

Neste tutorial, você aprenderá o seguinte:
- O que é a Cloudflare.
- Uma análise mais detalhada de seu mecanismo WAF.
- Como seu sistema antibot funciona de um ponto de vista técnico.
- O que acontece quando você direciona um site protegido pela Cloudflare usando ferramentas de automação padrão.
- Abordagens de alto nível para contornar o Cloudflare.
- Como contornar a verificação humana do Cloudflare em Python.
- Como contornar o Cloudflare em escala.
Vamos mergulhar de cabeça!
O que é a Cloudflare?
A Cloudflare é uma empresa de infraestrutura e segurança da Web que opera uma das maiores redes da Web. Ela oferece um conjunto abrangente de serviços projetados para tornar os sites mais rápidos e mais seguros.
Em sua essência, a Cloudflare funciona principalmente como uma CDN(Content Delivery Network), armazenando em cache o conteúdo do site em uma rede global para melhorar os tempos de carregamento e reduzir a latência. Além disso, ela oferece recursos como proteção contra DDoS(negação de serviço distribuída), um WAF (firewall de aplicativo da Web), gerenciamento de bots, serviços de DNS e muito mais.
Ao se integrarem à rede da Cloudflare, os sites podem obter rapidamente segurança aprimorada e desempenho otimizado. Isso fez com que a Cloudflare se tornasse a solução ideal para milhões de sites em todo o mundo.
Entendendo os mecanismos anti-bot da Cloudflare
Um dos motivos pelos quais a Cloudflare é tão popular é seu WAF(Web Application Firewall). Ele pode ser ativado em qualquer página da Web servida por meio de sua rede global. Em detalhes, ele representa uma das soluções mais eficazes contra scrapers, crawlers indesejados e bots em geral.
Mais especificamente, o WAF da Cloudflare fica na frente de seus aplicativos da Web. Ele inspeciona e filtra as solicitações de entrada em tempo real para impedir ataques ou tráfego indesejado antes que eles cheguem aos seus servidores ou acessem suas páginas da Web.
Como parte de sua estratégia de defesa em várias camadas, o WAF da Cloudflare usa algoritmos proprietários para detectar e bloquear bots mal-intencionados. Esses algoritmos analisam várias características do tráfego de entrada, incluindo:
- Impressões digitais de TLS: Inspeciona como o handshake do TLS é realizado pelo cliente ou navegador HTTP. Ele analisa detalhes como os conjuntos de cifras oferecidos, a ordem de negociação e outras características de baixo nível. Os bots e os clientes fora do padrão geralmente têm assinaturas TLS incomuns e não semelhantes às do navegador que os denunciam.
- Detalhes da solicitação HTTP: Examina cabeçalhos HTTP, cookies, cadeias de caracteres do agente do usuário e outros aspectos. Os bots geralmente reutilizam configurações padrão ou suspeitas que diferem daquelas usadas pelos navegadores reais.
- Impressões digitais de JavaScript: Executa JavaScript no navegador do cliente para coletar informações detalhadas sobre o ambiente. Isso inclui a versão exata do navegador, o sistema operacional, as fontes ou extensões instaladas e até mesmo características sutis de hardware. Esses pontos de dados formam uma impressão digital que ajuda a distinguir usuários reais de scripts automatizados.
- Análise comportamental: Um dos indicadores mais fortes de tráfego automatizado é o comportamento não natural. A Cloudflare monitora padrões como solicitações rápidas, falta de movimentos do mouse, caminhos de cliques idênticos, tempos ociosos e muito mais. Ela usa o aprendizado de máquina para determinar se o comportamento de navegação corresponde ao de um humano ou de um bot. Essa é uma das técnicas anti-bot mais complexas.
A Cloudflare geralmente oferece dois modos de verificação humana:
- Sempre mostre o desafio da verificação humana
- Desafio de verificação humana automatizada (somente quando for detectada atividade suspeita)
Explore as duas opções abaixo!
Modo nº 1: Sempre mostrar o desafio de verificação humana
O primeiro modo é menos comum, mas oferece uma proteção mais forte. A ideia é sempre exigir verificação humana no primeiro acesso a um site.
