

Neste artigo, você aprenderá tudo sobre o RAG, incluindo seu papel no aprimoramento das respostas do LLM e seus componentes.
O que é RAG
RAG é uma técnica de aprendizado de máquina (ML) que leva os LLMs tradicionais um passo adiante, vinculando-os a sistemas de pesquisa (também conhecidos como recuperação). Em vez de depender apenas de seus dados de treinamento fixos, os modelos alimentados por RAG podem acessar fontes externas — como bancos de dados, documentos ou até mesmo a web — para encontrar informações relevantes e melhorar a qualidade de suas respostas. Essa combinação de recuperação de informações instantâneas e geração de linguagem torna as respostas mais precisas e atualizadas.
Recuperação + Geração
O RAG funciona combinando três partes: um sistema de pesquisa ou recuperação, o próprio modelo de linguagem e um processo que combina os dois. Quando recebe uma pergunta, o sistema RAG primeiro usa o componente de recuperação para encontrar dados relevantes fora do conjunto de dados de treinamento do modelo de linguagem. Em seguida, o prompt original é modificado para ser complementado com esses dados. O prompt atualizado é passado para o componente de geração (o LLM), que usa seus próprios padrões aprendidos e conteúdo novo para fornecer uma resposta. Dessa forma, o resultado não é apenas um produto do treinamento pré-existente — ele se baseia em informações reais e verificadas, extraídas diretamente das fontes.
O RAG combina de forma inteligente o poder da recuperação e da geração, oferecendo uma solução inteligente para as deficiências dos modelos de linguagem tradicionais. Ele fornece respostas mais confiáveis e precisas e pode se adaptar a diferentes tópicos, tornando-o ideal para aplicações em que as informações precisam ser atuais ou especializadas.
Por que os LLMs precisam de aprimoramento
Embora os LLMs sejam impressionantes na geração de respostas semelhantes às humanas, eles não são isentos de falhas.
Risco de alucinações
Um dos maiores desafios dos LLMs é o risco de alucinações, em que o modelo gera informações convincentes, mas incorretas. Isso acontece porque os LLMs são treinados em grandes Conjuntos de dados estáticos e não têm acesso em tempo real a atualizações ou fatos fora de sua janela de treinamento.
Além disso, se você observar atentamente, os LLMs não são máquinas de resolução de problemas; eles são modelos de preenchimento de texto. Seu objetivo final é gerar uma resposta que mais se assemelhe à resposta correta para o prompt fornecido; a resposta não precisa necessariamente ser correta. Como eles não usam algoritmos determinísticos para chegar a uma resposta,eles estão fadados a ter alucinaçõesem algum momento.
Verificação de informações
Além disso, os LLMs não podem verificar novas informações ou comparar suas respostas com fontes ao vivo, o que facilita a omissão ou deturpação dos fatos.
Limitação de conhecimento
Outra limitação é o corte de conhecimento. Como os LLMs são treinados com dados que vão apenas até um certo ponto, eles inerentemente não têm conhecimento de eventos ou descobertas que acontecem após o corte.
Fontes confiáveis
Os LLMs também têm dificuldade em citar fontes confiáveis, o que pode deixar os usuários questionando a precisão de suas respostas. Sem acesso a fontes atualizadas ou uma maneira de validar as informações, esses modelos podem ter dificuldade em garantir a confiabilidade.
RAG: a solução para as limitações dos LLMs
Como mencionado anteriormente, o RAG foi projetado para resolver as limitações dos LLMs, baseando suas respostas em dados reais e atualizados.
Informações atualizadas de fontes relevantes
Quando um LLM recebe uma consulta, em vez de depender exclusivamente de seus dados de treinamento estáticos, o RAG permite que ele obtenha informações atualizadas de fontes externas contextualmente relevantes. Essa configuração reduz efetivamente o risco de alucinações, baseando as respostas em documentos e dados reais. Como consulta ativamente fontes externas, o RAG pode responder a perguntas envolvendo eventos recentes, novas tecnologias ou qualquer informação que um LLM padrão perderia devido ao seu limite de conhecimento. Por exemplo, em um cenário de suporte ao cliente, o RAG pode recuperar as atualizações mais recentes das políticas de uma base de conhecimento, garantindo que as respostas estejam alinhadas com a documentação atual da empresa.
