

Neste guia, você aprenderá a criar um raspador de notícias automatizado com n8n, OpenAI e o servidor Bright Data MCP. Ao final deste tutorial, você será capaz de realizar o seguinte.
- Criar uma instância n8n auto-hospedada
- Instalar nós da comunidade no n8n
- Crie seus próprios fluxos de trabalho com a n8n
- Integrar agentes de IA usando OpenAI e n8n
- Conecte seu AI Agent ao Web Unlocker usando o servidor MCP da Bright Data
- Enviar e-mails automatizados usando o n8n
Primeiros passos
Para começar, precisamos iniciar uma instância auto-hospedada do n8n. Quando ela estiver em execução, precisaremos instalar um nó da comunidade n8n. Também precisamos obter chaves de API da OpenAI e da Bright Data para executar nosso fluxo de trabalho de raspagem.
Iniciando o n8n
Crie um novo volume de armazenamento para o n8n e inicie-o em um contêiner do Docker.
# Create persistent volume
sudo docker volume create n8n_data
# Start self-hosted n8n container with support for unsigned community nodes
sudo docker run -d
--name n8n
-p 5678:5678
-v n8n_data:/home/node/.n8n
-e N8N_BASIC_AUTH_ACTIVE=false
-e N8N_ENCRYPTION_KEY="this_is_my_secure_encryption_key_1234"
-e N8N_ALLOW_LOADING_UNSIGNED_NODES=true
-e N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true
-e N8N_HOST="0.0.0.0"
-e N8N_PORT=5678
-e WEBHOOK_URL="http://localhost:5678"
n8nio/n8nAgora, abra o site http://localhost:5678/ em seu navegador. Provavelmente, será solicitado que você entre ou crie um login.

Depois de fazer login, acesse suas configurações e selecione “Community Nodes” (Nós da comunidade). Em seguida, clique no botão intitulado “Instalar um nó de comunidade”.

Em “npm Package Name” (Nome do pacote npm), digite “n8n-nodes-mcp”.

Obtenção de chaves de API
Você precisará de uma chave de API OpenAI e de uma chave de API Bright Data. Sua chave OpenAI permite que sua instância n8n acesse LLMs como o GPT-4.1. Sua chave de API da Bright Data permite que seu LLM acesse dados da Web em tempo real por meio do servidor MCP da Bright Data.
Chaves da API da OpenAI
Acesse a plataforma de desenvolvedores da OpenAI e crie uma conta, caso ainda não o tenha feito. Selecione “API keys” (Chaves de API) e clique no botão “Create new secret key” (Criar nova chave secreta). Salve a chave em um local seguro.

Chaves da API da Bright Data
Talvez você já tenha uma conta na Bright Data. Mesmo que tenha, você deve criar uma nova zona do Web Unlocker. No painel de controle da Bright Data, selecione “Proxies and Scraping” (Proxies e raspagem) e clique no botão “Add” (Adicionar).

Você pode usar outros nomes de zona, mas é altamente recomendável nomear essa zona como “mcp_unlocker”. Esse nome permite que ela funcione com o nosso servidor MCP praticamente sem problemas.
Nas configurações de sua conta, copie sua chave de API e coloque-a em um local seguro. Essa chave fornece acesso a todos os serviços da Bright Data.
Agora que temos uma instância n8n auto-hospedada e as credenciais adequadas, é hora de criar nosso fluxo de trabalho.
Criação do fluxo de trabalho

Agora, vamos criar nosso fluxo de trabalho real. Clique no botão “Criar um novo fluxo de trabalho”. Isso lhe dará uma tela em branco para trabalhar.
1. Criando nosso acionador

Começaremos criando um novo nó. Na barra de pesquisa, digite “chat” e selecione o nó “Chat Trigger”.

O Chat Trigger não será nosso acionador permanente, mas facilita muito a depuração. Nosso agente de IA receberá um prompt. Com o nó Chat Trigger, você pode experimentar diferentes prompts facilmente sem precisar editar seus nós.
2. Como adicionar nosso agente

Em seguida, precisamos conectar nosso nó de acionamento a um AI Agent. Adicione outro nó e digite “ai agent” na barra de pesquisa. Selecione o nó AI Agent.

