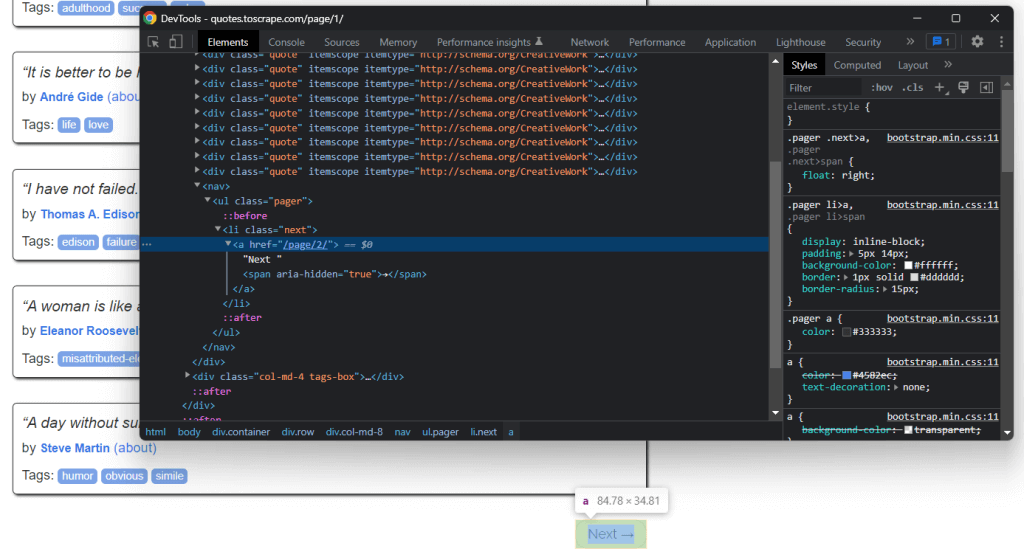
Para extrair dados de uma página web, primeiro tem de identificar os elementos HTML que contêm os dados em que está interessado. Especificamente, tem de encontrar os selecionadores de CSS necessários para extrair estes elementos do DOM. Pode consegui-lo utilizando as ferramentas de desenvolvimento oferecidas pelo seu navegador. Em Chrome, clique com o botão direito do rato no elemento HTML de interesse e selecione Inspecionar.
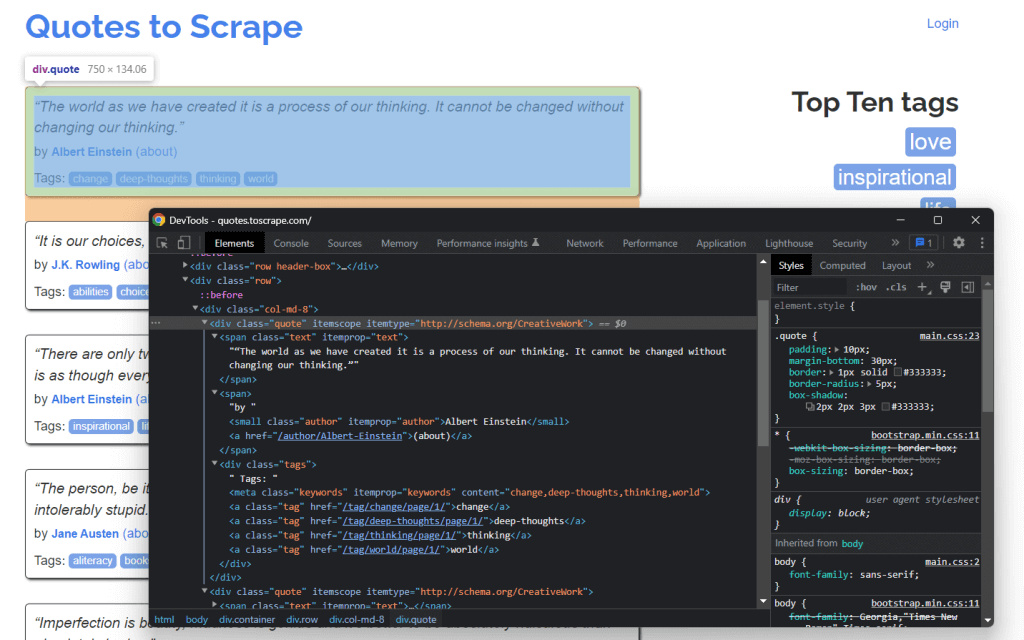
Como se pode ver aqui, o <div> elemento HTML da citação é identificado por classe de citação. Isto contém:
- O texto da citação num <span> elemento HTML
- O autor da citação num <small> elemento HTML
- Uma lista de etiquetas num <div> elemento, cada uma contida em <a> elemento HTML
Em detalhe, pode extrair estes dados utilizando os seguintes seletores CSS em .quote:
.text.author.tags .tag
Vamos agora aprender como conseguir isto com Beautiful Soup em Python. Primeiro, vamos passar o documento HTML page.text para o construtor de BeautifulSoup():
soup = BeautifulSoup(page.text, 'html.parser')O segundo parâmetro especifica o analisador que a Beautiful Soup utilizará para analisar o documento HTML. A variável soup contém agora um objeto BeautifulSoup. Esta é uma árvore de análise gerada a partir da análise do documento HTML contido em page.text com o html.parser de Python incorporado.
