

Resumo: este tutorial mostrará como extrair dados de um site em C++ e por que essa é uma das linguagens mais eficientes para extração de dados.
Este guia abordará:
- O C++ é uma boa linguagem para web scraping?
- Melhores bibliotecas de web scraping em C++
- Como criar um web scraper em C++
O C++ é uma boa linguagem para web scraping?
C++ é uma linguagem de programação de tipo estático que é amplamente usada para desenvolver aplicativos de alto desempenho. Isso ocorre porque ele é bem conhecido pela sua velocidade, eficiência e recursos de gerenciamento de memória. C++ é uma linguagem versátil que é útil em uma ampla variedade de aplicações, incluindo web scraping.
C++ é uma linguagem compilada e é inerentemente mais rápida do que linguagens interpretadas, como Python. Isso o torna uma excelente opção para criar scrapers rápidos. No entanto, o C++ não foi projetado para desenvolvimento web e não há muitas bibliotecas disponíveis para web scraping. Embora existam alguns pacotes de terceiros, as opções não são tão extensas quanto em Python, Ruby ou Java.
Em resumo, o web scraping em C++ é possível e eficiente, mas exige mais programação de baixo nível em comparação com outras linguagens. Vamos descobrir quais ferramentas podem facilitar esse processo!
Melhores bibliotecas de web scraping em C++
Eis algumas bibliotecas populares de web scraping em C++:
- CPR: uma biblioteca moderna de cliente HTTP em C++, inspirada no projeto Python Requests. Ela é um wrapper de libcurl que fornece uma interface fácil de entender, recursos de autenticação integrados e suporte para chamadas assíncronas.
- libxml2: uma biblioteca poderosa e completa para fazer o parsing de documentos XML e HTML, originalmente desenvolvida para o Gnome. Ela suporta manipulação de DOM por meio de seletores XPath.
- Lexbor: uma biblioteca de parsing de HTML rápida e leve, inteiramente escrita em C com suporte para seletores CSS. Ela está disponível somente para Linux.
Durante anos, o parser de HTML mais usado para C++ foi o Gumbo. Ele não recebe manutenção desde 2016 e até mesmo o README oficial agora desaconselha seu uso.
Pré-requisitos
Antes de mergulhar nos códigos, você precisa:
Siga o guia abaixo para seu sistema operacional e saiba como cumprir esses pré-requisitos.
Configurar o C++ no macOS
No macOS, o compilador de C, C++ e Objective-C mais popular é o Clang. Tenha em mente que muitos Macs vêm com o Clang pré-instalado. Para verificar isso, abra um terminal e execute o comando abaixo:
clang --version
Se você receber o erro command not found: clang (comando não encontrado), significa que o Clang não está instalado ou configurado corretamente. Nesse caso, você pode instalá-lo por meio das ferramentas de linha de comando do Xcode:
xcode-select --install
Isso pode demorar um pouco, então seja paciente.
Para configurar o vcpkg, você precisará primeiro das ferramentas de desenvolvedor do macOS. Adicione-as ao seu Mac com:
xcode-select --install
Então, você precisará instalar o vcpkg globalmente. Crie uma pasta /dev , insira-a no terminal e execute:
git clone https://github.com/microsoft/vcpkg
O diretório agora conterá o código-fonte. Crie o gerenciador de pacotes com:
./vcpkg/bootstrap-vcpkg.sh
Para executar este comando, talvez você precise de privilégios elevados.
Por fim, adicione /dev/vcpkg ao seu $PATH seguindo este guia.
Para instalar o CMake, baixe o instalador do site oficial, inicialize-o e siga o assistente de instalação.
Configurar o C++ no Windows
Baixe o instalador MinGW-x64 do MSYS2, inicialize-o e siga as instruções. Esse pacote fornece compilações nativas atualizadas do GCC, MinGW-w64 e outras ferramentas e bibliotecas úteis de C++.
No terminal do MSYS2 aberto no final do processo de instalação, execute o comando abaixo para instalar a cadeia de ferramentas MinGW-w64:
pacman -S --needed base-devel mingw-w64-x86_64-toolchain
Aguarde o término do processo e adicione o MinGW ao ambiente PATH , conforme explicado aqui.
Em seguida, você precisará instalar o vcpkg globalmente. Crie uma pasta C:/dev , abra-a no PowerShell e execute:
git clone https://github.com/microsoft/vcpkg
Crie o código-fonte do gerenciador de pacotes contido na subpasta vcpkg com:
./vcpkg/bootstrap-vcpkg.bat
Agora, adicione C:/dev/vcpkg ao seu PATH como feito antes.
