

Neste tutorial, você aprenderá:
- O que é o AWS Glue e o que ele oferece.
- Por que a Bright Data oferece suporte a pipelines ETL graças aos seus serviços de recuperação de dados da web.
- Como integrar a Bright Data a uma tarefa ETL no AWS Glue.
Vamos começar!
O que é o AWS Glue?
O AWS Glue é um serviço de integração de dados sem servidor criado para simplificar o processo de descoberta, preparação e combinação de dados de várias fontes em qualquer escala.
Ele permite que você crie fluxos de trabalho ETL (Extract, Transform, Load) para análise, aprendizado de máquina e desenvolvimento de aplicativos sem gerenciar a infraestrutura. O AWS Glue acelera o desenvolvimento do pipeline de dados e torna os dados prontamente acessíveis para análise. Isso é conseguido centralizando seu catálogo de dados e fornecendo ferramentas de criação de tarefas visuais e baseadas em código.
Os três recursos mais relevantes que ele oferece são:
- Descobrir e organizar dados: inferir esquemas automaticamente, catalogar metadados e conectar-se a fontes de dados na AWS, no local e em outras nuvens.
- Transforme e limpe os dados: editor visual de tarefas, notebooks interativos, suporte a ETL em streaming e deduplicação integrada baseada em ML.
- Crie e monitore pipelines: programe, automatize e dimensione tarefas, com a capacidade de monitorar pipelines com insights detalhados e gatilhos.
Saiba mais nos documentos oficiais.
Por que integrar a Bright Data ao seu fluxo de trabalho ETL do AWS Glue
Integrar o Bright Data a um fluxo de trabalho ETL da AWS pode expandir drasticamente o escopo e a qualidade de seus pipelines de dados.
Enquanto o ETL tradicionalmente se concentra na extração de dados estruturados de fontes conhecidas, o Bright Data permite o acesso a dados estruturados da web em tempo real. Isso revela insights que, de outra forma, exigiriam coleta manual ou Infraestrutura de scraping complexa.
Além da extração de dados da web (E), o Bright Data também pode melhorar sua fase de transformação (T). Durante a transformação, você pode enriquecer os Conjuntos de dados anexando informações ao vivo sobre o mercado, produtos ou redes sociais aos seus registros. Por exemplo, você pode adicionar métricas de desempenho de ações, preços da concorrência ou metadados da empresa aos seus Conjuntos de dados internos.
Essas informações ajudam as equipes a tomar decisões mais informadas. A verificação de dados é outro benefício importante, pois os dados coletados podem ser cruzados com fontes confiáveis. Isso ajuda a garantir a precisão antes de carregar os dados no armazenamento de destino.
Como usar a Bright Data para recuperar dados da web para uma tarefa ETL do AWS Glue
Esta seção guiada mostrará uma possível integração do Bright Data em uma tarefa ETL do AWS Glue. Especificamente, você verá como construir este pipeline ETL de amostra:
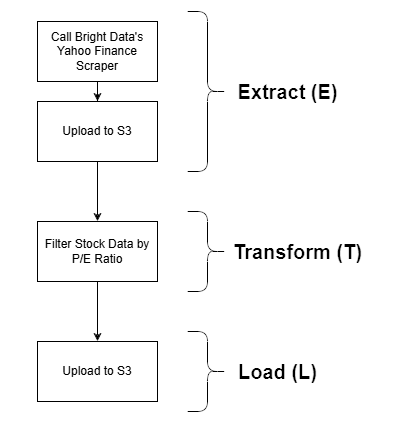
O Bright Data entra em ação na fase de extração (E), graças às suas poderosas opções de recuperação de dados da web. O Yahoo Finance Scraper é empregado para recuperar dados de ações, que são então filtrados pela relação P/E e, finalmente, armazenados em um bucket S3. Este é um exemplo simples, mas ainda assim uma demonstração realista de um fluxo de trabalho ETL completo.
Observação: outras abordagens de integração da Bright Data no AWS Glue podem ser exploradas e consideradas após este tutorial.
Siga as instruções abaixo para começar!
Pré-requisitos
Antes de seguir este tutorial, certifique-se de ter o seguinte configurado:
- Uma conta AWS (mesmo uma conta de avaliação gratuita funcionará).
- Uma conta Bright Data com uma chave API configurada. Siga as instruções oficiais para gerar sua chave API.
- Um bucket S3 definido em sua conta AWS.
- Conhecimento básico de Python para escrever um script que se integre às APIs de scraping da Bright Data e envie os dados coletados para o seu bucket S3.
- Habilidades básicas em SQL para escrever uma consulta simples na fase Transform (T) do pipeline ETL.
Para este tutorial, vamos supor que seu bucket S3 se chama bright-data-etl-bucket: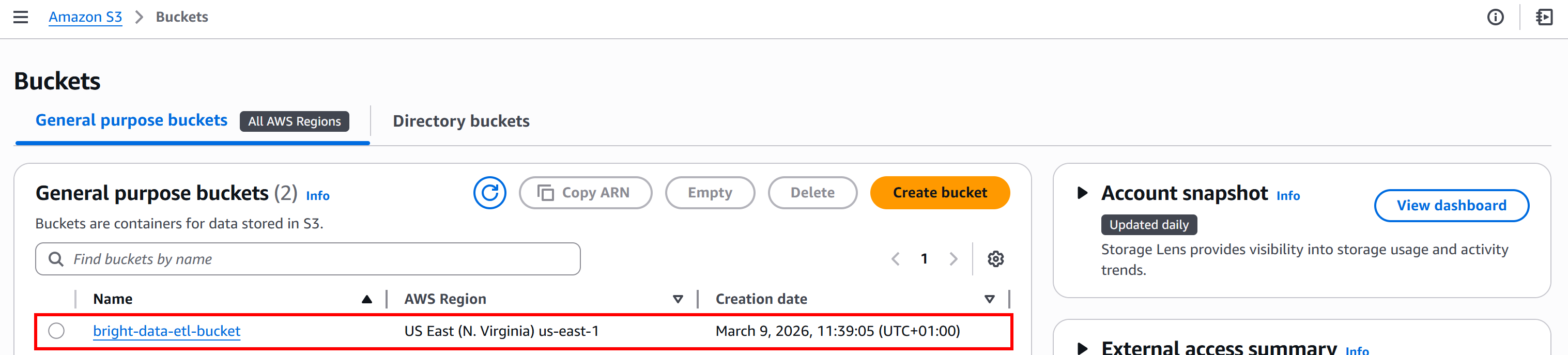
Também é útil ter alguma familiaridade com o funcionamento das APIs de Scraping de dados da Bright Data.
Etapa 1: Comece a usar as APIs de scraping da Bright Data
Ao desenvolver um pipeline ETL, você deve obviamente começar pela fase Extract (E). O primeiro passo é recuperar os dados usando o Bright Data Yahoo Finance Scraper, por isso é importante se familiarizar com ele.
