

Neste artigo, você verá:
- O que é o CloakBrowser, o que ele oferece e como funciona.
- O que é a Browser API da Bright Data, quais recursos ela oferece e os benefícios de infraestrutura que acompanham a solução.
- Como as duas soluções abordam a navegação stealth e o gerenciamento de fingerprint.
- Os diferentes modelos de infraestrutura em que as duas ferramentas se baseiam.
- As integrações e ferramentas compatíveis que tanto o CloakBrowser quanto a Browser API suportam.
- Uma tabela comparativa final entre CloakBrowser e Bright Data Browser API para uma visão rápida.
Vamos começar!
Visão Geral do CloakBrowser
Antes de mergulhar na comparação entre CloakBrowser e Bright Data Browser API, entenda o que o CloakBrowser tem a oferecer.
O Que É o CloakBrowser?

CloakBrowser é um navegador stealth de código aberto desenvolvido sobre um binário Chromium personalizado. Ele funciona como uma solução de automação de navegador e scraping de dados.
Ao contrário dos plugins stealth tradicionais que dependem de injeções de JavaScript, patches de navegador ou ajustes de configuração, o CloakBrowser modifica os fingerprints do navegador diretamente no nível do código-fonte C++ do Chromium. Essa abordagem visa produzir um comportamento de navegador mais consistente e realista.
Essa ferramenta funciona como um substituto direto para o Playwright e o Puppeteer. Inclui gerenciamento integrado de fingerprint, simulação de interação humana, suporte a Proxy, perfis de navegador persistentes e integrações com agentes de IA e frameworks de automação.
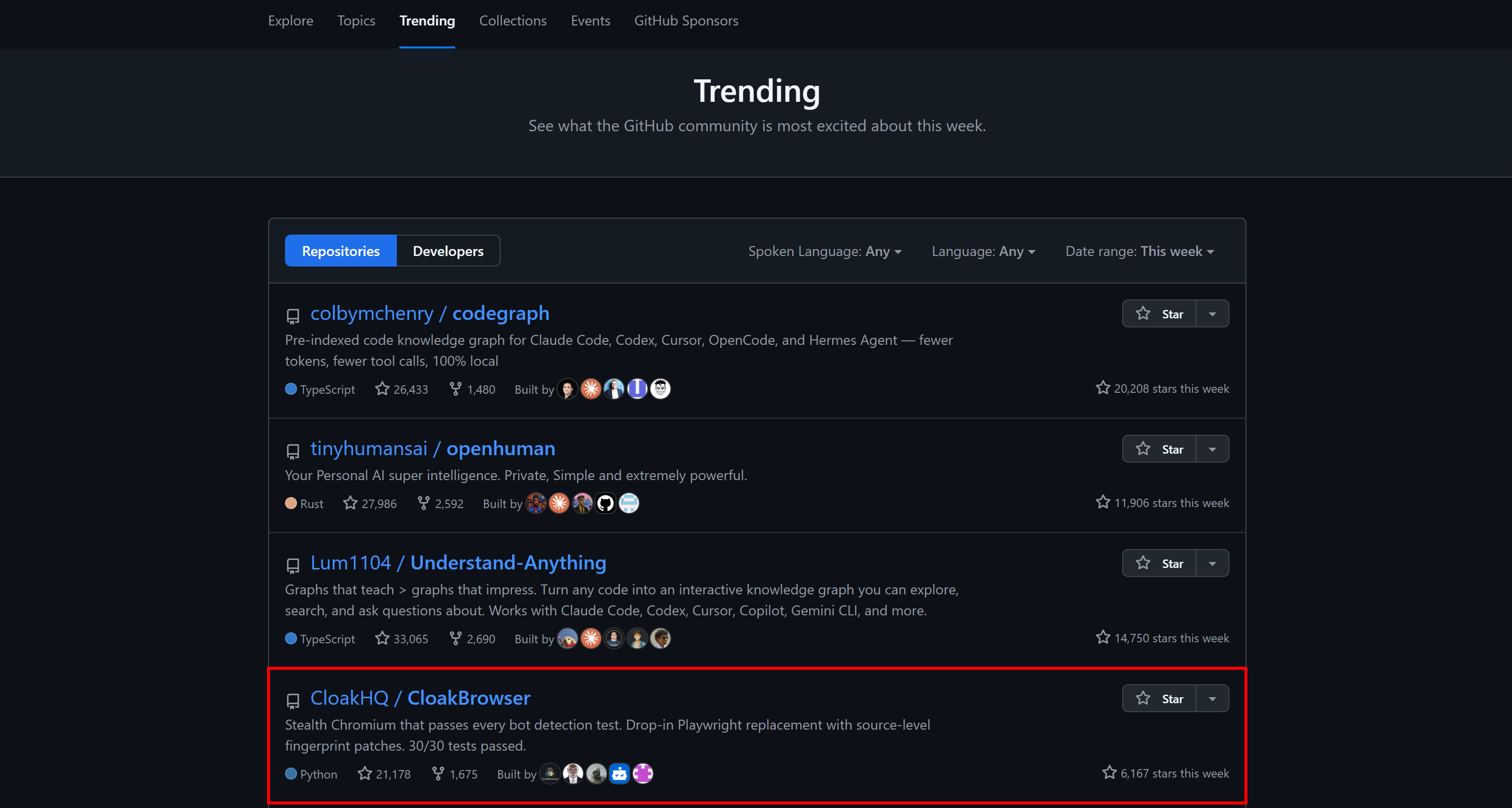
Nas últimas semanas, o projeto ganhou tração significativa. Cresceu de alguns milhares de estrelas no GitHub para mais de 21,2 mil estrelas no momento da escrita.
