
Neste guia, você aprenderá:
- O que é Agentic Retrieval-Augmented Generation (RAG) e por que é importante adicionar recursos agênticos
- Como a Bright Data permite a recuperação autônoma e ao vivo de dados da Web para sistemas RAG
- Como processar e limpar dados extraídos da Web para geração de incorporação
- Implementação de um controlador de agente para orquestrar entre a pesquisa vetorial e a geração de texto LLM
- Projetar um loop de feedback para capturar as entradas do usuário e otimizar a recuperação e a geração de forma dinâmica
Vamos mergulhar de cabeça!
O surgimento da Inteligência Artificial (IA) introduziu novos conceitos, incluindo o Agentic RAG. Em termos simples, o Agentic RAG é o Retrieval Augmented Generation (RAG) que integra agentes de IA. Como o nome sugere, o RAG é um sistema de recuperação de informações que segue um processo linear: ele recebe uma consulta, recupera informações relevantes e gera uma resposta.
Por que combinar agentes de IA com o RAG?
Uma pesquisa recente mostra que quase dois terços dos fluxos de trabalho que usam agentes de IA relatam aumento de produtividade. Além disso, cerca de 60% relatam economia de custos. Isso faz com que a combinação de agentes de IA com o RAG seja um divisor de águas em potencial para os fluxos de trabalho de recuperação modernos.
O Agentic RAG oferece recursos avançados. Diferentemente dos sistemas RAG tradicionais, ele pode não apenas recuperar dados, mas também decidir buscar informações de fontes externas, como dados da Web ao vivo incorporados em um banco de dados.
Este artigo demonstra como criar um sistema Agentic RAG que recupera informações de notícias usando Bright Data para coleta de dados da Web, Pinecone como banco de dados vetorial, OpenAI para geração de texto e Agno como controlador de agente.
Visão geral dos dados da Bright
Quer você esteja obtendo dados de um fluxo de dados ao vivo ou usando dados preparados do seu banco de dados, a qualidade da saída do seu sistema Agentic RAG depende da qualidade dos dados que ele recebe. É nesse ponto que a Bright Data se torna essencial.
A Bright Data fornece dados da Web confiáveis, estruturados e atualizados para uma ampla gama de casos de uso. Com a API de raspagem da Web da Bright Data, que tem acesso a mais de 120 domínios, a raspagem da Web está mais eficiente do que nunca. Ela lida com desafios comuns de raspagem, como proibições de IP, CAPTCHA, cookies e outras formas de detecção de bots.
Para começar, inscreva-se para uma avaliação gratuita e obtenha sua chave de API e dataset_id para o domínio que deseja extrair. Assim que tiver esses dados, você estará pronto para começar.
Abaixo estão as etapas para recuperar dados novos de um domínio popular como a BBC News:
- Crie uma conta na Bright Data, caso ainda não tenha feito isso. Uma avaliação gratuita está disponível.
- Vá para a página Web Scrapers. Em Web Scrapers Library, explore os modelos de raspadores disponíveis.
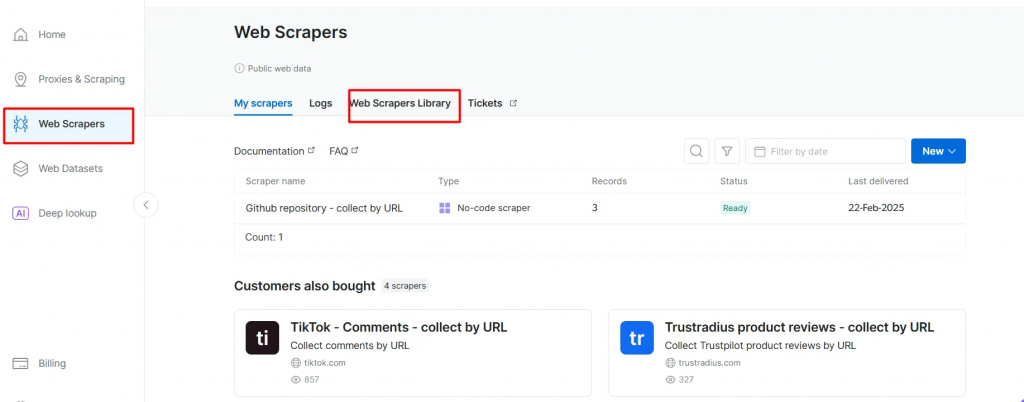
- Pesquise seu domínio de destino, como BBC News, e selecione-o.
