

Neste guia, você aprenderá:
- Tudo o que você precisa saber para começar a usar o Scraping de dados do Baidu.
- As abordagens mais populares e eficazes para fazer scraping do Baidu.
- Como criar um Scraper personalizado do Baidu a partir do zero em Python.
- Como recuperar resultados de mecanismos de pesquisa usando a API SERP da Bright Data.
- Como dar aos seus agentes de IA acesso aos dados de pesquisa do Baidu por meio do Web MCP.
Vamos mergulhar de cabeça!
Familiarização com o Baidu SERP
Antes de tomar qualquer medida, dedique algum tempo a entender como a SERP (Search Engine Results Page, página de resultados do mecanismo de busca) do Baidu está estruturada, quais dados ela contém, como acessá-la e assim por diante.
URLs da SERP do Baidu e sistema de detecção de bots
Abra o Baidu em seu navegador e comece a fazer algumas pesquisas. Por exemplo, pesquise “bright data”. Você deve obter um URL como este:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=bright%20data&fenlei=256&oq=ai%2520model&rsv_pq=970a74b9001542b3&rsv_t=7f84gPOmZQIjrqRcld6qZUI%2FiqXxDExphd0Tz5ialqM87sc5Falk%2B%2F3hxDs&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=12&rsv_sug1=1&rsv_sug7=100&rsv_btype=t&inputT=1359&rsv_sug4=1358Entre todos esses parâmetros de consulta, os mais importantes são:
- URL de base:
https://www.baidu.com/s. - Parâmetro de consulta de pesquisa:
wd.
Em outras palavras, você pode obter os mesmos resultados com um URL mais curto:
https://www.baidu.com/s?wd=bright%20dataAlém disso, o Baidu estrutura seus URLs para paginação por meio do parâmetro de consulta pn. Em detalhes, a segunda página adiciona &pn=10 e, em seguida, cada página subsequente aumenta esse valor em 10. Por exemplo, se você quiser extrair 3 páginas com a palavra-chave “dados brilhantes”, os URLs de SERP seriam
https://www.baidu.com/s?wd=bright%20data -> página 1
https://www.baidu.com/s?wd=bright%20data&pn=10 -> página 2
https://www.baidu.com/s?wd=bright%20data&pn=20 -> página 3Agora, se você tentar acessar esse URL diretamente usando uma solicitação HTTP GET simples em um cliente HTTP como o Postman, provavelmente verá algo como isto:
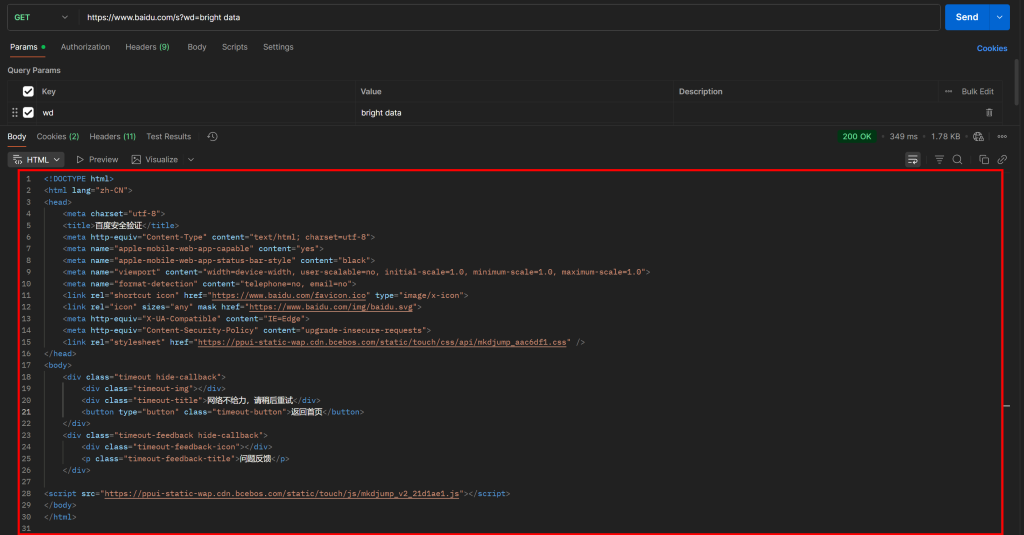
Como você pode ver, o Baidu retorna uma página com a mensagem “网络不给力,请稍后重试” (que significa “A rede não está funcionando bem, tente novamente mais tarde”, mas na verdade é uma página anti-bot).
Isso acontece mesmo se você incluir um cabeçalho User-Agent, que normalmente é essencial para tarefas de Scraping de dados. Em outras palavras, o Baidu detecta que sua solicitação é automatizada e a bloqueia, exigindo verificação humana adicional.
Isso mostra claramente que, para raspar o Baidu, você precisa de uma ferramenta de automação do navegador (como o Playwright ou o Puppeteer). Uma simples combinação de um cliente HTTP e um analisador de HTML não será suficiente, pois acionará consistentemente bloqueios anti-bot.
