

Neste guia XPath vs CSS Selector, você aprenderá:
- O que são expressões XPath, como funcionam e suas vantagens e desvantagens.
- O que são seletores CSS, como funcionam e suas vantagens e desvantagens.
- Como as expressões XPath e os seletores CSS se comparam em termos de desempenho, simplicidade e casos de uso.
Hora de mergulhar no assunto!
XPath: análise completa
Vamos começar este guia comparativo entre XPath e seletores CSS mergulhando no primeiro elemento da comparação, o XPath.
Definição
XPath, abreviação de XML Path Language, é uma linguagem de consulta para navegar e consultar o DOM. Em particular, ela fornece uma maneira poderosa de localizar e extrair informações de documentos XML/HTML.
O XPath tem uma sintaxe semelhante à de um sistema de arquivos, dependendo de expressões para localizar nós na árvore XML/HTML. Uma expressão XPath define o caminho para elementos e atributos específicos dentro da estrutura hierárquica do documento.
Sintaxe
Abaixo está uma análise dos principais componentes da sintaxe do XPath:
/: Para começar a selecionar nós a partir do nó raiz.//: Para selecionar nós no documento a partir do nó atual que correspondam à seleção, independentemente de sua localização..:Para selecionar o nó atual...: Para selecionar o pai do nó atual.@: Para selecionar atributos de nó.element: Para selecionar nós com base em uma tag específica (por exemplo,div).[condição]: Para selecionar nós com base em uma condição especificada (por exemplo,[@type="submit"]).função(): Para aplicar uma função XPath específica na expressão (por exemplo,text()retorna o conteúdo de texto do nó selecionado).
Alguns exemplos para entender melhor a sintaxe do XPath são:
//a: Seleciona todos os elementos<a>no documento.//ul/li: Seleciona todos os elementos<li>que são filhos de elementos<ul>.//ul/..: Seleciona todos os nós pai dos elementos<ul>.//ul/li[@category='fiction']: Seleciona todos os elementos<il>sob as tags<ul>com um atributode categoriaigual a'fiction'.//title[@lang='en']: Seleciona todos os elementos<title>com um atributolangigual a'en'em qualquer lugar do documento.- //title/text(): Recupera o conteúdo de texto de todos os elementos
<title>no documento. //div[contains(@class, 'post')]/following-sibling::div[1]: Seleciona o primeiro elemento<div>que é irmão de cada elemento<div>contendo a classe'post'.
Observe que as expressões XPath também suportam operadores booleanos e aritméticos para combinar várias funções e condições.
Prós
- Alta versatilidade: permite navegar por estruturas XML e HTML, possibilitando a localização precisa de elementos, atributos e nós de texto. Também suporta a travessia para frente e para trás do DOM, bem como a seleção de nós pai e irmãos.
- Muitas funções e operadores: Ele vem com um rico conjunto de funções integradas (por exemplo,
contains(),concat(),count(), etc.) e operadores (por exemplo,+,or,and, etc.) para manipular e comparar dados em documentos XML/HTML. - Suporte para caminhos absolutos e relativos: as expressões XPath descrevem o caminho para os nós desejados a partir da raiz do documento (caminhos absolutos) ou de um elemento específico (caminhos relativos).
- Suporte para seleção de nós de texto: permite a seleção direta de nós de texto, abrindo caminho para a extração de conteúdo textual de documentos XML/HTML sem a necessidade de processamento ou Parsing adicional.
- Independência de plataforma: não está vinculado a uma linguagem de programação ou plataforma específica, oferecendo suporte a uma ampla variedade de ambientes, bibliotecas, navegadores e sistemas operacionais.
Contras
- Sintaxe complexa e longa: a sintaxe do XPath pode ser desafiadora, especialmente para iniciantes. Escrever o caminho para um nó específico profundamente aninhado no DOM pode resultar em uma expressão longa que pode envolver algumas funções e operadores. Isso pode tornar as expressões XPath propensas a erros e difíceis de depurar.
- Suporte e popularidade limitados: nem todas as bibliotecas de Parsing HTML suportam XPath. Isso ocorre porque os seletores CSS são muito mais populares entre os desenvolvedores web, e as bibliotecas tendem a se concentrar neles. Além disso, a maioria das bibliotecas baseadas em XPath, como HtmlAgilityPack, ainda depende do XPath 1.0, lançado em 1999. A versão atual é o XPath 3.1, lançado em 2017. Leia nosso guia sobre HtmlAgilityPack para se tornar um especialista no Scraping de dados com C#.
Dicas e truques
O Chrome permite que você teste e recupere expressões XPath diretamente no navegador.
Suponha que você esteja interessado em selecionar um elemento específico em uma página da web. Acesse-a no Chrome, clique com o botão direito do mouse no nó de interesse e selecione “Inspecionar:”.