Maior transparência
Além da precisão, o RAG aumenta a transparência com fontes para suas respostas. Como ele extrai dados de documentos específicos e relevantes, ele fornece um rastreamento mais claro do raciocínio, permitindo que os usuários vejam de onde vêm as informações. Essa verificabilidade não apenas aumenta a confiança do usuário, mas também torna os modelos equipados com RAG mais úteis em áreas como serviços jurídicos e financeiros, onde os usuários exigem respostas claras e bem fundamentadas.
Principais casos de uso do RAG
O RAG se destaca em aplicações onde informações precisas e atualizadas são essenciais, especialmente em áreas que mudam rapidamente. Aqui estão alguns dos casos de uso mais populares do RAG.
Automação do suporte ao cliente
O RAG transforma o suporte ao cliente ao acessar a base de conhecimento e os artigos de ajuda de uma empresa. Ele fornece respostas instantâneas às perguntas dos clientes, extraindo os documentos, informações de produtos e dicas de solução de problemas mais atualizados. Isso significa que os clientes obtêm respostas precisas e personalizadas para suas necessidades específicas, sem sobrecarregar os agentes de suporte com perguntas rotineiras.
Serviços jurídicos e financeiros
Esses setores exigem informações que não sejam apenas precisas, mas também rastreáveis a fontes confiáveis. Um profissional da área jurídica, por exemplo, pode usar o RAG para recuperar jurisprudências ou regulamentos relevantes ao formar uma opinião. Analistas financeiros podem usar o RAG para obter relatórios ou dados atuais do mercado, fornecendo aos clientes insights oportunos e respaldados por informações concretas.
Pesquisa e criação de conteúdo
Escritores, jornalistas e pesquisadores podem usar o RAG para obter referências precisas de fontes confiáveis, simplificando e acelerando o processo de verificação de fatos e coleta de informações. Seja para redigir um artigo ou compilar dados para um estudo, o RAG facilita o acesso rápido a materiais relevantes e confiáveis, permitindo que os criadores se concentrem na produção de conteúdo de alta qualidade.
Agentes conversacionais e chatbots
Ao integrar o RAG, os agentes conversacionais e os chatbots podem fornecer respostas mais precisas e contextualmente conscientes, melhorando a experiência do usuário. Por exemplo, um chatbot de saúde poderia recuperar informações sobre estudos médicos recentes, ou um bot de suporte técnico poderia obter os detalhes da última atualização de firmware do dispositivo. A capacidade do RAG de combinar a recuperação de dados em tempo real com a geração de linguagem melhora a qualidade e a confiabilidade das respostas.
Saiba mais sobre como criar um chatbot RAG usando modelos GPT.
Desafios e limitações do RAG
Embora o RAG agregue um valor significativo aos modelos de linguagem, ele também traz seu próprio conjunto de desafios.
Qualidade e precisão
Uma questão importante é a qualidade e a precisão das informações recuperadas para aumentar o prompt. Como o RAG depende de fontes externas, a resposta do modelo é tão boa quanto os dados que ele obtém. A resposta gerada ainda pode ser insuficiente se o sistema de recuperação retornar documentos irrelevantes ou imprecisos. Garantir uma recuperação de alta qualidade é importante e geralmente requer ajustes e atualizações regulares para manter os dados relevantes e precisos.
Custo e complexidade computacionais
Outros desafios incluem o custo computacional e a complexidade envolvidos na execução de um sistema RAG. Ao contrário dos LLMs autônomos, o RAG precisa de um sistema de recuperação poderoso e de um modelo capaz de integrar facilmente as informações recuperadas, o que pode consumir muitos recursos. Esse aumento na carga computacional pode retardar os tempos de resposta, especialmente se grandes quantidades de dados precisarem ser pesquisadas ou processadas em tempo real. As organizações que implementam o RAG muitas vezes precisam equilibrar precisão e desempenho, encontrando maneiras de configurar a recuperação sem comprometer a velocidade.