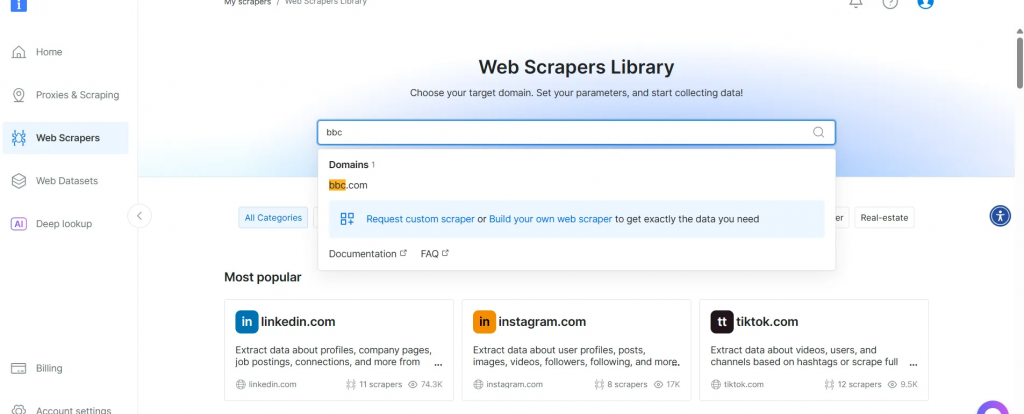
- Na lista de raspadores da BBC News, selecione BBC News – collect by URL. Esse coletor de dados permite que você recupere dados sem fazer login no domínio.
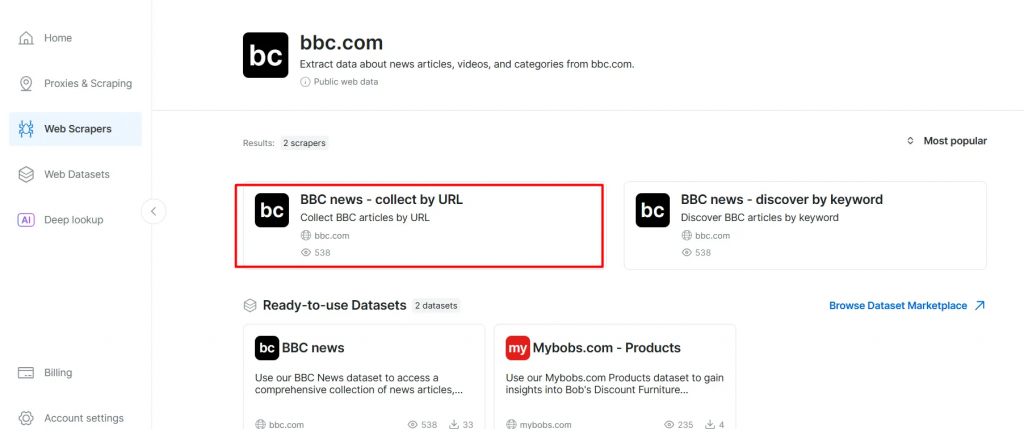
- Escolha a opção Scraper API. O No-Code Scraper ajuda a recuperar conjuntos de dados sem código.

- Clique em API Request Builder e, em seguida, copie sua
chave de API,URL do BBC Datasetedataset_id. Você os usará na próxima seção ao criar o fluxo de trabalho Agentic RAG.
