









A web contém grandes quantidades de dados que podem ser inestimáveis para pesquisas e decisões de negócios. É por isso que é tão importante saber usar ferramentas como o Playwright.
O Playwright é uma poderosa biblioteca Node.js desenvolvida pela Microsoft que é capaz de extrair dados de sites. Nesta publicação, você verá exemplos práticos e detalhados usando o Playwright para extrair dados da página inicial da Bright Data. Em seguida, você poderá aplicar esses exemplos a qualquer outro site cujos dados queira extrair usando o Playwright.
Por que usar o Playwright
A extração de dados da web não é um conceito novo. No ecossistema JavaScript, ferramentas como Cheerio, Selenium, Puppeteere Playwright ajudam a simplificar essa extração.
Por ser uma biblioteca mais nova de extração de dados da web, o Playwright é particularmente atrativo devido aos seguintes recursos:
Localizadores poderosos
O Playwright usa localizadores, que têm uma lógica integrada de espera automática e novas tentativas, para selecionar elementos em uma página da web. A lógica de espera automática simplifica seu código de extração de dados porque não é necessário esperar que as páginas sejam carregadas manualmente.
A lógica de novas tentativas também torna o Playwright uma biblioteca adequada para extrair dados de aplicativos de página única (SPA) modernos que carregam dados dinamicamente após o carregamento da página inicial.
Métodos com vários localizadores
Ao usar localizadores, o Playwright permite especificar quais elementos localizar na página usando várias sintaxes diferentes, incluindo a sintaxe de seletores CSS, a sintaxe XPathe o conteúdo de textos de elementos. Você também pode aplicar filtros aos localizadores para ajustar ainda mais o localizador.
Extração de dados da web com Playwright
Nesta seção, você criará um projeto Node.js, instalará o Playwright e aprenderá como localizar, interagir com dados de uma página da web e extraí-los usando o Playwright.
Pré-requisitos
Os trechos de código deste artigo são executados na versão mais recente do suporte de longo prazo (LTS) do Node.js, que, no momento em que este artigo foi escrito, era a v18.15.0. Confirme se tem o Node.js instalado antes de começar.
Também é altamente recomendado um editor de código capaz de realçar e preencher automaticamente a sintaxe do JavaScript, como o Visual Studio Code.
Como criar um novo projeto
Abra uma nova janela do terminal, crie uma nova pasta para o seu projeto Node.js e navegue até ela usando o seguinte comando:
mkdir playwright-demo
cd playwright-demo
Em seguida, crie seu projeto Node.js executando o seguinte comando npm:
npm init -y
Como instalar o Playwright
Depois de criar um projeto Node.js, instale a biblioteca Playwright usando o seguinte comando na sua janela do terminal:
npm install playwright
A instalação da biblioteca pode demorar um pouco porque o Playwright baixará os navegadores necessários como parte de sua instalação.
Como abrir a página inicial da Bright Data
Com a biblioteca Playwright instalada, crie um novo arquivo na pasta do seu projeto chamado index.js. Em seguida, copie o seguinte código nele:
// Import the Playwright library to use it
const playwright = require("playwright");
(async () => {
// Launch a new instance of a Chromium browser
const browser = await playwright.chromium.launch({
// Set headless to false so you can see how Playwright is
// interacting with the browser
headless: false,
});
// Create a new Playwright context
const context = await browser.newContext();
// Create a new page/tab in the context.
const page = await context.newPage();
// Navigate to the Bright Data home page.
await page.goto("https://brightdata.com/");
// Wait 10 seconds (or 10,000 milliseconds)
await page.waitForTimeout(10000);
// Close the browser
await browser.close();
})();
Execute o trecho usando o seguinte comando no terminal:
node index.js
Um navegador Chromium deverá abrir e carregar a página inicial da Bright Data:
Como localizar elementos
Agora que você navegou até a página inicial da Bright Data usando o Playwright, poderá usar localizadores para selecionar elementos específicos na página da web. O Playwright tem vários localizadores, e as seções a seguir demonstrarão como cada localizador funciona.
Localizando elementos com seletores CSS
O Playwright permite localizar elementos em uma página da web usando seletores CSS, uma sintaxe concisa, porém poderosa, usada em CSS para aplicar estilos a elementos HTML específicos na página da web.
