
Neste tutorial, você aprenderá:
- O que é o Cursor e por que ele se tornou tão popular.
- Os principais motivos para adicionar um servidor MCP revolucionário, como o da Bright Data, ao Cursor.
- Como conectar o Cursor ao Web MCP da Bright Data.
- Como obter os mesmos resultados no Visual Studio Code.
Vamos nos aprofundar no assunto!
O que é o Cursor?
O Cursor é um editor de código com IA criado como uma bifurcação do Visual Studio Code. Sua principal funcionalidade, como a de qualquer editor de texto, é fornecer uma interface para escrever código. Ainda assim, o que o torna especial é sua profunda integração com IA.
Em vez do preenchimento automático básico, o Cursor usa LLms para entender toda a sua base de código e o contexto. Isso permite que ele forneça recursos inteligentes como:
- Prompts de conversação: Descreva o que você deseja em inglês simples, e o Cursor escreverá ou editará o código para você.
- Preenchimento automático de várias linhas: Ele sugere e completa blocos inteiros de código, não apenas linhas únicas.
- Refatoração orientada por IA: Ele pode otimizar, limpar e corrigir seu código de forma inteligente com base no contexto de todo o projeto.
- Assistência à depuração: Peça à IA para encontrar e explicar os erros em seu código.
O Cursor transforma um editor de código padrão em um programador de pares proativo e altamente inteligente. Ele é compatível com vários LLMs de diversos fornecedores e inclui suporte integrado para ferramentas por meio do MCP.
Por que adicionar o Web MCP da Bright Data ao Cursor
Nos bastidores, o Cursor se baseia em modelos de LLM conhecidos. Embora sua integração seja mais profunda e mais refinada do que a maioria das ferramentas, ele ainda enfrenta a mesma limitação central de qualquer LLM: o conhecimento de IA é estático!
Afinal de contas, os dados de treinamento de IA refletem um instantâneo no tempo. Isso se torna rapidamente desatualizado, especialmente em campos de rápida evolução, como o desenvolvimento de software. Agora, imagine dar ao agente de IA do Cursor a capacidade de:
- acessar os tutoriais e a documentação mais recentes para fluxos de trabalho RAG,
- consultar guias ao vivo enquanto escreve código e
- navegar em sites em tempo real com a mesma facilidade com que navega em seus arquivos locais.
É exatamente isso que você desbloqueia ao conectar o Cursor ao Web MCP da Bright Data!
O Web MCP oferece acesso a mais de 60 ferramentas prontas para IA criadas para interação com a Web em tempo real e coleta de dados. Todas elas são alimentadas pela rica infraestrutura de IA da Bright Data.
Mesmo na camada gratuita, seu agente Cursor já pode acessar duas ferramentas poderosas:
| Ferramenta | Descrição da ferramenta |
|---|---|
motor_de_pesquisa |
Recupere resultados de pesquisa do Google, Bing ou Yandex em JSON ou Markdown. |
scrape_as_markdown |
Extraia qualquer página da Web em um formato Markdown limpo, ignorando a detecção de bots e o CAPTCHA. |
Além disso, o Web MCP inclui ferramentas para automação do navegador em nuvem e recuperação de dados estruturados de plataformas como Amazon, YouTube, LinkedIn, TikTok, Google Maps e muitas outras.
Aqui estão apenas alguns exemplos do que se torna possível ao estender o Cursor com o Web MCP da Bright Data:
- Recuperar as mais recentes referências de API ou tutoriais de estrutura e, em seguida, gerar automaticamente o código de trabalho ou os andaimes do projeto.
- Obter instantaneamente resultados atualizados de mecanismos de pesquisa e incorporá-los à sua documentação ou aos comentários do código.
- Reúna dados ao vivo da Web para criar simulações de testes realistas, painéis de análise ou pipelines de conteúdo automatizados.
Para explorar a gama completa de recursos, dê uma olhada na documentação do Bright Data MCP.
Como integrar o Web MCP ao Cursor para obter uma experiência aprimorada de codificação de IA
Nesta seção passo a passo, você verá como conectar uma instância do servidor local do Bright Data Web MCP ao Cursor. Essa configuração fornece uma experiência de IA superalimentada com mais de 60 ferramentas disponíveis diretamente em seu IDE.
Em detalhes, usaremos as ferramentas do Web MCP para criar um backend Express com uma API simulada que retorna dados do mundo real da Amazon. Esse é apenas um exemplo dos muitos casos de uso suportados por essa integração.
Siga as instruções abaixo!
Pré-requisitos
Para acompanhar este tutorial, certifique-se de que você tenha:
- Uma conta do Cursor (um plano gratuito é suficiente).