Só resta instalar o CMake. Baixe o instalador, clique duas vezes nele e certifique-se de marcar a opção abaixo durante a configuração.

Configurar o C++ no Linux
Em distribuições baseadas em Debian, instale o GCC (GNU Compiler Collection), CMake e outros pacotes úteis para desenvolvimento com:
sudo apt install build-essential cmake
Isso pode levar algum tempo, então seja paciente.
Em seguida, você precisará instalar o vcpkg globalmente. Crie um diretório /dev , abra-o no terminal e digite:
git clone https://github.com/microsoft/vcpkg
O subdiretório vcpkg agora conterá o código-fonte do gerenciador de pacotes. Crie a ferramenta com:
./vcpkg/bootstrap-vcpkg.sh
Note que esse comando pode exigir privilégios de administrador.
Em seguida, adicione /dev/vcpkg à sua variável de ambiente $PATH seguindo este guia.
Perfeito! Agora você tem tudo o que precisa para começar a usar o web scraping em C++!
Como criar um web scraper em C++
Neste capítulo, você aprenderá a codificar um rastreador web em C++. O site de destino será a página inicial da Bright Data e o script cuidará da:
- Conexão com a página web
- Seleção dos elementos HTML de interesse do DOM
- Recuperação dos dados deles
- Exportação dos dados copiados para CSV
No momento, isso é o que os visitantes veem ao explorar a página de destino:

Lembre-se de que a página inicial da BrightData muda com frequência. Então, isso pode ter mudado quando você estiver lendo este artigo.
Alguns dados interessantes para extrair da página são as informações do setor contidas nestes cartões:
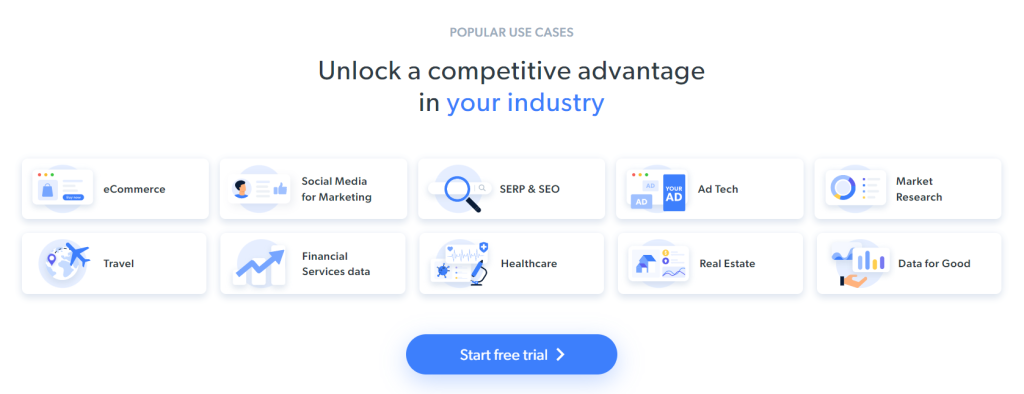
A meta de extração de dados para este tutorial passo a passo foi definida. Vamos ver como fazer web scraping com C++!
Etapa 1: inicialize um projeto de extração de dados em C++
Primeiro, você precisa de uma pasta onde colocar seu projeto C++. Abra o terminal e crie o diretório do projeto com:
mkdir c++-web-scraper
Isso conterá seu script de extração de dados.
Ao criar software em C++, você deve optar por um IDE do Visual Studio. Em detalhes, você está prestes a ver como configurar o Visual Studio Code (VS Code) para desenvolvimento em C++ com o vcpkg como gerenciador de pacotes. Note que procedimentos similares podem ser aplicados a outros IDEs de C++.
O VS Code não oferece suporte integrado para C++, então primeiro você precisa adicionar o plugin C/C++ . Inicie o Visual Studio Code, clique no ícone “Extensions” (extensões) na barra esquerda e digite “C++” no campo de pesquisa na parte superior.