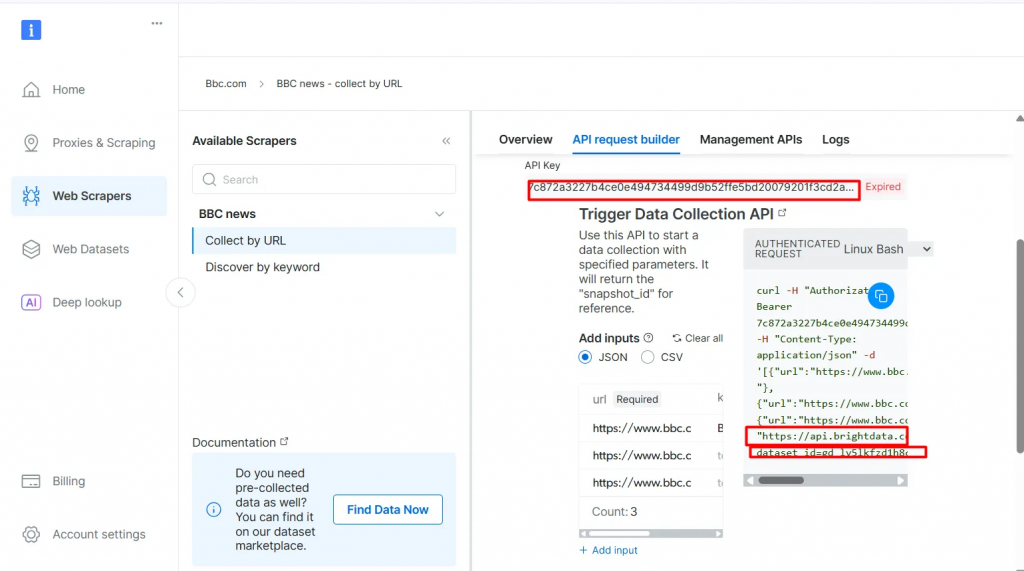
A API-key e o dataset_id são necessários para ativar os recursos agênticos em seu fluxo de trabalho. Eles permitem que você incorpore dados ao vivo em seu banco de dados de vetores e ofereça suporte a consultas em tempo real, mesmo quando a consulta de pesquisa não corresponde diretamente ao conteúdo pré-indexado.
Pré-requisitos
Antes de começar, verifique se você tem o seguinte:
- Uma conta da Bright Data
- Uma chave de API da OpenAI Inscreva-se na OpenAI para obter sua chave de API:
- Uma chave de API do Pinecone Consulte a documentação do Pinecone e siga as instruções na seção Obter uma chave de API.
- Um conhecimento básico de Python Você pode instalar o Python no site oficial
- Conhecimento básico dos conceitos de RAG e agente
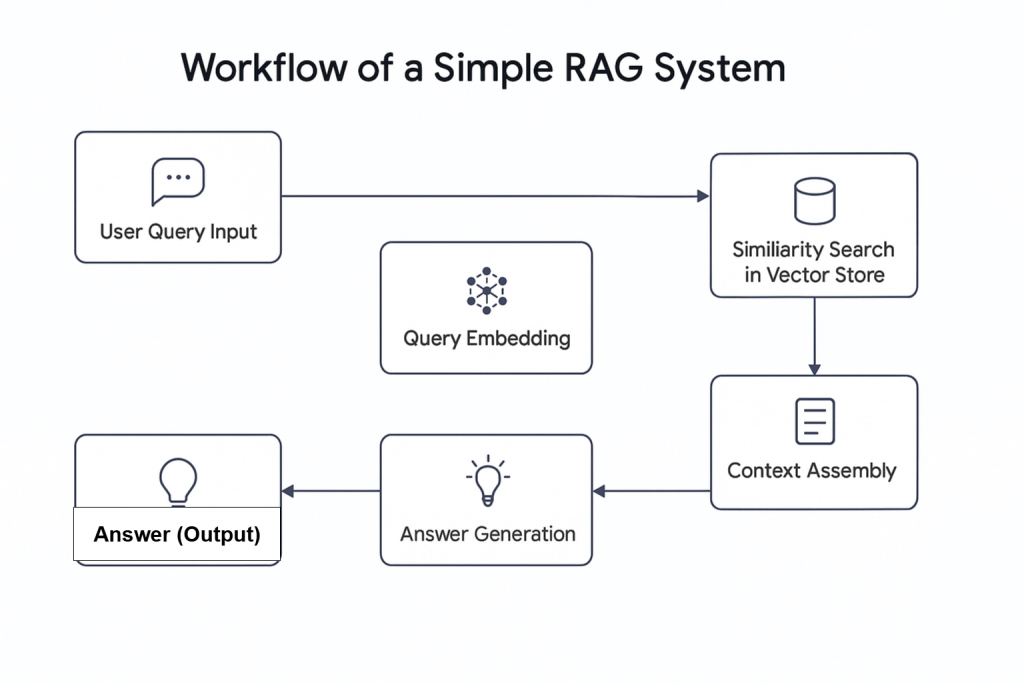
Estrutura do RAG autêntico
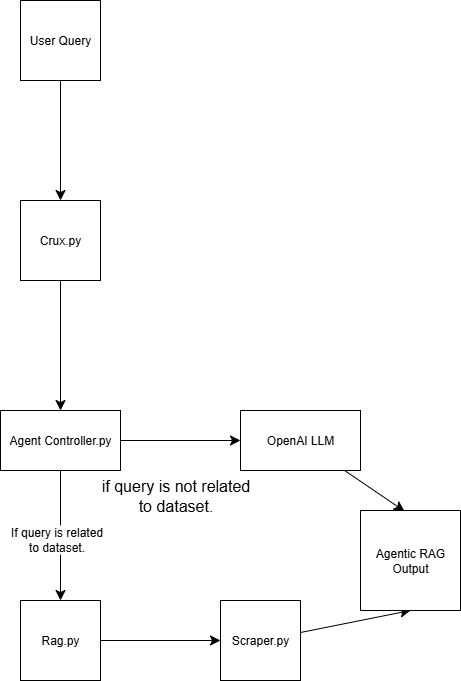
Esse sistema Agentic RAG foi criado usando quatro scripts:
scraper.py Recupera dados da Web por meio do Bright Data
rag.py Incorpora dados no banco de dados vetorial (Pinecone) Observação: Um banco de dados vetorial (incorporação numérica) é usado porque armazena dados não estruturados normalmente gerados por um modelo de aprendizado de máquina. Esse formato é ideal para pesquisa de similaridade em tarefas de recuperação.
agent_controller.py Contém a lógica de controle. Determina se deve usar dados pré-processados do banco de dados de vetores ou confiar no conhecimento geral do GPT, dependendo da natureza da consulta
crux.py Atua como o núcleo do sistema Agentic RAG. Ele armazena as chaves da API e inicializa o fluxo de trabalho.
