

Neste guia, você aprenderá:
- O que é a biblioteca de
uso do navegadorpara desenvolvimento de agentes de IA - Por que seus recursos são limitados pelo navegador que ele controla
- Como superar essas limitações usando um navegador de raspagem
- Como criar um agente de IA que opera no navegador e evita bloqueios graças à integração com o Scraping Browser
Vamos mergulhar de cabeça!
O que é o uso do navegador?
O Browser Use é um projeto Python de código aberto que torna os sites acessíveis aos agentes de IA. Ela identifica todos os elementos interativos em uma página da Web, permitindo que os agentes realizem interações significativas com eles. Em resumo, a biblioteca de uso do navegador permite que a IA controle e interaja com seu navegador de forma programática.
Em detalhes, os principais recursos que ele oferece são:
- Automação avançada do navegador: Combina IA avançada com automação robusta do navegador para simplificar as interações na Web para agentes de IA.
- Visão + extração de HTML: Integra a compreensão visual e a extração da estrutura HTML para uma navegação e tomada de decisões mais eficazes.
- Gerenciamento de várias guias: Pode lidar com várias guias do navegador, abrindo a porta para fluxos de trabalho complexos e tarefas paralelas.
- Rastreamento de elementos: Rastreia os elementos clicados usando XPath e pode repetir as ações exatas realizadas por um LLM, garantindo a consistência.
- Ações personalizadas: Oferece suporte à definição de ações personalizadas, como salvar em arquivos, gravar em bancos de dados, enviar notificações ou manipular entradas humanas.
- Mecanismo de autocorreção: Vem com um sistema integrado de tratamento de erros e recuperação automática para um pipeline de automação mais confiável.
- Suporte a qualquer LLM: é compatível com todos os principais LLMs via LangChain, incluindo GPT-4, Claude 3 e Llama 2.
Limitações do uso do navegador no desenvolvimento de agentes de IA
O Browser Use é uma tecnologia inovadora que causou um impacto sem precedentes na comunidade de TI. Não é de surpreender que o projeto tenha alcançado mais de 60.000 estrelas no GitHub em apenas alguns meses:

Além disso, a equipe por trás dele garantiu mais de US$ 17 milhões em financiamento inicial, o que diz muito sobre o potencial e a promessa desse projeto.
No entanto, é importante reconhecer que os recursos de controle de navegador oferecidos pelo Browser Use não se baseiam em mágica. Em vez disso, a biblioteca combina entrada visual com controle de IA para automatizar os navegadores por meio do Playwright, umaestrutura de automação de navegadores rica em recursos que vem com certas limitações.
Conforme destacamos em nossos artigos anteriores sobre raspagem da Web do Playwright, as limitações não decorrem da estrutura de automação em si. Muito pelo contrário, elas vêm dos navegadores que ela controla. Especificamente, ferramentas como o Playwright iniciam navegadores com configurações especiais e instrumentação que permitem a automação. O problema é que essas configurações também podem expô-las a sistemas de detecção anti-bot.
Isso se torna um grande problema, especialmente ao criar agentes de IA que precisam interagir com sites bem protegidos. Por exemplo, suponha que você queira utilizar o Browser Use para criar um agente de IA que adicione itens específicos a um carrinho de compras na Amazon para você. Este é o resultado que você provavelmente obterá:

Como você pode ver, o sistema anti-bot da Amazon pode detectar e interromper sua automação de IA. Em particular, a plataforma de comércio eletrônico pode mostrar o desafiador Amazon CAPTCHA ou responder com a página de erro “Sorry, something went wrong on our end”:

Nesses casos, é “fim de jogo” para seu agente de IA. Portanto, embora o uso do navegador seja uma ferramenta incrível e avançada, atingir todo o seu potencial requer ajustes cuidadosos. O objetivo final é evitar o acionamento de sistemas antibot para que sua automação de IA possa operar conforme desejado.
Por que um navegador de raspagem é a solução
Agora, você pode estar pensando: “Por que não ajustar o navegador que os controles de uso do navegador usam por meio do Playwright, usando sinalizadores especiais para reduzir as chances de detecção?” Isso é de fato possível e faz parte da estratégia usada por bibliotecas como a Playwright Stealth.