Dados disponíveis em uma SERP do Baidu
Agora, concentre-se no SERP do Baidu para “dados brilhantes” renderizados em seu navegador. Você deverá ver algo parecido com isto:
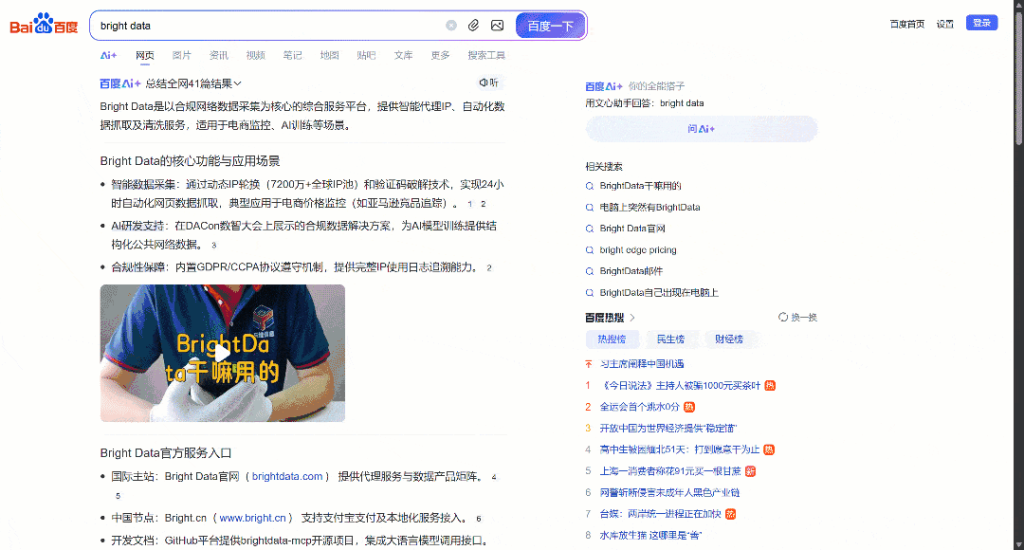
Cada página SERP do Baidu é dividida em duas colunas. A coluna da esquerda contém uma visão geral da IA (veja como extrair visões gerais da IA), seguida pelos resultados da pesquisa. Na parte inferior dessa coluna, há a seção “相关搜索” (“Pesquisas relacionadas”) e, abaixo dela, os elementos de navegação de paginação.
A coluna da direita contém a seção “百度热搜” (“Baidu Hot Searches”), que mostra os tópicos mais populares ou de tendência no Baidu.(Observação: esses resultados de tendências não estão necessariamente relacionados aos seus termos de pesquisa).
Isso abrange todos os principais dados que você pode extrair de uma SERP do Baidu. Neste tutorial, vamos nos concentrar apenas nos resultados da pesquisa, que geralmente são as informações mais importantes!
Principais abordagens para a coleta de dados do Baidu
Há várias maneiras de obter dados de resultados de pesquisa do Baidu. Compare as principais na tabela de resumo abaixo:
| Abordagem | Integração Complexidade | Requisitos | Preço | Risco de blocos | Escalabilidade |
|---|---|---|---|---|---|
| Criar um Scraper personalizado | Médio/alto | Habilidades de programação em Python + habilidades de automação de navegador | Gratuito (pode exigir navegadores anti-bot para evitar bloqueios) | Possível | Limitado |
| Usar a API SERP da Bright Data | Baixo | Qualquer cliente HTTP | Pago | Nenhum | Ilimitado |
| Integrar o servidor Web MCP | Baixo | Estrutura ou plataforma de agente de IA com suporte para MCP | Nível gratuito disponível, depois pago | Nenhum | Ilimitado |
Você aprenderá a implementar cada abordagem ao longo do tutorial!
Observação 1: Independentemente do método que você escolher, a consulta de pesquisa de destino usada neste guia será “dados brilhantes”. Isso significa que você verá como recuperar os resultados de pesquisa do Baidu especificamente para essa consulta.
Observação 2: presumimos que você já tenha o Python instalado localmente e esteja familiarizado com scripts Python para a Web.
Abordagem nº 1: criar um Scraper personalizado
Use uma estrutura de automação de navegador ou um cliente HTTP combinado com um analisador de HTML para criar um Scraper do Baidu do zero.
Prós:
- Controle total sobre a lógica de análise de dados, com a possibilidade de extrair exatamente o que você precisa.
- Flexível e personalizável de acordo com suas necessidades.
Contras:
- Requer esforço de configuração, codificação e manutenção.
- Pode enfrentar bloqueios de IP, CAPTCHAs, limites de taxa e outros desafios de Scraping de dados ao executá-lo em escala.
Abordagem nº 2: usar a API SERP da Bright Data
Aproveite a API SERP da Bright Data, uma solução premium que permite consultar o Baidu (e outros mecanismos de pesquisa) por meio de um ponto de extremidade HTTP fácil de chamar. Ela cuida de todas as medidas anti-bot e do dimensionamento para você. Esses e muitos outros recursos fazem dela uma das melhores APIs SERP e de pesquisa do mercado.
Prós:
- Altamente escalável e confiável, com o apoio de uma rede Proxy de mais de 150 milhões de IPs.
- Sem proibições de IP ou problemas de CAPTCHA.
- Funciona com qualquer cliente HTTP (incluindo ferramentas visuais como Postman ou Insomnia).
Contras:
- Serviço pago.
Abordagem nº 3: integrar o servidor Web MCP
Permita que seu agente de IA acesse os resultados de pesquisa do Baidu gratuitamente por meio do Web MCP da Bright Data, que se conecta à API SERP da Bright Data e ao Web Unlocker nos bastidores.
Prós:
- Integração em fluxos de trabalho e agentes de IA.
- Nível gratuito disponível.
- Não é necessária nenhuma lógica de análise de dados (a IA se encarregará disso).
Contras:
- Controle limitado sobre o comportamento dos LLMs.
Abordagem nº 1: criar um Scraper personalizado do Baidu em Python usando o Playwright
Siga as etapas abaixo para criar um script personalizado de scraping de dados do Baidu em Python.
Conforme mencionado anteriormente, a raspagem do Baidu requer automação do navegador porque as solicitações HTTP simples serão bloqueadas. Nesta seção do tutorial, usaremos o Playwright, uma das melhores bibliotecas para automação de navegador em Python.
Etapa 1: Configurar seu projeto de raspagem
Comece abrindo seu terminal e criando uma nova pasta para seu projeto Scraper do Baidu:
mkdir baidu-scraperA pasta baidu-scraper/ conterá todos os arquivos do seu projeto de raspagem.
Em seguida, navegue até o diretório do projeto e crie um ambiente virtual Python dentro dele:
cd baidu-scraper
python -m venv .venvAgora, abra a pasta do projeto em seu IDE Python preferido. Recomendamos o Visual Studio Code com a extensão Python ou o PyCharm Community Edition.