Por exemplo, o logotipo da Bright Data é um elemento <svg> no cabeçalho da página, com a classe page_header_logo_svg associada:

Usando essas informações, você pode localizar o elemento SVG usando um seletor CSS:
const logoSvg = page.locator(".page_header_logo_svg");
O localizador é armazenado na variável logoSvg e pode ser usado posteriormente para interagir com as informações do elemento ou extraí-las.
Como localizar elementos com consultas XPath
O XPath é outra sintaxe seletora que você pode usar para localizar elementos em um documento XML. Como HTML é XML, você pode usar a sintaxe para encontrar elementos HTML em uma página da web.
Por exemplo, você pode selecionar o mesmo logotipo SVG visto na seção anterior com a seguinte consulta XPath:
const logoSvg = page.locator("//*[@class='page_header_logo_svg']");
A consulta procura qualquer elemento com a classe page_header_logo_svg associada a ela e armazena sua localização na variável logoSvg .
Como localizar elementos por função
Os elementos HTML podem ter diferentes funções associadas a eles. Essas funções fornecem significado semântico a uma página da web, facilitando o suporte da página para leitores de tela e outras ferramentas. Leia mais sobre as funções aqui.
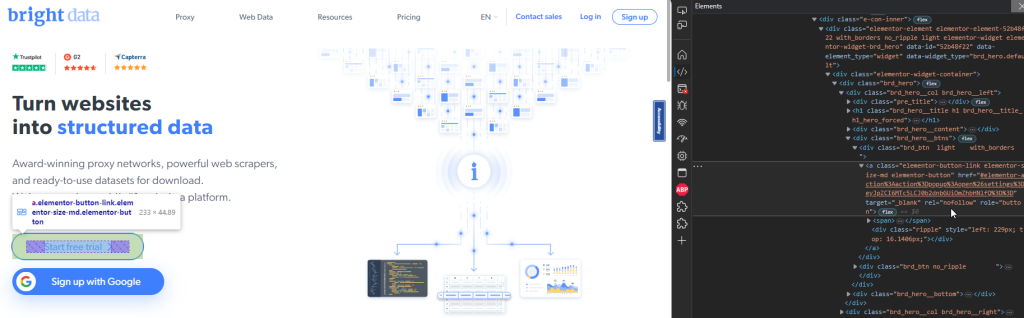
O trecho de código a seguir mostra como você pode encontrar o botão Cadastre-se usando a função e o nome associados a ele:
const signupButton = page.getByRole("button", {
name: "Start free trial",
});
Este trecho localizará o botão Começar avaliação gratuita na página inicial:
const signupButton = page.getByRole("button", {
name: "Start free trial",
});Este trecho localizará o botão Começar avaliação gratuita na página inicial:
Como localizar elementos por texto
Se um elemento HTML não tiver um atributo identificador significativo, como um atributo id ou class, você poderá selecionar o elemento pelo texto usando o método getByText.
Por exemplo, a página inicial da Bright Data tem um título na seção hero com as palavras “dados estruturados” em azul:
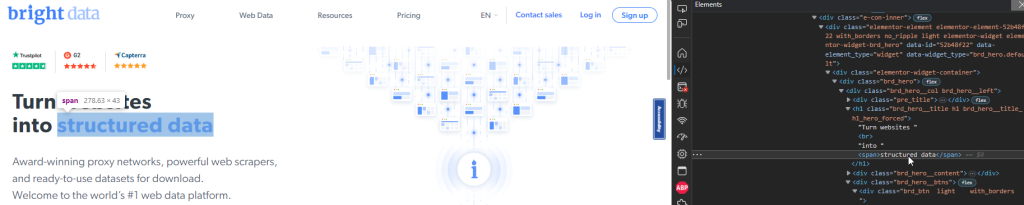
Você pode selecionar o elemento <span> contendo essas palavras usando o seguinte trecho do Playwright:
const structuredData = page.getByText("structured data");
Como localizar elementos por rótulo
Em um formulário HTML, os elementos de entrada geralmente têm rótulos. O Playwright pode usar esses rótulos para identificar o elemento de entrada associado a esse rótulo usando o método getByLabel.
