

Neste artigo, você aprenderá:
- O que é a ferramenta Anthropic web fetch e suas principais limitações.
- Como ela funciona.
- Como usá-la em cURL e Python.
- O que a Bright Data oferece para atingir objetivos semelhantes.
- Como a ferramenta Anthropic Web fetch e as ferramentas de dados da Web da Bright Data se comparam.
- Uma tabela de resumo para uma comparação rápida.
Vamos nos aprofundar!
O que é a ferramenta Anthropic Web Fetch?
A ferramenta Anthropic Web Fetch permite que os modelos Claude recuperem conteúdo de páginas da Web e documentos PDF. Essa ferramenta foi introduzida gratuitamente na versão beta do Claude em 2026-09-10.
Ao incluir essa ferramenta em uma solicitação da API do Claude, o LLM configurado pode buscar e analisar o texto completo de URLs de páginas da Web ou PDFs especificados. Isso dá ao Claude acesso a informações atualizadas e baseadas na fonte para respostas fundamentadas.
Observações e limitações
Estas são as principais observações e limitações associadas à ferramenta Anthropic web fetch:
- Disponível na API do Claude sem custo adicional. Você só paga as taxas de token padrão pelo conteúdo obtido que está incluído no contexto da conversa.
- Recupera o conteúdo completo de páginas da Web e documentos PDF especificados.
- Atualmente está na versão beta e requer o cabeçalho beta
web-fetch-2026-09-10. - O Claude não pode construir URLs dinamicamente. Você deve fornecer explicitamente URLs completos, ou ele só pode usar URLs obtidos de pesquisas anteriores na Web ou buscar resultados.
- Só pode buscar URLs que já tenham aparecido no contexto da conversa. Isso inclui URLs de mensagens de usuários, resultados de ferramentas do lado do cliente ou resultados anteriores de pesquisa e busca na Web.
- Funciona somente com os seguintes modelos: Claude Opus 4.1
(claude-opus-4-1-20260805), Claude Opus 4(claude-opus-4-20260514), Claude Sonnet 4.5(claude-sonnet-4-5-20260929), Claude Sonnet 4(claude-sonnet-4-20260514), Claude Sonnet 3.7(claude-3-7-sonnet-20260219), Claude Sonnet 3.5 v2 (depreciado)(claude-3-5-sonnet-latest) e Claude Haiku 3.5(claude-3-5-haiku-latest). - Não oferece suporte a sites JavaScript renderizados dinamicamente.
- Pode incluir citações opcionais para o conteúdo obtido.
- Funciona com cache de prompt, de modo que os resultados em cache podem ser reutilizados em turnos de conversa.
- Oferece suporte aos parâmetros
max_uses,allowed_domains,blocked_domainsemax_content_tokens. - Os códigos de erro comuns incluem:
invalid_input,url_too_long,url_not_allowed,url_not_accessible,too_many_requests,unsupported_content_type,max_uses_exceededeunavailable.
Como funciona o Web Fetch em Claude Models
Isso é o que acontece nos bastidores quando você adiciona a ferramenta Anthropic Web Fetch à sua solicitação de API:
- O Claude determina quando buscar o conteúdo com base no prompt e nos URLs fornecidos.
- A API recupera o conteúdo de texto completo do URL especificado.
- Para PDFs, a extração automática de texto é realizada.
- O Claude analisa o conteúdo obtido e gera uma resposta, opcionalmente incluindo citações.
A resposta resultante é então devolvida ao usuário ou adicionada ao contexto da conversa para análise posterior.
Como usar a ferramenta Anthropic Web Fetch
As duas principais maneiras de usar a ferramenta de busca na Web são ativando-a em uma solicitação para um dos modelos Claude compatíveis. Isso pode ser feito de uma das seguintes maneiras:
- Por meio de uma chamada direta da API para a API do Anthropic.
- Por meio de um dos SDKs do cliente Claude, como a biblioteca da API do Anthropic Python.
Veja como nas seções a seguir!