Comece criando uma conta Bright Data, se ainda não tiver uma. Caso contrário, faça login em sua conta existente. No painel de controle, navegue até a seção“Scrapers”:
Em seguida, vá para a guia “Web Scrapers Library”. Pesquise por “finance” e selecione a opção “Yahoo Finance Scraper”. Acesse o Scraper disponível: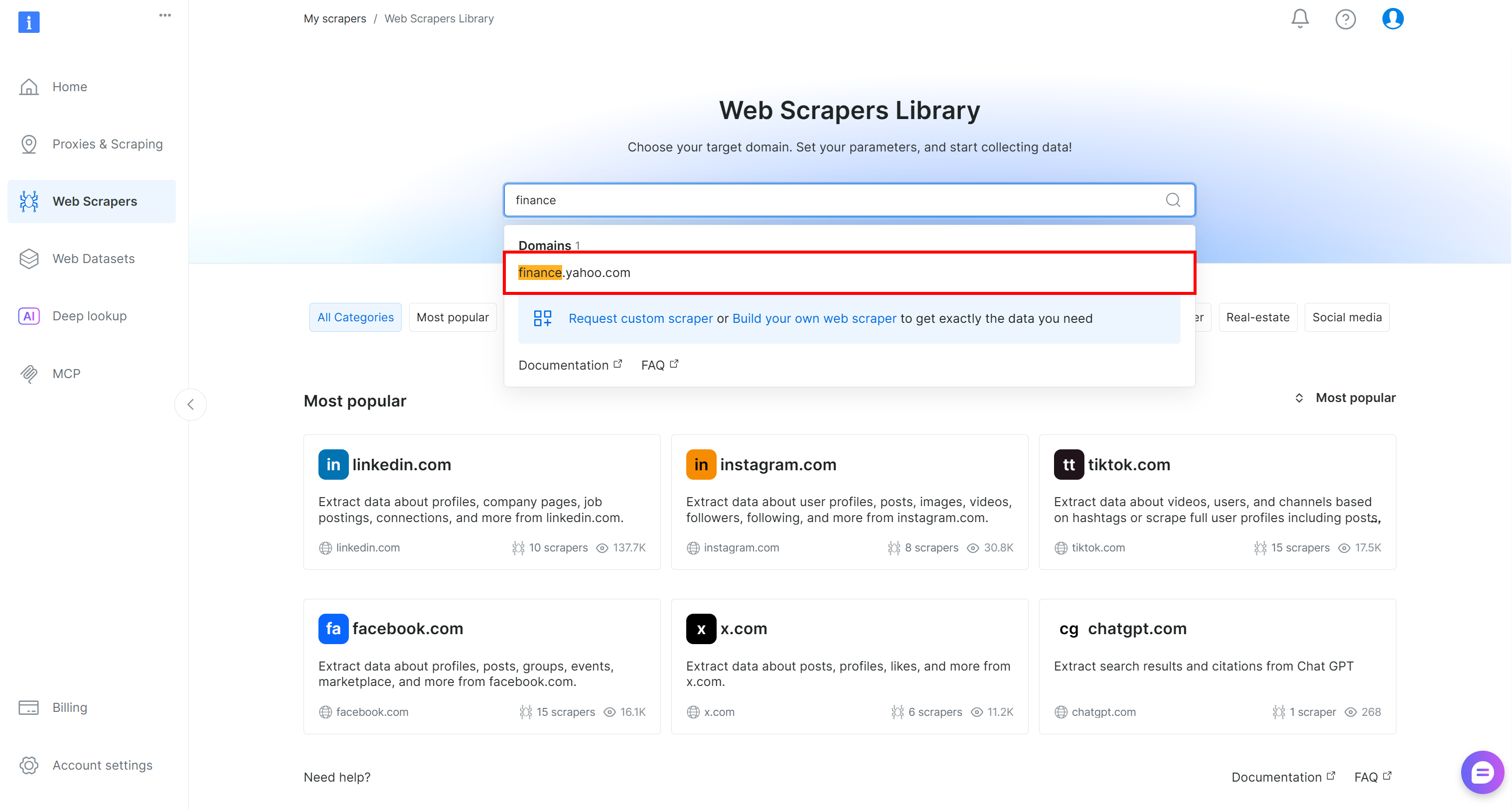
Na página do Yahoo Finance Scraper, você pode explorar os requisitos de entrada e o esquema de saída deste Scraper: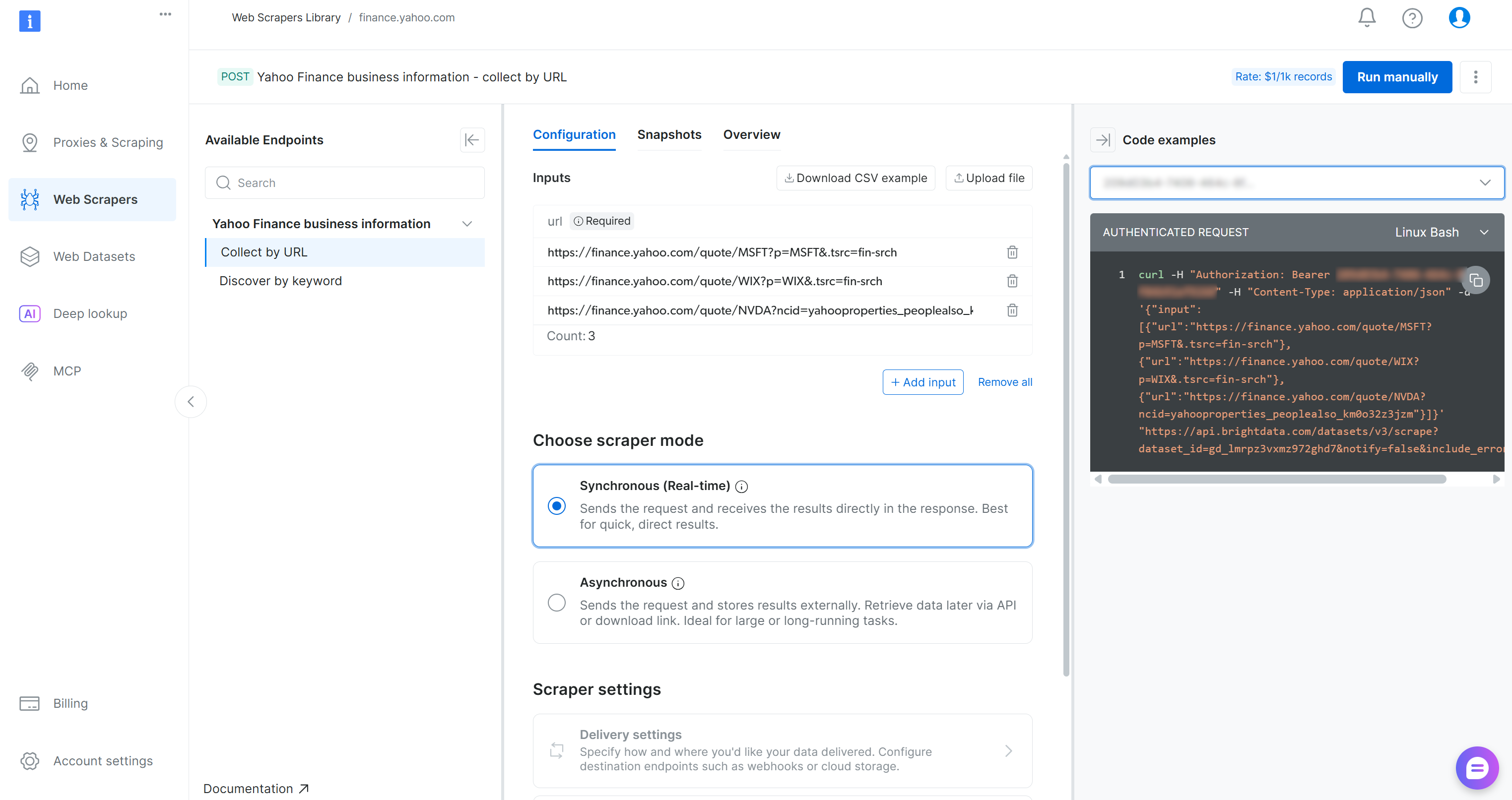
O painel de controle também fornece trechos de código em várias linguagens de programação para uma configuração rápida. O ponto principal é que o Scraper aceita uma ou mais páginas de ações do Yahoo Finance como entrada e retorna dados de ações estruturados em tempo real. Perfeito!
Etapa 2: Configure a entrega S3
As APIs de Scraping de dados da Bright Data oferecem suporte à entrega automática de dados coletados para o Amazon S3. Portanto, faz sentido aproveitar esse recurso útil para acelerar a etapa de coleta de dados. Para configurar a entrega do Amazon S3, primeiro você precisa habilitar o modo assíncrono.
Na guia “Configuração”, selecione a opção “Assíncrono”. Em seguida, clique no botão “Configurações de entrega”:
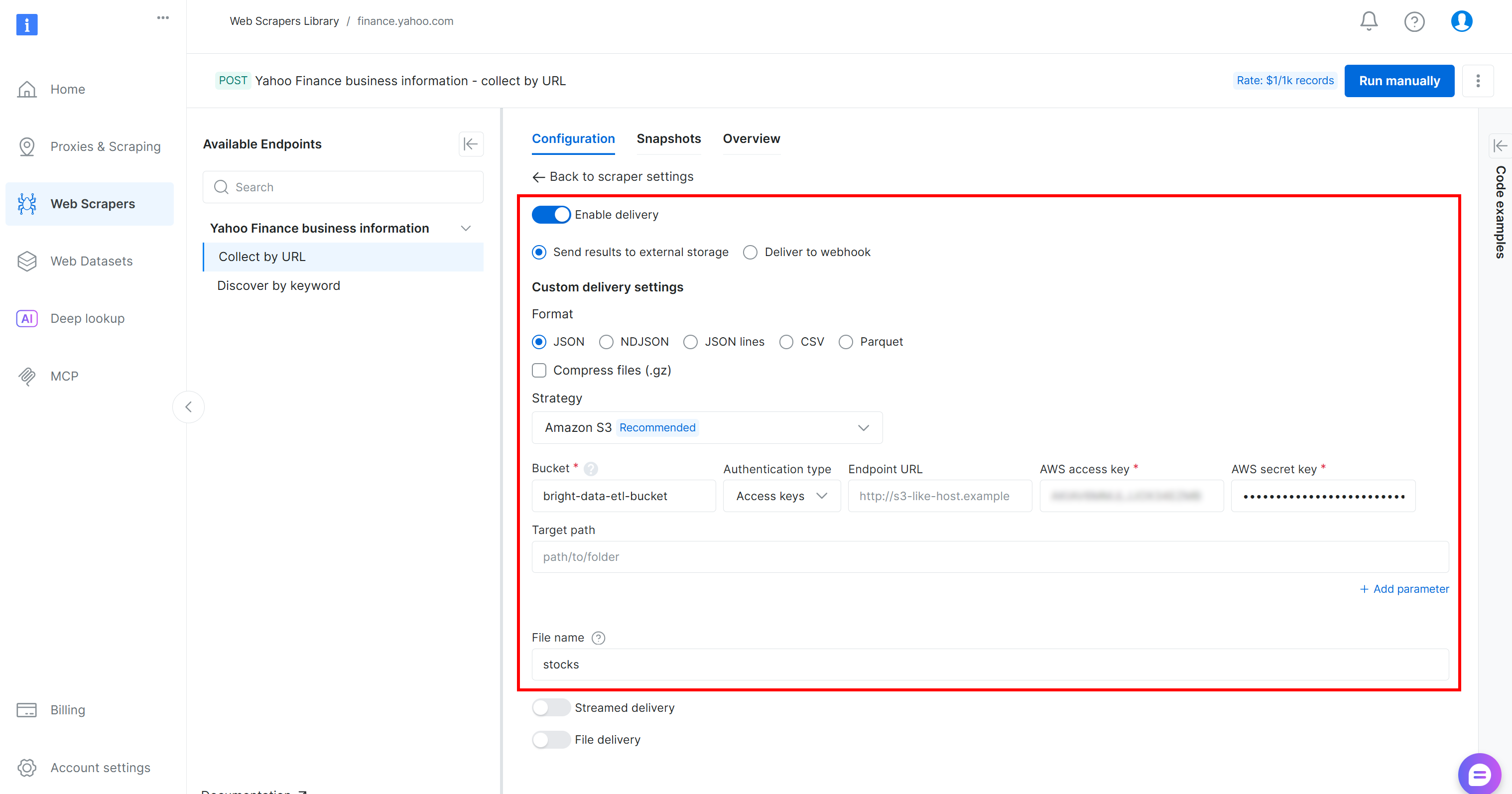
Configure a entrega de dados para o seu bucket do Amazon S3 preenchendo o formulário da seguinte maneira:
- Habilite a opção “Habilitar entrega”.