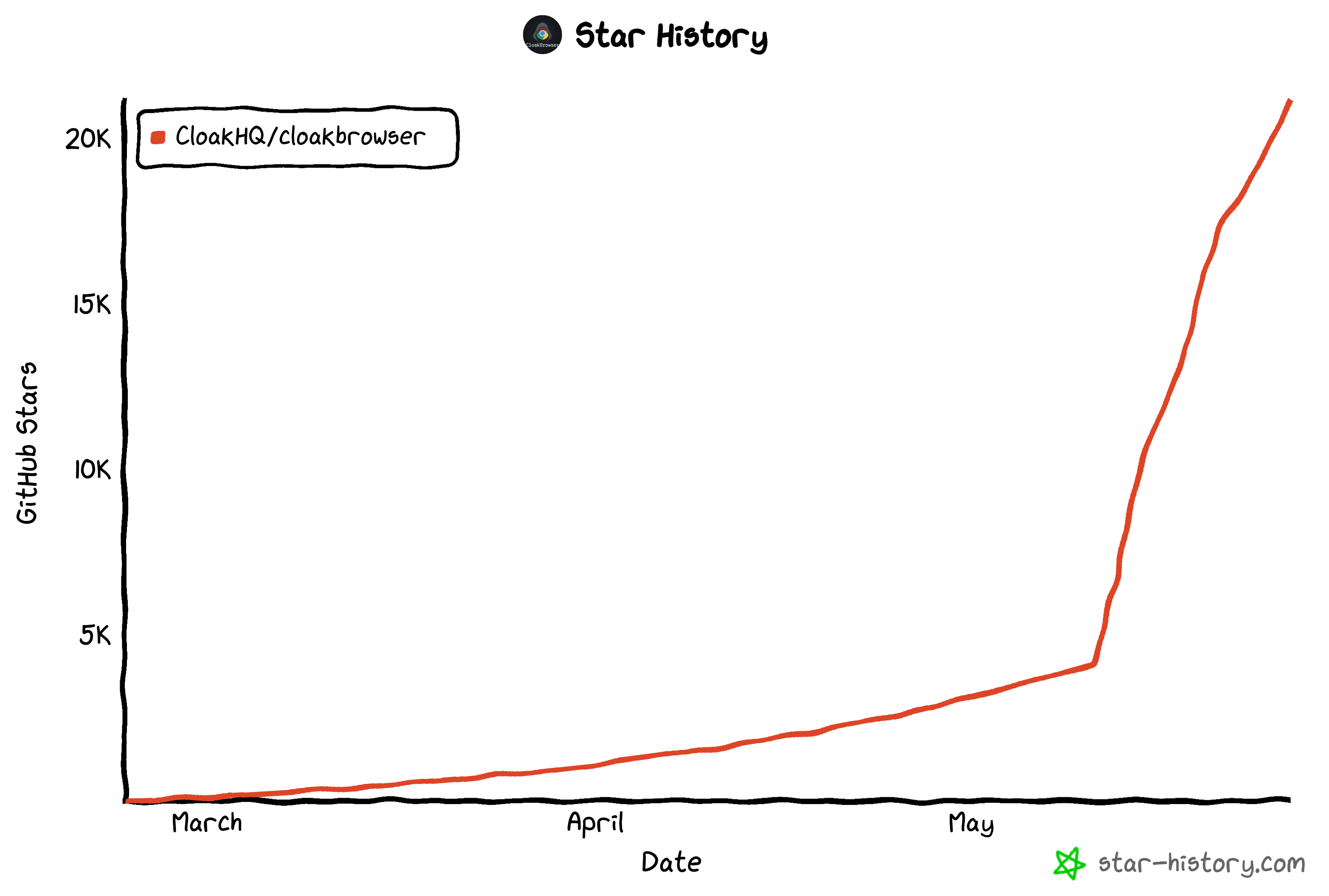
Chegou a aparecer nos repositórios em alta semanais do GitHub em toda a plataforma:
Principais Recursos
Estes são os principais recursos fornecidos pelo projeto CloakBrowser:
- Patch de fingerprint do Chromium no nível do código-fonte: Aplica 58+ modificações em C++ para GPU, canvas, WebGL, áudio, fontes e sinais de temporização diretamente no motor do navegador.