Adicione um novo arquivo chamado scraper.py à raiz do diretório do projeto. A estrutura do seu projeto deve ser semelhante a esta:
baidu-scraper/
├── .venv/
└── scraper.pyEm seguida, ative o ambiente virtual no terminal. No Linux ou macOS, execute:
source .venv/bin/activateDe forma equivalente, no Windows, execute:
.venv/Scripts/activateCom seu ambiente virtual ativado, instale o Playwright usando o pip por meio do pacote playwright:
pip install playwrightEm seguida, instale as dependências necessárias do Playwright (por exemplo, os binários do navegador):
python -m playwright installPronto! Seu ambiente Python agora está pronto para começar a criar o Scraper da Web do Baidu.
Etapa 2: inicializar o script do Playwright
Em scraper.py, importe o Playwright e use sua API síncrona para iniciar uma instância controlada do navegador Chromium:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# Inicialize uma instância do Chromium no modo sem cabeça
browser = p.chromium.launch(headless=True) # defina headless=False para ver o navegador para depuração
page = browser.new_page()
# Lógica de raspagem...
# Feche o navegador e libere seus recursos
browser.close()O snippet acima forma a base de seu Scraper do Baidu.
O parâmetro headless=True diz ao Playwright para iniciar o Chromium sem uma GUI visível. Com base em testes, essa configuração não aciona a detecção de bots do Baidu. Portanto, ela funciona bem para raspagem. No entanto, ao desenvolver ou depurar seu código, talvez você prefira definir headless=False para poder observar o que está acontecendo no navegador em tempo real.
Ótimo! Agora, conecte-se ao Baidu SERP e comece a recuperar os resultados da pesquisa.
Etapa 3: visitar a SERP de destino
Conforme analisado anteriormente, a criação de um URL do Baidu SERP é simples. Em vez de instruir o Playwright a simular as interações do usuário (como digitar na caixa de pesquisa e enviá-la), é muito mais fácil criar o URL SERP programaticamente e dizer ao Playwright para navegar diretamente para ele.
Esta é a lógica para criar um URL SERP do Baidu para o termo de pesquisa “bright data”:
# O URL base da página de pesquisa do Baidu
base_url = "https://www.baidu.com/s"
# A palavra-chave/keyphrase da pesquisa
search_query = "bright data" (dados brilhantes)
params = {"wd": search_query}
# Crie o URL da SERP do Baidu
url = f"{base_url}?{urlencode(params)}"Não se esqueça de importar a função urlencode() da biblioteca padrão do Python:
from urllib.parse import urlencodeAgora, instrua o navegador controlado pelo Playwright a visitar o URL gerado por meio de goto():
page.goto(url)Se você executar o script no modo headful (com headless=False) no depurador, verá uma janela do Chromium carregar a página SERP do Baidu:
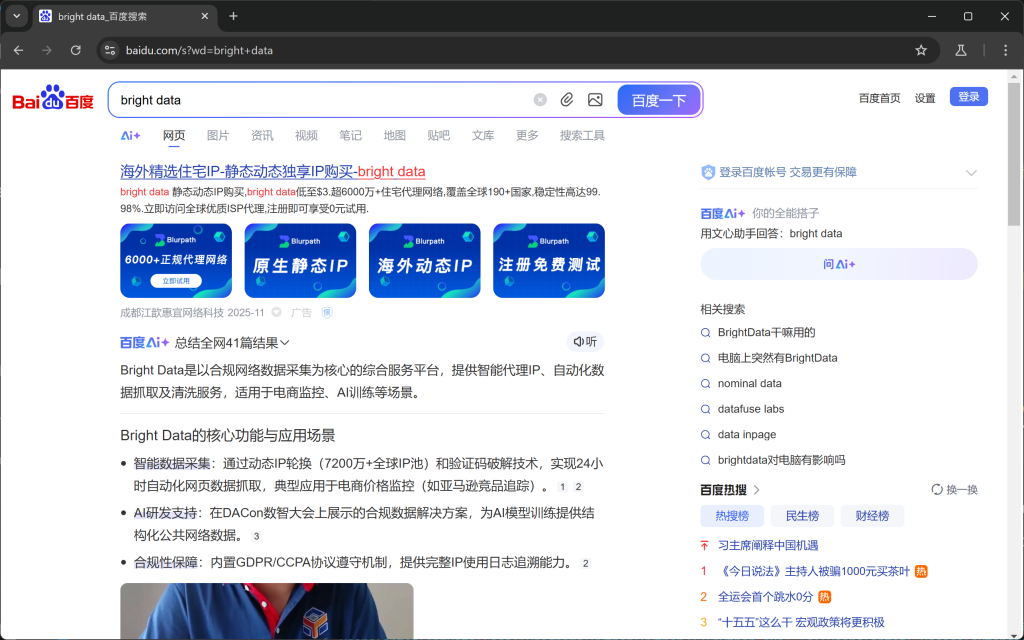
Incrível! Essa é exatamente a SERP que você coletará a seguir.
Etapa 4: Prepare-se para extrair todos os resultados da SERP
Antes de mergulhar na lógica da coleta de dados, você deve estudar a estrutura das SERPs do Baidu. Primeiro, como a página contém vários elementos de resultados de pesquisa, você precisará de uma lista para armazenar os dados extraídos. Portanto, comece inicializando uma lista vazia:
serp_results = []Em seguida, abra a SERP do Baidu de destino em uma janela anônima (para garantir uma sessão limpa) em seu navegador:
https://www.baidu.com/s?wd=bright%20dataClique com o botão direito do mouse em um dos elementos do resultado da pesquisa e escolha “Inspect” (Inspecionar) para abrir o DevTools do navegador:
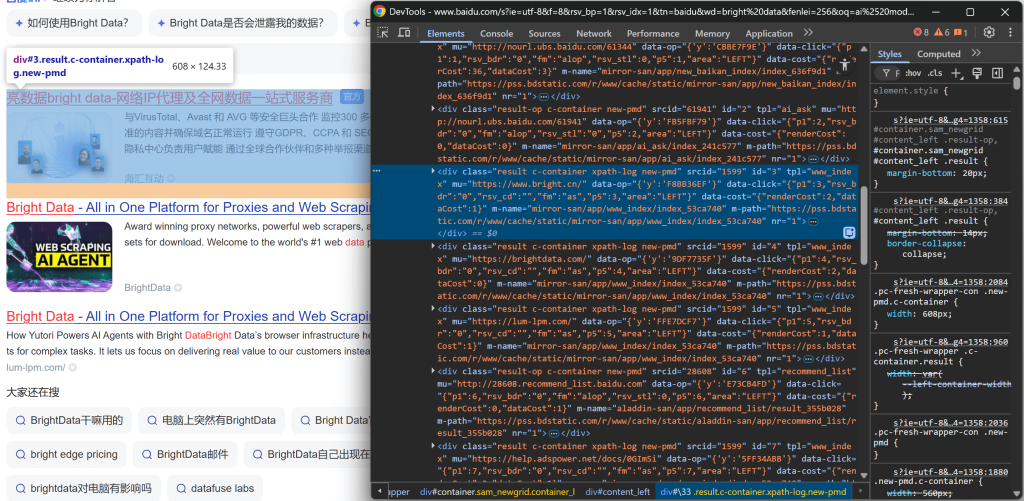
Observando a estrutura DOM, você notará que cada item do resultado da pesquisa tem a classe result. Isso significa que você pode selecionar todos os resultados da pesquisa na página usando o seletor CSS .result.