Em ambos os casos, demonstraremos como usar a ferramenta de busca na Web para fazer o Scraping de dados da página inicial do Anthropic, mostrada abaixo:

Pré-requisitos
O principal requisito para usar a ferramenta Anthropic web fetch é ter acesso a uma chave da API do Anthropic. Aqui, assumiremos que você tem uma conta Anthropic com uma chave de API instalada.
Por meio de uma chamada direta à API
Utilize a ferramenta de busca na Web fazendo uma chamada de API direta para a API do Anthropic com um dos modelos suportados, conforme mostrado abaixo em uma solicitação cURL POST:
curl https://api.anthropic.com/v1/messages
--header "x-api-key: <YOUR_ANTHROPIC_API_KEY>"
--header "anthropic-version: 2023-06-01"
--header "anthropic-beta: web-fetch-2026-09-10"
--header "content-type: application/json"
--data '{
"model": "claude-sonnet-4-5-20260929",
"max_tokens": 1024,
"messages": [
{
"role": "user" (usuário),
"content" (conteúdo): "Extrair o conteúdo de 'https://www.anthropic.com/'"
}
],
"tools" (ferramentas): [{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
}]
}'Observe que claude-sonnet-4-5-20260929 é um dos modelos compatíveis com a ferramenta web fetch.
Além disso, observe que os dois cabeçalhos especiais, anthropic-version e anthropic-beta, são necessários.
Para ativar a ferramenta de busca na Web no modelo configurado, você deve adicionar o seguinte item à matriz de ferramentas no corpo da solicitação:
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
}Os campos type e name são importantes, enquanto max_uses é opcional e define quantas vezes a ferramenta pode ser chamada em uma única iteração.
Substitua o espaço reservado <YOUR_ANTHROPIC_API_KEY> por sua chave real da API do Anthropic. Em seguida, execute a solicitação e você deverá obter algo parecido com isto:
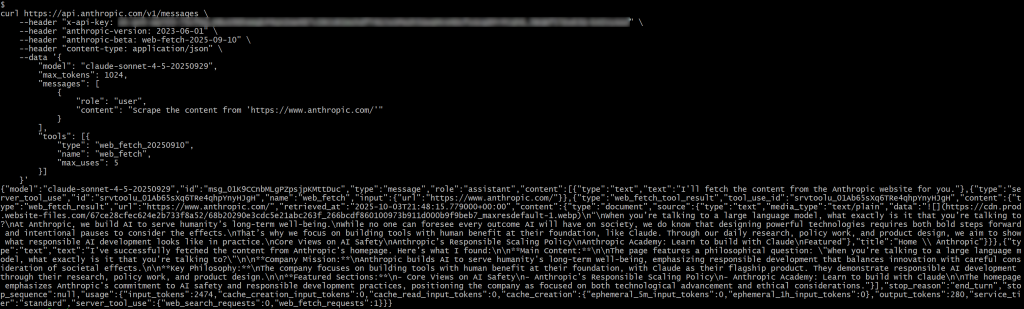
Na resposta, você deverá ver:
{"type": "server_tool_use", "id": "srvtoolu_01Ab65sXq6TRe4qhpYnyHJgH", "name": "web_fetch", "input":{"url": "https://www.anthropic.com/"}}Isso especifica que o LLM executou uma chamada para a ferramenta web_fetch.
Especificamente, o resultado produzido pela ferramenta seria algo como:

"Quando você está falando com um modelo de linguagem grande, com o que exatamente você está falando?
Na Anthropic, criamos IA para atender ao bem-estar da humanidade em longo prazo.
Embora ninguém possa prever todos os resultados que a IA terá na sociedade, sabemos que projetar tecnologias poderosas requer passos ousados e pausas intencionais para considerar os efeitos.
É por isso que nos concentramos na criação de ferramentas que tenham o benefício humano em sua base, como o Claude. Por meio de nossa pesquisa diária, trabalho com políticas e design de produtos, nosso objetivo é mostrar como é o desenvolvimento responsável da IA na prática.