No entanto, contornar a detecção de antibot é muito mais complexo do que lançar algumas bandeiras…
Ele envolve fatores como reputação de IP, limitação de taxa, impressão digital do navegador e outros aspectos avançados. Você não pode simplesmente superar sistemas antibot sofisticados com alguns truques manuais. O que você realmente precisa é de uma solução desenvolvida desde o início para não ser detectada pelas defesas antibot e antirraspagem. E é aí que entra um navegador de raspagem!
As soluções de navegador de raspagem oferecem recursos antidetecção incrivelmente eficazes. Então, qual é o melhor navegador antidetecção do mercado? O navegador de raspagem da Bright Data!
Em particular, o Scraping Browser é um navegador da Web de última geração, baseado na nuvem, que oferece:
- Impressões digitais confiáveis de TLS para se confundir com usuários reais
- Escalabilidade ilimitada para raspagem de alto volume
- Rotação automática de IP, apoiada por uma rede proxy de mais de 150 milhões de IPs
- Lógica de nova tentativa incorporada para tratar graciosamente as solicitações com falha
- Recursos de resolução de CAPTCHA, prontos para uso
- Um kit de ferramentas anti-bot bypass abrangente
O Scraping Browser se integra a todas as principais bibliotecas de automação de navegador, incluindo Playwright, Puppeteer e Selenium. Portanto, ele é totalmente compatível com o uso do navegador, pois essa biblioteca é construída sobre o Playwright.
Ao integrar o Scraping Browser ao Browser Use, você pode contornar os bloqueios da Amazon que encontrou anteriormente ou evitar bloqueios semelhantes em qualquer outro site.
Como integrar o uso do navegador com um navegador de raspagem
Nesta seção do tutorial, você aprenderá a integrar o Browser Use com o Scraping Browser da Bright Data. Criaremos um agente de IA com tecnologia OpenAI que pode adicionar itens ao carrinho da Amazon.
Este é apenas um exemplo para demonstrar o poder da automação de navegador orientada por IA. Observe que o agente de IA pode interagir com outros sites, de acordo com suas necessidades e metas. O que importa é que ele permite que você economize muito tempo e esforço executando operações tediosas para você.
Em detalhes, o agente de IA da Amazon que estamos prestes a construir será capaz de:
- Conecte-se à Amazon usando uma instância remota do Scraping Browser para evitar detecção e bloqueios.
- Leia uma lista de itens do prompt.
- Pesquise, selecione os produtos corretos e adicione-os ao seu carrinho automaticamente.
- Visite o carrinho e forneça um resumo de todo o pedido.
Siga as etapas abaixo para ver como utilizar o Browser Use with Scraping Browser!
Pré-requisitos
Para acompanhar este tutorial, verifique se você tem o seguinte:
- Uma conta da Bright Data.
- Uma chave de API de um provedor de IA compatível, como OpenAI, Anthropic, Gemini, DeepSeek, Grok ou Novita.
- Conhecimento básico de programação Python assíncrona e automação de navegador.
Se você ainda não tiver uma conta de provedor da Bright Data ou da AI, não se preocupe. Nós o orientaremos sobre como criá-las nas etapas abaixo.
Etapa 1: Configuração do projeto
Antes de começar, certifique-se de ter o Python 3 instalado em seu sistema. Caso contrário, faça o download no site oficial e siga as instruções de instalação.
Abra seu terminal e crie uma nova pasta para seu projeto de agente de IA:
mkdir browser-use-amazon-agentA pasta browser-use-amazon-agent conterá todo o código do seu agente de IA baseado em Python.
Navegue até a pasta do projeto e configure um ambiente virtual dentro dela:
cd browser-use-amazon-agent
python -m venv venvAgora abra a pasta do projeto em seu IDE Python favorito. O Visual Studio Code com a extensão Python ou o PyCharm Community Edition são opções válidas.
Na pasta browser-use-amazon-agent, crie um novo arquivo Python chamado agent.py. A estrutura de seu projeto agora deve ser semelhante a esta:
Neste momento, o agent.py é apenas um script vazio, mas logo conterá toda a lógica de automação do navegador de IA.
No terminal do seu IDE, ative o ambiente virtual. No Linux/macOS, execute:
source venv/bin/activateDe forma equivalente, no Windows, execute:
venv/Scripts/activateEstá tudo pronto! Seu ambiente Python agora está pronto para criar um agente de IA com o Browser Use e o Scraping Browser.
