

A raspagem da Web está em um momento decisivo, pois os métodos tradicionais estão sendo frustrados por sofisticadas defesas antibot e os desenvolvedores estão constantemente corrigindo scripts frágeis. Embora eles ainda funcionem, suas limitações são claras, especialmente em comparação com infraestruturas de raspagem modernas e nativas de IA que oferecem resiliência e escalabilidade. Com o mercado de agentes de IA definido para crescer de US$ 7,84 bilhões para US$ 52,62 bilhões até 2030, o futuro do acesso aos dados está nos sistemas inteligentes e autônomos.
Ao combinar a estrutura de agente autônomo da CrewAI com a infraestrutura robusta da Bright Data, você obtém uma pilha de raspagem que raciocina e supera as barreiras anti-bot. Neste tutorial, você criará um agente de raspagem com tecnologia de IA que fornece dados confiáveis e em tempo real.
Os limites da raspagem antiga
A raspagem tradicional é frágil, pois depende de seletores estáticos de CSS ou XPath que quebram com qualquer ajuste de front-end. Os principais desafios incluem:
- Defesas anti-bot. CAPTCHAs, limitação de IP e impressão digital bloqueiam rastreadores simples.
- Páginas com muito JavaScript. O React, o Angular e o Vue constroem o DOM no navegador, portanto, as chamadas HTTP brutas perdem a maior parte do conteúdo.
- HTML não estruturado. HTML inconsistente e dados em linha dispersos exigem análise e pós-processamento pesados antes do uso.
- Gargalos de dimensionamento. A orquestração de proxies, novas tentativas e aplicação contínua de patches se transforma em uma carga operacional exaustiva e interminável.
Como a CrewAI e a Bright Data simplificam a raspagem
A construção de um raspador autônomo depende de dois pilares: um “cérebro” adaptável e um “corpo” resistente.
- CrewAI (O cérebro). Um runtime multiagente de código aberto em que você cria uma “equipe” de agentes que pode planejar, raciocinar e coordenar trabalhos de raspagem de ponta a ponta.
- MCP da Bright Data (O corpo). Um gateway de dados em tempo real que encaminha cada solicitação por meio da pilha Unlocker da Bright Data – IPs rotativos, resolução de CAPTCHAs e execução de navegadores sem cabeça – para que os LLMs recebam HTML ou JSON limpos de uma só vez. A implementação da Bright Data é a fonte líder do setor de dados confiáveis para agentes de IA.
Juntos, essa combinação de cérebro e corpo permite que seus agentes pensem, recuperem e se adaptem em praticamente qualquer local.
O que é a CrewAI?
O CrewAI é uma estrutura de código aberto para orquestrar agentes de IA cooperativos. Você define a função, o objetivo e as ferramentas de cada agente e, em seguida, agrupa-os em uma equipe para executar fluxos de trabalho de várias etapas.
Componentes principais:
- Agente. Um trabalhador orientado por LLM com uma função, um objetivo e uma história de fundo opcional, fornecendo o contexto do domínio do modelo.
- Tarefa. Um trabalho único e bem dimensionado para um agente, além de um expected_output que serve como porta de qualidade.
- Ferramenta. Qualquer chamável que o agente possa invocar – uma busca HTTP, uma consulta ao banco de dados ou o ponto de extremidade MCP da Bright Data para raspagem.
- Equipe. O conjunto de agentes e suas tarefas trabalhando em prol de um objetivo.
- Processo. O plano de execução – sequencial, paralelo ou hierárquico – que controla a ordem das tarefas, a delegação e as novas tentativas.
Isso espelha uma equipe de verdade: os especialistas lidam com sua fatia, encaminham os resultados e escalam quando necessário.
O que é o protocolo de contexto de modelo (MCP)?
O MCP é um padrão JSON-RPC 2.0 aberto que permite que os agentes de IA chamem ferramentas e fontes de dados externas por meio de uma interface única e estruturada. Pense nisso como uma porta USB-C para modelos: um plugue, muitos dispositivos.