- Gerenciamento automático de binários: Baixa automaticamente o build personalizado do Chromium para você, sem nenhuma configuração manual necessária.
- Substituto direto para Playwright e Puppeteer: Mantém a mesma API, portanto o código de automação existente funciona alterando apenas algumas linhas de código.
- Motor de interação semelhante ao humano: Simula movimentos de mouse realistas, temporização de teclado, comportamento de rolagem e dinâmicas de clique por meio de um único flag
humanize=True. - Suporte avançado a Proxy: Suporta proxies HTTP e SOCKS5 com autenticação, além de alinhamento opcional de fuso horário e localidade baseado em GeoIP.
- Perfis de navegador persistentes: Pode manter cookies,
localStoragee cache entre sessões para permitir fluxos de trabalho autenticados de longa duração. - Sistema de controle de fingerprint: Usa seeds determinísticos ou aleatórios para gerar identidades de navegador consistentes ou rotativas entre sessões.
- Alta taxa de sucesso contra detecção de bots: Passa pelos principais sistemas como reCAPTCHA v3, Cloudflare Turnstile, FingerprintJS e BrowserScan em testes de benchmark.
Como o CloakBrowser Funciona
O CloakBrowser opera como uma camada de automação leve sobre um navegador personalizado baseado em Chromium. Veja como funciona:
- Você instala o CloakBrowser usando
pipounpm. - Na primeira execução, ele baixa automaticamente um binário Chromium pré-compilado para o seu sistema operacional.
- Cada sessão subsequente é iniciada neste navegador personalizado.
- Seu código existente permanece inalterado e continua a usar as APIs padrão do Playwright ou Puppeteer.
Nota: O CloakBrowser também pode ser configurado via Docker e conectado por meio de ferramentas padrão como Playwright, Puppeteer, Selenium ou qualquer framework compatível com CDP.
O binário do Chromium inclui dezenas de modificações C++ de baixo nível que ajustam ou mascaram os sinais de fingerprint do navegador. Ele também reduz a detecção de automação alterando sinais internos do navegador e do nível CDP. Essas alterações são compiladas diretamente nos binários Chromium baixados.
Uma implicação importante desse design é que apenas a camada wrapper é de código aberto, enquanto o binário do navegador é distribuído como um artefato pré-compilado. Isso limita a inspeção direta ou engenharia reversa da lógica de fingerprinting (por empresas por trás de WAFs e outras soluções anti-bot), pois as modificações críticas estão incorporadas no código compilado.
Primeiros Passos
Comece instalando o CloakBrowser. Em Python, execute:
pip install cloakbrowserOu em um projeto Node.js, instale com:
npm install cloakbrowserUma vez instalado, você pode usar as APIs padrão do Playwright ou Puppeteer. Por exemplo, abaixo está um exemplo Python no estilo Playwright:
# pip install cloakbrowser
from cloakbrowser import launch
browser = launch()
page = browser.new_page()
page.goto("https://example.com")
print(page.title()) # Resultado esperado: "Example Domain"
browser.close()Ou, equivalentemente, em JavaScript:
// npm install cloakbrowser
import { launch } from "cloakbrowser";
const browser = await launch();
const page = await browser.newPage();
await page.goto("https://example.com");
console.log(await page.title()); // Resultado esperado: "Example Domain"
await browser.close();Observe que a lógica de automação permanece idêntica ao Playwright ou Puppeteer padrão. O CloakBrowser apenas muda como o navegador é iniciado, não como você escreve o código de automação.