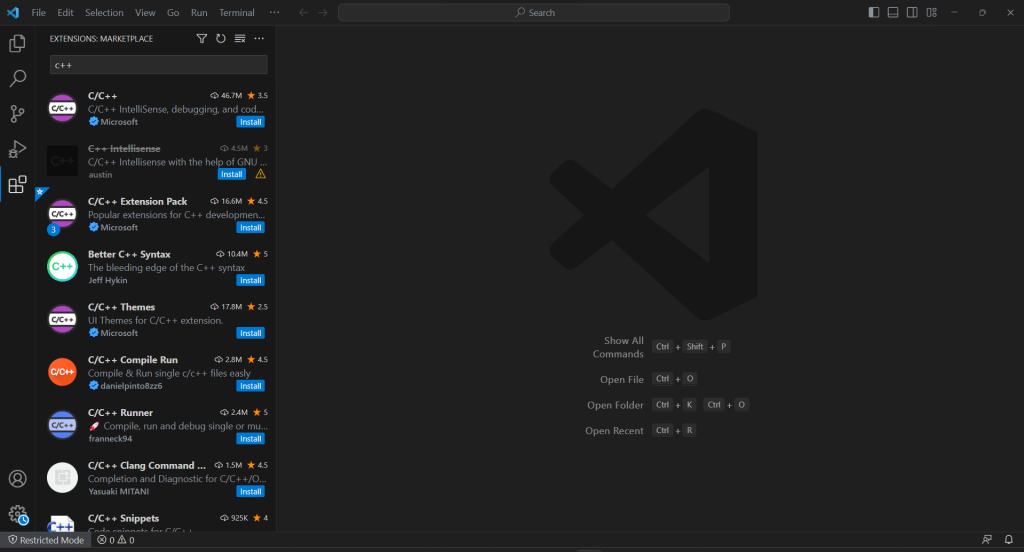
Clique no botão “Install” (instalar) no primeiro elemento para adicionar a funcionalidade de desenvolvimento de C++ ao VS Code. Aguarde a configuração da extensão e abra a pasta c++-web-scraper com “``File``” > “``Open Folder... ``”(arquivo > abrir pasta…).
Clique com o botão direito na seção “EXPLORER” (explorador), selecione “New File…” (novo arquivo) e inicialize um arquivo scraper.cpp da seguinte forma:
#include <iostream>
int main()
{
std::cout << "Hello World" << std::endl;
}
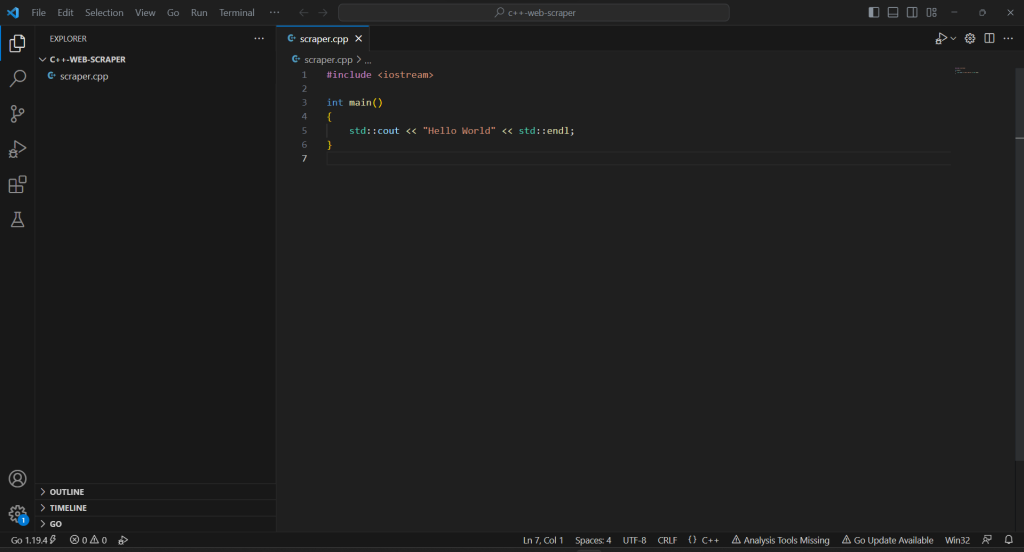
Agora você tem um projeto em C++!
Etapa 2: instale as bibliotecas de scraping
A sintaxe complicada do C++ e seus recursos web limitados podem representar um obstáculo ao criar um web scraper. Para facilitar tudo, você deve adotar algumas bibliotecas C++ de web scraping. Como mencionado anteriormente, a escolha é bastante limitada. Portanto, você deve escolher as mais populares: cpr e libxml2.
Você pode instalá-los no Windows por meio do vcpkg com:
vcpkg install cpr libxml2 --triplet=x64-windows
No macOS, substitua a opção triplet por x64-osx . No Linux, use x64-linux.
No terminal do Visual Studio Code, você também precisa executar o seguinte comando no diretório raiz do seu projeto:
vcpkg integrate install
Isso permitirá a vinculação de pacotes vcpkg ao projeto.
