

Neste guia, abordaremos:
- Começando com o web scraping em R
- Entendendo as ferramentas
- Configurando o ambiente de desenvolvimento
- Entendendo a página web
- Entendendo o DevTools
- Entendendo as ferramentas
- Visão aprofundada do web scraping em R: tutorial
- Pré-requisitos
- Explorando interativamente a página web
- Seletor CSS vs. XPath para web scraping
- Extraindo informações programaticamente da página web
- Escalando para múltiplos URLs
- Próxima etapa: pré-construído vs. construção própria?
Começando com o web scraping em R
O primeiro passo seria entender quais ferramentas vamos usar neste tutorial de R.
Entendendo as ferramentas: R e rvest
R é uma biblioteca rica e fácil de usar para análise estatística e visualização de dados, que fornece ferramentas úteis para organização de dados e digitação dinâmica.
rvest — de “harvest” — é um dos pacotes em R mais populares (senão o mais popular) com funcionalidades de web scraping, também graças à sua interface extremamente fácil de usar. O Vanilla rvest permite extrair dados de apenas uma página web, o que é perfeito para uma exploração inicial. Você pode estendê-la posteriormente com a biblioteca polite para extrair dados de várias páginas.
Configurando o ambiente de desenvolvimento
Se você ainda não estiver usando R no RStudio, siga as instruções apresentadas aqui para instalação.
Depois de terminar, abra o console e instale o rvest:
install.packages("rvest")
Como parte da coleção tidyverse , é oficialmente recomendado estender ainda mais as funcionalidades integradas do rvest com outros pacotes na coleção, como magrittr, para facilitar a leitura do código, ou xml2, para trabalhar com HTML e XML. Você pode fazer isso instalando o tidyverse diretamente:
install.packages("tidyverse")Entendendo a página web
O web scraping é uma técnica para recuperar dados de sites dentro de processos automatizados compatíveis.
Três considerações importantes vêm dessa definição:
- Os dados vêm em vários formatos.
- Os sites exibem informações de maneiras muito diferentes.
- Os dados coletados precisam ser acessíveis de forma legal.
Para entender como extrair dados de um URL, primeiro você precisa entender como o conteúdo da página web é exibido por meio da linguagem de marcação HTML e da linguagem de folhas de estilo CSS.
O HTML fornece o conteúdo e a estrutura da página web, carregada no navegador para criar um Document Object Model (DOM) semelhante a uma árvore, organizando o conteúdo com “tags”.
As tags têm uma estrutura hierárquica, com cada tag tendo uma funcionalidade específica aplicada a todo o conteúdo contido em suas declarações de abertura () e fechamento ():
<!DOCTYPE html>
<html lang="en-gb" class="a-ws a-js a-audio a-video a-canvas a-svg a-drag-drop a-geolocation a-history a-webworker a-autofocus a-input-placeholder a-textarea-placeholder a-local-storage a-gradients a-transform3d -scrolling a-text-shadow a-text-stroke a-box-shadow a-border-radius a-border-image a-opacity a-transform a-transition a-ember" data-19ax5a9jf="dingo" data-aui-build-date="3.22.2-2022-12-01">
▶<head>..</head>
▶<body class="a-aui_72554-c a-aui_accordion_a11y_role_354025-c a-aui_killswitch_csa_logger_372963-c a-aui_launch_2021_ally_fixes_392482-t1 a-aui_pci_risk_banner_210084-c a-aui_preload_261698-c a-aui_rel_noreferrer_noopener_309527-c a-aui_template_weblab_cache_333406-c a-aui_tnr_v2_180836-c a-meter-animate" style="padding-bottom: 0px;">..</body>
</html>A tag <html> é o componente mínimo de qualquer página web, com as tags <head> e <body> aninhadas dentro dela. As tags <head> e <body> são elas próprias “pais” de outras tags dentro delas, com <div> (para seção de documento) e <p> (para parágrafo) sendo alguns de seus “filhos” mais comuns.