Aplique esse seletor em seu script do Playwright:
search_result_elements = page.locator(".result")Observação: se você não estiver familiarizado com essa sintaxe, leia nosso guia sobre Scraping de dados do Playwright.
Por fim, itere sobre cada elemento selecionado:
for search_result_element in search_result_elements.all():
# Lógica de análise de dados...Prepare-se para aplicar a lógica de análise de dados para extrair os resultados de pesquisa do Baidu e preencher a lista serp_results:
Perfeito! Agora você está perto de concluir seu fluxo de trabalho de raspagem do Baidu.
Etapa 5: Extrair dados de resultados de pesquisa
Inspecione a estrutura HTML de um elemento SERP na página de resultados do Baidu. Desta vez, concentre-se em seus elementos aninhados para identificar os dados que deseja extrair.
Comece explorando a seção de título:
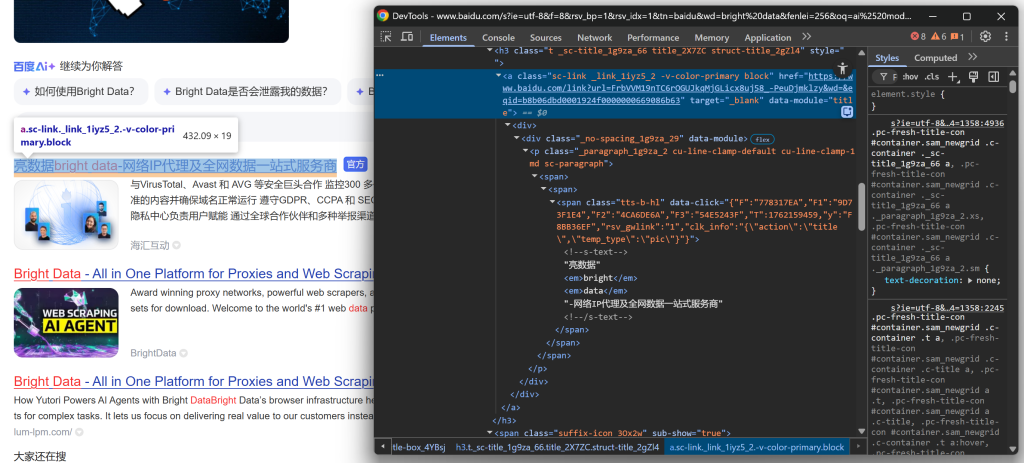
Continue observando que alguns resultados exibem um rótulo “官方” (“Oficial”):
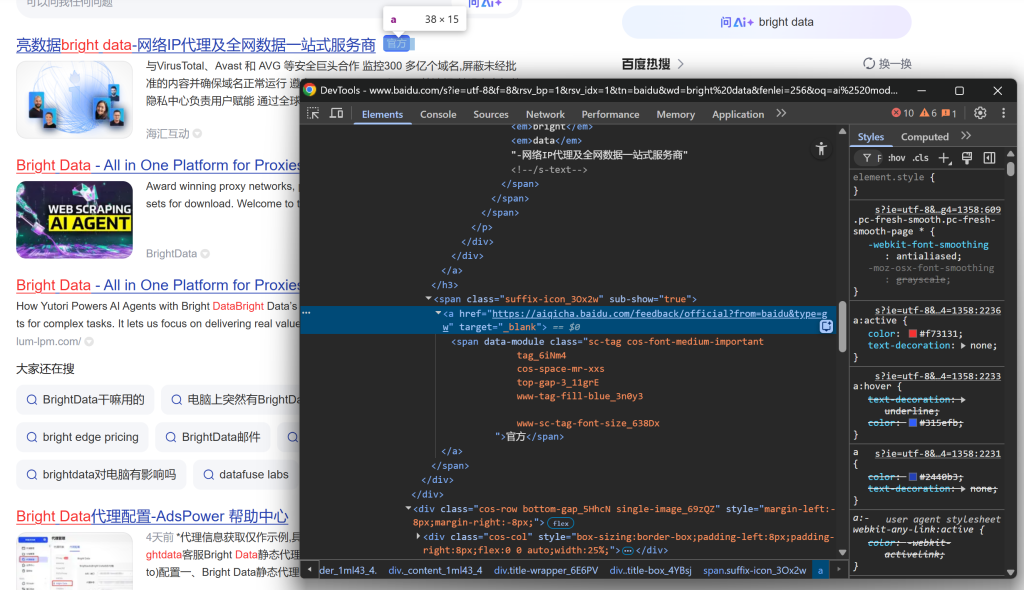
E, em seguida, concentre-se na imagem do resultado da SERP:
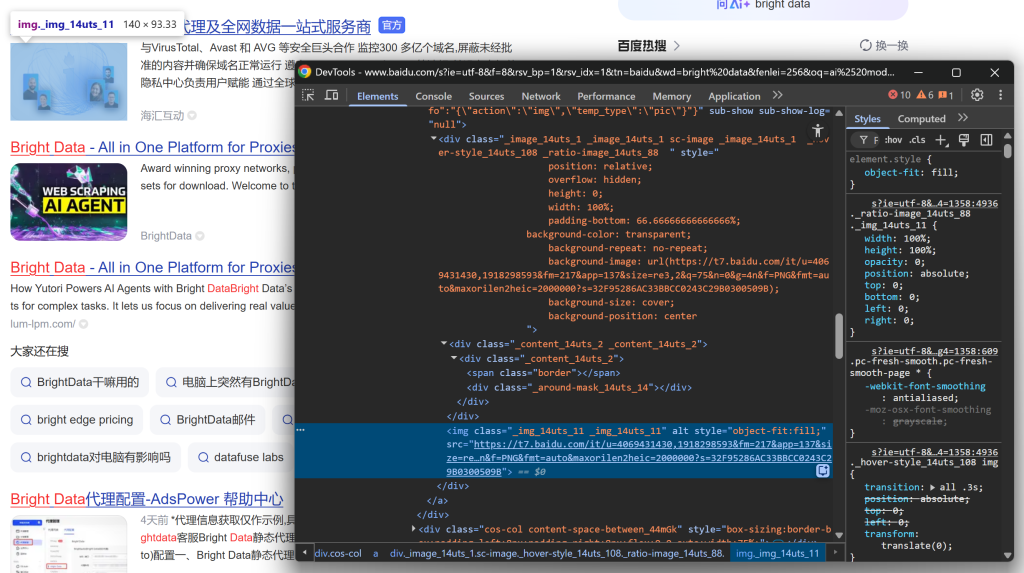
E conclua examinando a descrição/abstração:
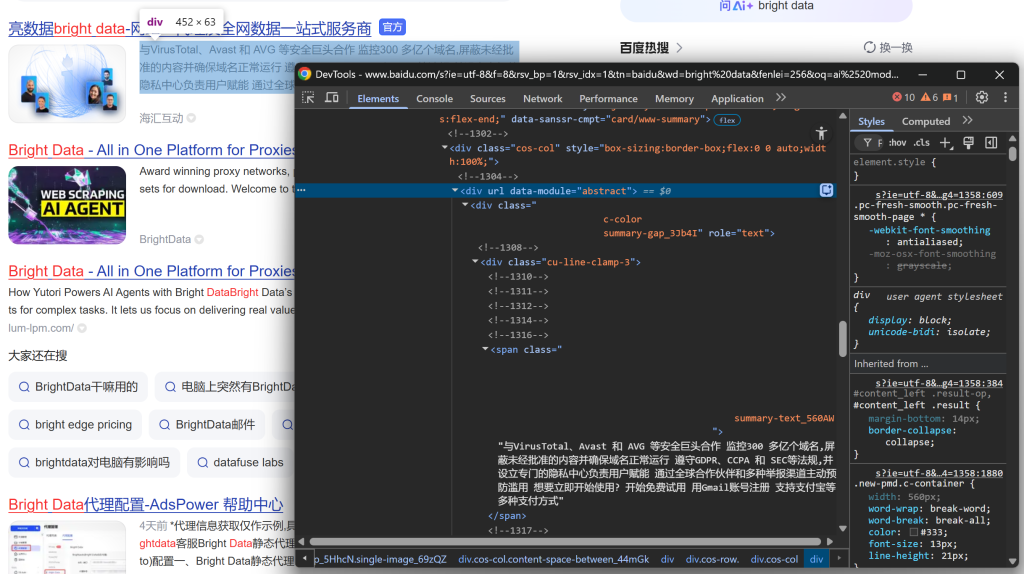
A partir desses elementos aninhados, você pode extrair os seguintes dados:
- URL do resultado a partir do atributo
hrefdo elemento.sc-link. - Título do resultado a partir do texto do elemento
.sc-link. - Descrição/abstração do resultado do texto
[data-module='abstract']. - Imagem do resultado do atributo
srcdoimgdentro de.sc-image. - Trecho doresultado do texto