Esse agente de IA contém basicamente todo o nosso tempo de execução. O agente recebe um prompt e, em seguida, executa nossa lógica de raspagem. Você pode ler nosso prompt abaixo. Sinta-se à vontade para ajustá-lo como achar melhor – é por isso que adicionamos o acionador de bate-papo. O snippet abaixo contém o prompt que usaremos para esse fluxo de trabalho.
Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite.3. Conexão de um modelo

Clique no “+” em “Chat Model” e digite “openai” na barra de pesquisa. Selecione o modelo de chat da OpenAI.

Quando solicitado a adicionar credenciais, adicione sua chave de API da OpenAI e salve a credencial.

Em seguida, precisamos escolher um modelo. Você pode escolher entre uma variedade de modelos, mas lembre-se de que esse é um fluxo de trabalho complexo para um único agente. Com o GPT-4o, tivemos sucesso limitado. O GPT-4.1-Nano e o GPT-4.1-Mini se mostraram insuficientes. O modelo completo do GPT-4.1 é mais caro, mas se mostrou incrivelmente competente – portanto, foi com ele que ficamos.

4. Adição de memória

Para gerenciar as janelas de contexto, precisamos adicionar memória. Não precisamos de nada complexo. Precisamos apenas de uma configuração de memória simples para que o nosso modelo possa se lembrar do que está fazendo em todas as etapas.
Escolha a opção “Simple Memory” (Memória simples) para dar memória ao seu modelo.

5. Conexão com o MCP da Bright Data

Para pesquisar na Web, nosso modelo precisa se conectar ao servidor MCP da Bright Data. Clique em “+” em “Tool” (Ferramenta) e selecione o MCP Client (Cliente MCP) que aparece na parte superior da seção “Other Tools” (Outras ferramentas).

Quando solicitado, digite suas credenciais para o servidor MCP da Bright Data. Na caixa “Command” (Comando), digite npx – isso permite que o NodeJS crie e execute automaticamente nosso servidor MCP. Em “Arguments” (Argumentos), adicione @brightdata/mcp. Em “Environments” (Ambientes), insira API_TOKEN=YOUR_BRIGHT_DATA_API_KEY (substitua isso por sua chave real).

O método padrão para essa ferramenta é “List Tools”. É exatamente isso que precisamos fazer. Se o seu modelo conseguir se conectar, ele fará ping no servidor MCP e listará as ferramentas disponíveis para ele.

