

Neste guia, você aprenderá:
- O que é o Undetected ChromeDriver e como ele pode ser útil
- Como ele minimiza a detecção de bots
- Como usá-lo com Python para Scraping de dados
- Usos e métodos avançados
- Suas principais limitações e desvantagens
- Tecnologias semelhantes
Vamos começar!
O que é o Undetected ChromeDriver?
O Undetected ChromeDriveré uma biblioteca Python que fornece uma versão otimizada do ChromeDriver do Selenium. Ele foi corrigido para limitar a detecção por serviços antibots, tais como:
- Imperva
- DataDome
- Distil Networks
Ele também pode ajudar a contornar certas proteções do Cloudflare, embora isso possa ser mais desafiador. Para obter mais detalhes, siga nosso guia sobrecomo contornar o Cloudflare.
Se você já usouferramentas de automação de navegadorcomo o Selenium, sabe que elas permitem controlar navegadores programaticamente. Para que isso seja possível, elas configuram os navegadores de maneira diferente das configurações normais dos usuários.
Os sistemas antibot procuram essas diferenças, ou “vazamentos”, para identificar bots de navegador automatizados. O ChromeDriver não detectado corrige os drivers do Chrome para minimizar esses sinais reveladores, reduzindo a detecção de bots. Isso o torna ideal para sites de Scraping de dados protegidos pormedidas anti-scraping!
Como funciona
O Undetected ChromeDriver reduz a detecção do Cloudflare, Imperva, DataDome e soluções semelhantes empregando as seguintes técnicas:
- Renomeando variáveis Selenium para imitar as usadas por navegadores reais
- Usar strings de User-Agent legítimas e reais para evitar a detecção
- Permitir que o usuário simule uma interação humana natural
- Gerenciando cookies e sessões adequadamente durante a navegação em sites
- Habilitando o uso de Proxies para contornar o bloqueio de IP e evitar a limitação de taxa
Esses métodos ajudam o navegador controlado pela biblioteca a contornar várias defesas anti-scraping de maneira eficaz.
Usando o ChromeDriver não detectado para Scraping de dados: guia passo a passo
A maioria dos sites usa medidas anti-bot avançadas para impedir que scripts automatizados acessem suas páginas. Esses mecanismos também impedem efetivamenteos bots de Scraping de dados.