Principais pontos de vista sobre a segurança da IA
Política de escalonamento responsável da Anthropic
Anthropic Academy: Aprenda a construir com Claude
Em destaque
Isso representa uma espécie de versão semelhante ao Markdown da página inicial do URL de entrada especificado. É uma “espécie de” Markdown, pois alguns links são omitidos e, além da primeira imagem, o resultado se concentra principalmente no texto, que é exatamente o que a ferramenta de busca na Web foi projetada para retornar.
Observação: de modo geral, o resultado é preciso, mas sem dúvida deixa passar algum conteúdo, que pode ter sido perdido durante o processamento pela ferramenta. De fato, a página original contém mais texto do que o que foi recuperado.
Usando a biblioteca da API do Anthropic Python
Como alternativa, você pode chamar a ferramenta de busca na Web usando a biblioteca da API do Anthropic Python com:
# pip install anthropic
importar anthropic
# Substitua-o por sua chave da API do Anthropic
ANTHROPIC_API_KEY = "<SUA_CHAVE_DE_API_ANTRÓPICA>"
# Inicializar o cliente da API Anthropic
cliente = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
# Realizar uma solicitação ao Claude com a ferramenta de busca na Web ativada
response = client.messages.create(
model="claude-sonnet-4-5-20260929",
max_tokens=1024,
messages=[
{
"role": "user" (usuário),
"content": "Extrair o conteúdo de 'https://www.anthropic.com/'"
}
],
tools=[
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
},
],
extra_headers={
"anthropic-beta": "web-fetch-2026-09-10"
}
)
# Imprimir o resultado produzido pela IA no terminal
print(response.content)
Desta vez, o resultado será:
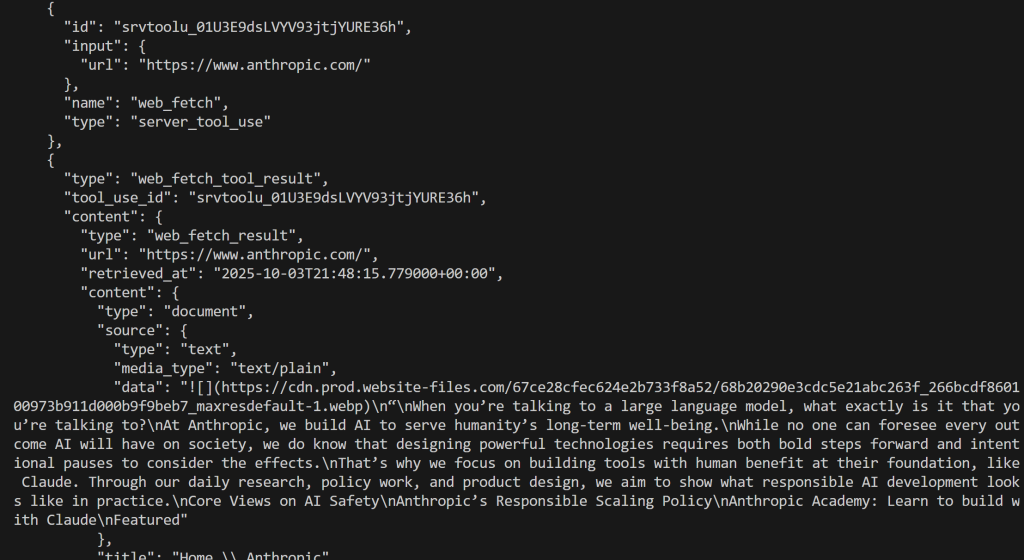
Great! Isso é equivalente ao que vimos anteriormente.
Introdução às ferramentas de dados da Web da Bright Data
A infraestrutura de IA da Bright Data oferece um rico conjunto de soluções para permitir que sua IA pesquise, rastreie e navegue livremente na Web. Isso inclui:
- API Unlocker: Obtenha conteúdo de forma confiável de qualquer URL público, contornando automaticamente bloqueios e resolução de CAPTCHAs.
- API Crawl: Rastreie e extraia sites inteiros sem esforço, com resultados em formatos prontos para LLM para inferência e raciocínio eficazes.
