
Neste guia passo a passo, você aprenderá como fazer web scraping no YouTube usando Python
Este tutorial abordará:
- API do YouTube vs. extração de dados do YouTube
- Quais dados extrair do YouTube
- Extraindo dados do YouTube com Selenium
API do YouTube versus extração de dados do YouTube
A API de dados do YouTube é a forma oficial de obter dados da plataforma, incluindo informações sobre vídeos, playlists e criadores de conteúdo. No entanto, há pelo menos três bons motivos para a extração de dados do YouTube ser melhor do que confiar apenas em sua API:
- Flexibilidade e personalização: com um rastreador do YouTube, você pode ajustar o código para selecionar apenas os dados de que precisa. Esse nível de personalização ajuda você a coletar as informações exatas para seu caso de uso específico. Por outro lado, a API só dá acesso a dados predefinidos.
- Acesso a dados não oficiais: a API fornece acesso a conjuntos específicos de dados selecionados pelo YouTube. Isso significa que alguns dados nos quais você confia atualmente podem não estar mais disponíveis no futuro. O web scraping permite que você obtenha qualquer informação adicional disponível no site do YouTube, mesmo que não seja exposta por meio da API.
- Sem limitações: as APIs do YouTube estão sujeitas a limitações de taxa. Essa restrição determina a frequência e o volume de solicitações que você pode fazer em um determinado período de tempo. Ao interagir diretamente com a plataforma, você pode contornar qualquer limitação.
Quais dados extrair do YouTube
Principais campos de dados para extrair do YouTube
- Metadados do vídeo:
- Título
- Descrição
- Visualizações
- Curtidas
- Duração
- Data de publicação
- Canal
- Perfis do usuário:
- Nome do usuário
- Descrição do usuário
- Inscritos
- Número de vídeos
- Listas de reprodução
- Outros:
- Comentários
- Vídeos relacionados
Conforme visto anteriormente, a melhor maneira de obter esses dados é por meio de um scraper personalizado. Mas qual linguagem de programação escolher?
Python é uma das linguagens mais populares para web scraping, graças à sua sintaxe simples e rico ecossistema de bibliotecas. Sua versatilidade, legibilidade e amplo suporte da comunidade o tornam uma excelente opção. Confira nosso guia detalhado para começar a usar web scraping com Python.
Extraindo dados do YouTube com Selenium
Siga este tutorial e aprenda a criar um script em Python para extrair dados do YouTube.
Etapa 1: configure
Antes de programar, você precisa cumprir os seguintes pré-requisitos:
- Python 3+: baixe o instalador, clique duas vezes nele e siga as instruções.
- Um IDE para Python: PyCharm Community Edition ou Visual Studio Code com a extensão Python são duas ótimas opções gratuitas.
Você pode inicializar um projeto Python com um ambiente virtual usando os comandos abaixo:
mkdir youtube-scraper
cd youtube-scraper
python -m venv env
O diretório youtube-scraper criado acima representa a pasta do projeto para o seu script Python.
Abra-o no IDE, crie um arquivo scraper.py e inicialize-o da seguinte forma:
print('Hello, World!')
No momento, esse arquivo é um exemplo de script que imprime apenas “Hello, World!”, mas em breve conterá a lógica de extração de dados.
Verifique se o script funciona pressionando o botão Run (executar) do seu IDE ou com:
python scraper.py
No terminal, você deve ver:
Hello, World!
Perfeito, agora você tem um projeto Python para seu scraper do YouTube.
Etapa 2: escolha e instale as bibliotecas de extração de dados
Se você passar algum tempo visitando o YouTube, notará que é uma plataforma altamente interativa. Com base nas operações de clique e rolagem, o site carrega e renderiza dados dinamicamente. Isso significa que o YouTube depende muito de JavaScript.
Extrair dados do YouTube exige uma ferramenta que possa renderizar páginas web em um navegador, assim como o Selenium! Essa ferramenta possibilita extrair dados de sites dinâmicos com Python, permitindo que você execute tarefas automatizadas em sites em um navegador.
Adicione os pacotes Selenium e Webdriver Manager às dependências do seu projeto com:
pip install selenium webdriver-manager
A tarefa de instalação pode demorar um pouco, então seja paciente.
webdriver-manager não é estritamente necessário, mas facilita o gerenciamento de drivers web no Selenium. Graças a isso, você não precisa baixar, instalar e configurar manualmente os drivers web.