Por exemplo, a página de Login da Bright Data tem um elemento de entrada com um rótulo contendo as palavras “E-mail profissional”:
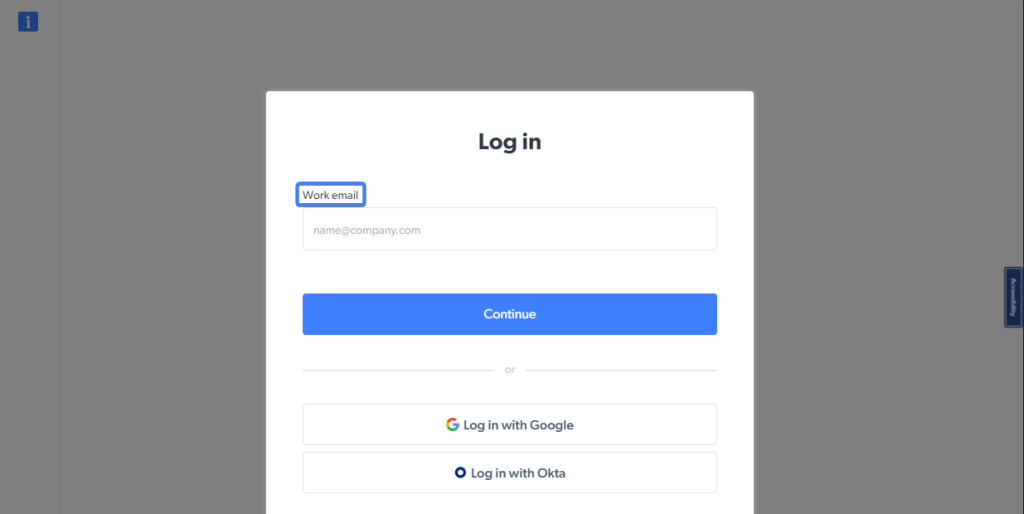
Você pode localizar o elemento de entrada na página e armazená-lo em uma variável para uso posterior utilizando o seguinte trecho de código:
// Navigate to the Bright Data login page.
await page.goto("https://brightdata.com/cp/start");
// Locate the <input> using the label
const emailInput = page.getByLabel("Work email");
Como localizar elementos por espaço reservado
Você também pode localizar um elemento de entrada com base no texto de exemplo exibido usando o método getByPlaceholder.
Você notará que o campo de e-mail da página de Login da Bright Data tem um texto de exemplo para dar ao usuário um contexto sobre quais informações inserir.
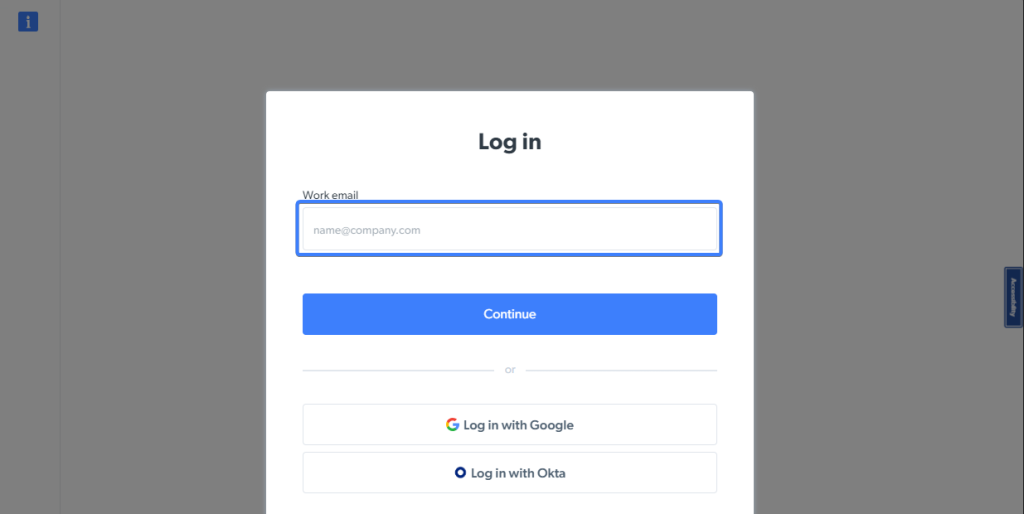
O trecho a seguir localizará esse elemento com base no texto de exemplo mostrado pela entrada:
// Navigate to the Bright Data login page.
