
Neste guia, você aprenderá:
- O que é o AWS Step Functions e por que ele é importante para a automação de fluxos de trabalho.
- Por que os fluxos de trabalho de Scraping de dados são adequados para este serviço da AWS.
- Como a Bright Data ajuda a superar os desafios inerentes ao Scraping de dados.
- Como integrar a Bright Data ao AWS Step Functions, seja por meio de chamadas diretas de API ou por meio de uma função Lambda dedicada.
Vamos começar!
Uma introdução ao AWS Step Functions
Antes de mostrar como usar o AWS Step Functions para orquestrar um fluxo de trabalho de Scraping de dados, obtenha mais contexto sobre essa solução.
O que é o AWS Step Functions?
O AWS Step Functions é um serviço totalmente gerenciado que permite coordenar e automatizar fluxos de trabalho complexos entre os serviços da AWS. É um serviço de orquestração visual usado para criar aplicativos distribuídos e automatizar processos, conectando vários serviços da AWS em fluxos de trabalho sem servidor.
Em sua essência, o Step Functions depende de máquinas de estado, que são fluxos de trabalho compostos por uma série de etapas, chamadas de estados. Cada estado executa uma tarefa, como invocar um serviço AWS ou executar um código personalizado.
Essa abordagem simplifica a orquestração, o tratamento de erros e o monitoramento, permitindo que você se concentre na lógica do aplicativo em vez da infraestrutura. Em detalhes, os principais benefícios que elas trazem são:
- Orquestração simplificada: gerencie processos de várias etapas e dependências sem escrever código complexo.
- Tratamento de erros integrado: novas tentativas e blocos de captura ajudam os fluxos de trabalho a se recuperarem automaticamente de falhas.
- Execução paralela e dinâmica: execute tarefas simultaneamente ou itere sobre Conjuntos de dados para um processamento mais rápido.
- Suporte humano no ciclo: inclua etapas de aprovação ou retornos de chamada nos fluxos de trabalho.
- Integração de serviços: conecte-se perfeitamente com AWS Lambda, Glue, SQS, SNS, SageMaker e muito mais.
Saiba mais nos documentos oficiais.
Entendendo como o AWS Step Functions funciona
Para entender verdadeiramente o AWS Step Functions, é útil se concentrar em seus conceitos básicos, que formam a base de qualquer fluxo de trabalho:
- Máquina de estados: a espinha dorsal do Step Functions. Uma máquina de estados representa seu fluxo de trabalho, armazenando e atualizando seu estado à medida que as tarefas avançam. Você a define usando JSON e a linguagem Amazon States Language. Você pode escolher fluxos de trabalho padrão para processos de longa duração ou que exigem intervenção humana, ou fluxos de trabalho expressos para tarefas curtas e de alto volume.
- Estados: cada etapa de um fluxo de trabalho. Os estados podem executar tarefas (Task), tomar decisões (Choice), pausar a execução (Wait), lidar com falhas ou sucessos (Fail/Succeed), ramificar a execução (Parallel) ou repetir entradas (Map). A combinação de estados define a lógica do seu fluxo de trabalho.
- Estados da tarefa: unidades de trabalho dentro de um fluxo de trabalho. As tarefas de serviço automatizam as interações com serviços da AWS, como Lambda ou Glue. Em vez disso, as tarefas de atividade se conectam a códigos externos ou humanos, úteis para etapas ou aprovações assíncronas.
- Execução e monitoramento: o Step Functions registra todas as entradas, saídas, novas tentativas e erros de cada etapa, permitindo rastrear problemas e verificar o comportamento do fluxo de trabalho.
Orquestração de fluxo de trabalho de Scraping de dados sem servidor
O AWS Step Functions oferece uma maneira eficaz de orquestrar fluxos de trabalho de Scraping de dados sem servidor de maneira escalável e confiável. Em vez de criar um script de Scraping de dados monolítico, você pode dividir o processo em etapas menores, orientadas por eventos, e coordená-las por meio de uma máquina de estados.
Por exemplo, um fluxo de trabalho pode começar acionando uma tarefa de coleta de dados, continuar com o Parsing e a validação dos dados e, em seguida, armazenar os resultados em serviços como o Amazon S3 ou um banco de dados. O Step Functions pode coordenar essas etapas enquanto se integra a outros serviços da AWS, como AWS Lambda, AWS Glue ou Amazon SQS.
Essa abordagem traz vários benefícios: escalabilidade aprimorada, repetição e tratamento de erros integrados, processamento paralelo de tarefas de scraping e monitoramento claro de cada execução do fluxo de trabalho.
No entanto, o Scraping de dados em grande escala também apresenta desafios. O motivo é que muitos sites implementam proteções anti-bot e mecanismos anti-scraping que podem bloquear solicitações automatizadas. Exemplos incluem limitadores de taxa, impressões digitais, CAPTCHAs, desafios JavaScript e muito mais.
Recuperação perfeita de dados da web no AWS Step Functions
Para equipes que orquestram fluxos de trabalho de Scraping de dados da web com AWS Step Functions, a Bright Data oferece uma solução abrangente para apoiar a recuperação bem-sucedida de dados da web em grande escala.
A Bright Data vem com vários serviços especializados de scraping que se integram perfeitamente ao Step Functions:
- API SERP: reúna resultados de mecanismos de pesquisa em escala para insights de SEO ou análise de mercado.
- Web Unlocker: acesse qualquer página da web contornando defesas anti-bot, como CAPTCHAs, obstáculos JavaScript e restrições de IP.
- API de Scraping de dados: recupere informações estruturadas de plataformas de comércio eletrônico, redes sociais e outras fontes da web com configuração mínima.
- Crawl API: automatize a extração de conteúdo completo de sites de qualquer domínio para Markdown, texto simples, HTML ou JSON.
Essas soluções utilizam uma rede Proxy com mais de 150 milhões de IPs em mais de 195 países, oferecendo simultaneidade ilimitada para casos de uso prontos para produção. Além disso, todos os serviços incorporam o kit de ferramentas antibot da Bright Data para evitar CAPTCHAs e outras restrições de acesso.
A integração da orquestração do Step Functions com as ferramentas de dados da web da Bright Data permite pipelines totalmente automatizados que gerenciam a extração, transformação e armazenamento. Isso significa operação contínua, mesmo em cenários complexos, em grande escala e prontos para uso corporativo.
Como integrar as soluções de Scraping de dados da Bright Data ao AWS Step Functions
Para integrar a Bright Data ao AWS Step Functions para recuperação automatizada de dados da web, há duas abordagens possíveis:
- Use o nó “HTTP Endpoint – Call HTTPS APIs”: conecte-se diretamente às APIs da Bright Data (Web Unlocker API, APIs de Scraping de dados, API SERP, Crawl API, etc.).
- Confie no nó “AWS Lambda – Invoke”: crie um código personalizado em uma função Lambda (em Python ou outra linguagem suportada) para integrar com os produtos Bright Data, recuperar dados e, opcionalmente, aplicar uma lógica específica (por exemplo, acessar apenas campos específicos, retornar dados em uma estrutura específica ou aplicar uma lógica de Parsing personalizada).
Nas seções abaixo, vamos guiá-lo por ambas as abordagens. Mas primeiro, vamos explorar os prós e contras dos dois métodos.
Ponto final HTTP – Chamar APIs HTTPS Nó: Prós e contras
👍 Prós:
- Rápido de configurar.
- Mais fácil de gerenciar e manter.
- Funciona bem para extrair dados de páginas da web únicas.
👎 Contras:
- Flexibilidade limitada para processamento personalizado de dados.
- Mais difícil de lidar com fluxos de trabalho complexos que exigem várias chamadas diferentes da API de extração da Bright Data.
AWS Lambda – Invoke Node: Prós e contras
👍 Prós:
- Controle total sobre o processamento e a transformação de dados da web.
- Permite implementar lógica personalizada (por exemplo, novas tentativas, fluxos condicionais, etc.).
- Possibilidade de integração com vários serviços da Bright Data em uma única função.
👎 Contras:
- Requer codificação em Python, Node.js ou outra linguagem compatível.
- Adiciona um serviço extra para monitorar e manter.
Pré-requisitos
Para acompanhar as seções guiadas a seguir, você precisa de:
- Uma conta AWS ativa (mesmo uma versão de avaliação gratuita funciona).
- Uma conta Bright Data com uma chave API pronta.
- Conhecimento básico de chamadas HTTP RESTful ou habilidades básicas de programação Python para a integração Lambda.
Configure sua conta Bright Data
Se você ainda não tem uma conta Bright Data, crie uma primeiro. Caso contrário, faça login e siga as instruções para configurar uma chave API. Você precisará dessa chave para autenticar suas chamadas HTTP (seja chamando a Bright Data diretamente de chamadas HTTP ou em uma função Lambda).