Quando estiver pronto, insira um prompt no bate-papo. Use um simples pedido para listar as ferramentas disponíveis.
List the tools available to youVocê deve receber uma resposta listando as ferramentas disponíveis para o modelo. Se isso acontecer, você está conectado ao servidor MCP. O trecho abaixo contém apenas uma parte da resposta. No total, há 21 ferramentas disponíveis para o modelo.
Here are the tools available to me:
1. search_engine – Search Google, Bing, or Yandex and return results in markdown (URL, title, description).
2. scrape_as_markdown – Scrape any webpage and return results as Markdown.
3. scrape_as_html – Scrape any webpage and return results as HTML.
4. session_stats – Show the usage statistics for tools in this session.
5. web_data_amazon_product – Retrieve structured Amazon product data (using a product URL).6. Adição das ferramentas de raspagem
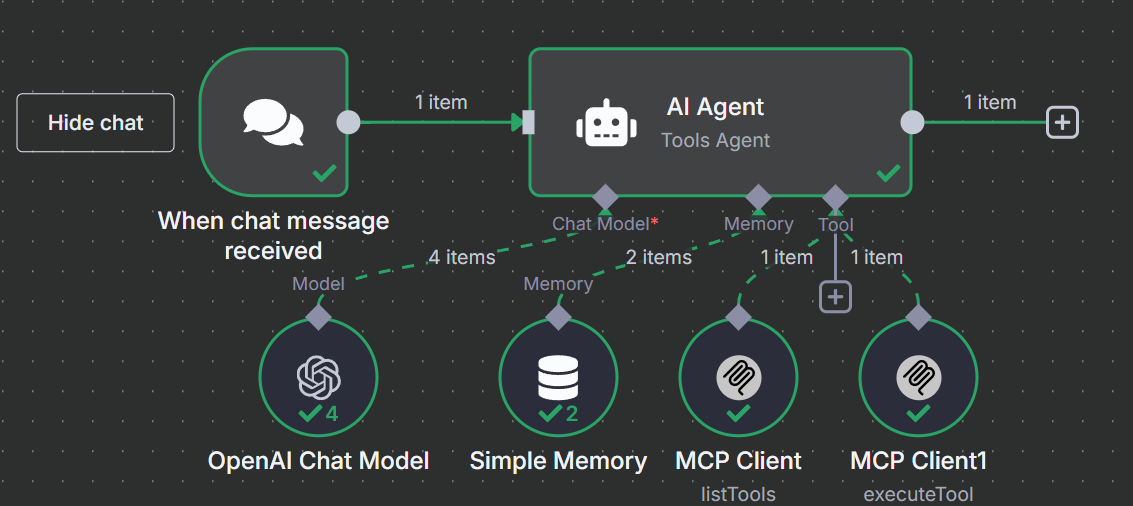
Clique novamente no “+” em “Tool” (Ferramenta). Mais uma vez, selecione a mesma “MCP Client Tool” na seção “Other Tools” (Outras ferramentas).

Dessa vez, defina a ferramenta para usar “Execute Tool”.

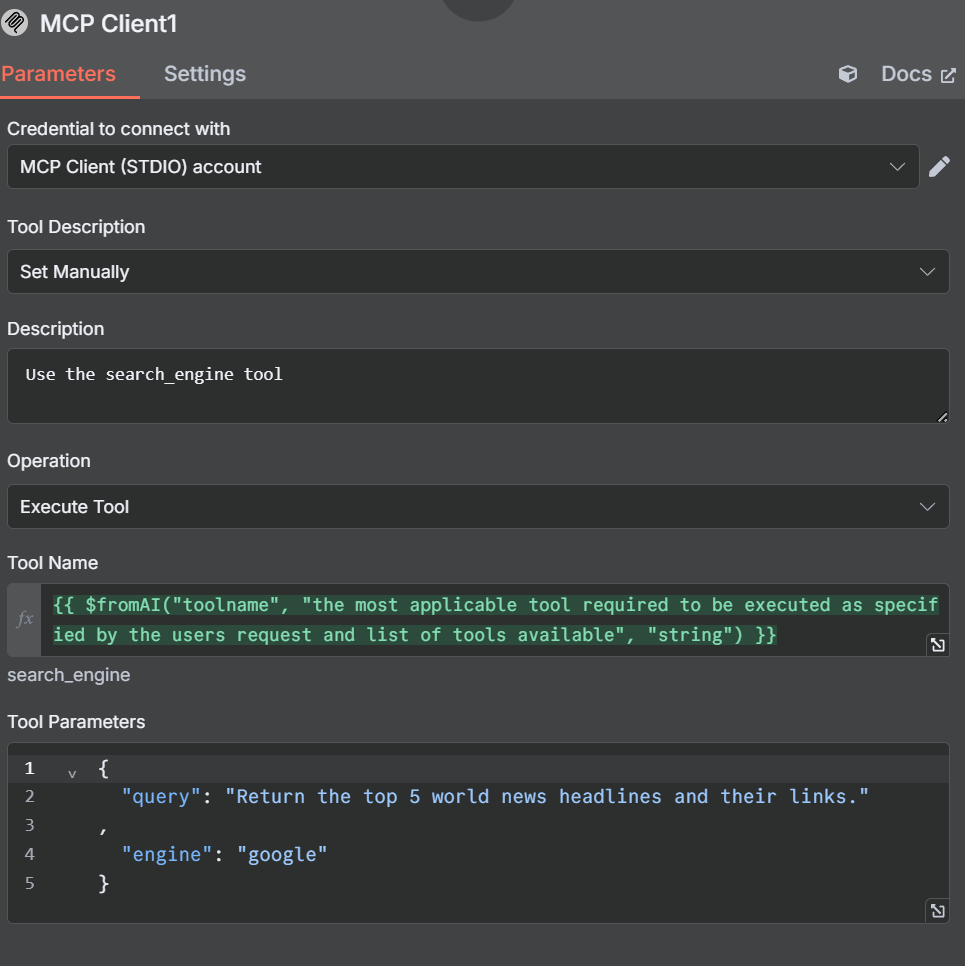
Em “Nome da ferramenta”, cole a seguinte expressão JavaScript. Chamamos a função “fromAI” e passamos o nome da ferramenta, a descrição e o tipo de dado.
{{ $fromAI("toolname", "the most applicable tool required to be executed as specified by the users request and list of tools available", "string") }}Sob os parâmetros, adicione o seguinte bloco. Ele fornece uma consulta ao modelo juntamente com seu mecanismo de pesquisa preferido.
{
"query": "Return the top 5 world news headlines and their links."
,
"engine": "google"
}Agora, ajuste os parâmetros do próprio agente de IA. Adicione a seguinte mensagem do sistema.
You are an expert web scraping assistant with access to Bright Data's Web Unlocker API. This gives you the ability to execute a specific set of actions. When using tools, you must share across the exact name of the tool for it to be executed.
For example, "Search Engine Scraping" should be "search_engine"
Antes de realmente executar o raspador, precisamos ativar as novas tentativas. Os agentes de IA são inteligentes, mas não são perfeitos. Às vezes, os trabalhos falham e precisam ser tratados. Assim como os raspadores codificados manualmente, a lógica de nova tentativa não é opcional se você quiser um produto que funcione de forma consistente.