Reinicie o VS Code e então você poderá importar qualquer biblioteca instalada com #include. Então, adicione as três linhas a seguir no topo do seu arquivo scraper.cpp :
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
Certifique-se de que o IDE não relate nenhum erro.
Etapa 3: finalize a inicialização do projeto C++
Para criar o script de scraping em C++ e concluir o processo de inicialização do projeto, você precisará adicionar a extensão CMake Tools ao VS Code:
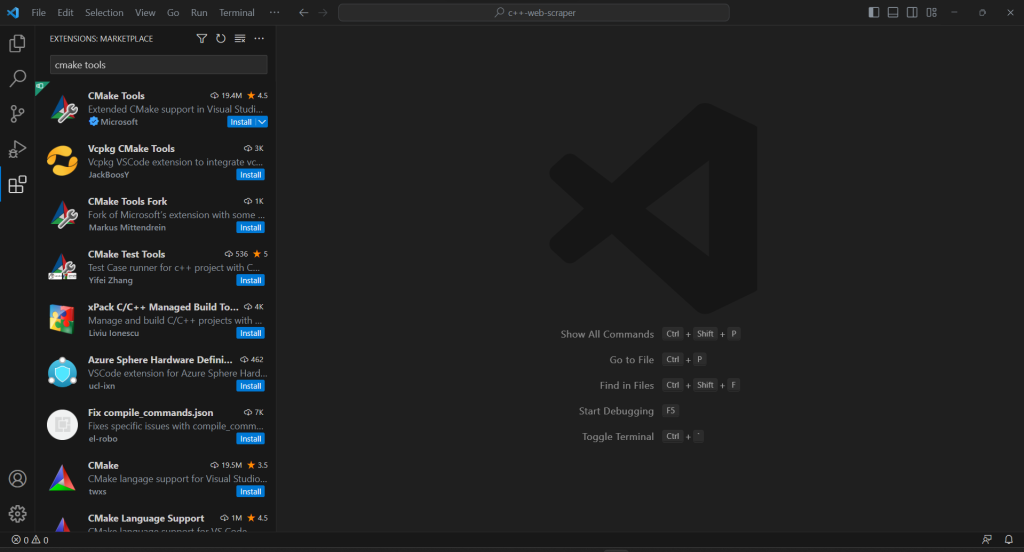
Se o seu projeto não tiver uma pasta .vscode , crie-a. É aí que o VS Code procura configurações relacionadas ao projeto atual.
Configure o CMake Tools para usar o vcpkg como uma cadeia de ferramentas criando um arquivo settings.json dentro da pasta .vscode da seguinte forma:
{
"cmake.configureSettings": {
"CMAKE_TOOLCHAIN_FILE": "c:/dev/vcpkg/scripts/buildsystems/vcpkg.cmake"
}
}
No macOS e no Linux, corrija o campo CMAKE_TOOLCHAIN_FILE de acordo com o caminho em que você instalou o vcpkg. Se você seguiu o guia de configuração acima, ele deve ser /dev/vcpkg/scripts/buildsystems/vcpkg.cmake.
Na barra de pesquisa principal do VS Code, digite “>cmake” e selecione a opção “CMake: Configure”:

Isso permitirá que você selecione a plataforma de compilação de destino. No Windows, opte por “Visual Studio Build Tools 2019 Release – x86_amd64″:

Adicione o arquivo CMakeLists.txt à pasta raiz do seu projeto para configurar o CMake:
cmake_minimum_required(VERSION 3.0.0)
project(main VERSION 0.1.0)
INCLUDE_DIRECTORIES(
C:/dev/vcpkg/installed/x86-windows/include
)
LINK_DIRECTORIES(
C:/dev/vcpkg/installed/x86-windows/lib
)
add_executable(main scraper.cpp)
target_compile_features(main PRIVATE cxx_std_20)
find_package(cpr CONFIG REQUIRED)
target_link_libraries(main PRIVATE cpr::cpr)
find_package(LibXml2 REQUIRED)
target_link_libraries(main PRIVATE LibXml2::LibXml2)
Note que isso envolve os dois pacotes instalados anteriormente. Certifique-se de atualizar INCLUDE_DIRECTORIES e LINK_DIRECTORIES de acordo com sua pasta de instalação do vcpkg .
Para permitir que o Visual Studio Code execute o programa C++, você precisa de um arquivo de configuração de inicialização. Na pasta .vscode , inicialize launch.json conforme abaixo:
{
"configurations": [
{
"name": "C++ Launch (Windows)",
"type": "cppvsdbg",
"request": "launch",
"program": "${workspaceFolder}/build/Debug/main.exe",
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": []
}
]
}
Ao inicializar o comando de execução ou depuração, o VS Code então executará o arquivo no caminho do programa produzido pelo CMake. Observe que no macOS e no Linux, não será um arquivo .exe .