Clique com o botão direito do mouse no elemento DOM específico e escolha “Copiar > Copiar XPath” para obter uma expressão XPath para ele. No exemplo acima, você obterá:
//*[@id="site-content"]/section[1]/div/div/div[1]/div[4]/a[1]
Observação: isso é útil para ter uma ideia de como construir uma estratégia de seleção XPath eficaz. Ao mesmo tempo, as expressões XPath geradas automaticamente tendem a ser muito longas e orientadas para a implementação. Portanto, você não pode confiar nelas na produção.
Agora, você deseja testar uma expressão XPath na página. No Chrome, há duas maneiras de fazer isso.
Primeiro, cole a expressão XPath na barra de pesquisa da seção “Elementos” do DevTools, que você pode ativar com CTRL/Command + F:
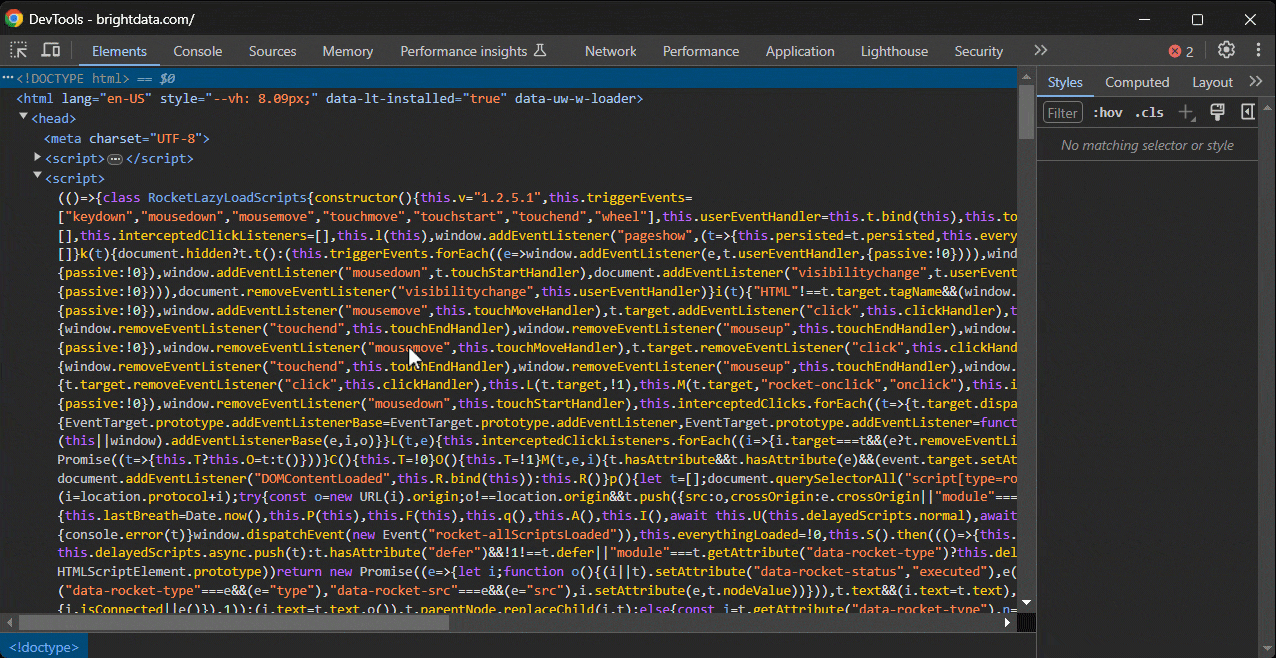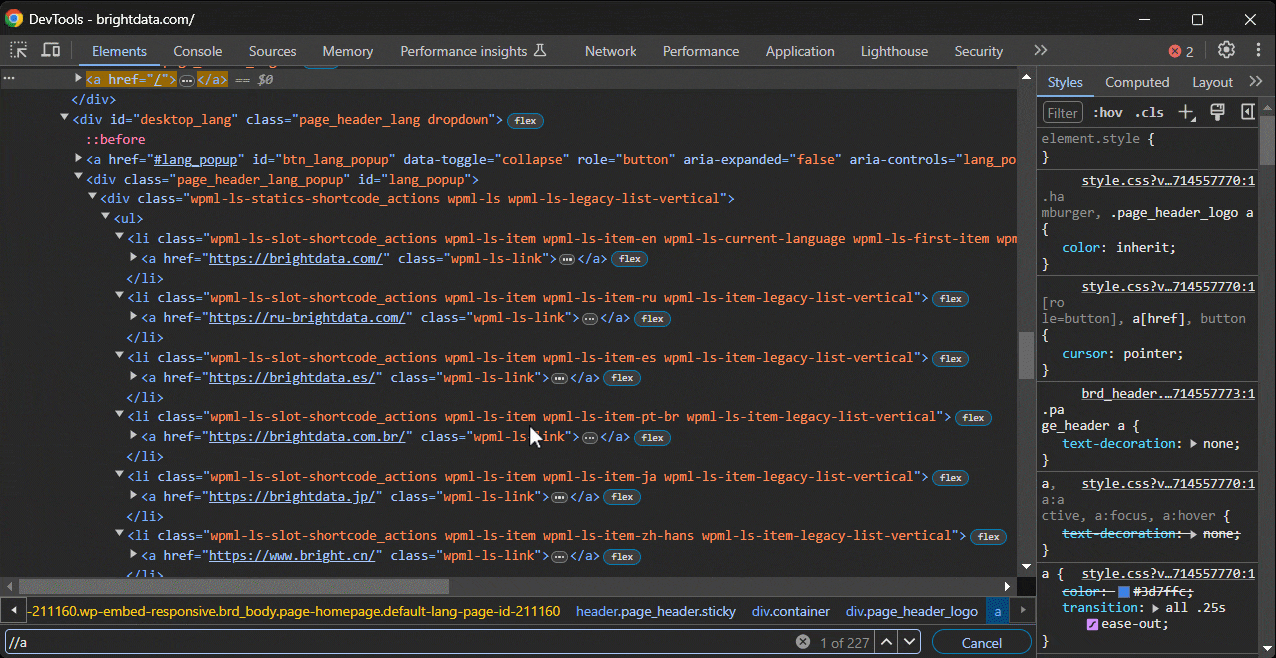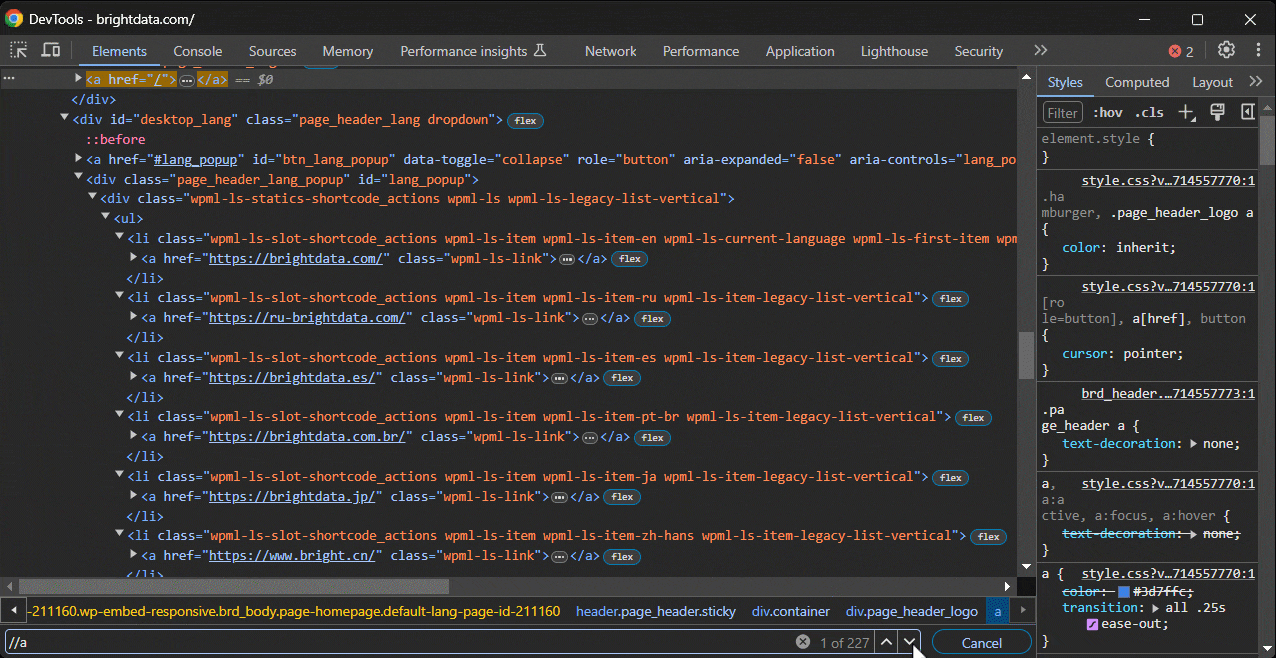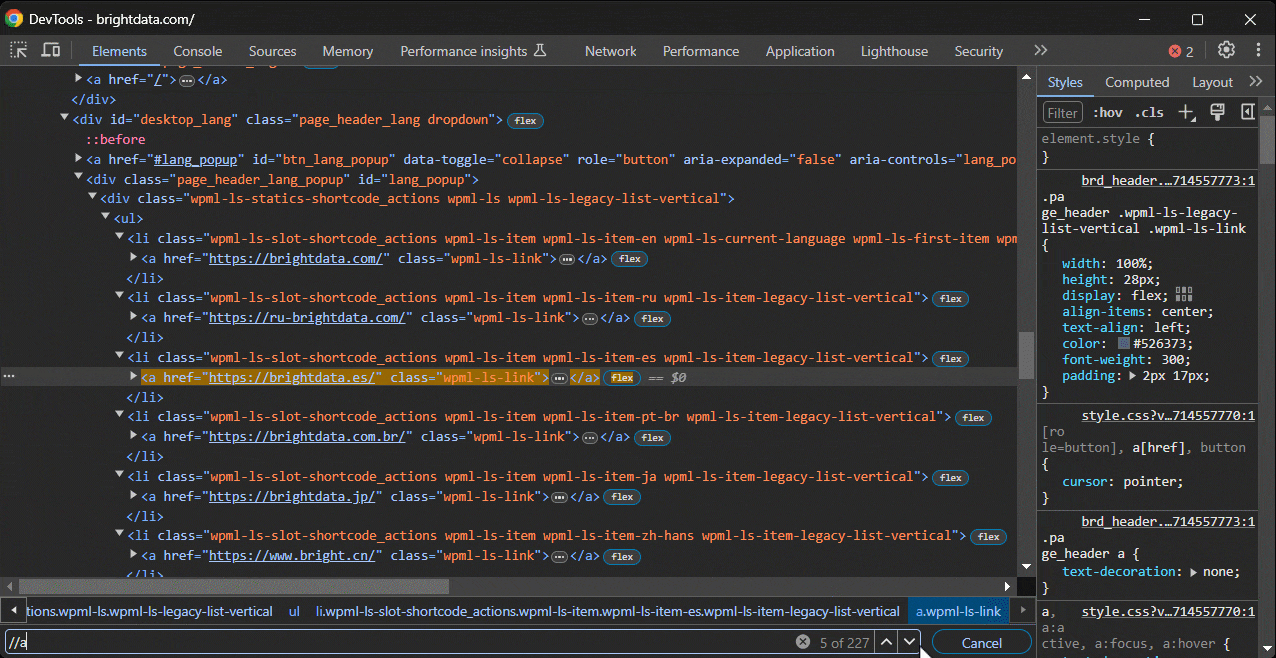
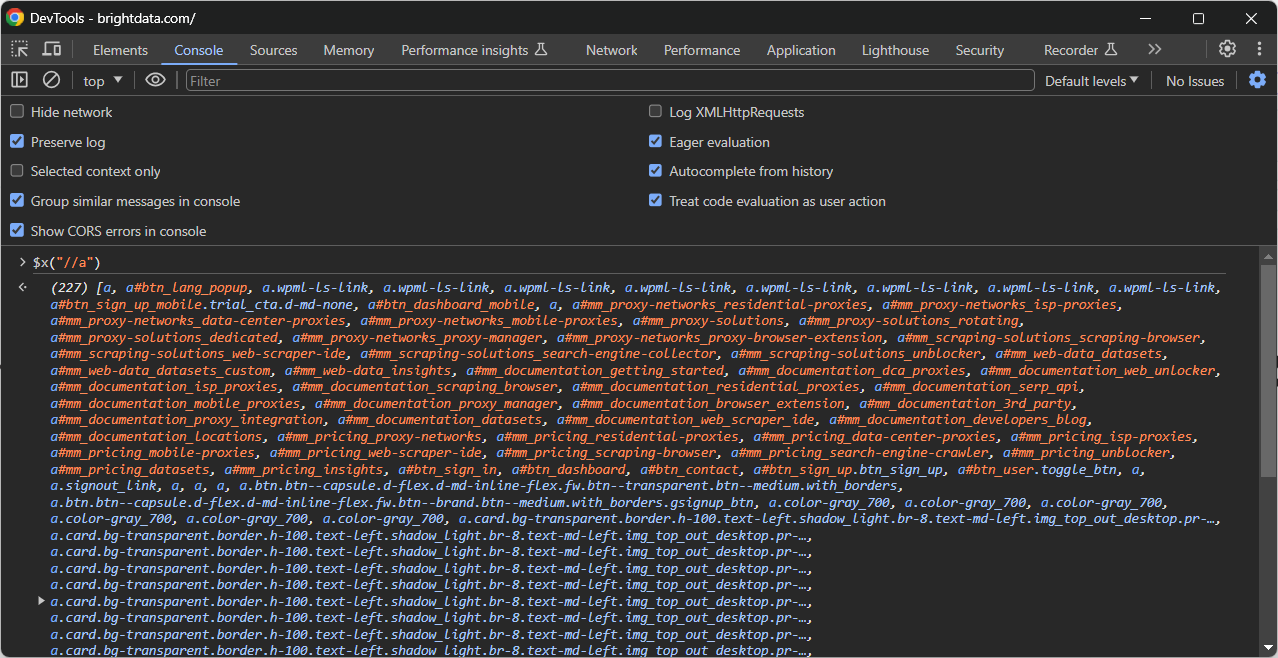
Segundo, chame-a no console com a função especial $x():
Seletores CSS: análise aprofundada
Continue este artigo sobre seletores XPath vs CSS explorando o segundo elemento da comparação, os seletores CSS.