- Uma conta da Bright Data com uma chave de API ativa.
Não se preocupe em configurar a Bright Data agora. Você será orientado durante o processo ao longo do artigo!
Uma compreensão básica de como o MCP funciona, como o Cursor funciona e as ferramentas fornecidas pelo Web MCP também serão úteis.
Etapa 1: Começar a usar o Cursor
Instale a versão do Cursor para seu sistema operacional, abra-o e faça login com sua conta.
Se esta for a primeira vez que você inicia o aplicativo, conclua o assistente de configuração.
Você deverá ver algo parecido com isto:
Ótimo! Agora, abra a pasta do seu projeto e prepare-se para usar o agente de codificação IA integrado, estendido com o Web MCP.
Etapa 2: configurar o LLM
No momento em que escrevo, o Cursor usa o modelo Claude 4.5 por padrão (por meio do modo “Auto”). Se não tiver problemas com isso, pule para a próxima seção. Lembre-se de que o Claude também pode ser integrado ao Web MCP.
Se você quiser alterar o modelo padrão, pesquise “configurações do cursor” e selecione a opção equivalente:
Na guia que se abre, vá para a guia “Models” (Modelos):

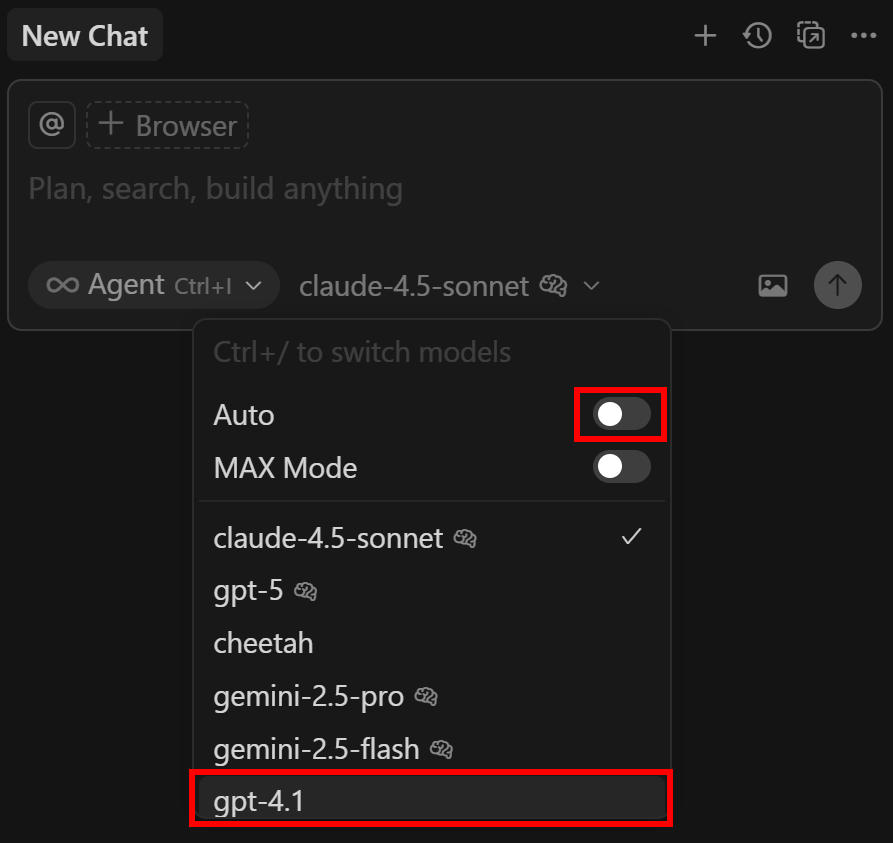
Aqui, você pode configurar qual agente de IA do LLM Cursor deve utilizar. Lembre-se de que os usuários gratuitos só podem escolher entre GPT-4.1 e “Auto” como modelos premium.
Para alterar o modelo para GTP 4.1, pesquise “gpt”, localize o modelo “gpt-4.1” e ative-o:

Se você tiver uma assinatura Pro ou Business, poderá ativar quaisquer outros LLMs compatíveis. Além disso, você pode até mesmo fornecer sua própria chave de API para o provedor escolhido.
Em seguida, abra o painel “Novo chat” à direita. Clique na lista suspensa “Auto”, desative-a e selecione a opção “gpt-4.1”:
Pronto! O Cursor agora está operando por meio do LLM configurado.
Etapa 3: Teste o Web MCP da Bright Data em sua máquina
Antes de conectar o Cursor ao Web MCP da Bright Data, verifique se você pode realmente executar o servidor localmente. Isso é necessário porque o servidor MCP será configurado por meio de STDIO.
