

Neste tutorial guiado, você descobrirá:
- Uma visão geral do RAG e seus mecanismos
- As vantagens de integrar dados SERP ao GPT-4o por meio do RAG
- Como implementar um chatbot Python RAG usando modelos OpenAI GPT e dados SERP
Vamos nos aprofundar!
O que é RAG?
RAG, abreviação de Retrieval-Augmented Generation, é uma abordagem de IA que combina a recuperação de informações com a geração de texto. Em um fluxo de trabalho RAG, o aplicativo primeiro recupera dados relevantes de fontes externas, como documentos, páginas da Web ou bancos de dados. Em seguida, ele passa os dados para os modelos de IA para que possa gerar respostas contextualmente mais relevantes.
O RAG aprimora os grandes modelos de linguagem (LLMs), como o GPT, permitindo que eles acessem e façam referência a informações atualizadas além dos dados de treinamento originais. Essa abordagem é fundamental em cenários em que são necessárias informações precisas e específicas do contexto, pois melhora a qualidade e a precisão das respostas geradas pela IA.
Por que alimentar modelos de IA com dados de SERP?
A data de corte de conhecimento para o GPT-4o é outubro de 2023, o que significa que ele não tem acesso a eventos ou informações publicados após essa data. No entanto, os modelos GPT-4o podem extrair dados da Internet em tempo real usando a integração de pesquisa do Bing. Isso os ajuda a oferecer informações mais atualizadas.
Mas e se você quiser que o modelo de IA empregue fontes de dados específicas ou prefira mecanismos de pesquisa mais confiáveis? É aí que o RAG entra em ação!
Em particular, alimentar os modelos de IA com dados SERP(Search Engine Results Page, página de resultados do mecanismo de busca) via RAG é uma ótima maneira de obter melhores respostas. Essa abordagem é especialmente benéfica para tarefas que exigem informações atuais ou insights especializados.
Em resumo, passar dados de resultados de pesquisa de alto nível para o GPT-4o ou o GPT-4o mini resulta em respostas detalhadas, precisas e contextualmente ricas.
RAG com dados SERP com modelos GPT usando Python: Tutorial passo a passo
Neste tutorial, você aprenderá a criar um chatbot RAG usando os modelos GPT da OpenAI. A ideia é reunir o texto das páginas com melhor desempenho no Google para uma consulta de pesquisa específica e usá-lo como contexto para uma solicitação de GPT.
Agora, o maior desafio é extrair dados de SERP. O motivo é que a maioria dos mecanismos de pesquisa vem com soluções avançadas anti-bot para impedir o acesso automatizado às suas páginas. Para obter orientações detalhadas, consulte nosso guia sobre como fazer scraping do Google em Python.
Para simplificar o processo de coleta de dados, usaremos a API SERP da Bright Data:
Esse Scraper SERP premium permite que você recupere facilmente SERPs do Google, DuckDuckGo, Bing, Yandex, Baidu e outros mecanismos de pesquisa usando solicitações HTTP simples.
Em seguida, extrairemos os dados de texto dos URLs retornados usando um navegador sem cabeça. Em seguida, usaremos essas informações como o contexto do modelo GPT em um fluxo de trabalho RAG. Se, em vez disso, você quiser recuperar dados on-line diretamente usando IA, leia nosso artigo sobre Scraping de dados da Web com o ChatGPT.
Se você estiver ansioso para explorar o código ou quiser mantê-lo à mão enquanto segue as etapas abaixo, clone o repositório do GitHub que dá suporte a este artigo:
git clone https://github.com/Tonel/rag_gpt_serp_scrapingSiga as instruções no arquivo README.md para instalar as dependências do projeto e iniciar o projeto.
Lembre-se de que a abordagem apresentada nesta postagem do blog pode ser facilmente adaptada a qualquer outro mecanismo de pesquisa ou LLM.