A única diferença é a função launch(), que inicializa uma sessão do CloakBrowser. Por padrão, ela inicia uma sessão de navegador headless com a configuração stealth padrão. Para mais controle, veja os argumentos disponíveis suportados pela função launch().
Quando você executa seu script pela primeira vez, o CloakBrowser:
- Detecta seu sistema operacional.
- Baixa um binário pré-compilado baseado em Chromium para sua plataforma.
- Armazena em cache localmente para uso futuro.
A partir desse ponto, cada chamada launch() inicia o binário Chromium personalizado por meio do Playwright ou Puppeteer.
Preços
O CloakBrowser não tem taxas de assinatura, limites de uso ou planos pagos. Portanto, você pode instalá-lo e usá-lo gratuitamente. No entanto, os custos reais vêm da infraestrutura ao redor.
Para uso escalável, você deve depender de integrações com provedores de Proxy terceirizados confiáveis. Os proxies são essenciais para cargas de trabalho de automação distribuída e podem se tornar o principal custo operacional, dependendo do volume de Tráfego e da cobertura geográfica.
Além disso, o CloakBrowser é frequentemente implantado em vários servidores usando Docker em ambientes de produção. Isso permite escalabilidade horizontal, mas também introduz sobrecarga adicional, incluindo orquestração de contêineres, gerenciamento de instâncias, monitoramento e manutenção contínua.
Como resultado, mesmo que o próprio CloakBrowser seja gratuito, a complexidade operacional e os custos de infraestrutura aumentam conforme você escala.
Uma Introdução à Browser API da Bright Data
Continue esta comparação entre CloakBrowser e Bright Data Browser API mergulhando na Browser API.
O Que É a Browser API?
A Browser API da Bright Data é uma automação de navegador gerenciada na nuvem, otimizada para interação web em larga escala e de nível produtivo, além de coleta de dados.
Em vez de executar e manter uma infraestrutura de navegador local, ela permite conectar seus scripts existentes do Playwright, Puppeteer ou Selenium a navegadores stealth totalmente hospedados. Esses navegadores são automaticamente escalados e mantidos na nuvem.
Em sua essência, foi criada para cenários onde confiabilidade, capacidade de desbloqueio e escala são importantes. Os casos de uso comuns incluem scraping de dados dinâmico, QA/testes automatizados, geração de leads e muito mais.
É respaldada pela enorme rede de Proxy da Bright Data com mais de 400 milhões de IPs, permitindo forte distribuição geográfica, rotação de IP e escalabilidade e concorrência ilimitadas. A solução lida com Resolução de CAPTCHA, fingerprinting, gerenciamento de sessão e renderização de JavaScript de forma nativa. Graças a esses recursos, ela alcança altas taxas de sucesso em sites fortemente protegidos.
A Browser API suporta todas as ferramentas compatíveis com CDP, bem como fluxos de trabalho modernos de agentes de IA via Web MCP. Isso significa que também é adequada para agentes autônomos que precisam navegar, clicar e extrair informações em tempo real.
Principais Recursos
Estes são os principais recursos da Bright Data Browser API:
- Infraestrutura de navegador gerenciada na nuvem: Navegadores totalmente hospedados executados na nuvem, eliminando configuração local, gerenciamento de Proxy e manutenção de infraestrutura.
- Compatibilidade com Playwright, Puppeteer e Selenium: A integração direta com os principais frameworks de automação de navegador permite a reutilização de scripts existentes com alterações mínimas, possibilitando migração rápida.
- Resolução de CAPTCHA integrada: Detecta e resolve automaticamente CAPTCHAs e sistemas de desafio-resposta, reduzindo interrupções no scraping e eliminando a necessidade de serviços externos.
- Acesso a rede de Proxy em larga escala: Aproveita um Pool de proxies residencial com mais de 400 milhões de endereços para permitir solicitações geo-distribuídas, reduzindo bloqueios e detecções.
- Emulação de fingerprint de navegador: Simula características de navegador de usuários reais para reduzir o risco de detecção e melhorar a confiabilidade contra sistemas anti-bot avançados.
- Infraestrutura de auto-escalonamento: Provisiona dinamicamente sessões de navegador com base na demanda, suportando cargas de trabalho de alta concorrência sem escalonamento manual.
- Depuração com Chrome DevTools: Fornece inspeção de sessão usando DevTools, permitindo monitorar logs, solicitações de rede e comportamento do navegador durante a execução do scraping.