- Defina o formato como
JSON. - Selecione “Amazon S3” como destino de armazenamento.
- Insira o nome do seu bucket S3 (neste exemplo,
bright-data-etl-bucket). (O campo URL do endpoint pode ser deixado em branco.) - Deixe o campo “Caminho de destino” em branco para enviar o arquivo para a pasta raiz do bucket.
- Defina a opção “Tipo de autenticação” para o valor “Chaves de acesso”.
- Cole sua ID da chave de acesso AWS e sua chave secreta de acesso AWS.
- Defina o nome do arquivo como
stocks.
Com essa configuração, a API de Scraping de dados será executada no modo assíncrono. Isso significa que a Bright Data criará uma tarefa de scraping que será executada em sua infraestrutura. Quando a tarefa for concluída, os dados coletados serão automaticamente carregados no seu bucket Amazon S3, onde poderão ser acessados pela sua tarefa AWS Glue ETL. Incrível!
Etapa 3: execute a lógica de extração de dados da Web
Para verificar se a lógica de extração de dados da web funciona, adicione alguns URLs de ações do Yahoo Finance (por exemplo, NVDA, AAPL, GOOGL, MSFT, AMZN, TSLA, META, AVGO, BRK.B, LLY) e pressione o botão “Executar manualmente”: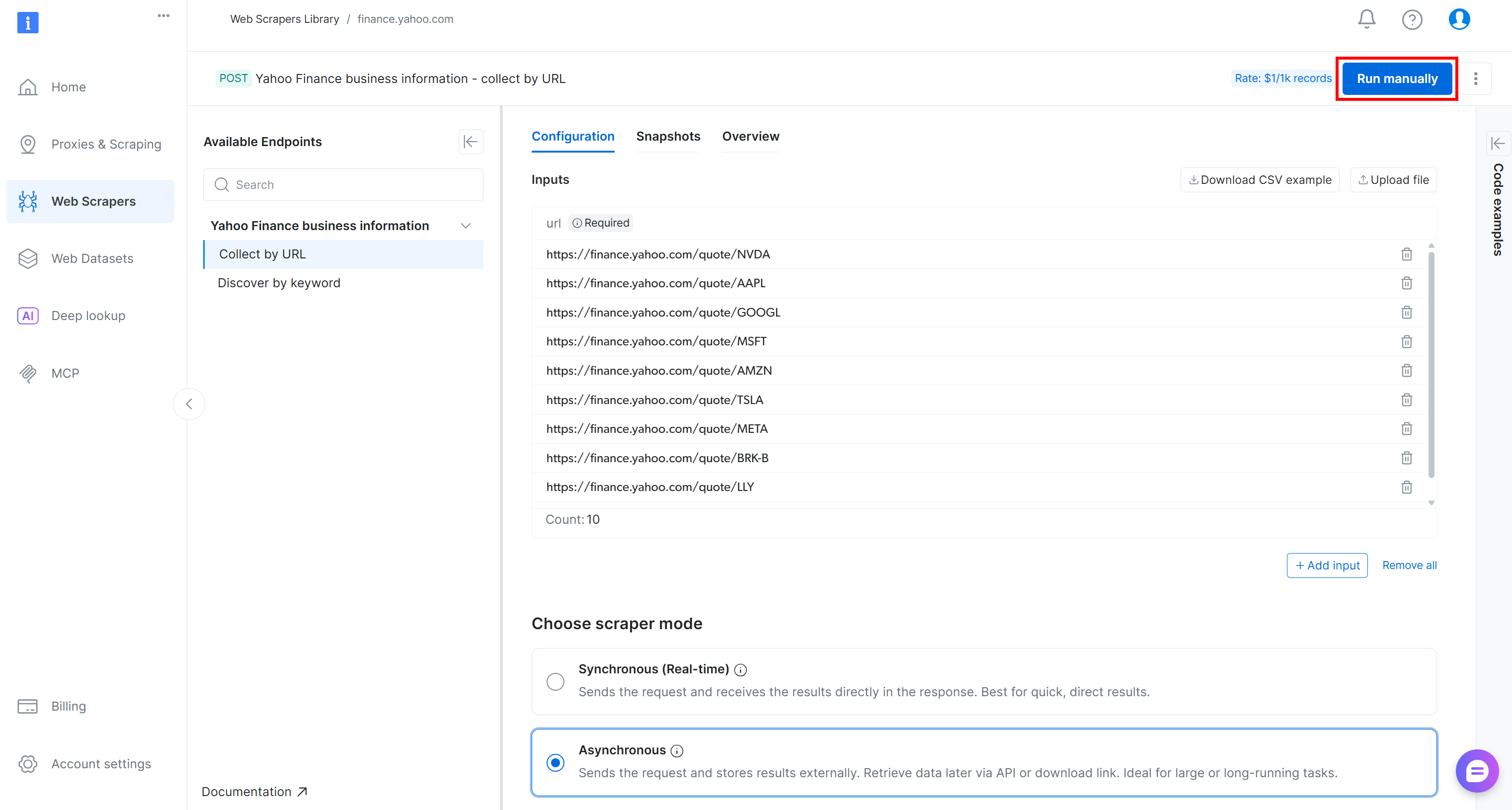
A solicitação da API de scraping será enviada e a tarefa de scraping será iniciada na nuvem. Você pode monitorar o status da tarefa em tempo real no painel de controle da Bright Data: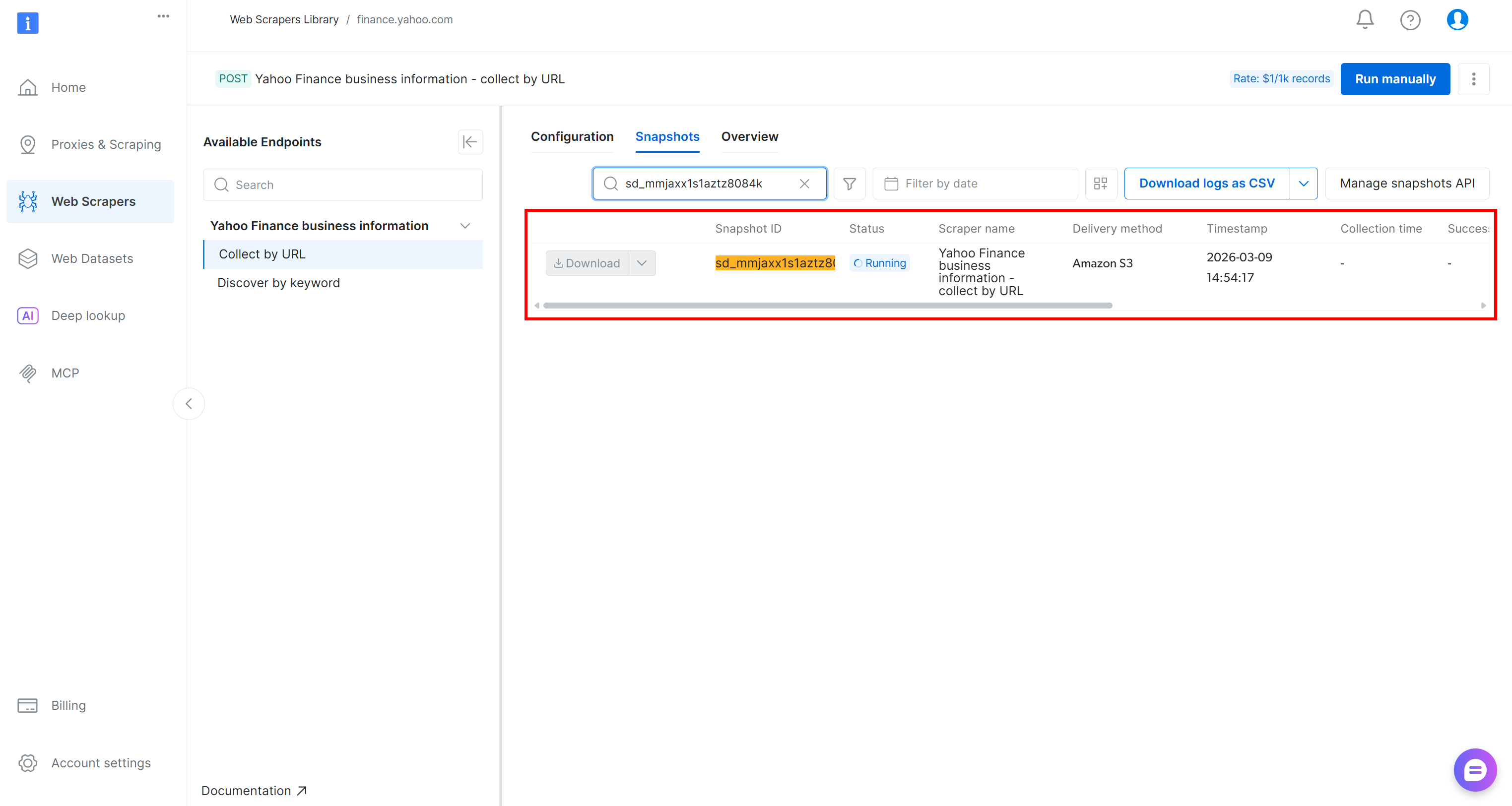
Como alternativa, você pode obter o mesmo resultado programaticamente executando um dos trechos de código disponíveis no console Bright Data (mostrado na coluna à direita), usando sua linguagem de programação preferida:
Quando o status da tarefa mudar para “Pronto”, verifique seu bucket AWS S3. Você deverá notar um novo arquivo chamado stocks.json:
Se você abrir o arquivo stocks.json no seu navegador, verá algo assim: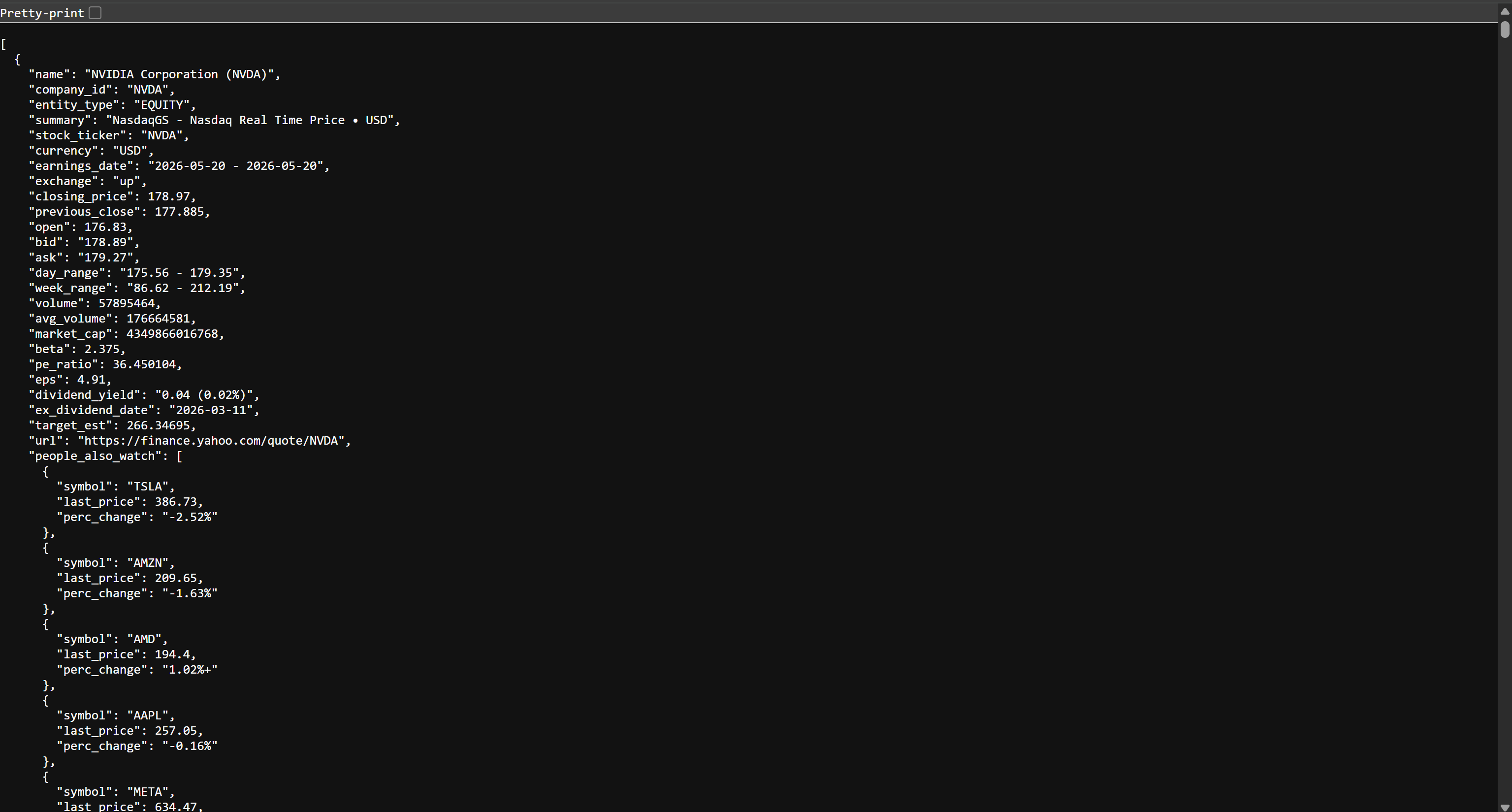