Observação: este guia refere-se ao Unix e ao macOS. Se você for um usuário do Windows, ainda poderá seguir o tutorial usando o Windows Subsystem for Linux(WSL).
Etapa 1: inicializar um projeto Python
Certifique-se de ter o Python 3 instalado em sua máquina. Caso contrário, faça o download e instale-o.
Crie uma pasta para seu projeto e digite-a no terminal:
mkdir rag_gpt_serp_scraping
cd rag_gpt_serp_scrapingA pasta rag_gpt_serp_scraping conterá seu projeto Python RAG.
Em seguida, carregue o diretório do projeto em seu IDE Python favorito. O PyCharm Community Edition ou o Visual Studio Code com a extensão Python são suficientes.
Dentro de rag_gpt_serp_scraping, adicione um arquivo app.py vazio. Ele conterá sua lógica de raspagem e RAG.
Em seguida, inicialize um ambiente virtual Python no diretório do projeto:
python3 -m venv envAtive o ambiente virtual com o comando abaixo:
source ./env/bin/activateMuito bom! Agora você está totalmente configurado.
Etapa 2: instalar as bibliotecas necessárias
As dependências usadas por este projeto Python RAG baseado em modelos GPT são:
python-dotenv: para carregar variáveis de ambiente de um arquivo .env. Ele será usado para gerenciar com segurança credenciais confidenciais, como as credenciais da Bright Data e as chaves da API da OpenAI.requests: Para executar solicitações HTTP para a API SERP da Bright Data. Para obter mais informações, consulte nosso guia sobre como usar um Proxy com Requests.langchain-community: Faz parte da estrutura LangChain, um conjunto de ferramentas para construir com LLMs encadeando componentes interoperáveis. Ele será usado para recuperar texto das páginas SERP do Google e limpá-lo para gerar conteúdo relevante para o RAG.openai: A biblioteca oficial do cliente Python para a API OpenAI. Ela será empregada para fazer interface com os modelos GPT para gerar respostas em linguagem natural com base nas entradas fornecidas e no contexto do RAG.streamlit: Uma estrutura para criar aplicativos interativos da Web em Python. Será útil para criar uma interface de usuário em que os usuários possam inserir suas consultas de pesquisa do Google e o prompt de IA e visualizar os resultados dinamicamente.
Em um ambiente virtual ativado, execute o comando abaixo para instalar todas as dependências:
pip install python-dotenv requests langchain-community openai streamlitEm detalhes, usaremos o AsyncChromiumLoader da langchain-community, que requer as seguintes dependências:
pip install --upgrade --quiet playwright beautifulsoup4 html2textPara funcionar corretamente, o Playwright também exige que você instale os navegadores com:
playwright installA instalação de todas essas bibliotecas demorará um pouco, portanto, seja paciente.
Fantástico! Você está pronto para escrever sua lógica Python.
Etapa 3: Prepare seu projeto
Em app.py, adicione as seguintes importações:
from dotenv import load_dotenv
importar os
importar requests
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from openai import OpenAI
importar streamlit como stEm seguida, crie um arquivo .env na pasta do projeto para armazenar todas as suas credenciais. A estrutura do seu projeto agora será parecida com a abaixo:

Use a função abaixo em app.py para instruir o python-dotenv a carregar as variáveis de ambiente do arquivo .env:
load_dotenv()Agora você pode importar variáveis de ambiente de .env ou do sistema com:
os.environ.get("<ENV_NAME>")Aqui também está o motivo pelo qual importamos a biblioteca padrão do Python.
Etapa 4: configurar a API SERP
Conforme mencionado na introdução, contaremos com a API SERP da Bright Data para recuperar o conteúdo das páginas de resultados dos mecanismos de pesquisa e usá-lo em nosso fluxo de trabalho Python RAG. Especificamente, extrairemos o texto dos URLs das páginas da Web retornadas pela API SERP.
Para configurar a API SERP, consulte a documentação oficial. Como alternativa, siga as instruções abaixo.