Agora, inicialize uma variável que conterá a lista de todos os dados raspados.
quotes = []É agora altura de utilizar soup para extrair elementos do DOM da seguinte forma:
quote_elements = soup.find_all('div', class_='quote')O método find_all() devolverá a lista de todos os elementos HTML <div> identificados pela classe de citação. Noutros termos, esta linha de código é equivalente a aplicar o seletor CSS .quote para recuperar a lista de elementos HTML da citação na página. Pode então iterar sobre a lista de citações para recuperar os dados das citações como se segue:
for quote_element in quote_elements:
# extracting the text of the quote
text = quote_element.find('span', class_='text').text
# extracting the author of the quote
author = quote_element.find('small', class_='author').text
# extracting the tag <a> HTML elements related to the quote
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
# storing the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)Graças ao método da Beautiful Soup find(), pode extrair o único elemento HTML de interesse. Uma vez que as etiquetas associadas à citação são mais do que uma, deve guardá-las numa lista.
Depois, pode transformar estes dados num dicionário e anexá-los à lista de citações como se segue:
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merging the tags into a "A, B, ..., Z" string
}
)O armazenamento dos dados extraídos em tal formato de dicionário tornará os seus dados mais fáceis de aceder e compreender.
Acabou de aprender como extrair todos os dados de citações a partir de uma única página. Mas tenha em mente que o sítio web alvo é constituído por várias páginas web. Vamos agora aprender a rastejar o sítio web inteiro.
Implementar a lógica de rastejamento
No fundo da página inicial, pode encontrar um <a> elemento HTML “Next →” que redireciona para a página seguinte do sítio web alvo. Este elemento HTML está contido em todas as páginas, exceto na última. Tal cenário é comum em qualquer sítio web paginado.
Ao seguir a ligação contida no <a> elemento HTML “Next →”, pode navegar facilmente em todo o sítio web. Assim, comecemos pela página inicial e vejamos como passar por cada página em que o sítio web alvo consiste. Só tem de procurar o <li> elemento HTML .next e extrair a ligação relativa à página seguinte.
Pode implementar a lógica de rastejamento da seguinte forma:
# the url of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# retrieving the page and initializing soup...
# getting the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# getting the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parsing the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping logic...
# looking for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')Isto é onde o ciclo faz iterações sobre cada página até não haver página seguinte. Especificamente, extrai o URL relativo da página seguinte e utiliza-o para criar o URL da página seguinte a raspar. Depois, descarrega a página seguinte. A seguir, a raspa e repete a lógica.
Acabou de aprender como implementar uma lógica de rastejamento para raspar um sítio web inteiro. Chegou o momento de ver como converter os dados extraídos num formato mais útil.
Conversão dos dados a formato CSV
Vamos ver como converter a lista de dicionários contendo os dados das citações raspadas num ficheiro CSV. Consiga isto com as seguintes linhas:
import csv
# scraping logic...
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()O que este trecho faz é escrever os dados das citações contidas na lista de dicionários num ficheiro quotes.csv. Note-se que o csv faz parte da Biblioteca Padrão de Python. Assim, pode importá-lo e utilizá-lo sem instalar uma dependência adicional. Em detalhe, basta criar um ficheiro com open(). Depois, pode preenchê-lo com a função writerow() desde o objeto Writer da biblioteca csv. Isto irá escrever cada dicionário de citações como uma linha formatada em CSV no ficheiro CSV.