O servidor MCP da Bright Data transforma esse padrão em prática ao conectar um agente diretamente à pilha de raspagem da Bright Data, tornando a raspagem da Web com o MCP não apenas mais avançada, mas muito mais simples do que as pilhas tradicionais:
- Contorno de anti-bot. As solicitações fluem por meio do Web Unlocker e de um pool de mais de 150 milhões de IPs residenciais rotativos, abrangendo 195 países.
- Suporte a sites dinâmicos. Um navegador de raspagem desenvolvido especificamente renderiza JavaScript, para que os agentes vejam o DOM totalmente carregado.
- Resultados estruturados. Muitas ferramentas retornam JSON limpo, eliminando analisadores personalizados.
O servidor publica mais de 50 ferramentas prontas, desde buscas genéricas de URL até raspadores específicos de sites, para que seu agente CrewAI possa obter preços de produtos, dados de SERP ou instantâneos de DOM com uma única chamada.
Criando seu primeiro agente de raspagem de IA
Vamos criar um agente CrewAI que extrai detalhes de uma página de produto da Amazon e os retorna como JSON estruturado. Você pode facilmente redirecionar a mesma pilha para outro site ajustando apenas algumas linhas.
Pré-requisitos
- Python 3.11 – Recomendado para estabilidade.
- Node.js + npm – Necessário para executar o servidor Bright Data MCP; faça o download no site oficial.
- Ambiente virtual Python – Mantém as dependências isoladas; consulte a documentação do
venv. - Conta da Bright Data – Inscreva-se e crie um token de API (créditos de avaliação gratuitos estão disponíveis).
- Chave de API do Google Gemini – Crie uma chave no Google AI Studio (clique em + Criar chave de API). A camada gratuita permite 15 solicitações por minuto e 500 solicitações por dia. Não é necessário um perfil de faturamento.
Visão geral da arquitetura
Environment Setup → LLM Config → MCP Server Init →
Agent Definition → Task Definition → Crew Execution → JSON OutputEtapa 1. Configuração e importação de ambiente
mkdir crewai-bd-scraper && cd crewai-bd-scraper
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install "crewai-tools[mcp]" crewai mcp python-dotenv
from crewai import Agent, Task, Crew, Process
from crewai_tools import MCPServerAdapter
from mcp import StdioServerParameters
from crewai.llm import LLM
import os
from dotenv import load_dotenv
load_dotenv() # Load credentials from .envEtapa 2. Configurar chaves e zonas da API
Crie um arquivo .env na raiz do seu projeto:
BRIGHT_DATA_API_TOKEN="…"
WEB_UNLOCKER_ZONE="…"
BROWSER_ZONE="…"
GEMINI_API_KEY="…"Você precisa:
- Token de API. Gerar um novo token de API.
- Zona do Web Unlocker. Crie uma nova zona de Web Unlocker. Se omitido, uma zona padrão chamada
mcp_unlockerserá criada para você. - Zona da API do navegador. Crie uma nova zona de API do navegador. Necessária apenas para alvos com muito JavaScript. Copie a string de nome de usuário mostrada na guia Overview (Visão geral) da zona.
- Chave da API do Google Gemini. Já criada em Pré-requisitos.
Etapa 3. Configuração do LLM (Gemini)
Configure o LLM (Gemini 1.5 Flash) para saída determinística:
llm = LLM(
model="gemini/gemini-1.5-flash",
api_key=os.getenv("GEMINI_API_KEY"),
temperature=0.1,
)Etapa 4. Configuração do Bright Data MCP
Configure o servidor MCP da Bright Data. Isso informa ao CrewAI como iniciar o servidor e passar as credenciais:
server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": os.getenv("WEB_UNLOCKER_ZONE"),
"BROWSER_ZONE": os.getenv("BROWSER_ZONE"),
},
)Isso inicia o *npx @brightdata/mcp* como um subprocesso e expõe mais de 50 ferramentas (≈ 57 no momento da redação) por meio do padrão MCP.