Sua estrutura de trapo autêntico terá a seguinte aparência no final da demonstração:
Criação de RAG autêntico com dados brilhantes
Etapa 1: Configurar o projeto
1.1 Crie um novo diretório de projeto
Crie uma pasta para seu projeto e navegue até ela:
mkdir agentic-rag
cd agentic-rag
1.2 Abra o projeto no Visual Studio Code
Inicie o Visual Studio Code e abra o diretório recém-criado:
.../Desktop/agentic-rag> code .
1.3 Configurar e ativar um ambiente virtual
Para configurar um ambiente virtual, execute:
python -m venv venv
Como alternativa, no Visual Studio Code, siga os prompts no guia de ambientes Python para criar um ambiente virtual.
Para ativar o ambiente:
- No Windows:
.venv\\Scripts\\\activate - No macOS ou Linux:
source venv/bin/activate
Etapa 2: Implementar o Bright Data Retriever
2.1 Instale a biblioteca de solicitações em seu arquivo scraper.py
pip install requests
2.2 Importe os seguintes módulos
import requests
import json
import time
2.3 Configure suas credenciais
Use a chave da API da Bright Data, o URL do conjunto de dados e o dataset_id que você copiou anteriormente.
def trigger_bbc_news_articles_scraping(api_key, urls):
# Endpoint to trigger the Web Scraper API task
url = "<https://api.brightdata.com/datasets/v3/trigger>"
params = {
"dataset_id": "gd_ly5lkfzd1h8c85feyh", # ID of the BBC web scraper
"include_errors": "true",
}
# Convert the input data in the desired format to call the API
data = [{"url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
2.4 Configurar a lógica de resposta
Preencha sua solicitação com os URLs das páginas que você deseja extrair. Nesse caso, concentre-se em artigos relacionados a esportes.
