

Neste guia, vamos abordar a criação de um servidor MCP local em Python para extrair dados de produtos da Amazon sob demanda. Você aprenderá os fundamentos do MCP, como escrever e executar seu próprio servidor e como conectá-lo a ferramentas de desenvolvedor como o Claude Desktop e o Cursor IDE. Concluiremos com uma integração real do Bright Data MCP para dados da Web prontos para IA em tempo real.
Vamos nos aprofundar no assunto.
O gargalo: Por que os LLMs têm dificuldades com a interação no mundo real (e como o MCP resolve isso)
Os modelos de linguagem grandes (LLMs) são incrivelmente poderosos no processamento e na geração de texto a partir de conjuntos de dados de treinamento em massa. Mas eles vêm com uma limitação importante: não podem interagir nativamente com o mundo real. Isso significa que não há acesso a arquivos locais, não há execução de scripts personalizados nem busca de dados ao vivo na Web.
Veja um exemplo simples: peça ao Claude para extrair detalhes do produto de uma página ativa da Amazon, e ele não conseguirá. Por quê? Porque ele não tem a capacidade integrada de navegar na Web ou acionar ações externas.

Sem ferramentas externas, os LLMs não podem realizar tarefas práticas que dependem de dados em tempo real ou de integração com sistemas externos.
É aí que entra o protocolo de contexto de modelo (MCP) do Anthropic. Ele permite que os LLMs se comuniquem com ferramentas externas – como scrapers, APIs ou scripts – de forma segura e padronizada.
Aqui está a diferença em ação. Após a integração de um servidor MCP personalizado, conseguimos extrair dados estruturados de produtos da Amazon diretamente por meio do Claude:

Não se preocupe com o funcionamento ainda, pois explicaremos tudo passo a passo mais adiante no guia.
Por que o MCP é importante?
- Padronização: O MCP forneceu uma interface padronizada para que os sistemas baseados no LLM se conectem a ferramentas e dados externos, semelhante à forma como as APIs padronizam as integrações da Web. Isso reduz drasticamente a necessidade de integrações personalizadas, acelerando o desenvolvimento.
- Flexibilidade e escalabilidade: Os desenvolvedores podem trocar LLMs ou plataformas de hospedagem sem reescrever as integrações de ferramentas. O MCP oferece suporte a vários transportes de comunicação (como
stdio), o que o torna adaptável a diferentes configurações. - Recursos aprimorados do LLM: Ao conectar os LLMs a dados em tempo real e ferramentas externas, o MCP permite que eles vão além das respostas estáticas. Agora, eles podem retornar informações atuais e relevantes e acionar ações do mundo real com base no contexto.
Analogia: Pense no MCP como uma interface USB para LLMs. Assim como o USB permite que diferentes dispositivos (teclados, impressoras, unidades externas) sejam conectados a qualquer máquina compatível sem a necessidade de drivers especiais, o MCP permite que os LLMs se conectem a uma ampla gama de ferramentas usando um protocolo padronizado, sem a necessidade de integração personalizada a cada vez.
O que é o protocolo de contexto de modelo (MCP)?
O MCP (Model Context Protocol) é um padrão aberto desenvolvido pela Anthropic que permite que grandes modelos de linguagem (LLMs) interajam com ferramentas externas, APIs e fontes de dados de forma consistente e segura. Ele atua como um conector universal, permitindo que os LLMs executem tarefas do mundo real, como raspagem de sites, consulta a bancos de dados ou acionamento de scripts.
Embora tenha sido introduzido pela Anthropic, o MCP é aberto e extensível, o que significa que qualquer pessoa pode implementar ou contribuir com o padrão. Se você já trabalhou com o Retrieval-Augmented Generation (RAG), vai gostar do conceito. O MCP se baseia nessa ideia padronizando as interações por meio de uma interface JSON-RPC leve para que os modelos possam acessar dados em tempo real e realizar ações.
Arquitetura MCP: Como funciona
Em sua essência, o MCP padroniza a comunicação entre um modelo de IA e os recursos externos.
Ideia principal: Uma interface padronizada (geralmente JSON-RPC 2.0 sobre transportes como stdio) permite que um LLM (por meio de um cliente) descubra e invoque ferramentas expostas por servidores externos.
A MCP opera por meio de uma arquitetura cliente-servidor com três componentes principais:
- Host do MCP: O ambiente ou aplicativo que inicia e gerencia as interações entre o LLM e as ferramentas externas. Os exemplos incluem assistentes de IA como o Claude Desktop ou IDEs como o Cursor.
- Cliente MCP: Um componente dentro do host que estabelece e mantém conexões com os servidores MCP, manipulando os protocolos de comunicação e gerenciando a troca de dados.
- Servidor MCP: Um programa (que nós, desenvolvedores, criamos) que implementa o protocolo MCP e expõe um conjunto específico de recursos. Um servidor MCP pode fazer interface com um banco de dados, um serviço da Web ou, no nosso caso, um site (Amazon). Os servidores expõem sua funcionalidade de maneiras padronizadas
: Polylang placeholder não modificar
Aqui está o diagrama de arquitetura do MCP:

Fonte da imagem: Protocolo de contexto de modelo
Nessa configuração, o host (Claude Desktop ou Cursor IDE) gera um cliente MCP, que então se conecta a um servidor MCP externo. Esse servidor expõe ferramentas, recursos e prompts, permitindo que a IA interaja com eles conforme necessário.
Em resumo, o fluxo de trabalho funciona da seguinte forma:
- O usuário envia uma mensagem como “Fetch product info from this Amazon link”.
- O cliente MCP verifica se há uma ferramenta registrada que possa lidar com essa tarefa
- O cliente envia uma solicitação estruturada ao servidor MCP
- O servidor MCP executa a ação apropriada (por exemplo, iniciar um navegador sem cabeça)
- O servidor retorna resultados estruturados para o cliente MCP
- O cliente encaminha os resultados para o LLM, que os apresenta ao usuário
Criação de um servidor MCP personalizado
Vamos criar um servidor Python MCP para extrair as páginas de produtos da Amazon.

Esse servidor exporá duas ferramentas: uma para baixar HTML e outra para extrair informações estruturadas. Você interagirá com o servidor por meio de um cliente LLM no Cursor ou no Claude Desktop.
Etapa 1: Configuração do ambiente
Primeiro, verifique se você tem o Python 3 instalado. Em seguida, crie e ative um ambiente virtual:
python -m venv mcp-amazon-scraper
# On macOS/Linux:
source mcp-amazon-scraper/bin/activate
# On Windows:
.mcp-amazon-scraperScriptsactivateInstale as bibliotecas necessárias: MCP Python SDK, Playwright e LXML.
pip install mcp playwright lxml
# Install browser binaries for Playwright
python -m playwright installIsso instala:
- mcp: SDK Python para servidores e clientes do Model Context Protocol que lida com todos os detalhes da comunicação JSON-RPC
- playwright: Biblioteca de automação do navegador que fornece recursos de navegador sem cabeça para renderização e raspagem de sites com muito JavaScript
- lxml: Biblioteca de análise rápida de XML/HTML que facilita a extração de elementos de dados específicos de páginas da Web usando consultas XPath
Em resumo, o MCP Python SDK(mcp) lida com todos os detalhes do protocolo, permitindo que você exponha ferramentas que o Claude ou o Cursor possam chamar por meio de prompts de linguagem natural. O Playwright nos permite renderizar completamente as páginas da Web (inclusive o conteúdo JavaScript), e o lxml nos fornece recursos avançados de análise de HTML.
Etapa 2: inicializar o servidor MCP
Crie um arquivo Python chamado amazon_scraper_mcp.py. Comece importando os módulos necessários e inicializando o servidor FastMCP:
import os
import asyncio
from lxml import html as lxml_html
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
# Define a temporary file path for the HTML content
HTML_FILE = os.path.join(os.getenv("TMPDIR", "/tmp"), "amazon_product_page.html")
# Initialize the MCP server with a descriptive name
mcp = FastMCP("Amazon Product Scraper")
print("MCP Server Initialized: Amazon Product Scraper")Isso cria uma instância do servidor MCP. Agora, adicionaremos ferramentas a ela.
Etapa 3: implementar a ferramenta fetch_page
Essa ferramenta receberá um URL como entrada, usará o Playwright para navegar até a página, aguardará o carregamento do conteúdo, baixará o HTML e o salvará em nosso arquivo temporário.
@mcp.tool()
async def fetch_page(url: str) -> str:
"""
Fetches the HTML content of the given Amazon product URL using Playwright
and saves it to a temporary file. Returns a status message.
"""
print(f"Executing fetch_page for URL: {url}")
try:
async with async_playwright() as p:
# Launch headless Chromium browser
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate to the URL with a generous timeout
await page.goto(url, timeout=90000, wait_until="domcontentloaded")
# Wait for a key element (e.g., body) to ensure basic loading
await page.wait_for_selector("body", timeout=30000)
# Add a small delay for any dynamic content rendering via JavaScript
await asyncio.sleep(5)
html_content = await page.content()
with open(HTML_FILE, "w", encoding="utf-8") as f:
f.write(html_content)
await browser.close()
print(f"Successfully fetched and saved HTML to {HTML_FILE}")
return f"HTML content for {url} downloaded and saved successfully to {HTML_FILE}."
except Exception as e:
error_message = f"Error fetching page {url}: {str(e)}"
print(error_message)
return error_messageEssa função assíncrona usa o Playwright para lidar com a possível renderização de JavaScript nas páginas da Amazon. O decorador @mcp.tool() registra essa função como uma ferramenta que pode ser chamada em nosso servidor.
Etapa 4: implementar a ferramenta extract_info
Essa ferramenta lê o arquivo HTML salvo por fetch_page, analisa-o usando seletores LXML e XPath e retorna um dicionário que contém os detalhes extraídos do produto.