Por exemplo, é assim que o StackOverflow funciona no momento em que este artigo foi escrito. Tente visitá-lo no modo incógnito (para garantir uma nova sessão sem cookies) e você verá um CAPTCHA chamado Cloudflare Turnstile, mesmo que seja um usuário humano real:
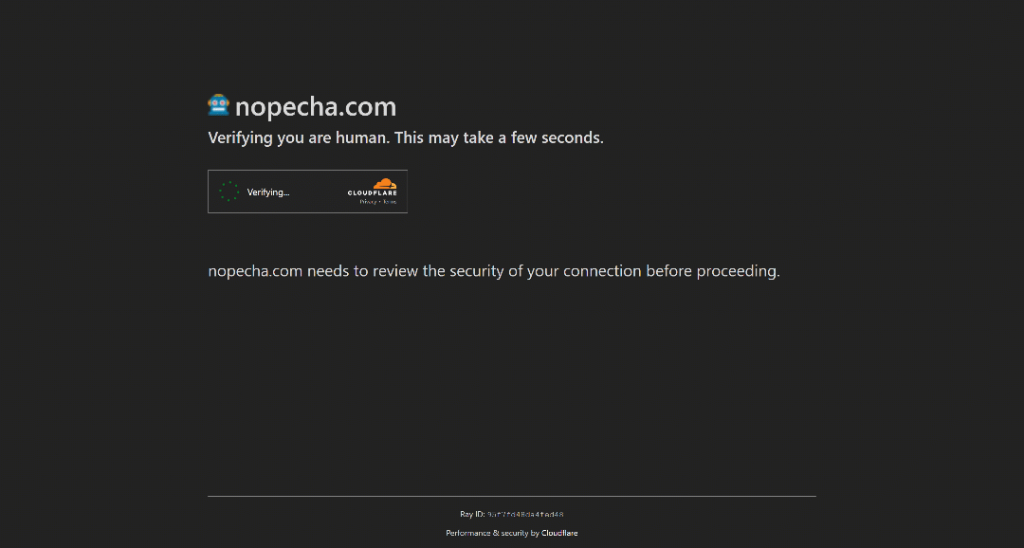
Observação: No momento em que você ler este artigo, a proteção contra bots do StackOverflow poderá ter mudado ou estar funcionando de forma diferente.
Nesse caso, se você estiver criando um script automatizado, a única opção é automatizar a interação do CAPTCHA do Turnstile de forma semelhante à humana. Isso é particularmente desafiador, pois o Turnstile depende da análise comportamental nos bastidores e de outras verificações proprietárias. É assim que ele consegue verificar se você é humano com um único clique.
Modo #2: Desafio de verificação humana automatizada
Nesse modo, a Cloudflare só emite um desafio se suspeitar que uma solicitação possa ser de um bot. Ela faz isso apresentando um desafio JavaScript, que é executado de forma invisível no navegador para verificar se o cliente se comporta como um usuário legítimo:
Esse processo é contínuo e geralmente é concluído automaticamente se você for um ser humano usando um navegador comum. Se for aprovado, você poderá continuar navegando no site sem interrupções. Como isso causa o mínimo de interrupção para os usuários comuns, é de longe o modo mais comum do Cloudflare.
No entanto, se o desafio do JavaScript falhar (o que significa que a Cloudflare conclui que o cliente provavelmente é um bot), ele passará a exibir um CAPTCHA Turnstile para verificação humana:
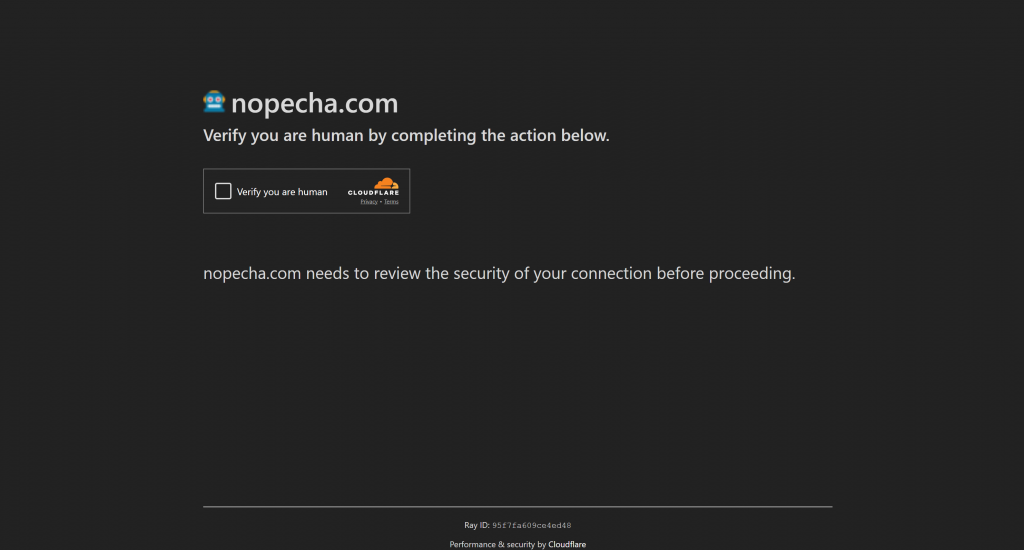
Agora, você está de volta ao que viu no cenário anterior. Nesse modo, usar um bot que apresente impressões digitais semelhantes às humanas pode ser suficiente para passar na verificação inicial, evitando completamente o CAPTCHA da catraca. Ainda assim, se ele aparecer, você precisará de uma maneira de lidar com ele.
Como a Cloudflare funciona em detalhes de um ponto de vista técnico
Tente abrir a página de teste do NopeCHA Cloudflare no modo anônimo usando seu navegador. Essa página é protegida pelo WAF da Cloudflare, portanto, o processo de verificação automatizado baseado em JavaScript será iniciado imediatamente.