Execute o prompt abaixo.
Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite.Se tudo estiver funcionando, você deverá receber uma resposta semelhante à abaixo.
Here are real global news headlines for today, each with a direct source link:
1. Reuters
Headline: Houthi ceasefire followed US intel showing militants sought off-ramp
Source: https://www.reuters.com/world/
2. CNN
Headline: UK police arrest man for arson after fire at PM Starmer's house
Source: https://www.cnn.com/world
3. BBC
Headline: Uruguay's José Mujica, world's 'poorest president', dies
Source: https://www.bbc.com/news/world
4. AP News
Headline: Israel-Hamas war, Russia-Ukraine War, China, Asia Pacific, Latin America, Europe, Africa (multiple global crises)
Source: https://apnews.com/world-news
5. The Guardian
Headline: Fowl play: flying duck caught in Swiss speed trap believed to be repeat offender
Source: https://www.theguardian.com/world
These headlines were selected from the main headlines of each trusted global news outlet’s world section as of today.7. O início e o fim

Agora que nosso AI Agent faz seu trabalho, precisamos adicionar o início e o fim do fluxo de trabalho. Nosso coletor de notícias deve funcionar a partir de um agendador, não de um prompt individual. Por fim, nossa saída deve enviar um e-mail usando SMTP.
Adição do gatilho adequado
Procure o nó “Schedule Trigger” e adicione-o ao seu fluxo de trabalho.

Configure-o para ser acionado no horário desejado. Escolhemos 9:00 da manhã.

Agora, precisamos adicionar mais um nó à nossa lógica de acionamento. Esse nó injetará um prompt fictício em nosso modelo de chat.
Adicione o nó “Editar campos” ao seu acionador de agendamento.

Adicione o seguinte ao seu nó Edit Fields como JSON. “sessionId” é apenas um valor fictício – você não pode iniciar um bate-papo sem um sessionId. “chatInput” contém o prompt que estamos injetando no LLM.
{
"sessionId": "google",
"chatInput": "Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite."
}Por fim, conecte essas novas etapas ao seu AI Agent. Seu agente agora pode ser acionado pelo agendador.