No trecho acima, você pode ver os “attributes” (atributos) associados a cada “element” (elemento) HTML: lang, classe style são pré-construídos; os atributos que começam com data- são personalizados para a Amazon.
class é de particular interesse para web scraping, junto com o atributo id, pois eles nos permitem segmentar um grupo de elementos e um elemento específico, respectivamente. Originalmente, isso se destinava à estilização em CSS.
O CSS fornece o estilo da página web. Da coloração ao posicionamento e dimensionamento, você pode selecionar qualquer elemento HTML e atribuir novos valores às suas propriedades de estilo. Você também pode aplicar o estilo CSS embutido no elemento HTML com o atributo style , como você viu no trecho acima:
<body .. style="padding-bottom: 0px;">Em CSS puro, isso seria escrito como:
body {padding-bottom: 0px;}
Aqui, body é o “seletor”, padding-bottom é a “propriedade” e 0px é o “valor”.
Qualquer tag , classou id pode ser usada como seletor de CSS.
Os usuários podem interagir dinamicamente com o conteúdo exibido na página web por meio de funcionalidades fornecidas pela linguagem de programação JavaScript por meio da tag script . Após a interação do usuário, o conteúdo exibido pode mudar, e um novo conteúdo pode aparecer; os web scrapers avançados podem imitar as interações do usuário, como discutiremos mais adiante.
Entendendo o DevTools