Etapa 2: Configurar a leitura das variáveis de ambiente
Seu projeto será integrado a serviços de terceiros, como a Bright Data e o provedor de IA escolhido. Em vez de codificar chaves de API e segredos de conexão diretamente em seu código Python, é uma prática recomendada carregá-los a partir de variáveis de ambiente.
Para simplificar essa tarefa, usaremos a biblioteca python-dotenv. No ambiente virtual ativado, instale-a com:
pip install python-dotenvEm seu arquivo agent.py, importe a biblioteca e carregue as variáveis de ambiente com load_dotenv():
from dotenv import load_dotenv
load_dotenv()Agora você poderá ler variáveis de um arquivo .env local. Adicione-o ao seu projeto:

Agora você pode acessar essas variáveis de ambiente em seu código com esta linha de código:
env_value = os.getenv("<ENV_NAME>")Não se esqueça de importar os da biblioteca padrão do Python:
import osExcelente! Agora você está pronto para ler com segurança os segredos para integração com serviços de terceiros dos envs.
Etapa 3: Comece a usar o navegador
Com seu ambiente virtual ativado, instale o uso do navegador:
pip install browser-useComo a biblioteca depende de várias dependências, isso pode levar alguns minutos. Portanto, seja paciente.
Como o uso do navegador usa o Playwright, talvez você também precise instalar as dependências do navegador do Playwright. Para fazer isso, execute o seguinte comando:
python -m playwright installIsso faz o download dos binários necessários do navegador e configura tudo o que o Playwright precisa para funcionar corretamente.
Agora, importe as classes necessárias do browser-use:
from browser_use import Agent, Browser, BrowserConfigEm breve, usaremos essas classes para criar a lógica de automação do navegador do agente de IA.
Como o browser-use fornece uma API assíncrona, você precisa inicializar o agent.py com um ponto de entrada assíncrono:
# other imports..
import asyncio
async def main():
# AI agent logic...
if __name__ == "__main__":
asyncio.run(main())O snippet acima usa a biblioteca asyncio do Python para executar tarefas assíncronas, o que é necessário para trabalhar com o uso do navegador.
Muito bem! A próxima etapa é configurar o navegador de raspagem e integrá-lo ao seu script.
Etapa 4: Começar a usar o navegador de raspagem
