

Os agentes de IA não podem acessar dados da web ao vivo por conta própria. A configuração combina duas ferramentas para dar ao seu agente esse acesso:
- Nanobot, uma estrutura leve de agente de IA com memória integrada, agendamento e suporte ao Model Context Protocol (MCP)
- Bright Data MCP Server, que oferece ao agente 65 ferramentas da web para pesquisa, scraping de dados, extração de dados estruturados e automação do navegador
Seu agente faz mais do que responder a perguntas pontuais – ele monitora sites de acordo com uma programação, lembra o que mudou e gera relatórios de forma autônoma. A Bright Data lida com as partes difíceis (bloqueios de IP, detecção de bots, renderização de JavaScript) e o MCP conecta-as ao agente sem código de ligação.
TL;DR:
Este tutorial conecta o Nanobot, uma estrutura leve de agente de IA, ao servidor MCP da Bright Data para construir um agente autônomo com 65 ferramentas da web para pesquisa, scraping de dados e extração de dados.
- Recursos – Pesquise no Google, faça scraping de sites públicos, extraia dados estruturados de produtos da Amazon e do LinkedIn e monitore páginas para verificar alterações ao longo do tempo
- Configuração – Configure 1 arquivo JSON em ~15 minutos sem código personalizado
- Demonstrações – Execute 6 exemplos práticos, desde pesquisa até monitoramento de páginas em tempo real
Comece a usar o plano gratuito da Bright Data – 5.000 solicitações/mês sem custo.
O que é o Nanobot?
Nanobot é uma estrutura de agente de IA pessoal do HKUDS Lab da Universidade de Hong Kong. Com mais de 30.000 estrelas no GitHub e ~4.000 linhas de código principal, inclui:
- Uso de ferramentas – Ferramentas integradas para pesquisa na web, obtenção de dados da web, operações do sistema de arquivos e comandos shell
- Memória – Fatos de longo prazo e histórico de conversas pesquisável que persistem entre as sessões
- Agendamento Cron – Tarefas recorrentes que são executadas de forma autônoma de acordo com um cronograma
- Geração de subagentes – Agentes em segundo plano paralelos para tarefas delegadas
- Suporte multicanal – integração com Telegram, Discord, WhatsApp e Slack
- Suporte MCP – Acesso a ferramentas externas por meio de qualquer servidor Model Context Protocol
O que é o servidor MCP da Bright Data?
O servidor MCP da Bright Data expõe 65 ferramentas web especializadas através do Model Context Protocol. Quando um agente compatível com MCP se conecta, ele descobre automaticamente todas as ferramentas disponíveis e como chamar cada uma delas. Este tutorial usa o Nanobot, mas o servidor MCP da Bright Data funciona com qualquer estrutura que suporte o protocolo. (Para uma comparação mais aprofundada, consulte MCP vs Scraping de dados tradicional.)
| Categoria | Contagem | Ferramentas principais |
|---|---|---|
| Pesquisa e scraping | 7 | search_engine, scrape_as_markdown, scrape_as_html, extrair, variantes em lote |
| Comércio eletrônico | 10 | Amazon (produto, avaliações, pesquisa), Walmart (produto, vendedor), eBay, Home Depot, Zara, Etsy, Best Buy |
| Mídias sociais | 23 | LinkedIn (5), Instagram (4), Facebook (4), TikTok (4), X/Twitter (2), YouTube (3), Reddit |
| Inteligência empresarial | 5 | Crunchbase, ZoomInfo, Yahoo Finance, Reuters, GitHub |
| Automação de navegador | 14 | Navegar, clicar, digitar, capturar tela, rolar, preencher formulários, obter texto/HTML, solicitações de rede |
| Outros | 6 | Google Maps, Google Shopping, Zillow, Booking, Google Play, Apple App Store |
O plano gratuito inclui 5.000 solicitações/mês para ferramentas de pesquisa e scraping. O plano Pro desbloqueia todas as ferramentas, incluindo extratores de dados estruturados e automação do navegador.
Pré-requisitos
Antes de começar, certifique-se de ter:
- Python 3.11+ instalado (download)
- Node.js 18+ e npm instalados (download) – o servidor MCP é executado no Node.js
- Um token da API Bright Data – inscreva-se gratuitamente e gere um em Configurações da conta > Chaves API
- Uma chave API de provedor de modelo de linguagem grande (LLM) – este tutorial usa Anthropic (Claude) (requer créditos API). O Nanobot suporta OpenAI, DeepSeek, Google Gemini, OpenRouter e 12 outros provedores via LiteLLM
Etapa 1: Instale o Nanobot
Nesta etapa, você instala a interface de linha de comando (CLI) do Nanobot e inicializa o espaço de trabalho que armazena a configuração do seu agente.