Certifique-se de ter uma API Bright Data Web Unlocker configurada (e uma API SERP se você planeja seguir a seção do tutorial Lambda):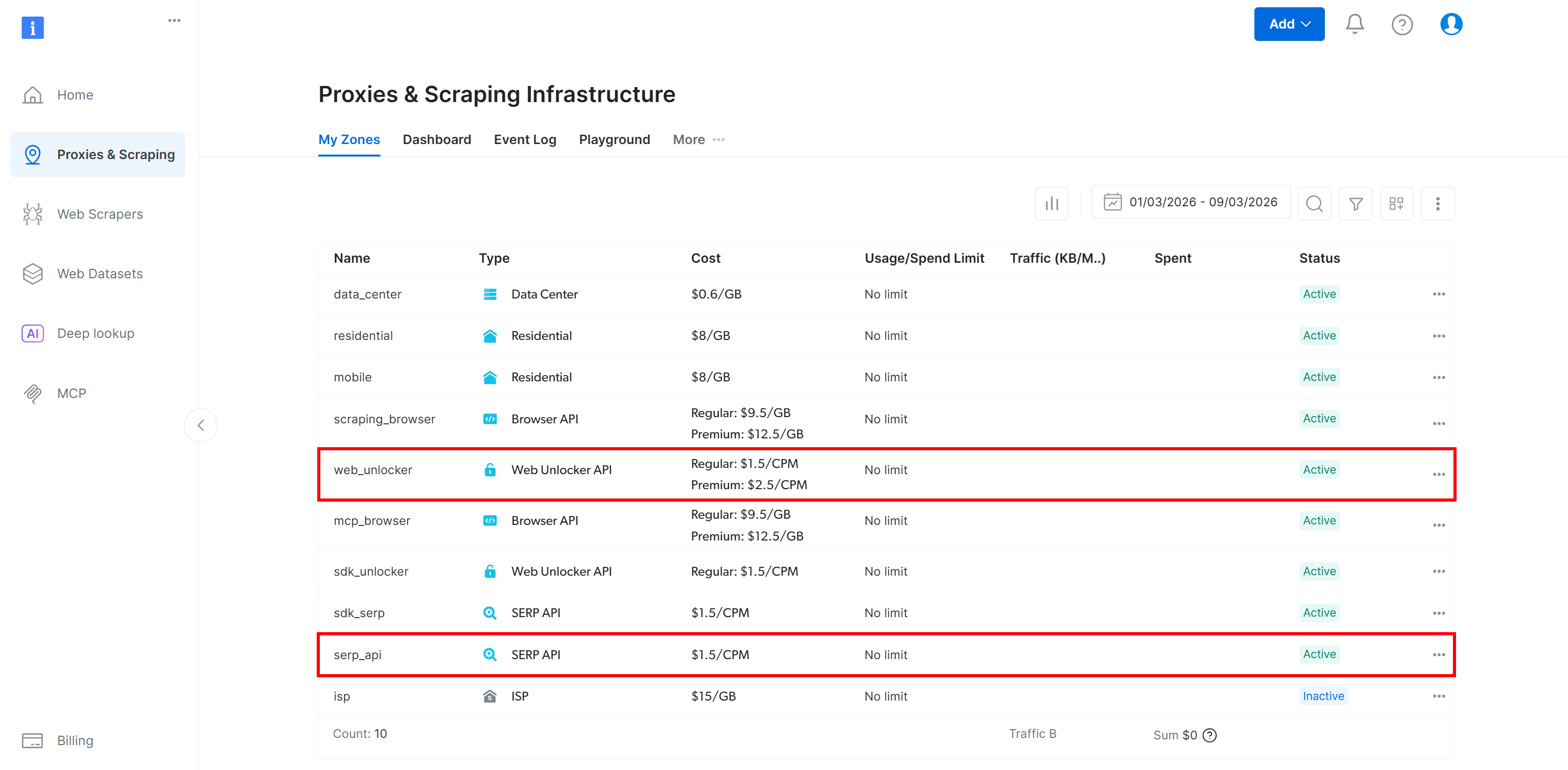
Para obter mais informações, consulte as seguintes páginas da documentação:
Configure seu fluxo de trabalho AWS Step Functions
Comece fazendo login no seu console AWS e procurando o serviço “Step Functions”. Abra a página do serviço: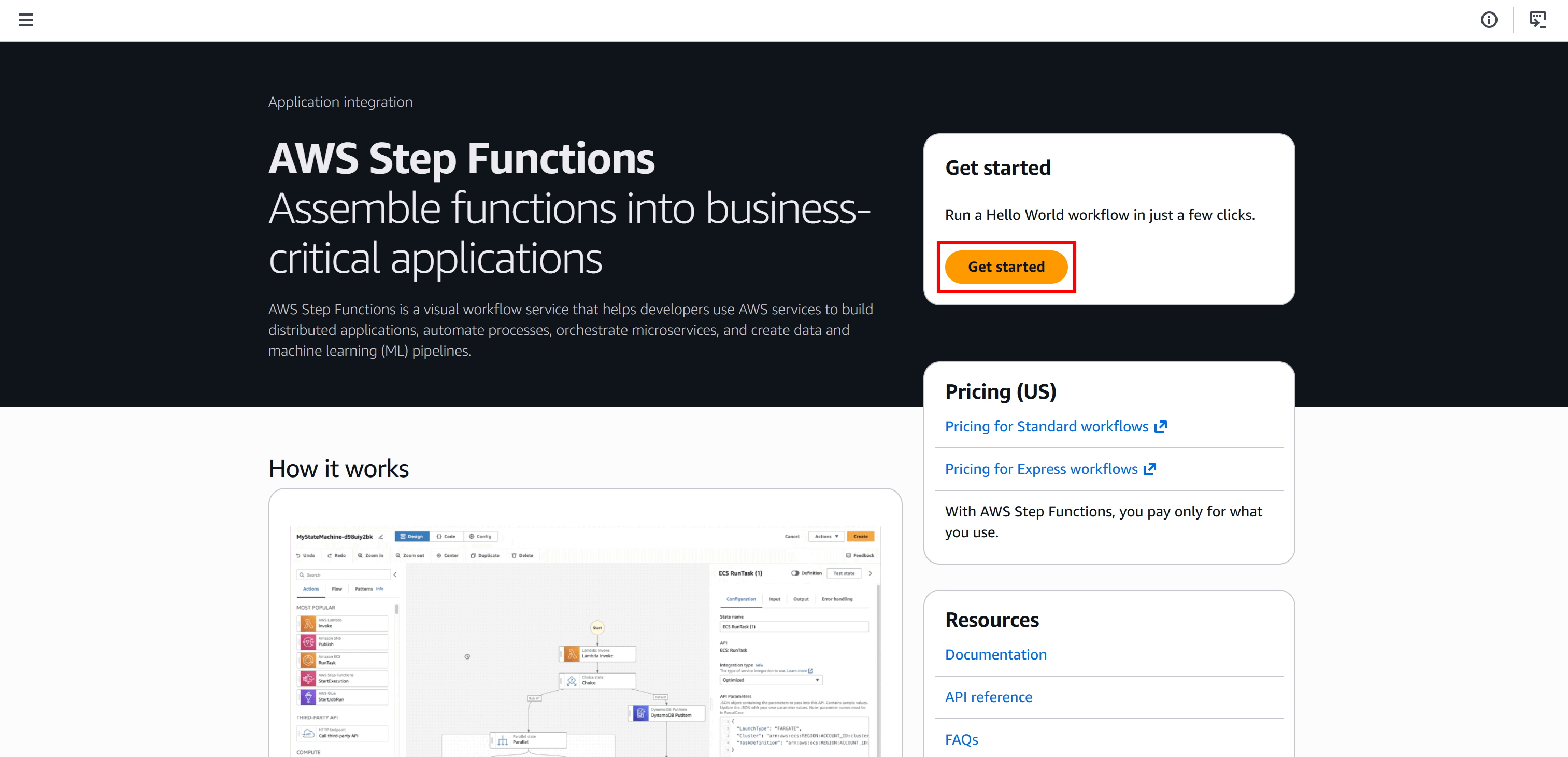
Aqui, clique no botão “Começar” e selecione “Criar o seu próprio” para começar a construir um fluxo de trabalho sem servidor a partir do zero: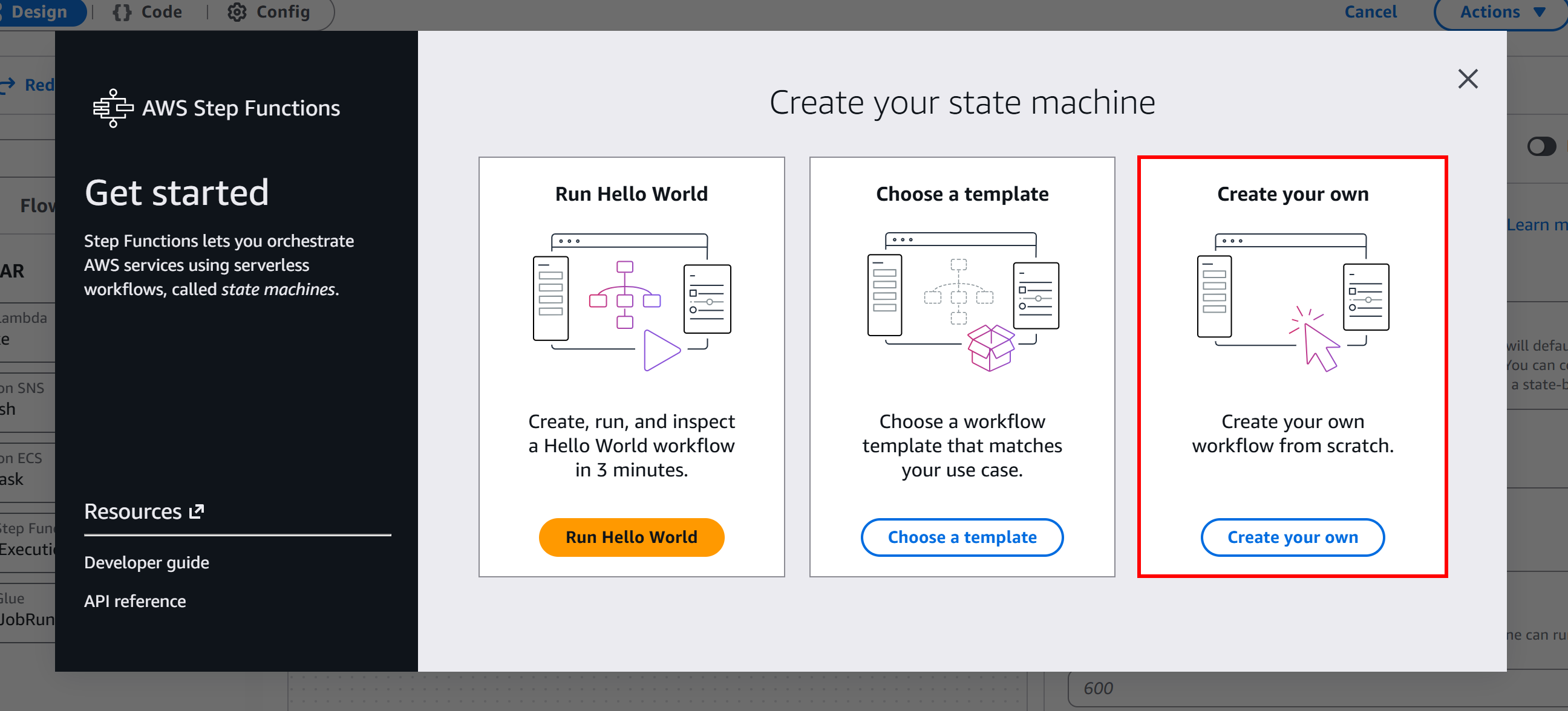
Dê um nome à sua máquina de estados (por exemplo, “BrightDataWebScrapingMachine”) e escolha o tipo de máquina de estados que deseja criar. Neste tutorial, usaremos uma máquina “Standard”: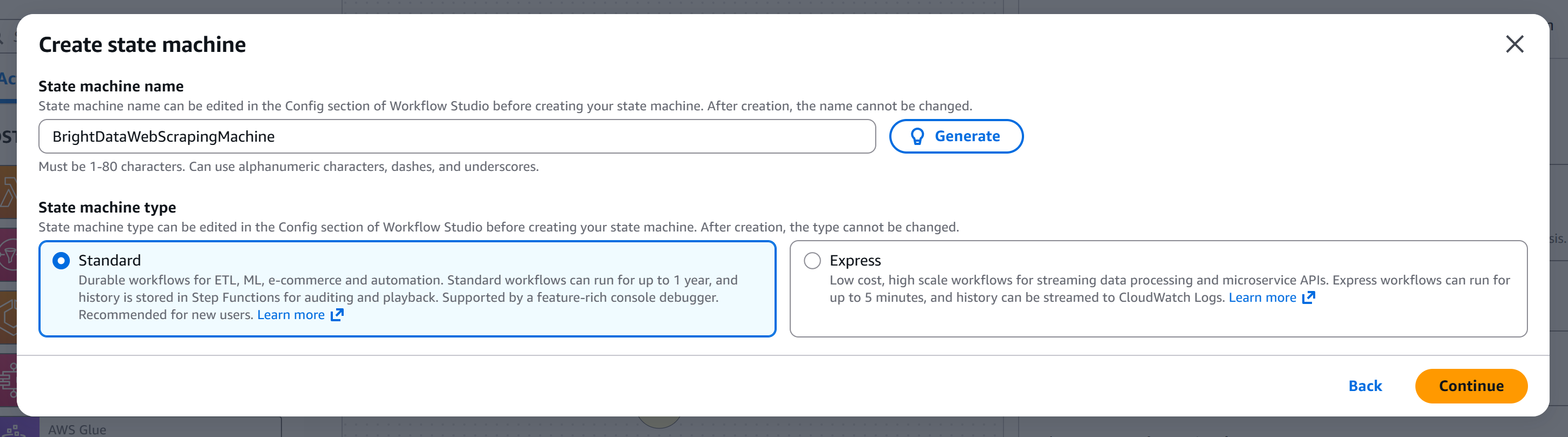