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Request successful! Response: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"<https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json>"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
# Write the snapshot to an output json file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
return
elif response.status_code == 202:
print(F"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "BRIGHT DATA KEY" # Replace it with your Bright Data's Web Scraper API key
# URLs of BBC articles to retrieve data from
urls = [
"<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"<https://www.bbc.com/sport/formula1/articles/cgenqvv9309o>",
"<https://www.bbc.com/sport/formula1/articles/c78jng0q2dxo>",
"<https://www.bbc.com/sport/formula1/articles/cdrgdm4ye53o>",
"<https://www.bbc.com/sport/formula1/articles/czed4jk7eeeo>",
"<https://www.bbc.com/sport/football/articles/c807p94r41do>",
"<https://www.bbc.com/sport/football/articles/crgglxwge10o>",
"<https://www.bbc.com/sport/tennis/articles/cy700xne614o>",
"<https://www.bbc.com/sport/tennis/articles/c787dk9923ro>",
"<https://www.bbc.com/sport/golf/articles/ce3vjjq4dqzo>"
]
snapshot_id = trigger_bbc_news_articles_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "news-data.json")
2.5 Executar o código
Depois de executar o script, um arquivo chamado news-data.json aparecerá na pasta do projeto. Ele contém os dados do artigo extraído no formato JSON estruturado.
Aqui está um exemplo do conteúdo dentro do arquivo JSON:
[
{
"id": "c9dj0elnexyo",
"url": "<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"author": "BBC",
"headline": "Max Verstappen: Red Bull adviser Helmut Marko has 'great concern' about world champion's future with team",
"topics": [
"Formula 1"
],
"publication_date": "2026-04-14T13:42:08.154Z",
"content": "Saudi Arabian Grand PrixVenue: Jeddah Dates: 18-20 April Race start: 18:00 BST on SundayCoverage: Live radio commentary of practice, qualifying and race online and BBC 5 Sports Extra; live text updates on the BBC Sport website and app; Red Bull motorsport adviser Helmut Marko says he has \\"great concern\\" about Max Verstappen's future with the team in the context of their current struggles.AdvertisementThe four-time champion finished sixth in the Bahrain Grand Prix on Sunday, while Oscar Piastri scored McLaren's third win in four races so far this year.Dutchman Verstappen is third in the drivers' championship, eight points behind leader Lando Norris of McLaren.Marko told Sky Germany: \\"The concern is great. Improvements have to come in the near future so that he has a car with which he can win again.\\"We have to create a basis with a car so that he can fight for the world championship.\\"Verstappen has a contract with Red Bull until 2028. But Marko told BBC Sport this month that it contains a performance clause that could allow him to leave the team.; The wording of this clause is not known publicly but it effectively says that Red Bull have to provide Verstappen with a winning car.Verstappen won the Japanese Grand Prix a week before Bahrain but that victory was founded on a pole position lap that many F1 observers regarded as one of the greatest of all time.Because overtaking was next to impossible at Suzuka, Verstappen was able to hold back the McLarens of Norris and Piastri and take his first win of the year.Verstappen has qualified third, fourth and seventh for the other three races in Australia, China and Bahrain.The Red Bull is on average over all qualifying sessions this year the second fastest car but 0.214 seconds a lap slower than the McLaren.Verstappen has complained all year about balance problems with the Red Bull, which is unpredictable on corner entry and has mid-corner understeer.Red Bull team principal Christian Horner admitted after the race in Bahrain that the car's balance problems were fundamentally similar to the ones that made the second half of last year a struggle for Verstappen.He won just twice in the final 13 races of last season, but managed to win his fourth world title because of the huge lead he built up when Red Bull were in dominant form in the first five races of the season.Horner also said the team were having difficulties with correlation between their wind tunnel and on-track performance. Essentially, the car performs differently on track than the team's simulation tools say it should.; Verstappen had a difficult race in Bahrain including delays at both pit stops, one with the pit-lane traffic light system and one with fitting a front wheel.At one stage he was running last, and he managed to snatch sixth place from Alpine's Pierre Gasly only on the last lap.Verstappen said that the hot weather and rough track surface had accentuated Red Bull's problems.He said: \\"Here you just get punished a bit harder when you have big balance issues because the Tarmac is so aggressive.\\"The wind is also quite high and the track has quite low grip, so everything is highlighted more.\\"Just the whole weekend struggling a bit with brake feeling and stopping power, and besides that also very poor grip. We tried a lot on the set-up and basically all of it didn't work, didn't give us a clear direction to work in.\\"Verstappen has said this year that he is \\"relaxed\\" about his future.Any decision about moving teams for 2026 is complicated by the fact that F1 is introducing new chassis and engine rules that amount to the biggest regulation change in the sport's history, and it is impossible to know which team will be in the best shape.But it is widely accepted in the paddock that Mercedes are looking the best in terms of engine performance for 2026.Mercedes F1 boss Toto Wolff has made no secret of his desire to sign Verstappen.The two parties had talks last season but have yet to have any discussions this season about the future.",
"videos": [],
"images": [
{
"image_url": "<https://ichef.bbci.co.uk/ace/branded_sport/1200/cpsprodpb/bfc4/live/d3cc7850-1931-11f0-869a-33b652e8958c.jpg>",
"image_description": "Main image"
},
Agora que você tem os dados, a próxima etapa é incorporá-los.