Em segundo plano, uma série de solicitações POST é trocada com os endpoints da Cloudflare, transmitindo dados criptografados em suas cargas úteis:

O conteúdo exato desses payloads não está documentado publicamente. No entanto, com base nas estratégias de detecção conhecidas da Cloudflare, é razoável supor que elas incluam vários tipos de impressões digitais do navegador e do sistema.
Como seu navegador e sua configuração de hardware são legítimos, esse desafio deve ser aprovado automaticamente. Caso contrário, realize a interação necessária com o usuário (ou seja, clique na caixa de seleção).
Quando a verificação é bem-sucedida, o servidor da Cloudflare emite um cookie cf_clearance, que indica que essa sessão de usuário específica tem permissão para acessar o site:
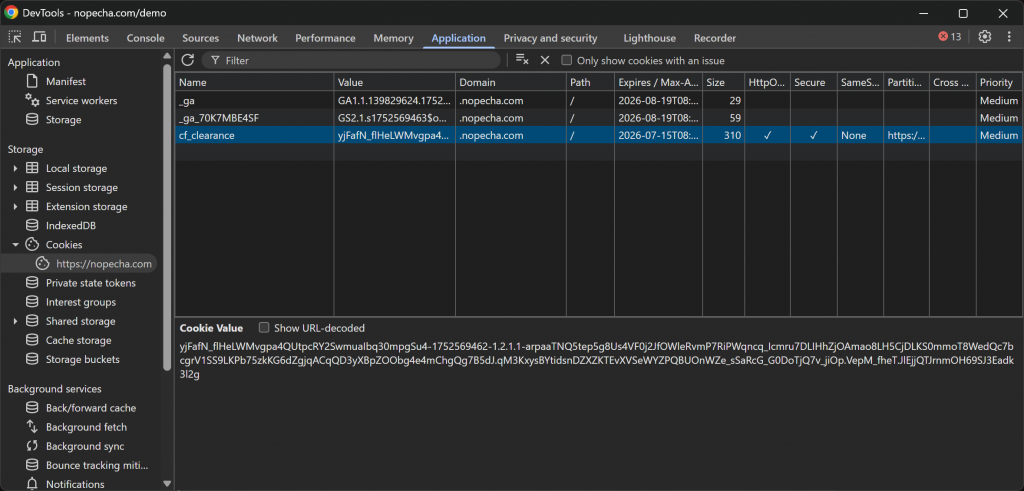
Nesse caso, o cookie é válido por 15 dias. Isso significa que, teoricamente, ele poderia ser reutilizado por um bot automatizado por algumas semanas para acessar o site de destino sem ter que resolver o processo de verificação novamente.
O que acontece quando você tenta se conectar a um site protegido pela Cloudflare
Agora, vamos dar uma olhada no que realmente acontece quando um bot automatizado tenta visitar uma página protegida pela Cloudflare.
Observação: os exemplos de scripts abaixo serão escritos em Python, mas os mesmos princípios se aplicam independentemente da linguagem de programação, do cliente HTTP ou da ferramenta de automação do navegador que você escolher.
Para esta demonstração, usaremos a página de desafio do Cloudflare do ScrapingCourse:
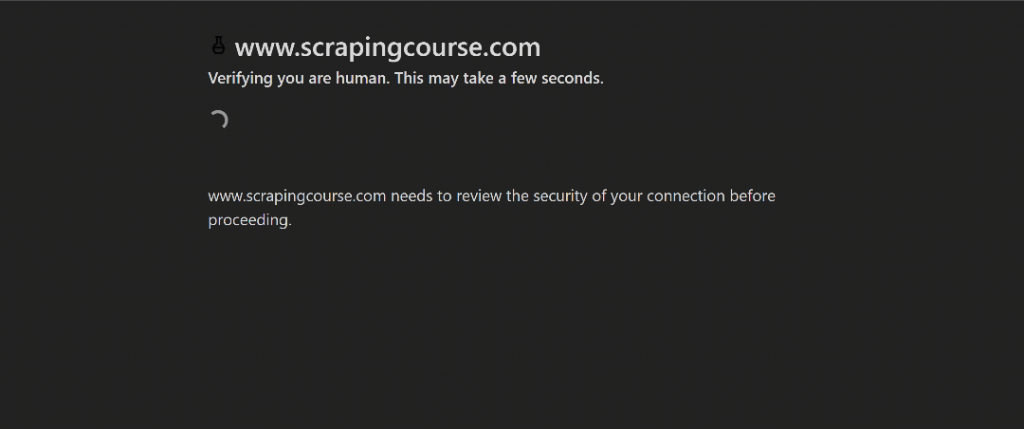
Este é um site que exige a aprovação da verificação da Cloudflare. Quando o desafio for resolvido com sucesso, a página a seguir será exibida:
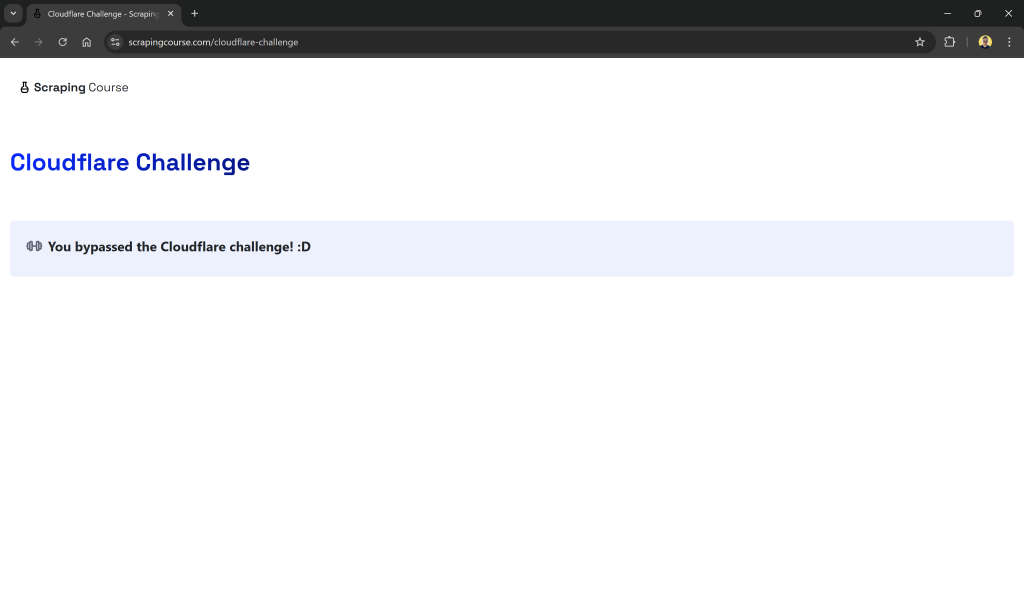
Nos exemplos a seguir, verificaremos especificamente se o conteúdo da página recuperada inclui a string:
"You bypassed the Cloudflare challenge! :D"Isso confirmará que o processo de verificação foi concluído com êxito.
Como um teste básico, veremos o que ocorre ao visitar a página protegida pelo Cloudflare acima usando duas abordagens diferentes:
- Com um cliente HTTP como o Requests
- Com uma ferramenta de automação de navegador como o Playwright
Direcionamento de páginas protegidas pelo Cloudflare com solicitações
Verifique se os pedidos podem ignorar automaticamente a verificação humana da Cloudflare com:
# pip install requests
import requests
# Connect to the target page
response = requests.get(
"https://www.scrapingcourse.com/cloudflare-challenge"