Comece usando o Selenium no scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# initialize a web driver instance to control a Chrome window
# in headless mode
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# scraping logic...
# close the browser and free up the resources
driver.quit()
Esse script cria uma instância do Chrome WebDriver, o objeto por meio do qual se controla programaticamente uma janela do Chrome.
Por padrão, o Selenium inicia o navegador com a interface do usuário. Embora isso seja útil para depuração, já que você pode experimentar ao vivo o que o script automatizado está fazendo na página, isso exige muitos recursos. Por esse motivo, você deve configurar o Chrome para ser executado no modo headless. Graças à opção --headless=new , a instância controlada do navegador será inicializada nos bastidores, sem interface de usuário.
Perfeito! É hora de definir a lógica de extração de dados!
Etapa 3: conecte-se ao YouTube
Para realizar a extração de dados do YouTube, você deve primeiro selecionar um vídeo do qual extrair dados. Neste guia, você verá como extrair dados do vídeo mais recente do canal da Bright Data no YouTube. Tenha em mente que qualquer outro vídeo serve.
Aqui está a página do YouTube escolhida como alvo:
https://www.youtube.com/watch?v=kuDuJWvho7Q
É um vídeo sobre web scraping intitulado “Introduction to Bright Data | Scraping Browser” (introdução à Bright Data).
Armazene a string do URL em uma variável do Python:
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
Agora você pode instruir o Selenium a se conectar à página-alvo com:
driver.get(url)
A função get() diz para o navegador controlado visitar a página identificada pelo URL passado como parâmetro.
É assim que o seu scraper de YouTube está ficando:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# initialize a web driver instance to control a Chrome window
# in headless mode
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# the URL of the target page
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
# visit the target page in the controlled browser
driver.get(url)
# close the browser and free up the resources
driver.quit()
Se você executar o script, ele abrirá a janela do navegador abaixo por uma fração de segundo antes de fechá-la devido à instrução quit() :
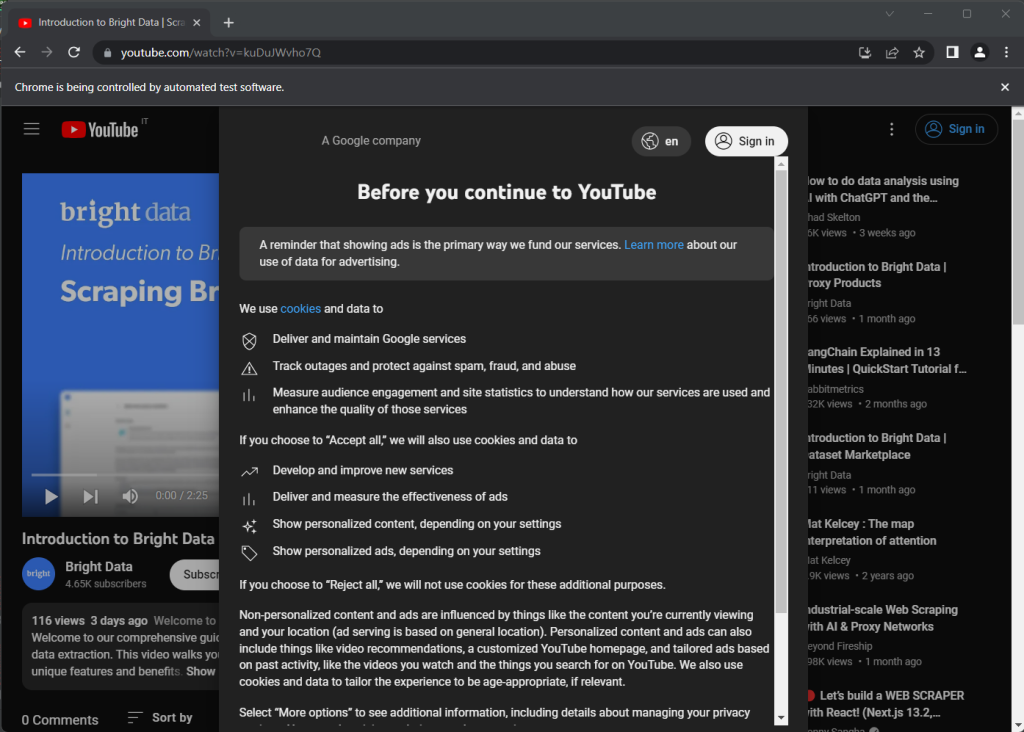
Observe a mensagem “O Chrome está sendo controlado por um software de teste automatizado”, o que garante que o Selenium está funcionando corretamente no Chrome.