Etapa 5. Definição do agente e da tarefa
Aqui, definimos a persona do agente e a tarefa específica que ele precisa realizar. As implementações eficazes da CrewAI seguem a regra 80/20: dedicar 80% do esforço ao design da tarefa e 20% à definição do agente.
def build_scraper_agent(mcp_tools):
return Agent(
role="Senior E-commerce Data Extractor",
goal=(
"Return a JSON object with snake_case keys containing: title, current_price, "
"original_price, discount, rating, review_count, last_month_bought, "
"availability, product_id, image_url, brand, and key_features for the "
"target product page. Ensure strict schema validation."
),
backstory=(
"Veteran web-scraping engineer with years of experience reverse-"
"engineering Amazon, Walmart, and Shopify layouts. Skilled in "
"Bright Data MCP, proxy rotation, CAPTCHA avoidance, and strict "
"JSON-schema validation."
),
tools=mcp_tools,
llm=llm,
max_iter=3,
verbose=True,
)
def build_scraping_task(agent):
return Task(
description=(
"Extract product data from https://www.amazon.in/dp/B071Z8M4KX "
"and return it as structured JSON."
),
expected_output="""{
"title": "Product name",
"current_price": "$99.99",
"original_price": "$199.99",
"discount": "50%",
"last_month_bought": 150,
"rating": 4.5,
"review_count": 1000,
"availability": "In Stock",
"product_id": "ABC123",
"image_url": "https://example.in/image.jpg",
"brand": "BrandName",
"key_features": ["Feature 1", "Feature 2"],
}""",
agent=agent,
)Veja a seguir o que cada parâmetro faz:
- role – Título de trabalho curto, que a CrewAI injeta em cada prompt do sistema.
- meta – objetivo da estrela do norte; a CrewAI compara-o após cada loop para decidir se deve parar.
- backstory – contexto de domínio que orienta o tom e reduz as alucinações.
- tools – Lista de objetos
BaseTool(por exemplo, MCPsearch_engine,scrape_as_markdown). - llm – Modelo que o CrewAI usa para cada ciclo pensar → planejar → agir → responder.
- max_iter – Limite rígido dos loops internos do agente (padrão 20 na versão 0.30+).
- verbose – Transmite cada prompt, pensamento e chamada de ferramenta para stdout (útil para depuração).
- Descrição – A instrução orientada para a ação é injetada a cada turno.
- expected_output – Contrato formal de uma resposta válida (use JSON estrito, sem vírgula à direita).
- agent – Vincula essa tarefa a uma instância específica do
agenteparaCrew.kickoff().
Etapa 6. Montagem e execução da equipe
Essa parte reúne o agente e a tarefa em um Crew e executa o fluxo de trabalho.
def scrape_product_data():
"""Assembles and runs the scraping crew."""
with MCPServerAdapter(server_params) as mcp_tools:
scraper_agent = build_scraper_agent(mcp_tools)
scraping_task = build_scraping_task(scraper_agent)
crew = Crew(
agents=[scraper_agent],
tasks=[scraping_task],
process=Process.sequential,
verbose=True
)
return crew.kickoff()
if __name__ == "__main__":
try:
result = scrape_product_data()
print("n[SUCCESS] Scraping completed!")
print("Extracted product data:")
print(result)
except Exception as e:
print(f"n[ERROR] Scraping failed: {str(e)}")Etapa 7. Execução do raspador
Execute o script em seu terminal. Você verá o processo de pensamento do agente no console à medida que ele planeja e executa a tarefa.