A configuração está pronta!
Toda vez que você quiser depurar ou compilar seu aplicativo, digite “>cmake: Build” no campo de entrada no topo e selecione a opção “CMake: Build”.

Aguarde o término do processo de compilação e execute o programa compilado na seção “Run & Debug” (executar e depurar), ou pressionando F5. Você verá o resultado do seu aplicativo no console de depuração do VSC.
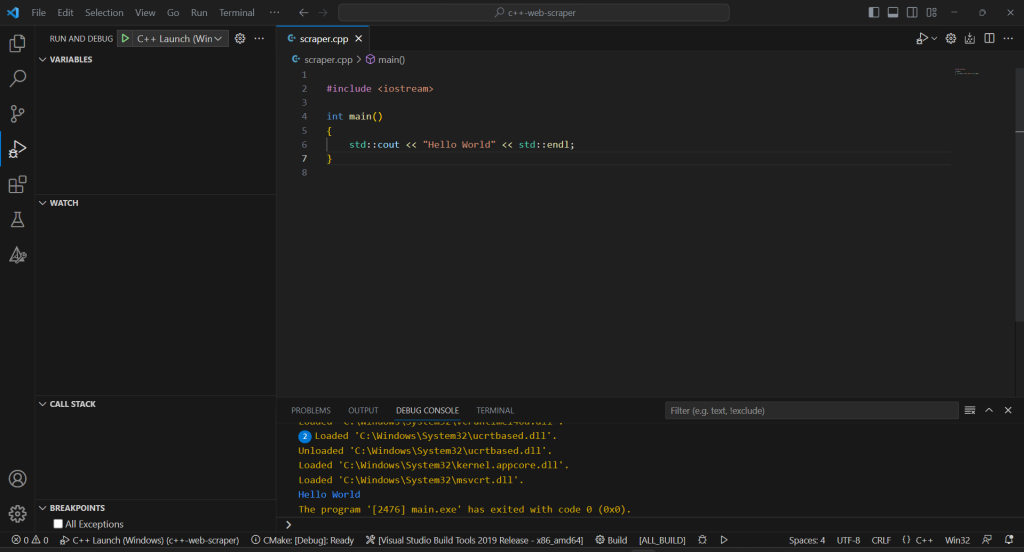
Ótimo! É hora de começar a extrair alguns dados em C++!
Etapa 4: baixe a página de destino com a CPR
Se você quiser extrair dados de uma página, primeiro você precisa recuperar seu documento HTML por meio de uma solicitação HTTP GET .
Use o CPR para baixar a página de destino com:
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"});
Nos bastidores, o método Get() executa uma solicitação GET para o URL passado como parâmetro. response.text conterá a representação em string do código HTML retornado pelo servidor.
Observe que a realização de solicitações HTTP automatizadas pode acionar tecnologias antibot. Elas podem interceptar suas solicitações, impedindo que seu script acesse o site de destino. Especificamente, as soluções antiscraping mais básicas bloqueiam as solicitações recebidas sem um cabeçalho HTTP User-Agent válido. Saiba mais sobre User-Agents para web scraping.
Assim como qualquer outro cliente HTTP, a CPR usa um valor de exemplo para User-Agent. Como ele é muito diferente dos agentes usados pelos navegadores populares, os sistemas antibot podem identificá-lo facilmente. Para evitar ser bloqueado por esse motivo, você pode definir um User-Agent válido na CPR com:
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/121.21.21.da/31/3das/32/1"}, headers);
A solicitação HTTP feita por meio desse Get() agora aparecerá como proveniente do Google Chrome 113.
Isso é o que o scraper.cpp contém atualmente:
#include <iostream>
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
int main()
{
// define the user agent for the GET request
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
// make the HTTP request to retrieve the target page
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"}, headers);
// scraping logic...
}
Etapa 5: faça o parsing do conteúdo HTML com a libxml2
Para que o documento HTML retornado pelo servidor se torne facilmente explorável, você deve primeiro fazer seu parsing.
Passe sua representação de string em C para a função htmlReadMemory() da libxml2 para conseguir isso:
htmlDocPtr doc = htmlReadMemory(response.text.c_str(), response.text.length(), nullptr, nullptr, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
A variável doc agora expõe a API de exploração DOM oferecida pela libxml2. Em detalhes, você pode recuperar elementos HTML na página por meio de seletores XPath. No momento em que este artigo foi escrito, a libxml2 não dava suporte a seletores CSS.