Clique em “Continuar” para acessar a página do editor de fluxo de trabalho: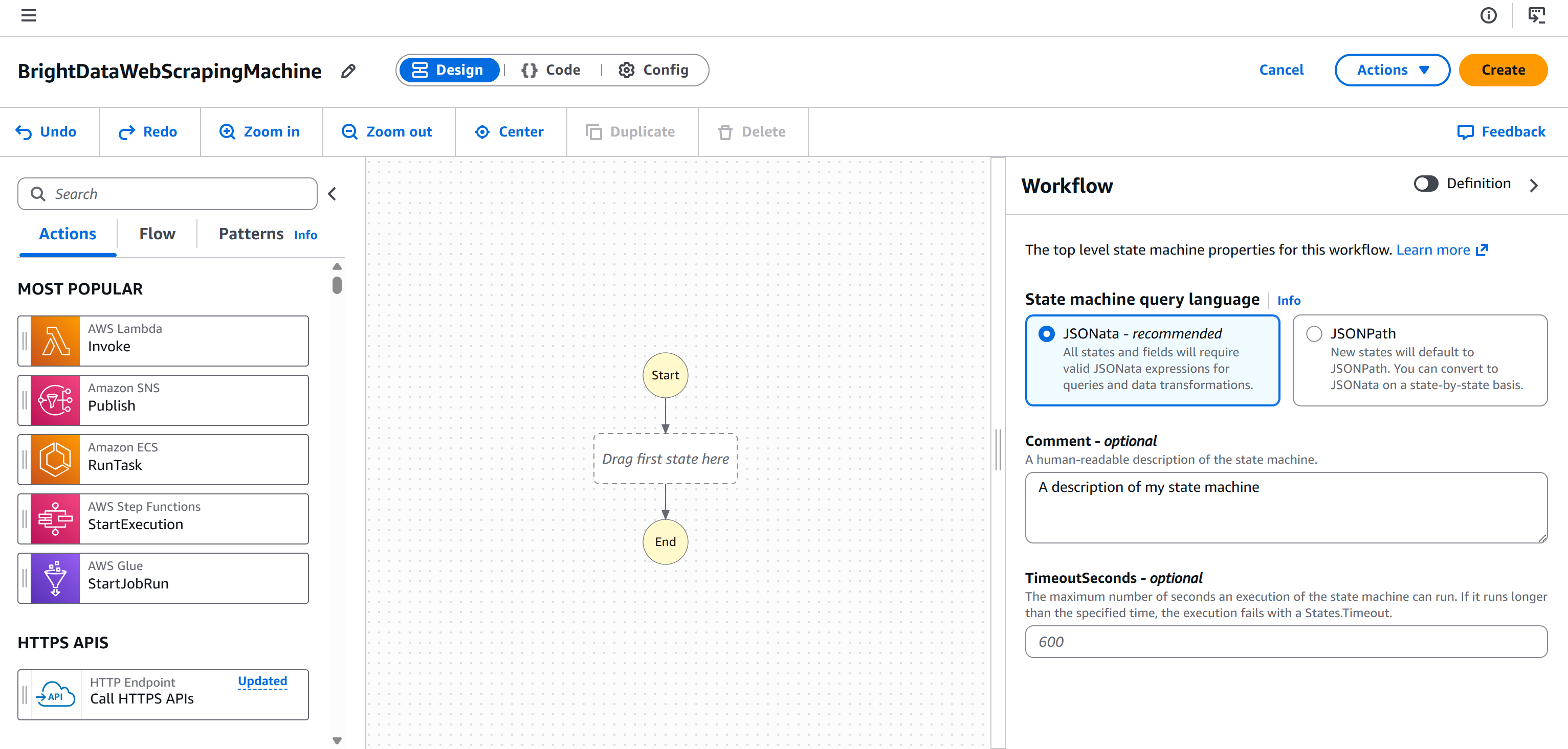
Agora você está totalmente configurado e pronto para adicionar um nó de Scraping de dados da Bright Data ao seu fluxo de trabalho do AWS Step Functions.
Abordagem nº 1: use o nó “Chamar APIs HTTPS”
Aqui, você aprenderá como definir um nó que se conecta diretamente às APIs do Bright Data Web Unlocker por meio de uma chamada HTTP. Esse nó permite que você extraia dados de qualquer página da web de forma programática. Em particular, vamos configurá-lo para recuperar dados no formato Markdown, que é ideal para ingestão de LLM.
Observação: um procedimento muito semelhante pode ser aplicado para se conectar a qualquer outro produto Bright Data baseado em API.