Se ainda não tiver criado uma conta, inscreva-se na Bright Data. Uma vez conectado, navegue até o painel de controle da sua conta:

Lá, clique no botão “Get proxy products” (Obter produtos Proxy).
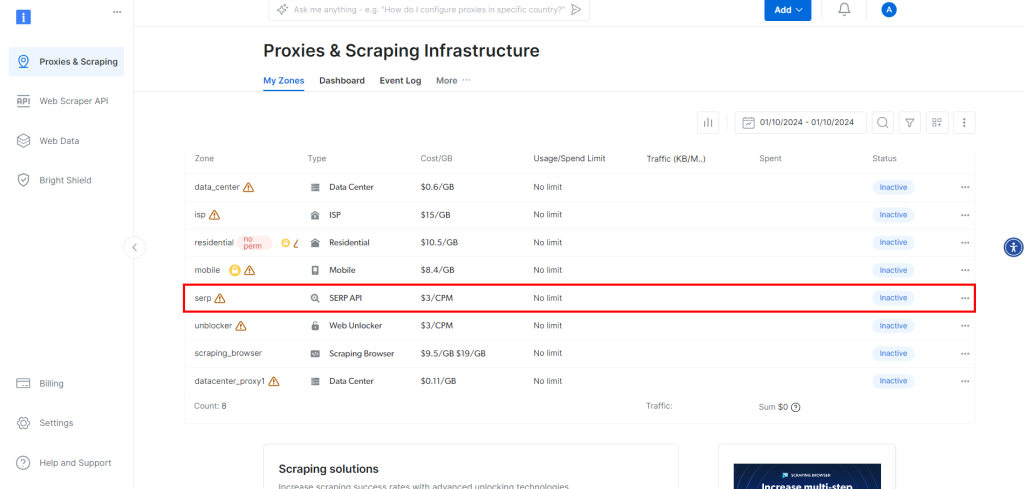
Isso o levará à página abaixo, onde você deverá clicar na linha “API SERP”:
Na página do produto API SERP, ative a opção “Activate Zone” (Ativar zona) para ativar o produto:
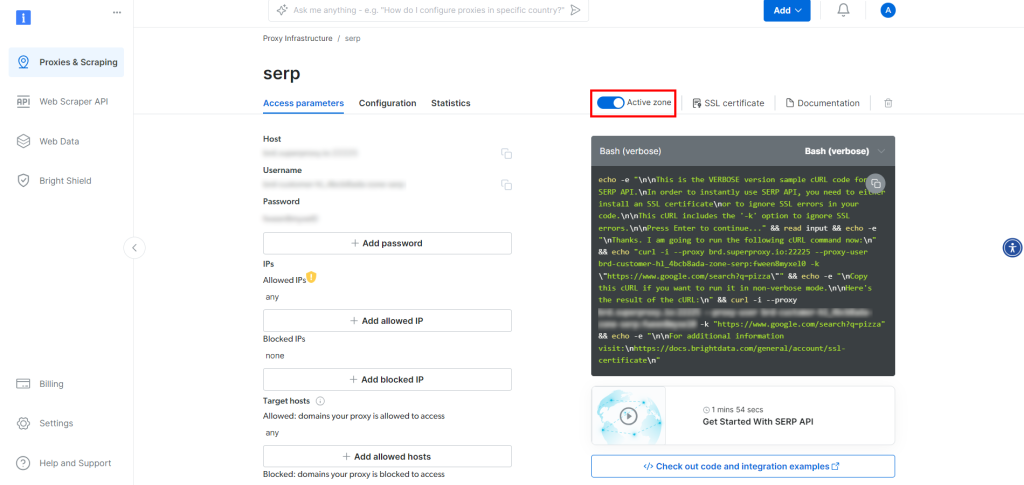
Agora, copie o host, a porta, o nome de usuário e a senha da API SERP na seção “Access parameters” (Parâmetros de acesso) e adicione-os ao seu arquivo .env:
BRIGHT_DATA_SERP_API_HOST="<SEU_HOST>"
BRIGHT_DATA_SERP_API_PORT=<SUA_PORTA>
BRIGHT_DATA_SERP_API_USERNAME="<SEU_NOME_DE_USUÁRIO>"
BRIGHT_DATA_SERP_API_PASSWORD="<SUA_SENHA>"Substitua os espaços reservados <YOUR_XXXX> pelos valores fornecidos pela Bright Data na página da API SERP.