Passo 4: inspecione a página-alvo
Dê uma olhada na captura de tela anterior. Quando você abre o YouTube pela primeira vez, aparece uma caixa de diálogo de consentimento. Para acessar os dados na página, você deve primeiro fechá-la clicando no botão “Accept all” (aceitar tudo). Vamos aprender como fazer isso!
Para criar uma nova sessão no navegador, abra o YouTube no modo de navegação anônima. Clique com o botão direito do mouse no modal de consentimento e selecione “Inspecionar”. Isso abrirá a seção Chrome DevTools:
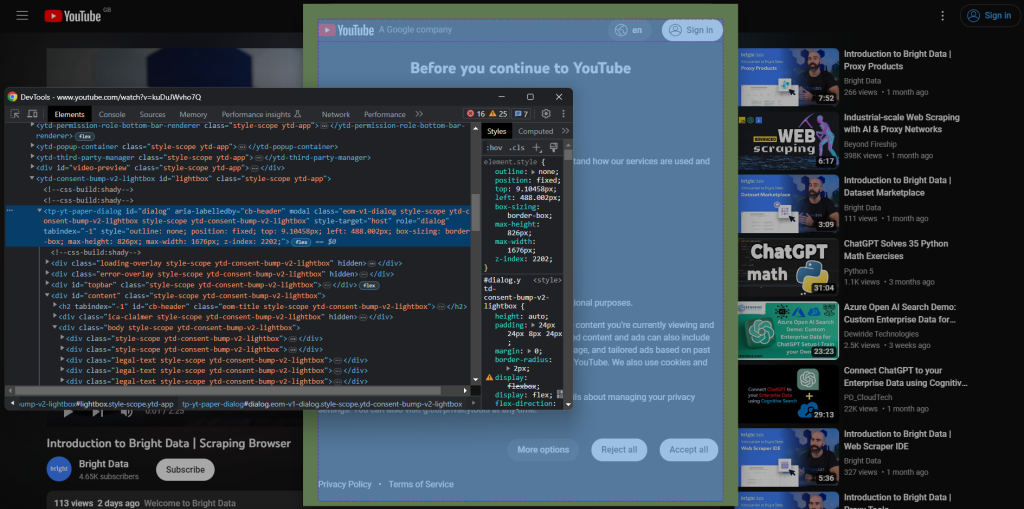
Observe que a caixa de diálogo tem um atributo id . Essa é uma informação útil para definir uma estratégia eficaz de seleção no Selenium.
Da mesma forma, inspecione o botão “Accept all”:
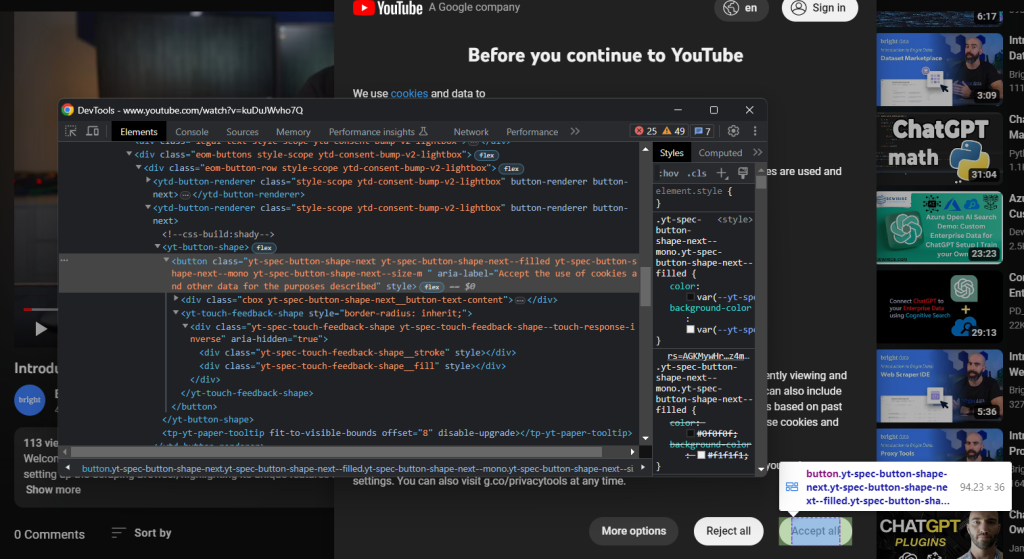
É o segundo botão identificado pelo seletor CSS abaixo:
.eom-buttons button.yt-spec-button-shape-next
Junte tudo e use estas linhas de código para lidar com a política de cookies do YouTube no Selenium:
try:
# wait up to 15 seconds for the consent dialog to show up
consent_overlay = WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.ID, 'dialog'))
)
# select the consent option buttons
consent_buttons = consent_overlay.find_elements(By.CSS_SELECTOR, '.eom-buttons button.yt-spec-button-shape-next')
if len(consent_buttons) > 1:
# retrieve and click the 'Accept all' button
accept_all_button = consent_buttons[1]
accept_all_button.click()
except TimeoutException:
print('Cookie modal missing')