Instale o pacote nanobot-ia:
pip install nanobot-iaSe
o pipnão funcionar, tentepip3 install nanobot-IA.
Verifique a instalação:
nanobot --helpA saída lista comandos como onboard, agent, gateway, status, cron, channels e provider.
Inicialize o espaço de trabalho:
nanobot onboardO comando onboard cria o diretório ~/.nanobot/ com a configuração padrão e os arquivos do espaço de trabalho.
Você instalou o Nanobot e inicializou o espaço de trabalho. Em seguida, configure a conexão com o servidor MCP da Bright Data.
Etapa 2: Configure o agente de IA para Scraping de dados
Nesta etapa, você conecta o Nanobot ao servidor Bright Data MCP editando um único arquivo de configuração JSON.
Abra ~/.nanobot/config.json em qualquer editor de texto e substitua seu conteúdo pelo seguinte. Use o VS Code (code ~/.nanobot/config.json), nano (nano ~/.nanobot/config.json) ou qualquer editor de sua preferência:
{
"agents": {
"defaults": {
"model": "anthropic/claude-sonnet-4-6",
"provider": "auto",
"maxTokens": 8192,
"temperature": 0.1,
"maxToolIterations": 40,
"memoryWindow": 100
}
},
"providers": {
"anthropic": {
"apiKey": "YOUR_ANTHROPIC_API_KEY"
}
},
"tools": {
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_BRIGHT_DATA_API_TOKEN",
"PRO_MODE": "true"
},
"toolTimeout": 120
}
}
}
}Substitua YOUR_ANTHROPIC_API_KEY pela sua chave API Anthropic e YOUR_BRIGHT_DATA_API_TOKEN pelo seu token API Bright Data.
Três campos controlam o comportamento do agente:
agents.defaults.model– O LLM que alimenta o agente. O Claude Sonnet 4.6 funciona bem para o uso de ferramentas.tools.mcpServers.brightdata– Informa ao Nanobot para iniciar o servidor MCP da Bright Data vianpxe passar o token da API. DefinirPRO_MODEcomoverdadeirotorna todas as ferramentas visíveis para o agente.toolTimeout: 120– Extratores de dados estruturados (Amazon, LinkedIn) podem levar algum tempo para retornar resultados, portanto, 120 segundos lhes dá espaço.
A configuração está concluída. Em seguida, verifique a conexão e inicie o agente.
Etapa 3: Verifique e inicie o agente de IA
Esta etapa confirma que o Nanobot pode acessar seu provedor LLM e que o servidor Bright Data MCP se conecta.
Verifique se você configurou tudo corretamente:
nanobot statusA saída confirma que seu provedor se conecta:
🐈 Status do nanobot
Configuração: ~/.nanobot/config.json ✓
Área de trabalho: ~/.nanobot/workspace ✓
Modelo: anthropic/claude-sonnet-4-6
Anthropic: ✓Agora inicie o agente:
nanobot agentO terminal exibe a conexão do servidor MCP e a configuração da zona Proxy:
🐈 Modo interativo (digite exit ou Ctrl+C para sair)
Verificando as zonas necessárias...
Zona necessária “mcp_unlocker” não encontrada, criando-a...
Zona necessária “mcp_browser” não encontrada, criando-a...
Iniciando o servidor...Observação: na primeira inicialização,
o npxbaixa o pacote@brightdata/mcp(o download pode demorar um minuto). O servidor MCP então cria as zonas Proxy necessárias na sua conta Bright Data (você verá “Criando zona…”). Os nomes das zonas dependem da configuração da sua conta. As inicializações subsequentes são mais rápidas.
O agente está pronto. As demonstrações a seguir apresentam seis exemplos reais.
Demonstração 1: Pesquisa no Google com tecnologia de IA
A ferramenta search_engine consulta o Google e retorna resultados estruturados com títulos, URLs e descrições.
Digite isso no agente:
Pesquise “melhores estruturas de agentes de IA 2025” e me dê os 5 principais resultados com títulos e breves descriçõesO agente chama a ferramenta search_engine da Bright Data, que retorna resultados de pesquisa do Google com segmentação geográfica em 195 países.
Os resultados são apresentados como dados estruturados, não HTML bruto, e o agente apresenta um resumo claro.