Observe que o host em “Parâmetros de acesso” tem um formato como este:
brd.superproxy.io:33335Você deve dividi-lo como abaixo:
BRIGHT_DATA_SERP_API_HOST="brd.superproxy.io"
BRIGHT_DATA_SERP_API_PORT=33335Excelente! Agora você pode usar a API SERP em Python.
Etapa 5: implementar a lógica de raspagem de SERP
Em app.py, adicione a seguinte função para recuperar os primeiros URLs number_of_urls de uma página SERP do Google:
def get_google_serp_urls(query, number_of_urls=5):
# executa uma solicitação da API SERP da Bright Data
# com autoparsing de JSON
host = os.environ.get("BRIGHT_DATA_SERP_API_HOST")
port = os.environ.get("BRIGHT_DATA_SERP_API_PORT")
nome de usuário = os.environ.get("BRIGHT_DATA_SERP_API_USERNAME")
senha = os.environ.get("BRIGHT_DATA_SERP_API_PASSWORD")
proxy_url = f "http://{username}:{password}@{host}:{port}"
proxies = {"http": proxy_url, "https": proxy_url}
url = f "https://www.google.com/search?q={query}&brd_json=1"
response = requests.get(url, proxies=proxies, verify=False)
# recuperar a resposta JSON analisada
response_data = response.json()
# Extrair um número "number_of_urls" de
# URLs SERP do Google a partir da resposta
google_serp_urls = []
if "organic" in response_data:
for item in response_data["organic"]:
if "link" in item:
google_serp_urls.append(item["link"])
return google_serp_urls[:number_of_urls]Isso faz uma solicitação HTTP GET para a API SERP com a consulta de pesquisa especificada no argumento query. O parâmetro de consulta brd_json=1 garante que a API SERP analise os resultados em JSON para você, no formato abaixo:
{
"general": {
"search_engine": "google",
"results_cnt": 1980000000,
"search_time": 0.57,
"language" (idioma): "en",
"mobile": falso,
"basic_view": falso,
"search_type": "text",
"page_title": "pizza - Pesquisa do Google",
"code_version": "1.90",
"timestamp" (registro de data e hora): "2023-06-30T08:58:41.786Z"
},
"input": {
"original_url": "https://www.google.com/search?q=pizza&brd_json=1",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12) AppleWebKit/608.2.11 (KHTML, como Gecko) Versão/13.0.3 Safari/608.2.11",
"request_id": "hl_1a1be908_i00lwqqxt1"
},
"organic": [
{
"link": "https://www.pizzahut.com/",
"display_link": "https://www.pizzahut.com",
"title": "Pizza Hut | Delivery & Carryout - Ninguém Fica de ForaPizzas The Hut!",
"imagem": "omitido por brevidade...",
"image_alt": "pizza de www.pizzahut.com",
"image_base64": "omitido por brevidade...",
"rank": 1,
"global_rank": 1
},
{
"link": "https://www.dominos.com/en/",
"display_link": "https://www.dominos.com ' ...",
"title": "Domino's: Pizza Delivery & Carryout, Pasta, Frango & Mais",
"description": "Peça pizza, macarrão, sanduíches e muito mais on-line para levar ou entregar na Domino's. Veja o cardápio, encontre locais, acompanhe os pedidos. Registre-se para receber o e-mail da Domino's ...",
"image": "omitido por brevidade...",
"image_alt": "pizza de www.dominos.com",
"image_base64": "omitido por brevidade...",
"rank": 2,
"global_rank": 3
},
// omitido por brevidade...