Passou de dados em bruto contidos num sítio web para dados estruturados armazenados num ficheiro CSV. O processo de extração de dados terminou e pode agora dar uma vista de olhos a todo o raspador da web de Python.
Juntando tudo
Este é o aspeto de todo o script de raspagem da web de Python:
import requests
from bs4 import BeautifulSoup
import csv
def scrape_page(soup, quotes):
# retrieving all the quote <div> HTML element on the page
quote_elements = soup.find_all('div', class_='quote')
# iterating over the list of quote elements
# to extract the data of interest and store it
# in quotes
for quote_element in quote_elements:
# extracting the text of the quote
text = quote_element.find('span', class_='text').text
# extracting the author of the quote
author = quote_element.find('small', class_='author').text
# extracting the tag <a> HTML elements related to the quote
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
# storing the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)
# appending a dictionary containing the quote data
# in a new format in the quote list
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merging the tags into a "A, B, ..., Z" string
}
)
# the url of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# defining the User-Agent header to use in the GET request below
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
# retrieving the target web page
page = requests.get(base_url, headers=headers)
# parsing the target web page with Beautiful Soup
soup = BeautifulSoup(page.text, 'html.parser')
# initializing the variable that will contain
# the list of all quote data
quotes = []
# scraping the home page
scrape_page(soup, quotes)
# getting the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# getting the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parsing the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping the new page
scrape_page(soup, quotes)
# looking for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()Como aprendeu aqui, em menos de 100 linhas de código é possível construir um raspador da web. Este script de Python é capaz de rastejar um sítio web inteiro, extrair automaticamente todos os seus dados, e convertê-los num ficheiro CSV.
Parabéns! Acabou de aprender a construir um raspador da web de Python com as bibliotecas Requests e Beautiful Soup!
Executar o script de Python para raspagem da web
Se for um usuário de PyCharm, execute o script clicando no botão abaixo:

Caso contrário, execute o seguinte comando Python no terminal dentro do diretório do projeto:
python scraper.pyAguarde pelo fim do processo, e terá agora acesso a um ficheiro quotes.csv. Abra-o, e deve conter os seguintes dados:
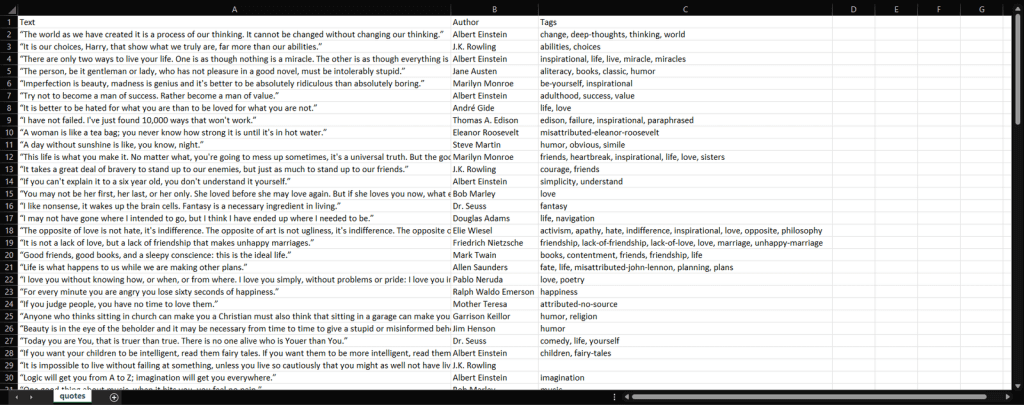
Et voilà! Tem agora todas as 100 citações contidas no sítio web alvo num único ficheiro CSV!
Conclusão
Neste tutorial, aprendeu o que é a raspagem da web, o que precisa para começar em Python, e quais são as melhores bibliotecas de Python para raspagem da web. Depois, viu como usar Beautiful Soup e Requests para construir uma aplicação de raspagem da web através de um exemplo do mundo real. Como aprendeu, a raspagem da web em Python leva apenas algumas linhas de código.
No entanto, a raspagem da web vem com vários desafios. Em particular, as tecnologias antibot e antirraspagem têm-se tornado cada vez mais populares. É por isso que precisa de uma ferramenta de raspagem automática avançada e completa, fornecida por Bright Data.
Para evitar ficar bloqueado, também recomendamos que escolha um proxy com base no seu caso de utilização a partir dos diferentes serviços de proxy que a Bright Data fornece.