await page.goto("https://brightdata.com/cp/start");
// Locate the <input> using the placeholder
const emailInput = page.getByPlaceholder("[email protected]");
Como localizar elementos por texto alternativo
O HTML permite adicionar uma descrição de texto a imagens usando o atributo alt, que é exibido se a imagem não for carregada e lida em voz alta pelos leitores de tela para descrevê-la. O método getByAltText do Playwright permite localizar um elemento img usando seu atributo alt.
Por exemplo, a Bright Data lista os setores que usam seus dados. Você pode recuperar a imagem usada no setor de saúde usando seu valor alternativo, “caso de uso de saúde”:
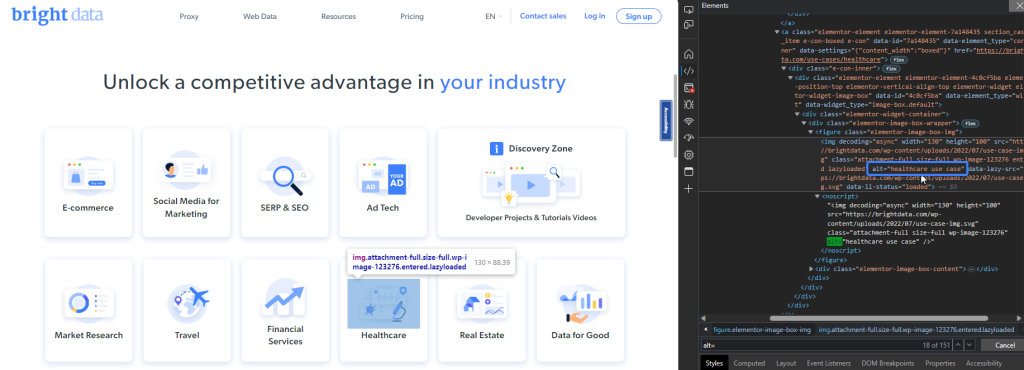
O seguinte trecho de código localizará o elemento da imagem:
const healthcareImage = page.getByAltText("healthcare use case");
Como localizar elementos por título
O seletor final do Playwright que você pode usar para extrair dados é o método getByTitle, que localiza um elemento HTML pelo atributo de título. Você verá o valor do título ao passar o mouse sobre o componente HTML com o ponteiro.
Por exemplo, o site de suporte técnico da Bright Data contém um link de login com um atributo de título:

Você pode usar o seguinte trecho do Playwright para localizar o link usando seu atributo de título:
// Navigate to the Bright Data helpdesk webpage.
await page.goto("https://help.brightdata.com/hc/en-us");
// Locate the Sign in link using its title attribute
const signInLink = page.getByTitle("Opens a dialog");
Agora que você viu alguns métodos que podem ser usados para localizar elementos em uma página da web usando o Playwright, vamos aprender como interagir com os dados desses elementos e como os extrair.
Como interagir com elementos
Depois de localizar um elemento em uma página da web, você pode interagir com ele. Por exemplo, talvez seja necessário fazer login em um site antes de extrair dados de páginas protegidas.
Este trecho de código demonstra diferentes métodos do Playwright para interagir com elementos em uma página da web. Você encontrará uma explicação de cada função no código a seguir:
// Import the Playwright library to use it
const playwright = require("playwright");
(async () => {
// Launch a new instance of a Chromium browser
const browser = await playwright.chromium.launch({
// Set headless to false so you can see how Playwright is
// interacting with the browser
headless: false,
});
// Create a new Playwright context
const context = await browser.newContext();
// Create a new page/tab in the context.
const page = await context.newPage();
// Navigate to the Bright Data login page.
await page.goto("https://brightdata.com/");
// Locate and click on the signup button
await page
.locator("#hero_new")
.getByRole("button", {
name: "Start free trial",
})
.click();
// Locate the first name field and FILL in a first name
await page.locator(".hs_firstname input").fill("John");
// Locate the last name field and FILL in a last name
await page.locator(".hs_lastname input").fill("Smith");
// Locate the email field and TYPE in an email address
await page.locator(".hs_email input").type("[email protected]");
// Locate the company size field and SELECT an option
await page.locator(".hs_numemployees select").selectOption("1-9 employees");
// Locate the terms and conditions checkbox and CHECK it.