Os principais navegadores web fornecem ferramentas de desenvolvedor integradas, que permitem a coleta e a atualização em tempo real de informações técnicas em uma página web para registro, depuração, teste e análise de desempenho. Neste tutorial, usaremos o DevTools do Chrome.
As ferramentas do desenvolvedor podem ser acessadas no canto superior direito do navegador, em Mais ferramentas:
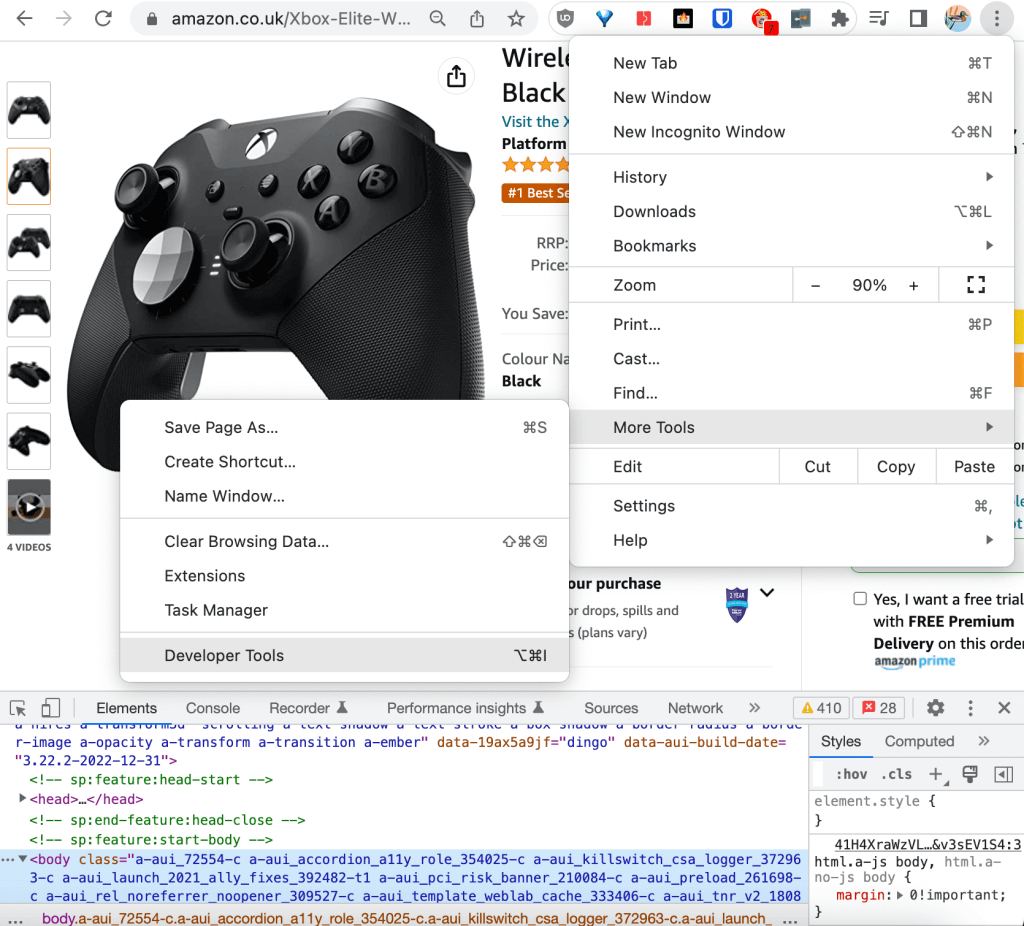
No DevTools, você pode percorrer o HTML bruto na guia Elements. Ao percorrer qualquer uma das linhas HTML, você verá o elemento correspondente renderizado na página web destacado em azul:
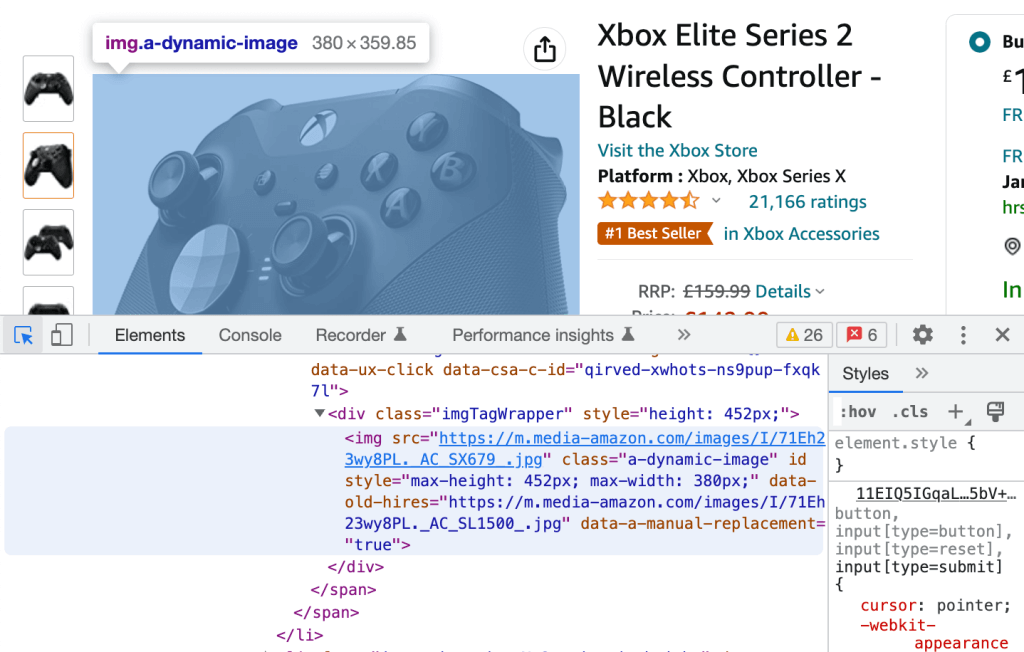
Por outro lado, você pode clicar no ícone no canto superior esquerdo e selecionar qualquer elemento renderizado da página web para ser redirecionado para sua contraparte HTML bruta, novamente destacada em azul.
Esses dois processos são tudo o que você precisa para extrair os descritores CSS para nosso tutorial prático.
Visão aprofundada do web scraping em R: tutorial
Nesta seção, exploraremos como extrair da web o URL da Amazon para extrair avaliações de produtos.
Pré-requisitos
Certifique-se de ter o seguinte instalado em seu ambiente Rstudio:
- R = 4.2.2
- rvest= 1.0.3
- tidyverse = 1.3.2
Explorando interativamente a página web
Você pode usar o DevTools do Chrome para explorar o HTML do seu URL e criar uma lista de todas as classes e IDs dos elementos HTML que contêm as informações que estamos interessados em coletar, ou seja, as avaliações dos produtos:

Cada avaliação de cliente pertence a um div com um id no formato:
customer_review_$INTERNAL_ID.