Definição
Os seletores CSS permitem selecionar elementos HTML dentro de uma página da web. Eles fazem parte do CSS e são usados para direcionar os elementos HTML nas páginas da web. Da mesma forma, ferramentas de navegador sem interface gráfica e bibliotecas de Parsing HTML os suportam como uma forma de selecionar nós no DOM.
Um seletor CSS pode direcionar elementos únicos ou grupos de elementos com base em sua ID, classe, atributos e posição na árvore do documento. Embora os seletores CSS desempenhem um papel crucial na aplicação de estilos e formatação a páginas da web, eles também são uma ótima ferramenta quando se trata de Scraping de dados.
Sintaxe
A melhor maneira de explicar a sintaxe dos seletores CSS é mostrá-los por meio de alguns exemplos:
- Seletor de elemento: para direcionar elementos com base em seu nome de tag. Por exemplo,
pseleciona todos os elementos<p>no DOM. - Seletor de classe: para selecionar elementos com um atributo de classe específico. Por exemplo,
.highlightseleciona todos os elementos com o atributo HTMLclass="highlight <outras_classes>". - Seletor de ID: para selecionar um elemento específico com base em seu atributo ID. Por exemplo,
#navbarseleciona o elemento comid="navbar". - Seletor de atributo: para selecionar elementos com base em seus atributos. Por exemplo,
input[type="text"]seleciona todos os elementos<input>com o atributotype="text". - Seletor descendente: para selecionar elementos que são descendentes de outro elemento. Por exemplo,
div aseleciona todos os elementos<a>que são descendentes de elementos<div>. - Seletor de filho: para selecionar elementos que são filhos diretos de outro elemento. Por exemplo,
ul > liseleciona todos os elementos<li>que são filhos diretos de elementos<ul>. - Seletor de irmãos adjacentes: para selecionar um elemento que é imediatamente precedido por um elemento irmão especificado. Por exemplo,
h2 + pseleciona o elemento<p>imediatamente após um elemento<h2>.
Lembre-se de que diferentes navegadores fornecem diferentes implementações do padrão CSS. Verifique sites como caniuse.com para obter informações sobre a compatibilidade de um operador ou sintaxe CSS específico.
Prós
- Excelente desempenho: a maioria dos navegadores possui um mecanismo seletor CSS dedicado que garante alto desempenho. Esse mecanismo é usado principalmente para estilização, mas também pode ser útil ao usar seletores CSS em uma página por meio de uma ferramenta de automação do navegador.
- Rápido de aprender: a curva para dominar os seletores CSS é bastante suave, mesmo para iniciantes, graças à sua sintaxe intuitiva.
- Sintaxe fácil e bem conhecida: eles têm uma sintaxe concisa que não envolve operadores ou funções complexas. Além disso, a maioria dos desenvolvedores web sabe como usá-los, o que os torna capazes de usá-los em mais do que apenas estilo.
- Ótima manutenção: os seletores CSS são projetados para serem fáceis de ler e atualizar, simplificando a manutenção do código.
- Compatibilidade geral: os navegadores web modernos e as melhores ferramentas de Scraping de dados oferecem suporte a eles. Isso garante uma seleção consistente de nós em diferentes plataformas, dispositivos e casos de uso, sem a necessidade de soluções alternativas específicas para cada ambiente.
Contras
- Não suportam funções e operadores avançados: ao contrário do XPath, os seletores CSS são bastante diretos e não têm muitas funções ou operadores. Por exemplo, você não pode usá-los para selecionar nós de texto ou extrair dados do DOM.
- Não suportam a travessia ascendente da árvore DOM: eles podem procurar elementos no DOM apenas a partir do nó raiz e movendo-se para baixo.
Dicas e truques
Assim como no caso do XPath, o Chrome pode testar e gerar seletores CSS diretamente em uma página.