Esses são os mesmos dados de ações disponíveis no Yahoo Finance, mas estruturados no formato JSON. Esses dados foram coletados pela API de Scraping de dados da Bright Data. Missão cumprida! Agora você tem os dados necessários para construir seu pipeline ETL do AWS Glue.
Etapa 4: inicialize sua tarefa do AWS Glue
Faça login no AWS Console e pesquise a string “AWS Glue”. Selecione o serviço para abrir sua página principal.
A partir daí, clique no botão “Ir para tarefas ETL” para abrir o AWS Glue Studio, a interface oficial para criar fluxos de trabalho ETL:
Aqui, você pode inicializar um novo trabalho do AWS Glue. Para este tutorial, selecione a opção “Visual ETL”. Ela é recomendada para criar pipelines por meio de uma interface simplificada de arrastar e soltar.
Você será direcionado para uma tela em branco, onde poderá definir visualmente seu fluxo de trabalho ETL do AWS Glue conectando diferentes nós:
Dê ao seu trabalho ETL um nome descritivo, como “Trabalho ETL do Bright Data Glue”. Depois de fazer isso, você estará pronto para começar a construir seu pipeline ETL.
Etapa 5: crie uma função IAM
Para executar uma tarefa do AWS Glue, você deve fornecer uma função IAM para acessar recursos como o Amazon S3 e gerenciar o AWS Glue. Essas permissões são necessárias para componentes do Glue, como tarefas, rastreadores e pontos de extremidade de desenvolvimento.
Para criar a função diretamente do Glue Studio, acesse o painel “Detalhes da tarefa” e clique no botão “Criar nova função”: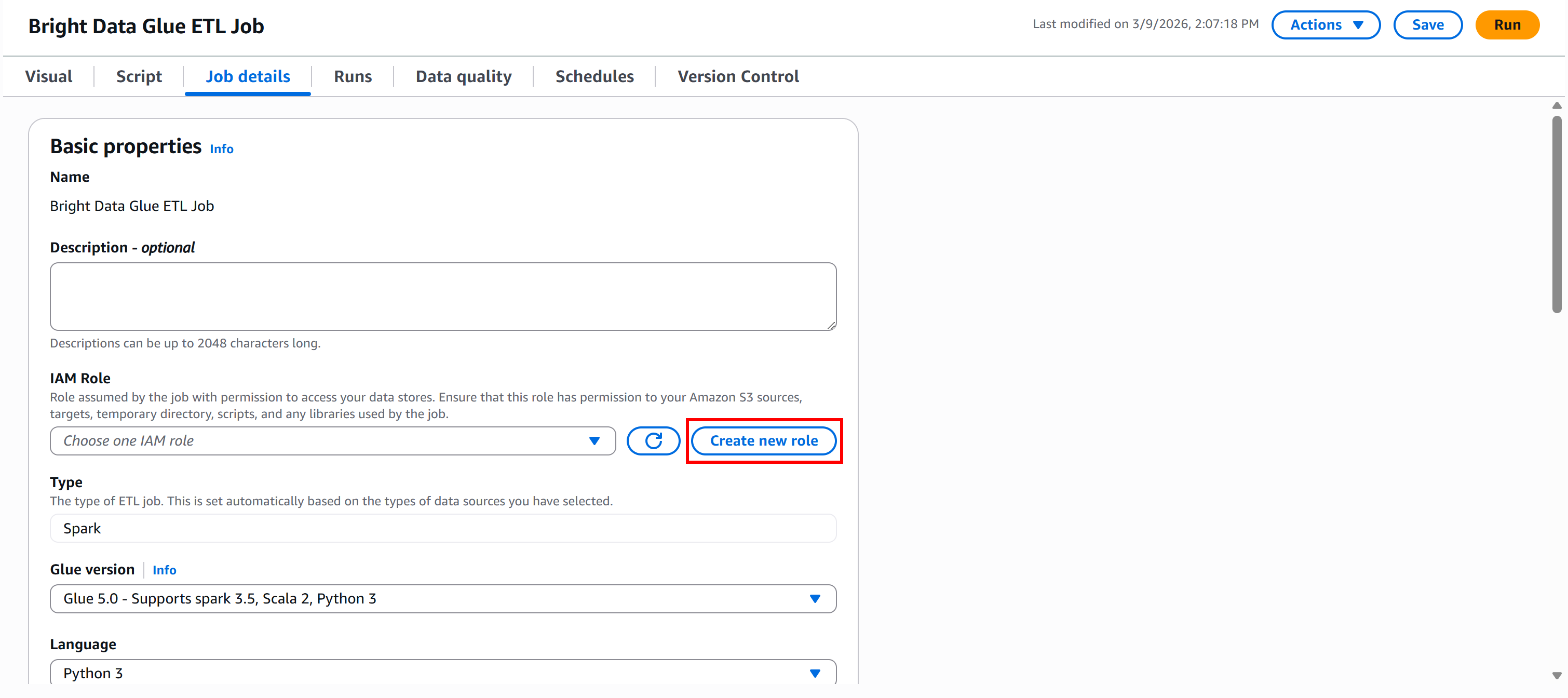
Na seção “Criar função”, dê à sua função IAM um nome descritivo, como “bd-glue-role”:
Por padrão, a AWS anexará as duas políticas necessárias:
AWSGlueConsoleFullAccess: fornece acesso total ao AWS Glue por meio do AWS Management Console.AWSGlueServiceRole: política para a função de serviço do AWS Glue, que permite o acesso a serviços relacionados, incluindo EC2, S3 e Cloudwatch Logs.