)
# Raise exceptions in case of HTTP error status codes
response.raise_for_status()
# Verify if you received the success page
html = response.text
print("Cloudflare Bypassed:", "You bypassed the Cloudflare challenge! :D" in html) Observe que o script não chegará nem mesmo ao comando print() final. Em vez disso, ele falhará com:
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://www.scrapingcourse.com/cloudflare-challengeComo você pode ver, o Cloudflare reconheceu a solicitação como proveniente de um script automatizado e a bloqueou com uma resposta 403 Forbidden.
Visitando páginas protegidas pelo Cloudflare com o Playwright
Vamos tentar agora com uma solução de automação de navegador como o Playwright:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Go to the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
try:
# Wait for the desired text to be on the page
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)Esse script instrui um navegador Chromium a visitar a página de destino. Em seguida, ele usa um localizador para verificar se um elemento contendo o texto necessário aparece na página, aguardando automaticamente por ele (por padrão, o Playwright aguarda até 30 segundos).
Execute os comandos de instalação necessários e execute o script acima. Você verá o seguinte resultado:
Cloudflare Bypassed: FalseSe você executá-lo no modoheadless (headless=False), perceberá que o script fica preso na página de verificação do Cloudflare. Isso mostrará um CAPTCHA Turnstile e aguardará que ele seja resolvido manualmente:

Observação: Se você tentar automatizar o clique na caixa de seleção Turnstile, a verificação falhará. Isso ocorre porque a Cloudflare é inteligente o suficiente para detectar que isso é automatizado e não uma interação humana real.
Abordagens de alto nível para contornar a Cloudflare
Explore três abordagens que você pode usar para contornar a proteção da Cloudflare com seu script automatizado.
Abordagem nº 1: contornar totalmente o Cloudflare
Não se esqueça de que a Cloudflare atua como uma CDN, o que significa que ela armazena em cache e distribui o conteúdo do site em vários servidores geograficamente dispersos. Portanto, os sites distribuídos pela Cloudflare normalmente só podem ser acessados por meio de servidores na rede CDN.
Agora, imagine se você conseguisse descobrir o endereço IP do servidor do site por trás da CDN. A consequência seria que você poderia interagir com o site ignorando totalmente a Cloudflare. Afinal de contas, a Cloudflare só pode avaliar as solicitações que passam por sua rede.