Saída dos resultados por e-mail
Clique em “+” no lado direito de seu nó do AI Agent. Adicione o nó “Send Email” (Enviar e-mail) ao final de seu fluxo de trabalho. Adicione suas credenciais de SMTP e, em seguida, use os parâmetros para personalizar o e-mail.

O e-mail
Agora você pode clicar no botão “Testar fluxo de trabalho”. Quando o fluxo de trabalho for executado com êxito, você receberá um e-mail com todas as manchetes atuais. GPT-4.1

Indo além: Raspagem de sites reais
Em seu estado atual, nosso agente de IA encontra manchetes do Google News usando a ferramenta de mecanismo de pesquisa do servidor MCP. Usando apenas um mecanismo de pesquisa, os resultados podem ser inconsistentes. Às vezes, o AI Agent encontra manchetes reais. Outras vezes, ele vê apenas os metadados do site – “Obtenha as últimas manchetes da CNN!”
Em vez de limitar nossa extração à ferramenta do mecanismo de pesquisa, vamos adicionar uma ferramenta de raspagem. Comece adicionando outra ferramenta ao seu fluxo de trabalho. Agora você deve ter três clientes MCP conectados ao seu AI Agent, como na imagem abaixo.
Adição de ferramentas de raspagem

Agora, precisamos abrir as configurações e os parâmetros para essa nova ferramenta. Observe como definimos a Descrição da ferramenta manualmente desta vez. Estamos fazendo isso para que o agente não se confunda.
Em nossa descrição, dizemos ao AI Agent para usar essa ferramenta para extrair URLs. Nosso nome de ferramenta é semelhante ao que criamos anteriormente.
{{ $fromAI("toolname", "the most applicable scraping tool required to be executed as specified by the users request and list of tools available", "string") }}Em nossos parâmetros, especificamos uma url em vez de uma consulta ou mecanismo de pesquisa.
{
"url": "{{$fromAI('URL', 'url that the user would like to scrape', 'string')}}"
}Ajuste dos outros nós e ferramentas
A ferramenta do mecanismo de pesquisa
Com nossa ferramenta de raspagem, definimos a descrição manualmente para evitar que o AI Agent se confunda. Também vamos ajustar a ferramenta do mecanismo de pesquisa. As alterações não são extensas, apenas informamos manualmente que ele deve usar a ferramenta Search Engine ao executar esse cliente MCP.
Editar campos: O prompt fictício
Abra o nó Edit Fields e ajuste nosso prompt fictício.
{
"sessionId": "google",
"chatInput": "get the latest news from https://www.brightdata.com/blog and https://www.theguardian.com/us with your scrape_as_markdown and Google News with your search engine tool to find the latest global headlines--pull actual headlines, not just the site description."
}Seus parâmetros devem se parecer com a imagem abaixo.

Originalmente, usamos o Reddit em vez do The Guardian. No entanto, os LLMs do OpenAI obedecem ao arquivo robots.txt. Embora o Reddit seja fácil de ser extraído, o AI Agent se recusa a fazer isso.

O novo feed com curadoria
Ao adicionar outra ferramenta, demos ao nosso Agente de IA o poder de realmente raspar sites, não apenas resultados de mecanismos de pesquisa. Dê uma olhada no e-mail abaixo. Ele tem um formato muito mais limpo, com uma análise altamente detalhada das notícias de cada fonte.

Conclusão
Ao combinar o n8n, o OpenAI e o servidor MCP (Model Context Protocol) da Bright Data, você pode automatizar a raspagem e a entrega de notícias com fluxos de trabalho avançados e orientados por IA. O MCP facilita o acesso a dados da Web atualizados e estruturados em tempo real, capacitando seus agentes de IA a extrair conteúdo preciso de qualquer fonte. À medida que a automação da IA evolui, ferramentas como o MCP da Bright Data serão essenciais para uma coleta de dados eficiente, escalável e confiável.
A Bright Data o incentiva a ler nosso artigo sobre raspagem da web com servidores MCP. Registre-se agora para obter seus créditos gratuitos para testar nossos produtos.