Etapa 6: defina os seletores XPath para obter os elementos HTML desejados
Para definir uma estratégia eficaz de seleção de XPath para os nós HTML de interesse, você precisa analisar o DOM da página de destino. Abra a página inicial da Bright Data no navegador, clique com o botão direito em um dos cartões de setor e escolha “Inspecionar”. Isso abrirá a seção DevTools:
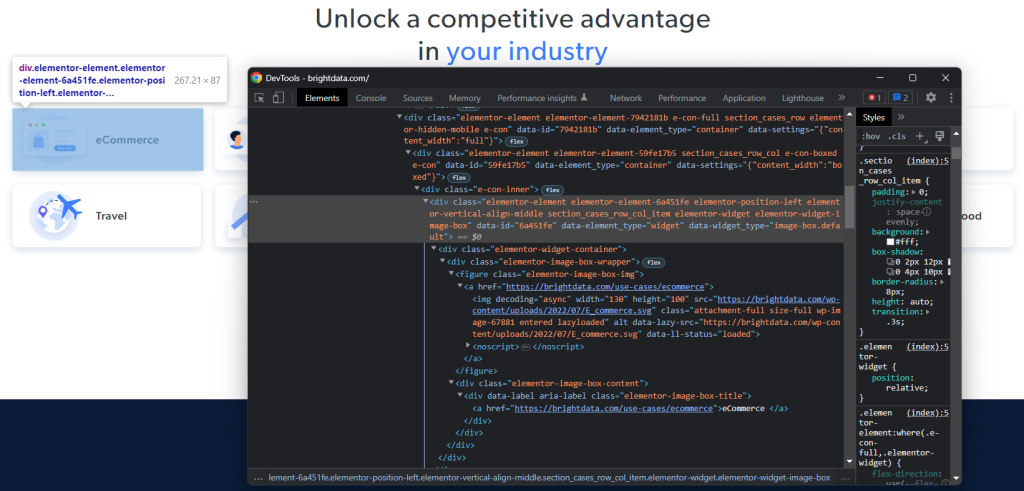
Explore o código HTML e você notará que cada cartão de setor é um elemento <div> que contém:
- Um elemento
<figure>com um<img>representando a imagem do setor e um<a>contendo o URL para a página do setor. - Um elemento
<div>HTML que armazena o nome do setor em um<a>.
Para cada cartão, o objetivo do scraper em C++ é extrair:
- O URL da imagem do setor
- O URL da página do setor
- O nome do setor
Para definir seletores XPath adequados, volte sua atenção para a estrutura DOM dos elementos de interesse. Você notará que pode obter todos os cartões do setor com o seletor XPath abaixo:
//div[contains(@class, 'section_cases_row_col_item')]
Se você tiver alguma dúvida, teste as instruções do XPath no console do navegador com $x():
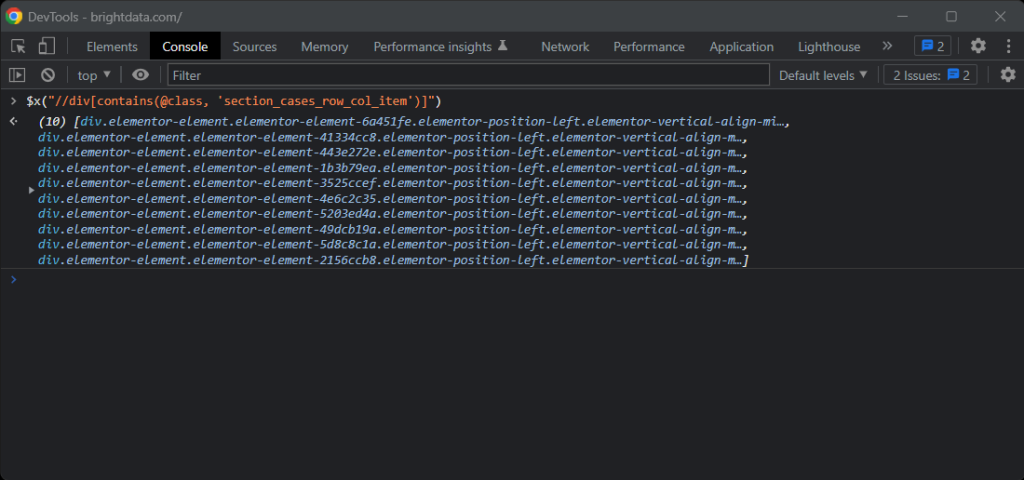
Com um cartão, você pode obter os nós desejados com:
.//figura/a/img.//figura/a.//div[contains(@class, 'elementor-image-box-title')]/a
Etapa 7: extraia dados de uma página web com a libxml2
Agora você poderá usar a libxml2 para aplicar os seletores XPath definidos anteriormente e obter os dados desejados da página HTML de destino.