Por exemplo, suponha que você queira extrair o título e a descrição da seguintepágina de produto da GoDaddy:
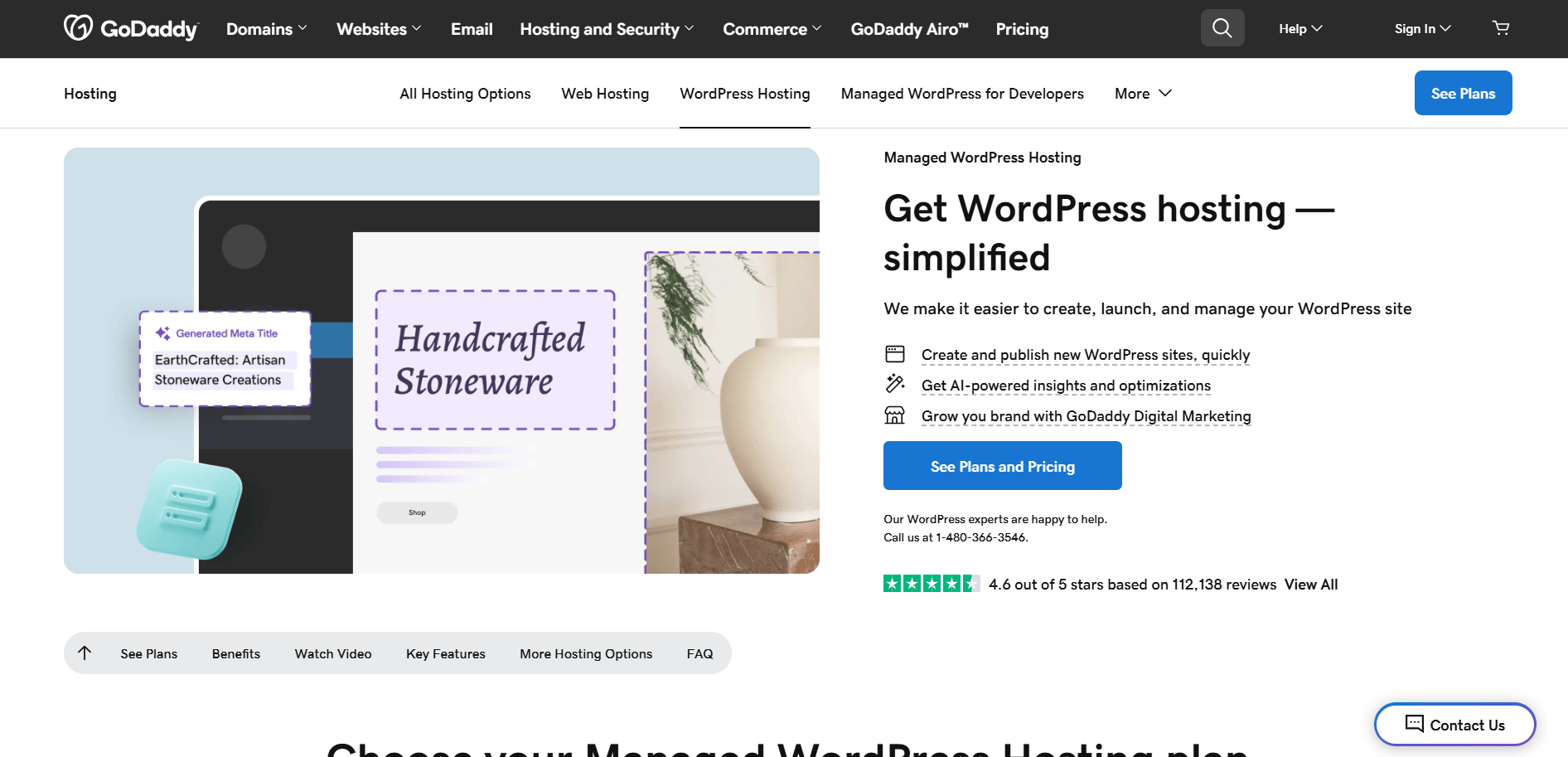
Com o Selenium simples em Python, seu script de scraping ficará mais ou menos assim:
# pip install selenium
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# configure uma instância do Chrome para iniciar no modo headless
options = Options()
options.add_argument("--headless")
# criar uma instância do driver web do Chrome
driver = webdriver.Chrome(service=Service(), options=options)
# conectar-se à página de destino
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
# lógica de scraping...
# fechar o navegador
driver.quit()
Se você não estiver familiarizado com essa lógica, consulte nosso guia sobreScraping de dados comSelenium.
Ao executar o script, ele falhará devido a esta página de erro:

Em outras palavras, o script Selenium foi bloqueado por uma solução anti-bot (Akamai, neste exemplo).
Então, como contornar isso? A resposta é o Undetected ChromeDriver!
Siga as etapas abaixo para aprender a usar a biblioteca Python undetected_chromedriver para Scraping de dados.
Etapa 1: Pré-requisitos e configuração do projeto
O Undetected ChromeDriver tem os seguintes pré-requisitos:
- Versão mais recente do Chrome
- Python 3.6+: se o Python 3.6 ou posterior não estiver instalado em sua máquina,baixe-o do site oficiale siga as instruções de instalação.
Observação: a biblioteca baixa e corrige automaticamente o binário do driver para você, portanto, não há necessidade de baixar manualmenteo ChromeDriver.
Agora, use o seguinte comando para criar um diretório para o seu projeto:
mkdir undetected-chromedriver-Scraper
O diretório undetected-chromedriver-scraper servirá como pasta do projeto para o seu Scraper Python.
Navegue até ele e inicialize umambiente virtual:
cd undetected-chromedriver-Scraper
python -m venv env
Abra a pasta do projeto em seu IDE Python preferido.O Visual Studio Code com a extensão Pythonouo PyCharm Community Editionsão ótimas opções.
Em seguida, crie um arquivoscraper.pydentro da pasta do projeto, seguindo a estrutura mostrada abaixo:
Atualmente,scraper.pyé um script Python vazio. Em breve, você adicionará a lógica de raspagem a ele.