def _extract_xpath(tree, xpath, default="N/A"):
"""Helper function to extract text using XPath, returning default if not found."""
try:
# Use text_content() to get text from node and children, strip whitespace
result = tree.xpath(xpath)
if result:
return result[0].text_content().strip()
return default
except Exception:
return default
def _extract_price(price_str):
"""Helper function to parse price string into a float."""
if price_str == "N/A":
return None
try:
# Remove currency symbols and commas, handle potential whitespace
cleaned_price = "".join(filter(str.isdigit or str.__eq__("."), price_str))
return float(cleaned_price)
except (ValueError, TypeError):
return None
@mcp.tool()
def extract_info() -> dict:
"""
Parses the saved HTML file (downloaded by fetch_page) to extract
Amazon product details like title, price, rating, features, etc.
Returns a dictionary of the extracted data.
"""
print(f"Executing extract_info from file: {HTML_FILE}")
if not os.path.exists(HTML_FILE):
return {
"error": f"HTML file not found at {HTML_FILE}. Please run fetch_page first."
}
try:
with open(HTML_FILE, "r", encoding="utf-8") as f:
page_html = f.read()
tree = lxml_html.fromstring(page_html)
# --- XPath Selectors for Amazon Product Details ---
title = _extract_xpath(tree, '//span[@id="productTitle"]')
# Handle different price structures (main price, sale price)
price_whole = _extract_xpath(tree, '//span[contains(@class, "a-price-whole")]')
price_fraction = _extract_xpath(
tree, '//span[contains(@class, "a-price-fraction")]'
)
price_str = (
f"{price_whole}.{price_fraction}"
if price_whole != "N/A"
else _extract_xpath(tree, '//span[contains(@class,"a-offscreen")]')
) # Fallback to offscreen if needed
price = _extract_price(price_str)
# Original price (strike-through)
original_price_str = _extract_xpath(
tree, '//span[@class="a-price a-text-price"]//span[@class="a-offscreen"]'
)
original_price = _extract_price(original_price_str)
# Rating
rating_text = _extract_xpath(tree, '//span[@id="acrPopover"]/@title')
rating = None
if rating_text != "N/A":
try:
rating = float(rating_text.split()[0])
except (ValueError, IndexError):
rating = None
# Review Count
reviews_text = _extract_xpath(tree, '//span[@id="acrCustomerReviewText"]')
review_count = None
if reviews_text != "N/A":
try:
review_count = int(reviews_text.split()[0].replace(",", ""))
except (ValueError, IndexError):
review_count = None
# Availability
availability = _extract_xpath(
tree,
'//div[@id="availability"]//span/text()',
)
# Features (bullet points)
feature_elements = tree.xpath(
'//div[@id="feature-bullets"]//li//span[@class="a-list-item"]'
)
features = [
elem.text_content().strip()
for elem in feature_elements
if elem.text_content().strip()
]
# Calculate Discount
discount = None
if price and original_price and original_price > price:
discount = round(((original_price - price) / original_price) * 100)
extracted_data = {
"title": title,
"price": price,
"original_price": original_price,
"discount_percent": discount,
"rating_stars": rating,
"review_count": review_count,
"features": features,
"availability": availability.strip(),
}
print(f"Successfully extracted data: {extracted_data}")
return extracted_data
except Exception as e:
error_message = f"Error parsing HTML: {str(e)}"
print(error_message) # Added for logging
return {"error": error_message}Essa função usa o fromstring do LXML para analisar o HTML e seletores XPath robustos para encontrar os elementos desejados
Etapa 5: Executar o servidor
Por fim, adicione as seguintes linhas ao final do script amazon_scraper_mcp.py para iniciar o servidor usando o mecanismo de transporte stdio, que é padrão para servidores MCP locais que se comunicam com clientes como o Claude Desktop ou o Cursor.
if __name__ == "__main__":
print("Starting MCP Server with stdio transport...")
# Run the server, listening via standard input/output
mcp.run(transport="stdio")Código completo(amazon_scraper_mcp.py)
import os
import asyncio
from lxml import html as lxml_html
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
# Define a temporary file path for the HTML content
HTML_FILE = os.path.join(os.getenv("TMPDIR", "/tmp"), "amazon_product_page.html")
# Initialize the MCP server with a descriptive name
mcp = FastMCP("Amazon Product Scraper")
print("MCP Server Initialized: Amazon Product Scraper")
@mcp.tool()
async def fetch_page(url: str) -> str:
"""
Fetches the HTML content of the given Amazon product URL using Playwright
and saves it to a temporary file. Returns a status message.
"""
print(f"Executing fetch_page for URL: {url}")
try:
async with async_playwright() as p:
# Launch headless Chromium browser
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate to the URL with a generous timeout
await page.goto(url, timeout=90000, wait_until="domcontentloaded")
# Wait for a key element (e.g., body) to ensure basic loading
await page.wait_for_selector("body", timeout=30000)
# Add a small delay for any dynamic content rendering via JavaScript
await asyncio.sleep(5)
html_content = await page.content()
with open(HTML_FILE, "w", encoding="utf-8") as f:
f.write(html_content)
await browser.close()
print(f"Successfully fetched and saved HTML to {HTML_FILE}")
return f"HTML content for {url} downloaded and saved successfully to {HTML_FILE}."
except Exception as e:
error_message = f"Error fetching page {url}: {str(e)}"
print(error_message)
return error_message
def _extract_xpath(tree, xpath, default="N/A"):
"""Helper function to extract text using XPath, returning default if not found."""
try:
# Use text_content() to get text from node and children, strip whitespace
result = tree.xpath(xpath)
if result:
return result[0].text_content().strip()
return default
except Exception:
return default
def _extract_price(price_str):
"""Helper function to parse price string into a float."""
if price_str == "N/A":
return None
try:
# Remove currency symbols and commas, handle potential whitespace
cleaned_price = "".join(filter(str.isdigit or str.__eq__("."), price_str))
return float(cleaned_price)
except (ValueError, TypeError):
return None
@mcp.tool()
def extract_info() -> dict:
"""
Parses the saved HTML file (downloaded by fetch_page) to extract
Amazon product details like title, price, rating, features, etc.
Returns a dictionary of the extracted data.
"""
print(f"Executing extract_info from file: {HTML_FILE}")
if not os.path.exists(HTML_FILE):
return {
"error": f"HTML file not found at {HTML_FILE}. Please run fetch_page first."
}
try:
with open(HTML_FILE, "r", encoding="utf-8") as f:
page_html = f.read()
tree = lxml_html.fromstring(page_html)
# --- XPath Selectors for Amazon Product Details ---
title = _extract_xpath(tree, '//span[@id="productTitle"]')
# Handle different price structures (main price, sale price)
price_whole = _extract_xpath(tree, '//span[contains(@class, "a-price-whole")]')
price_fraction = _extract_xpath(
tree, '//span[contains(@class, "a-price-fraction")]'
)
price_str = (
f"{price_whole}.{price_fraction}"
if price_whole != "N/A"
else _extract_xpath(tree, '//span[contains(@class,"a-offscreen")]')
) # Fallback to offscreen if needed
price = _extract_price(price_str)
# Original price (strike-through)
original_price_str = _extract_xpath(
tree, '//span[@class="a-price a-text-price"]//span[@class="a-offscreen"]'
)
original_price = _extract_price(original_price_str)
# Rating
rating_text = _extract_xpath(tree, '//span[@id="acrPopover"]/@title')
rating = None
if rating_text != "N/A":
try:
rating = float(rating_text.split()[0])
except (ValueError, IndexError):
rating = None
# Review Count
reviews_text = _extract_xpath(tree, '//span[@id="acrCustomerReviewText"]')
review_count = None
if reviews_text != "N/A":
try:
review_count = int(reviews_text.split()[0].replace(",", ""))
except (ValueError, IndexError):
review_count = None
# Availability
availability = _extract_xpath(
tree,
'//div[@id="availability"]//span/text()',
)
# Features (bullet points)
feature_elements = tree.xpath(
'//div[@id="feature-bullets"]//li//span[@class="a-list-item"]'
)
features = [
elem.text_content().strip()
for elem in feature_elements
if elem.text_content().strip()
]
# Calculate Discount
discount = None
if price and original_price and original_price > price:
discount = round(((original_price - price) / original_price) * 100)
extracted_data = {
"title": title,
"price": price,
"original_price": original_price,
"discount_percent": discount,
"rating_stars": rating,
"review_count": review_count,
"features": features,
"availability": availability.strip(),
}
print(f"Successfully extracted data: {extracted_data}")
return extracted_data
except Exception as e:
error_message = f"Error parsing HTML: {str(e)}"
print(error_message) # Added for logging
return {"error": error_message}
if __name__ == "__main__":
print("Starting MCP Server with stdio transport...")
# Run the server, listening via standard input/output
mcp.run(transport="stdio")Integração de seu servidor MCP personalizado
Agora que o script do servidor está pronto, vamos conectá-lo aos clientes MCP, como o Claude Desktop e o Cursor.
Conexão com o Claude Desktop
Etapa 1: Abra o Claude Desktop.
Etapa 2: Navegue até Settings -> Developer -> Edit Config. Isso abrirá o arquivo claude_desktop_config.json em seu editor de texto padrão.