Etapa #1: Adicione um nó “Endpoint HTTP – Chamar APIs HTTPS”
Comece selecionando o nó “Ponto final HTTP – Chamar APIs HTTPS” no painel esquerdo e arrastando-o para a seção “Arraste o primeiro estado aqui”: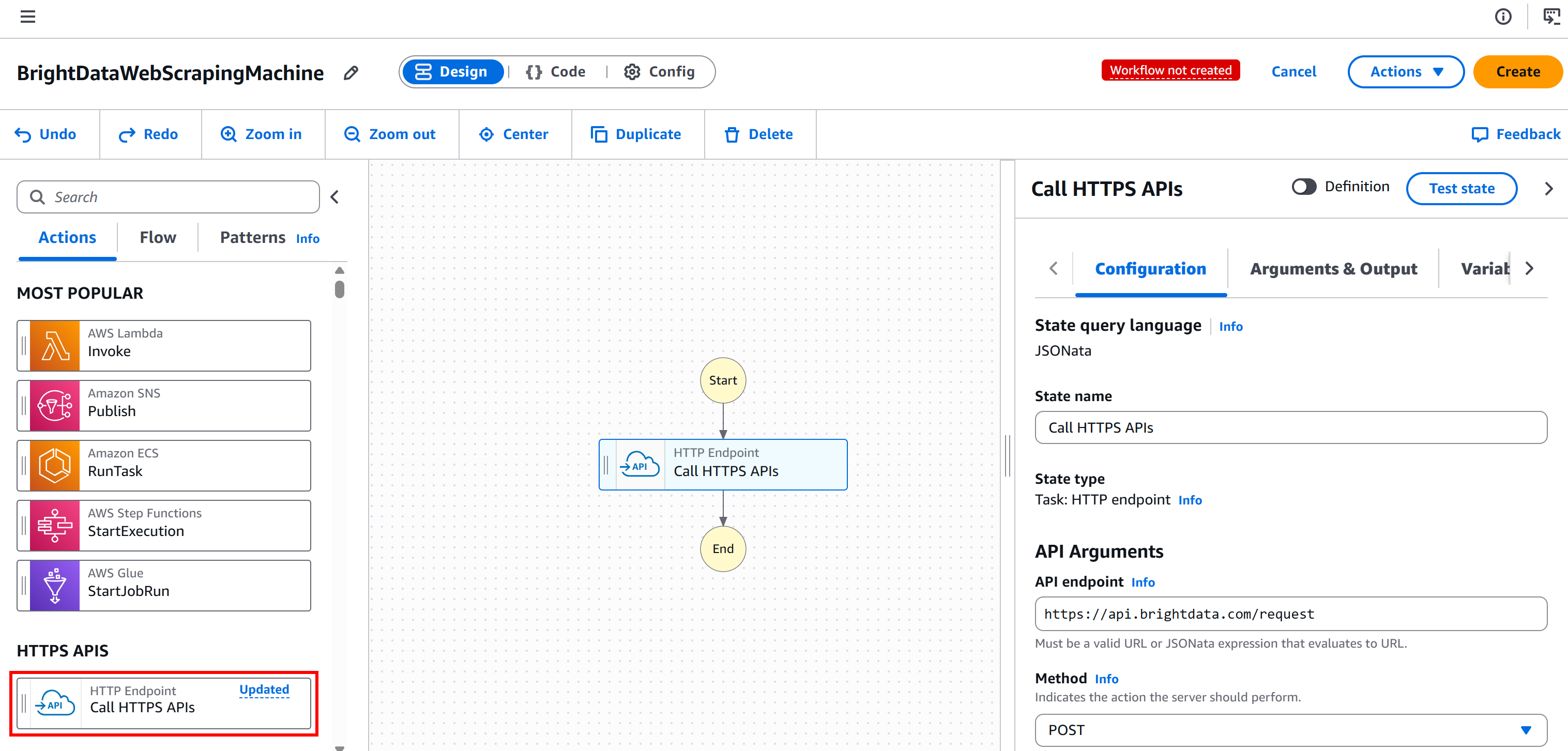
Selecione o nó e, na guia “Configuração” à direita:
- Dê um nome ao seu estado.
- Defina o “API endpoint” como
https://api.brightdata.com/request. - Defina o “Método” como
POST.
Isso configura o nó para se conectar ao endpoint POST https://api.brightdata.com/request, que é a API Bright Data básica para os serviços Web Unlocker e API SERP: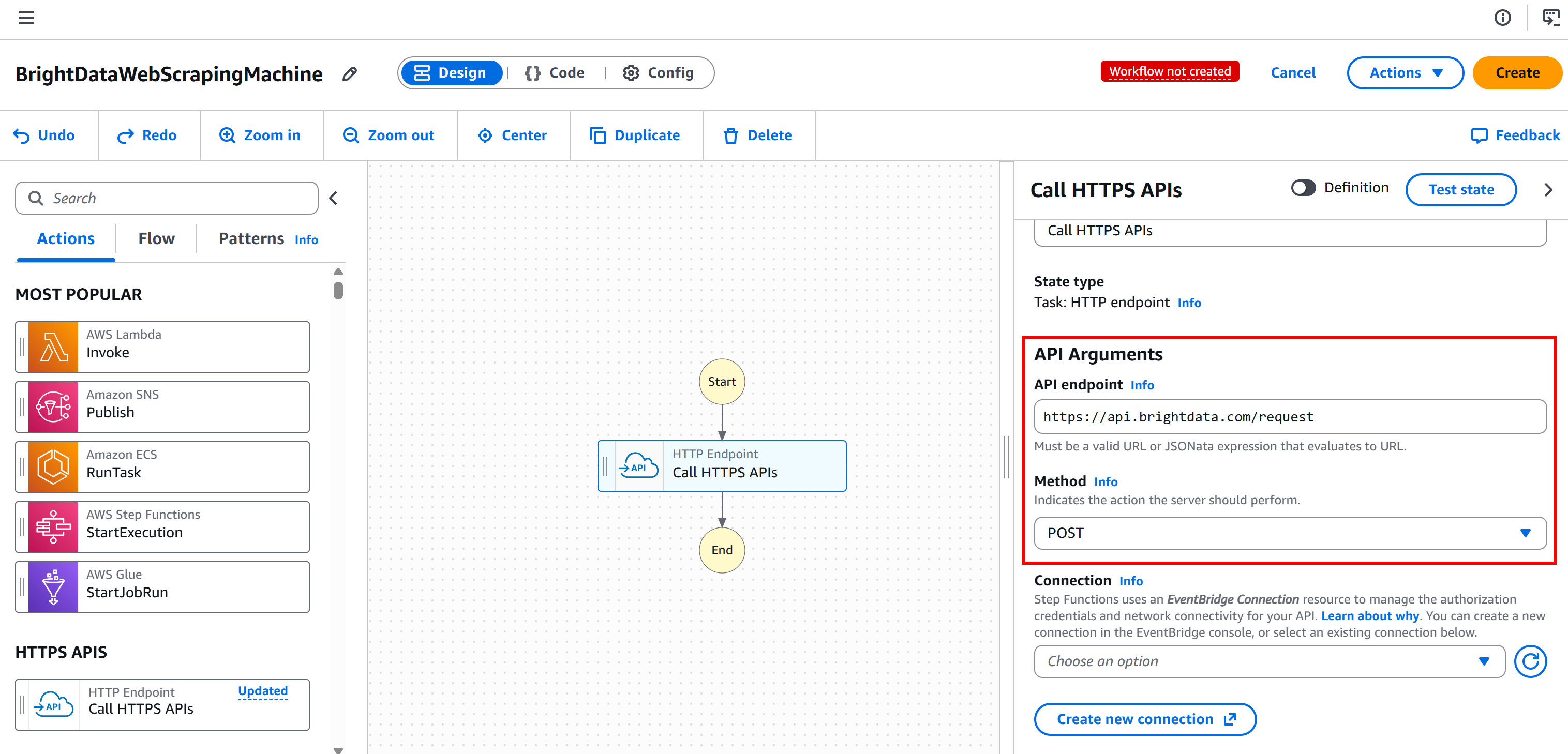
Etapa 2: Configure a autenticação da API
As APIs da Bright Data são autenticadas usando sua chave API da Bright Data. Especificamente, você deve incluí-la no cabeçalho de autorização no seguinte formato:
Bearer <BRIGHT_DATA_API_KEY>Para evitar codificar sua chave API no nó, você precisa criar uma nova conexão via Amazon EventBridge. Para fazer isso, pressione o botão “Criar nova conexão” na seção “Conexão” na guia “Configuração”:
Dê um nome à sua conexão (por exemplo, brightdata-api) e defina-a como “Pública” (já que as chaves API da Bright Data são expostas publicamente).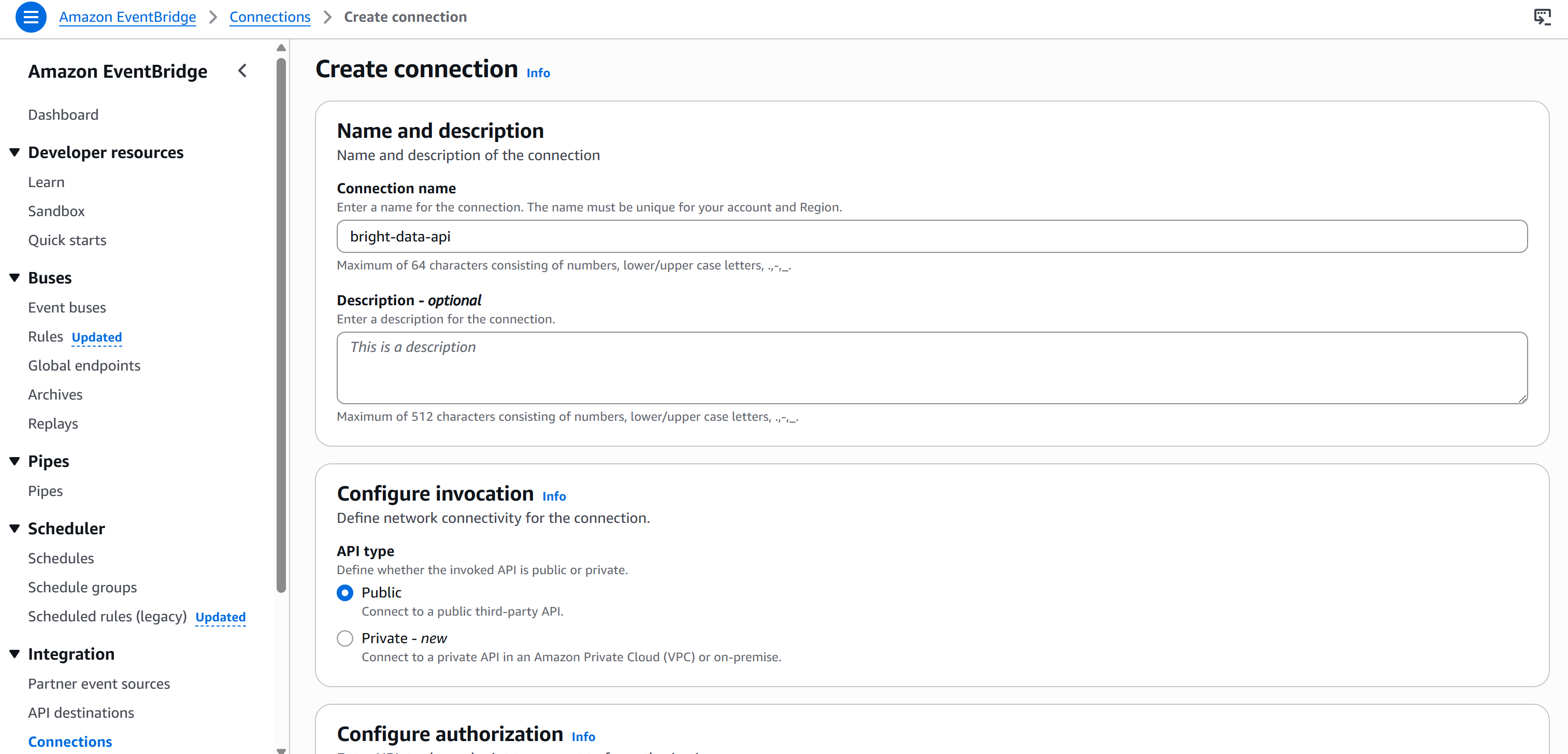
Em seguida, selecione o tipo de autenticação “Chave API” e configure-a assim:
- Nome da chave API:
Autorização(deve corresponder ao nome do cabeçalho HTTP usado para autenticação). - Valor:
Portador <BRIGHT_DATA_API_KEY>(substitua o espaço reservado<BRIGHT_DATA_API_KEY>pela sua chave API real).