Para obter instruções gerais de integração, consulte a documentação oficial do Scraping Browser. Caso contrário, siga as etapas abaixo.
Para começar, se você ainda não o fez, crie uma conta na Bright Data. Faça login, acesse o painel de controle do usuário e clique no botão “Get proxy products” (Obter produtos proxy):
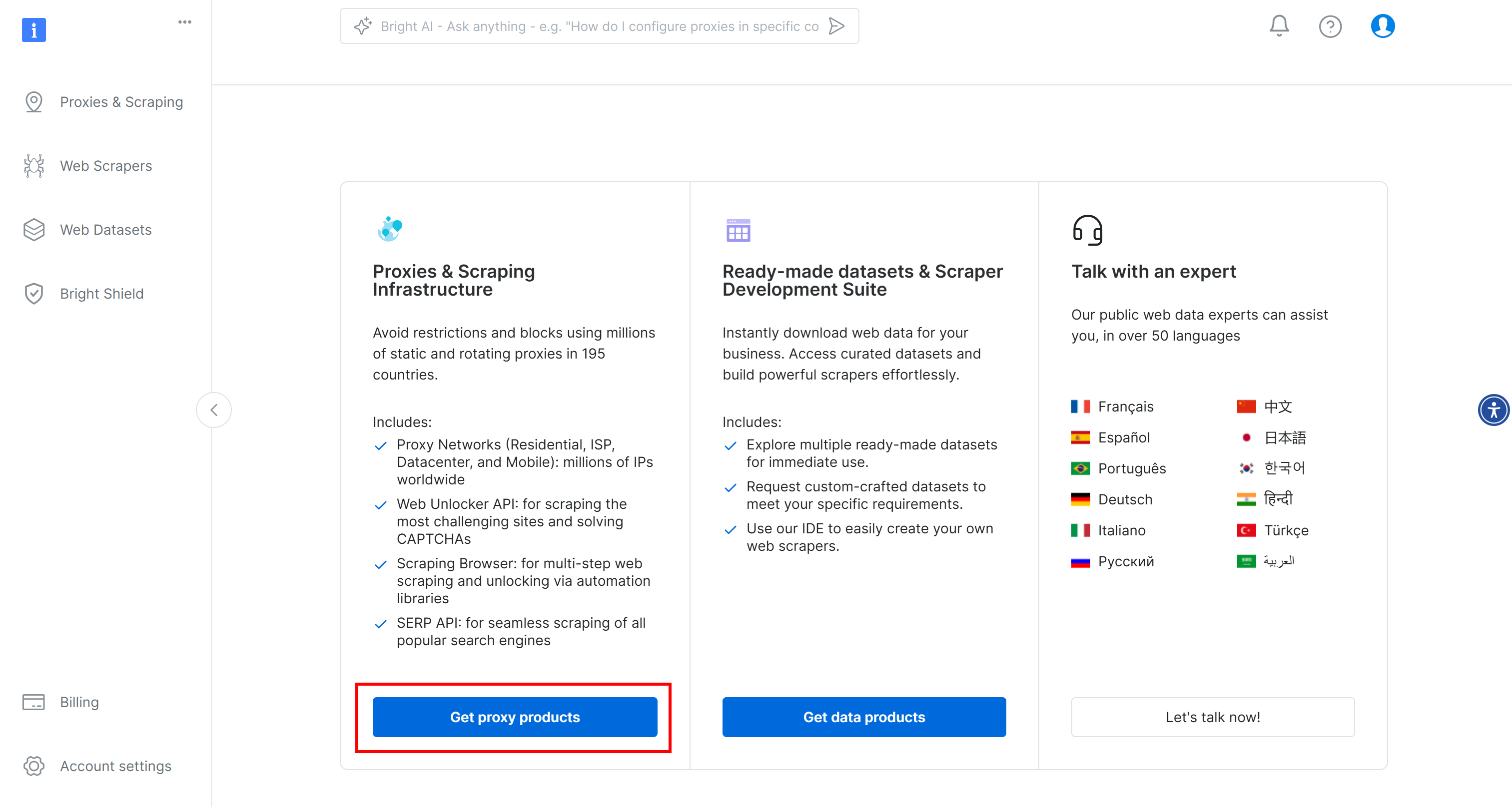
Na página “Proxies & Scraping Infrastructure”, procure a tabela “My Zones” e selecione a linha referente ao tipo “Scraping Browser”:

Se você não vir essa linha, significa que ainda não configurou a zona do navegador de raspagem. Nesse caso, role a tela para baixo até encontrar o cartão “Browser API” e pressione o botão “Get Started” (Iniciar):

Em seguida, siga a configuração guiada para configurar o Scraping Browser pela primeira vez.
Quando chegar à página do produto, ative-o alternando o botão liga/desliga:

Agora, vá para a guia “Configuration” (Configuração) e verifique se os “Premium domains” (Domínios premium) e o “CAPTCHA Solver” (Solucionador de CAPTCHA) estão ativados para obter o máximo de eficácia:

Vá para a guia “Overview” (Visão geral) e copie a string de conexão do Playwright Scraping Browser:

Adicione essa string de conexão ao seu arquivo .env:
SBR_CDP_URL="<YOUR_PLAYWRIGHT_SCRAPING_BROWSER_CONNECTION_STRING>"Substitua pelo valor que você acabou de copiar.
Agora, em seu arquivo agent.py, carregue a variável de ambiente com:
SBR_CDP_URL = os.getenv("SBR_CDP_URL")Incrível! Agora você pode usar o Scraping Browser dentro do uso do navegador. Antes de nos aprofundarmos nisso, vamos concluir as integrações de terceiros adicionando o OpenAI ao seu script.
Etapa 5: começar a usar a OpenAI
Isenção de responsabilidade: a etapa a seguir se concentra na integração do OpenAI, mas você pode adaptar facilmente as instruções abaixo para qualquer outro provedor de IA compatível com o Browser Use.
Para ativar os recursos de IA no uso do navegador, você precisa de uma chave de API válida de um provedor de IA externo. Aqui, usaremos a OpenAI. Se você ainda não gerou uma chave de API, siga o guia oficial da OpenAI para criar uma.
Depois de obter sua chave, adicione-a ao seu arquivo .env:
OPENAI_API_KEY="<YOUR_OPENAI_KEY>"Certifique-se de substituir por sua chave de API real.