O modal de consentimento é carregado dinamicamente e pode levar algum tempo para aparecer. Veja por que você precisa usar WebDriverWait para aguardar a condição esperada ocorrer. Se nada acontecer no tempo limite especificado, ele gerará uma TimeoutException. O YouTube é bem lento, então é recomendável usar tempos-limite superiores a 10 segundos.
Como o YouTube continua mudando suas políticas, a caixa de diálogo pode não aparecer em países ou situações específicas. Portanto, trate a exceção com try-catch para evitar que o script falhe caso o modal não esteja presente.
Para fazer o script funcionar, lembre-se de adicionar as seguintes importações:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
Depois de pressionar o botão “Accept all”, o YouTube demora um pouco para renderizar novamente a página de forma dinâmica:
Durante esse período, você não pode interagir com a página no Selenium. Se você tentar selecionar um elemento HTML, receberá o erro “stale element reference” (referência de elemento obsoleto). Isso acontece porque o DOM muda muito nesse processo.
Como você pode ver, o elemento do título contém uma linha cinza. Se você inspecionar esse elemento, você verá:
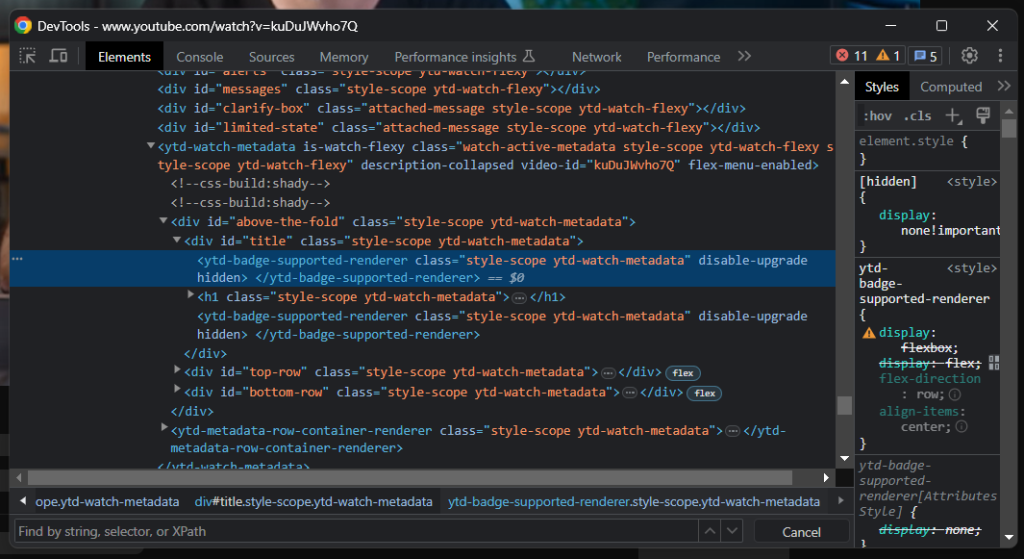
Um bom indicador de quando a página foi carregada é esperar até que o elemento do título esteja visível:
# wait for YouTube to load the page data
WebDriverWait(driver, 15).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, 'h1.ytd-watch-metadata'))
)
Você está pronto para extrair dados do YouTube com Python. Continue analisando o site-alvo no DevTools e familiarize-se com seu DOM.