.result__snippet. - Rótulo oficial, em um elemento
<a>cujohrefcomeça comhttps://aiqicha.baidu.com/feedback/official(se presente).
Use a API de localização do Playwright para selecionar elementos e extrair os dados desejados:
link_element = search_result_element.locator(".sc-link")
link = link_element.get_attribute("href")
title = link_element.inner_text()
description_element = search_result_element.locator("[data-module='abstract']")
description = description_element.inner_text() if description_element.count() > 0 else ""
image_element = search_result_element.locator(".sc-image img")
image = image_element.get_attribute("src") if image_element.count() > 0 else None
official_element = search_result_element.locator("a[href^='https://aiqicha.baidu.com/feedback/official']")
official = official_element.count() > 0Lembre-se de que nem todos os itens SERP são iguais. Para evitar erros, sempre verifique se o elemento existe (.count() > 0) antes de acessar seus atributos ou texto.
Excelente! Você acabou de definir a lógica de análise de dados SERP do Baidu.
Etapa 6: coletar os dados dos resultados de pesquisa raspados
Conclua o loop for criando um dicionário para cada resultado de pesquisa e anexando-o à lista serp_results:
serp_result = {
"title": title.strip(),
"href": link.strip(),
"description": description.strip(),
"image": image.strip() if image else "",
"official": official
}
serp_results.append(serp_result)Maravilhoso! Sua lógica de Scraping de dados do Baidu agora está completa. A etapa final é exportar os dados extraídos para uso posterior.