Em seguida, importe a classe ChatOpenAI de langchain_openai em agent.py:
from langchain_openai import ChatOpenAIObserve que o Browser Use depende do LangChain para lidar com as integrações de IA. Portanto, mesmo que você não tenha instalado explicitamente o langchain_openai em seu projeto, ele já está disponível para uso. Para obter mais orientações, leia nosso tutorial sobre como integrar o Bright Data nos fluxos de trabalho do LangChain.
Configure a integração do OpenAI usando o modelo gpt-4o com:
llm = ChatOpenAI(model="gpt-4o")Não é necessária nenhuma configuração adicional. Isso ocorre porque o langchain_openai lerá automaticamente a chave de API da variável de ambiente OPENAI_API_KEY.
Para integração com outros modelos ou provedores de IA, consulte a documentação oficial do Browser Use.
Etapa 6: Integrar o navegador de raspagem ao uso do navegador
Para se conectar a um navegador remoto no uso do navegador, você precisa usar o objetoBrowserConfig da seguinte forma:
config = BrowserConfig(
cdp_url=SBR_CDP_URL
)
browser = Browser(config=config)Essa configuração instrui o Playwright a se conectar à instância remota do Bright Data Scraping Browser.
Etapa nº 7: Definir a tarefa a ser automatizada
Agora é hora de definir a tarefa que você deseja que o agente de IA execute no navegador usando linguagem natural.
Antes de fazer isso, certifique-se de que o objetivo esteja claramente definido em sua mente. Nesse caso, vamos supor que você queira que o agente de IA:
- Conecte-se à Amazon.com.
- Adicione o console PlayStation 5 e o jogo Astro Bot PS5 ao carrinho.
- Acessar a página do carrinho e gerar um resumo do pedido atual.
Se você fornecer apenas essas instruções básicas ao Browser Use, as coisas podem não sair como esperado. Isso ocorre porque alguns produtos têm várias versões, algumas páginas podem solicitar que você compre um seguro adicional, alguns itens podem não estar disponíveis, etc.
Portanto, faz sentido adicionar notas extras para orientar as decisões do agente de IA nessas situações.
Além disso, para melhorar o desempenho, é útil delinear claramente as etapas mais importantes em palavras.
Com isso em mente, a tarefa que seu agente de IA deve executar no navegador pode ser descrita da seguinte forma:
task="""
# Prompt for Your Amazon Agent
**Objective:**
Visit [Amazon](https://www.amazon.com/), search for the required items, add them to the cart, and show a summary of the current order.
**Important:**
- Click on a product's title to access its page. There, you can find the "Add to cart" button.
- If you are asked for extended warranty or similar after adding a product to the cart, decline the option.
- You can find the search bar to search for products at the top section of each Amazon page. If you cannot use it, go back to the Amazon home page before a search.
- If the product is unavailable, add the cheapest used option to the cart instead. If no used options are available, skip the product.
- If any modal/section occupying a part of the page appears, remember that you can close it by clicking the "X" button.
- Avoid refurbished items.
---
## Step 1: Navigate to the Target Website
- Open [Amazon](https://www.amazon.com/)
---
## Step 2: Add Items to the Cart
- Add the items you can find in the shopping list below to the Amazon cart:
- PlayStation 5 (Slim) console
- Astro Bot PS5 game
---
## Step 3: Output Summary
- Reach the cart page and use the info you can find on that page to generate a summary of the current order. For each item in the cart, include:
- **Name**
- **Quantity**
- **Cost**
- **Expected delivery time**
- At the end of the report, mention the total cost and any other useful additional info.
"""Observe como essa versão é detalhada o suficiente para orientar o agente de IA em cenários comuns e evitar que ele fique preso.
Que lindo! Veja como iniciar essa tarefa.
Etapa 8: Iniciar a tarefa de IA
Inicialize um objeto Agent de uso do navegador usando a definição de tarefa de seu agente de IA:
agent = Agent(
task=task,
llm=llm,
browser=browser,
)Agora você pode executar o agente com:
await agent.run()Além disso, não se esqueça de fechar o navegador controlado pelo Playwright quando a tarefa for concluída para liberar seus recursos:
await browser.close()Perfeito! A integração do Browser Use + Bright Data Scraping Browser agora está totalmente configurada. Tudo o que resta é juntar tudo e executar o código completo.