O conteúdo HTML do div correspondente à avaliação do cliente na captura de tela acima é o seguinte:
<div id="customer_review-R2U9LWUSIPY0GS" class="a-section celwidget" data-csa-c-id="kj23dv-axnw47-69iej3-apdvzi" data-cel-widget="customer_review-R2U9LWUSIPY0GS">
<div data-hook="genome-widget" class="a-row a-spacing-mini">..</div>
<div class="a-row">
<a class="a-link-normal" title="4.0 out of 5 stars" href="https://www.amazon.co.uk/gp/customer-reviews/R2U9LWUSIPY0GS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07SR4R8K1">
<i data-hook="review-star-rating" class="a-icon a-icon-star a-star-4 review-rating">
<span class="a-icon-alt">4.0 out of 5 stars</span>
</i>
</a>
<span class="a-letter-space"></span>
<a data-hook="review-title" class="a-size-base a-link-normal review-title a-color-base review-title-content a-text-bold" href="https://www.amazon.co.uk/gp/customer-reviews/R2U9LWUSIPY0GS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07SR4R8K1">
<span>Very good controller if a little overpriced</span>
</a>
</div>
<span data-hook="review-date" class="a-size-base a-color-secondary review-date">..</span>
<div class="a-row a-spacing-mini review-data review-format-strip">..</div>
<div class="a-row a-spacing-small review-data">
<span data-hook="review-body" class="a-size-base review-text">
<div data-a-expander-name="review_text_read_more" data-a-expander-collapsed-height="300" class="a-expander-collapsed-height a-row a-expander-container a-expander-partial-collapse-container" style="max-height:300px">
<div data-hook="review-collapsed" aria-expanded="false" class="a-expander-content reviewText review-text-content a-expander-partial-collapse-content">
<span>In all honesty I'm not sure why the price is quite as high ….</span>
</div>
…</div>
…</span>
…</div>
…</div>
Cada conteúdo em que você estiver interessado em razão das avaliações dos clientes tem sua classe exclusiva: review-title-content para o título, review-text-content para o corpo e review-rating para a avaliação.
Você pode verificar se a classe é exclusiva no documento e usar diretamente o “seletor simples”. Em vez disso, uma abordagem mais garantida é usar o descritor CSS, que permanecerá exclusivo mesmo se a classe for atribuída a novos elementos no futuro.
Basta recuperar o descritor CSS clicando com o botão direito do mouse no elemento no DevTools e selecionando Copy Selector:
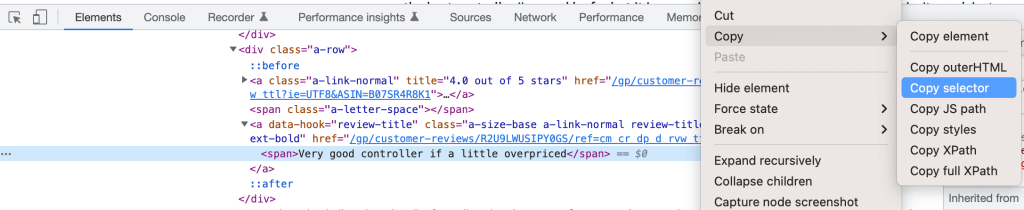
Você pode definir seus três seletores como:
customer_review-R2U9LWUSIPY0GS > div:nth-child(2) > a.a-size-base.a-link-normal.review-title.a-color-base.review-title-content.a-text-bold > spanpara o títulocustomer_review-R2U9LWUSIPY0GS > div.a-row.a-spacing-small.review-data > span > div > div.a-expander-content.reviewText.review-text-content.a-expander-partial-collapse-content > spanpara o corpocustomer_review-R2U9LWUSIPY0GS > div:nth-child(2) > a:nth-child(1) > i.review-rating > spanpara a avaliação*
.review-ratingfoi adicionado manualmente para melhorar a consistência.
Seletor CSS vs. XPath para web scraping
Para este tutorial, decidimos usar um seletor CSS para identificar elementos para web scraping. A outra abordagem comum é usar o XPath, ou seja, o caminho XML, que identifica um elemento por meio de seu caminho completo no DOM.