],
// omitido para fins de brevidade...
}As últimas linhas da função recuperam cada URL SERP dos dados JSON resultantes, selecionam somente os primeiros URLs number_of_urls e os retornam em uma lista.
É hora de extrair o texto desses URLs!
Etapa nº 6: extrair texto dos URLs SERP
Defina uma função que extraia o texto de cada um dos URLs SERP:
def extract_text_from_urls(urls, number_of_words=600):
# instrui uma instância do Chrome sem cabeça a visitar os URLs fornecidos
# com o agente de usuário especificado
loader = AsyncChromiumLoader(
urls,
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/129.0.0.0 Safari/537.36",
)
html_documents = loader.load()
# Processar os documentos HTML extraídos para extrair o texto deles
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
html_documents,
tags_to_extract=["p", "em", "li", "strong", "h1", "h2"],
unwanted_tags=["a"],
remove_comments=True,
)
# Certifique-se de que cada documento de texto HTML contenha apenas um número
# number_of_words palavras
lista_de_texto_extraído = []
para doc_transformed em docs_transformed:
# dividir o texto em palavras e juntar o primeiro número_de_palavras
palavras = doc_transformed.page_content.split()[:number_of_words]
texto_extraído = " ".join(words)
# Ignorar documentos de texto vazios
se len(texto_extraído) != 0:
extracted_text_list.append(extracted_text)
return extracted_text_listEsta função:
- Carrega páginas da Web a partir dos URLs passados como argumento usando uma instância sem cabeça do navegador Chrome.
- Utiliza o BeautifulSoupTransformer para processar o HTML de cada página e extrair o texto de tags específicas (como <p>, <h1>, <strong> etc.), omitindo tags indesejadas (como <a>) e comentários.
- Limita o texto extraído de cada página da Web a um número de palavras especificado pelo argumento
number_of_words. - Retorna uma lista do texto extraído de cada URL.
Lembre-se de que as tags [“p”, “em”, “li”, “strong”, “h1”, “h2”] são suficientes para extrair o texto da maioria das páginas da Web. Entretanto, em alguns cenários específicos, talvez seja necessário personalizar essa lista de tags HTML. Além disso, talvez seja necessário aumentar ou diminuir o número alvo de palavras para cada item de texto.
Por exemplo, considere a página da Web abaixo:

A aplicação dessa função a essa página resultará na seguinte matriz de texto:
["A análise de Transformers One de Lisa Johnson Mandell revela o até então inconcebível: É um dos melhores filmes de animação do ano! Nunca pensei que me veria escrevendo isso sobre um filme dos Transformers, mas Transformers One é realmente um filme excepcional! ..."]Incrível! Mesmo que não seja perfeito, ainda é de alta qualidade para os padrões dos modelos de IA.
A lista de itens de texto retornada por extract_text_from_urls() representa o contexto RAG para alimentar o modelo OpenAI.
Etapa nº 7: Gerar o prompt do RAG
Defina uma função que transforme a solicitação de prompt da IA e o contexto de texto no prompt final do RAG:
def get_openai_prompt(request, text_context=[]):
# prompt padrão
prompt = request
# Adicionar o contexto ao prompt, se presente
se len(text_context) != 0:
context_string = "nn--------nn".join(text_context)
prompt = f "Responda à solicitação usando somente o contexto abaixo.nnContext:n{context_string}nnRequest: {request}"
return promptOs prompts retornados pela função anterior quando um contexto RAG é especificado têm este formato:
Responda à solicitação usando somente o contexto abaixo.
Contexto:
Bla bla bla...
--------
Bla bla bla...
--------
Bla bla bla...