Etapa 7: Exportar os resultados de pesquisa extraídos para CSV
Nesta etapa, os resultados da pesquisa do Baidu estão armazenados em uma lista Python. Para que os dados possam ser usados por outras equipes ou ferramentas, exporte-os para um arquivo CSV usando a biblioteca csv integrada do Python:
with open("baidu_serp_results.csv", mode="w", newline="", encoding="utf-8") as csvfile:
# Ler dinamicamente os nomes dos campos do primeiro item
fieldnames = list(serp_results[0].keys())
# Inicializar o gravador de CSV
escritor = csv.DictWriter(csvfile, fieldnames=fieldnames)
# Escreva o cabeçalho e preencha o arquivo CSV de saída
escritor.writeheader()
writer.writerows(serp_results)Não se esqueça de importar o csv:
import csvDessa forma, seu Scraper do Baidu gerará um arquivo de saída chamado baidu_serp_results.csv, contendo todos os resultados extraídos no formato CSV. Missão cumprida
Etapa #8: Juntar tudo
O código final contido no Scraper.py é:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
from urllib.parse import urlencode
importar csv
# Onde armazenar os dados extraídos
serp_results = []
with sync_playwright() as p:
# Inicialize uma instância do Chromium no modo headless
browser = p.chromium.launch(headless=True) # Defina headless=False para ver o navegador para depuração
page = browser.new_page()
# O URL base da página de pesquisa do Baidu
base_url = "https://www.baidu.com/s"
# A palavra-chave/keyphrase da pesquisa
search_query = "bright data" (dados brilhantes)
params = {"wd": search_query}
# Crie o URL da SERP do Baidu
url = f"{base_url}?{urlencode(params)}"
# Visite a página de destino no navegador
page.goto(url)
# Selecionar todos os elementos do resultado da pesquisa
elementos_resultados_da_pesquisa = page.locator(".result")
for search_result_element in search_result_elements.all():
# Lógica de análise de dados
link_element = search_result_element.locator(".sc-link")
link = link_element.get_attribute("href")
title = link_element.inner_text()
description_element = search_result_element.locator("[data-module='abstract']")
description = description_element.inner_text() if description_element.count() > 0 else ""
image_element = search_result_element.locator(".sc-image img")
image = image_element.get_attribute("src") if image_element.count() > 0 else None
official_element = search_result_element.locator("a[href^='https://aiqicha.baidu.com/feedback/official']")
official = official_element.count() > 0
# Preencher um novo objeto de resultado de pesquisa com os dados extraídos
serp_result = {
"title": title.strip(),
"href": link.strip(),
"description": description.strip(),
"image": image.strip() if image else "",
"official": official
}
# Anexar o resultado da SERP do Baidu extraído à lista
serp_results.append(serp_result)
# Feche o navegador e libere seus recursos
browser.close()
with open("baidu_serp_results.csv", mode="w", newline="", encoding="utf-8") as csvfile:
# Ler dinamicamente os nomes dos campos do primeiro item
fieldnames = list(serp_results[0].keys())
# Inicializar o gravador de CSV
escritor = csv.DictWriter(csvfile, fieldnames=fieldnames)
# Escreva o cabeçalho e preencha o arquivo CSV de saída
escritor.writeheader()
writer.writerows(serp_results)Uau! Com apenas cerca de 70 linhas de código, você criou um script de raspagem de dados do Baidu.
Teste o script com:
python scraper.pyO resultado será um arquivo baidu_serp_results.csv na pasta do seu projeto. Abra-o para ver os dados estruturados extraídos dos resultados de pesquisa do Baidu:

Observação: para extrair resultados adicionais, repita o processo usando o parâmetro de consulta pn para lidar com a paginação.
E pronto! Você transformou com sucesso os resultados de pesquisa não estruturados do Baidu em um arquivo CSV estruturado.
[Extra] Use um serviço de navegador remoto para evitar bloqueios
O Scraper mostrado acima funciona bem para pequenas execuções, mas não será bem dimensionado. O Baidu começará a bloquear solicitações quando vir muito tráfego do mesmo IP, retornando páginas de erro ou desafios. A execução de muitas instâncias locais do Chromium também consome muitos recursos (muita RAM) e é difícil de coordenar.
Uma solução mais dimensionável e fácil de gerenciar é conectar sua instância do Playwright a uma solução remota de Navegador de scraping como serviço, como a API de navegador da Bright Data. Isso fornece rotação automática de Proxy, manipulação de CAPTCHA e desvio anti-bot, instâncias reais de navegador para evitar problemas de impressão digital e dimensionamento ilimitado.
Siga o guia de configuração da API do navegador da Bright Data e você terá uma string de conexão WSS semelhante a esta:
wss://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:9222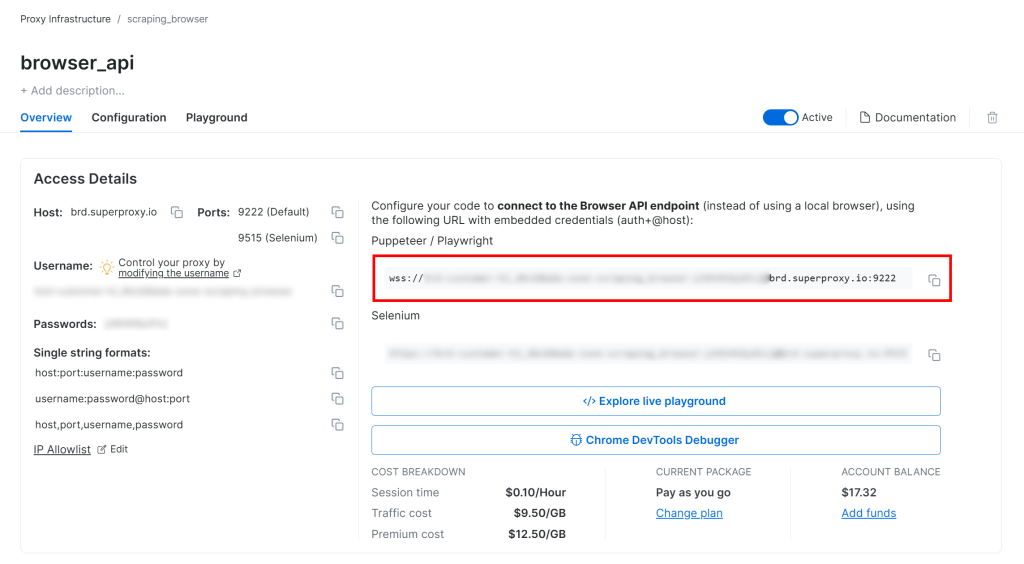
Use esse URL do WSS para conectar o Playwright às instâncias do navegador remoto por meio do CDP(Chrome DevTools Protocol):
wss_url = "wss://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:9222"
navegador = playwright.chromium.connect_over_cdp(wss_url)
page = browser.new_page()
# ...Agora, suas solicitações do Playwright ao Baidu serão roteadas pela infraestrutura remota da API do navegador da Bright Data, que é apoiada por uma rede proxy residencial de 150 milhões de IPs e instâncias reais do navegador. Isso garante um IP novo para cada sessão e uma impressão digital realista do navegador.