await page.locator(".legal-consent-container input").check();
// Wait 10 seconds so you can see the result.
await page.waitForTimeout(10000);
// Close the browser
await browser.close();
})();
Cole este trecho em seu arquivo index.js e execute-o novamente usando o seguinte comando:
node index.js
A página inicial da Bright Data aparecerá brevemente antes de exibir uma caixa de diálogo de cadastro. A seguir, você verá como o Playwright preenche o formulário Cadastre-se usando os diferentes métodos neste trecho:
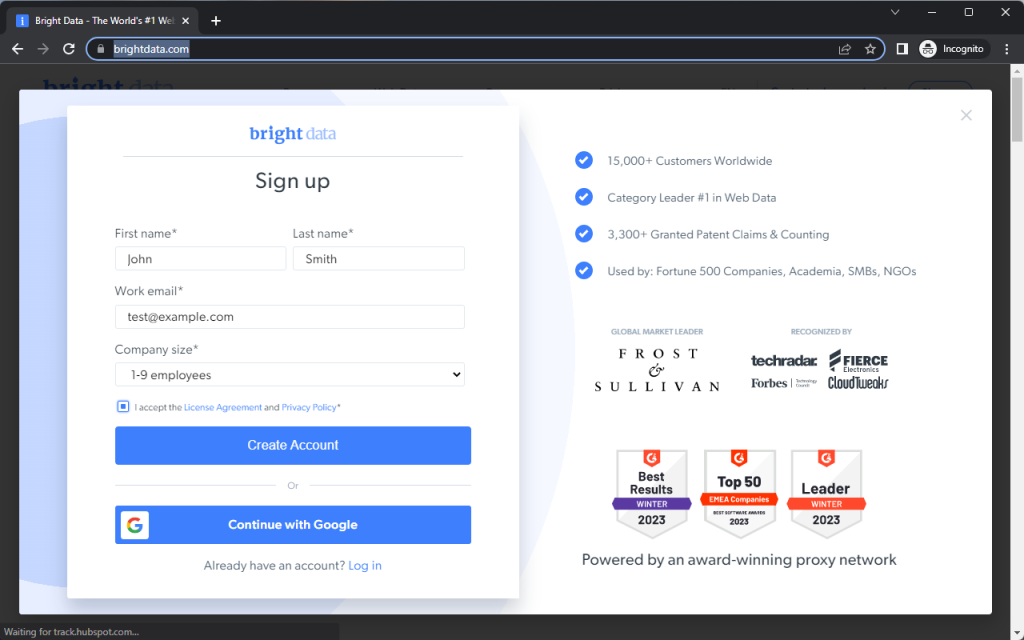
Como clicar em elementos
No trecho anterior, o Playwright primeiro clicou no botão Cadastre-se para que a caixa de diálogo aparecesse:
// Locate and click on the signup button
await page
.getByRole("button", {
name: "Start free trial",
})
.click();
O Playwright tem dois métodos para clicar nos elementos:
- O método
clicksimula um clique único em um elemento. - O método
dblclicksimula um clique duplo em um elemento.
Neste exemplo, você só precisou clicar uma vez no botão Cadastre-se, e é por isso que o trecho usa o método click.
Como preencher campos de texto
Neste exemplo, o trecho usou dois métodos para preencher campos de texto no formulário Cadastre-se:
// Locate the first name field and FILL in a first name
await page.locator(".hs_firstname input").fill("John");
// Locate the last name field and FILL in a last name
await page.locator(".hs_lastname input").fill("Smith");
// Locate the email field and TYPE in an email address
await page.locator(".hs_email input").type("[email protected]");
O trecho usa os métodos fill e type em campos diferentes. Ambas as funções preenchem um campo de texto, mas o fazem de forma um pouco diferente:
- O método
fillinsere o valor especificado no campo de texto. Embora isso funcione para a maioria dos formulários, alguns sites podem impedir que você insira um valor inteiro. - O método
typeajuda a mitigar isso, simulando cada aperto de tecla para inserir o valor especificado.