Etapa 3: adicione uma entrada para seu servidor na chave mcpServers. Certifique-se de substituir o caminho em args pelo caminho absoluto para o arquivo amazon_scraper_mcp.py.
{
"mcpServers": {
"amazon_product_scraper": {
"command": "python", // Or python3 if needed
"args": ["/full/path/to/your/amazon_scraper_mcp.py"], // <-- IMPORTANT: Use the correct absolute path
}
}
}Etapa 4: Salve o arquivo claude_desktop_config.json, feche completamente e reabra o Claude Desktop para que as alterações tenham efeito.
Etapa 5: No Claude Desktop, você deverá ver um pequeno ícone de ferramentas (como um martelo 🔨) na área de entrada do bate-papo.
Etapa 6: Clique nele para listar seu “Amazon Product Scraper” com suas ferramentas fetch_page e extract_info.

Etapa 7: Envie um Prompt, por exemplo: “Get the current price, original price, and rating for this Amazon product: https://www.amazon.com/dp/B09C13PZX7″.
Etapa 8: O Claude detectará que isso requer ferramentas externas e solicitará sua permissão para executar primeiro o fetch_page e depois o extract_info. Clique em “Allow for this chat” para cada ferramenta.

Etapa 9: Após conceder as permissões, o servidor MCP executará as ferramentas. Em seguida, o Claude receberá os dados estruturados e os apresentará no chat.