Comece registrando-se na Bright Data. Caso contrário, se você já tiver uma conta, basta fazer o login. Para uma configuração rápida, siga as instruções na seção “MCP” do painel:
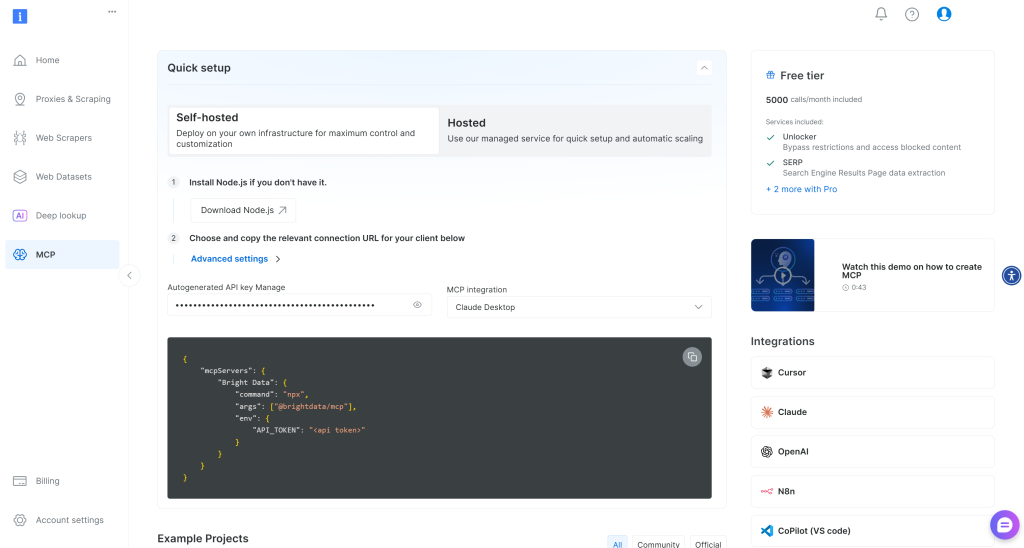
Para obter mais orientações, consulte as instruções abaixo.
Primeiro, gere sua chave da API da Bright Data e guarde-a em um local seguro. Você precisará dela na próxima etapa. Vamos supor que sua chave de API tenha permissões de administrador, pois isso simplifica a integração do Web MCP.
Agora, instale o Web MCP globalmente em sua máquina por meio deste comando npm:
npm install -g @brightdata/mcpVerifique se o servidor MCP funciona, iniciando-o:
API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>" npx -y @brightdata/mcpOu, de forma equivalente, no PowerShell:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>"; npx -y @brightdata/mcpSubstitua o espaço reservado <YOUR_BRIGHT_DATA_API> pelo seu token da API da Bright Data. Esses comandos definem a variável de ambiente API_TOKEN necessária e iniciam o Web MCP localmente por meio do pacote @brightdata/mcp.
Se for bem-sucedido, você verá uma saída como esta:

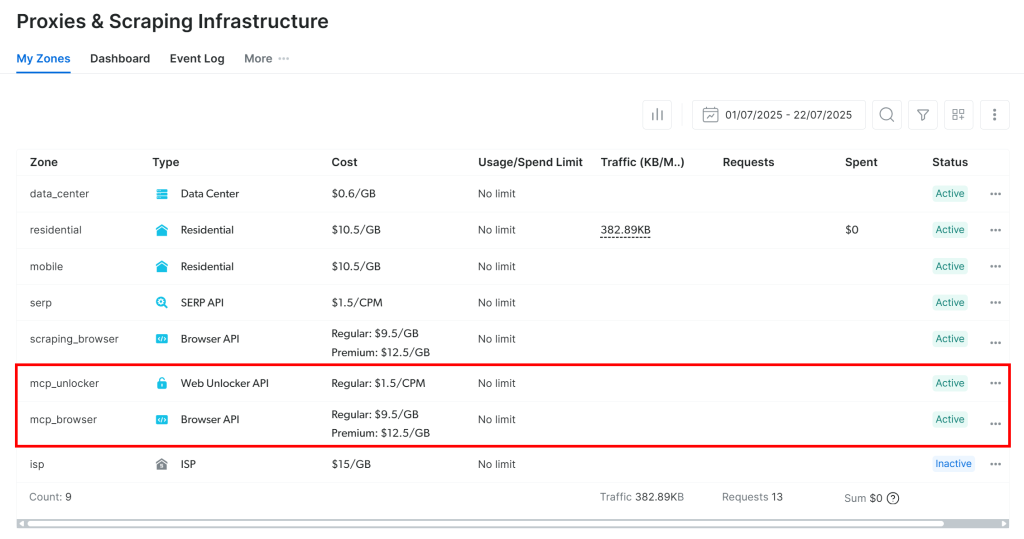
Na primeira inicialização, o Web MCP cria duas zonas padrão em sua conta da Bright Data:
mcp_unlocker: Uma zona para o Web Unlocker.mcp_browser: Uma zona para a API do navegador.