- API SERP: Reúna resultados de mecanismos de pesquisa em tempo real e específicos da região geográfica para descobrir fontes de dados relevantes para uma consulta específica.
- API do navegador: Permita que sua IA interaja com sites dinâmicos e automatize fluxos de trabalho agênticos em escala usando navegadores furtivos remotos.
Entre as várias ferramentas, serviços e produtos para recuperação de dados da Web na infraestrutura da Bright Data, vamos nos concentrar no Web MCP. Ele fornece ferramentas prontas para integração de IA criadas com base nos produtos da Bright Data que são diretamente comparáveis às oferecidas pelo Anthropic. Observe que o Web MCP também funciona como Claude MCP, integrando-se totalmente a qualquer modelo Anthropic.
De todas as mais de 60 ferramentas disponíveis, a ferramenta scrape_as_markdown é a combinação perfeita para comparação. Ela permite que você extraia o URL de uma única página da Web com opções avançadas para extração de conteúdo e retorna os resultados no formato Markdown. Essa ferramenta pode acessar qualquer página da Web, mesmo aquelas que usam detecção de bots ou CAPTCHA.
É importante ressaltar que essa ferramenta está disponível no Web MCP mesmo na camada gratuita, o que significa que você pode usá-la sem nenhum custo. Portanto, ela alcança uma funcionalidade de recuperação de dados da Web semelhante à ferramenta de busca da Web do Anthropic, tornando o Web MCP ideal para uma comparação direta.
Ferramenta Anthropic Web Fetch vs Bright Data Web Data Tools
Nesta seção, criaremos um processo para comparar a ferramenta de busca na Web do Anthropic com as ferramentas de dados da Web da Bright Data. Em detalhes, vamos:
- Usar a ferramenta de busca na Web por meio da biblioteca Python API do Anthropic.
- Conectar ao Web MCP da Bright Data usando adaptadores LangChain MCP (mas qualquer outra integração compatível é aceitável).
Executaremos as duas abordagens usando o mesmo prompt e o modelo Claude nos quatro URLs de entrada a seguir:
"https://www.anthropic.com/""https://www.g2.com/products/bright-data/reviews""https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/""https://it.linkedin.com/in/antonello-zanini"
Esses URLs representam uma boa combinação de páginas do mundo real das quais você pode querer que uma IA busque conteúdo automaticamente: a página inicial de um site, uma página de produto do G2, uma página de produto da Amazon e um perfil público do LinkedIn. Observe que a G2 é notoriamente desafiadora para raspagem devido à proteção da Cloudflare, razão pela qual foi intencionalmente incluída na comparação.
Vamos ver o desempenho das duas ferramentas!
Pré-requisitos
Antes de seguir esta seção, você deve ter:
- Python instalado localmente.
- Uma chave de API do Anthropic.
- Uma conta da Bright Data com uma chave de API.
Para configurar uma conta da Bright Data e gerar sua chave de API, siga o guia oficial. Também é recomendável revisar a documentação oficial do Web MCP.
Além disso, será útil saber como funciona a integração do LangChain e estar familiarizado com as ferramentas fornecidas pelo Web MCP.
Script de integração da ferramenta Web Fetch
Para executar a ferramenta Anthropic Web Fetch por meio dos URLs de entrada selecionados, você pode escrever uma lógica Python como esta:
# pip install anthropic
importar anthropic
Substitua-o por sua chave da API do Anthropic
ANTHROPIC_API_KEY = ""
Inicialize o cliente da API Anthropic
cliente = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
def scrape_content_with_anthropic_web_fetch_tool(url):
return client.messages.create( model="claude-sonnet-4-5-20260929",
max_tokens=1024,
messages=[
{
"role": "user" (usuário),
"content": f "Extrair o conteúdo de '{url}'"
}
],
tools=[
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
},
],
extra_headers={
"anthropic-beta": "web-fetch-2026-09-10"
}
)
Em seguida, você pode chamar essa função em um URL de entrada como este:
scrape_content_with_anthropic_web_fetch_tool("https://www.anthropic.com/")
Script de integração de ferramentas de dados da Web da Bright Data
O Web MCP pode ser integrado a uma ampla gama de tecnologias, conforme descrito em nosso blog. Aqui, demonstraremos a integração com o LangChain, pois é uma das opções mais fáceis e mais populares.