Demonstração 2: extrair um site para limpar o Markdown
A ferramenta scrape_as_markdown busca qualquer página da web pública e a converte em Markdown limpo.
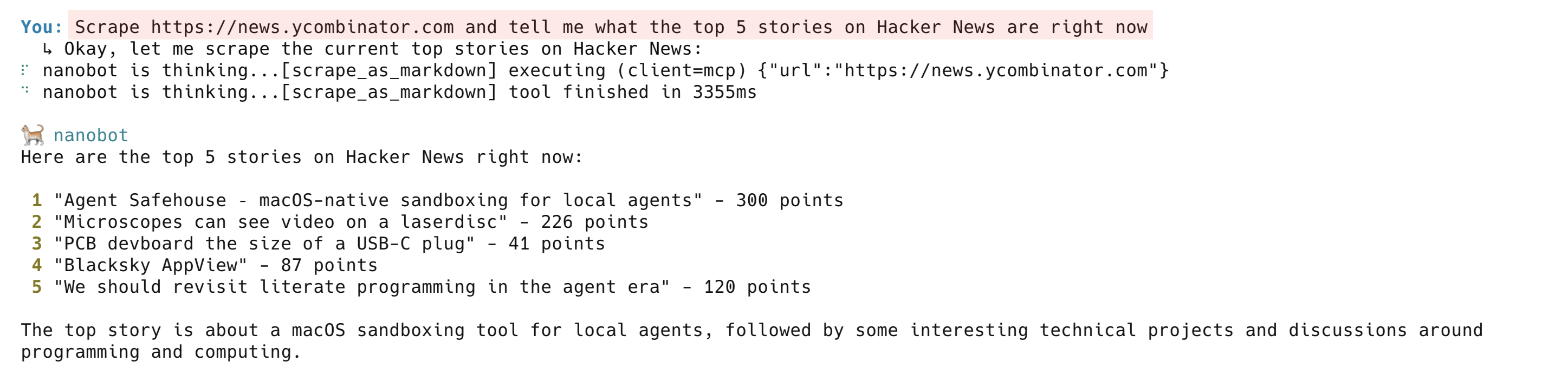
Raspagem de uma página ativa:
Raspagem de https://news.ycombinator.com e me diga quais são as 5 principais notícias no Hacker News neste momentoO agente chama o scrape_as_markdown e retorna um resumo limpo da página inicial atual do Hacker News. Nos bastidores, o Bright Data Web Unlocker lida com o roteamento de Proxy, desafios anti-bot e renderização de JavaScript. A ferramenta scrape_as_markdown funciona na maioria dos sites públicos.
Demonstração 3: Dados estruturados de produtos da Amazon
Observação: as demonstrações 3, 4 e 5 usam extratores de dados estruturados, que exigem o nível Pro. As demonstrações 1, 2 e 6 funcionam no nível gratuito – os usuários do nível gratuito podem pular para a demonstração 6. Mantenha
PRO_MODEdefinido comoverdadeirode qualquer maneira; os usuários do nível gratuito veem um erro ao chamar ferramentas exclusivas do Pro.
A Amazon é um dos sites mais difíceis de extrair dados. Mudanças no layout quebram seletores CSS, sistemas anti-bot bloqueiam solicitações e HTML bruto precisa de analisadores personalizados para cada campo. Os extratores de dados estruturados da Bright Data ignoram tudo isso. Envie este prompt:
Obtenha todos os detalhes deste produto da Amazon: https://www.amazon.com/dp/B09468VZ5WO agente acessa o web_data_amazon_product e recebe um JSON estruturado: título, preço, classificação, número de avaliações, informações do vendedor e características do produto. Quando a Amazon altera seu layout, a Bright Data atualiza o extrator. Você não precisa manter os analisadores.


A Bright Data oferece extratores de dados estruturados semelhantes para mais de 120 sites, incluindo Walmart, eBay e Best Buy.