Você pode extrair o XPath completo seguindo o mesmo procedimento do seletor CSS. Por exemplo, o título da avaliação é:
/html/body/div[2]/div[3]/div[6]/div[32]/div/div/div[2]/div/div[2]/span[2]/div/div/div[3]/div[3]/div/div[1]/div/div/div[2]/a[2]/span
Um seletor CSS é um pouco mais rápido, enquanto o XPath tem uma compatibilidade um pouco melhor com versões anteriores. Fora essas pequenas diferenças, selecionar uma em vez da outra depende mais das preferências pessoais do que das implicações técnicas.
Extraindo informações programaticamente da página web
Embora pudéssemos usar o console diretamente para começar a explorar como extrair dados do URL, criaremos um script para rastreabilidade e reprodutibilidade e o executaremos por meio do console usando o comando source() .
Depois de criar o script, a primeira etapa é carregar as bibliotecas instaladas:
library(”rvest”)
library(”tidyverse”)Em seguida, você pode extrair programaticamente o conteúdo de seu interesse da seguinte maneira. Primeiro, crie uma variável na qual você armazenará o URL para pesquisar:
HtmlLink <- "https://www.amazon.co.uk/Xbox-Elite-Wireless-Controller-2/dp/B07SR4R8K1/ref=sr_1_1_sspa?crid=3F4M36E0LDQF3"
Em seguida, extraia o Número de Identificação Padrão da Amazon (ASIN) do URL para usá-lo como um ID exclusivo do produto:
ASIN <- str_match(HtmlLink, "/dp/([A-Za-z0-9]+)/")[,2]
É comum e recomendado usar RegEx para limpar o texto extraído por meio de web scraping, a fim de garantir a qualidade dos dados.
Agora, baixe o conteúdo HTML da página web:
HTMLContent <- read_html(HtmlLink)
A função read_html() faz parte do pacote xml2.
Se você fizer o print() do conteúdo, veremos que ele corresponde à estrutura HTML bruta analisada anteriormente:
{html_document}
<html lang="en-gb" class="a-no-js" data-19ax5a9jf="dingo">
[1] <head>n<meta http-equiv="Content-Type" content="text/ht ...
[2] <body class="a-aui_72554-c a-aui_accordion_a11y_role_354 ...
Agora você pode extrair os três nós de interesse para todas as avaliações de produtos na página. Use os descritores CSS fornecidos pelo Chrome DevTools, modificados para remover o identificador específico de avaliação do cliente #customer_review-R2U9LWUSIPY0GS e o conector “>” da string; você também pode aproveitar as funcionalidades html_nodes() e html_text() do rvest para salvar o conteúdo HTML em objetos separados.
Os comandos a seguir extrairão os títulos das avaliações:
review_title <- HTMLContent %>%
html_nodes("div:nth-child(2) a.a-size-base.a-link-normal.review-title.a-color-base.review-title-content.a-text-bold span") %>%
html_text()
Um exemplo de entrada em review_title é “Very good controller if a little overpriced” (controlador muito bom, mas um pouco caro).
O código abaixo extrairá o corpo da avaliação:
review_body <- HTMLContent %>%
html_nodes("div.a-row.a-spacing-small.review-data span div div.a-expander-content.reviewText.review-text-content.a-expander-partial-collapse-content span") %>%
html_text()
Um exemplo de entrada em review_body começa com “In all honesty, I’m not sure why the price…” (com toda a sinceridade, não sei por que o preço…).
E você pode usar os seguintes comandos para extrair a classificação da avaliação:
review_rating <- HTMLContent %>%
html_nodes("div:nth-child(2) a:nth-child(1) i.review-rating span") %>%
html_text()
Um exemplo de entrada em review_rating é “4,0 de 5 estrelas”.
Para melhorar a qualidade dessa variável, extraia somente a classificação “4,0” e converta-a em int:
review_rating <- substr(review_rating, 1, 3) %>% as.integer()
A funcionalidade de pipe %>% é fornecida pelo kit de ferramentas magrittr.
Agora é hora de exportar o conteúdo copiado dentro de um tibble para análise de dados.
tibble é um pacote R que também pertence à coleção tidyverse e é usado para manipular e imprimir dataframes (estruturas de dados).
df <- tibble(review_title, review_body, review_rating)
O dataframe de saída é o seguinte:

Finalmente, é uma boa ideia refatorar o código na função scrape_amazon <- function(HtmlLink) para cumprir as melhores práticas e preparar melhor o código para escalar para múltiplos URLs.