No terminal do seu IDE, ative o ambiente virtual. No Linux ou macOS, use:
./env/bin/activate
De forma equivalente, no Windows, execute:
env/Scripts/activate
Ótimo! Agora você tem um ambiente Python pronto para Scraping de dados por meio da automação do navegador.
Etapa 2: Instale o Undetected ChromeDriver
Em um ambiente virtual ativado, instale o Undetected ChromeDriver através do pacote pipundetected_chromedriver:
pip install undetected_chromedriver
Nos bastidores, essa biblioteca instalará automaticamente o Selenium, pois ele é uma de suas dependências. Portanto, você não precisa instalar o Selenium separadamente. Isso também significa que você terá acesso a todas as importações do Selenium por padrão.
Etapa 3: Configuração inicial
Importe o undetected_chromedriver:
import undetected_chromedriver as uc
Você pode então inicializar um Chrome WebDriver com:
driver = uc.Chrome()
Assim como o Selenium, isso abrirá uma janela do navegador que você poderá controlar usando a API do Selenium. Isso significa que o objeto driver expõe todos os métodos padrão do Selenium, juntamente com alguns recursos adicionais que exploraremos mais tarde.
A principal diferença é que esta versão do driver Chrome foi corrigida para ajudar a contornar certas soluções anti-bot.
Para fechar o driver, basta chamar o método quit():
driver.quit()
Veja como é uma configuração básica do Undetected ChromeDriver:
import undetected_chromedriver as uc
# Inicializar uma instância do Chrome
driver = uc.Chrome()
# Lógica de scraping...
# Fechar o navegador e liberar seus recursos
driver.quit()
Fantástico! Agora você está pronto para realizar o Scraping de dados diretamente no navegador.
Etapa 4: use-o para Scraping de dados
Aviso: esta seção segue as mesmas etapas de uma configuração padrão do Selenium. Se você já está familiarizado com o Scraping de dados do Selenium, sinta-se à vontade para pular para a próxima seção com o código final.
Primeiro, use o método get() para navegar no navegador até a página de destino:
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
Em seguida, visite a página no modo de navegação anônima do seu navegador e inspecione o elemento que deseja extrair:
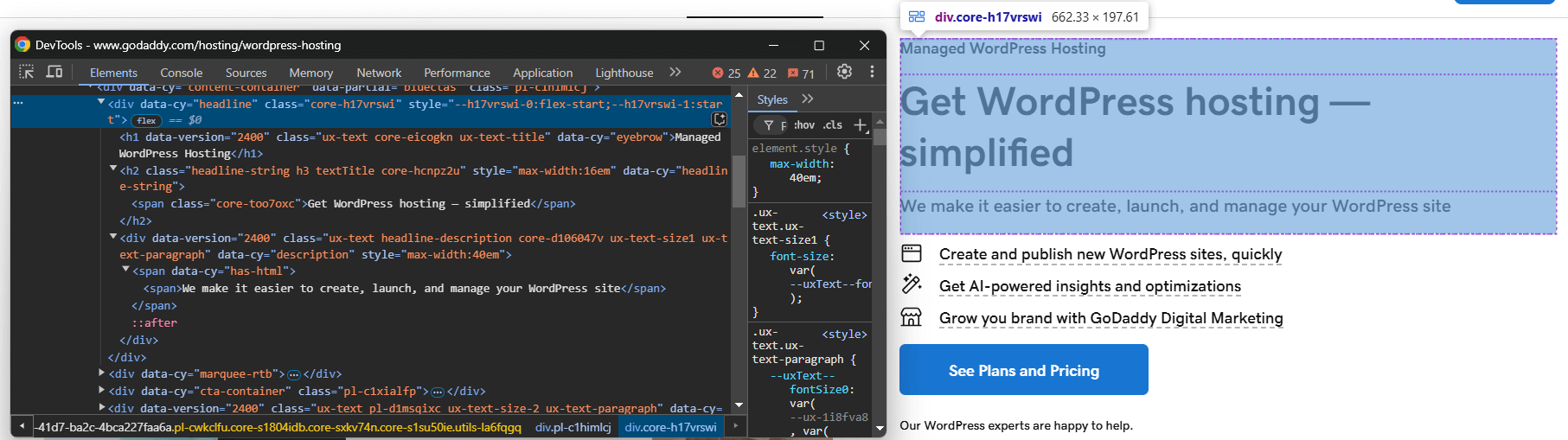
Suponha que você deseja extrair o título, o slogan e a descrição do produto.