Isso é possível por meio de ferramentas de pesquisa de histórico de DNS, como a SecurityTrails, para identificar quaisquer registros históricos de DNS que revelem o endereço IP do servidor original. Depois de obter o IP, você pode tentar enviar solicitações diretamente para o servidor, evitando o Cloudflare.
O problema é que o servidor pode ter configurações adicionais para aceitar solicitações somente do intervalo de IPs da Cloudflare. Isso tornaria quase impossível conectar-se diretamente ao site sem ser bloqueado. Além disso, encontrar com sucesso o IP original do servidor é bastante difícil e improvável.
Abordagem nº 2: confiar em um solucionador da Cloudflare
Na Internet, você pode encontrar várias bibliotecas gratuitas e de código aberto projetadas para contornar o Cloudflare. Algumas das mais populares incluem:
- cloudscraper: Um módulo Python que lida com os desafios anti-bot do Cloudflare.
- Cfscrape: Um módulo PHP leve para contornar as páginas anti-bot do Cloudflare.
- Humanoid: Um pacote Node.js para contornar os desafios JavaScript anti-bot do Cloudflare.
Não é de surpreender que a maioria desses projetos não receba atualizações há anos. O motivo é que os desenvolvedores desistiram devido à luta constante para acompanhar as atualizações da Cloudflare. Portanto, essas ferramentas geralmente não funcionam por muito tempo.
Abordagem nº 3: use uma solução de automação com recursos de desvio do Cloudflare
Na maioria dos casos, a melhor solução para raspar um site protegido pela Cloudflare é usar uma solução de automação completa. Para serem eficazes, essas bibliotecas ou serviços on-line precisam oferecer pelo menos os seguintes recursos:
- Renderização de JavaScript, para que os desafios de JavaScript da Cloudflare possam ser executados corretamente.
- TLS, cabeçalho HTTP e falsificação de impressão digital do navegador para simular usuários reais e evitar a detecção.
- Recursos de resolução de CAPTCHA do Turnstile, para lidar com a verificação humana da Cloudflare quando ela aparecer.
- Simulação de interação semelhante à humana, como mover o mouse ao longo de uma curva B-spline para imitar o comportamento natural do usuário.
Além disso, as soluções premium geralmente incluem uma rede proxy integrada para alternar endereços IP e reduzir o risco de bloqueio.
Nos dois capítulos seguintes, você verá soluções de código aberto e principalmente soluções premium em ação!
Como contornar a verificação humana do Cloudflare em Python
A maioria das soluções de código aberto que afirmam contornar a Cloudflare só consegue fazer isso por um período limitado de tempo. Isso ocorre porque é essencialmente um jogo de gato e rato, e sua natureza de código aberto (onde os engenheiros da Cloudflare podem facilmente estudar seu código) não ajuda.
Portanto, não é de surpreender que muitas ferramentas que antes funcionavam (como o Puppeteer Stealth) não atinjam mais o objetivo. Ainda assim, no momento em que escrevo, há duas soluções que realmente conseguem contornar as proteções do Cloudflare:
- Camoufox: Um navegador Python de código aberto e antidetecção baseado em uma versão personalizada do Firefox, projetado para evitar a detecção de bots e permitir a raspagem da Web.
- SeleniumBase: Um kit de ferramentas Python de código aberto e de nível profissional para automação avançada da Web.
Vamos ver o desempenho de ambos em relação à página de desafio do Cloudflare do ScrapingCourse!
Contornar a catraca do Clouflare com o Camoufox
Primeiro, instale o Camoufox em seu projeto Python com:
pip install camoufox[geoip]Em seguida, recupere as dependências adicionais necessárias com:
python -m camoufox fetchPara obter mais informações, consulte o guia de instalação oficial.
A biblioteca Camoufox Python foi criada com base no Playwright, portanto, sua API é muito semelhante. Visite o site de destino, aguarde o desafio da catraca aparecer e lide com ele (se ele realmente aparecer) usando a lógica a seguir:
# pip install camoufox[geoip]
# python -m camoufox fetch
from camoufox.sync_api import Camoufox
from playwright.sync_api import TimeoutError
with Camoufox(
headless=False,
humanize=True,
window=(1280, 720) # So that the Turnstile checkbox is on coordinate (210, 290)
) as browser:
page = browser.new_page()
# Visit the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
# Wait for the Cloudflare Turnstile to appear and load
page.wait_for_load_state(state="domcontentloaded")
page.wait_for_load_state("networkidle")
page.wait_for_timeout(5000) # 5 seconds
# Ckick the Turnstile checkbox (if it is present)
page.mouse.click(210, 290)
try:
# Wait for the desired text to appear
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
# The text did not appear
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)Observe que a lógica de manipulação do Turnstile é um pouco complicada. Ela se baseia na suposição de que a caixa de seleção Torniquete aparecerá aproximadamente na coordenada (210, 290) em uma janela de navegador de 1280×720.