Solicitação: <YOUR_REQUEST>Etapa nº 8: executar a solicitação de GPT
Primeiro, inicialize o cliente OpenAI na parte superior do arquivo app.py:
openai_client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))Isso se baseia na variável de ambiente OPENAI_API_KEY, que pode ser definida diretamente nos ambientes do sistema ou no arquivo .env:
OPENAI_API_KEY="<SUA_API_KEY>"
Substitua <YOUR_API_KEY> pelo valor de sua chave da API OpenAI. Se você não souber como obter uma, siga o guia oficial.
Em seguida, escreva uma função que use o cliente oficial do OpenAI para realizar uma solicitação ao mini modelo de IA do GPT-4o:
def interrogate_openai(prompt, max_tokens=800):
# interroga o modelo OpenAI com o prompt fornecido
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=max_tokens,
)
return response.choices[0].message.contentObserve que você pode configurar qualquer outro modelo de GPT compatível com a API OpenAI.
Se for chamado com um prompt retornado por get_openai_prompt() que inclua um contexto de texto especificado, interrogate_openai() executará com êxito a geração aumentada por recuperação, conforme pretendido.
Etapa 9: criar a interface do usuário do aplicativo
Use o Streamlit para definir uma interface de usuário de formulário simples em que os usuários possam especificar:
- A consulta de pesquisa do Google a ser passada para a API SERP
- O prompt de IA a ser enviado para o GPT-4o mini
Faça isso com estas linhas de código:
com st.form("prompt_form"):
# inicializar os resultados de saída
resultado = ""
final_prompt = ""
# área de texto para o usuário inserir sua consulta de pesquisa do Google
google_search_query = st.text_area("Google Search:", None)
# área de texto para o usuário inserir seu prompt de IA
request = st.text_area("IA Prompt:", None)
# botão para enviar o formulário
submitted = st.form_submit_button("Send")
# se o formulário for enviado
se submetido:
# recupera os URLs SERP do Google a partir da consulta de pesquisa fornecida
google_serp_urls = get_google_serp_urls(google_search_query)
# Extrair o texto das respectivas páginas HTML
extracted_text_list = extract_text_from_urls(google_serp_urls)
# gerar o prompt de IA usando o texto extraído como contexto
final_prompt = get_openai_prompt(request, extracted_text_list)
# Interrogar um modelo OpenAI com o prompt gerado
result = interrogate_openai(final_prompt)
# menu suspenso contendo o prompt gerado
final_prompt_expander = st.expander("IA Final Prompt:")
final_prompt_expander.write(final_prompt)
# Escrever o resultado do modelo OpenAI
st.write(result)Aqui vamos nós! O script Python RAG está pronto.
Etapa 10: Juntar tudo
Seu arquivo app.py deve conter o seguinte código:
from dotenv import load_dotenv
importar os
importar requests
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from openai import OpenAI
importar streamlit como st
# Carregue as variáveis de ambiente do arquivo .env
load_dotenv()
# Inicializar o cliente da API OpenAI com sua chave de API
openai_client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
def get_google_serp_urls(query, number_of_urls=5):
# executa uma solicitação da API SERP da Bright Data
# com autoparsing de JSON
host = os.environ.get("BRIGHT_DATA_SERP_API_HOST")
port = os.environ.get("BRIGHT_DATA_SERP_API_PORT")
nome de usuário = os.environ.get("BRIGHT_DATA_SERP_API_USERNAME")
senha = os.environ.get("BRIGHT_DATA_SERP_API_PASSWORD")
proxy_url = f "http://{username}:{password}@{host}:{port}"
proxies = {"http": proxy_url, "https": proxy_url}
url = f "https://www.google.com/search?q={query}&brd_json=1"
response = requests.get(url, proxies=proxies, verify=False)
# recuperar a resposta JSON analisada
response_data = response.json()