Etapa nº 9: Juntar tudo
Seu arquivo agent.py deve conter:
from dotenv import load_dotenv
import os
from browser_use import Agent, Browser, BrowserConfig
from browser_use.browser.context import BrowserContextConfig, BrowserContext
import asyncio
from langchain_openai import ChatOpenAI
# Load the environment variables from the .env file
load_dotenv()
async def main():
# Read the remote URL of Scraping Browser from the envs
SBR_CDP_URL = os.getenv("SBR_CDP_URL")
# Set up the AI engine
llm = ChatOpenAI(model="gpt-4o")
# Configure the browser automation to connect to a remote Scraping Browser instance
config = BrowserConfig(
cdp_url=SBR_CDP_URL
)
browser = Browser(config=config)
# The task you want to automate in the browser
task="""
# Prompt for Your Amazon Agent
**Objective:**
Visit [Amazon](https://www.amazon.com/), search for the required items, add them to the cart, and show a summary of the current order.
**Important:**
- Click on a product's title to access its page. There, you can find the "Add to cart" button.
- If you are asked for extended warranty or similar after adding a product to the cart, decline the option.
- You can find the search bar to search for products at the top section of each Amazon page. If you cannot use it, go back to the Amazon home page before a search.
- If the product is unavailable, add the cheapest used option to the cart instead. If no used options are available, skip the product.
- If any modal/section occupying a part of the page appears, remember that you can close it by clicking the "X" button.
- Avoid refurbished items.
---
## Step 1: Navigate to the Target Website
- Open [Amazon](https://www.amazon.com/)
---
## Step 2: Add Items to the Cart
- Add the items you can find in the shopping list below to the Amazon cart:
- PlayStation 5 (Slim) console
- Astro Bot PS5 game
---
## Step 3: Output Summary
- Reach the cart page and use the info you can find on that page to generate a summary of the current order. For each item in the cart, include:
- **Name**
- **Quantity**
- **Cost**
- **Expected delivery time**
- At the end of the report, mention the total cost and any other useful additional info.
"""
# Initialize a new AI browser agent with the configured browser
agent = Agent(
task=task,
llm=llm,
browser=browser,
)
# Start the AI agent
await agent.run()
# Close the browser when the task is complete
await browser.close()
if __name__ == "__main__":
asyncio.run(main())E pronto! Em menos de 100 linhas de código, você criou um agente de IA avançado que combina o uso do navegador com o navegador de raspagem da Bright Data.
Para executar seu agente de IA, execute:
python agent.pyUma vez iniciado, o browser-use registrará tudo o que fizer. Como o Scraping Browser é executado na nuvem e não há interface visual, esses registros são essenciais para entender o que o agente está fazendo.
Aqui está um pequeno trecho de como os registros podem ser:
INFO [agent] 📍 Step 1
INFO [browser] 🔌 Connecting to remote browser via CDP wss://brd-customer-hl_4bcb8ada-zone-scraping_browser:[email protected]:9222
INFO [agent] 🤷 Eval: Unknown - Task has just started, beginning with navigating to Amazon.
INFO [agent] 🧠 Memory: Step 1: Navigate to Amazon's website. Open tab to Amazon's main page.
INFO [agent] 🎯 Next goal: Navigate to Amazon's website by opening the following URL: https://www.amazon.com/.
INFO [agent] 🛠️ Action 1/1: {"go_to_url":{"url":"https://www.amazon.com/"}}
INFO [controller] 🔗 Navigated to https://www.amazon.com/
INFO [agent] 📍 Step 2
INFO [agent] 👍 Eval: Success - Navigated to Amazon homepage. The search bar is available for input.
INFO [agent] 🧠 Memory: On the Amazon homepage, ready to search for items. 0 out of 2 items added to cart.
INFO [agent] 🎯 Next goal: Search for the 'PlayStation 5 (Slim) console' in the search bar.
INFO [agent] 🛠️ Action 1/2: {"input_text":{"index":2,"text":"PlayStation 5 (Slim) console"}}
INFO [agent] 🛠️ Action 2/2: {"click_element_by_index":{"index":4}}
INFO [controller] ⌨️ Input PlayStation 5 (Slim) console into index 2
INFO [agent] Something new appeared after action 1 / 2
# Omitted for brevity...
INFO [agent] 📍 Step 14
INFO [agent] 👍 Eval: Success - Extracted the order summary from the cart page.