Execute o script acima e você obterá o seguinte resultado:
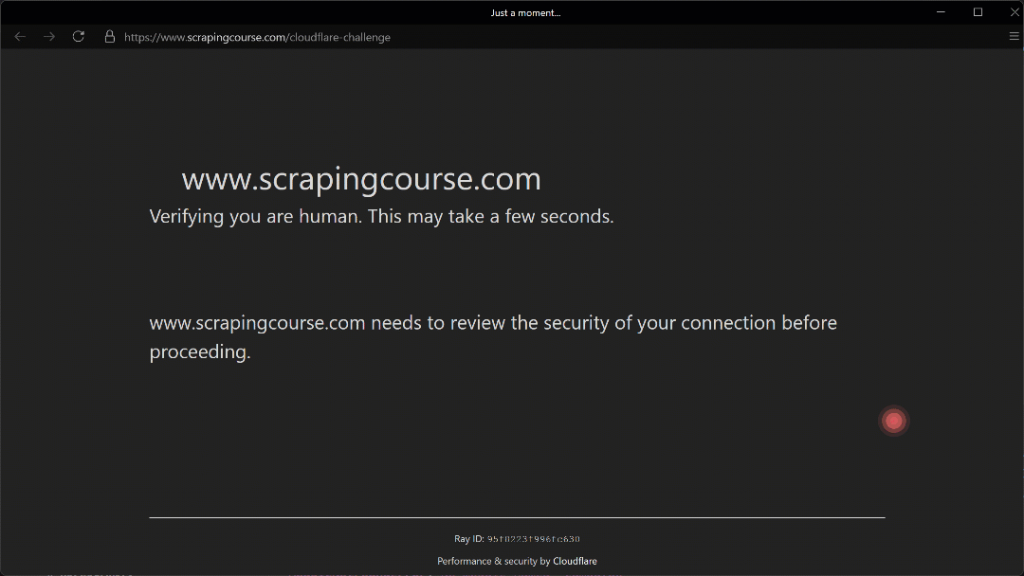
O movimento automatizado do mouse em direção à coordenada (210, 290) parece realista graças ao parâmetro Humanize=True.
Conforme mostrado aqui, o Camoufox consegue clicar com êxito na caixa de seleção. Como resultado, no terminal, você verá esta saída:
Cloudflare Bypassed: TrueMissão concluída!
Evite o Clouflare com o SeleniumBase
Instale o SeleniumBase com:
pip install seleniumbaseEm seguida, use-o para lidar com o Cloudflare:
# pip install seleniumbase
from seleniumbase import Driver
from seleniumbase.common.exceptions import TextNotVisibleException
# Launch in undetected-chromedriver mode
driver = Driver(uc=True)
# Visit the target page
url = "https://www.scrapingcourse.com/cloudflare-challenge"
driver.uc_open_with_reconnect(url, 4)
# Click the Turnstile (if it is present) and reload the page
driver.uc_gui_click_captcha()
try:
# Wait for the desired text to appear
driver.wait_for_text("You bypassed the Cloudflare challenge! :D", "main")
challenge_bypassed = True
except TextNotVisibleException:
# The text did not appear
challenge_bypassed = False
# Close the browser and release its resources
driver.quit()
print("Cloudflare Bypassed:", challenge_bypassed) No modo uc=True (que usa o undetected-chromedriver sob o capô), o SeleniumBase pode aproveitar o método dedicado uc_gui_click_captcha() para lidar com o CAPTCHA do Turnstile, se ele aparecer. Isso significa que, desta vez, não há necessidade de lógica de clique personalizada.
Execute o script e você verá:
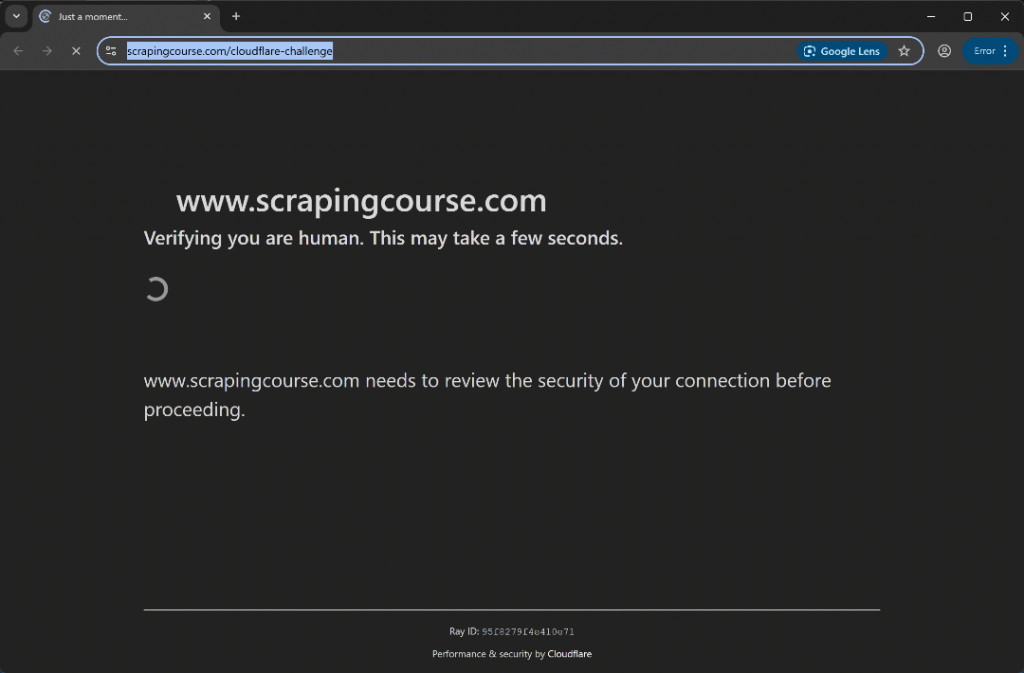
Dessa vez, o script de automação ignora a fase de verificação inicial sem nem mesmo acionar o CAPTCHA do Turnstile. De qualquer forma, o método uc_gui_click_captcha() teria sido capaz de lidar com isso com sucesso. Isso é possível graças ao modo UC, sobre o qual você pode saber mais em nosso guia de raspagem do SeleniumBase.