O sucesso do RAG depende muito do acesso a fontes de dados estruturadas e confiáveis. O sistema de recuperação pode ter dificuldade em obter informações úteis sem bancos de dados externos confiáveis e bem organizados. Além disso, nem todas as fontes de dados são facilmente acessíveis ou acessíveis, o que pode ser uma barreira para organizações menores.
Apesar desses desafios, com uma configuração cuidadosa e fontes de dados confiáveis, o RAG ainda pode oferecer benefícios transformadores para uma ampla gama de aplicações.
Implementação do RAG na prática
A configuração de um sistema RAG requer a conexão de um modelo de linguagem com um mecanismo de recuperação eficaz para permitir o acesso a dados externos.
O processo começa com o estabelecimento de uma arquitetura de alto nível que combina um sistema de pesquisa com o modelo de linguagem. Quando um usuário envia uma consulta, o sistema de recuperação pesquisa fontes externas em busca de informações relevantes e, em seguida, envia essas informações para o LLM junto com o prompt, que gera uma resposta com base em seu próprio conhecimento e nos dados recuperados. Essa abordagem garante que as respostas sejam informadas e contextualizadas com base em informações recentes e confiáveis.
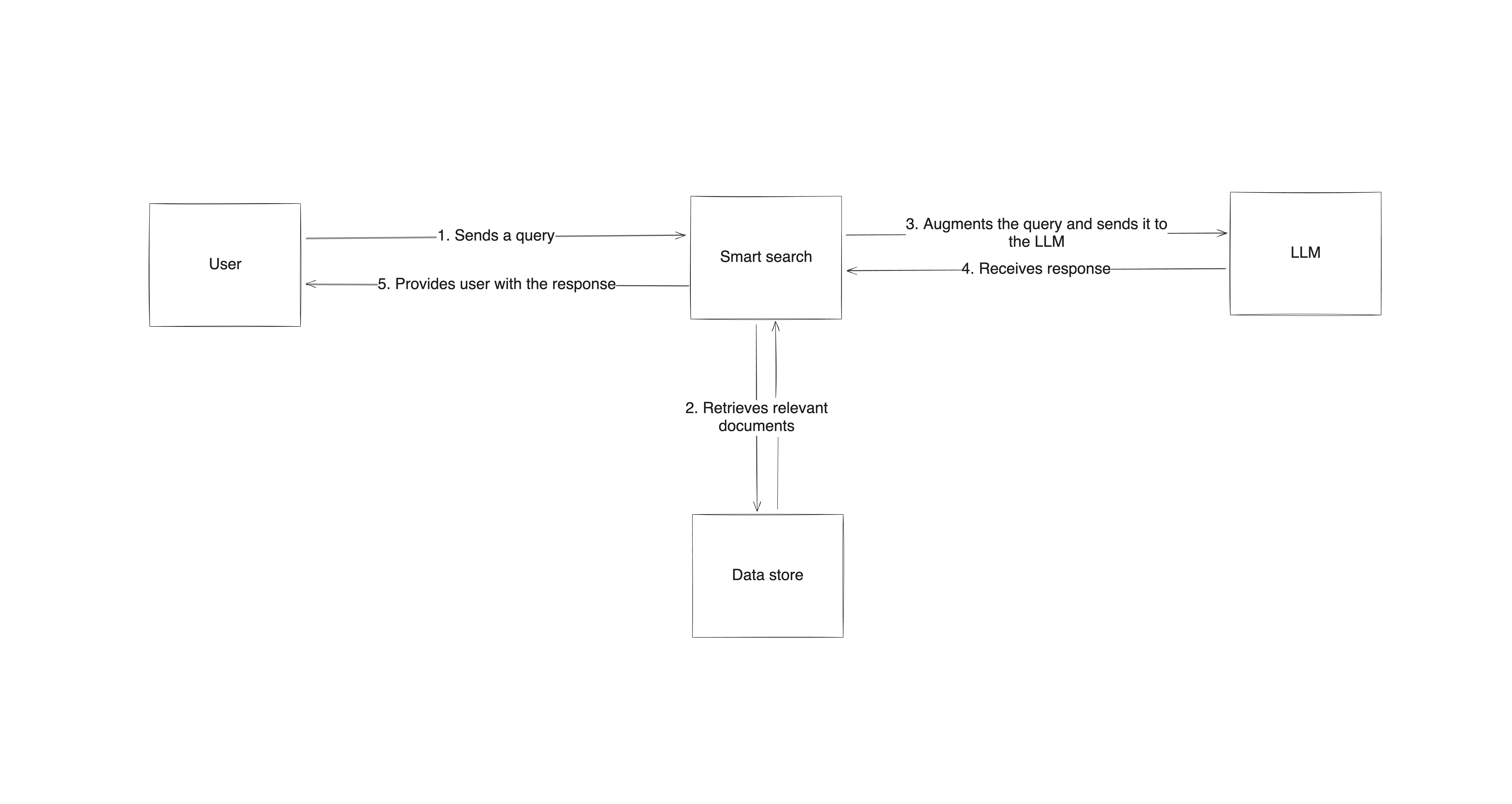
A implementação do RAG requer ferramentas e estruturas específicas
Em termos práticos, a implementação do RAG requer ferramentas e estruturas específicas que possam lidar com a recuperação de informações, seu processamento e a geração da resposta. Bibliotecas comoLangChaineHaystacksão opções populares, pois fornecem componentes prontos para integrar a recuperação ao processo de geração de respostas.
Por exemplo, o LangChain oferece ferramentas paraestruturar prompts,recuperar dados ecanalizar os resultadosdiretamente para um LLM, enquanto o Haystack é especializado emrecuperação de alto desempenho, permitindo extrair informações de bancos de dados, documentos ou até mesmo da web. Você pode personalizar essas ferramentas para trabalhar com diferentes fontes de dados, tornando-as altamente adaptáveis para várias aplicações RAG.
RAG é uma estrutura construída sobre um LLM existente