Em seguida, recupere o ARN do seu bucket S3. Você pode encontrá-lo na página “Propriedades” do seu bucket no console S3: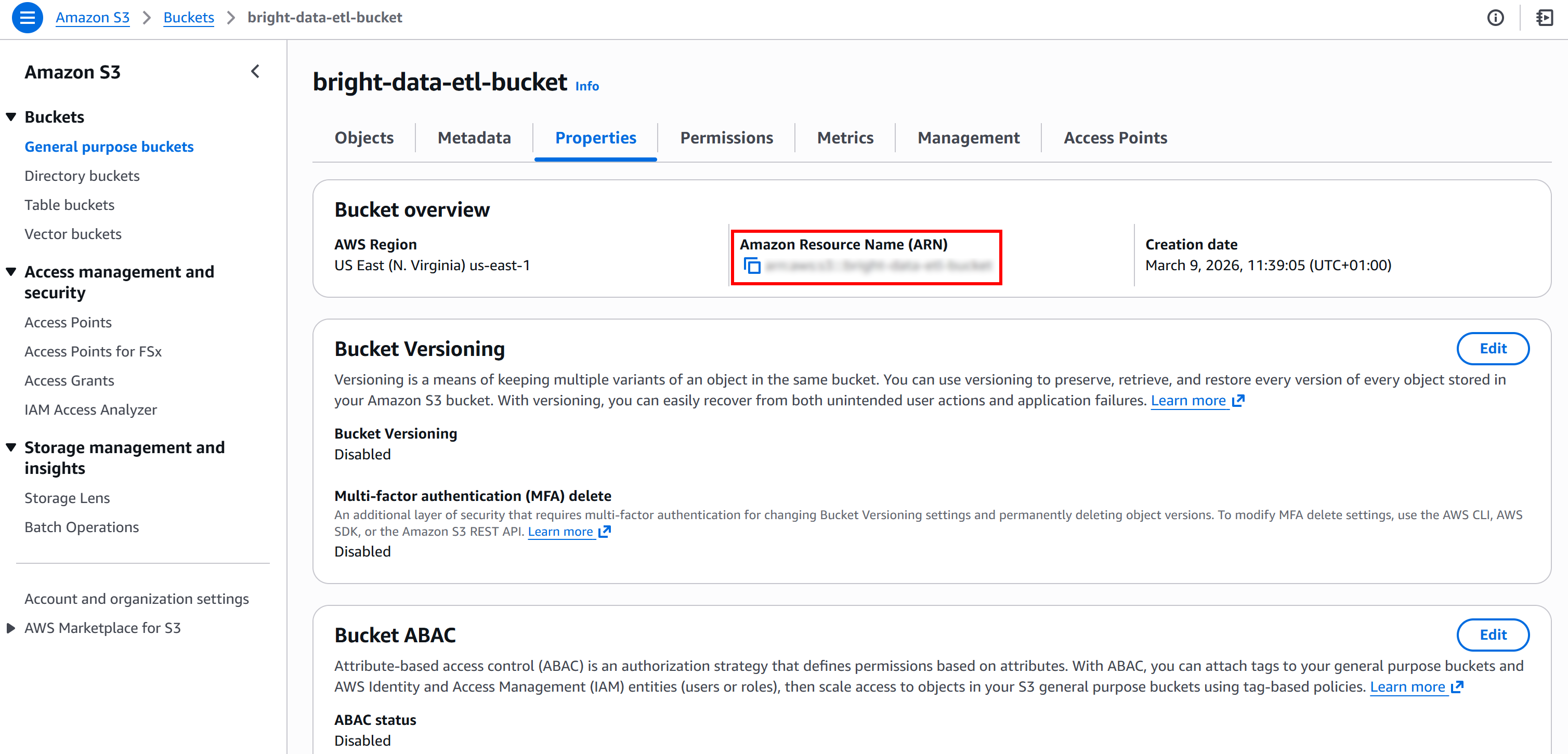
Essas informações são necessárias para substituir a política padrão fornecida pelo AWS Glue. Mais especificamente, cole o ARN do bucket S3 no campo “Recurso” no editor de texto “Política adicional” da página “Criar função”:
"Recurso": {
"<YOUR_S3_BUCKET_ARN>/*"
} 
Por fim, clique no botão “Criar função”. Depois que a função for criada, ela aparecerá automaticamente na configuração da sua tarefa do AWS Glue: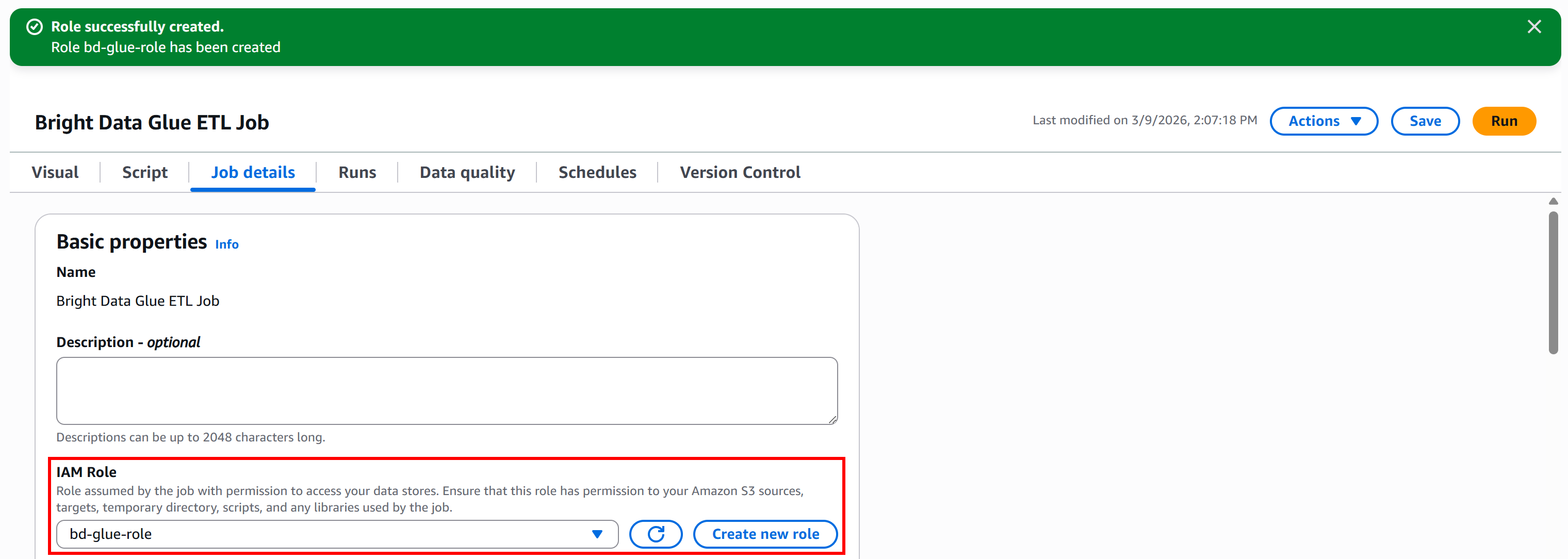
Ótimo! Seu trabalho do AWS Glue agora tem uma função IAM com as permissões necessárias para acessar o S3 e executar seu pipeline ETL.
Etapa 6: adicione o nó Extrair (E) ao seu pipeline
A fase Extrair (E) do pipeline começou quando você executou o Scraper da Bright Data que coletou dados de ações e os carregou no Amazon S3.
Agora, o objetivo é conectar seu pipeline ETL do AWS Glue a esses dados para que possam ser processados. Para fazer isso, vá para a guia “Fontes” no painel “Adicionar nós” e selecione o nó “Amazon S3”.