Etapa 5: extraia dados do YouTube
Primeiro, você precisa de uma estrutura de dados onde armazenar as informações coletadas. Inicialize um dicionário em Python com:
video = {}
Como você deve ter notado na etapa anterior, algumas das informações mais interessantes estão na seção abaixo do player de vídeo:

Com o seletor CSS h1.ytd-watch-metadata , você pode obter o título do vídeo:
title = driver
.find_element(By.CSS_SELECTOR, 'h1.ytd-watch-metadata')
.text
Logo abaixo do título, há o elemento HTML contendo as informações do canal:
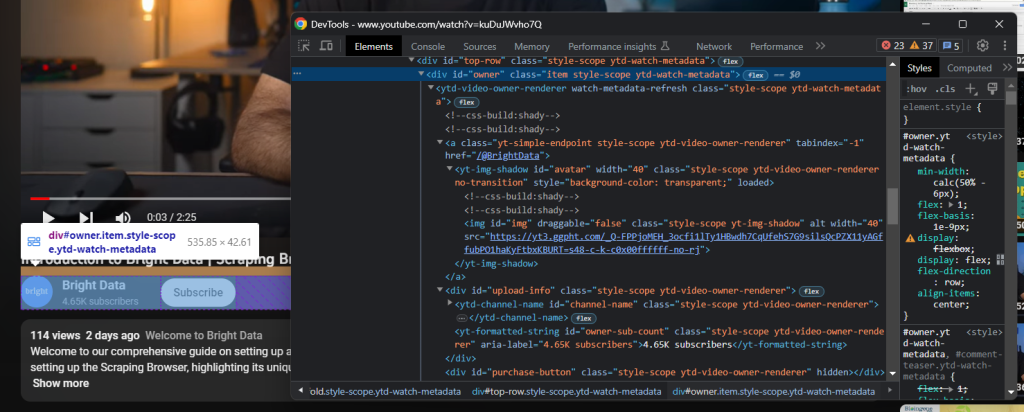
Isso é identificado pelo atributo id do “proprietário”, e você pode obter todos os dados dele com:
# dictionary where to store the channel info
channel = {}
# scrape the channel info attributes
channel_element = driver
.find_element(By.ID, 'owner')
channel_url = channel_element
.find_element(By.CSS_SELECTOR, 'a.yt-simple-endpoint')
.get_attribute('href')
channel_name = channel_element
.find_element(By.ID, 'channel-name')
.text
channel_image = channel_element
.find_element(By.ID, 'img')
.get_attribute('src')
channel_subs = channel_element
.find_element(By.ID, 'owner-sub-count')
.text
.replace(' subscribers', '')
channel['url'] = channel_url
channel['name'] = channel_name
channel['image'] = channel_image
channel['subs'] = channel_subs
Ainda mais abaixo, há a descrição do vídeo. Esse componente tem um comportamento complicado, pois mostra dados diferentes com base no fato de estar fechado ou aberto.