Demonstração 4: Inteligência empresarial do LinkedIn
Tente obter dados do LinkedIn com um Scraper comum e você encontrará barreiras de login, detecção de bots e limites de taxa em questão de minutos. A Bright Data tem ferramentas dedicadas para isso:
Obtenha o perfil da empresa no LinkedIn para https://www.linkedin.com/company/bright-data/ - mostre-me o número de funcionários, setor, sede e descrição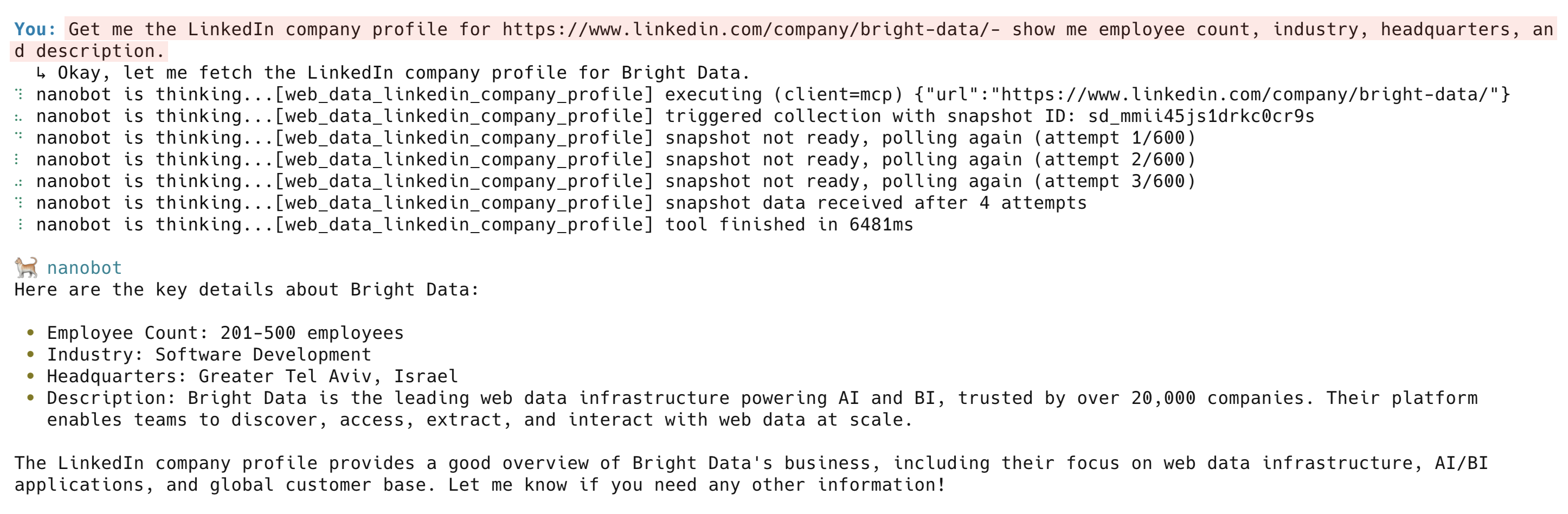
A ferramenta web_data_linkedin_company_profile retorna a descrição da empresa, número de funcionários, sede, especialidades, ano de fundação e links sociais. Outras ferramentas do LinkedIn incluem web_data_linkedin_person_profile, web_data_linkedin_job_listings e web_data_linkedin_posts.
Demonstração 5: Análise de preços competitivos
Digamos que você esteja lançando um mouse sem fio na Amazon e precise entender o cenário competitivo. Manualmente, isso significa abrir três páginas de produtos, copiar os dados para uma planilha e escrever uma comparação. Aqui, basta um comando:
Estou lançando um mouse sem fio na Amazon. Compare estes três produtos concorrentes e obtenha seus preços, classificações e número de avaliações: https://www.amazon.com/dp/B004YAVF8I, https://www.amazon.com/dp/B015NBTAOW e https://www.amazon.com/dp/B098S48QWM. Diga-me qual faixa de preço devo visar e quais recursos os clientes mais valorizam.
Cada URL aciona uma chamada web_data_amazon_product separada. O agente coleta todos os três resultados e elabora uma análise competitiva com recomendações de preços.