Um nó “Fonte de dados – bucket S3 – Amazon S3” aparecerá na tela. Clique nele e configure a fonte S3: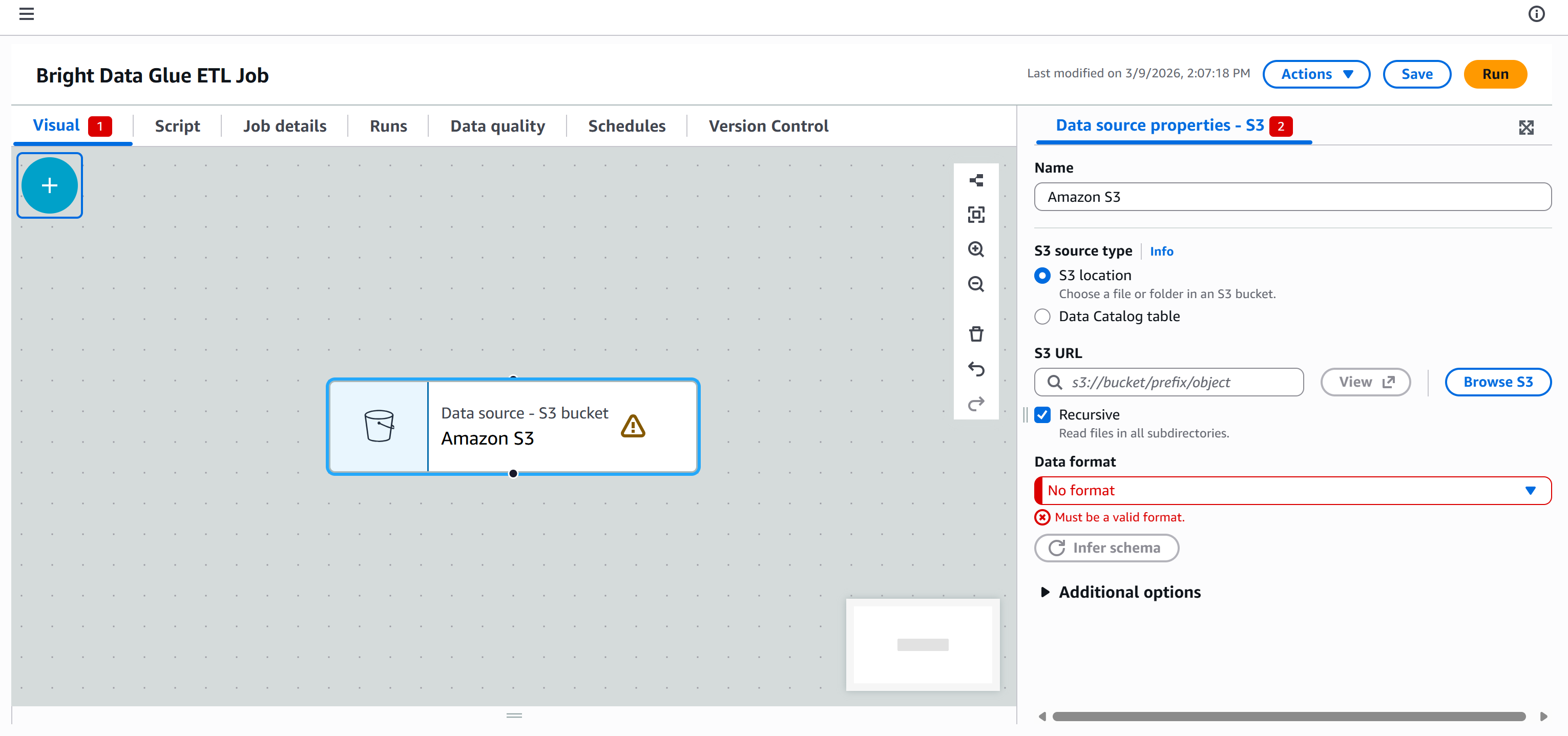
Pressione o botão “Browse S3” e selecione seu bucket S3 (por exemplo, bright-data-etl-bucket).
Após selecionar o bucket, o AWS Glue preencherá o campo “URL do S3” com algo como:
s3://bright-data-etl-bucketPor padrão, o AWS Glue tenta ler todos os arquivos dentro do caminho S3 especificado. Como sabemos o nome exato do arquivo de entrada, atualize o campo “URL do S3” para apontar diretamente para ele:
s3://bright-data-etl-bucket/stocks.jsonIsso instrui o AWS Glue a usar o arquivo stocks.json carregado anteriormente, que contém os dados coletados com o Yahoo Finance Scraper.
Em seguida, configure o formato dos dados. Como o conjunto de dados de entrada é um arquivo JSON, selecione “JSON” como formato de entrada.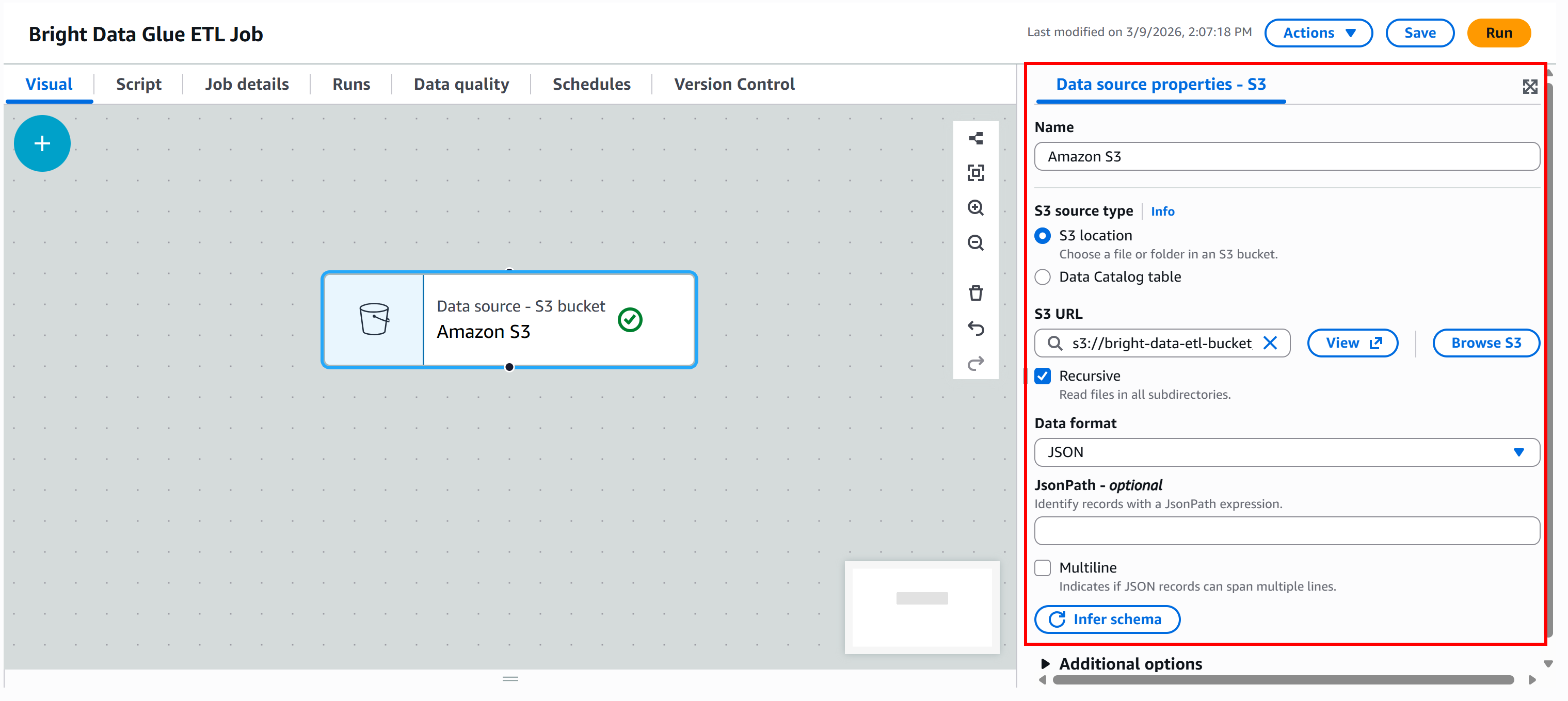
Em seguida, clique no botão “Inferir esquema”. O AWS Glue analisará automaticamente o arquivo JSON de entrada e gerará o esquema correspondente.
Na seção “Output schema” (Esquema de saída) do nó, você verá a estrutura inferida a partir dos dados JSON:
O esquema inferido corresponde ao esquema de dados de saída retornado pelo Bright Data Yahoo Finance Scraper. Legal!
Etapa 7: definir a lógica de transformação (T)
Como mencionado anteriormente, este é apenas um exemplo simples, portanto, a etapa de transformação (T) será mínima. O objetivo é filtrar os dados de origem usando uma consulta SQL e manter apenas as empresas cujo índice P/E seja inferior a 30.
Para isso, vá para a guia “Transformações” e selecione o nó “Consulta SQL”:
O nó será adicionado à tela. Clique nele e configure-o para que o nó pai seja “Amazon S3”. Isso significa que a saída do nó Amazon S3 se torna a entrada do nó “SQL Query”. Em outras palavras, você executará uma consulta SQL nos dados JSON coletados.
Em seguida, defina o nome do alias para o conjunto de dados de entrada como stocks e adicione esta consulta SQL:
select stock_ticker, pe_ratio from stocks
WHERE pe_ratio < 30;Essa consulta seleciona os campos stock_ticker e pe_ratio de cada ação coletada, mantendo apenas aquelas cujo índice P/E é inferior a 30.