E pronto! Cloudflare contornado mais uma vez.
Como contornar o Cloudflare em escala
As duas bibliotecas apresentadas anteriormente funcionam bem para scripts de automação simples, mas têm três grandes desvantagens:
- Para obter uma alta porcentagem de resultados efetivos, eles precisam executar os navegadores no modo de cabeçalho. Isso consome muitos recursos do sistema e torna a escalabilidade mais desafiadora.
- Elas são inconsistentes e podem parar de funcionar temporariamente se a Cloudflare atualizar sua lógica de detecção. Como essas soluções são mantidas pela comunidade, as atualizações podem levar dias ou até semanas para serem lançadas.
- Não há suporte oficial. Você deve confiar nos recursos on-line e na ajuda da comunidade.
Por esses motivos, as bibliotecas de código aberto com recursos de bypass da Cloudflare não são recomendadas para projetos de produção. Para obter resultados mais dimensionáveis e consistentes – e o apoio de uma equipe de suportededicada 24 horaspor dia, 7 dias por semana -, vocêprecisa de produtos premium como os fornecidos pela Bright Data.
Especificamente, aqui, vamos nos concentrar nas duas soluções a seguir:
- Web Unlocker: Um ponto de extremidade de raspagem tudo-em-um que inclui todos os recursos de desvio anti-bot para recuperar HTML de qualquer site.
- API do navegador: Um navegador em nuvem infinitamente dimensionável criado para suportar qualquer fluxo de trabalho de automação. Ele se integra ao Puppeteer, Selenium, Playwright e a qualquer outra ferramenta de automação de navegador. Inclui gerenciamento avançado de impressões digitais, solução CAPTCHA integrada e rotação automática de proxy.
Veja como integrar essas ferramentas em Python (embora elas sejam compatíveis com qualquer linguagem de programação) em seus scripts de automação!
Como contornar a Cloudflare com o Web Unlocker
Antes de começar, siga o guia oficial para configurar o Web Unlocker gratuitamente em sua conta da Bright Data. Você também precisará gerar uma chave de API da Bright Data para autenticar suas solicitações no endpoint do Web Unlocker.
Aqui, assumiremos que o nome de sua zona do Web Unlocker é web_unlocker.
Depois de concluir as etapas acima, teste o Web Unlocker na página de destino usada neste artigo:
# pip install requests
import requests
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace with your Bright Data API key
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
data = {
"zone": "web_unlocker", # Replace with the name of your Web Unlocker zone
"url": "https://www.scrapingcourse.com/cloudflare-challenge",
"format": "raw"
}
# Perform a request to the Web Unlocker endpoint
response = requests.post(
"https://api.brightdata.com/request",
json=data,
headers=headers
)
# Get the response and check if Cloudflare was bypassed
html = response.text
print("Cloudflare Bypassed:", "You bypassed the Cloudflare challenge! :D" in html)O Web Unlocker retornará o conteúdo HTML da página por trás da parede de verificação do Cloudflare. Em particular, a variável html conterá conteúdo como este:
<!doctype html>
<html lang="en"><head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Cloudflare Challenge - ScrapingCourse.com</title>
<!-- omitted for brevity ... -->
<main class="page-content py-4" id="main-content" data-testid="main-content" data-content="main">
<div class="container" id="content-container" data-testid="content-container" data-content="container">
<div class="cloudflareChallenge">
<h1 id="page-title" class="page-title text-4xl font-bold mb-2 text-left gradient-text highlight gradient-text leading-10" data-testid="page-title" data-content="title">
Cloudflare Challenge
</h1>
<div class="challenge-info bg-[#EDF1FD] rounded-md p-4 mb-8 mt-5" id="challenge-info" data-testid="challenge-info" data-content="challenge-info">
<div class="info-header flex items-center gap-2 pb-2" id="info-header" data-testid="info-header" data-content="info-header">
<img width="25" height="15" src="https://www.scrapingcourse.com/assets/images/challenge.svg" data-testid="challenge-image" data-content="challenge-image">
<h2 class="challenge-title text-xl font-bold" id="challenge-title" data-testid="challenge-title" data-content="challenge-title">
You bypassed the Cloudflare challenge! 😀
</h2>
</div>
</div>
</div>
</div>
</main>
<!-- omitted for brevity ... -->
</html>Esse é exatamente o conteúdo HTML da página por trás do muro de verificação humana da Cloudflare. Portanto, não é surpresa que o resultado do script seja:
Cloudflare Bypassed: TrueObserve que você só será cobrado por solicitações bem-sucedidas, e uma avaliação gratuita está disponível!