Ótimo, você criou e integrou com sucesso seu primeiro servidor MCP!
Conexão com o Cursor
O processo do Cursor (um IDE com IA em primeiro lugar) é semelhante.
Etapa 1: Abra o Cursor.
Etapa 2: Vá para Settings (Configurações ) ⚙️ e navegue até a seção MCP.

Etapa 3: Clique em “+Add a new global MCP Server” (Adicionar um novo servidor MCP global). Isso abrirá o arquivo de configuração mcp.json. Adicione uma entrada para seu servidor, novamente usando o caminho absoluto para seu script.
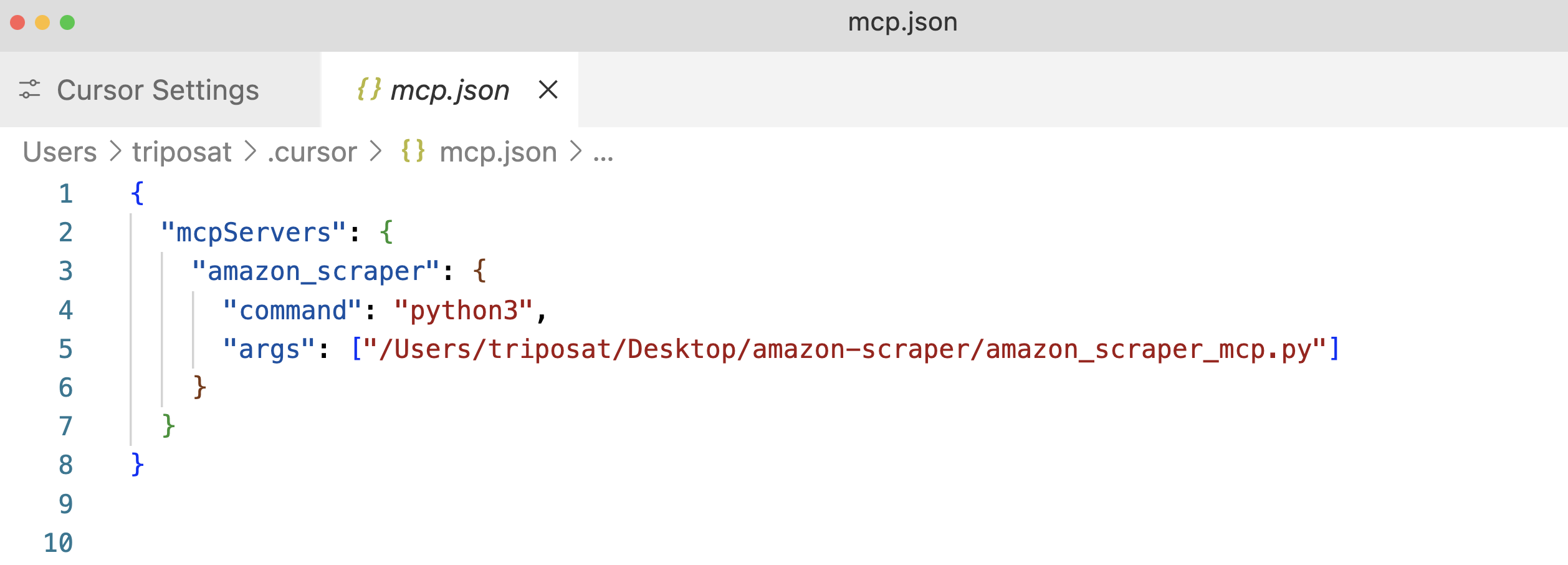
Etapa 4: Salve o arquivo mcp.json e você deverá ver seu “amazon_product_scraper” listado, com um ponto verde indicando que ele está em execução e conectado.

Etapa 5: use o recurso de bate-papo do Cursor(Cmd+l ou Ctrl+l).
Etapa 6: Envie um prompt, por exemplo: “Extraia todos os dados de produtos disponíveis deste URL da Amazon: https://www.amazon.com/dp/B09C13PZX7. Formate a saída como um objeto JSON estruturado”.
Etapa 7: De forma semelhante ao Claude Desktop, o Cursor solicitará permissão para executar as ferramentas fetch_page e extract_info. Aprovar essas solicitações (“Run Tool”).
Etapa 8: O Cursor exibirá o fluxo de interação, mostrando as chamadas para suas ferramentas MCP e, por fim, apresentando os dados JSON estruturados retornados por sua ferramenta extract_info.