Se você está se perguntando de onde vêm esses campos, stock_ticker e pe_ratio são dois dos atributos retornados pelo Bright Data Yahoo Finance Scraper (que o AWS Glue inferiu automaticamente na etapa anterior):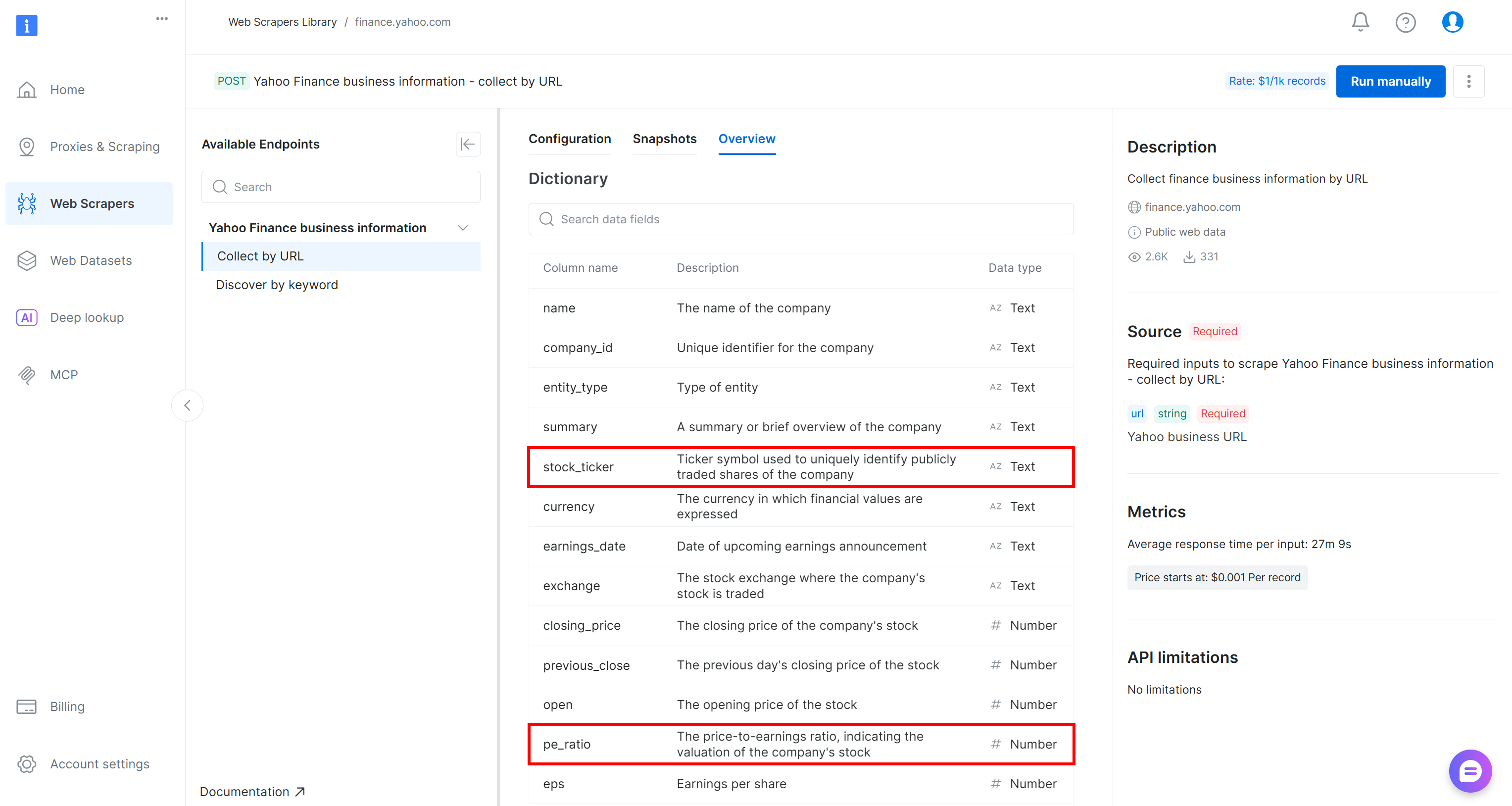
Neste ponto, seu pipeline ETL deve estar assim: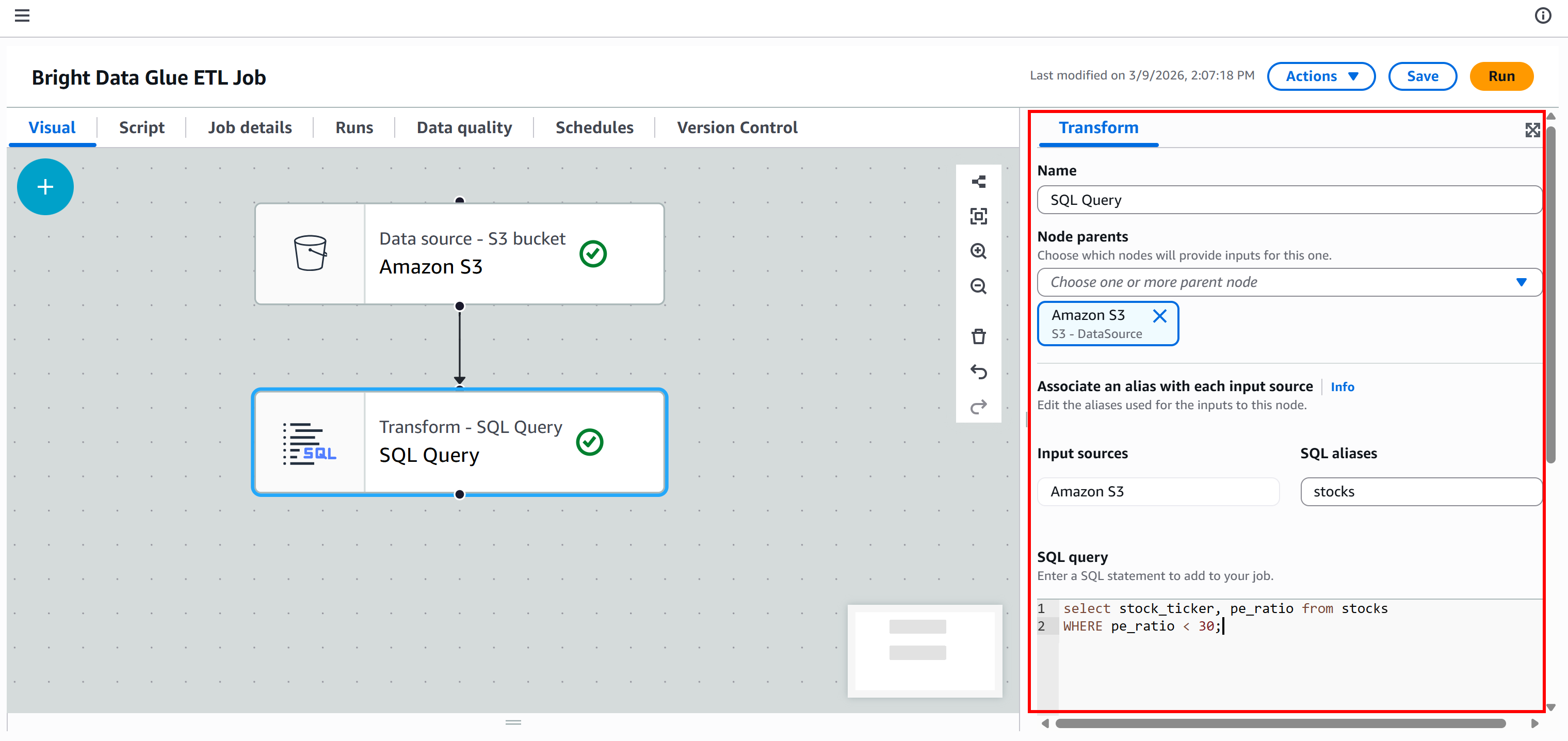
Observação: em pipelines reais, a fase Transform (T) geralmente inclui várias etapas. Você pode implementá-las adicionando vários nós de transformação e conectando-os sequencialmente ou criando várias ramificações no fluxo de trabalho.
Etapa 8: conecte-se ao seu bucket S3 na fase Load (L)
A saída do seu nó “SQL Query” são os dados filtrados e transformados. A etapa final é armazenar esses dados no seu bucket S3 para concluir a fase Load (L) do seu pipeline ETL.
Na guia “Destinos”, adicione outro nó Amazon S3:
Clique no novo nó para configurá-lo. Defina o nó pai como seu nó “SQL Query”. A saída do nó “SQL Query” será enviada como entrada para o novo nó Amazon S3.
Defina o formato de saída como “JSON” sem compactação. Em seguida, especifique a pasta S3 de saída de destino, como:
s3://bright-data-etl-bucket/output/Observação: certifique-se de substituir bright-data-etl-bucket pelo nome do seu bucket S3 real.
Dessa forma, os dados transformados serão armazenados na pasta /output.
Mantenha todas as outras opções como padrão e pressione “Salvar” para atualizar sua tarefa ETL do AWS Glue: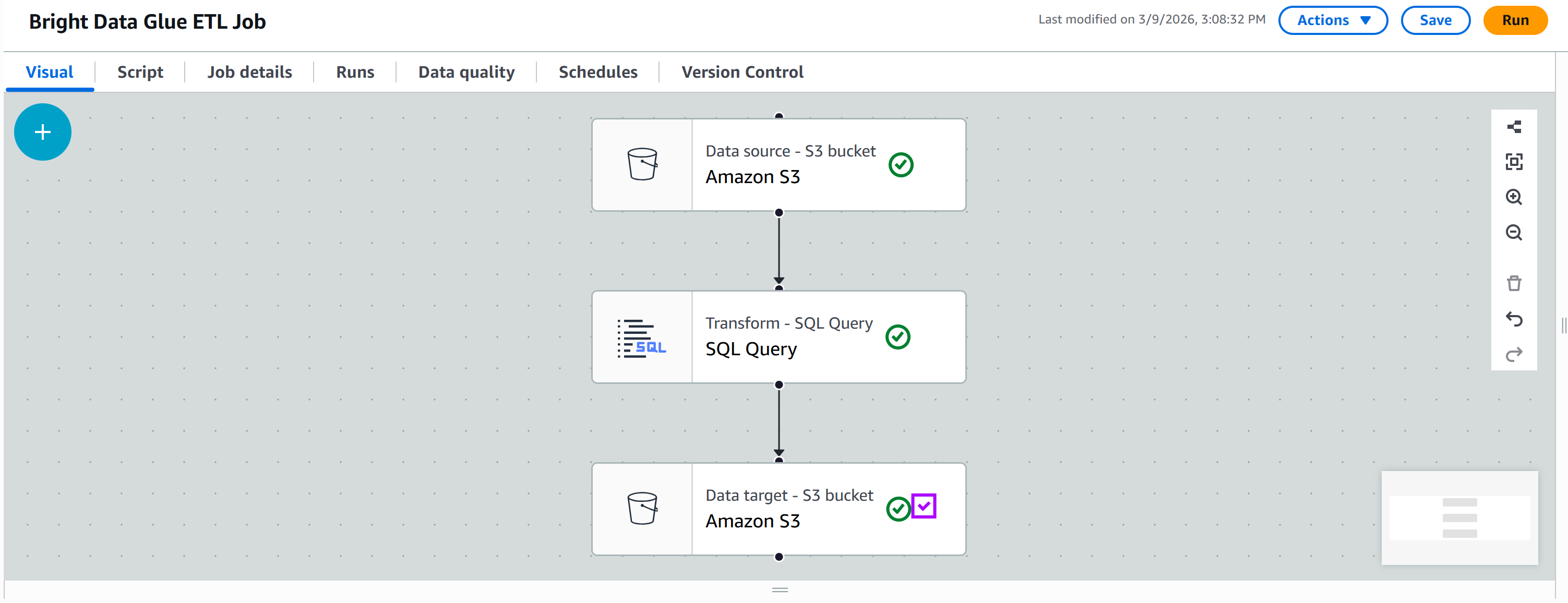
Ótimo! Seu pipeline ETL agora está totalmente configurado e pronto para ser executado.
Etapa 9: execute o pipeline e explore os resultados
Pressione o botão “Executar” para iniciar sua tarefa do AWS Glue. Você deverá ver uma notificação como esta:
Vá para a guia “Execuções” para monitorar a execução do seu pipeline: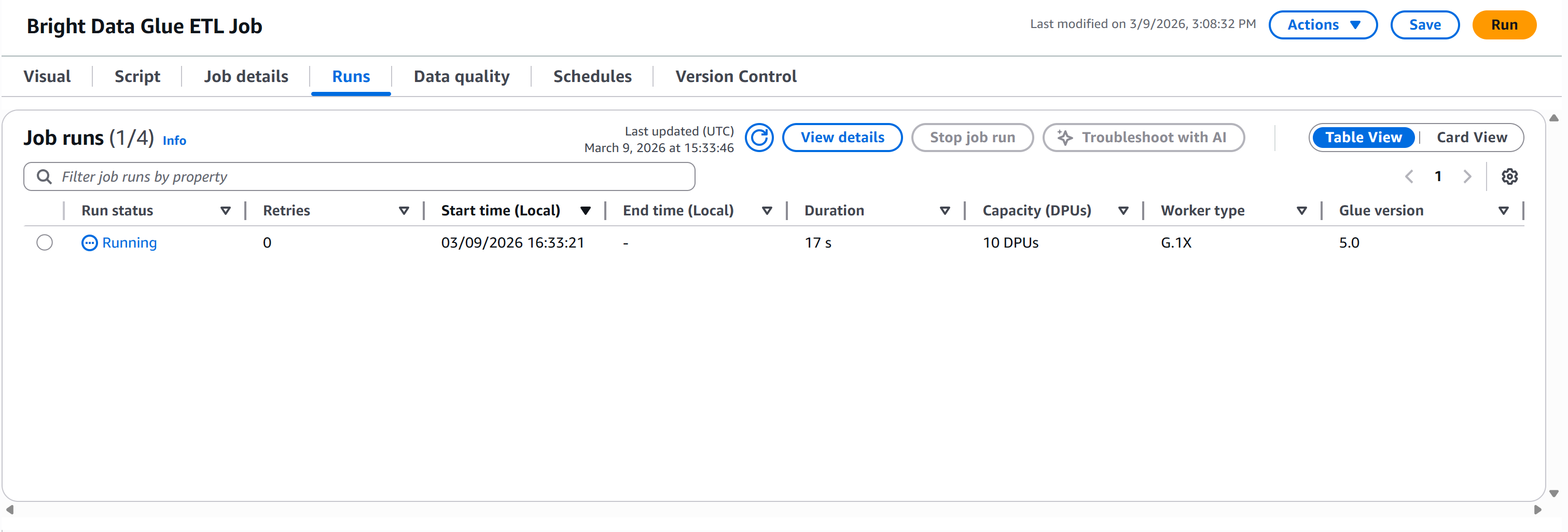
Aguarde até que o “Status da execução” alcance o status “Bem-sucedido”. Isso pode levar mais de um minuto, então seja paciente:
Quando concluído, o arquivo de saída aparecerá na pasta /output do seu bucket S3: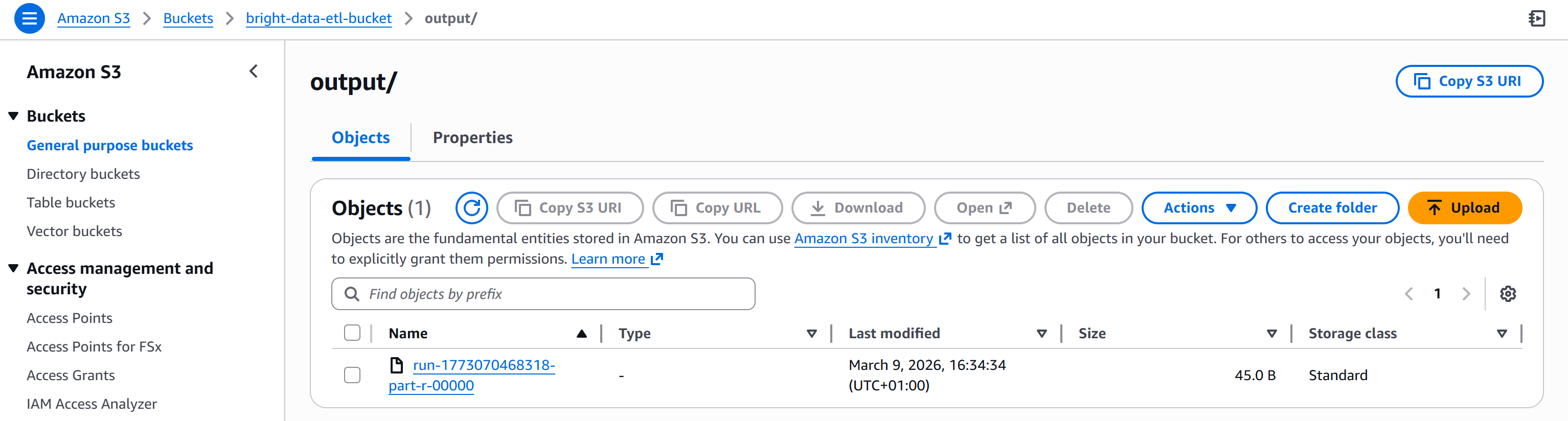
Abra o arquivo produzido. Você verá a lista de ações com um índice P/E abaixo do limite do seu filtro (por exemplo, menos de 30):
Como você pode ver, as ações resultantes incluem AMZN, BRK.B, META, MSFT e GOOGL.
Et voilà! Você acabou de criar um pipeline ETL do AWS Glue integrado ao Bright Data. A fase de extração utiliza as APIs de Scraping de dados do Bright Data, a fase de transformação filtra os dados com SQL e a fase de carregamento armazena os resultados de volta no S3.
Outras ideias de integração da Bright Data em um trabalho ETL do AWS Glue
Não há dúvida de que a Bright Data pode desempenhar um papel importante na fase de extração de um pipeline ETL, graças aos seus recursos de recuperação de dados da web.
No entanto, a Bright Data também pode ser aproveitada além da extração, incluindo na fase de transformação para enriquecimento, validação ou verificação de dados. Por exemplo, você poderia:
- Aprimorar perfis de empresas: use o ZoomInfo Scraper para anexar dados firmográficos aos registros extraídos de fontes da web.
- Validar informações de funcionários: integre os perfis do LinkedIn para verificar cargos, e-mails ou perfis sociais.
- Recuperar preços ou detalhes de produtos dos concorrentes: use o Amazon Scraper ou o Amazon Reviews Scraper para enriquecer seus conjuntos de dados com insights de mercado.
- Adicionar dados de SEO ou pesquisa: use a API SERP para incluir dados de classificação do mecanismo de pesquisa ou insights de palavras-chave como parte do seu conjunto de dados transformado, bem como para verificação de dados.
Se você está se perguntando como essa integração é possível, consulte o guia oficial sobre como definir transformações visuais personalizadas. Tudo o que você precisa fazer é incluir um arquivo JSON com as descrições e um arquivo Python contendo a lógica para a integração da API Bright Data.
Conclusão
Neste tutorial, você aprendeu o que é o AWS Glue e como a Bright Data pode aprimorar seus recursos por meio de uma ampla gama de soluções de Scraping de dados.
Em particular, você viu como as APIs de Scraping de dados da Bright Data podem dar suporte às fases de extração (E) e transformação (T) de um pipeline ETL (seja recuperando dados brutos, enriquecendo Conjuntos de dados ou verificando informações).
Crie uma conta gratuita na Bright Data hoje mesmo e comece a explorar nossas soluções de dados da web!