Você provavelmente usaria o método fill na maioria dos casos, mas, quando necessário, pode usar o método type para simular a digitação manual do valor.
Como selecionar uma opção suspensa
O formulário Cadastre-se tem um campo suspenso para selecionar o porte da empresa, que o Playwright preencheu com “1 a 9 funcionários”:
// Locate the company size field and SELECT an option
await page.locator(".hs_numemployees select").selectOption("1-9 employees");
O Playwright permite utilizar o método SelectOption para preencher os campos suspensos em um formulário. A função permite selecionar um item suspenso com base no valor ou no rótulo e escolher várias opções em um menu de seleção múltipla.
Como marcar botões e caixas de seleção
Antes de enviar o formulário, você precisa aceitar os termos e condições. O trecho a seguir marca a caixa de seleção apropriada:
// Locate the terms and conditions checkbox and CHECK it.
await page.locator(".legal-consent-container input").check();
Para modificar uma caixa de seleção, você pode usar o método check e uncheck:
- O método
checkgarante que a caixa de seleção esteja marcada. - O método
uncheckgarante que a caixa de seleção esteja desmarcada.
Agora que você viu como o Playwright permite interagir com elementos HTML em uma página, a próxima seção mostrará como extrair seus dados.
Como extrair dados de elementos
A extração de dados é essencial para a função de web scraping. O Playwright permite utilizar vários métodos para recuperar diferentes tipos de dados dos elementos que você localizou. As seções a seguir abordam alguns desses métodos.
Como extrair textos internos
O método innerText permite extrair o texto dentro de um elemento. Por exemplo, a página inicial da Bright Data tem um elemento hero na parte superior:
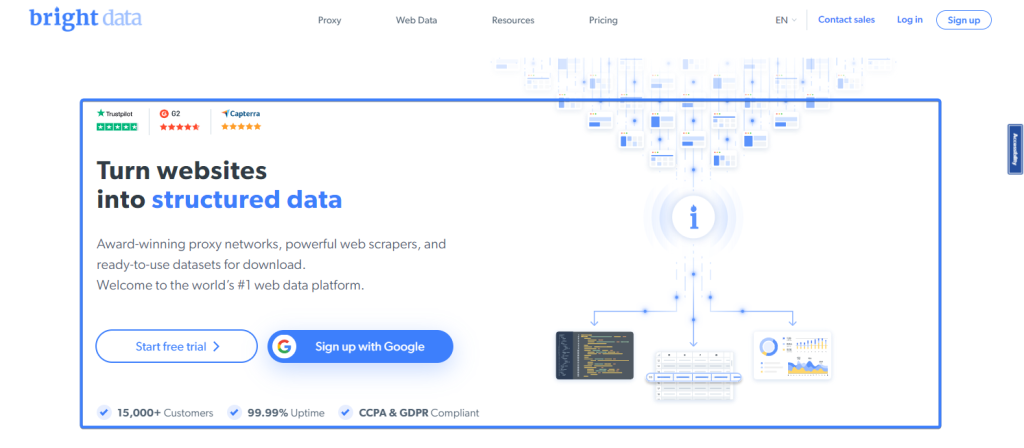
Você pode extrair o título do hero na página inicial da Bright Data usando o seguinte trecho:
const headerText = await page.locator(".brd_hero__title.h1").innerText();
// headerText = "Turn websites\ninto structured data"
Se seu localizador apontar para mais de um elemento, você poderá recuperar o texto em todos os elementos como uma sequência de matrizes usando o método allInnerTexts. Por exemplo, a página inicial da Bright Data tem uma lista de casos de uso para seus dados:
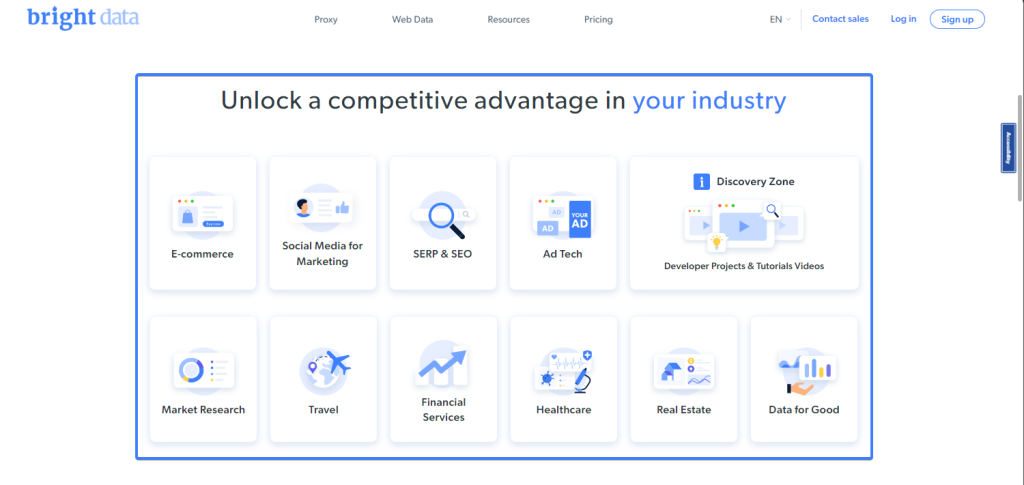
Você pode extrair uma lista de todos os casos de uso da Bright Data usando o seguinte trecho:
const useCases = await page
.locator(".section_cases_row_col .elementor-image-box-title")
.allInnerTexts();
// useCases = [
// 'E-commerce',
// 'Social Media for Marketing',
// 'SERP & SEO',
// 'Ad Tech',
// 'Market Research',
// 'Travel',
// 'Financial Services',
// 'Healthcare',
// 'Real Estate',
// 'Data for Good'
// ]
Como extrair HTML interno
O Playwright também permite extrair HTML interno de um elemento usando o método innerHTML. Por exemplo, você pode obter o HTML para o rodapé na página inicial da Bright Data usando o seguinte trecho:
const footerHtml = await page.locator("#footer").innerHTML();
// footerHtml = '<div class="container"><div class="footer__logo">...'
Como extrair valores de atributos
Talvez seja necessário extrair dados de atributos em um elemento HTML, como o atributo href em um link. O trecho a seguir do Playwright demonstra como você pode extrair a propriedade href no link de Login:
const signUpHref = await page.getByText("Log in").getAttribute("href");
// signUpHref = '/cp/start'
Como capturar a tela de páginas
Ao extrair dados, talvez seja necessário fazer capturas de tela para fins de auditoria. Você pode usar o método screenshot para fazer isso. A função permite configurar várias opções, como onde salvar o arquivo de captura de tela e se deseja fazer uma captura da página inteira.
O trecho a seguir faz uma captura de tela da página inicial inteira da Bright Data e a salva:
await page.screenshot({
// Save the screenshot to the "homepage.png" file
path: "homepage.png",
// Take a screenshot of the entire page
fullPage: true,
});
Como utilizar os serviços automatizados de extração de dados
Os trechos anteriores detalham como localizar, interagir com os dados de uma página da web e extraí-los. Esses métodos permitem extrair quase todos os dados de uma página da web. No entanto, eles exigem esforço, pois você deve identificar os elementos apropriados antes de os localizar. Você também precisa estar ciente dos CAPTCHAs e dos limites de taxa ao extrair dados de várias páginas no mesmo site.
A Bright Data oferece várias soluções que lhe permitem se concentrar na extração de dados. A Bright Data fornece um Web Scraper IDE com funções e modelos JavaScript prontos para ajudá-lo a extrair dados de sites populares. Você também pode contornar CAPTCHAs usando o Web Unlocker e evitar limites de taxa e bloqueios de localizações geográficas usando os serviços de proxy da Bright Data. Esses serviços eliminam muitos obstáculos no Playwright e ajudam você a extrair dados com mais rapidez e facilidade.
Conclusão
Neste artigo, você aprendeu sobre o Playwright, uma biblioteca desenvolvida pela Microsoft que ajuda a extrair dados de sites, e aprendeu a usar o Playwright para localizar, interagir com dados de elementos em uma página da web e extraí-los. Por fim, você viu como um serviço de extração de dados automatizado, como a Bright Data, é capaz de simplificar seus processos de web scraping.