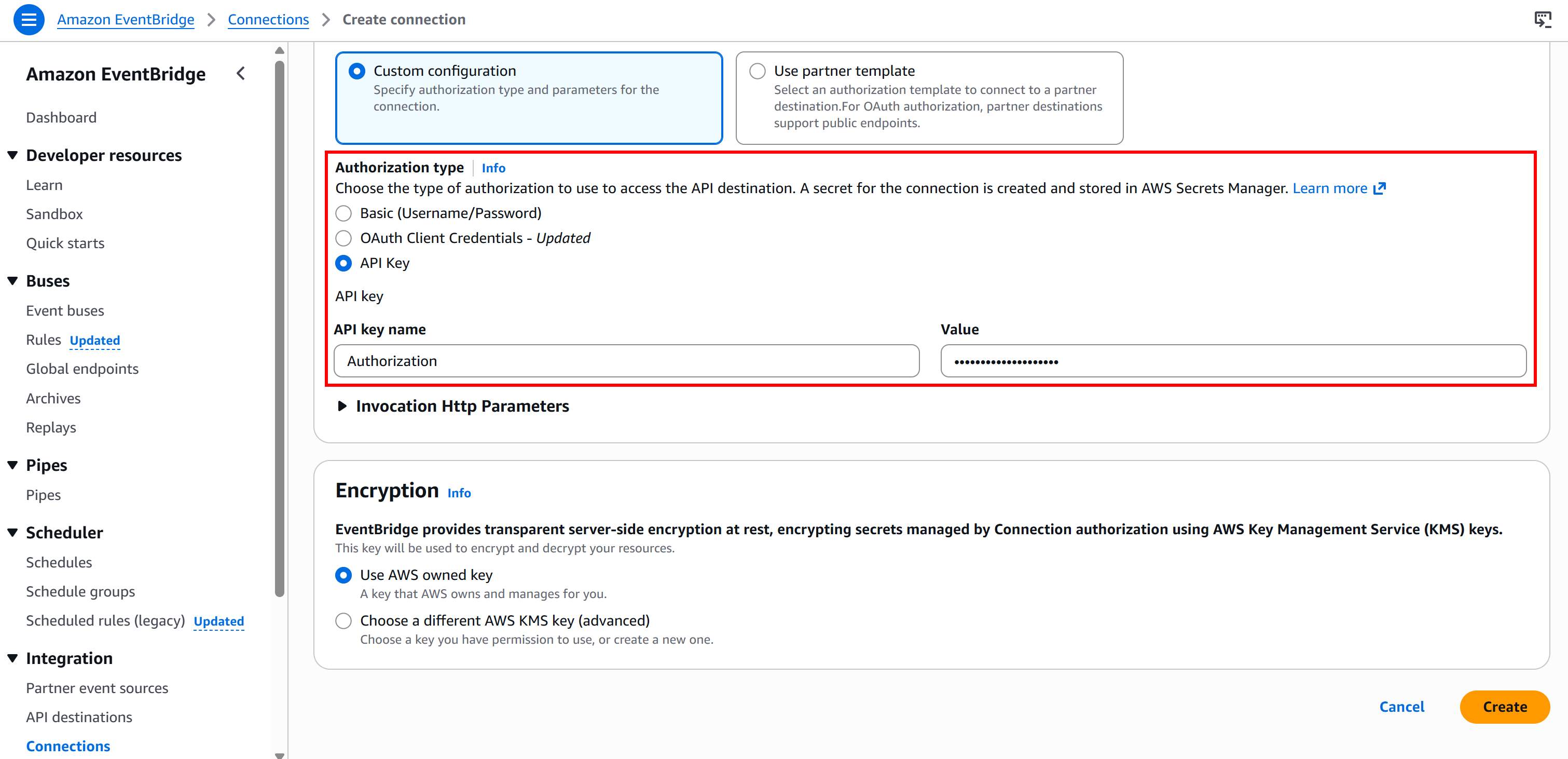
Por fim, pressione “Criar” para configurar a conexão do EventBridge. Após a criação, você deverá ver: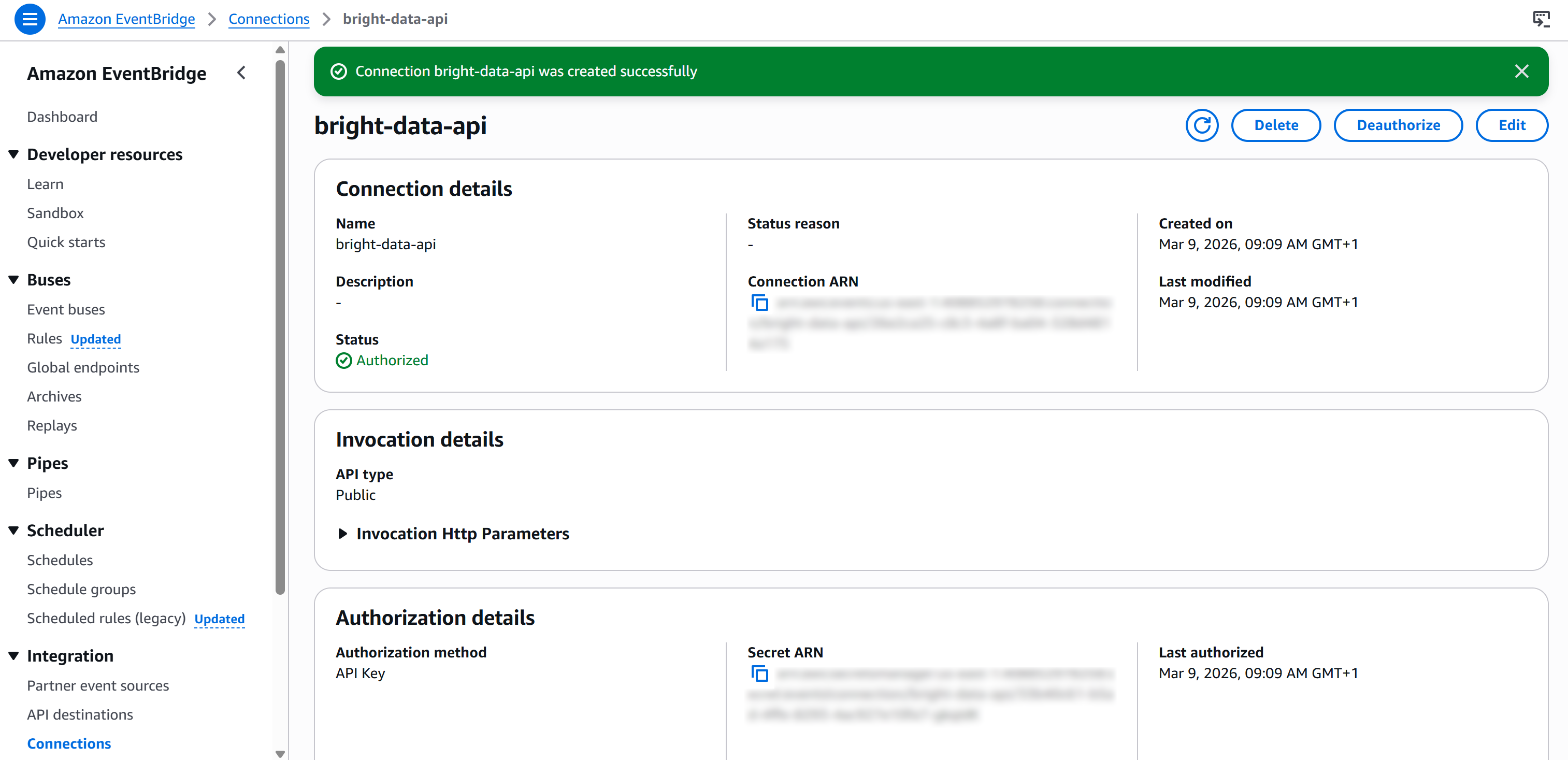
Etapa 3: Conclua a configuração da API
De volta à página do editor de fluxo de trabalho, selecione o nó “HTTP Endpoint – Call HTTPS APIs” e vá para a guia “Configuração”. Em seguida, selecione a conexão que você acabou de criar (bright-data-api):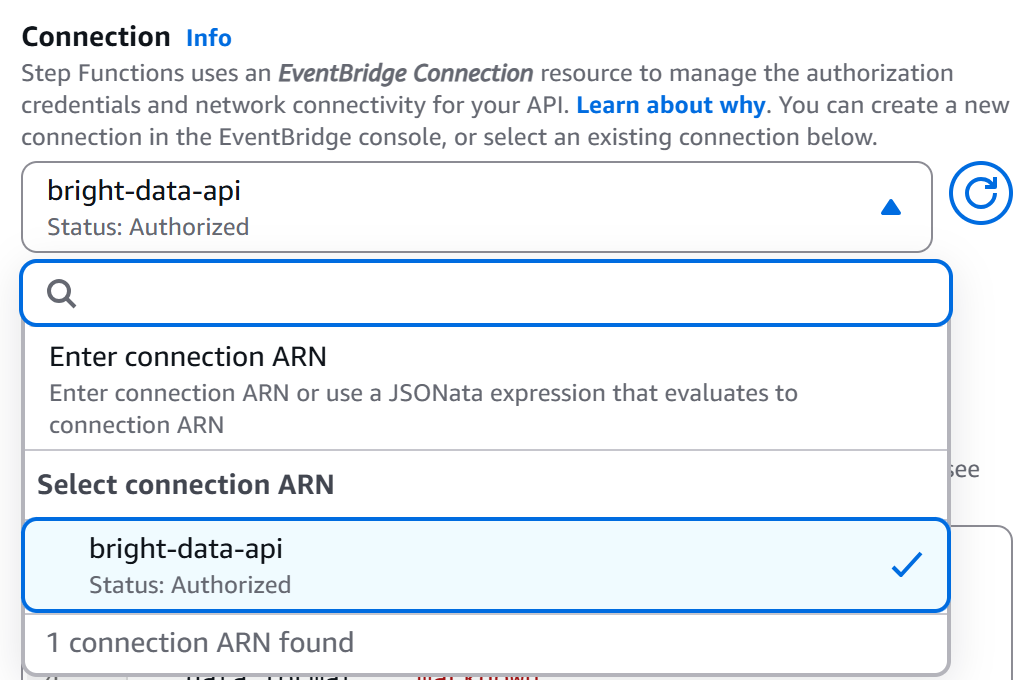
Dessa forma, a chave da API Bright Data será adicionada ao cabeçalho de autorização para autenticação (no formato necessário).