Suponha que você esteja interessado em escrever um seletor CSS para direcionar um nó específico. Acesse a página de destino no Chrome, clique com o botão direito do mouse no elemento de interesse e selecione “Inspecionar”:
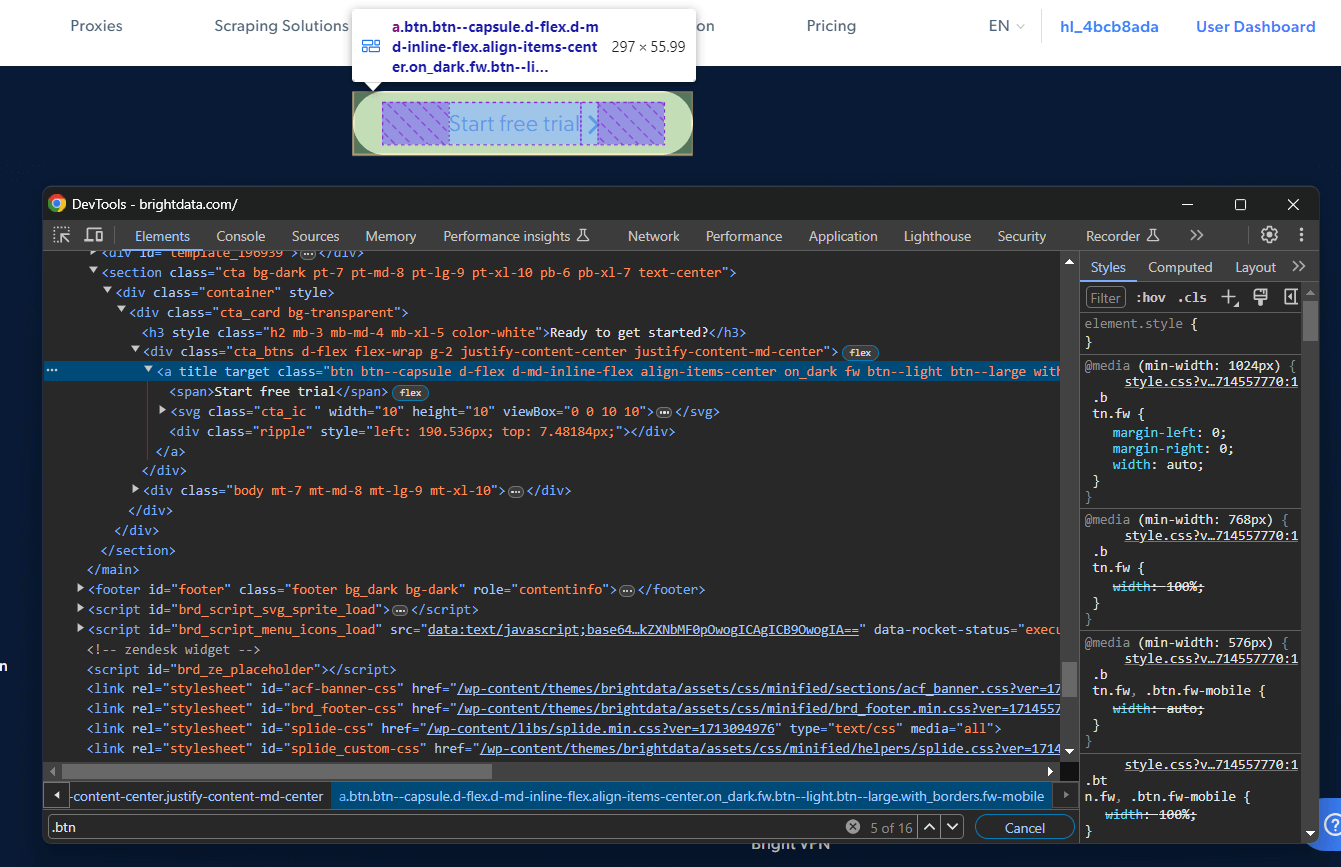
Clique com o botão direito do mouse no elemento DOM específico e selecione “Copiar > Copiar seletor” para obter um seletor CSS completo para ele. No exemplo acima, você receberá:
#site-content > section.cta.bg-dark.pt-7.pt-md-8.pt-lg-9.pt-xl-10.pb-6.pb-xl-7.text-center > div > div > div.cta_btns.d-flex.flex-wrap.g-2.justify-content-center.justify-content-md-center > a
Como você pode ver, é muito longo e específico para a implementação. Embora seja útil para se ter uma ideia, não use os seletores CSS gerados com essa função na produção.
Digamos que você precise testar um seletor CSS em uma página da web. No Chrome, existem algumas maneiras de fazer isso.