Etapa 3: Configurar Embeddings e Vector Store
3.1 Instale as bibliotecas necessárias em seu arquivo rag.py
pip install openai pinecone pandas
3.2 Importar as bibliotecas necessárias
import json
import time
import re
import openai
import pandas as pd
from pinecone import Pinecone, ServerlessSpec
3.3 Configure sua chave OpenAI
Use o OpenAI para gerar embeddings a partir do campo text_for_embedding.
# Configure your OpenAI API key here or pass to functions
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI API key
3.4 Configure sua chave de API Pinecone e as configurações de índice
Configure o ambiente do Pinecone e defina sua configuração de índice.
pinecone_api_key = "PINECONE_API_KEY" # Replace with your Pinecone API key
index_name = "news-articles"
dimension = 1536 # OpenAI embedding dimension for text-embedding-ada-002 (adjust if needed)
namespace = "default"
3.5 Inicializar o cliente e o índice do Pinecone
Certifique-se de que o cliente e o índice sejam inicializados corretamente para armazenamento e recuperação de dados.
# Initialize Pinecone client and index
pc = Pinecone(api_key=pinecone_api_key)
# Check if index exists
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=dimension,
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
while not pc.describe_index(index_name).status["ready"]:
time.sleep(1)
pinecone_index = pc.Index(index_name)
print(pinecone_index)
3.6 Limpar, carregar e pré-processar dados
# Text cleaning helper
def clean_text(text):
text = re.sub(r"\\s+", " ", text)
return text.strip()
# Load and preprocess `news-data.json`
def load_and_prepare_data(json_path="news-data.json"):
with open(json_path, "r", encoding="utf-8") as f:
news_data = json.load(f)
df = pd.DataFrame(news_data)
df["text_for_embedding"] = df["headline"].map(clean_text) + ". " + df["content"].map(clean_text)
df["id"] = df["id"].astype(str)
return df
Observação: Você pode executar novamente o
scraper.pypara garantir que seus dados estejam atualizados.
3.7 Gerar embeddings usando o OpenAI
Crie embeddings a partir de seu texto pré-processado usando o modelo de embedding da OpenAI.
# New embedding generation via OpenAI API
def openai_generate_embeddings(texts, model="text-embedding-ada-002"):
openai.api_key = OPENAI_API_KEY
# OpenAI endpoint accepts a list of strings and returns list of embeddings
response = openai.embeddings.create(
input=texts,
model=model
)
embeddings = [datum.embedding for datum in response.data]
return embeddings
3.8 Atualizar o Pinecone com embeddings
Envie os embeddings gerados para o Pinecone para manter o banco de dados de vetores atualizado.
# Embed and upsert to Pinecone
def embed_and_upsert(json_path="news-data.json", namespace=namespace):
df = load_and_prepare_data(json_path)
texts = df["text_for_embedding"].tolist()
print(f"Generating embeddings for {len(texts)} texts using OpenAI...")
embeddings = openai_generate_embeddings(texts)
df["embedding"] = embeddings
records = []
for row in df.itertuples():
records.append((
row.id,
row.embedding,
{
"url": getattr(row, "url", ""), # safe get url if present
"text": row.text_for_embedding
}
))
pinecone_index.upsert(vectors=records, namespace=namespace)
print(f"Upserted {len(records)} records to Pinecone index '{index_name}'.")
Observação: Você só precisa executar essa etapa uma vez para preencher o banco de dados. Depois disso, você pode comentar essa parte do código.