Escalando para múltiplos URLs
Depois que o modelo de web scraping for criado, você poderá criar uma lista de URLs de todos produtos dos principais concorrentes na Amazon por meio de web crawling e scraping.
Ao escalar para múltiplos URLs para produzir a solução, você precisa descrever os requisitos técnicos do aplicativo.
Ter requisitos técnicos bem definidos garantirá que você atenda corretamente aos requisitos de negócios e se integre perfeitamente aos seus sistemas existentes.
Dependendo dos requisitos técnicos específicos, a função de scraping precisa ser atualizada para suportar uma combinação do seguinte:
- Processo em tempo real ou em lote
- Formato(s) de saída, como JSON, NDJSON, CSV ou XLSX
- Alvo(s) de saída, como e-mail, API, webhook ou armazenamento em nuvem
Já mencionamos que você pode estender o rvest com polite para extrair dados de múltiplas páginas web. O polite cria e gerencia uma sessão de coleta na web por meio do uso de três funcionalidades principais, em total conformidade com o arquivo robots.txt do host e com limitação de taxa e cache de resposta integrados:
bow()cria a sessão de scraping para um URL específico, ou seja, ele apresenta você ao host da web e pede permissão para fazer o scraping.scrape()acessa o HTML da URL; você pode fazer o pipe da função parahtml_nodes()ehtml_text()do rvest para recuperar conteúdo específico.nod()atualiza o URL da sessão para a próxima página, sem a necessidade de recriar uma sessão.
Citando diretamente do site deles: “os três pilares de uma sessão polite são buscar permissão, ir devagar e nunca perguntar duas vezes.”
Próxima etapa: pré-construído vs. construção própria?
Para desenvolver um web scraper de última geração que possa extrair bons dados para uma empresa, alguns recursos precisam estar disponíveis:
- Uma equipe de especialistas em dados com experiência em extração de dados na web
- Uma equipe de engenheiros de DevOps com experiência em gerenciamento de proxy e contorno antibot para permitir resolver CAPTCHAs e desbloquear sites menos acessíveis ao público
- Uma equipe de engenheiros de dados com experiência na criação de infraestrutura para extração de dados em lote e em tempo real
- Uma equipe de especialistas jurídicos para entender os requisitos legais de proteção de dados quanto à privacidade (como GDPR e CCPA)
O conteúdo da web vem em formatos variados, e é difícil encontrar dois sites com exatamente a mesma estrutura. Quanto mais complexo for um site e quanto mais recursos e dados houver para extrair, mais avançado será o conhecimento de programação necessário, sem falar no tempo e nos recursos adicionais necessários para a solução.
Normalmente, você gostaria de implementar pelo menos as seguintes funcionalidades avançadas:
- Minimize as chances de detecção de CAPTCHAs e bots: uma abordagem simples aqui é adicionar um sleep() aleatório para evitar a sobrecarga dos servidores web e padrões de solicitação regulares. Uma abordagem mais eficaz é usar um user_agent ou servidor proxy para distribuir solicitações entre diferentes IPs.
- Scraping de sites com JavaScript: em nosso exemplo da Amazon, o URL não muda ao selecionar uma variante de produto específica. Isso é aceitável para coletar avaliações, pois elas são compartilhadas, mas não para coletar especificações de produtos. Para imitar as interações do usuário em páginas web dinâmicas, você pode usar uma ferramenta como RSelenium para automatizar a navegação do navegador web.
Quando quiser obter acesso a dados da web com recursos limitados, garantir a qualidade dos dados ou desbloquear casos de uso mais avançados, um web scraper pré-construído pode ser a escolha certa.
O Web Scraper da Bright Data fornece modelos para muitos sites com funcionalidades de última geração, incluindo uma implementação muito mais avançada do demonstrado Amazon Scraper!
Não quer lidar com a coleta de dados? Confira nossos datasets; amostras gratuitas disponíveis.