Você pode extrair tudo isso com o seguinte código:
headline_element = driver.find_element(By.CSS_SELECTOR, "[data-cy="headline"]")
title_element = headline_element.find_element(By.CSS_SELECTOR, "h1")
title = title_element.text
tagline_element = headline_element.find_element(By.CSS_SELECTOR, "h2")
tagline = tagline_element.text
description_element = headline_element.find_element(By.CSS_SELECTOR, "[data-cy="description"]")
description = description_element.text
Para que o código acima funcione, você precisa importar By do Selenium:
from selenium.webdriver.common.by import By
Agora, armazene os dados coletados em um dicionário Python:
produto = {
"título": título,
"slogan": slogan,
"descrição": descrição
}
Por fim, exporte os dados para um arquivo JSON:
with open("product.json", "w") as json_file:
json.dump(product, json_file, indent=4)
Não se esqueça de importar json da biblioteca padrão do Python:
import json
E pronto! Você acabou de implementar a lógica básica de Scraping de dados do Undetected ChromeDriver.
Etapa 5: Junte tudo
Este é o script final de scraping:
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
# Crie uma instância do Chrome Web Driver
driver = uc.Chrome()
# Conecte-se à página de destino
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
# Lógica de scraping
headline_element = driver.find_element(By.CSS_SELECTOR, "[data-cy="headline"]")
title_element = headline_element.find_element(By.CSS_SELECTOR, "h1")
title = title_element.text
tagline_element = headline_element.find_element(By.CSS_SELECTOR, "h2")
tagline = tagline_element.text
description_element = headline_element.find_element(By.CSS_SELECTOR, "[data-cy="description"]")
description = description_element.text
# Preencha um dicionário com os dados coletados
produto = {
"title": título,
"tagline": tagline,
"description": descrição
}
# Exporte os dados coletados para JSON
com open("produto.json", "w") como json_file:
json.dump(produto, json_file, indent=4)
# Fechar o navegador e liberar seus recursos
driver.quit()
Execute com:
python3 Scraper.py
Ou, no Windows:
python Scraper.py
Isso abrirá um navegador mostrando a página da web de destino, não a página de erro como no Selenium básico:
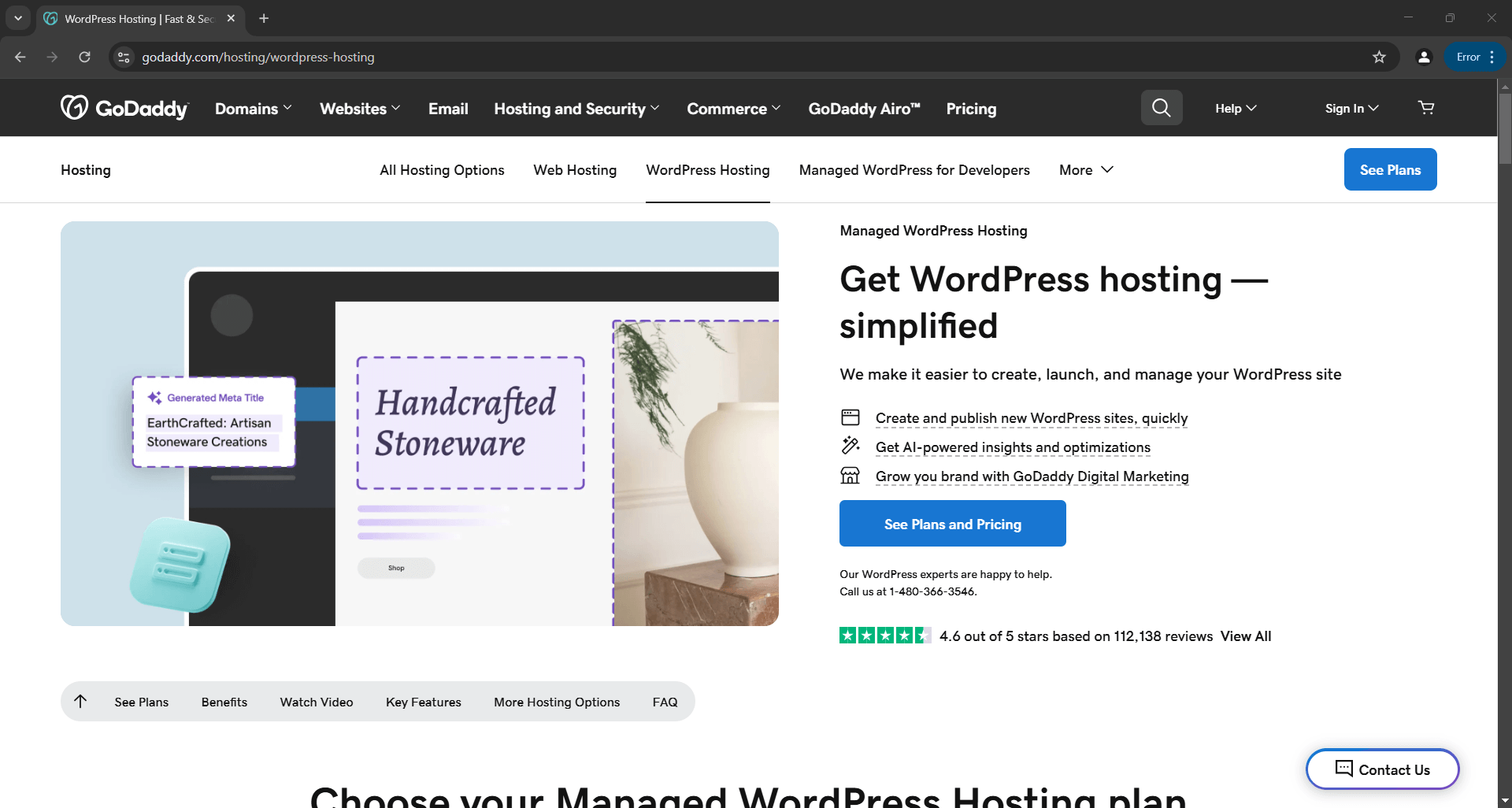
O script extrairá os dados da página e produzirá o seguinte arquivo product.json:
{
"title": "Hospedagem WordPress gerenciada",