A primeira abordagem é colar o seletor CSS na barra de pesquisa, conforme mostrado abaixo, que pode ser ativada com o atalho CTRL/Command + F :
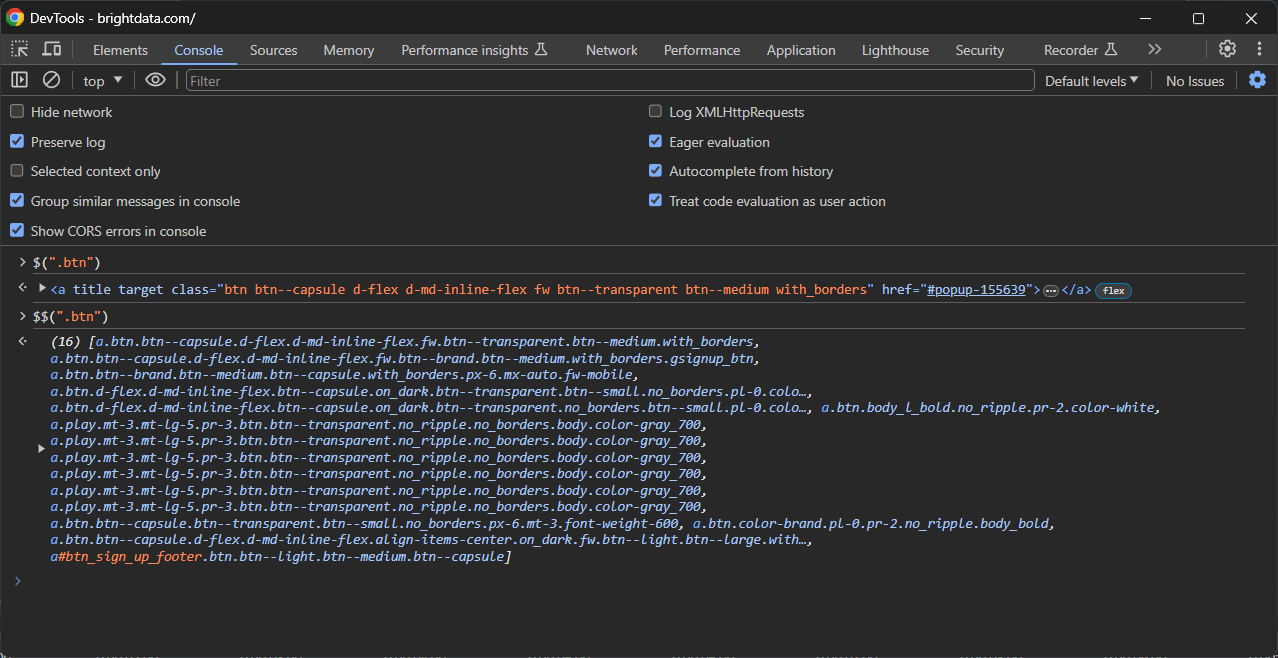
A segunda é testá-los no console usando estas funções especiais:
$(): para selecionar um único elemento com o seletor CSS especificado.- $$(): Para selecionar todos os elementos correspondentes.
Use-as como no exemplo a seguir:
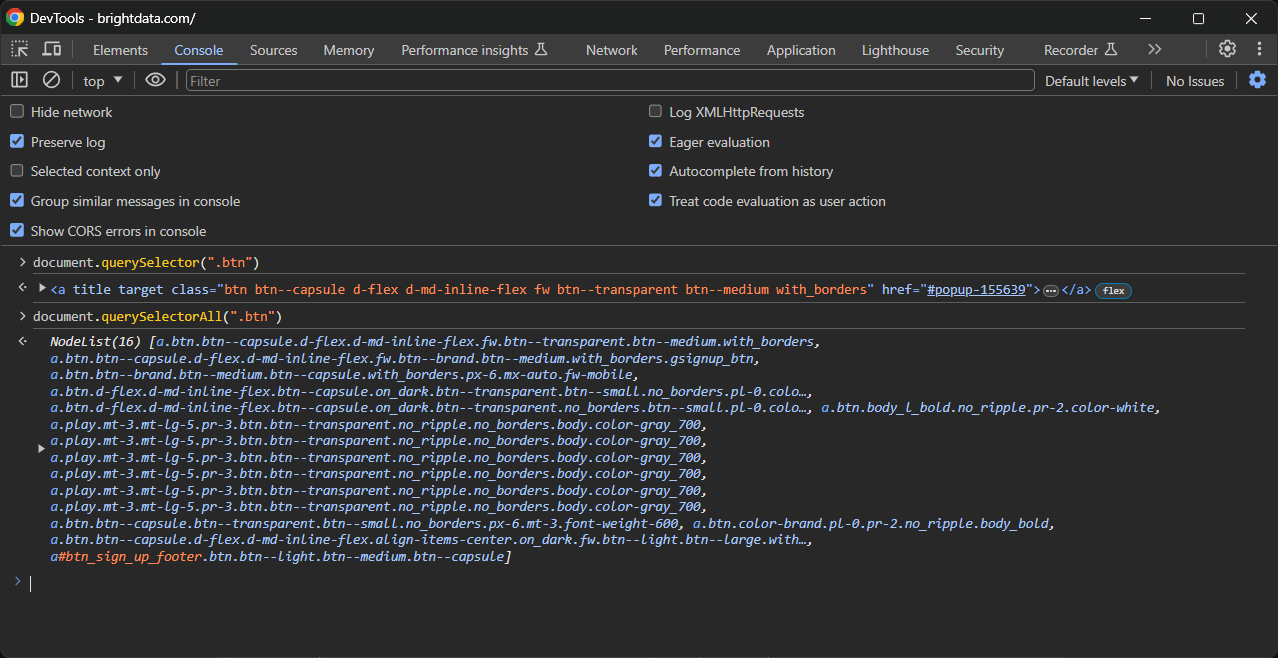
De forma equivalente, você pode usar as funções JavaScript querySelector() e querySelectorAll():
XPath vs Seletor CSS: Comparação direta
Agora que você sabe o que são seletores XPath e CSS, está pronto para se aprofundar na análise do seletor XPath vs CSS.