Abordagem nº 2: usar a API SERP da Bright Data
Neste capítulo, você verá como usar a API SERP Baidu tudo-em-um da Bright Data para recuperar resultados de pesquisa de forma programática.
Observação: para simplificar, presumimos que você já tenha um projeto Python com a biblioteca desolicitações instalada.
Etapa 1: Configure uma Zona da API SERP em sua conta Bright Data
Comece configurando o produto API SERP na Bright Data para raspar os resultados de pesquisa do Baidu. Primeiro, crie uma conta da Bright Data – ou faça login se já tiver uma.
Para uma configuração mais rápida, você pode consultar o guia oficial de “Início Rápido” da API SERP da Bright Data. Caso contrário, continue com as etapas abaixo.
Uma vez conectado, navegue até “Proxies & Scraping” em sua conta da Bright Data para acessar a página de produtos:
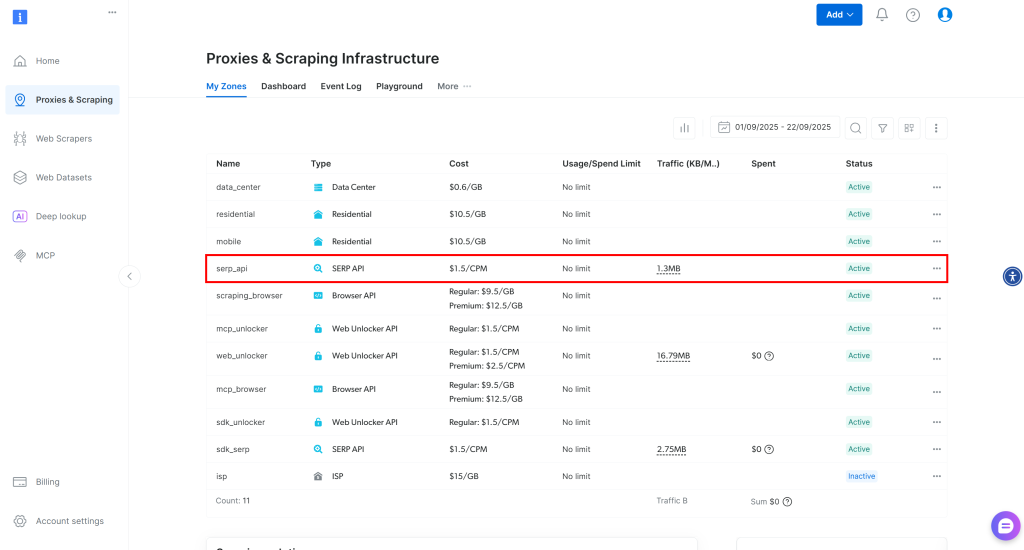
Dê uma olhada na tabela “My Zones” (Minhas zonas), que lista seus produtos Bright Data configurados. Se já existir uma Zona API SERP ativa, você está pronto para começar. Basta copiar o nome da Zona (por exemplo, serp_api), pois você precisará dele mais tarde.
Se não houver nenhuma zona da API SERP, role para baixo até a seção “Scraping Solutions” e clique em “Create Zona” (Criar zona) no cartão “API SERP”:
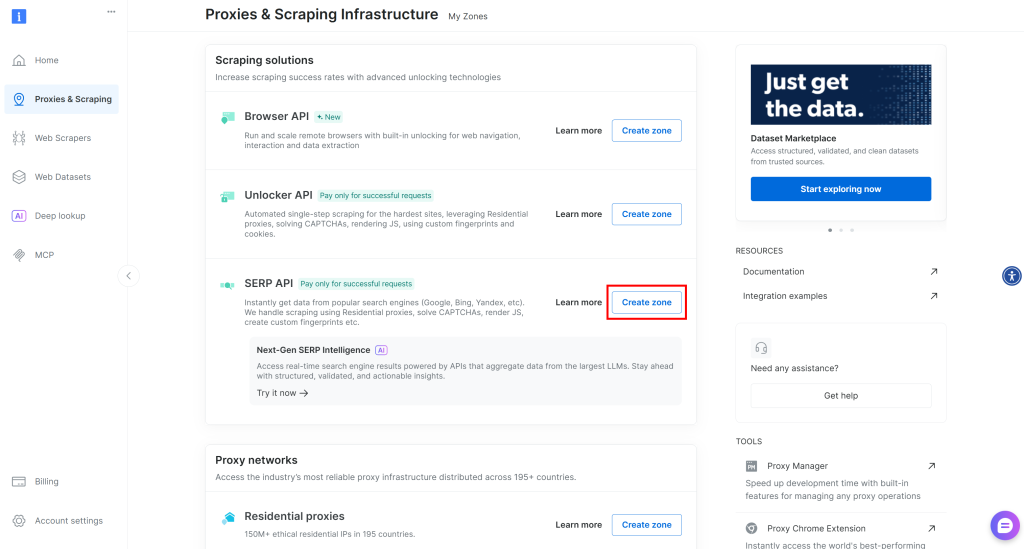
Dê um nome à sua Zona (por exemplo, serp-api) e clique no botão “Add” (Adicionar):
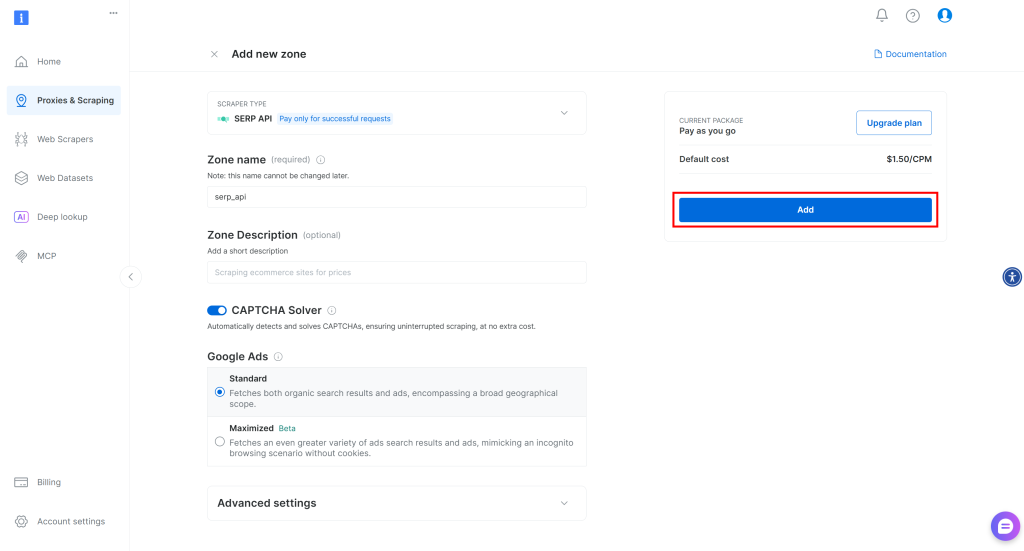
Em seguida, vá para a página de produto da Zona e certifique-se de que ela esteja ativada, alternando o botão para “Active” (Ativo):
Legal! Sua zona API SERP da Bright Data está agora configurada com sucesso e pronta para ser usada.