Aqui está um exemplo de saída JSON do Cursor:
{
"title": "Razer Basilisk V3 Customizable Ergonomic Gaming Mouse: Fastest Gaming Mouse Switch - Chroma RGB Lighting - 26K DPI Optical Sensor - 11 Programmable Buttons - HyperScroll Tilt Wheel - Classic Black",
"price": 39.99,
"original_price": 69.99,
"discount_percent": 43,
"rating_stars": 4.6,
"review_count": 7782,
"features": [
"ICONIC ERGONOMIC DESIGN WITH THUMB REST — PC gaming mouse favored by millions worldwide with a form factor that perfectly supports the hand while its buttons are optimally positioned for quick and easy access",
"11 PROGRAMMABLE BUTTONS — Assign macros and secondary functions across 11 programmable buttons to execute essential actions like push-to-talk, ping, and more",
"HYPERSCROLL TILT WHEEL — Speed through content with a scroll wheel that free-spins until its stopped or switch to tactile mode for more precision and satisfying feedback that's ideal for cycling through weapons or skills",
"11 RAZER CHROMA RGB LIGHTING ZONES — Customize each zone from over 16.8 million colors and countless lighting effects, all while it reacts dynamically with over 150 Chroma integrated games",
"OPTICAL MOUSE SWITCHES GEN 2 — With zero unintended misclicks these switches provide crisp, responsive execution at a blistering 0.2ms actuation speed for up to 70 million clicks",
"FOCUS+ 26K DPI OPTICAL SENSOR — Best-in-class mouse sensor with intelligent functions flawlessly tracks movement with zero smoothing, allowing for crisp response and pixel-precise accuracy",
// ... (other features)
],
"availability": "In Stock"
}Isso mostra a flexibilidade do MCP – o mesmo servidor funciona perfeitamente com diferentes aplicativos clientes.
Integração do MCP da Bright Data para extração de dados da Web orientada por IA
Os servidores MCP personalizados oferecem controle total, mas apresentam desafios, como gerenciar a infraestrutura de proxy, lidar com mecanismos anti-bot sofisticados e garantir a escalabilidade. A Bright Data aborda esses problemas com sua solução MCP pré-construída de nível de produção, projetada para uma integração perfeita com agentes de IA e LLMs.
A integração do protocolo de contexto de modelo (MCP) com a Bright Data oferece aos LLMs e aos agentes de IA acesso contínuo e em tempo real a dados públicos da Web, adaptados para fluxos de trabalho de IA. Ao se conectar ao MCP da Bright Data, seus aplicativos e modelos podem recuperar resultados de SERP de todos os principais mecanismos de pesquisa e desbloquear perfeitamente o acesso a sites de difícil acesso.
A solução MCP (Model Context Protocol) da Bright Data conecta seu aplicativo a um conjunto de ferramentas poderosas de extração de dados da Web, incluindo Web Unlocker, SERP API, Web Scraper API e Scraping Browser, fornecendouma infraestrutura abrangente que:
- Fornece dados prontos para IA: Obtém e formata automaticamente o conteúdo da Web, reduzindo as etapas extras de pré-processamento.
- Garante a escalabilidade e a confiabilidade: Utiliza uma infraestrutura robusta para lidar com grandes volumes de solicitações sem comprometer o desempenho.
- Contorna bloqueios e CAPTCHAs: Usa estratégias avançadas anti-bot para navegar e recuperar conteúdo até mesmo dos sites mais protegidos.
- Oferece cobertura global de IP: Usa uma vasta rede de proxy que abrange 195 países para acessar conteúdo com restrição geográfica.
- Simplifica a integração: Minimiza o esforço de configuração ao trabalhar perfeitamente com qualquer cliente MCP.
Pré-requisitos para o Bright Data MCP
Antes de começar a integrar o Bright Data MCP, verifique se você tem o seguinte:
- Conta da Bright Data: Registre-se em brightdata.com. Os novos usuários recebem créditos gratuitos para testes.
- Token de API: Obtenha seu token de API nas configurações de sua conta Bright Data(página de configurações do usuário).
- Zona do Web Unlocker: Crie uma zona de proxy do Web Unlocker no painel de controle da Bright Data. Dê a ela um nome memorável, como
mcp_unlocker(você pode substituir isso posteriormente por meio de variáveis de ambiente, se necessário). - (Opcional) Zona do navegador de raspagem: se precisar de recursos avançados de automação do navegador (por exemplo, para interações complexas de JavaScript ou capturas de tela), crie uma zona do navegador de raspagem. Observe os detalhes de autenticação (nome de usuário e senha) fornecidos para essa zona (na guia Visão geral ), geralmente no formato
brd-customer-ACCOUNT_ID-zone-ZONE_NAME:PASSWORD.
Início rápido: Configuração do Bright Data MCP para o Claude Desktop
Etapa 1: O servidor Bright Data MCP normalmente é executado usando o npx, que vem com o Node.js. Instale o Node.js, se ainda não o tiver feito, no site oficial.
Etapa 2: Abra o Claude Desktop -> Configurações -> Desenvolvedor -> Editar configuração(claude_desktop_config.json).
Etapa 3: adicione a configuração do servidor Bright Data em mcpServers. Substitua os espaços reservados por suas credenciais reais.
{
"mcpServers": {
"Bright Data": { // Choose a name for the server
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_BRIGHTDATA_API_TOKEN", // Paste your API token here
"WEB_UNLOCKER_ZONE": "mcp_unlocker", // Your Web Unlocker zone name
// Optional: Add if using Scraping Browser tools
"BROWSER_AUTH": "brd-customer-ACCOUNTID-zone-YOURZONE:PASSWORD"
}
}
}
}Etapa 4: Salve o arquivo de configuração e reinicie o Claude Desktop.
Etapa 5: Passe o mouse sobre o ícone do martelo (🔨) no Claude Desktop. Agora você deve ver várias ferramentas do MCP.