O Web MCP depende desses dois serviços da Bright Data para alimentar suas mais de 60 ferramentas.
Se quiser verificar se as zonas foram configuradas, acesse a página “Proxies & Scraping Infrastructure” (Proxies e Infraestrutura de scraping) em sua conta da Bright Data. Você deverá localizar as duas zonas na tabela:
Observação: Se seu token de API não tiver permissões de administrador, as duas zonas não serão criadas automaticamente. Nesse caso, defina-as manualmente e configure-as por meio de variáveis de ambiente , conforme explicado no GitHub.
Lembre-se de que, na camada gratuita, o Web MCP expõe apenas as ferramentas search_engine e scrape_as_markdown (e suas versões em lote). Para desbloquear todas as outras ferramentas, ative o modo Pro ** definindo a variável de ambiente PRO_MODE="true":
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpOu, no Windows:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpO modo Pro desbloqueia todas as mais de 60 ferramentas, mas não está incluído na camada gratuita, o que significa que incorrerá em cobranças adicionais.
Excelente! Você acabou de se certificar de que o servidor Web MCP funciona localmente. Encerre o processo do MCP, pois você está prestes a configurar o Cursor para iniciá-lo para você e conectar-se a ele.
Etapa 4: Configurar o Web MCP no Cursor
Comece procurando por “>mcp” e selecionando a opção “View: Abrir configurações de MCP”:
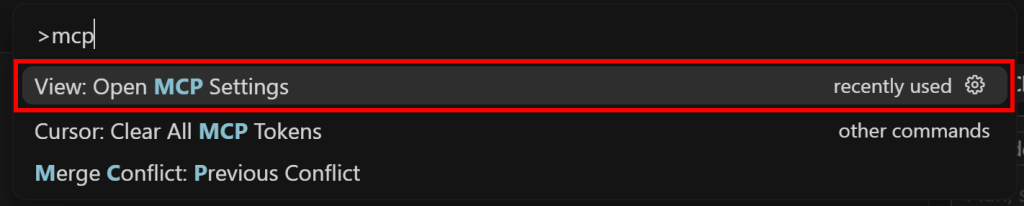
Na seção “Tools & MCP”, clique no botão “Add Custom MCP” (Adicionar MCP personalizado):

Isso abrirá o seguinte arquivo de configuração mcp.json:

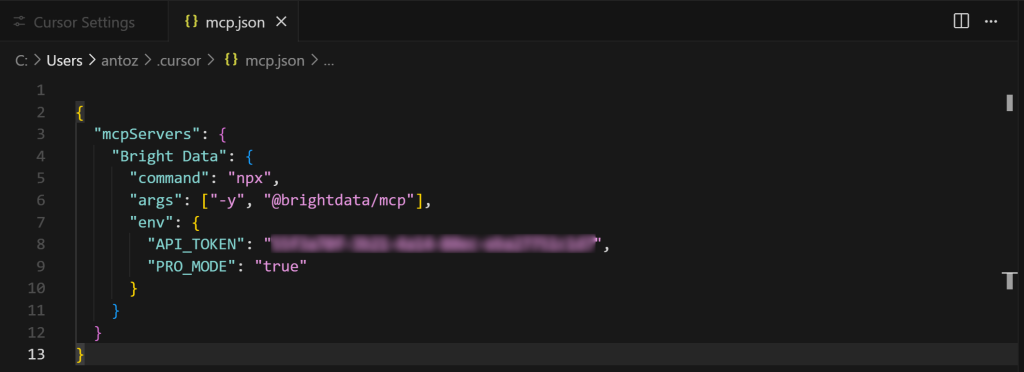
Como você pode ver, por padrão, ele está vazio. Para a integração do Web MCP da Bright Data, preencha-o conforme abaixo:
{
"mcpServers": {
"Bright Data": {
"command" (comando): "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<SUA CHAVE_API_DATA_BRIGHT_DATA>",
"PRO_MODE": "true"
}
}
}
}Em seguida, salve o arquivo usando Ctrl + S (ou Cmd + S no macOS):
A configuração acima replica o comando npx que testamos anteriormente, usando variáveis de ambiente para passar credenciais e configurações:
API_TOKENé necessário. Defina-a como a chave da API da Bright Data que você gerou anteriormente.PRO_MODEé opcional. Remova-o se não pretender ativar o modo Pro.