# Extrair um número "number_of_urls" de
# URLs SERP do Google a partir da resposta
google_serp_urls = []
if "organic" in response_data:
for item in response_data["organic"]:
if "link" in item:
google_serp_urls.append(item["link"])
return google_serp_urls[:number_of_urls]
def extract_text_from_urls(urls, number_of_words=600):
# instrui uma instância sem cabeça do Chrome a visitar os URLs fornecidos
# com o agente de usuário especificado
loader = AsyncChromiumLoader(
urls,
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/129.0.0.0 Safari/537.36",
)
html_documents = loader.load()
# Processar os documentos HTML extraídos para extrair o texto deles
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
html_documents,
tags_to_extract=["p", "em", "li", "strong", "h1", "h2"],
unwanted_tags=["a"],
remove_comments=True,
)
# Certifique-se de que cada documento de texto HTML contenha apenas um número
# number_of_words palavras
lista_de_texto_extraído = []
para doc_transformed em docs_transformed:
# dividir o texto em palavras e juntar o primeiro número_de_palavras
palavras = doc_transformed.page_content.split()[:number_of_words]
texto_extraído = " ".join(words)
# Ignorar documentos de texto vazios
se len(texto_extraído) != 0:
extracted_text_list.append(extracted_text)
return extracted_text_list
def get_openai_prompt(request, text_context=[]):
# prompt padrão
prompt = request
# Adicionar o contexto ao prompt, se presente
se len(text_context) != 0:
context_string = "nn--------nn".join(text_context)
prompt = f "Responda à solicitação usando somente o contexto abaixo.nnContext:n{context_string}nnRequest: {request}"
return prompt
def interrogate_openai(prompt, max_tokens=800):
# interroga o modelo OpenAI com o prompt fornecido
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=max_tokens,
)
return response.choices[0].message.content
# Criar um formulário no aplicativo Streamlit para a entrada do usuário
com st.form("prompt_form"):
# inicializar os resultados de saída
resultado = ""
final_prompt = ""
# área de texto para o usuário inserir sua consulta de pesquisa do Google
google_search_query = st.text_area("Google Search:", None)
# área de texto para o usuário inserir seu prompt de IA
request = st.text_area("IA Prompt:", None)
# botão para enviar o formulário
submitted = st.form_submit_button("Send")
# se o formulário for enviado
se submetido:
# recupera os URLs SERP do Google a partir da consulta de pesquisa fornecida
google_serp_urls = get_google_serp_urls(google_search_query)
# Extrair o texto das respectivas páginas HTML
extracted_text_list = extract_text_from_urls(google_serp_urls)
# gerar o prompt de IA usando o texto extraído como contexto
final_prompt = get_openai_prompt(request, extracted_text_list)
# Interrogar um modelo OpenAI com o prompt gerado
result = interrogate_openai(final_prompt)
# menu suspenso contendo o prompt gerado
final_prompt_expander = st.expander("IA Final Prompt")
final_prompt_expander.write(final_prompt)
# Escrever o resultado do modelo OpenAI
st.write(result)Dá para acreditar? Em menos de 150 linhas de código, você pode obter o RAG usando Python!
Etapa 11: testar o aplicativo
Inicie seu aplicativo Python RAG com:
streamlit run app.pyNo terminal, você deverá ver a seguinte saída:
Agora você pode visualizar o aplicativo Streamlit no navegador.
URL local: http://localhost:8501
URL da rede: http://172.27.134.248:8501Siga as instruções e acesse http://localhost:8501 no navegador. Veja abaixo o que você deve estar vendo:

Como você pode notar, o formulário contém as entradas de área de texto “Google Search:” e “IA Prompt:” definidas no código, bem como o botão “Send” e o menu suspenso “IA Final Prompt”.