Clique nele para ter acesso e ver os dados completos:
driver.find_element(By.ID, 'description-inline-expander').click()
Você deve ter acesso ao elemento de informações com a descrição expandida:
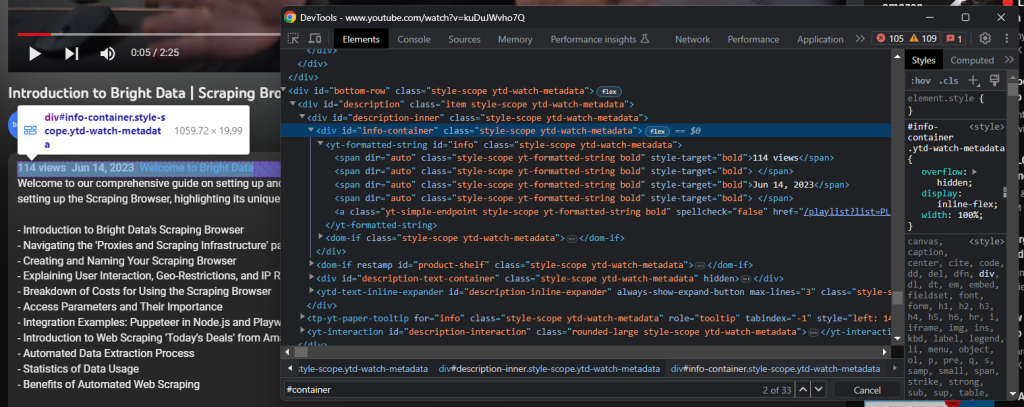
Recupere as visualizações do vídeo e a data de publicação com:
info_container_elements = driver
.find_elements(By.CSS_SELECTOR, '#info-container span')
views = info_container_elements[0]
.text
.replace(' views', '')
publication_date = info_container_elements[2]
.text
A descrição textual associada ao vídeo está contida no seguinte elemento filho:
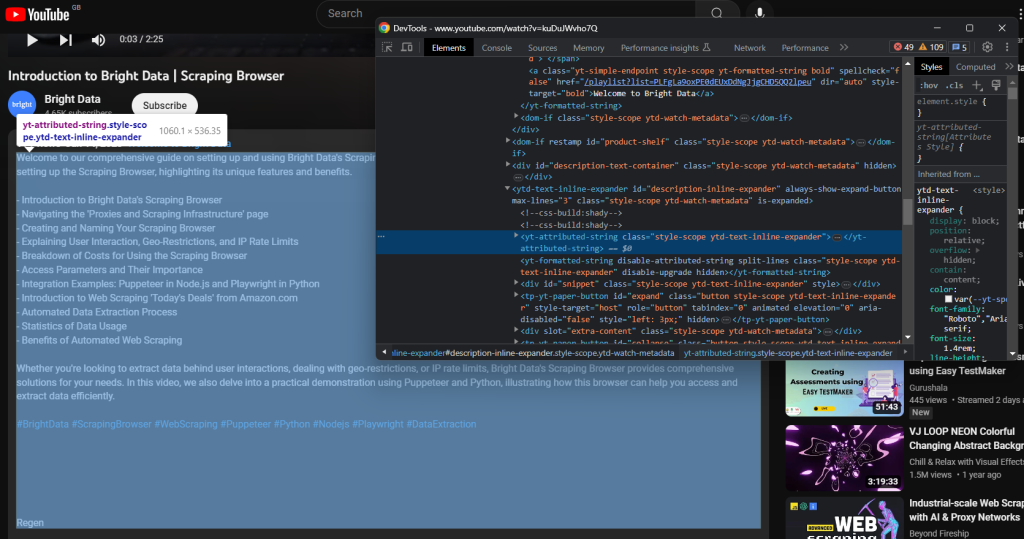
Extraia com:
description = driver
.find_element(By.CSS_SELECTOR, '#description-inline-expander .ytd-text-inline-expander span')
.text
Em seguida, inspecione o botão curtir:
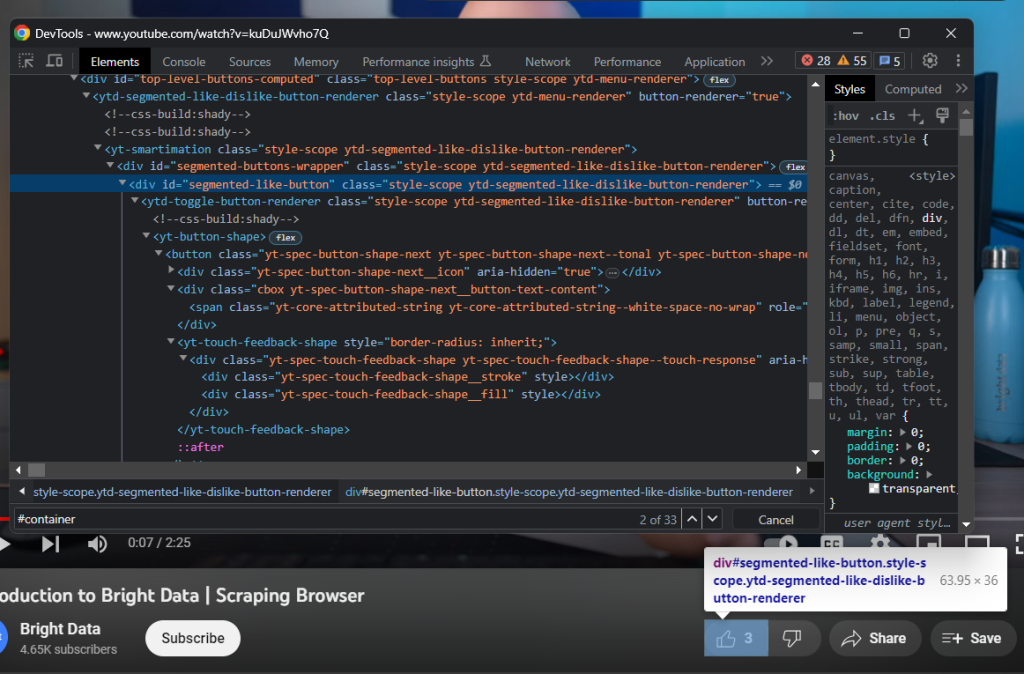
Colete o número de curtidas com:
likes = driver
.find_element(By.ID, 'segmented-like-button')
.text
Por fim, não se esqueça de inserir os dados extraídos no dicionário video :
video['url'] = url
video['title'] = title
video['channel'] = channel
video['views'] = views
video['publication_date'] = publication_date
video['description'] = description
video['likes'] = likes
Excelente! Você acabou de fazer o web scraping em Python!
Etapa 6: exporte os dados extraídos para JSON
Os dados de interesse agora estão armazenados em um dicionário em Python, que não é o melhor formato para compartilhá-los com outras equipes. Você pode converter as informações coletadas para JSON e exportá-las para um arquivo usando apenas duas linhas de código:
with open('video.json', 'w') as file:
json.dump(video, file)
Esse trecho inicializa um arquivo video.json com open(). Em seguida, ele usa json.dump() para escrever a representação JSON do dicionário video no arquivo de saída. Dê uma olhada em nosso artigo para saber mais sobre como analisar JSON em Python.
Você não precisa de uma dependência extra para atingir o objetivo. Tudo o que precisa é do pacote json Python Standard Library, que você pode importar com:
import json
Fantástico! Você começou com dados brutos contidos em uma página HTML dinâmica e agora tem dados JSON semiestruturados. É hora de ver o scraper completo do YouTube.
Etapa 7: junte tudo
Aqui está o script completo do scraper.py :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
import json
# enable the headless mode
options = Options()
# options.add_argument('--headless=new')
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# the URL of the target page
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