- Segmentação por geolocalização: Permite segmentação precisa por país, cidade ou nível ASN para acessar conteúdo localizado, testar experiências regionais e extrair dados geo-restritos com precisão.
- Recuperação automática: Restaura sessões para manter a continuidade, reduzindo o tempo de inatividade e melhorando a robustez em ambientes instáveis ou bloqueados.
- Compatibilidade com agentes de IA (via Web MCP): Suporta agentes de navegador autônomos capazes de navegar, clicar, rolar e extrair dados da web, habilitando fluxos de trabalho avançados de automação orientados por IA.
- Validação de integridade de dados: Garante que os dados extraídos sejam consistentes e confiáveis por meio de mecanismos de validação integrados, melhorando a qualidade para análises downstream e pipelines de produção.
Para mais informações, explore a documentação oficial.
Como a Browser API Funciona
A Browser API funciona executando seus scripts de automação de navegador dentro de navegadores totalmente gerenciados baseados na nuvem. Você se conecta usando um único endpoint CDP e seu código é executado remotamente em ambientes de navegador reais. Basicamente, você interage com o navegador como se fosse local, mas a execução, o escalonamento e o desbloqueio são totalmente gerenciados e acontecem na nuvem.
Nos bastidores, a plataforma lida com toda a complexidade de infraestrutura. Ela gerencia automaticamente a rotação de Proxy, o fingerprinting do navegador, o gerenciamento de sessão, a Resolução de CAPTCHA e muito mais. Cada sessão é executada em um ambiente de nuvem escalável que pode alocar recursos dinamicamente com base na demanda. Isso significa alta concorrência sem configuração manual.
Primeiros Passos
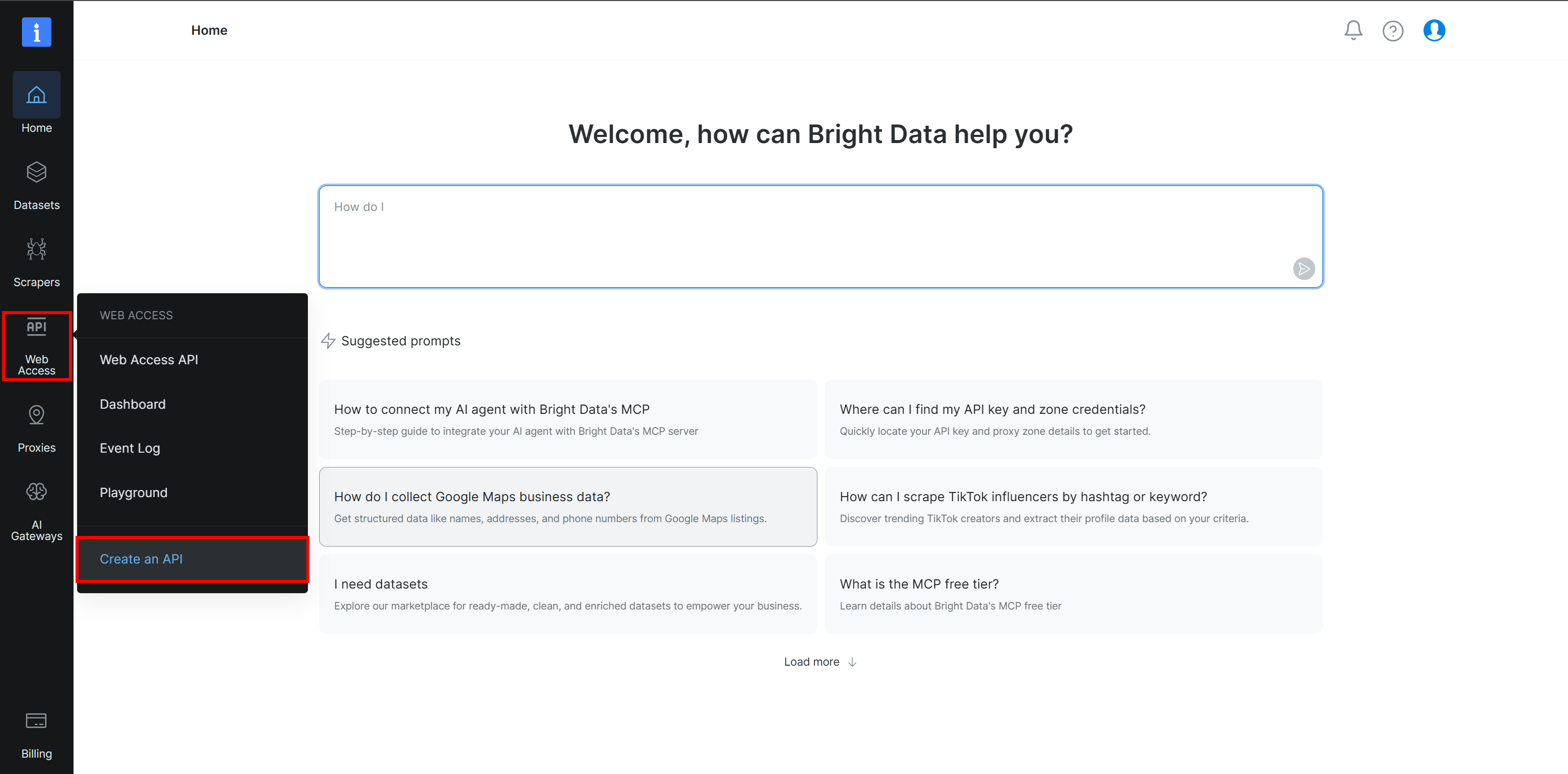
Primeiro, você precisa configurar uma Zona de Browser API em sua conta Bright Data. Se ainda não fez isso, crie uma conta Bright Data. Caso contrário, faça login normalmente.