Em outras palavras, o Cursor usará a configuração em mcp.json para executar o comando npx visto anteriormente. Ele executará um processo Web MCP localmente, se conectará a ele e obterá acesso às ferramentas expostas.
Feche a guia mcp.json, pois a integração do Cursor + Bright Data Web MCP está concluída!
Observação: Se você preferir não usar STDIO e quiser usar SSE ou HTTP de fluxo contínuo, lembre-se de que o Web MCP da Bright Data também oferece uma opção de servidor remoto.
Etapa #5: Verificar a disponibilidade da ferramenta a partir da integração do MCP
É hora de verificar se o Cursor se conectou com êxito ao servidor Web MCP e se pode acessar todas as suas ferramentas.
Para isso, volte para a seção “Tools & MCP” (Ferramentas e MCP) na guia “Cursor Settings” (Configurações do Cursor). Agora você deve ver a opção “Bright Data” configurada, listando todas as ferramentas disponíveis:
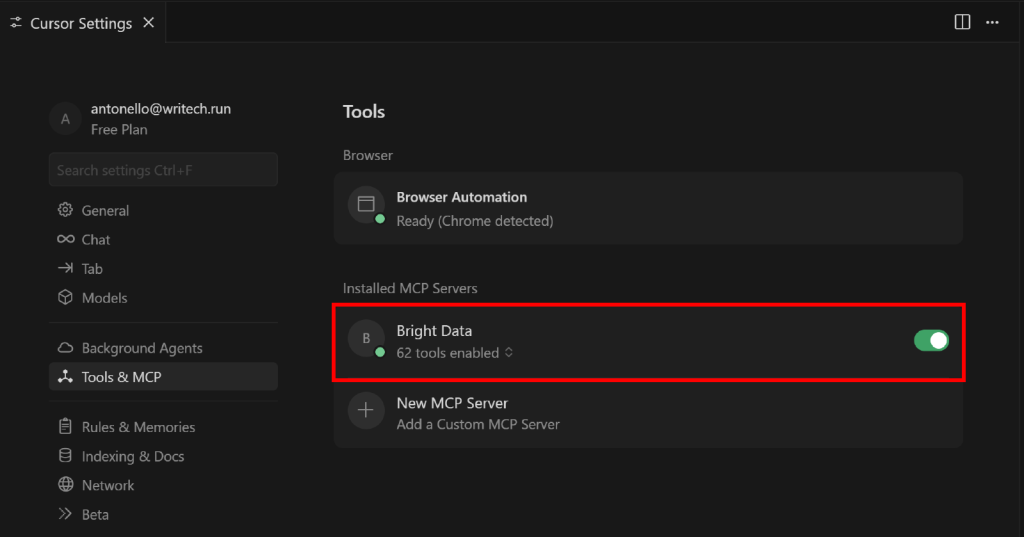
Expanda o menu suspenso “N tools enabled” (onde N é o número de ferramentas ativadas) para inspecionar todas as ferramentas disponíveis:
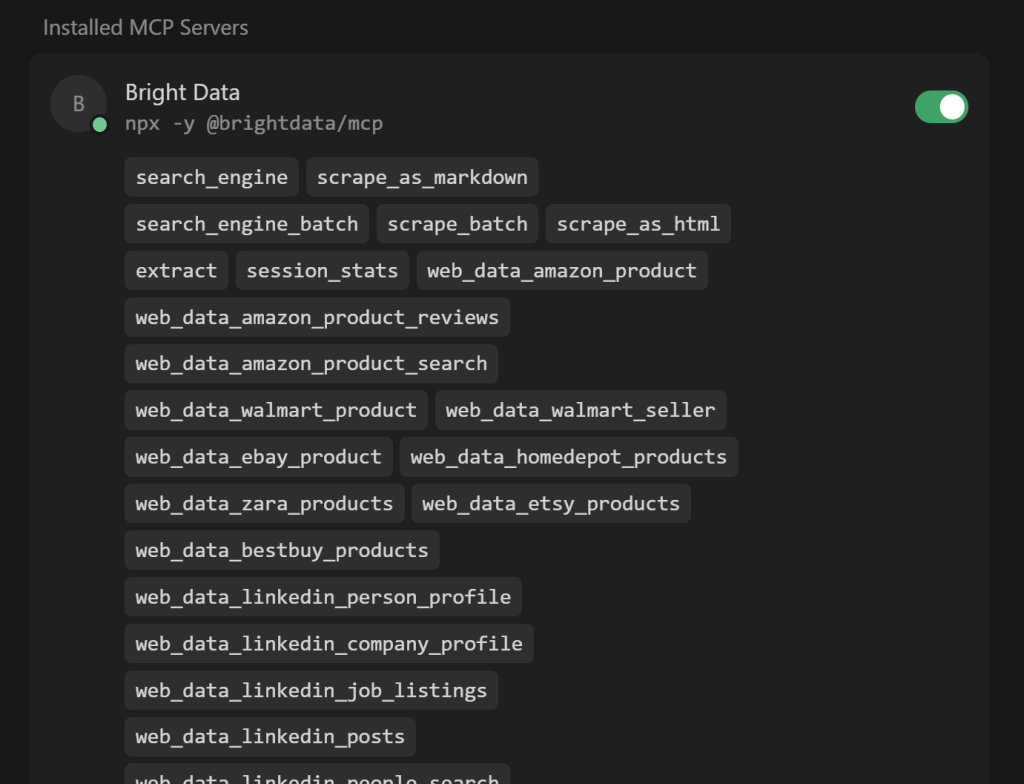
Observe que o Cursor se conecta automaticamente ao servidor e recupera suas mais de 60 ferramentas.