# visit the target page in the controlled browser
driver.get(url)
try:
# wait up to 15 seconds for the consent dialog to show up
consent_overlay = WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.ID, 'dialog'))
)
# select the consent option buttons
consent_buttons = consent_overlay.find_elements(By.CSS_SELECTOR, '.eom-buttons button.yt-spec-button-shape-next')
if len(consent_buttons) > 1:
# retrieve and click the 'Accept all' button
accept_all_button = consent_buttons[1]
accept_all_button.click()
except TimeoutException:
print('Cookie modal missing')
# wait for YouTube to load the page data
WebDriverWait(driver, 15).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, 'h1.ytd-watch-metadata'))
)
# initialize the dictionary that will contain
# the data scraped from the YouTube page
video = {}
# scraping logic
title = driver
.find_element(By.CSS_SELECTOR, 'h1.ytd-watch-metadata')
.text
# dictionary where to store the channel info
channel = {}
# scrape the channel info attributes
channel_element = driver
.find_element(By.ID, 'owner')
channel_url = channel_element
.find_element(By.CSS_SELECTOR, 'a.yt-simple-endpoint')
.get_attribute('href')
channel_name = channel_element
.find_element(By.ID, 'channel-name')
.text
channel_image = channel_element
.find_element(By.ID, 'img')
.get_attribute('src')
channel_subs = channel_element
.find_element(By.ID, 'owner-sub-count')
.text
.replace(' subscribers', '')
channel['url'] = channel_url
channel['name'] = channel_name
channel['image'] = channel_image
channel['subs'] = channel_subs
# click the description section to expand it
driver.find_element(By.ID, 'description-inline-expander').click()
info_container_elements = driver
.find_elements(By.CSS_SELECTOR, '#info-container span')
views = info_container_elements[0]
.text
.replace(' views', '')
publication_date = info_container_elements[2]
.text
description = driver
.find_element(By.CSS_SELECTOR, '#description-inline-expander .ytd-text-inline-expander span')
.text
likes = driver
.find_element(By.ID, 'segmented-like-button')
.text
video['url'] = url
video['title'] = title
video['channel'] = channel
video['views'] = views
video['publication_date'] = publication_date
video['description'] = description
video['likes'] = likes
# close the browser and free up the resources
driver.quit()
# export the scraped data to a JSON file
with open('video.json', 'w') as file:
json.dump(video, file, indent=4)
Você pode criar um web scraper para obter dados de vídeos do YouTube com apenas 100 linhas de código, aproximadamente!