Teste o aplicativo usando uma consulta de pesquisa do Google, conforme abaixo:
Análise do Transformers OneE um prompt de IA como o seguinte:
Escreva uma resenha sobre o filme Transformers OneClique em “Send” (Enviar) e aguarde enquanto o aplicativo processa a solicitação. Após alguns segundos, você deverá obter um resultado como este:
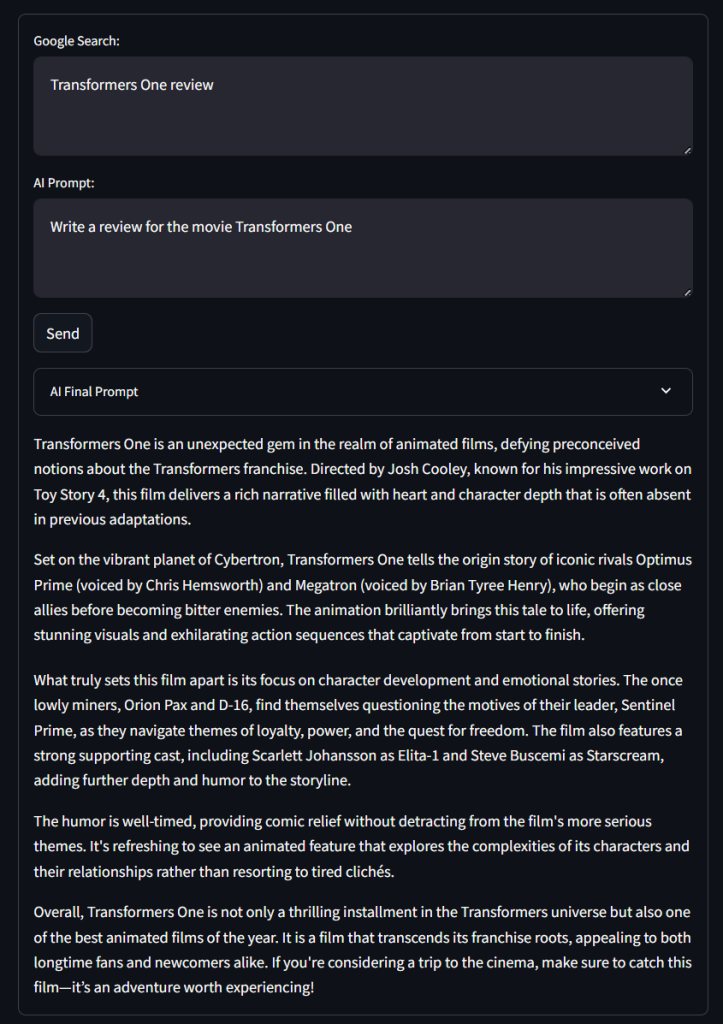
Uau! Não é uma crítica ruim…
Se você expandir o menu suspenso “IA Final Prompt”, verá o prompt completo usado pelo aplicativo para o RAG.
E pronto! Você acabou de implementar um chatbot Python RAG com o GPT-4o mini usando dados SERP.
Conclusão
Neste tutorial, você explorou o que é RAG e como ele pode ser obtido alimentando modelos de IA com dados de SERP. Especificamente, você aprendeu a criar um chatbot Python RAG que extrai dados SERP e os usa em modelos GPT para melhorar a precisão dos resultados.
O principal desafio dessa abordagem é a extração de dados de mecanismos de pesquisa como o Google:
- Eles alteram frequentemente a estrutura de suas páginas SERP.
- Eles são protegidos por algumas das mais sofisticadas medidas anti-bot disponíveis.
- A recuperação simultânea de grandes volumes de dados SERP é complexa e pode custar muito dinheiro.
Como mostrado aqui, a API SERP da Bright Data o ajuda a recuperar dados SERP em tempo real de todos os principais mecanismos de pesquisa sem nenhum esforço. Isso é compatível com o RAG e muitos outros aplicativos. Obtenha sua avaliação gratuita agora!
Inscreva-se agora para descobrir qual dos serviços de Proxy ou produtos de raspagem da Bright Data é mais adequado às suas necessidades. Comece com um Teste grátis!