Antes de começar, recomendamos que você dê uma olhada no guia: “Adaptadores LangChain MCP com o Web MCP da Bright Data“.
Nesse caso, você deve terminar com um trecho de Python como este:
# pip install "langchain[anthropic]" langchain-mcp-adapters langgraph
importar asyncio
from langchain_anthropic import ChatAnthropic
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
importar json
# Substitua por suas chaves de API
ANTHROPIC_API_KEY = "<SUA_CHAVE_DE_API_ANTRÓPICA>"
BRIGHT_DATA_API_KEY = "<SUA_CHAVE_DE_API_DE_DADOS_BRILHANTES>"
async def scrape_content_with_bright_data_web_mcp_tools(agent, url):
# Descrição da tarefa do agente
input_prompt = f "Extrair o conteúdo de '{url}'"
# Executar a solicitação no agente, transmitir a resposta e retorná-la como uma cadeia de caracteres
output = []
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
content = step["messages"][-1].content
if isinstance(content, list):
output.append(json.dumps(content))
else:
output.append(content)
return "".join(output)
async def main():
# Inicializar o mecanismo LLM
llm = ChatAnthropic(
model="claude-sonnet-4-5-20260929",
api_key=ANTHROPIC_API_KEY
)
# Configuração para se conectar a uma instância local do servidor Bright Data Web MCP
server_params = StdioServerParameters(
comando="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "false" # Opcionalmente definido como "true" para o modo Pro
}
)
# Conectar-se ao servidor MCP
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Inicializar a sessão do cliente MCP
await session.initialize()
# Obter as ferramentas do Web MCP
tools = await load_mcp_tools(session)
# Criar o agente ReAct com a integração do Web MCP
agent = create_react_agent(llm, tools)
# scrape_content_with_bright_data_web_mcp_tools(agent, "https://www.anthropic.com/")
se __name__ == "__main__":
asyncio.run(main())
Isso define um agente ReAct que tem acesso às ferramentas do Web MCP.
Lembre-se: O Web MCP oferece um modo Pro, que fornece acesso a ferramentas premium. O uso do modo Pro não é estritamente necessário neste caso. Portanto, você pode contar apenas com as ferramentas disponíveis na camada gratuita. As ferramentas gratuitas incluem scrape_as_markdown, que é suficiente para esse benchmark.
Em termos mais simples, do ponto de vista do custo, usar o Web MCP no modo gratuito não custará mais do que o uso do token para o modelo Claude em si (que é o mesmo em ambos os cenários). Essencialmente, a estrutura de custos para essa configuração é a mesma de quando se conecta diretamente ao Claude por meio da API.