Inicie o script e o seguinte arquivo video.json aparecerá na pasta raiz do seu projeto:
{
"url": "https://www.youtube.com/watch?v=kuDuJWvho7Q",
"title": "Introduction to Bright Data | Scraping Browser",
"channel": {
"url": "https://www.youtube.com/@BrightData",
"name": "Bright Data",
"image": "https://yt3.ggpht.com/_Q-FPPjoMEH_3ocfi1lTy1HBwdh7CqUfehS7G9silsQcPZX11yAGffubPO1haKyFtbxKBURT=s48-c-k-c0x00ffffff-no-rj",
"subs": "4.65K"
},
"views": "116",
"publication_date": "Jun 14, 2023",
"description": "Welcome to our comprehensive guide on setting up and using Bright Data's Scraping Browser for efficient web data extraction. This video walks you through the process of setting up the Scraping Browser, highlighting its unique features and benefits.nn- Introduction to Bright Data's Scraping Browsern- Navigating the 'Proxies and Scraping Infrastructure' pagen- Creating and Naming Your Scraping Browsern- Explaining User Interaction, Geo-Restrictions, and IP Rate Limitsn- Breakdown of Costs for Using the Scraping Browsern- Access Parameters and Their Importancen- Integration Examples: Puppeteer in Node.js and Playwright in Pythonn- Introduction to Web Scraping 'Today's Deals' from Amazon.comn- Automated Data Extraction Processn- Statistics of Data Usagen- Benefits of Automated Web ScrapingnnWhether you're looking to extract data behind user interactions, dealing with geo-restrictions, or IP rate limits, Bright Data's Scraping Browser provides comprehensive solutions for your needs. In this video, we also delve into a practical demonstration using Puppeteer and Python, illustrating how this browser can help you access and extract data efficiently.nn#BrightData #ScrapingBrowser #WebScraping #Puppeteer #Python #Nodejs #Playwright #DataExtraction",
"likes": "3"
}
Parabéns! Você acabou de aprender a extrair dados do YouTube em Python!
Conclusão
Neste guia, você aprendeu por que extrair dados do YouTube é melhor do que usar suas APIs de dados. Em particular, você viu um tutorial passo a passo sobre como criar um scraper em Python capaz de recuperar dados de um vídeo do YouTube. Conforme comprovado aqui, não é complexo e exige apenas algumas linhas de código.
Ao mesmo tempo, o YouTube é uma plataforma dinâmica que continua evoluindo, então o scraper criado aqui pode não funcionar para sempre. Fazer sua manutenção para lidar com as mudanças no site-alvo é demorado e complicado. É por isso que criamos o YouTube Scraper, uma solução confiável e fácil de usar para obter todos os dados que você deseja sem se preocupar!
Além disso, não ignore os sistemas antibot do Google. O Selenium é uma ótima ferramenta, mas não pode fazer nada contra essas tecnologias avançadas. Se o Google decidir proteger o YouTube contra bots, a maioria dos scripts automatizados será cortada. Se isso acontecer, você precisará de uma ferramenta que possa renderizar JavaScript e seja capaz de lidar automaticamente com impressões digitais, CAPTCHAs e antiscraping para você. Bem, ela existe e se chama Scraping Browser!
Não quer lidar de forma alguma com a extração de dados do YouTube, mas tem interesse em dados de itens? Solicite um dataset do YouTube.