INFO [agent] 🧠 Memory: Amazon cart page shows both items: PlayStation 5 Slim and Astro Bot PS5 game added successfully. Extracted item names, quantities, costs, subtotal, and delivery details.
INFO [agent] 🎯 Next goal: Finalize the task by summarizing the order details.
INFO [agent] 🛠️ Action 1/1: {"done":{"text":"Order Summary:nnItems in Cart:n1. Name: Astro Bot PS5n Quantity: 11n Cost: $58.95nn2. Name: PlayStation®5 console (slim)n Quantity: 1n Cost: $499.00nnSubtotal: $557.95nDelivery Details: Your order qualifies for FREE Shipping. Choose this option at checkout.nnTotal Cost: $557.95","success":true}}
INFO [agent] 📄 Result: Order Summary:
Items in Cart:
1. Name: Astro Bot PS5
Quantity: 1
Cost: $58.95
2. Name: PlayStation®5 console (slim)
Quantity: 1
Cost: $499.00
Subtotal: $557.95
Delivery Details: Your order qualifies for FREE Shipping. Choose this option at checkout.Como você pode ver, o agente de IA encontrou com sucesso os itens desejados, adicionou-os ao carrinho e gerou um resumo limpo. Tudo isso sem bloqueios ou proibições da Amazon, graças ao Scraping Browser!
O browser-use também inclui recursos para gravar a sessão do navegador para fins de depuração. Embora isso ainda não funcione com o navegador remoto, se funcionasse, você veria uma reprodução fascinante do agente de IA em ação:
Verdadeiramente hipnótico – e um vislumbre empolgante de quão longe a navegação com IA chegou.
Etapa #10: Próximas etapas
O agente de IA da Amazon que criamos aqui é apenas um ponto de partida – uma prova de conceito para mostrar o que é possível. Para torná-lo pronto para a produção, apresentamos abaixo várias ideias de aprimoramento:
- Conecte-se à sua conta da Amazon: Permita que o agente faça login, para que ele possa acessar recursos personalizados, como histórico de pedidos e recomendações.
- Implementar um fluxo de trabalho de compra: Amplie o agente para concluir de fato as compras. Isso inclui a seleção de opções de envio, a aplicação de códigos promocionais ou cartões-presente e a confirmação do pagamento.
- Enviar uma confirmação ou relatório por e-mail: Antes de finalizar qualquer transação de pagamento, o agente pode enviar por e-mail um resumo detalhado do carrinho e das ações pretendidas para aprovação do usuário. Isso mantém você no controle e acrescenta uma camada de responsabilidade.
- Ler itens de uma lista de desejos ou de uma lista de entrada: Faça com que o agente carregue itens dinamicamente de uma lista de desejos salva da Amazon, de um arquivo local (por exemplo, JSON ou CSV) ou de um endpoint de API remoto.
Conclusão
Nesta publicação do blog, você aprendeu a usar a popular biblioteca browse-use em combinação com uma API de navegador de raspagem para criar um agente de IA altamente eficaz em Python.
Conforme demonstrado, a combinação do Browse Use com o navegador de raspagem da Bright Data permite que você crie agentes de IA que podem interagir de forma confiável com praticamente qualquer site. Esse é apenas um exemplo de como as ferramentas e os serviços da Bright Data podem capacitar a automação avançada orientada por IA.
Explore nossas soluções para o desenvolvimento de agentes de IA:
- Agentes autônomos de IA: Pesquise, acesse e interaja com qualquer site em tempo real usando um conjunto avançado de APIs.
- Aplicativos de IA verticais: crie pipelines de dados confiáveis e personalizados para extrair dados da Web de fontes específicas do setor.
- Modelos básicos: Acesse conjuntos de dados compatíveis e em escala da Web para potencializar o pré-treinamento, a avaliação e o ajuste fino.
- IA multimodal: aproveite o maior repositório do mundo de imagens, vídeos e áudio otimizados para IA.
- Provedores de dados: Conecte-se com provedores confiáveis para obter conjuntos de dados de alta qualidade e prontos para IA em escala.
- Pacotes de dados: Obtenha conjuntos de dados com curadoria, prontos para uso, estruturados, enriquecidos e anotados.
Para obter mais informações, explore nosso hub de IA.
Crie uma conta na Bright Data e experimente todos os nossos produtos e serviços para o desenvolvimento de agentes de IA!