Primeiro, você precisa de uma estrutura de dados cujas instâncias armazenem os dados extraídos:
struct IndustryCard
{
std::string image;
std::string url;
std::string name;
};
Em C++, uma struct permite agrupar vários atributos de dados com o mesmo nome em um bloco de memória.
Em seguida, inicialize um array de IndustryCards na função main():
std::vector<IndustryCard> industry_cards;
Isso armazenará todos os objetos de dados de extração.
Preencha esse vetor com a seguinte lógica de web scraping em C++:
// define an array to store all retrieved data
std::vector<IndustryCard> industry_cards;
// set the libxml2 context to the current document
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// select all industry card HTML elements
// with an XPath selector
xmlXPathObjectPtr industry_card_html_elements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'section_cases_row_col_item')]", context);
// iterate over the list of industry card elements
for (int i = 0; i < industry_card_html_elements->nodesetval->nodeNr; ++i)
{
// get the current element of the loop
xmlNodePtr industry_card_html_element = industry_card_html_elements->nodesetval->nodeTab[i];
// set the libxml2 context to the current element
// to limit the XPath selectors to its children
xmlXPathSetContextNode(industry_card_html_element, context);
xmlNodePtr image_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a/img", context)->nodesetval->nodeTab[0];
std::string image = std::string(reinterpret_cast<char *>(xmlGetProp(image_html_element, (xmlChar *)"data-lazy-src")));
xmlNodePtr url_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a", context)->nodesetval->nodeTab[0];
std::string url = std::string(reinterpret_cast<char *>(xmlGetProp(url_html_element, (xmlChar *)"href")));
xmlNodePtr name_html_element = xmlXPathEvalExpression((xmlChar *)".//div[contains(@class, 'elementor-image-box-title')]/a", context)->nodesetval->nodeTab[0];
std::string name = std::string(reinterpret_cast<char *>(xmlNodeGetContent(name_html_element)));
// instantiate an IndustryCard struct with the collected data
IndustryCard industry_card = {image, url, name};
// add the object with the scraped data to the vector
industry_cards.push_back(industry_card);
}
// free up the resource allocated by libxml2
xmlXPathFreeObject(industry_card_html_elements);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
O trecho acima seleciona os cartões de setor aplicando o seletor XPath definido anteriormente com xmlXPathEvalExpression(). Em seguida, ele itera sobre eles e implementa uma abordagem semelhante para obter os elementos filhos de interesse de cada cartão. Em seguida, ele extrai o URL da imagem do setor, o URL da página e o nome deles. Por fim, ele libera os recursos alocados pela libxml2.
Como você pode ver, o web scraping usando C++ com libxml2 não é tão complexo. Graças ao xmlGetProp() e xmlNodeGetContent() , você pode obter o valor de um atributo HTML e o conteúdo de um nó, respectivamente.
Agora que você sabe como funciona a extração de dados em C++, você tem as ferramentas para dar um passo adiante e também extrair dados das páginas do setor. Você só precisa seguir os links descobertos aqui e criar uma nova lógica de scraping. É disso que se trata o rastreamento e extração de dados da web!
Incrível! Você acabou de atingir seus objetivos. No entanto, o tutorial ainda não acabou.
Etapa 8: exporte os dados extraídos para CSV
Ao final do loop for() , industry_cards armazenará os dados extraídos em instâncias struct. Como você pode imaginar, esse não é o melhor formato para fornecer dados para outras equipes. Veja por que você deve converter os dados recuperados para CSV.
Você pode exportar um vetor para um arquivo CSV com funções C++ integradas, da seguinte forma:
// initialize the CSV output file
std::ofstream csv_file("output.csv");
// write the CSV header
csv_file << "url,image,name" << std::endl;
// poupulate the CSV output file
for (IndustryCard industry_card : industry_cards)
{
// transfrom each industry card record to a CSV record
csv_file << industry_card.url << "," << industry_card.image << "," << industry_card.name << std::endl;
}
// free up the file resources
csv_file.close();
O código acima cria um arquivo output.csv e o inicializa com o registro do cabeçalho. Em seguida, ele itera sobre o array industry_cards , converte cada elemento em uma string no formato CSV e o anexa ao arquivo de saída.