"tagline": "Obtenha hospedagem WordPress — simplificada",
"description": "Facilitamos a criação, o lançamento e o gerenciamento do seu site WordPress"
}
undetected_chromedriver: uso avançado
Agora que você sabe como a biblioteca funciona, está pronto para explorar alguns cenários mais avançados.
Escolha uma versão específica do Chrome
Você pode especificar uma versão específica do Chrome para a biblioteca usar, definindo o argumento version_main:
import undetected_chromedriver as uc
# Especifique a versão desejada do Chrome
driver = uc.Chrome(version_main=105)
Observe que a biblioteca também funciona com outros navegadores baseados no Chromium, mas isso requer alguns ajustes adicionais.
com Sytnax
Para evitar chamar manualmente o métodoquit()quando você não precisar mais do driver, você pode usar a sintaxewith, conforme mostrado abaixo:
import undetected_chromedriver as uc
with uc.Chrome() as driver:
driver.get("<YOUR_URL>")
Quando o código dentro do bloco with for concluído, o Python fechará automaticamente o navegador para você.
Observação: essa sintaxe é compatível a partir da versão 3.1.0.
Integração de Proxy
A sintaxe para adicionar um Proxy ao Undetected ChromeDriver é semelhante à do Selenium normal. Basta passar a URL do seu Proxy para o sinalizador --proxy-server, conforme mostrado abaixo:
import undetected_chromedriver como uc
proxy_url = "<SUA_URL_DE_PROXY>"
options = uc.ChromeOptions()
options.add_argument(f"--proxy-server={proxy}")
Observação: o Chrome não oferece suporte a proxies autenticados por meio do sinalizador --proxy-server.
API estendida
O undetected_chromedriver amplia a funcionalidade regular do Selenium com alguns métodos, incluindo:
WebElement.click_safe(): use este método se clicar em um link causar detecção. Embora não seja garantido que funcione, ele oferece uma abordagem alternativa para cliques mais seguros.WebElement.children(tag=None, recursive=False): este método ajuda você a encontrar facilmente elementos filhos. Por exemplo:
# Obtenha o sexto filho (de qualquer tag) dentro do corpo e, em seguida, encontre todos os elementos <img> recursivamente
images = body.children()[6].children("img", True)
Limitações da biblioteca Python undetected_chromedriver
Embora a undetected_chromedriver seja uma biblioteca Python poderosa, ela tem algumas limitações conhecidas. Aqui estão as mais importantes que você deve conhecer!