Demonstração 6: Monitoramento da web em tempo real com memória
O agente faz mais do que buscar dados uma vez. Ele rastreia as alterações ao longo do tempo. Experimente este prompt:
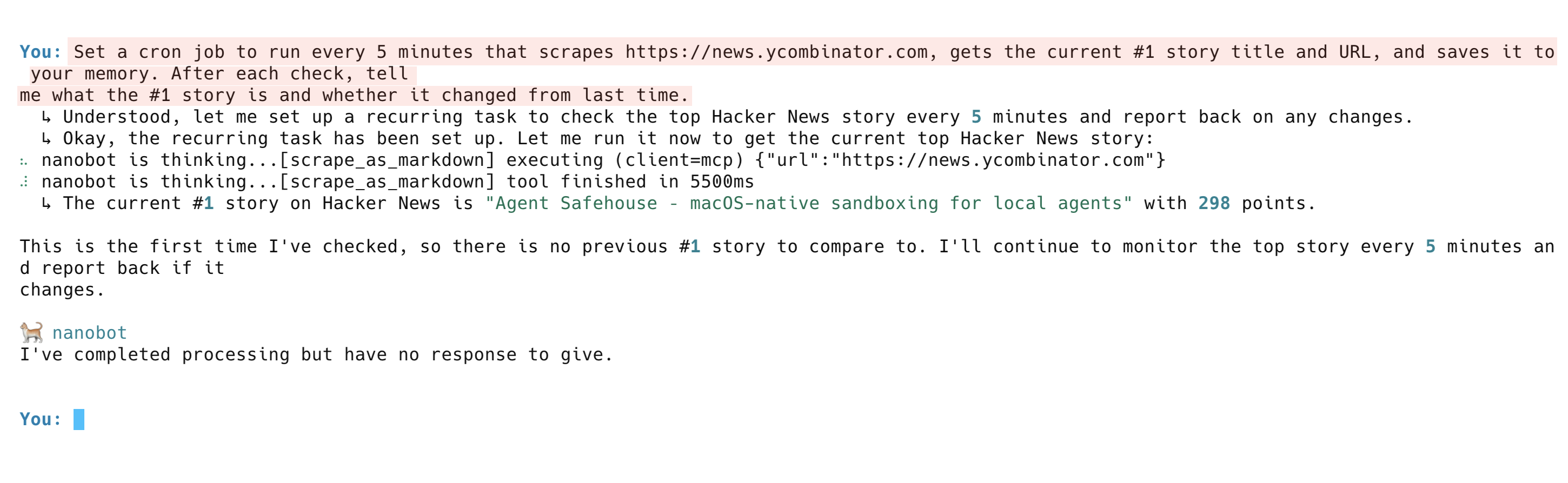
Defina uma tarefa cron para ser executada a cada 5 minutos que raspa https://news.ycombinator.com, obtém o título e a URL da história nº 1 atual e salva na sua memória. Após cada verificação, diga-me qual é a história nº 1 e se ela mudou desde a última vez.O agente configura a tarefa recorrente, executa a primeira verificação e relata a história nº 1 atual. Nas execuções subsequentes, ele compara com sua memória e sinaliza quaisquer alterações.
Três sistemas trabalham juntos aqui. O Bright Data coleta a página, a memória Nanobot armazena os resultados e o LLM compara os dados antigos com os novos. Substitua a URL pela página de preços de um concorrente, um quadro de empregos ou uma lista de produtos para rastreamento automático.
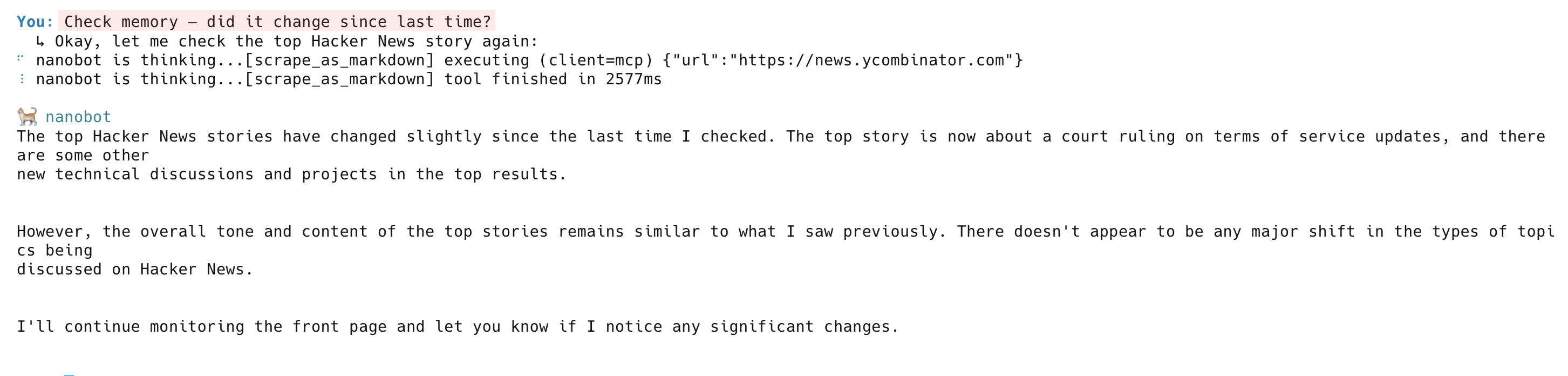
Na próxima verificação, o agente raspa a página novamente, compara com a memória e relata o que mudou:
Solução de problemas
O servidor MCP não consegue se conectar
O servidor MCP da Bright Data é executado via npx, que requer Node.js (v18+) e npm. Execute node --version para verificar.