Crie seu script de scraping em C++, execute-o e você verá o seguinte arquivo output.csv no diretório raiz do seu projeto:
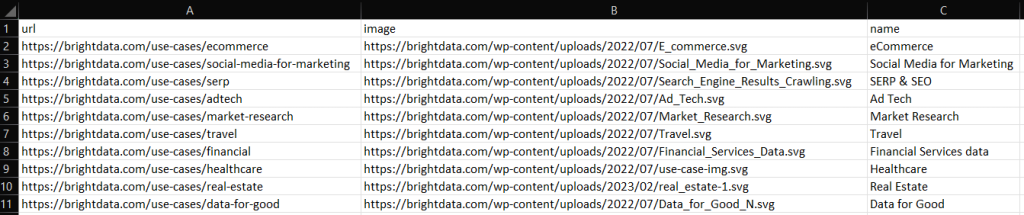
Muito bem! Agora você sabe como exportar para CSV dados extraídos em C++!
Etapa 9: junte tudo
Eis o scraper inteiro em C++:
// scraper.cpp
#include <iostream>
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
#include <vector>
// define a struct where to store the scraped data
struct IndustryCard
{
std::string image;
std::string url;
std::string name;
};
int main()
{
// define the user agent for the GET request
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
// make an HTTP GET request to retrieve the target page
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"}, headers);
// parse the HTML document returned by the server
htmlDocPtr doc = htmlReadMemory(response.text.c_str(), response.text.length(), nullptr, nullptr, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
// define an array to store all retrieved data
std::vector<IndustryCard> industry_cards;
// set the libxml2 context to the current document
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// select all industry card HTML elements
// with an XPath selector
xmlXPathObjectPtr industry_card_html_elements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'section_cases_row_col_item')]", context);
// iterate over the list of industry card elements
for (int i = 0; i < industry_card_html_elements->nodesetval->nodeNr; ++i)
{
// get the current element of the loop
xmlNodePtr industry_card_html_element = industry_card_html_elements->nodesetval->nodeTab[i];
// set the libxml2 context to the current element
// to limit the XPath selectors to its children
xmlXPathSetContextNode(industry_card_html_element, context);
xmlNodePtr image_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a/img", context)->nodesetval->nodeTab[0];
std::string image = std::string(reinterpret_cast<char *>(xmlGetProp(image_html_element, (xmlChar *)"data-lazy-src")));
xmlNodePtr url_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a", context)->nodesetval->nodeTab[0];
std::string url = std::string(reinterpret_cast<char *>(xmlGetProp(url_html_element, (xmlChar *)"href")));
xmlNodePtr name_html_element = xmlXPathEvalExpression((xmlChar *)".//div[contains(@class, 'elementor-image-box-title')]/a", context)->nodesetval->nodeTab[0];
std::string name = std::string(reinterpret_cast<char *>(xmlNodeGetContent(name_html_element)));
// instantiate an IndustryCard struct with the collected data
IndustryCard industry_card = {image, url, name};
// add the object with the scraped data to the vector
industry_cards.push_back(industry_card);
}
// free up the resource allocated by libxml2
xmlXPathFreeObject(industry_card_html_elements);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
// initialize the CSV output file
std::ofstream csv_file("output.csv");
// write the CSV header
csv_file << "url,image,name" << std::endl;
// poupulate the CSV output file
for (IndustryCard industry_card : industry_cards)
{
// transfrom each industry card record to a CSV record
csv_file << industry_card.url << "," << industry_card.image << "," << industry_card.name << std::endl;
}
// free up the file resources
csv_file.close();
return 0;
}
E pronto! Em cerca de 80 linhas de código, você pode criar um script de extração de dados em C++!
Conclusão
Neste tutorial, aprendemos por que o C++ é uma linguagem eficiente para extrair dados da web. Embora não haja tantas bibliotecas de scraping quanto em outras linguagens, existem algumas. E aqui você teve a oportunidade de ver quais são as mais populares. Em seguida, você viu como usar CPR e libxml2 para criar um rastreador em C++ que pode coletar dados de um alvo real.
No entanto, muitos desafios surgem com web scraping. Na verdade, um número cada vez maior de sites vem implementando tecnologias antibot e antiscraping para proteger seus dados. Essas ferramentas são capazes de detectar as solicitações automatizadas realizadas pelo seu script de scraping em C++ e bani-las. Felizmente, existem muitas soluções automatizadas para suas necessidades de coleta de dados. Entre em contato conosco para descobrir qual é a melhor solução para o seu caso de uso.
Não quer lidar de forma alguma com web scraping, mas tem interesse em dados web? Explore nossos datasets prontos para uso.