Para uma comparação direta rápida, confira a tabela resumida abaixo:
| Aspecto | XPath | Seletores CSS |
| Padrão W3C | Sim | Sim |
| Especificação mais recente | XPath 3.1 (2017) | CSS Nível 4 (em constante atualização) |
| Compatibilidade | A maioria dos navegadores de scraping e ferramentas de scraping ainda suportam o XPath 1.0 | A maioria dos navegadores de scraping e ferramentas de scraping suportam a especificação mais recente |
| Sintaxe | Complexa e prolixa | Simples e concisa |
| Funções e operadores | Muitas | Poucos |
| Seleção de nó de texto | Suportada | Não suportado |
| Desempenho no navegador | Médio/Lento | Rápido |
| Suporte de biblioteca | Normalmente suportado por bibliotecas de Parsing XML | Normalmente suportado pela maioria das bibliotecas de Parsing HTML |
Simplicidade
A sintaxe do XPath geralmente parece muito mais complexa em comparação com os seletores CSS. Sua sintaxe se assemelha a uma linguagem de consulta baseada em caminho, o que envolve uma curva de aprendizado íngreme para desenvolvedores que não estão familiarizados com ela. No entanto, o XPath oferece controle preciso sobre a seleção e a travessia de elementos.
Os seletores CSS são geralmente mais simples e intuitivos quando se trata de selecionar elementos DOM. Eles usam padrões familiares, como nomes de tags, classes e IDs, tornando-os fáceis de entender e usar, mesmo para iniciantes. Os seletores CSS são amplamente adotados no desenvolvimento web, o que torna sua sintaxe bastante familiar.
Velocidade
Conforme mostrado por um benchmark, as expressões XPath aplicadas a árvores DOM em um navegador tendem a ser mais lentas do que os seletores CSS. A razão é que os mecanismos XPath geralmente precisam realizar operações de travessia mais complexas do que os mecanismos seletores CSS. Além disso, a maioria dos navegadores modernos possui mecanismos seletores CSS altamente otimizados, que permitem a seleção eficiente de elementos HTML. Quanto às bibliotecas de Parsing HTML, as diferenças de desempenho dependem da implementação subjacente.
Casos de uso
O XPath é ótimo para consultar e navegar em documentos XML usando XSLT ou para extração simples de dados. Seus recursos avançados podem ser úteis em cenários específicos de scraping de dados, como ao direcionar nós pais. Os seletores CSS são usados predominantemente para estilizar documentos HTML e selecionar nós em scripts modernos de Scraping de dados.
Conclusão
Seletores XPath ou CSS? Neste guia sobre seletores XPath e CSS, você aprendeu que ambos são métodos eficazes para selecionar elementos DOM. O XPath se concentra mais em documentos XML e oferece recursos avançados, enquanto os seletores CSS funcionam muito bem em páginas HTML e são mais simples.
Ao usar expressões XPath e seletores CSS no Scraping de dados da web, o verdadeiro problema é ser bloqueado por tecnologias anti-bot. Independentemente da estratégia de seleção de nós que você adotar, esses sistemas podem detectar e bloquear seu script de extração automatizado. Felizmente, a Bright Data oferece várias soluções de ponta para você:
- Web Scraper API: APIs fáceis de usar para acesso programático a dados estruturados da web de dezenas de domínios populares.
- Navegador de scraping: um navegador controlável baseado em nuvem que oferece recursos de renderização JavaScript enquanto lida com CAPTCHAs, impressão digital do navegador, novas tentativas automatizadas e muito mais para você. Ele se integra às bibliotecas de navegador de automação mais populares, como Playwright e Puppeteer.
- Web Unlocker: uma API de desbloqueio que pode retornar perfeitamente o HTML bruto de qualquer página, contornando quaisquer medidas anti-scraping.
Não quer lidar com Scraping de dados, mas ainda está interessado em dados online? Explore nossos Conjuntos de dados prontos para uso!