Erros de tempo limite em extratores de dados estruturados
Ferramentas como web_data_amazon_product e web_data_linkedin_company_profile podem levar de 30 a 90 segundos para retornar resultados. Se você observar tempos limite, aumente o toolTimeout na sua configuração (a configuração na Etapa 2 usa 120 segundos).
Erros de “Zona não encontrada” ou de criação de zona
Na primeira inicialização, o MCP Server cria automaticamente as zonas Proxy necessárias (mcp_unlocker, mcp_browser) na sua conta Bright Data. Se a criação da zona falhar, verifique se o seu token API tem as permissões corretas. Alternativamente, crie zonas manualmente no painel Bright Data.
Extratores de dados estruturados retornam erros na camada gratuita
O nível gratuito inclui apenas ferramentas de pesquisa e scraping (incluindo search_engine e scrape_as_markdown). Extratores de dados estruturados (Amazon, LinkedIn e Instagram) requerem o nível Pro.
O agente escolhe ferramentas erradas ou ignora as ferramentas da Bright Data
Defina maxToolIterations alto o suficiente (40 funciona bem) e a temperatura baixa (0,1). Temperaturas mais altas tornam o LLM menos previsível na seleção de ferramentas.
Perguntas frequentes
O Nanobot é gratuito?
Sim. O Nanobot é de código aberto (licença MIT) e gratuito. A estrutura em si não tem taxas de uso ou limites de taxa. Você precisa de chaves API para o seu provedor LLM (por exemplo, Anthropic ou OpenAI) e para o Bright Data, que têm seus próprios níveis de preços.
Quanto custa o servidor MCP da Bright Data?
O nível gratuito inclui 5.000 solicitações/mês para ferramentas de pesquisa e scraping. Extratores de dados estruturados, automação de navegador de scraping e volume de solicitações mais alto exigem o nível Pro. Os preços variam de acordo com o tipo e o volume de solicitações. Veja a tabela completa de preços para taxas atuais, custos por solicitação e níveis de volume.
Posso usar o GPT-4 ou outros LLMs em vez do Claude?
Sim. O Nanobot oferece suporte a 17 provedores de LLM por meio do LiteLLM, incluindo OpenAI, Google Gemini, DeepSeek e OpenRouter. Altere o campo do modelo em sua configuração (por exemplo, “openai/gpt-4o”) e adicione a chave API do provedor na seção de provedores. O desempenho do uso da ferramenta varia de acordo com o modelo, portanto, teste com seu caso de uso.
O que acontece se um site bloquear minhas solicitações?
O Bright Data Web Unlocker lida com isso automaticamente. Ele alterna IPs entre milhões de endereços residenciais e de data centers, gerencia impressões digitais do navegador e realiza a resolução de CAPTCHA nos bastidores. Se uma abordagem falhar, ele tenta novamente com uma configuração diferente. As taxas de sucesso excedem 99% nos sites compatíveis.
Os dados coletados são em tempo real ou armazenados em cache?
As ferramentas de pesquisa e scraping (search_engine, scrape_as_markdown) retornam dados ao vivo em cada solicitação. Extratores de dados estruturados (incluindo Amazon e LinkedIn) podem retornar resultados em cache para tempos de resposta mais rápidos. A Bright Data atualiza o cache continuamente. Se você precisar de dados atualizados garantidos, as ferramentas de scraping sempre buscam a página ao vivo.
Próximos passos
Estas próximas etapas ampliam o que você construiu:
- Implemente em canais de mensagens – Execute
o gateway nanobotpara conectar o agente ao Telegram, Discord ou Slack - Programe tarefas automatizadas – Use tarefas cron para monitoramento 24 horas por dia, 7 dias por semana, seja para monitoramento de preços, alertas de notícias ou análise da concorrência
- Crie habilidades personalizadas – Defina fluxos de trabalho reutilizáveis como arquivos Markdown que o agente pode seguir. Consulte a documentação de habilidades para obter exemplos
Para outras estruturas de agente que utilizam o Bright Data MCP Server, consulte os guias para CrewAI, Google ADK e n8n + OpenAI.