Em seguida, defina o corpo HTTP da seguinte forma:
{
"zona": "<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONA_NAME>",
"url": "{% $states.input.url %}",
"format": "raw",
"data_format": "markdown"
}Substitua o espaço reservado <YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE_NAME> pelo nome da sua zona Web Unlocker da sua conta Bright Data. O campo url será lido dinamicamente a partir da entrada do fluxo de trabalho (graças à sintaxe {% $states.input.url %} ), permitindo que você extraia diferentes páginas sem codificar a URL. Em vez disso, data_format: "markdown" garante que a resposta da API seja retornada no formato Markdown pronto para IA.
Em nosso exemplo, a zona Web Unlocker é chamada de "``web_unlocker``", então o corpo fica assim: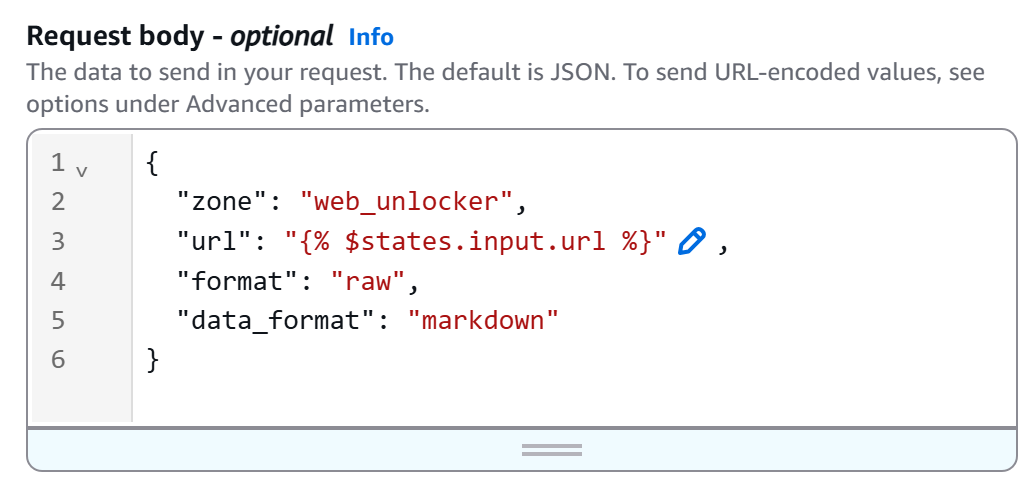
Agora, seu fluxo de trabalho ficará assim: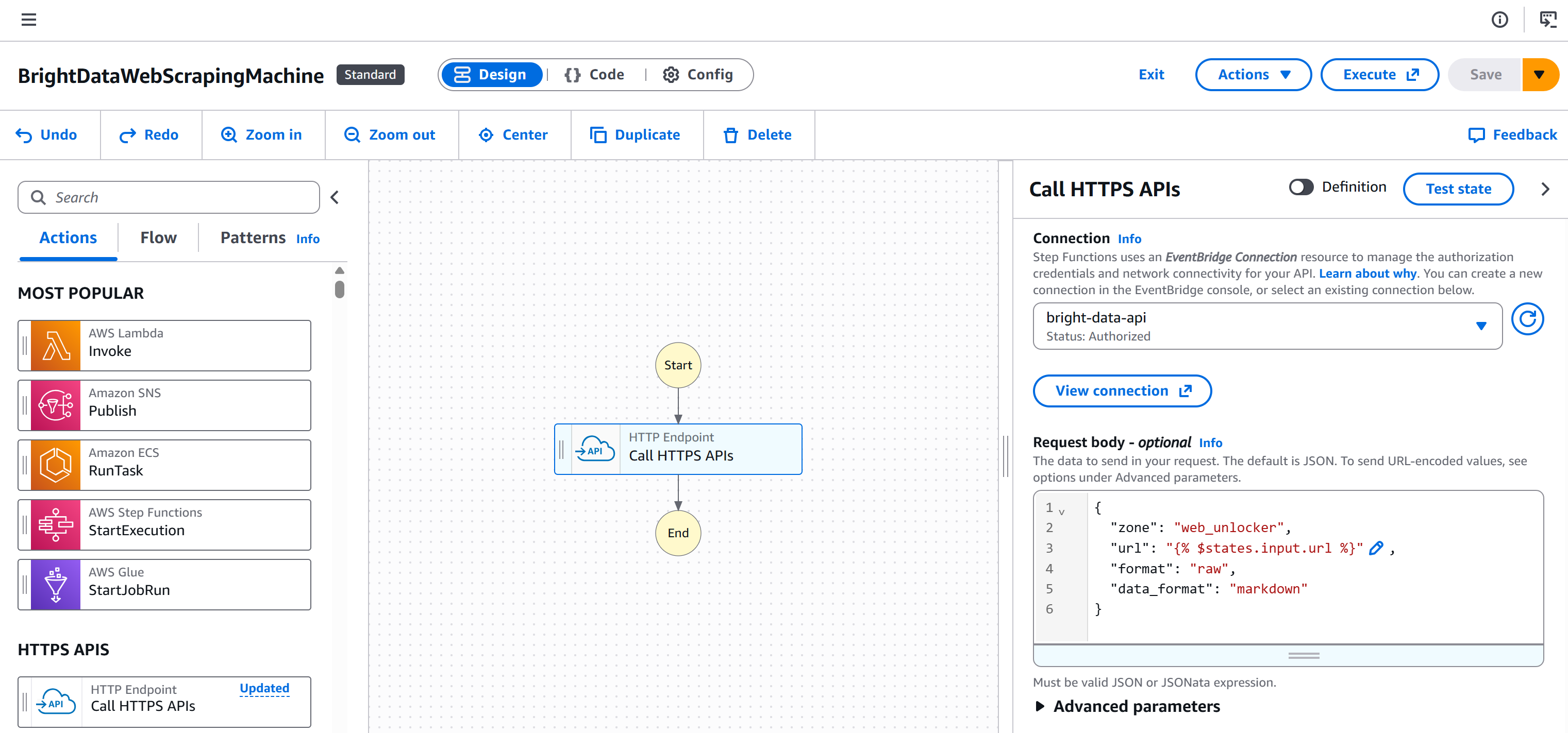
Fantástico! A configuração está concluída. Tudo o que resta é testar a integração do Bright Data no seu fluxo de trabalho do AWS Step Functions.