Bloqueios de IP
A página GitHub da biblioteca deixa claro:o pacote não oculta seu endereço IP. Portanto, se você estiver executando um script a partir de um datacenter, é provável que a detecção ainda ocorra. Da mesma forma, se o IP da sua casa tiver uma reputação ruim, você também poderá ser bloqueado!

Para ocultar seu IP, você precisa integrar o navegador controlado a um Proxy, conforme demonstrado anteriormente.
Sem suporte para navegação GUI
Devido ao funcionamento interno do módulo, você deve navegar programaticamente usando o método get(). Evite usar a GUI do navegador para navegação manual — interagir com a página usando o teclado ou o mouse aumenta o risco de detecção!
A mesma regra se aplica ao manuseio de novas guias. Se você precisar trabalhar com várias guias, abra uma nova guia com uma página em branco usando o URL data:, (sim, incluindo a vírgula), que o driver aceita. Depois disso, prossiga com sua lógica de automação habitual.
Somente seguindo essas diretrizes, você poderá minimizar a detecção e desfrutar de sessões de Scraping de dados mais tranquilas.
Suporte limitado para o modo headless
Oficialmente, o modo headless não é totalmente compatível com a biblioteca undetected_chromedriver. No entanto, você pode experimentá-lo usando a seguinte sintaxe:
driver = uc.Chrome(headless=True)
O autor anunciou no changelog da versão 3.4.5 que o modo headless deve funcionar e garantir a capacidade de contornar bots. No entanto, ele continua instável. Use esse recurso com cautela e realize testes completos para garantir que ele atenda às suas necessidades de scraping.
Problemas de estabilidade
Conforme mencionado na página PyPI do pacote, os resultados podem variar devido a vários fatores. Não são fornecidas garantias, além dos esforços contínuos para entender e combater os algoritmos de detecção.
Isso significa que um script que hoje consegue contornar o Distil, Cloudflare, Imperva, DataDome ou hCaptcha pode falhar amanhã se as soluções anti-bot receberem atualizações:
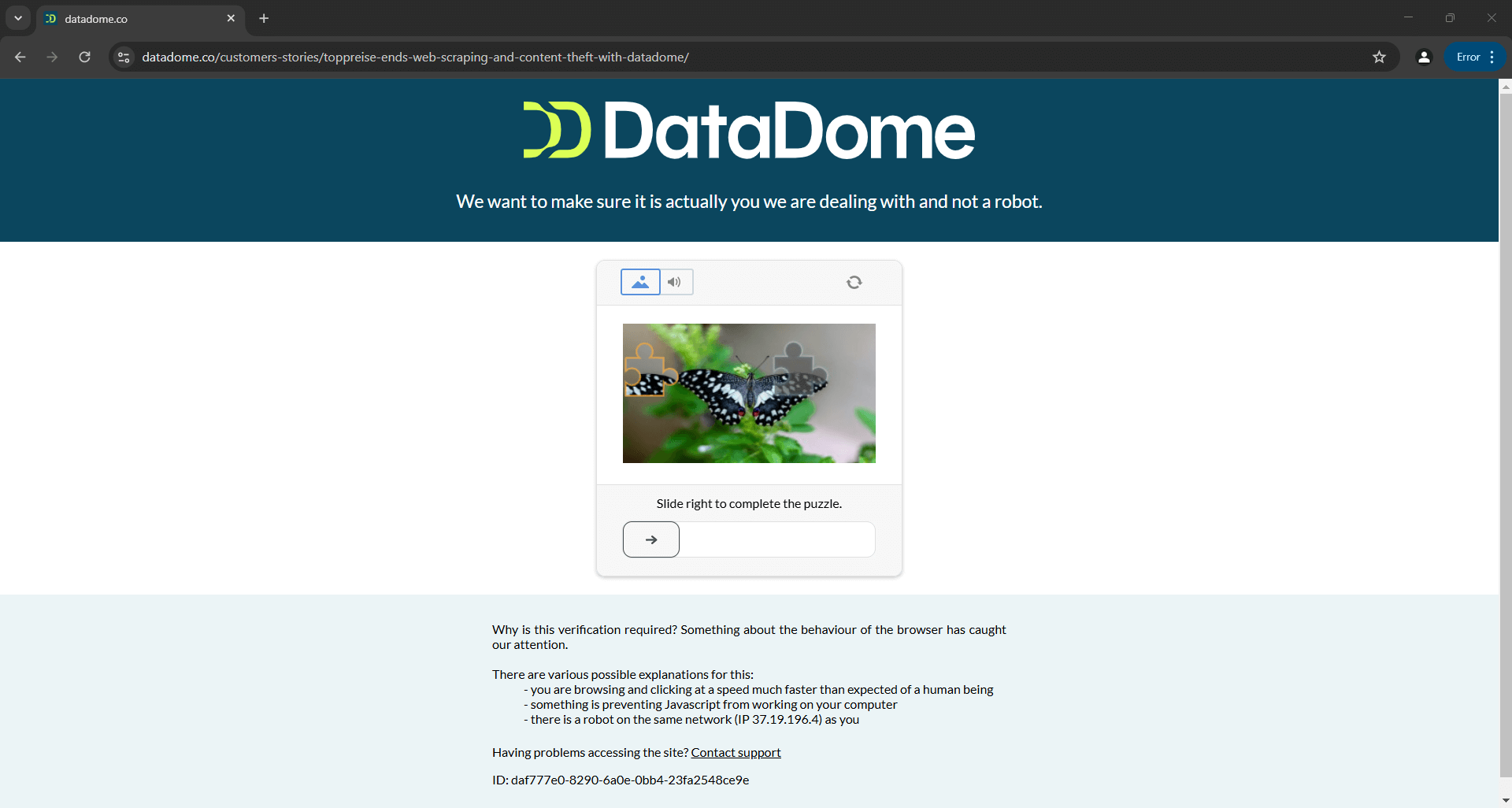