Se o Pro Mode estiver desativado, você verá apenas as 4/5 ferramentas gratuitas disponíveis. Aqui, você também pode ativar ou desativar as ferramentas como preferir. Por padrão, todas elas estão ativadas.
Após a confirmação, feche a guia “Cursor Settings” (Configurações do cursor). Prepare-se para aproveitar essas ferramentas para ter uma experiência de codificação ampliada com IA!
Etapa 6: Executar uma tarefa com o agente de codificação IA aprimorado
Para testar os recursos do seu agente de codificação do Cursor, você precisa de um prompt que exercite os recursos de recuperação de dados da Web recém-configurados.
Por exemplo, suponha que você esteja criando um backend no Express.js para seu aplicativo de comércio eletrônico. Você deseja simular uma API que retorna dados reais de produtos da Amazon.
Faça isso com um prompt como este:
Extraia os dados dos seguintes produtos da Amazon:
1. https://www.amazon.com/Clean-Skin-Club-Disposable-Sensitive/dp/B07PBXXNCY/
2. https://www.amazon.com/Neutrogena-Cleansing-Towelettes-Waterproof-Alcohol-Free/dp/B00U2VQZDS/
3. https://www.amazon.com/Medicube-Zero-Pore-Pads-Dual-Textured/dp/B09V7Z4TJG/
Em seguida, salve os dados extraídos em um arquivo JSON local. Em seguida, crie um projeto Express.js simples com um ponto de extremidade que aceite um ASIN (representando um produto da Amazon) e retorne os dados correspondentes lidos do arquivo JSON.Suponha que você esteja operando no modo Pro. Execute o prompt acima no Cursor.
Veja a seguir o que aconteceu, passo a passo:
- O LLM configurado no Cursor identifica
web_data_amazon_productcomo a ferramenta para recuperar dados de produtos da Amazon. - Para cada um dos três produtos da Amazon no prompt, é solicitada a permissão para executar
web_data_amazon_productpara obter os dados. - Você concede a permissão para cada ferramenta, acionando tarefas assíncronas de coleta de dados (que, por trás disso, chamam o Bright Data Amazon Scraper).
- Os dados recuperados de cada produto são exibidos no formato JSON.
- O GPT-4.1 processa os dados recuperados e preenche um arquivo
products.jsoncom eles. - O Cursor cria a estrutura do projeto npm, definindo
package.json, e o arquivoindex.jscom a lógica do servidor Express. - É solicitada a sua permissão para instalar as dependências do projeto por meio do
npm install. Isso resultará em um arquivopackage.jsone na pastanode_modules/. - É solicitada a sua permissão para executar o servidor com o
npm start.
Observação: mesmo que não tenha sido explicitamente especificado no prompt, o GPT-4.1 também decidiu solicitar a instalação da dependência do projeto e a configuração do servidor. Essa foi uma boa adição!
Neste exemplo, a saída final produzirá uma estrutura de projeto como a seguinte:
seu-projeto/
├── node_modules/
├── index.js
├── package.json
package-lock.json
└── produtos.jsonPerfeito! Vamos inspecionar o resultado para ver se ele atingiu o objetivo pretendido.
Etapa nº 7: explorar o projeto de saída
À medida que o agente de codificação IA gerava os arquivos, eles apareciam na coluna esquerda do Cursor.
Isenção de responsabilidade: seus arquivos podem ser diferentes do que é mostrado abaixo, pois diferentes execuções de IA podem produzir resultados diferentes.