3.9 Inicialização da função de pesquisa Pinecone
def pinecone_search(index, query, namespace=namespace, top_k=3, score_threshold=0.8, embedding_model=None):
# OpenAI embedding here
query_embedding = openai_generate_embeddings([query])[0]
results = index.query(
vector=query_embedding,
top_k=top_k,
namespace=namespace,
include_metadata=True,
)
filtered = []
for match in results.matches:
if match.score >= score_threshold:
filtered.append({
"score": match.score,
"url": match.metadata.get("url", ""),
"text": match.metadata.get("text", ""),
})
return filtered
Observação:
O limite de pontuação define a pontuação mínima de similaridade para que um resultado seja considerado relevante. Você pode ajustar esse valor de acordo com suas necessidades. Quanto maior a pontuação, mais preciso será o resultado.
3.10 Gerar respostas usando o OpenAI
Use o OpenAI para gerar respostas a partir do contexto recuperado via Pinecone.
# OpenAI answer generation
def openai_generate_answer(openai_api_key, query, context=None):
import openai
openai.api_key = openai_api_key
prompt_context = ""
if context:
prompt_context = "\\n\\nContext:\\n" + "\\n\\n".join(context)
prompt = f"Answer the following question: {query}" + prompt_context
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
max_tokens=256,
temperature=0.7,
)
answer = response.choices[0].message.content.strip()
return answer
3.11 (Opcional) Execute um teste simples para consultar e imprimir resultados
Inclua código amigável à CLI que permita executar um teste básico. O teste ajudará a verificar se a sua implementação está funcionando e mostrará uma visualização dos dados armazenados no banco de dados.
def search_news_and_answer(openai_api_key, query):
results = pinecone_search(pinecone_index, query)
if results:
print(f"Found {len(results)} relevant documents.")
print("Top documents:")
for doc in results:
print(f"Score: {doc['score']:.4f}")
print(f"URL: {doc['url']}")
print(f"Text (excerpt): {doc['text'][:250]}...\\n")
answer = openai_generate_answer(openai_api_key, query, [r["text"] for r in results])
print("\\nGenerated answer:\\n", answer)
if __name__ == "__main__":
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI key here or pass via arguments/env var
test_query = "What is wrong with Man City?"
search_news_and_answer(OPENAI_API_KEY, test_query)
Dica: Você pode controlar a quantidade de texto exibida cortando o resultado, por exemplo:
[:250].
Agora seus dados estão armazenados no banco de dados vetorial. Isso significa que você tem duas opções de consulta:
- Recuperar do banco de dados
- Usar uma resposta genérica gerada pela OpenAI
Etapa 4: Criar o controlador de agente
4.1 Em agent_controller.py
Importe a funcionalidade necessária do rag.py.
from rag import openai_generate_answer, pinecone_search
4.2 Implementar a recuperação do Pinecone
Adicionar lógica para recuperar dados relevantes do armazenamento de vetores Pinecone.
def agent_controller_decide_and_act(
pinecone_api_key,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
print(f"Agent received query: {query}")
try:
print("Trying Pinecone retrieval...")
results = pinecone_search(pinecone_index, query, namespace=namespace)
if results:
print(f"Found {len(results)} matching documents in Pinecone.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
return answer
else:
print("No good matches found in Pinecone. Falling back to OpenAI generator.")
except Exception as e:
print(f"Pinecone retrieval failed: {e}")
4.3 Implementar resposta de fallback da OpenAI
Crie uma lógica para gerar uma resposta usando o OpenAI quando nenhum contexto relevante for recuperado.
try:
print("Generating answer from OpenAI without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
return answer
except Exception as e:
print(f"OpenAI generation failed: {e}")
return "Sorry, I am currently unable to answer your query."
Etapa 5: Juntar tudo
5.1 No crux.py
Importe todas as funções necessárias do agent_controller.py.
from rag import pinecone_index # Import Pinecone index & embedding model
from rag import openai_generate_answer, pinecone_search # Import helper functions if needed
from agent_controller import agent_controller_decide_and_act # Your orchestration function
5.2 Forneça suas chaves de API
Certifique-se de que suas chaves de API OpenAI e Pinecone estejam definidas corretamente.
# Your actual API keys here - replace with your real keys
PINECONE_API_KEY = "PINECONE_API_KEY"
OPENAI_API_KEY = "OPENAI_API_KEY"
5.3 Digite seu prompt na função main()
Defina a entrada de prompt dentro da função main().
def main():
query = "What is the problem with Man City?"
answer = agent_controller_decide_and_act(
pinecone_api_key=PINECONE_API_KEY,
openai_api_key=OPENAI_API_KEY,
pinecone_index=pinecone_index,
query=query,
namespace="default"
)
print("\\nAgent's answer:\\n", answer)
if __name__ == "__main__":
main()
5.4 Chamar o RAG autêntico
Execute a lógica Agentic RAG. Você verá como ela processa uma consulta, verificando primeiro sua relevância antes de consultar o banco de dados de vetores.