No Painel de Controle da Bright Data, selecione a opção “Web Access > Create an API”:
 Create an API””/>
Create an API””/>Na página “Web Access API > Add API”, selecione o tipo “Browser API”:
Siga o assistente, dê um nome à sua Zona de Browser API (ex.: browser_api) e configure-a conforme necessário. Conclua o fluxo de configuração e você receberá suas URLs de conexão para Puppeteer, Playwright e Selenium:
Em seguida, pressione o botão “Open API settings” para acessar o Browser API Playground. Aqui, você pode acessar snippets prontos para uso para integração com frameworks populares de automação de navegador e linguagens de programação:
Use a URL de conexão remota para conectar via CDP no Playwright usando Python desta forma:
# pip install playwright
from playwright.sync_api import sync_playwright
# Substitua pela URL de conexão da sua Browser API
BROWSER_API_CDP = "wss://brd-customer-USER-zone-BROWSER_API_ZONE_NAME:[email protected]:9222"
with sync_playwright() as p:
browser = p.chromium.connect_over_cdp(BROWSER_API_CDP)
page = browser.new_page()
page.goto("https://example.com")
print(page.title()) # Resultado esperado: "Example Domain"
browser.close()Ou equivalentemente, em JavaScript:
// npm install playwright
const { chromium } = require("playwright");
# Substitua pela URL de conexão da sua Browser API
const BROWSER_API_CDP = "wss://brd-customer-USER-zone-BROWSER_API_ZONE_NAME:[email protected]:9222";
(async () => {
const browser = await chromium.connectOverCDP(BROWSER_API_CDP);
const page = await browser.newPage();
await page.goto("https://example.com");
console.log(await page.title()); // Resultado esperado: "Example Domain"
await browser.close();
})();A lógica de automação permanece idêntica ao Playwright ou Puppeteer padrão. A única mudança é como você se conecta ao navegador. Ao usar connect_over_cdp()/connectOverCDP(), você redireciona a execução para instâncias de nuvem da Browser API totalmente gerenciadas (em vez de depender de um navegador local).
Preços
A Browser API usa um modelo de Pagamento por uso baseado em Tráfego, onde você é cobrado apenas pelos GB de dados transferidos pela infraestrutura de navegador na nuvem. Em detalhes, os preços da Browser API seguem estes planos:
| Plano | Preço |
|---|---|
| Pagamento conforme o uso (sem compromisso, cobrança baseada em uso) | $8/GB |
| 71 GB incluídos | $499/mês ($7/GB) |
| 166 GB incluídos | $999/mês ($6/GB) |
| 399 GB incluídos | $1.999/mês ($5/GB) |
Não há cobranças por instâncias de navegador, tempo de execução ou concorrência. Todos os países são cobrados na mesma tarifa, tornando o preço previsível entre geografias. A única exceção são os domínios premium, que incorrem em custos mais altos por GB devido à complexidade adicional de desbloqueio.
Nota: Você também pode testar a Browser API, assim como qualquer outro produto da Bright Data, gratuitamente por meio de um teste gratuito.
Como o preço depende diretamente do Tráfego, otimizar a Largura de banda é importante para eficiência de custo e desempenho. Leia o guia oficial sobre otimização de largura de banda.