Comece inspecionando o arquivo products.json:
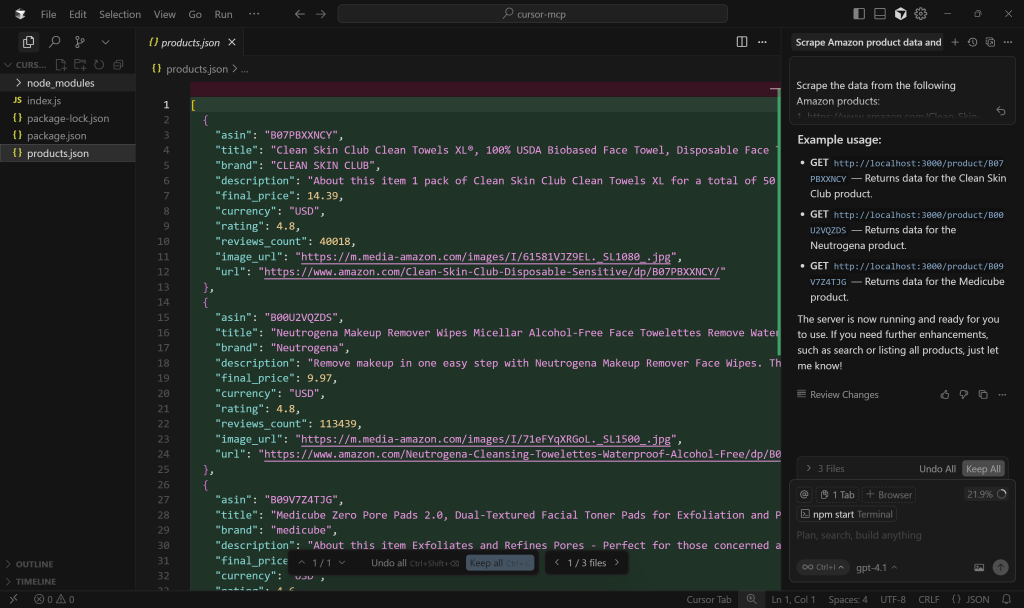
Como você pode ver, ele contém uma versão simplificada dos dados extraídos retornados pela ferramenta web_data_amazon_product:
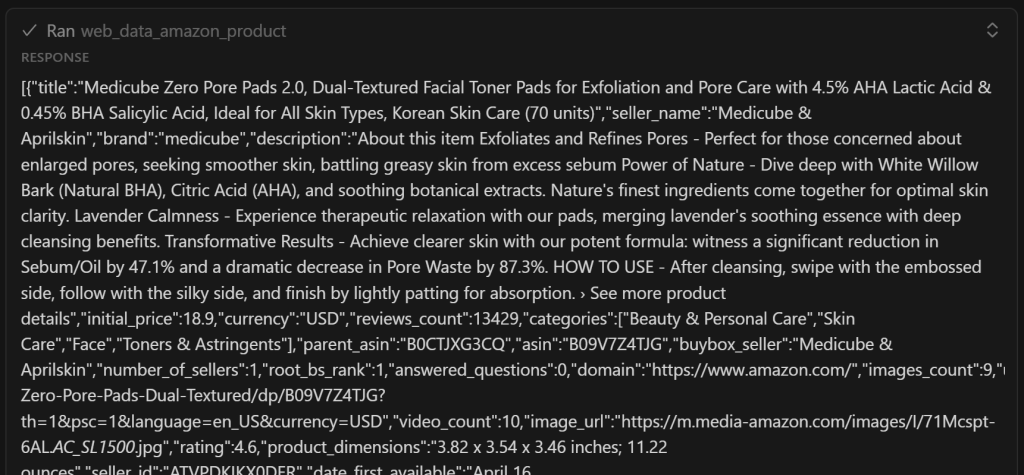
Importante: o web_data_amazon_product realmente retorna todos os dados do produto da página da Amazon, não apenas alguns campos. Ainda assim, a IA decidiu incluir apenas os campos mais relevantes. Com alguma otimização de prompt, você pode instruir a IA a incluir todos os campos, se desejar.