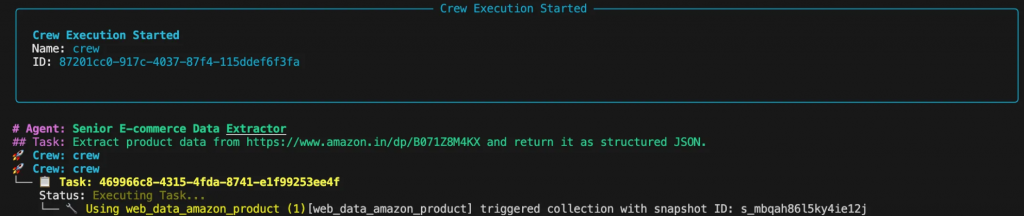
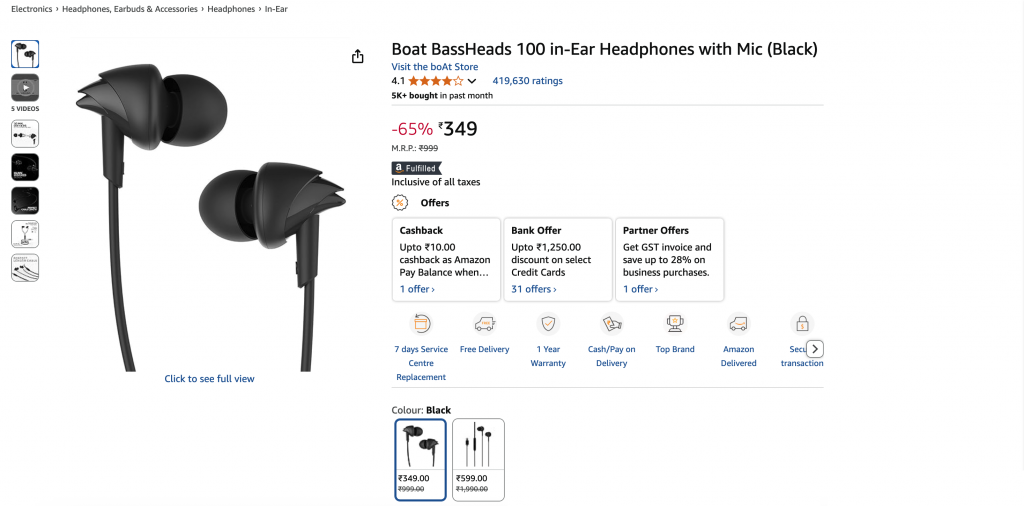
A saída final será um objeto JSON limpo:
{
"title": "Boat BassHeads 100 in-Ear Headphones with Mic (Black)",
"current_price": "₹349",
"original_price": "₹999",
"discount": "-65%",
"rating": 4.1,
"review_count": 419630,
"last_month_bought": 5000,
"availability": "In stock",
"product_id": "B071Z8M4KX",
"image_url": "https://m.media-amazon.com/images/I/513ugd16C6L._SL1500_.jpg",
"brand": "boAt",
"key_features": [
"10mm dynamic driver",
"HD microphone",
"1.2 m cable",
"Comfortable fit",
"1 year warranty"
]
}Adaptação a outras metas
O verdadeiro ponto forte de um design baseado em agentes é sua flexibilidade. Deseja extrair postagens do LinkedIn em vez de produtos da Amazon? Basta atualizar a função, o objetivo e a história do agente, além da descrição da tarefa e do expected_output. Todo o resto, inclusive o código e a infraestrutura subjacentes, permanece exatamente o mesmo.
role = "Senior LinkedIn Post Extractor"
goal = (
"Return a JSON object containing: author_name, author_title, "
"author_profile_url, post_content, post_date, likes_count, "
"and comments_count"
)
backstory = (
"Seasoned social-data engineer specializing in LinkedIn data "
"extraction using Bright Data MCP. Produces clean, structured "
"JSON output."
)
description = (
"Extract post data from LinkedIn post (ID: orlenchner_agents-"
"brightdata-activity-7336402761892122625-h5Oa) and return "
"structured JSON."