Agent received query: What exactly is the problem with Man City Women Team?
Trying Pinecone retrieval...
Found 1 matching documents in Pinecone.
Agent's answer:
The problems with the Man City Women Team this season include a significant injury crisis, managerial upheaval, and poor performances in key games. Key players such as Vivianne Miedema, Khadija Shaw, Lauren Hemp, and Alex Greenwood have been sidelined due to injuries, which has severely impacted the team's performance and highlighted a lack of squad depth. Interim manager Nick Cushing suggests that the number of injuries is not solely down to bad luck or bad practice and calls for an examination of the situation.
Tente testá-lo com uma consulta que não corresponda ao seu banco de dados, por exemplo:
def main():
query = "Why Sleep?"
O agente determina que não foram encontradas boas correspondências no Pinecone e volta a gerar uma resposta genérica usando o OpenAI.

Agent received query: Why Sleep?
Trying Pinecone retrieval...
No good matches found in Pinecone. Falling back to OpenAI generator.
as a car crash), or it can harm you over time.
For example, ongoing sleep deficiency can raise your risk for some chronic health problems. It also can affect how well you think, react, work, learn, and get along with as a car crash), or it can harm you over time.
Dica: você pode imprimir a pontuação de relevância (score_threshold) de cada prompt para entender o nível de confiança do agente.
É isso aí! Você criou seu RAG Agêntico com sucesso.
Etapa 6 (opcional): loop de feedback e otimização
Você pode aprimorar seu sistema implementando um loop de feedback para melhorar o treinamento e a indexação ao longo do tempo.
6.1 Adicionar uma função de feedback
Em agent_controller.py, crie uma função que peça feedback ao usuário depois que uma resposta for exibida. Você pode chamar essa função no final do main runner em crux.py.
def collect_user_feedback():
feedback = input("Was the answer helpful? (yes/no): ").strip().lower()
comments = input("Any comments or corrections? (optional): ").strip()
return feedback, comments
6.2 Implementar lógica de feedback
Crie uma nova função no agent_controller.py que reinvoca o processo de recuperação se o feedback for negativo. Em seguida, chame essa função no crux.py:
def agent_controller_handle_feedback(
feedback,
comments,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
if feedback == "no":
print("Feedback: answer not helpful. Retrying with relaxed retrieval parameters...")
# Relaxed retrieval - increase number of docs and lower score threshold
results = pinecone_search(
pinecone_index,
query,
namespace=namespace,
top_k=5,
score_threshold=0.3
)
if results:
print(f"Found {len(results)} documents after retry.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
print("\\nNew answer based on feedback:\\n", answer)
return answer
else:
print("No documents found even after retry. Generating answer without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
print("\\nAnswer generated without retrieval:\\n", answer)
return answer
else:
print("Thank you for your positive feedback!")
return None
Conclusão e próximas etapas
Neste artigo, você criou um sistema Agentic RAG autônomo que combina Bright Data para raspagem da Web, Pinecone como um banco de dados vetorial e OpenAI para geração de texto. Esse sistema fornece uma base que pode ser ampliada para oferecer suporte a uma variedade de recursos adicionais, como:
- Integração de bancos de dados vetoriais com bancos de dados relacionais ou não relacionais
- Criação de uma interface de usuário usando o Streamlit
- Automatizar a recuperação de dados da Web para manter os dados de treinamento atualizados
- Aprimoramento da lógica de recuperação e do raciocínio do agente
Conforme demonstrado, a qualidade do resultado do sistema Agentic RAG depende muito da qualidade dos dados de entrada. A Bright Data desempenhou um papel fundamental ao permitir dados da Web confiáveis e atualizados, o que é essencial para a recuperação e a geração eficazes.
Considere a possibilidade de explorar outros aprimoramentos desse fluxo de trabalho e usar o Bright Data em seus projetos futuros para manter dados de entrada consistentes e de alta qualidade.