Em seguida, abra o index.js para ver a lógica do servidor Express.js:
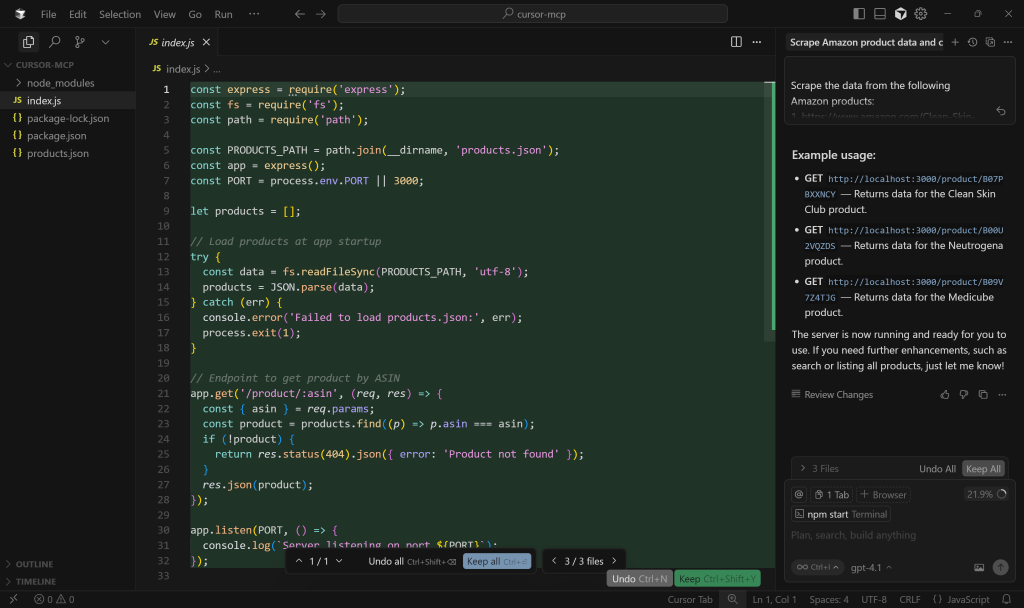
Especificamente, o endpoint simulado para recuperação de dados do produto usa o caminho /product/:asin.
Continue inspecionando os outros arquivos, mas todos eles devem estar corretos. Portanto, pressione o botão “Keep All” (Manter tudo) para confirmar a saída gerada pela IA e prepare-se para colocar seu projeto em teste!
Etapa 8: testar o projeto produzido
Seu aplicativo Express.js já deve estar em execução, pois o GPT-4.1 pediu permissão para executar o npm start. Se não estiver, você pode iniciá-lo manualmente com:
npm startSeu backend Express.js agora deve estar em execução em http://localhost.
Em seguida, execute o seguinte comando cURL para testar o endpoint GET /product/:asin:
curl "http://localhost/ product/B07PBXXNCYOnde B07PBXXNCY é o ASIN de um dos produtos da Amazon mencionados no prompt.
Você deverá ver algo parecido com isto:

Maravilhoso! Esses dados foram buscados corretamente no arquivo products.json gerado. O resultado corresponde a (uma versão simplificada de) os dados da página original da Amazon.
Se você já tentou extrair dados de produtos da Amazon, sabe como isso pode ser desafiador devido ao notório Amazon CAPTCHA e a outras medidas anti-bot. Certamente, o GPT-4.1 vanilla sozinho não pode recuperar dados da Amazon em tempo real.
Isso demonstra o poder da combinação do Web MCP com o Cursor. Este foi apenas um exemplo muito simples. No entanto, com as mais de 60 ferramentas disponíveis e os prompts certos, você pode lidar com cenários mais avançados diretamente no seu IDE!
E pronto! Um backend Express com um endpoint de API simulado foi criado com sucesso, graças à integração Cursor + Bright Data Web MCP.
[Extra] Abordagens alternativas no Visual Studio Code
Se você deseja obter uma experiência semelhante à do Cursor no Visual Studio Code, use extensões como Cline ou Roo Code.
Em particular, para integrar o Web MCP ao VS Code, consulte estes guias:
- Adição do Web MCP da Bright Data ao Roo Code no Visual Studio Code
- Scraping de dados da Web no Cline com o servidor MCP da Bright Data
Conclusão
Nesta postagem do blog, você aprendeu como aproveitar ao máximo a integração do MCP no Cursor. O agente de codificação IA incorporado ao IDE já é útil, mas se torna muito mais capaz e engenhoso quando conectado ao MCP da Web da Bright Data.
Essa integração dá ao Cursor a capacidade de realizar pesquisas ao vivo na Web, extrair dados estruturados, consumir feeds de dados dinâmicos e até mesmo automatizar as interações do navegador. Tudo isso, diretamente de seu ambiente de codificação.
Para criar fluxos de trabalho ainda mais avançados com IA, explore o conjunto completo de serviços e soluções de dados disponíveis no ecossistema de IA da Bright Data.
Crie uma conta gratuita da Bright Data hoje mesmo e comece a fazer experiências com nossas ferramentas de dados da Web prontas para IA!