Resultados do benchmark
Agora, execute as duas funções que representam os dois métodos de recuperação de dados da Web de IA usando uma lógica como esta:
# Onde armazenar os resultados do benchmark
benchmark_results = []
# Os URLs de entrada para testar as duas abordagens
urls = [
"https://www.anthropic.com/",
"https://www.g2.com/products/bright-data/reviews",
"https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/",
"https://it.linkedin.com/in/antonello-zanini"
]
# Testar cada URL
para url em urls:
print(f "Testando as duas abordagens no seguinte URL: {url}")
anthropic_start_time = time.time()
anthropic_response = scrape_content_with_anthropic_web_fetch_tool(url)
anthropic_end_time = time.time()
bright_data_start_time = time.time()
bright_data_response = await scrape_content_with_bright_data_web_mcp_tools(agent, url)
bright_data_end_time = time.time()
benchmark_entry = {
"url": url,
"anthropic": {
"execution_time": anthropic_end_time - anthropic_start_time,
"output": anthropic_response.to_json()
},
"bright_data": {
"execution_time": bright_data_end_time - bright_data_start_time,
"output": bright_data_response
}
}
benchmark_results.append(benchmark_entry)
# Exportar os dados da referência
with open("benchmark_results.json", "w", encoding="utf-8") as f:
json.dump(benchmark_results, f, ensure_ascii=False, indent=4)
Os resultados podem ser resumidos na tabela a seguir:
| Ferramenta Anthropic Web Fetch | Ferramentas de dados da Web de dados brilhantes | |
|---|---|---|
| Página inicial do Anthropic | ✔️ (informações de texto parciais) | ✔️ (informações completas em Markdown) |
| Página de revisão do G2 | ❌ (a ferramenta falhou após ~10 segundos) | ✔️ (versão completa da página em Markdown) |
| Página de produto da Amazon | ✔️ (informações parciais do texto) | ✔️ (versão Markdown completa da página ou dados estruturados do produto JSON no modo Pro) |
| Página de perfil do LinkedIn | ❌ (a ferramenta falhou imediatamente) | ✔️ (versão Markdown completa da página ou dados de perfil JSON estruturados no modo Pro) |
Como você pode ver, não só a ferramenta Anthropic de busca na Web é menos eficaz do que as ferramentas de dados da Web da Bright Data, como também, mesmo quando funciona, produz resultados menos completos.
A ferramenta Anthropic se concentra principalmente no texto, enquanto as ferramentas Web MCP, como scrape_as_markdown, retornam a versão Markdown completa de uma página. Além disso, com as ferramentas Pro, como web_data_amazon_product, você pode obter feeds de dados estruturados de sites populares como a Amazon.
De modo geral, as ferramentas de dados da Web da Bright Data são claramente as vencedoras em termos de precisão e tempo de execução!
Resumo: Tabela de comparação
| Ferramenta Anthropic Web Fetch | Ferramentas de dados da Web da Bright Data | |
|---|---|---|
| Tipos de conteúdo | Páginas da Web, PDFs | Páginas da Web |
| Recursos | Extração de texto | Extração de conteúdo, Scraping de dados, rastreamento da Web e muito mais |
| Saída | Principalmente texto simples | Markdown, JSON e outros formatos prontos para LLM |
| Integração de modelos | Funciona somente com modelos Claude específicos | Integra-se totalmente a qualquer LLM e a mais de 70 tecnologias |
| Suporte para sites renderizados em JavaScript | ❌ | ✔️ |
| Manipulação de Anti-Bot Bypass/CAPTCHA | ❌ | ✔️ |
| Robustez | Beta | Pronto para produção |
| Suporte para solicitações em lote | ✔️ | ✔️ |
| Integração de agentes | Somente nas soluções da Claude | ✔️ (em qualquer solução de criação de agentes de IA que suporte MCP ou ferramentas oficiais da Bright Data) |
| Confiabilidade e integridade | Conteúdo parcial; pode falhar em páginas complexas | Extração de conteúdo completo; lida com sites e páginas complexos com proteção de bots |
| Custo | Somente uso de token padrão | Somente uso de token padrão no modo gratuito; custos adicionais no modo Pro |
Para integrar o Web MCP às tecnologias Anthropic e aos modelos Claude, consulte os guias a seguir:
- Integração do código Claude com o Web MCP da Bright Data
- Scraping de dados com o Claude: Parsing com IA em Python
- Como usar o Bright Data com o Pica MCP no Claude Desktop
Conclusão
Nesta postagem comparativa do blog, você viu como a ferramenta Anthropic de busca na Web se compara aos recursos de interação e recuperação de dados da Web oferecidos pela Bright Data. Em particular, você aprendeu a usar a ferramenta Anthropic em exemplos do mundo real, seguido de uma comparação de benchmark usando um agente LangChain equivalente interagindo com o Web MCP da Bright Data.
O vencedor claro foram as ferramentas da Bright Data, que incluem uma gama de produtos e serviços prontos para IA capazes de suportar uma ampla variedade de casos e cenários de uso.
Crie uma conta da Bright Data gratuitamente hoje mesmo e comece a explorar nossas ferramentas de dados da Web prontas para IA!