Vamos tentar extrair dados do Zillow, um site conhecido por potencialmente bloquear scrapers. Solicite ao claude “Extrair dados de propriedades-chave no formato JSON deste URL do Zillow: https://www.zillow.com/apartments/arverne-ny/the-tides-at-arverne-by-the-sea/ChWHPZ/”

Permitir que o Claude use as ferramentas necessárias do Bright Data MCP. O servidor MCP da Bright Data cuidará das complexidades subjacentes (rotação de proxy, renderização de JavaScript por meio do navegador de raspagem, se necessário).
O servidor da Bright Data realiza a extração e retorna dados estruturados, que são apresentados por Claude.

Aqui está um trecho do resultado potencial:
{
"propertyInfo": {
"name": "The Tides At Arverne By The Sea",
"address": "190 Beach 69th St, Arverne, NY 11692",
"propertyType": "Apartment building",
// ... more info
},
"rentPrices": {
"studio": { "startingPrice": "$2,750", /* ... */ },
"oneBed": { "startingPrice": "$2,900", /* ... */ },
"twoBed": { "startingPrice": "$3,350", /* ... */ }
},
// ... amenities, policies, etc.
}Isso é fantástico!
Outro exemplo: Manchetes do Hacker News
Uma consulta mais simples:“Dê-me os títulos dos últimos 5 artigos de notícias do Hacker News“.

Isso mostra como o servidor MCP da Bright Data simplifica o acesso até mesmo ao conteúdo dinâmico ou altamente protegido da Web diretamente no seu fluxo de trabalho de IA.
Conclusão
Conforme exploramos ao longo deste guia, o protocolo de contexto de modelo do Anthropic representa uma mudança fundamental na forma como os sistemas de IA interagem com o mundo externo. Como vimos, você pode criar servidores MCP personalizados para tarefas específicas, como o nosso coletor de dados da Amazon. A integração do MCP da Bright Data melhora ainda mais isso, oferecendo recursos de raspagem da Web de nível empresarial que contornam as proteções antibot e fornecem dados estruturados prontos para IA.
Também selecionamos a dedo alguns dos melhores recursos sobre IA e modelos de linguagem grandes (LLMs). Não deixe de dar uma olhada neles para se aprofundar no assunto:






