

Neste guia, você aprenderá:
- O que é o SeleniumBase e por que ele é útil para Scraping de dados
- Como ele se compara ao Selenium básico
- Os recursos e benefícios que o SeleniumBase oferece
- Como usá-lo para criar um Scraper simples
- Como utilizá-lo para casos de uso mais complexos
Vamos começar!
O que é o SeleniumBase?
O SeleniumBase é uma estrutura Python para automação de navegadores. Construído sobre as APIs Selenium/WebDriver, ele fornece um kit de ferramentas de nível profissional para automação da web. Ele suporta uma ampla gama de tarefas, desde testes até scraping de dados.
O SeleniumBase é uma biblioteca completa para testar páginas da web, automatizar fluxos de trabalho e dimensionar operações baseadas na web. Ele vem equipado com recursos avançados, como bypass de CAPTCHA, prevenção de detecção de bots e ferramentas para aumentar a produtividade.
SeleniumBase vs Selenium: comparação de recursos e APIs
Para entender melhor o motivo por trás do SeleniumBase, faz sentido compará-lo diretamente com a versão básica do Selenium — a ferramenta na qual ele se baseia.
Para uma comparação rápida entre Selenium e SeleniumBase, consulte a tabela resumida abaixo:
| Recurso | SeleniumBase | Selenium |
|---|---|---|
| Executores de teste integrados | Integra-se com pytest, pynose e behave |
Requer configuração manual para integração de testes |
| Gerenciamento de drivers | Baixa automaticamente o driver do navegador compatível com a versão do navegador | Requer download e configuração manual do driver |
| Lógica de automação da Web | Combina várias etapas em uma única chamada de método | Requer várias linhas de código para funcionalidades semelhantes |
| Manipulação de seletores | Detecta automaticamente seletores CSS ou XPath | Requer a definição explícita dos tipos de seletores nas chamadas de método |
| Manipulação de tempo limite | Aplica tempos limite padrão para evitar falhas | Os métodos falham imediatamente se os tempos limite não forem definidos explicitamente |
| Saídas de erro | Fornece mensagens de erro claras e legíveis para facilitar a depuração | Gera logs de erros detalhados e menos interpretáveis |
| Painéis e relatórios | Inclui painéis, relatórios e capturas de tela de falhas integrados | Sem painéis integrados ou recursos de relatórios |
| Aplicativos GUI para desktop | Oferece ferramentas visuais para execução de testes | Não possui ferramentas GUI para desktop para execução de testes |
| Gravador de testes | Gravador de testes integrado para criar scripts a partir de ações manuais do navegador | Requer a escrita manual de scripts |
| Gerenciamento de casos de teste | Fornece CasePlans para organizar testes e documentar etapas diretamente na estrutura | Sem ferramentas integradas de gerenciamento de casos de teste |
| Suporte a aplicativos de dados | Inclui o ChartMaker para gerar JavaScript a partir do Python para criar aplicativos de dados | Sem ferramentas adicionais para a criação de aplicativos de dados |
É hora de explorar as diferenças!
Executores de teste integrados
O SeleniumBase se integra a executores de teste populares, como pytest, pynose e behave. Essas ferramentas fornecem uma estrutura organizada, descoberta de testes contínua, execução, rastreamento do status dos testes (por exemplo, aprovado, reprovado ou ignorado) e opções de linha de comando para personalizar configurações, como a seleção do navegador.
Com o Selenium básico, você precisaria implementar manualmente um analisador de opções ou contar com ferramentas de terceiros para configurar testes a partir da linha de comando.
Gerenciamento aprimorado de drivers
Por padrão, o SeleniumBase baixa uma versão de driver compatível que corresponde à versão principal do seu navegador. Você pode substituir isso usando a opção --driver-version=VER no seu comando pytest. Por exemplo:
pytest my_script.py --driver-version=114
Em vez disso, o Selenium exige que você baixe e configure manualmente o driver apropriado. Nesse caso, você é responsável por garantir a compatibilidade com a versão do navegador.
Métodos de múltiplas ações
O SeleniumBase combina várias etapas em métodos únicos para simplificar a automação da web. Por exemplo, o método driver.type(selector, text) executa o seguinte:
- Aguarda até que o elemento fique visível
- Aguarda até que o elemento esteja interativo
- Limpa qualquer texto existente
- Digita o texto fornecido
- Envia se o texto terminar com
“n”
Com o Selenium bruto, replicar a mesma lógica exigiria algumas linhas de código.
Manipulação simplificada do seletor
O SeleniumBase pode diferenciar automaticamente entre seletores CSS e expressões XPath. Isso elimina a necessidade de especificar explicitamente os tipos de seletor com By.CSS_SELECTOR ou By.XPATH. No entanto, você ainda pode fornecer o tipo explicitamente, se preferir.
Exemplo com SeleniumBase:
driver.click("button.submit") # Detecta automaticamente como seletor CSS
driver.click("//button[@class='submit']") # Detecta automaticamente como XPath
O código equivalente do Selenium básico é:
driver.find_element(By.CSS_SELECTOR, "button.submit").click()
driver.find_element(By.XPATH, "//button[@class='submit']").click()
Valores padrão e personalizados de tempo limite
O SeleniumBase aplica automaticamente um tempo limite padrão de 10 segundos aos métodos, garantindo que os elementos tenham tempo para carregar. Isso evita falhas imediatas, que são comuns no Selenium bruto.
Você também pode definir valores de tempo limite personalizados diretamente nas chamadas de método, como no exemplo abaixo:
driver.click("button", timeout=20)
O código Selenium equivalente seria muito mais detalhado e complexo:
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button"))).click()
Saídas de erro claras
O SeleniumBase fornece mensagens de erro claras e fáceis de ler quando os scripts falham. O Selenium bruto, por outro lado, geralmente gera logs de erros verbosos e menos interpretáveis, exigindo esforço adicional para depurar.
Painéis, relatórios e capturas de tela
O SeleniumBase inclui recursos para gerar painéis e relatórios para execuções de teste. Ele também salva capturas de tela de falhas na pasta ./latest_logs/ para facilitar a depuração. O Selenium bruto não possui esses recursos prontos para uso.
Recursos extras
Em comparação com o Selenium, o SeleniumBase inclui:
- Aplicativos GUI para desktop para executar testes visualmente, como o SeleniumBase Commander para
pyteste o SeleniumBase Behave GUI parabehave. - Um gravador/gerador de testes integrado para criar scripts de teste com base em ações manuais do navegador. Isso reduz significativamente o esforço necessário para escrever testes para fluxos de trabalho complexos.
- Software de gerenciamento de casos de teste chamado CasePlans para organizar testes e documentar descrições de etapas diretamente dentro da estrutura.
- Ferramentas como o ChartMaker para criar aplicativos de dados gerando código JavaScript a partir do Python. Isso o torna uma solução versátil além da automação de testes padrão.
SeleniumBase: Recursos, métodos e opções de CLI
Veja o que torna o SeleniumBase especial, explorando seus recursos e API.
Recursos
Esta é uma lista de alguns dos recursos mais relevantes do SleniumBase:
- Inclui o Modo Gravador para gerar instantaneamente testes de navegador em Python.
- Suporta vários navegadores, guias, iframes e Proxies dentro do mesmo teste.
- Possui software de gerenciamento de casos de teste com tecnologia Markdown.
- O mecanismo de espera inteligente melhora automaticamente a confiabilidade e reduz os testes instáveis.
- Compatível com
pytest,unittest,noseebehavepara descoberta e execução de testes. - Inclui ferramentas avançadas de registro para painéis, relatórios e capturas de tela.
- Pode executar testes no modo Headless para ocultar a interface do navegador.
- Suporta execução de testes multithread em navegadores paralelos.
- Permite que os testes sejam executados usando o emulador de dispositivo móvel do Chromium.
- Suporta a execução de testes através de um Proxy, mesmo que seja autenticado.
- Personaliza a string do agente do usuário do navegador para testes.
- Impede a detecção por sites que bloqueiam a automação do Selenium.
- Integra-se ao selenium-wire para inspecionar solicitações de rede do navegador.
- Interface de linha de comando flexível para opções personalizadas de execução de testes.
- Arquivo de configuração global para gerenciar as configurações de teste.
- Suporta integrações com GitHub Actions, Google Cloud, Azure, S3 e Docker.
- Suporta a execução de JavaScript a partir do Python.
- Pode interagir com elementos Shadow DOM usando
::shadowem seletores CSS.
Paraver a lista completa,consulte a documentação. Não deixe de ler nosso blog sobre como usar o SeleniumBase com Proxies.
Métodos
Abaixo está uma lista dos métodos mais úteis do SeleniumBase:
driver.open(url): Navegue pela janela do navegador até o URL especificado.driver.go_back(): Navegue de volta para a URL anterior.driver.type(selector, text): Atualiza o campo identificado pelo seletor com o texto especificado.driver.click(seletor): clica no elemento identificado pelo seletor.driver.click_link(link_text): clica no link que contém o texto especificado.driver.select_option_by_text(dropdown_selector, option): Seleciona uma opção de um menu suspenso pelo texto visível.driver.hover_and_click(seletor de foco, seletor de clique): Passe o mouse sobre um elemento e clique em outro.driver.drag_and_drop(seletor_arrastar, seletor_soltar): Arraste um elemento e solte-o em outro elemento.driver.get_text(selector): Obtenha o texto do elemento especificado.driver.get_attribute(seletor, atributo): Obter o atributo especificado de um elemento.driver.get_current_url(): Obter a URL da página atual.driver.get_page_source(): Obter a fonte HTML da página atual.driver.get_title(): Obter o título da página atual.driver.switch_to_frame(frame): Muda para o contêiner iframe especificado.driver.switch_to_default_content(): Sai do contêiner iframe e retorna ao documento principal.driver.open_new_window(): Abre uma nova janela do navegador na mesma sessão.driver.switch_to_window(window): Alterna para a janela do navegador especificada.driver.switch_to_default_window(): Retorna à janela original do navegador.driver.get_new_driver(OPTIONS): Abre uma nova sessão do driver com as opções especificadas.driver.switch_to_driver(driver): Alterna para o driver do navegador especificado.driver.switch_to_default_driver(): Retorna ao driver original do navegador.driver.wait_for_element(seletor): Aguarda até que o elemento especificado fique visível.driver.is_element_visible(seletor): Verifica se o elemento especificado está visível.driver.is_text_visible(texto, seletor): Verifica se o texto especificado está visível dentro de um elemento.driver.sleep(segundos): Pausa a execução pelo tempo especificado.driver.save_screenshot(name): Salva uma captura de tela no formato.pngcom o nome fornecido.driver.assert_element(seletor): Verifica se o elemento especificado está visível.driver.assert_text(texto, seletor): Verifica se o texto especificado está presente no elemento.driver.assert_exact_text(texto, seletor): Verifica se o texto especificado corresponde exatamente ao elemento.driver.assert_title(title): Verifica se o título da página atual corresponde ao título especificado.driver.assert_downloaded_file(arquivo): Verifica se o arquivo especificado foi baixado.driver.assert_no_404_errors(): Verifica se não há links quebrados na página.driver.assert_no_js_errors(): Verifica se não há erros de JavaScript na página.
Para obter a lista completa, explore a documentação.
Opções da CLI
O SeleniumBase estende o pytest com as seguintes opções de linha de comando:
--browser=BROWSER: Define o navegador da web (padrão: “chrome”).--chrome: Atalho para--browser=chrome.--edge: atalho para--browser=edge.--firefox: Atalho para--browser=firefox.--safari: atalho para--browser=safari.--settings-file=FILE: Substitui as configurações padrão do SeleniumBase.--env=ENV: Define o ambiente de teste, acessível viadriver.env.--account=STR: Define a conta, acessível viadriver.account.--data=STRING: Dados de teste extras, acessíveis viadriver.data.--var1=STRING: Dados de teste extras, acessíveis viadriver.var1.--var2=STRING: Dados de teste extras, acessíveis viadriver.var2.--var3=STRING: Dados de teste extras, acessíveis através dedriver.var3.--variáveis=DICT: Dados de teste extras, acessíveis viadriver.variáveis.--proxy=SERVIDOR:PORTA: Conecta-se a um servidor Proxy.--proxy=USERNAME:PASSWORD@SERVER:PORT: Usar um Proxy autenticado.--proxy-bypass-list=STRING: Hosts a serem ignorados (por exemplo, “*.foo.com”).--proxy-pac-url=URL: Conecta-se via URL PAC.--proxy-pac-url=USERNAME:PASSWORD@URL: Proxy autenticado com URL PAC.--proxy-driver: Use Proxy para download do driver.--multi-proxy: Permita vários proxies autenticados em multithreading.--agent=STRING: Modifique a string do agente do usuário do navegador.--mobile: habilitar emulador de dispositivo móvel.--metrics=STRING: Define métricas móveis (por exemplo, “CSSWidth,CSSHeight,PixelRatio”).--chromium-arg="ARG=N,ARG2": Define argumentos do Chromium.--firefox-arg="ARG=N,ARG2": Define argumentos do Firefox.--firefox-pref=SET: Define as preferências do Firefox.--extension-zip=ZIP: Carregar arquivos.zip/.crxda extensão do Chrome.--extension-dir=DIR: Carregar diretórios de extensões do Chrome.--disable-features="F1,F2": Desativar recursos.--binary-location=PATH: Define o caminho binário do Chromium.--driver-version=VER: Define a versão do driver.--headless: Modo headless padrão.--headless1: Utilizar o modo headless antigo do Chrome.--headless2: usa o novo modo headless do Chrome.--headed: Ativar o modo GUI no Linux.--xvfb: Executa testes com o Xvfb no Linux.--locale=LOCALE_CODE: Define a localidade do idioma do navegador.--reuse-session: Reutiliza a sessão do navegador para todos os testes.--reuse-class-session: Reutilize a sessão para testes de classe.--crumbs: excluir cookies entre sessões reutilizadas.--disable-cookies: Desative os cookies.--disable-js: Desativa o JavaScript.--disable-csp: Desativar a Política de Segurança de Conteúdo.--disable-ws: Desativar a segurança da Web.--enable-ws: Ativar a Segurança da Web.--log-cdp: Registra eventos do Chrome DevTools Protocol (CDP).--remote-debug: Sincronizar com o Chrome Remote Debugger.--visual-baseline: Define a linha de base visual para testes de layout.--timeout-multiplier=MULTIPLIER: Multiplicar os valores padrão de tempo limite.
Veja a lista completa de definições de opções de linha de comando na documentação.
Usando o SeleniumBase para Scraping de dados: guia passo a passo
Siga este tutorial passo a passo para aprender a criar um Scraper SeleniumBase para recuperar dados da sandbox Quotes to Scrape:
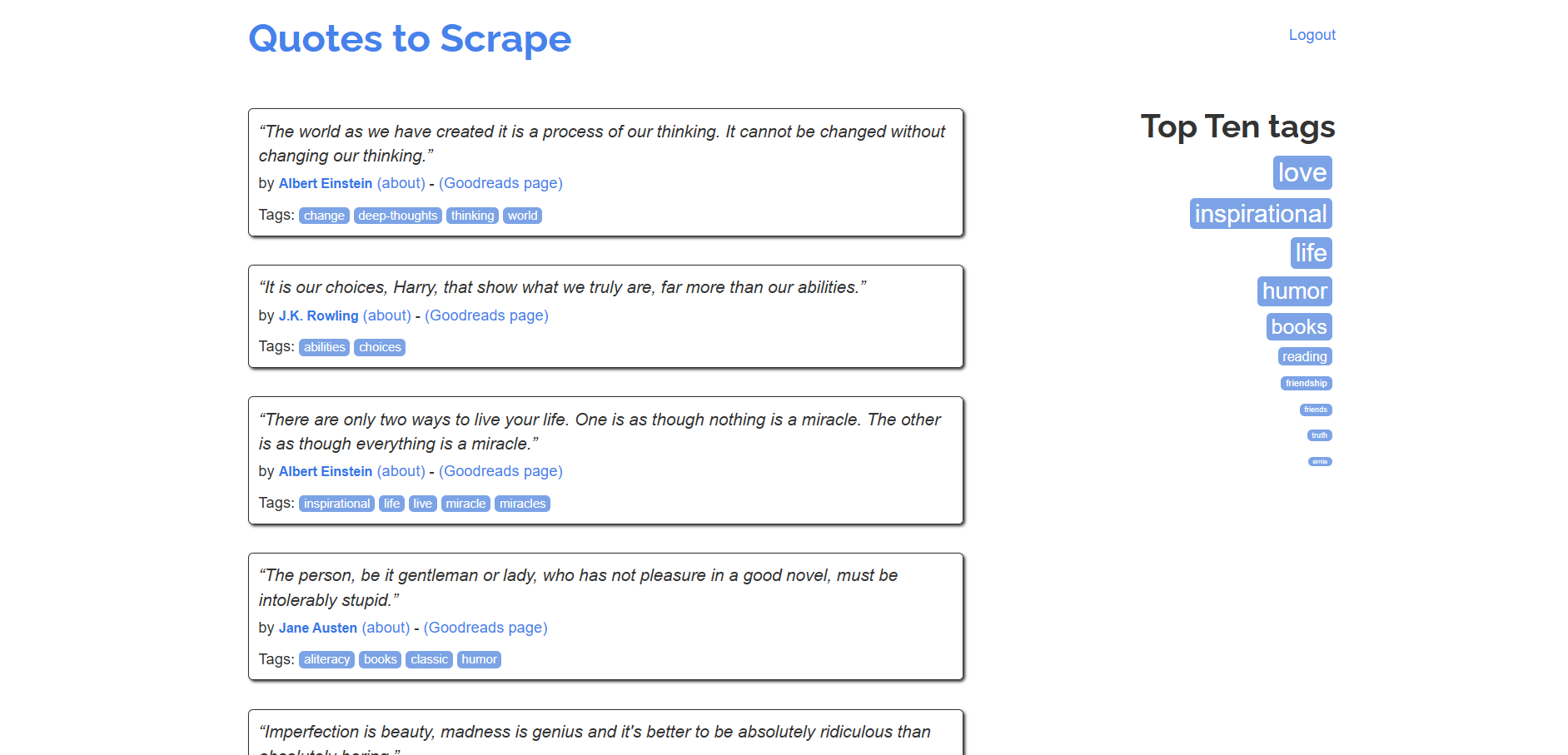
Para um tutorial semelhante usando o Selenium básico, consulte nosso guia sobre Scraping de dados com Selenium.
Etapa 1: Inicialização do projeto
Antes de começar, certifique-se de que o Python 3 esteja instalado em sua máquina. Caso contrário, baixe-o e instale-o.
Abra o terminal e execute o comando abaixo para criar um diretório para o seu projeto:
mkdir seleniumbase-Scraper
seleniumbase-scraper conterá seu Scraper SeleniumBase.
Navegue dentro dele e inicialize um ambiente virtual dentro dele:
cd seleniumbase-Scraper
python -m venv env
Em seguida, carregue a pasta do projeto em seu IDE Python favorito. O Visual Studio Code com a extensão Python ou o PyCharm Community Edition são opções adequadas.
Crie um arquivo scraper.py no diretório do projeto, que agora deve conter esta estrutura de arquivos:

O Scraper.py logo conterá sua lógica de raspagem.
Ative o ambiente virtual no terminal do IDE. No Linux ou macOS, faça isso com o comando abaixo:
./env/bin/activate
De forma equivalente, no Windows, execute:
env/Scripts/activate
No ambiente ativado, execute este comando para instalar o SeleniumBase:
pip install seleniumbase
Ótimo! Você tem um ambiente Python para o Scraping de dados da web com o SeleniumBase.
Etapa 2: Configuração do teste do SeleniumBase
Embora o SeleniumBase suporte a sintaxe pytest para a criação de testes, um bot de Scraping de dados não é um script de teste. Você ainda pode aproveitar todas as opções de extensão de linha de comando pytest do SeleniumBase usando a sintaxeSB:
from seleniumbase import SB
with SB() as sb:
pass
# Lógica de scraping...
Agora você pode executar seu teste com:
python3 Scraper.py
Observação: no Windows, substitua python3 por python.
Para executá-lo no modo headless, execute:
python3 Scraper.py --headless
Lembre-se de que você pode combinar várias opções de linha de comando.
Etapa 3: Conecte-se à página de destino
Use o método open() para instruir o navegador controlado a visitar sua página de destino:
sb.open("https://quotes.toscrape.com/")
Se você executar o script de teste de scraping no modo headed, isso é o que você verá por uma fração de segundo:
Observe que, em comparação com o Selenium básico, você não precisa fechar manualmente o driver. O SeleniumBase cuidará disso para você.
Passo 4: Selecione os elementos de cotação
Abra a página de destino no modo de navegação anônima do seu navegador e inspecione um elemento de citação:
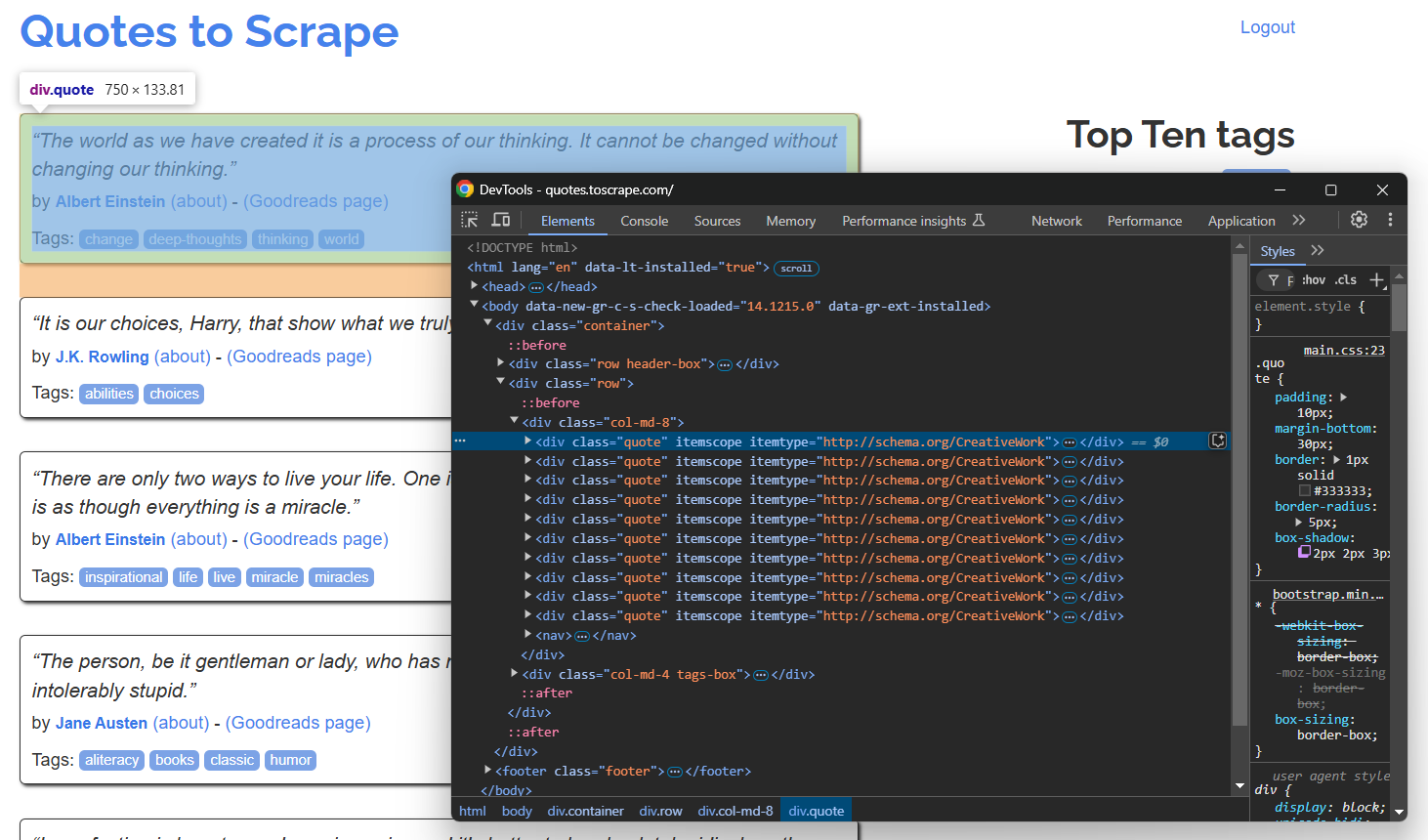
Como a página contém várias citações, crie uma matriz de citações para armazenar os dados extraídos:
citações = []
Na seção DevTools acima, você pode ver que todas as citações podem ser selecionadas usando o seletor CSS .quote. Use find_elements() para selecionar todas elas:
quote_elements = sb.find_elements(".quote")
Em seguida, prepare-se para iterar sobre os elementos e coletar dados de cada elemento de citação. Adicione os dados coletados a uma matriz:
para quote_element em quote_elements:
# Lógica de extração...
Ótimo! A lógica de extração de alto nível agora está pronta.
Etapa 5: extrair dados das citações
Inspecione um único elemento de citação:
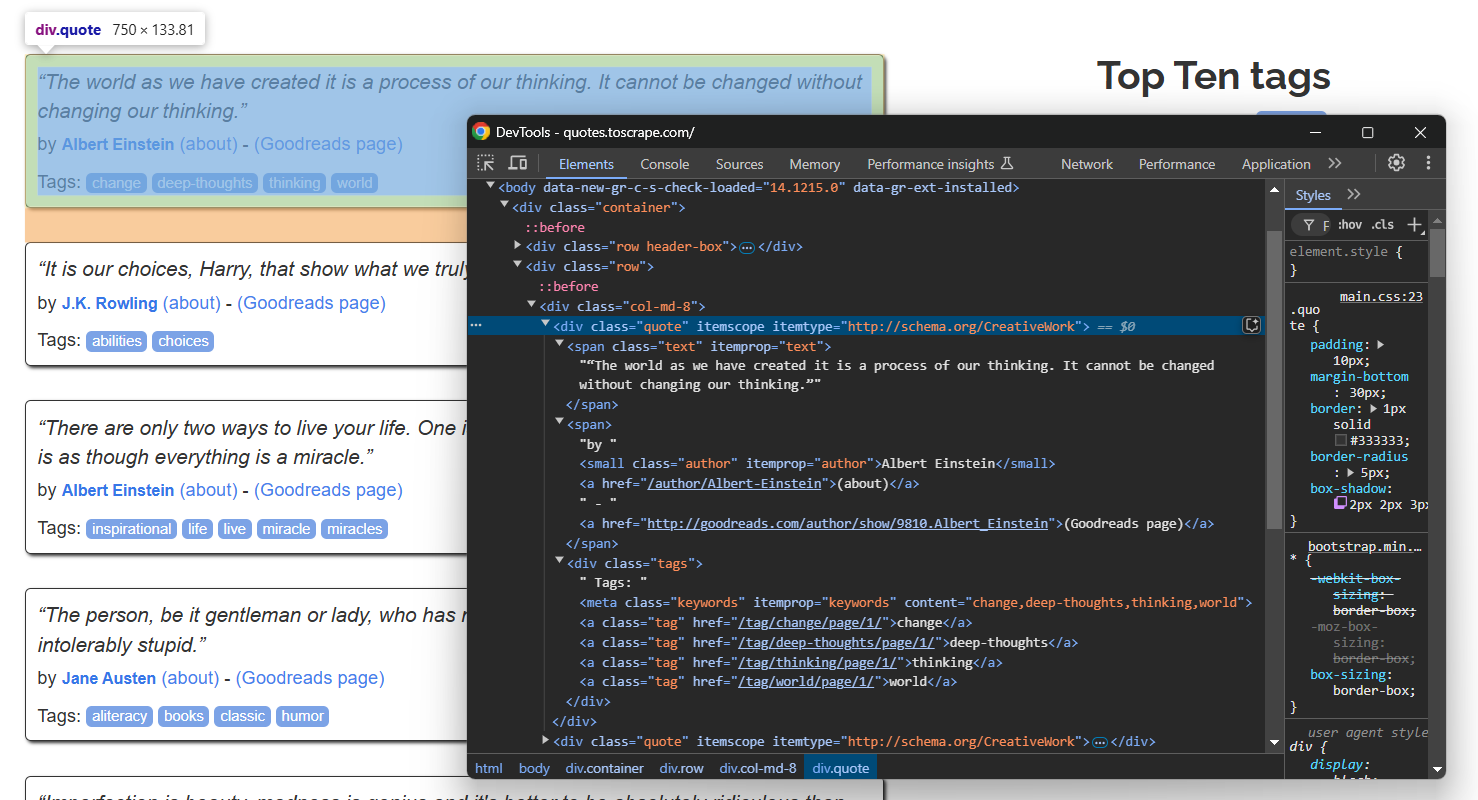
Observe que você pode extrair:
- O texto da citação de
.text - O autor da citação de
.author - As tags da citação de
.tag
Selecione cada nó e extraia os dados deles com o atributo de texto:
text_element = quote_element.find_element(By.CSS_SELECTOR, ".text")
text = text_element.text.replace("“", "").replace("”", "")
elemento_autor = quote_element.find_element(By.CSS_SELECTOR, ".author")
autor = elemento_autor.text
tags = []
elementos_tag = quote_element.find_elements(By.CSS_SELECTOR, ".tag")
para elemento_tag em elementos_tag:
tag = elemento_tag.text
tags.append(tag)
Observe que find_elements() retorna objetos Selenium WebElement básicos. Portanto, para selecionar elementos dentro deles, você deve usar os métodos nativos do Selenium. É por isso que você deve especificar By.CSS_SELECTOR como localizador.
Certifique-se de importar By no início do seu script:
from selenium.webdriver.common.by import By
Observe como a extração das tags requer um loop, pois uma única citação pode ter uma ou mais tags. Além disso, observe o uso do método replace() para remover as aspas duplas especiais que envolvem o texto.
Etapa 6: Preencha a matriz de citações
Preencha um novo objeto quotes com os dados extraídos e adicione-o a quotes:
quote = {
"text": text,
"author": author,
"tags": tags
}
quotes.append(quote)
Incrível! A lógica de extração do SelenumBase está completa.
Etapa 7: Implemente a lógica de rastreamento
Lembre-se de que o site de destino contém várias páginas. Para navegar para a próxima página, clique no botão “Próximo →” na parte inferior:
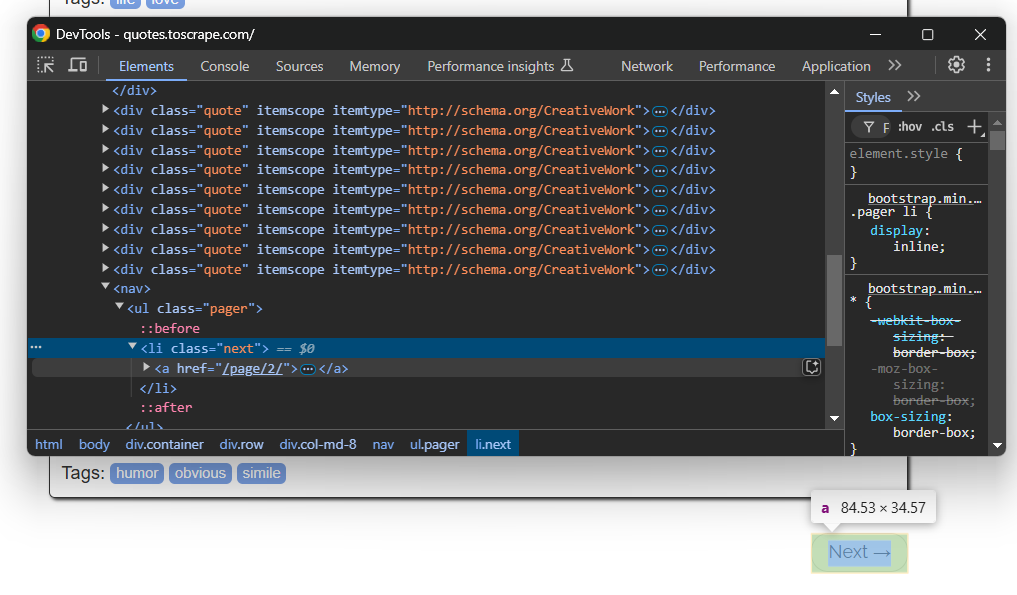
Na última página, esse botão não estará presente.
Para implementar o rastreamento da web e extrair todas as páginas, envolva sua lógica de extração em um loop que clica no botão “Próximo →” e para quando o botão não estiver mais disponível:
while sb.is_element_present(".next"):
# Lógica de scraping...
# Visite a próxima página
sb.click(".next a")
Observe o uso do método especial SleniumBae is_element_present() para verificar se o botão está presente ou não.
Perfeito! Seu scraper SeleniumBase agora percorrerá todo o site.
Etapa 8: Exportar os dados coletados
Exporte os dados coletados em quotes para um arquivo CSV da seguinte maneira:
com open("quotes.csv", mode="w", newline="", encoding="utf-8") como arquivo:
writer = csv.DictWriter(arquivo, fieldnames=["texto", "autor", "tags"])
writer.writeheader()
# Achate os objetos de citação para gravação em CSV
for quote in quotes:
writer.writerow({
"text": quote["text"],
"author": quote["author"],
"tags": ";".join(quote["tags"])
})
Não se esqueça de importar csv da biblioteca padrão do Python:
import csv
Etapa 9: Junte tudo
Seu arquivo script.py agora deve conter o seguinte código:
from seleniumbase import SB
from selenium.webdriver.common.by import By
import csv
with SB() as sb:
# Conecte-se à página de destino
sb.open("https://quotes.toscrape.com/")
# Onde armazenar os dados coletados
quotes = []
# Iterar sobre todas as páginas de citações
enquanto sb.is_element_present(".next"):
# Selecionar todos os elementos de citação na página
quote_elements = sb.find_elements(".quote")
# Iterar sobre eles e coletar dados para cada elemento de citação
para quote_element em quote_elements:
# Lógica de extração de dados
elemento_texto = elemento_citação.find_element(By.CSS_SELECTOR, ".text")
texto = elemento_texto.text.replace("“", "").replace("”", "")
elemento_autor = elemento_citação.find_element(By.CSS_SELECTOR, ".author")
autor = elemento_autor.text
tags = []
tag_elements = quote_element.find_elements(By.CSS_SELECTOR, ".tag")
para tag_element em tag_elements:
tag = tag_element.text
tags.append(tag)
# Preencha um novo objeto de citação com os dados coletados
quote = {
"text": text,
"author": author,
"tags": tags
}
# Adicione-o à lista de citações coletadas
quotes.append(quote)
# Visite a próxima página
sb.click(".next a")
# Exportar os dados coletados para CSV
com open("quotes.csv", modo="w", nova linha="", codificação="utf-8") como arquivo:
writer = csv.DictWriter(arquivo, nomes de campos=["texto", "autor", "tags"])
writer.writeheader()
# Achate os objetos de citação para gravação em CSV
para citação em citações:
writer.writerow({
"text": citação["text"],
"author": citação["author"],
"tags": ";".join(citação["tags"])
})
Execute o Scraper SeleniumBase no modo headless com:
python3 script.py --headless
Após alguns segundos, um arquivo quotes.csv aparecerá na pasta do projeto.
Abra-o e você verá:
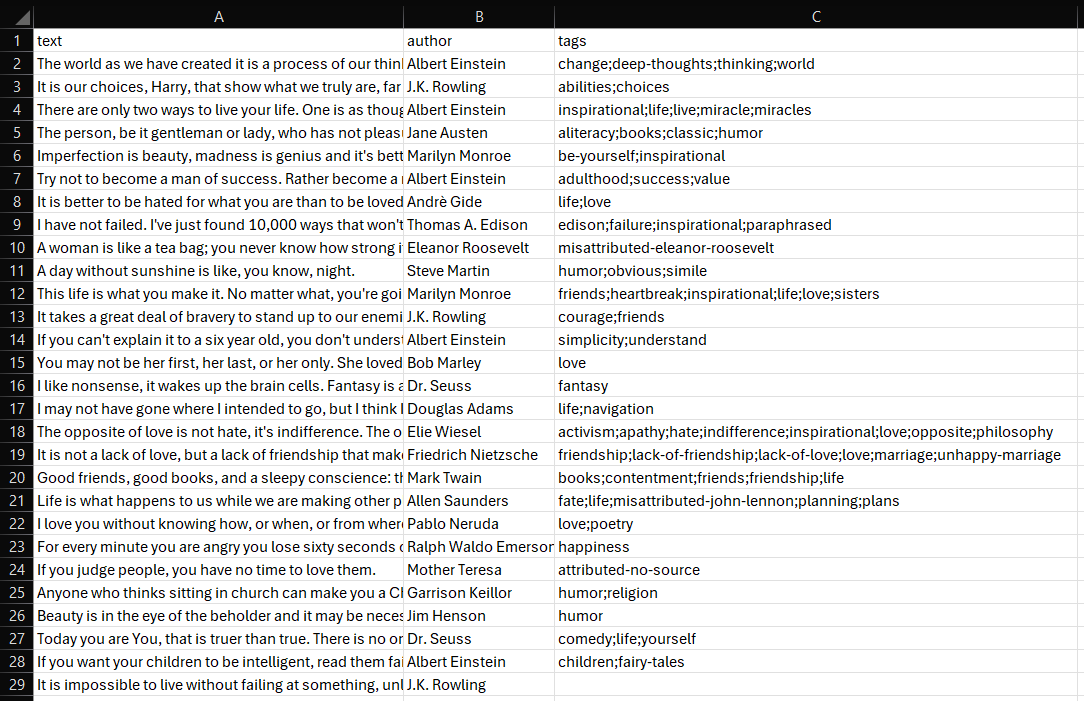
Et voilà! Seu script de Scraping de dados da web SeleniumBase funciona perfeitamente.
Casos de uso avançados de raspagem com SeleniumBase
Agora que você já conhece os fundamentos do SeleniumBase, está pronto para explorar alguns cenários mais complexos.
Automatizar o preenchimento e envio de formulários
Observação: a Bright Data não faz scraping atrás do login.
O SeleniumBase também permite que você interaja com elementos em uma página como um usuário humano faria. Por exemplo, suponha que você precise interagir com um formulário de login como mostrado abaixo:
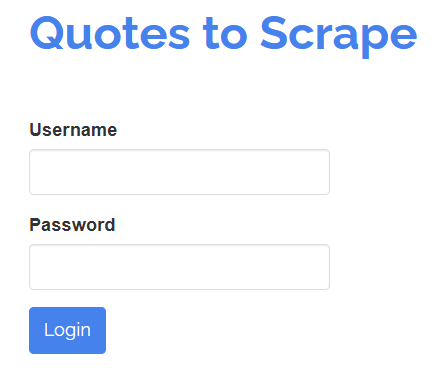
Seu objetivo é preencher os campos “Nome de usuário” e “Senha” e, em seguida, enviar o formulário clicando no botão “Login”. Você pode fazer isso com um teste do SeleniumBase da seguinte maneira:
# login.py
from seleniumbase import BaseCase
BaseCase.main(__name__, __file__)
class LoginTest(BaseCase):
def test_submit_login_form(self):
# Visite a página de destino
self.open("https://quotes.toscrape.com/login")
# Preencha o formulário
self.type("#username", "test")
self.type("#password", "test")
# Envie o formulário
self.click("input[type="submit"]")
# Verifique se você está na página certa
self.assert_text("Top Ten tags")
Este exemplo é ótimo para criar um teste, portanto, observe o uso da classe BaseCase. Isso permite que você crie testes pytest.
Execute o teste com este comando:
pytest login.py
Você verá o navegador abrir, carregar a página de login, preencher o formulário, enviá-lo e, em seguida, verificar se o texto fornecido aparece na página.
A saída no terminal será semelhante a esta:
login.py . [100%]
======================================== 1 aprovado em 11,20 s =========================================
Contornar tecnologias simples anti-bot
Muitos sites implementam medidas avançadas anti-scraping para impedir que bots acessem seus dados. Essas técnicas incluem desafios CAPTCHA, limites de taxa, impressão digital do navegador e outras. Para fazer scraping de sites de forma eficaz sem ser bloqueado, você precisa contornar essas proteções.
O SeleniumBase oferece um recurso especial chamado Modo UC (Modo Undetected-Chromedriver), que ajuda os bots de scraping a parecerem mais com usuários humanos. Isso permite que eles evitem a detecção por serviços anti-bot, que poderiam bloquear o bot de scraping diretamente ou acionar CAPTCHAs.
O Modo UC é baseado no undetected-chromedriver e vem com várias atualizações, correções e melhorias, tais como:
- Rotação automática do User-Agent para evitar a detecção.
- Configuração automática dos argumentos do Chromium conforme necessário.
- Métodos especiais
uc_*()para contornar CAPTCHAs.
Agora, vamos ver como usar o Modo UC no SeleniumBase para contornar os desafios anti-bot.
Para esta demonstração, você verá como acessar a página anti-bot do site Scraping Course:
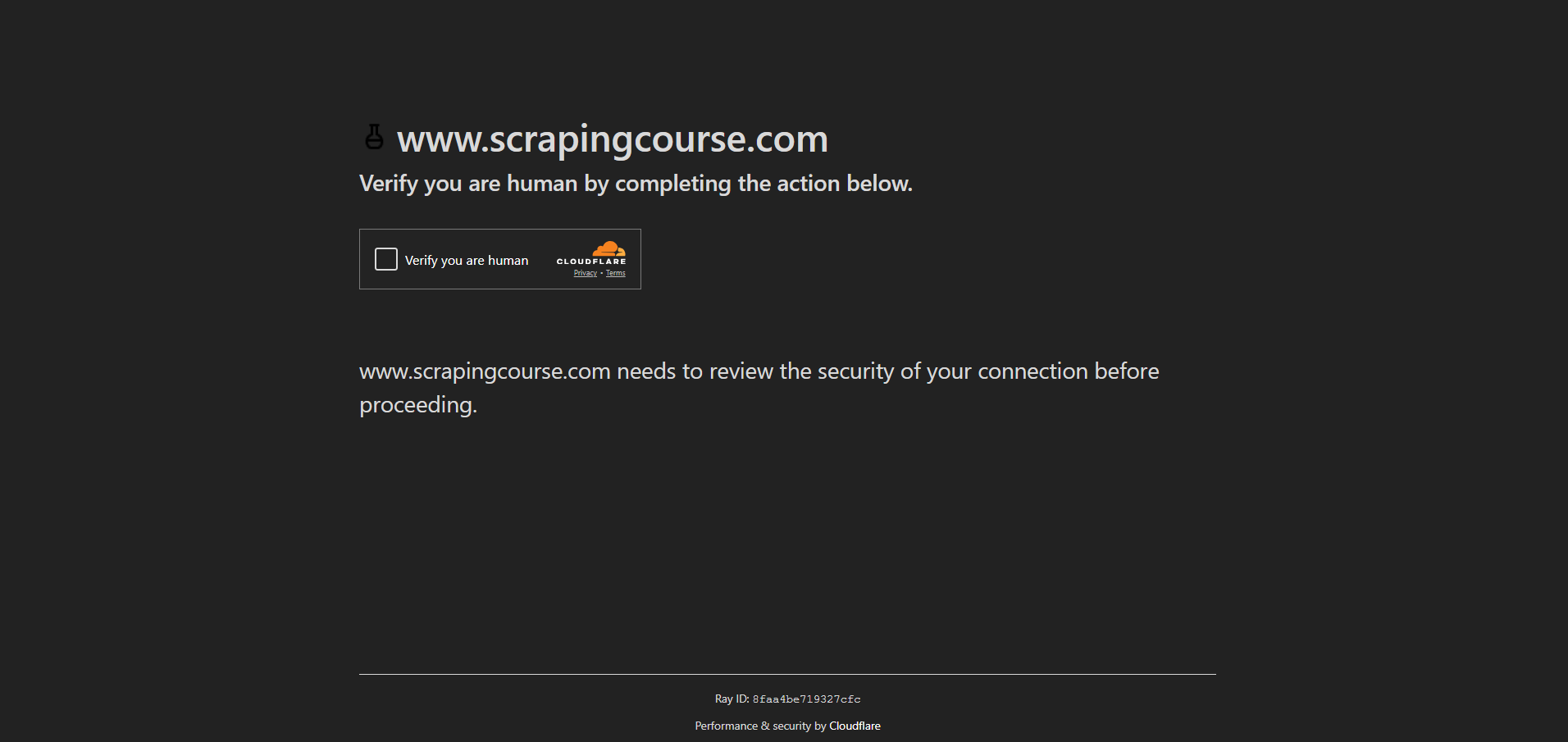
Para contornar as medidas anti-bot e lidar com o CAPTCHA, habilite o Modo UC e use os métodos uc_open_with_reconnect() e uc_gui_click_captcha():
from seleniumbase import SB
with SB(uc=True) as sb:
# Página de destino com medidas anti-bot
url = "https://www.scrapingcourse.com/antibot-challenge"
# Abra a URL usando o Modo UC com um tempo de reconexão de 4 segundos para evitar a detecção inicial
sb.uc_open_with_reconnect(url, reconnect_time=4)
# Tentar ignorar o CAPTCHA
sb.uc_gui_click_captcha()
# Capturar uma imagem da página
sb.save_screenshot("screenshot.png")
Agora, inicie o script e verifique se ele funciona conforme o esperado. Como o uc_gui_click_captcha() requer o PyAutoGUI para funcionar, o SeleniumBase irá instalá-lo para você na primeira execução:
PyAutoGUI necessário! Instalando agora...
Você verá o navegador clicar automaticamente na opção “Verificar que você é humano” movendo o mouse. O arquivo screenshot.png na pasta do seu projeto mostrará:
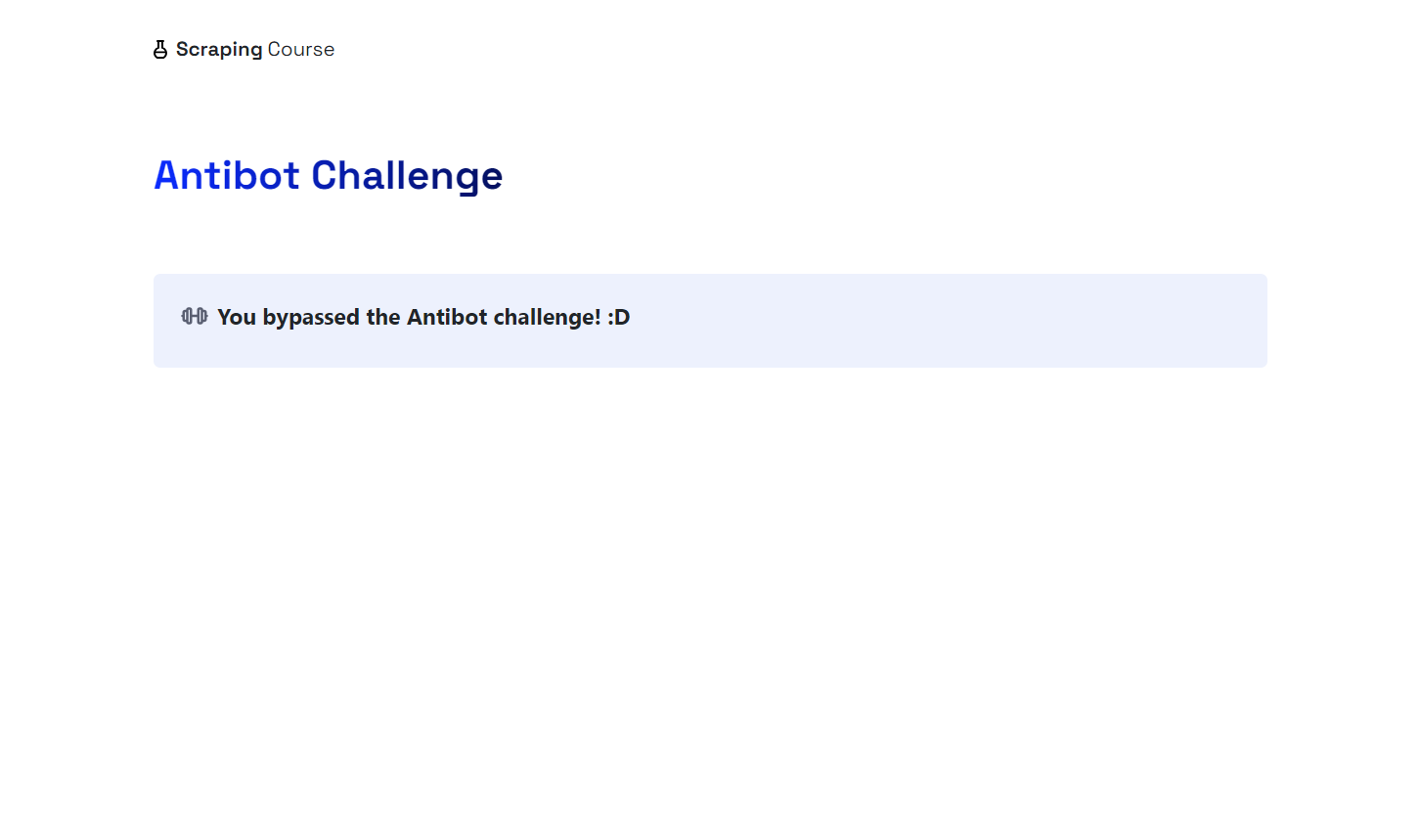
Uau! O Cloudflare foi contornado.
Contornar tecnologias anti-bot complexas
As soluções anti-bot estão se tornando cada vez mais sofisticadas, e o Modo UC pode não ser sempre eficaz. É por isso que o SeleniumBase também oferece um Modo CDP especial (Modo Chrome DevTools Protocol).
O Modo CDP opera dentro do Modo UC e permite que os bots pareçam mais humanos, controlando o navegador por meio do CDP-Driver. Enquanto o Modo UC normal não pode executar ações do WebDriver quando o driver está desconectado do navegador, o CDP-Driver ainda pode interagir com o navegador, superando essa limitação.
O Modo CDP é baseado em python-cdp, trio-cdp e nodriver. Ele foi projetado para contornar soluções anti-bot avançadas de sites do mundo real, como no exemplo abaixo:
from seleniumbase import SB
with SB(uc=True, test=True) as sb:
# Página de destino com medidas anti-bot avançadas
url = "https://gitlab.com/users/sign_in"
# Visite a página no Modo CDP
sb.activate_cdp_mode(url)
# Lidar com o CAPTCHA
sb.uc_gui_click_captcha()
# Aguardar 2 segundos para que a página seja recarregada e o driver retome o controle
sb.sleep(2)
# Capturar uma imagem da página
sb.save_screenshot("screenshot.png")
O resultado será:
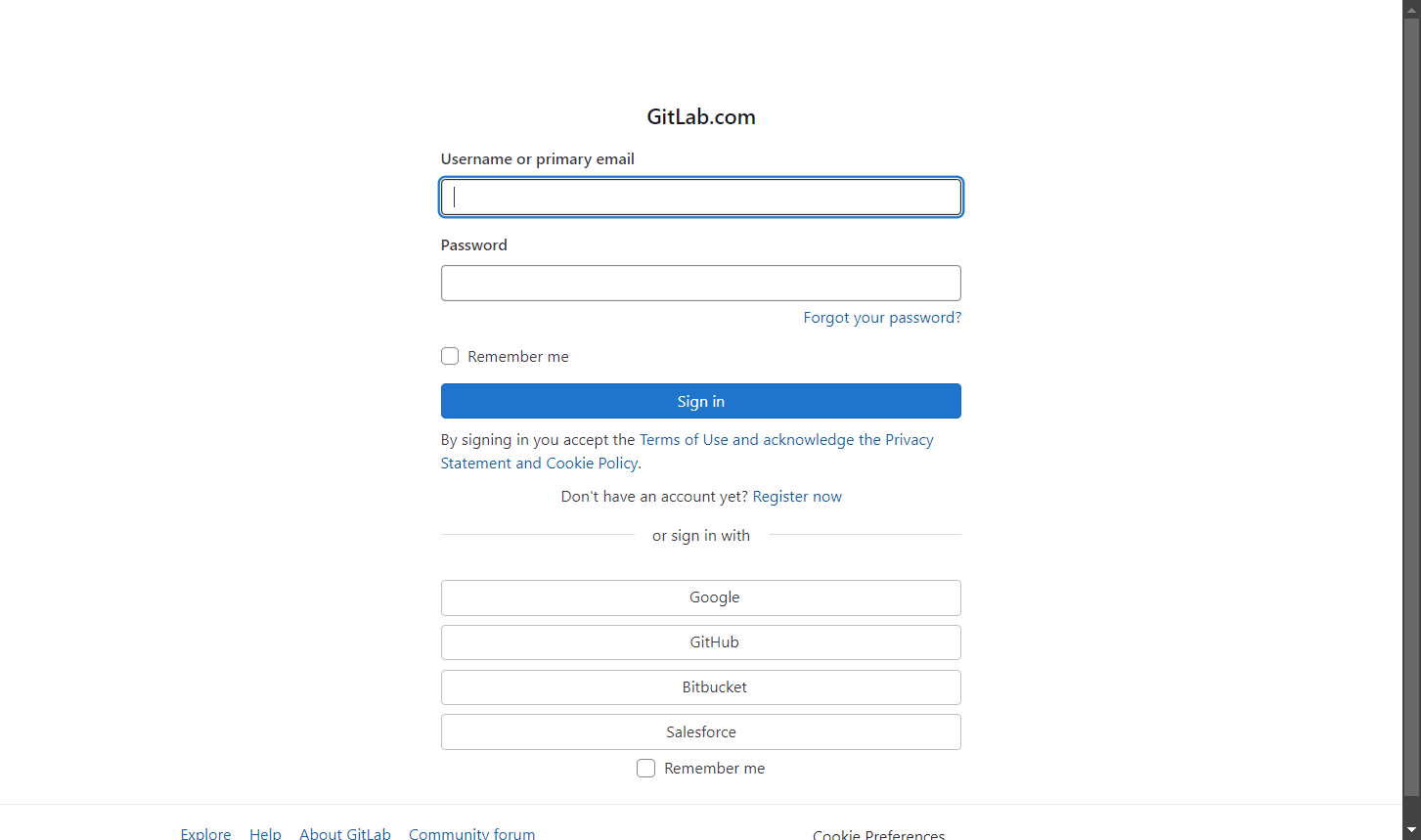
Pronto! Agora você é um mestre em scraping com SeleniumBase.
Conclusão
Neste artigo, você aprendeu sobre o SeleniumBase, os recursos e métodos que ele oferece e como usá-lo para Scraping de dados. Você começou com cenários básicos e depois explorou casos de uso mais complexos.
Embora o modo UC e o modo CDP sejam eficazes para contornar certas medidas anti-bot, eles não são infalíveis.
Os sites ainda podem bloquear seu IP se você fizer muitas solicitações ou desafiá-lo com CAPTCHAs mais complexos que exigem várias ações. Uma solução mais eficaz é usar uma ferramenta de automação de navegador da web como o Selenium em combinação com um navegador dedicado a scraping, baseado em nuvem e altamente escalável, como o Navegador de scraping da Bright Data.
O Navegador de scraping é um navegador que funciona com Playwright, Puppeteer, Selenium e outros. Ele alterna automaticamente os IPs de saída a cada solicitação e pode lidar com impressões digitais do navegador, novas tentativas, resolução de CAPTCHA e muito mais. Esqueça o bloqueio e otimize sua operação de scraping.
Inscreva-se agora e comece seu teste grátis!