Automatizando o Cloudflare com a API do navegador
Como pré-requisito, configure um produto de API do navegador em sua conta da Bright Data. Na página da zona, copie o URL de conexão do Playwright CDP:
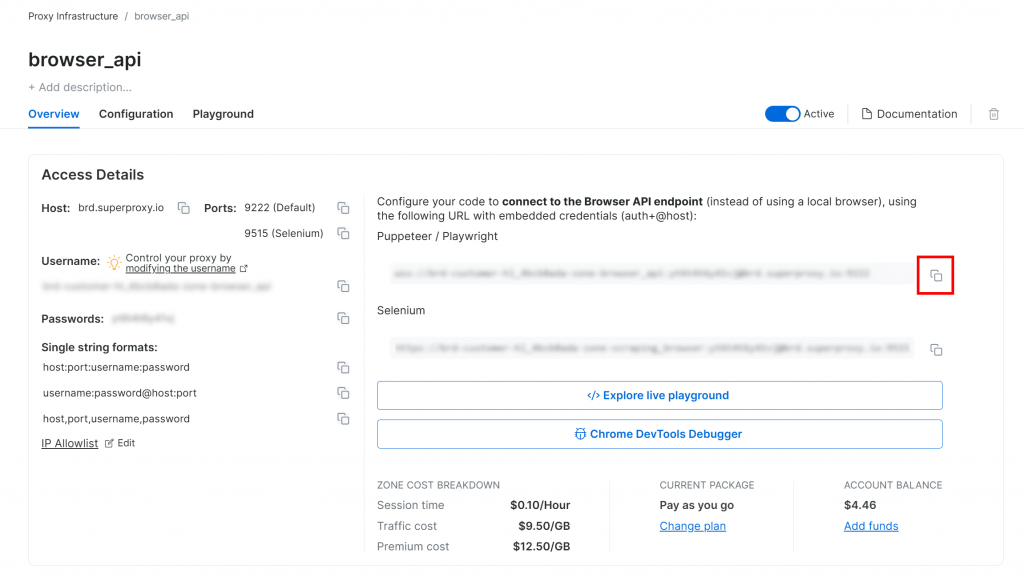
Esse URL contém suas credenciais e permite que você instrua qualquer solução de automação de navegador que suporte o CDP(Chrome DevTools Protocol) remoto a se conectar à API do navegador da Bright Data. Em outras palavras, sua ferramenta de automação funcionará em uma instância de navegador hospedada remotamente e gerenciada pela Bright Data. Isso significa que a escalabilidade e a manutenção do navegador são tratadas para você.
Amplie o script do Playwright mostrado anteriormente para se conectar à API do navegador por meio do URL do CDP:
# pip install playwright
# python install -m playwright install
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
BRIGHT_DATA_API_CDP_URL = "<YOUR_BRIGHT_DATA_API_CDP_URL>" # Replace with your Browser API Playwright CDP URL
with sync_playwright() as p:
# Connect to the remote Browser API
browser = p.chromium.connect_over_cdp(BRIGHT_DATA_API_CDP_URL)
page = browser.new_page()
# Go to the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
try:
# Wait for the desired text to be on the page
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)Dessa vez, o script contornará com êxito a verificação do Cloudflare graças aos recursos avançados da API do navegador. Você verá a seguinte saída no terminal:
Cloudflare Bypassed: TrueMuito bem! O desvio do Cloudflare não é mais um problema.
Conclusão
Neste artigo, você aprendeu como a Cloudflare funciona e explorou soluções práticas para contorná-la em seus fluxos de trabalho de automação. Como você viu aqui, contornar as medidas anti-scraping da Cloudflare é desafiador, mas certamente possível.
Independentemente da abordagem que você escolher, tudo se torna mais fácil com soluções profissionais, rápidas e confiáveis, como:
- Web Unlocker: Um endpoint que ignora automaticamente a limitação de taxa, a impressão digital e outras restrições anti-bot para você.
- API do navegador: Um navegador totalmente hospedado que permite automatizar a interação com qualquer página da Web.
Inscreva-se agora gratuitamente e descubra qual das soluções da Bright Data é mais adequada às suas necessidades!