Etapa 4: teste o nó de Scraping de dados com tecnologia Bright Data
Comece pressionando o botão “Criar” para gerar a função IAM necessária e todos os outros elementos necessários no seu console AWS para teste:
Em seguida, pressione o botão “Testar estado” no seu nó:
Você chegará ao modal “Testar estado”: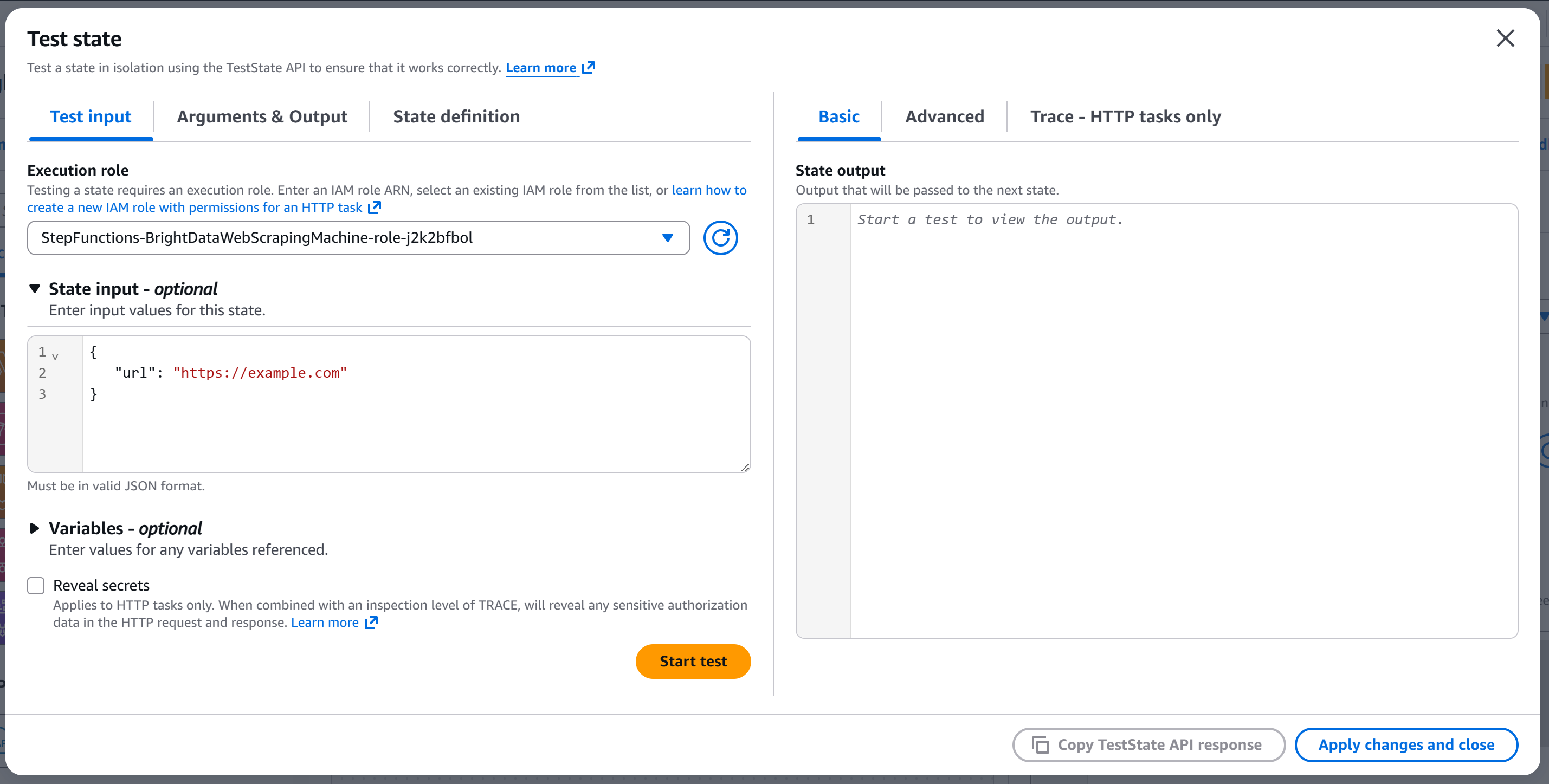
Configure a entrada de estado com algo como:
{
“url”: “https://example.com”
}O campo url será passado para o corpo da API (porque o nó foi configurado para ler o campo url body da entrada).
Pressione “Iniciar teste” para executar o nó. Você deverá ver uma saída semelhante a esta: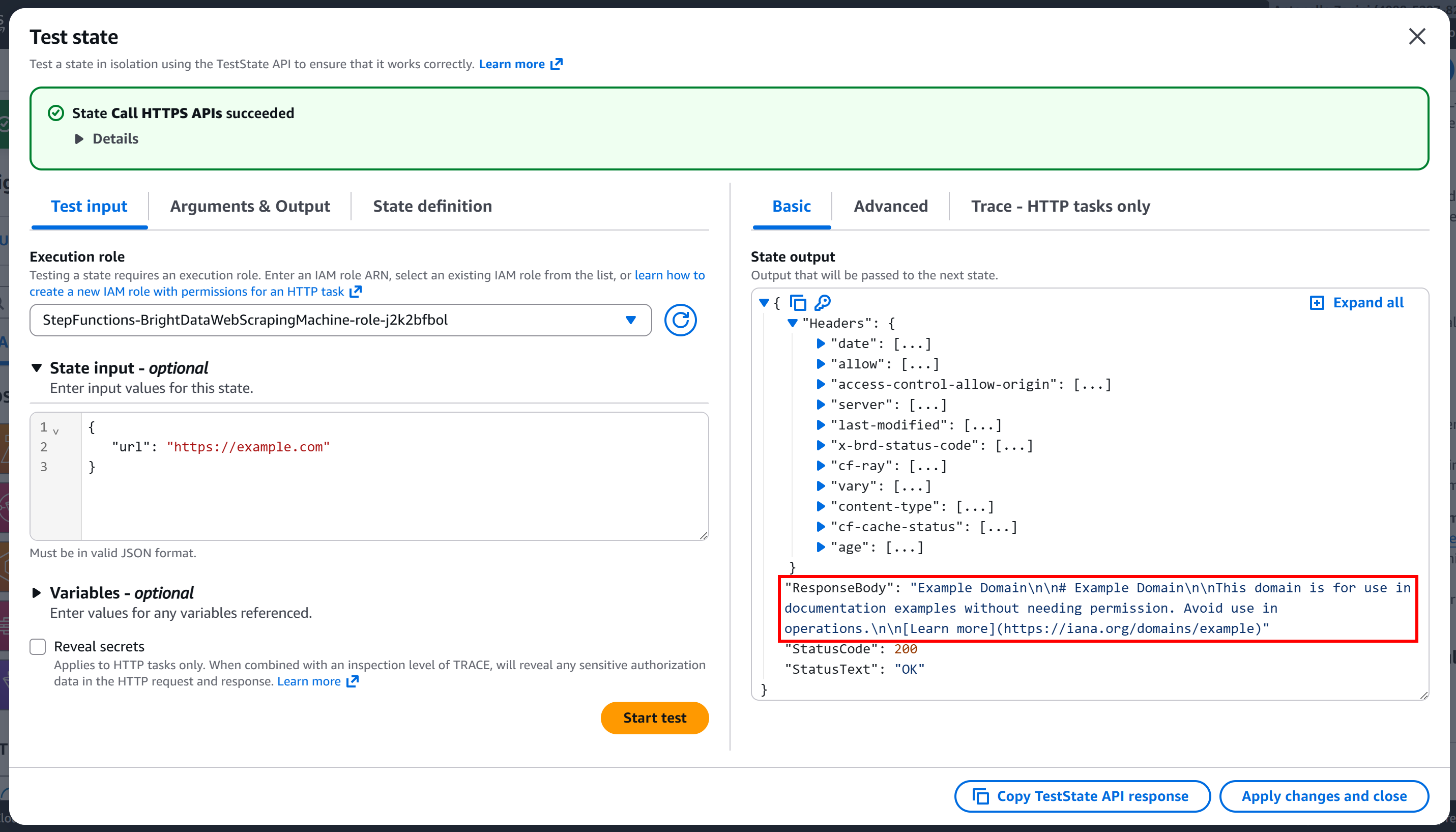
Como você pode ver, a solicitação foi bem-sucedida e o corpo da resposta contém a versão Markdown da página de destino: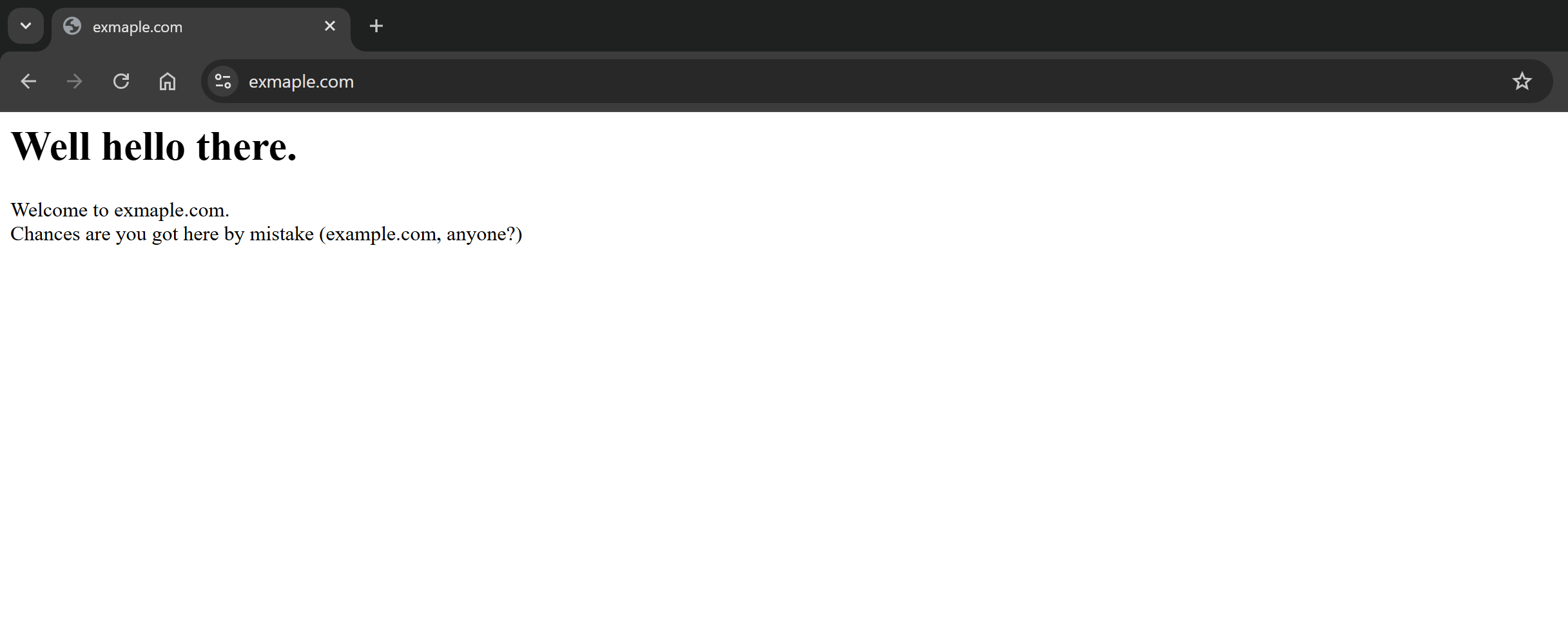
Et voilà! Sua integração do Bright Data no AWS Step Functions agora está totalmente funcionando e pronta para uso em produção.