Se você olhar de longe, ao contrário de técnicas comoo ajuste fino, o RAG não afeta a estrutura ou os componentes do seu LLM principal. É apenas uma estrutura construída sobre o seu LLM existente que ajuda a melhorar a qualidade dos prompts que você envia ao modelo. Alguns argumentamque o RAG é apenas uma engenharia de prompts glorificada, e você pode entender o ponto de vista deles se der uma olhada no prompt original que entra em um sistema RAG e compará-lo com o prompt aumentado que ele gera antes de gerar a resposta final. Aqui está um exemplo rápido (e extremamente simplificado) para ajudá-lo a entender melhor isso:
- Prompt bruto
Quais são os impactos mais recentes das mudanças climáticas nos recifes de corais?
- Resposta (de um LLM sem RAG)
Os recifes de corais são afetados pelo aumento da temperatura e pela acidificação dos oceanos, o que causa o branqueamento dos corais e perturba os ecossistemas marinhos.
- Prompt aumentado (com RAG)
Usando os dados recuperados: “Um relatório de 2024 da NOAA destaca que o aquecimento dos oceanos causou eventos de branqueamento em massa dos corais no Caribe e no Pacífico, levando a uma redução de 40% na cobertura de corais nas regiões afetadas. A acidificação também está enfraquecendo os esqueletos dos corais, tornando-os mais vulneráveis aos danos causados por tempestades”. Responda ao seguinte: Quais são os impactos mais recentes das mudanças climáticas nos recifes de corais?
- Resposta (de um LLM com RAG)
Relatórios recentes da NOAA indicam que o aquecimento dos oceanos está causando eventos de branqueamento em massa, especialmente no Caribe e no Pacífico, com a cobertura de corais diminuindo em 40% em algumas áreas. A acidificação também está danificando os esqueletos dos corais, aumentando sua vulnerabilidade.
Embora isso pareça apoiar o argumento, é importante enfatizar que obter os dados corretos do LLM no contexto da consulta original é o foco da configuração do RAG. Dependendo do armazenamento de dados, seu componente de pesquisa pode ser algo tão simples quanto uma consulta SQL ou algo tão complexo quanto uma pesquisa no Google e rastreamento da web. Então, depois de obter os dados, você precisa priorizá-los e resumí-los de forma correta e eficiente antes de anexá-los ao prompt. Essas duas etapas tornam o RAG muito mais complexo do que qualquer técnica de engenharia de prompt.