)
expected_output = """{
"author_name": "Post author's full display name",
"author_title": "Author's job title/headline",
"author_profile_url": "Author's profile URL",
"post_content": "Complete post text with formatting",
"post_date": "ISO 8601 UTC timestamp",
"likes_count": "Number of post likes",
"comments_count": "Number of post comments",
}"""A saída será um objeto JSON limpo:
{
"author_name": "Or Lenchner",
"author_title": "CEO at Bright Data - Keeping public web data, public.",
"author_profile_url": "https://il.linkedin.com/in/orlenchner",
"post_content": "NEW PRODUCT! There’s a consensus that the future internet will be run by automated #Agents , automating the activity on behalf of “their” humans. AI solved the automation part (or at least shows strong indications), but the number one problem is ensuring smooth access to every website at scale without being blocked. browser.ai is the solution → Your Agent always gains access to any website with a simple prompt. Agents using Bright Data are already executing hundreds of millions of web actions daily on our browser infrastructure. #BrightData has long been the go-to for major LLM companies, providing the tools and scale they need to train and deploy such technologies. With browser.ai , we’re taking that foundation and tailoring it specifically for AI agents, optimizing our APIs, proxy networks, and serverless browsers to handle their unique demands. The web isn’t fully prepared for this shift yet, but we are. browser.ai immediate focus is to ensure *smooth* access to any website (DONE!), while phase two will be all about *fast* access (wip). https://browser.ai/",
"post_date": "2026-06-05T14:45:22.155Z",
"likes_count": 119,
"comments_count": 7
}Otimização de custos
O MCP da Bright Data é baseado no uso, portanto, cada solicitação extra aumenta sua conta. Algumas opções de design mantêm os custos sob controle:
- Raspagem direcionada. Solicite apenas os campos de que você precisa, em vez de rastrear páginas ou conjuntos de dados inteiros.
- Cache. Ative o cache em nível de ferramenta do CrewAI
(cache_function) para ignorar chamadas quando o conteúdo não tiver sido alterado, economizando tempo e créditos. - Seleção eficiente de ferramentas. Usar como padrão a zona do Web Unlocker e alternar para uma zona da API do navegador somente quando a renderização de JavaScript for essencial.
- Definir
max_iter. Dê a cada agente um limite superior sensato para que ele não fique em loop infinito em uma página quebrada. (Você também pode limitar as solicitações commax_rpm).
Siga essas práticas e seus agentes CrewAI permanecerão seguros, confiáveis e econômicos, prontos para cargas de trabalho de produção no Bright Data MCP.
O que vem a seguir
O ecossistema MCP continua se expandindo: A API Responses da OpenAI e o SDK Gemini do Google DeepMind agora falam MCP nativamente, garantindo compatibilidade de longo prazo e investimento contínuo.
A CrewAI está implementando agentes multimodais, depuração mais avançada e RBAC empresarial, enquanto o servidor MCP da Bright Data expõe mais de 60 ferramentas prontas e continua crescendo.
Juntos, os frameworks de agentes e o acesso padronizado a dados desbloqueiam uma nova onda de inteligência da Web para aplicativos com tecnologia de IA. Os guias sobre como conectar o MCP ao SDK do OpenAI Agents destacam como os canais de dados sólidos se tornaram essenciais.
Em última análise, você não está apenas criando um raspador – está orquestrando um fluxo de trabalho de dados adaptável criado para a Web do futuro.
Precisa de mais escala? Evite a manutenção de scrapers e o combate a bloqueios – basta solicitar dados estruturados:
- Crawl API – extração de site completo em escala.
- APIs do Web Scraper – mais de 120 pontos de extremidade específicos de domínio.
- API SERP – raspagem de mecanismo de pesquisa sem complicações.
- Dataset Marketplace – conjuntos de dados novos e validados sob demanda.
Pronto para criar aplicativos de IA de última geração? Explore o conjunto completo de produtos de IA da Bright Data e veja o que o acesso à Web ao vivo e sem interrupções faz por seus agentes. Para obter informações mais detalhadas, consulte nossos guias MCP para Qwen-Agent e Google ADK.