Diferenças de Abordagem para Navegação Stealth
Tanto o CloakBrowser quanto a Browser API visam reduzir a detecção de bots. No entanto, eles adotam duas abordagens fundamentalmente diferentes para navegação stealth e gerenciamento de fingerprint.
O CloakBrowser alcança o bypass anti-bot por meio de um binário Chromium modificado executado localmente. Ele gera um fingerprint de navegador coerente no lançamento, falsificando sinais detectáveis como GPU, tamanho de tela, fontes, canvas, WebGL, áudio e especificações de hardware.
Você também pode controlar a persistência de identidade por meio de seeds determinísticos de fingerprint e ajustar atributos específicos via flags de lançamento. Isso torna o CloakBrowser particularmente adequado quando você precisa de controle preciso de fingerprint e identidades de navegador reproduzíveis entre sessões.
Ao contrário, a Browser API oferece stealth por meio de navegadores de nuvem totalmente gerenciados. Em vez de expor flags de fingerprint de baixo nível, ela lida com o fingerprinting do navegador nos bastidores. Ao mesmo tempo, expõe configurações e ações CDP personalizadas para controlar comportamentos avançados. Elas permitem emular dispositivos específicos, alterar geolocalização, bloquear anúncios, configurar a Resolução de CAPTCHA e muito mais.
A Diferença de Infraestrutura
O CloakBrowser fornece um binário Chromium stealth local. No entanto, tudo ao redor dele permanece sua responsabilidade. Isso significa que, se você quiser executar automação em escala, precisará provisionar máquinas, gerenciar concorrência de navegador, configurar e rotacionar proxies, monitorar falhas e muito mais.
Claro, você recebe imagens Docker que expõem o ambiente CloakBrowser e servidores de navegador para conexão via CDP. Mas ir de uma imagem Docker para uma infraestrutura de navegador verdadeiramente escalável é um desafio diferente. Isso requer habilidades de engenharia, expertise em infraestrutura e um orçamento que nem todas as equipes possuem.
A Browser API da Bright Data adota uma abordagem muito diferente. Em vez de fornecer um navegador para gerenciar, ela oferece uma infraestrutura de navegador totalmente gerenciada na nuvem. A rotação de Proxy, a orquestração de navegadores, o escalonamento, a concorrência e o monitoramento são todos gerenciados. Você simplesmente conecta seu script de automação de navegador ou agente de IA a um endpoint remoto, e a Bright Data cuida de toda a complexidade operacional para você.
Em particular, a Browser API é respaldada pela infraestrutura de nível empresarial com SLA da Bright Data. Ela oferece 99,99% de uptime, concorrência ilimitada, taxa de sucesso de 99,95%, escalabilidade ilimitada e conformidade com GDPR, CCPA e outros regulamentos de privacidade e segurança.
Essa distinção é o ponto-chave de toda a comparação entre CloakBrowser e Browser API. O CloakBrowser é indiscutivelmente uma ótima ferramenta. Ainda assim, a Browser API é a única das duas que pode ser verdadeiramente considerada uma infraestrutura completa de automação de navegador.
Esse também é o maior benefício da Browser API em comparação ao CloakBrowser. Ao reduzir a carga operacional desde o primeiro dia, ela permite que você se concentre na lógica de automação, que é o que mais importa.
Integrações Suportadas
O CloakBrowser suporta nativamente scripts do Playwright e Puppeteer. No entanto, requer uma dependência extra (cloakbrowser), enquanto ainda depende das dependências do sistema do Playwright.
Além das APIs nativas, o CloakBrowser expõe um navegador compatível com CDP por meio de uma configuração de servidor baseada em Docker. Dessa forma, ele pode se integrar com qualquer ferramenta compatível com CDP. Ele também suporta nativamente alguns frameworks de agentes de IA como CrawAI, Browser Use e LangChain.
A Browser API suporta Playwright, Puppeteer e Selenium, mas sem dependências adicionais necessárias. Além disso, é totalmente compatível com todas as ferramentas baseadas em CDP, incluindo Browser Use, Stagehand, Agent Browser e frameworks de automação baseados em IA semelhantes.