A implementação do RAG requer muitos dados de alta qualidade
Quando se trata do armazenamento de dados em si, a maioria dos sistemas RAG precisa de um, e é útil que a grande quantidade de dados seja precisa, atualizada e específica do domínio. Criar e manter esses Conjuntos de dados é demorado e difícil. Provedores de dados públicos, comoa Bright Data, podem facilitar isso, fornecendo vastos Conjuntos de dados que garantem que o sistema de recuperação esteja trabalhando com informações atualizadas e de alta qualidade.
Essas fontes podem incluir tudo, desde dados da web até Conjuntos de dados estruturados, o que aumenta muito a relevância do modelo. Ao se integrarem aos Conjuntos de dados da Bright Data, os modelos RAG têm acesso às informações mais recentes, o que não apenas melhora a precisão da resposta, mas também ajuda em áreas onde os dados em tempo real são essenciais, como sistemas meteorológicos ou logística e gestão da cadeia de suprimentos.
Como a Bright Data pode ajudar na recuperação de dados públicos
Como fornecedora de Conjuntos de dados públicos de alta qualidade da web, a Bright Data pode ser um recurso valioso para os sistemas RAG. Com a dependência do RAG de informações atualizadas e de alta qualidade, os Conjuntos de dados da Bright Data tornam possível obter conteúdo relevante para diversas aplicações, desde eventos atuais até pesquisas de nicho.
Dados estruturados em vários setores
Os conjuntos de dados da Bright Data incluem dados estruturados em diversos setores, como comércio eletrônico, mercados financeiros e notícias, que podem ser integrados aos sistemas RAG para melhorar a precisão e a relevância do modelo. Isso pode ajudar a garantir que os LLMs respondam com precisão a perguntas que exigem informações recentes ou específicas do setor, o que é fundamental para áreas como suporte ao cliente e análise competitiva.
Acesse e filtre dados públicos em grande escala
Se você deseja coletar dados da web por conta própria,a APIda Bright Data esua extensa infraestrutura de Proxypodem ajudá-lo a acessar e filtrar dados públicos em grande escala, mantendo a conformidade com as políticas de uso de dados. Isso pode ser muito útil para aplicações RAG que exigem a recuperação dinâmica de informações. Por exemplo, uma configuração RAG de serviços financeiros poderia extrair continuamente dados atualizados do mercado de ações ou notícias regulatórias, aprimorando a capacidade do modelo de fornecer insights em tempo real.
Usar a Bright Data como fonte de dados em seu sistema RAG elimina o trabalho de manter seu armazenamento de dados, permitindo que você se concentre em refinar o aumento de prompts e a geração de respostas.
Conclusão
O RAG representa um avanço significativo nas capacidades dos LLMs, permitindo que eles superem limitações importantes, como corte de conhecimento e alucinação, incorporando dados em tempo real de fontes externas. Por meio do RAG, os modelos podem obter acesso a informações atuais e verificadas, o que aumenta a relevância e a confiabilidade de suas respostas. Essa técnica transforma os modelos de linguagem de repositórios de conhecimento estáticos em agentes dinâmicos e sensíveis ao contexto.
Ao integrar dados de alta qualidade e em tempo real nas implementações de RAG, você pode melhorar a precisão, a relevância e a confiabilidade de suas aplicações de IA. Seja no suporte ao cliente, análise financeira, saúde ou qualquer outro setor, o uso do RAG pode ajudar a melhorar significativamente a experiência do usuário final.
A Bright Data ajuda a desenvolver implementações RAG com mais facilidade, oferecendo uma solução escalável para obter dados públicos confiáveis e estruturados. Com suas ofertas abrangentes de Conjuntos de dados, a Bright Data oferece suporte a sistemas RAG para fornecer respostas precisas e atualizadas em vários setores e aplicações.
Inscreva-se agora e comece seu teste grátis, incluindo amostras gratuitas de Conjuntos de dados que você pode baixar!