A imagem acima é o resultado de um script fornecido na documentação oficial. Isso demonstra que mesmo os scripts criados pelos desenvolvedores da ferramenta podem nem sempre funcionar como esperado. Mais especificamente, o script acionou um CAPTCHA, que pode facilmente interromper sua lógica de automação.
Saiba mais em nosso guia sobrecomo contornar CAPTCHAs em Python.
Leitura adicional
O Undetected ChromeDriver não é a única biblioteca que modifica os drivers do navegador para impedir a detecção. Se você estiver interessado em explorar ferramentas semelhantes ou aprender mais sobre esse tópico, leia estes guias:
- Evite ser bloqueado com o Puppeteer Stealth
- Evite a detecção de bots com o Playwright Stealth
- Guia para Scraping de dados com SeleniumBase
Conclusão
Neste artigo, você aprendeu como lidar com a detecção de bots no Selenium usando o Undetected ChromeDriver. Essa biblioteca fornece uma versão corrigida do ChromeDriver para Scraping de dados sem ser bloqueado.
O problema é que tecnologias anti-bot avançadas, como o Cloudflare, ainda serão capazes de detectar e bloquear seus scripts. Bibliotecas como o undetected_chromedriver são instáveis — embora possam funcionar hoje, podem não funcionar amanhã.
O problema não está na API do Selenium para controlar um navegador, mas nas configurações do próprio navegador. Isso implica que a solução é um navegador baseado em nuvem, sempre atualizado e escalável, com funcionalidade anti-bot integrada. Esse navegador existe e se chamaNavegador de scraping!
O Navegador de scraping da Bright Data é um navegador em nuvem altamente escalável que funciona comSelenium,Puppeteer,Playwright e muito mais. Ele pode lidar com impressões digitais do navegador, resolução de CAPTCHA e novas tentativas automatizadas para você. Além disso, ele alterna automaticamente o IP de saída a cada solicitação. Isso é possível graças à rede mundial de proxies que inclui:
- Proxy de datacenter– Mais de 770.000 IPs de datacenter.
- Proxies residenciais– Mais de 72 milhões de IPs residencialis em mais de 195 países.
- Proxy ISP– Mais de 700.000 IPs de ISP.
Crie uma conta gratuita na Bright Data hoje mesmo para experimentar nosso Navegador de scraping ou testar nossos Proxies.