Etapa 2: Obtenha sua chave da API da Bright Data
A maneira recomendada de autenticar solicitações à API SERP é usar sua chave da API da Bright Data. Se você ainda não gerou uma, siga o guia oficial da Bright Data para criar sua chave de API.
Ao fazer uma solicitação POST para a API SERP, inclua sua chave de API no cabeçalho de autorização da seguinte forma:
"Authorization: Bearer <YOUR_BRIGHT_DATA_API_KEY>"Incrível! Agora você tem tudo o que precisa para chamar a API SERP da Bright Data a partir de um script Python com solicitações - ouqualquer outro cliente HTTP Python.
Agora, vamos juntar tudo!
Etapa #3: Chamar a API SERP
Utilize a API SERP da Bright Data em Python para recuperar os resultados de pesquisa do Baidu para a palavra-chave “bright data”:
# pip install requests
importar solicitações
from urllib.parse import urlencode
# Credenciais da Bright Data (TODO: substitua por seus valores)
bright_data_api_key = "<YOUR_BRIGHT_DATA_API_KEY>"
bright_data_serp_api_zone_name = "<YOUR_SERP_API_ZONE_NAME>" # (por exemplo, "serp_api")
# URL base da página de pesquisa do Baidu
base_url = "https://www.baidu.com/s"
# Palavra-chave/keyphrase da pesquisa
search_query = "bright data" (dados brilhantes)
params = {"wd": search_query}
# Criar o URL da SERP do Baidu
url = f"{base_url}?{urlencode(params)}"
# Enviar uma solicitação POST para a API SERP da Bright Data
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Authorization": f "Bearer {bright_data_api_key}",
"Content-Type": "application/json"
},
json={
"Zona": bright_data_serp_api_zone_name,
"url": url,
"format" (formato): "raw"
}
)
# Recuperar o HTML totalmente renderizado
html = response.text
# A lógica do Parsing fica aqui...Para obter outro exemplo, confira o “Bright Data API SERP Python Project” no GitHub.
A API SERP da Bright Data lida com a renderização de JavaScript, integra-se a uma rede Proxy para rotação automática de IP e gerencia medidas antirraspagem, como impressão digital do navegador, CAPTCHAs e outras. Isso significa que você não encontrará a página de erro “网络不给力,请稍后重试” (“A rede não está funcionando bem, tente novamente mais tarde.”) que normalmente seria exibida ao fazer scraping do Baidu com um cliente HTTP básico, como solicitações.
Em termos mais simples, a variável html contém a página de resultados de pesquisa do Baidu totalmente renderizada. Verifique isso imprimindo o HTML com:
print(html)Você obterá um resultado como o mostrado abaixo:
A partir daqui, você pode analisar o HTML conforme mostrado na primeira abordagem para extrair os dados de pesquisa do Baidu de que precisa. Como prometido, a API SERP da Bright Data evita bloqueios e permite que você obtenha escalabilidade ilimitada!
Abordagem nº 3: Integrar o servidor Web MCP
Lembre-se de que a API SERP (e muitos outros produtos da Bright Data) também pode ser acessada por meio da ferramenta search_engine no Web MCP da Bright Data.
Esse servidor Web MCP de código aberto fornece acesso amigável à IA às soluções de recuperação de dados da Web da Bright Data, incluindo o Scraping do Baidu. Especificamente, as ferramentas search_engine e scrape_as_markdown estão disponíveis na camada gratuita do Web MCP, o que lhe dá a oportunidade de usá-las em agentes ou fluxos de trabalho de IA sem nenhum custo.
Para integrar o Web MCP à sua solução de IA, você só precisa do Node.js instalado localmente e de um arquivo de configuração como este:
{
"mcpServers": {
"Bright Data Web MCP": {
"command" (comando): "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<SUA_CHAVE_API_DATA_BRIGHT_DATA>"
}
}
}
}Por exemplo, essa configuração funciona com o Claude Desktop e o Code (e muitas outras bibliotecas e soluções de IA). Descubra outras integrações na documentação.
Como alternativa, você pode se conectar por meio do servidor remoto da Bright Data sem nenhum pré-requisito local.
Com essa integração, seus fluxos de trabalho ou agentes alimentados por IA poderão buscar autonomamente dados SERP do Baidu (ou de outros mecanismos de pesquisa compatíveis) e processá-los em tempo real.
Conclusão
Neste tutorial, você explorou três métodos recomendados para raspar o Baidu:
- Usar um Scraper personalizado.
- Aproveitamento da API SERP do Baidu.
- Por meio do Bright Data Web MCP.
Conforme demonstrado, a maneira mais confiável de raspar o Baidu em escala e evitar bloqueios é usar uma solução de raspagem estruturada. Isso deve ser apoiado por uma tecnologia avançada de bypass anti-bot e uma rede Proxy robusta, como os produtos da Bright Data.
Crie uma conta gratuita na Bright Data e comece a explorar nossas soluções de raspagem hoje mesmo!