Abordagem nº 2: use uma função Lambda
Nesta seção, você entenderá como se conectar aos serviços Bright Data por meio de uma função AWS Lambda personalizada.
Para simplificar a integração e acelerar o processo, você pode seguir as etapas 5, 6 e 7 do artigo “Dê aos agentes AWS Bedrock a capacidade de pesquisar na web através da API SERP da Bright Data”. Essas etapas orientam você na criação de uma função Lambda em Python que se conecta à API SERP da Bright Data.
Abaixo, você verá como integrar essa função Lambda ao seu fluxo de trabalho de Scraping de dados por meio do AWS Step Functions!
Etapa 1: adicione um nó “AWS Lambda – Invoke”
Comece selecionando o nó “AWS Lambda – Invoke” no painel esquerdo. Em seguida, arraste-o para a seção “Arraste o primeiro estado aqui” do seu fluxo de trabalho.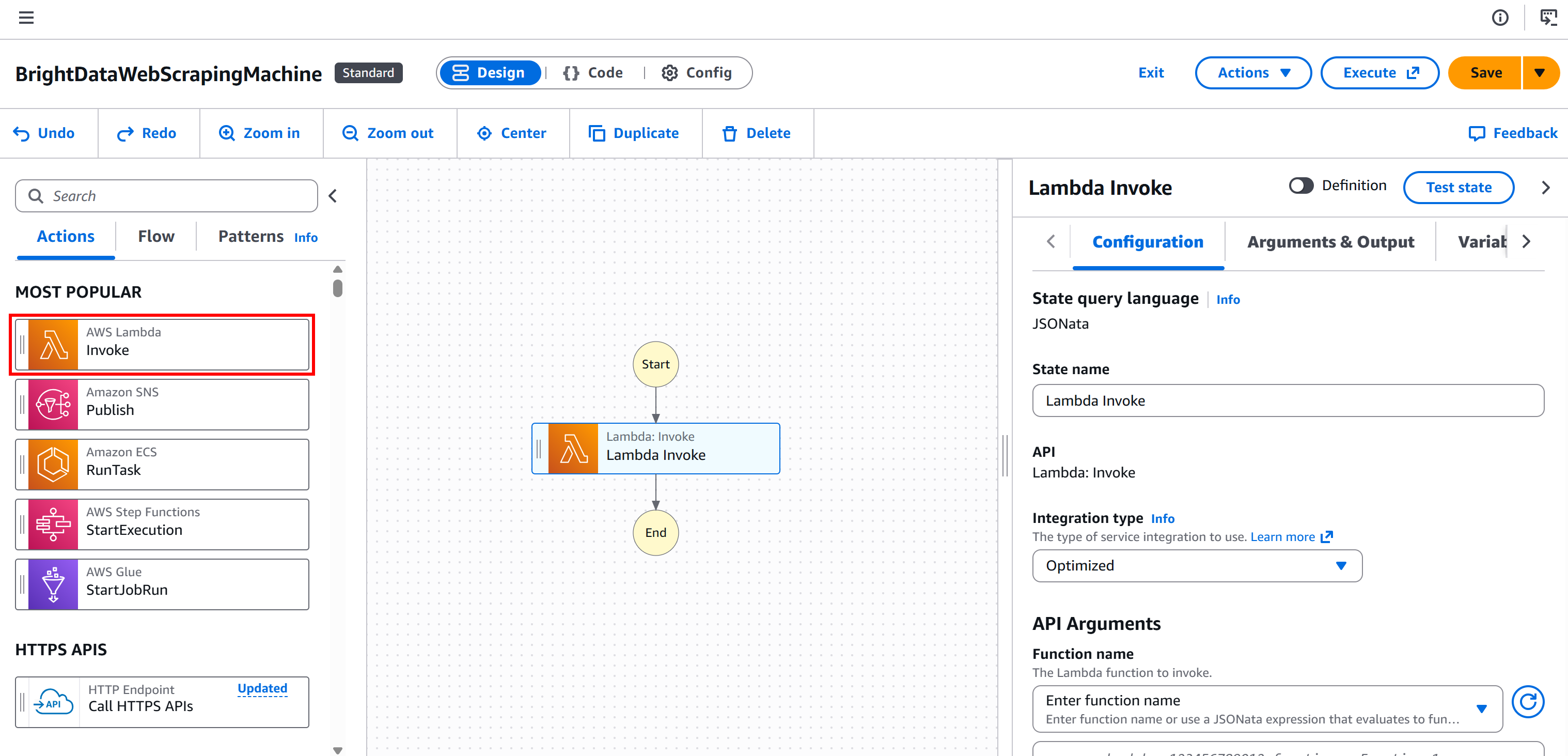
Etapa 2: Configure a função Lambda
Na seção “Configuração” do nó “AWS Lambda – Invoke”, no bloco “Argumentos da API – Nome da função”, selecione a função Lambda que deseja invocar: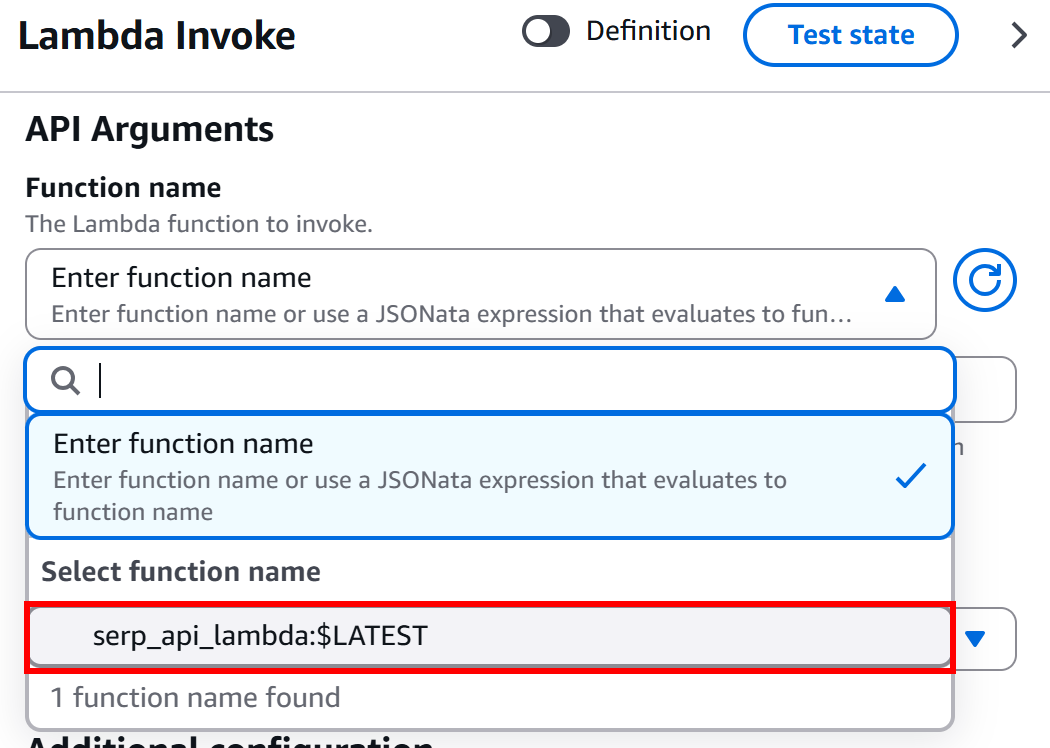
Neste exemplo, a função é serp_api_lambda, que foi criada conforme explicado anteriormente na introdução deste capítulo. Essa função se integra à API SERP da Bright Data.
Ótimo! Agora você tem uma função Lambda com tecnologia Bright Data para scraping SERP integrada ao seu fluxo de trabalho AWS Step Functions.
Conclusão
Neste guia, você aprendeu o que é o AWS Step Functions e por que ele é ideal para orquestrar fluxos de trabalho automatizados de Scraping de dados.
Você viu como o Step Functions simplifica o gerenciamento do fluxo de trabalho com máquinas de estado, execução paralela, novas tentativas e suporte human-in-the-loop. Você explorou como a Bright Data aprimora esse processo por meio das integrações Web Unlocker e API SERP, superando medidas anti-bot e garantindo a recuperação ininterrupta de dados da web em nível empresarial.
Ao integrar a Bright Data ao Step Functions, você pode criar pipelines completos que lidam com a coleta, validação e armazenamento de dados no S3 ou em outros serviços da AWS, mantendo a escalabilidade, a resiliência e o monitoramento.
Cadastre-se hoje mesmo para obter uma conta Bright Data e teste nossas soluções de dados da web gratuitamente!