Além disso, a Browser API da Bright Data é exposta via ferramentas Web MCP. Estas incluem:
| Ferramenta | Descrição |
|---|---|
scraping_browser_navigate |
Abrir ou reutilizar uma sessão e navegar para uma URL, redefinindo o rastreamento de rede |
scraping_browser_go_back |
Navegar para trás e retornar URL e título atualizados |
scraping_browser_go_forward |
Navegar para frente e retornar URL e título atualizados |
scraping_browser_snapshot |
Capturar snapshot ARIA com refs de elementos interativos |
scraping_browser_click_ref |
Clicar em um elemento usando seu ref ARIA |
scraping_browser_screenshot |
Capturar screenshot da página ou página inteira |
scraping_browser_wait_for_ref |
Aguardar visibilidade do elemento por ref ARIA |
scraping_browser_get_text |
Extrair texto visível do corpo da página |
scraping_browser_get_html |
Recuperar conteúdo HTML da página |
scraping_browser_scroll |
Rolar até o final da página |
scraping_browser_scroll_to_ref |
Rolar até um elemento referenciado específico |
O suporte a MCP torna a Browser API um navegador agêntico, ampliando a compatibilidade para um vasto ecossistema de frameworks de agentes de IA. As soluções suportadas incluem LangChain, Agno, OpenClaw, LlamaIndex, CrewAI, Dify, Mastra, Claude Code, Codex, Claude Desktop e mais de 70 outros.
Bright Data Browser API vs CloakBrowser: Comparação Lado a Lado
Compare as duas soluções na tabela final de CloakBrowser vs Bright Data Browser API abaixo:
| Aspecto | CloakBrowser | Bright Data Browser API |
|---|---|---|
| Conceito central | Binário Chromium stealth local | Infraestrutura de navegador na nuvem totalmente gerenciada |
| Natureza | Wrapper de código aberto + Binários de navegador proprietários com patches | Proprietário |
| Dependências | Requer cloakbrowser + dependências do sistema |
Sem dependências extras |
| Suporte a CDP | ✔️ (via servidor Docker) | ✔️ (endpoint CDP nativo na nuvem) |
| Abordagem stealth | Patch de fingerprint do Chromium no nível do código-fonte | Fingerprinting gerenciado |
| Controle de fingerprint | Alto controle via seeds e flags de lançamento | Controlado via ações CDP para emulação de dispositivos |
| Gerenciamento de Proxy | Provedor de Proxy externo necessário | Rede de Proxy integrada com 400M+ IPs |
| Tratamento de CAPTCHA | Não nativo | Resolução de CAPTCHA integrada |
| Suporte a frameworks | Playwright, Puppeteer, ferramentas compatíveis com CDP | Playwright, Puppeteer, Selenium, ferramentas compatíveis com CDP |
| Integração com agentes de IA | Suporta alguns frameworks de IA (Browser Use, LangChain, CrawAI) | Amplo ecossistema via Web MCP (LangChain, LlamaIndex, CrewAI, Agno, Claude e 70+ outros) |
| Responsabilidade de infraestrutura | Gerenciada pelo usuário | Totalmente gerenciada pela Bright Data |
| Escalonamento | Escalonamento horizontal manual necessário | Escalonamento elástico automático, com concorrência ilimitada |
| Garantias de uptime | Depende da infraestrutura do usuário | 99,99% de uptime com SLA |
| Modelo de custo | Software gratuito, infraestrutura com custo separado | Preço baseado em Tráfego por GB |
Veredicto Final
Tanto o CloakBrowser quanto a Browser API são soluções poderosas de automação de navegador prontas para stealth. O CloakBrowser, com sua natureza de código aberto, é melhor quando você precisa de máximo controle local sobre fingerprints de navegador e uma infraestrutura totalmente autogerenciada. É especialmente útil para configurações experimentais ou altamente personalizadas.
Para scraping de dados em escala de produção, automação confiável ou integração com agentes de IA, a Browser API da Bright Data deve ser a escolha preferida. Sua infraestrutura totalmente gerenciada, capacidades de desbloqueio integradas e escalonamento elástico eliminam a sobrecarga operacional. Isso a torna significativamente mais prática para equipes que desejam se concentrar na lógica de automação em vez do gerenciamento de infraestrutura.
Conclusão
Neste artigo de comparação entre Bright Data Browser API e CloakBrowser, você aprendeu o que são ambas as ferramentas, quais recursos elas oferecem e como funcionam, além de quanto custam.
O CloakBrowser é uma solução de automação de navegador de código aberto excelente quando você deseja controle de baixo nível. Já a Browser API é mais adequada para integrações de automação de navegador mais confiáveis, de nível empresarial ou agênticas.
Explore a Browser API hoje e comece a integrá-la em seus scripts de automação.
Crie uma conta Bright Data e explore nossas soluções de automação de dados da web prontas para IA!




