

Neste tutorial, aprenderemos como fazer scraping da Amazon usando o Bright Data e um projeto de scraping pronto para produção.
Abordaremos:
- Como usar a API Amazon Scraper
- Configurar um projeto e definir os alvos de scraping da Amazon
- Busca e renderização de páginas da Amazon
- Extrair dados de produtos das páginas de pesquisa e de produtos
- Raspagem da Amazon usando o Web MCP da Bright Data com o Claude Desktop
Por que fazer scraping da Amazon?
A Amazon é o maior mercado de produtos do mundo e uma das fontes mais ricas de dados comerciais em tempo real na internet. De tendências de preços a opinião dos clientes, a plataforma reflete o comportamento do mercado em uma escala que poucos outros sites conseguem igualar.
O scraping da Amazon permite que as equipes vão além da pesquisa manual e dos Conjuntos de dados estáticos, possibilitando a tomada de decisões automatizada e baseada em dados em grande escala.
Casos comuns de uso de scraping da Amazon
Algumas das razões mais comuns pelas quais empresas e desenvolvedores coletam dados da Amazon incluem:
- Monitoramento de preços e inteligência competitiva: acompanhe os preços dos produtos, descontos e disponibilidade de estoque em todas as categorias e vendedores quase em tempo real.
- Pesquisa de mercado e produtos: analise listagens de produtos, categorias e classificações de best-sellers para identificar tendências de demanda e novas oportunidades.
- Análise de avaliações e sentimentos: colete avaliações e classificações de clientes para entender o sentimento do comprador, o desempenho do produto e as lacunas de recursos.
- Aplicativos com tecnologia de IA: alimente dados da Amazon em tempo real em LLMs e agentes de IA para tarefas como assistentes de compras, modelos de preços dinâmicos e análises de mercado automatizadas.
Com os casos de uso claros, agora podemos ser práticos e percorrer as maneiras de fazer scraping da Amazon com a Bright Data.
Extraindo dados da Amazon com a API Amazon Scraper da Bright Data
Além de criar scrapers personalizados ou usar o MCP com o Claude, a Bright Data também oferece uma API Amazon Scraper gerenciada. Você precisará da sua chave API para autenticação.
Escolhendo um scraper da Amazon
Comece abrindo a Biblioteca de Scrapers da Bright Data.
Na lista de scrapers disponíveis, selecione o scraper da Amazon que corresponda ao seu caso de uso, como:
- Detalhes do produto por ASIN
- Resultados da pesquisa
- Avaliações
Cada scraper é projetado para um tipo específico de dados da Amazon.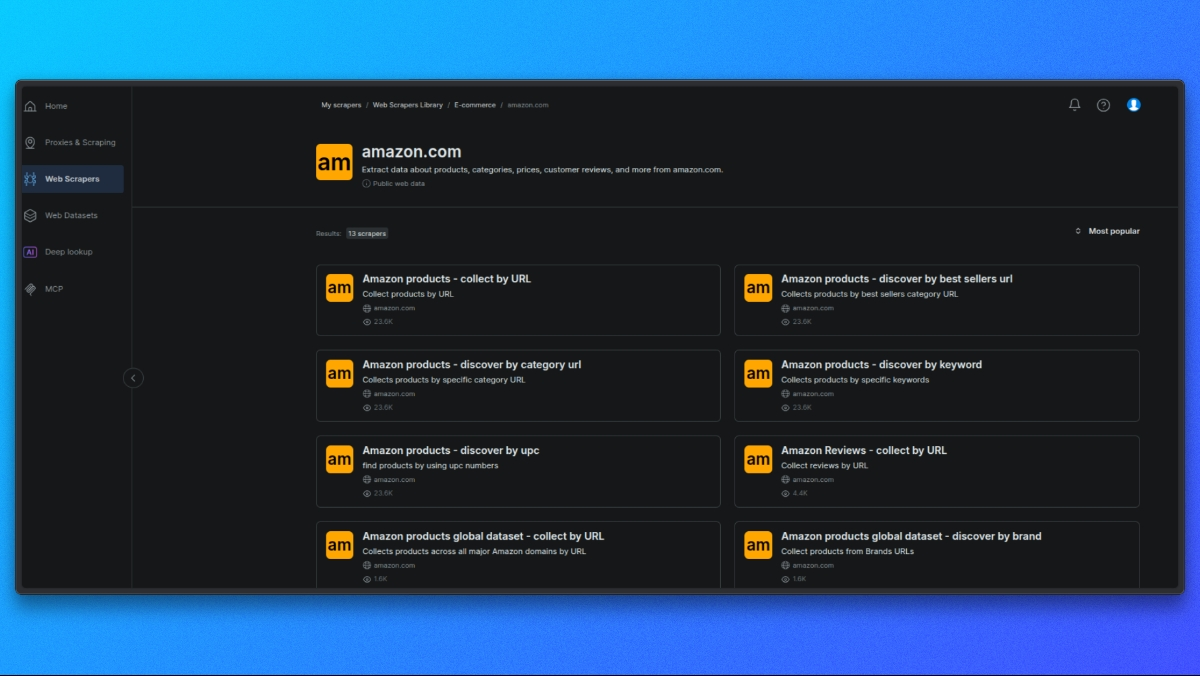
Selecione o endpoint do Scraper
Cada scraper oferece diferentes pontos finais, dependendo dos dados que você deseja (por exemplo, detalhes do produto, resultados de pesquisa, avaliações).
Clique no endpoint adequado ao seu caso de uso.
Crie sua solicitação
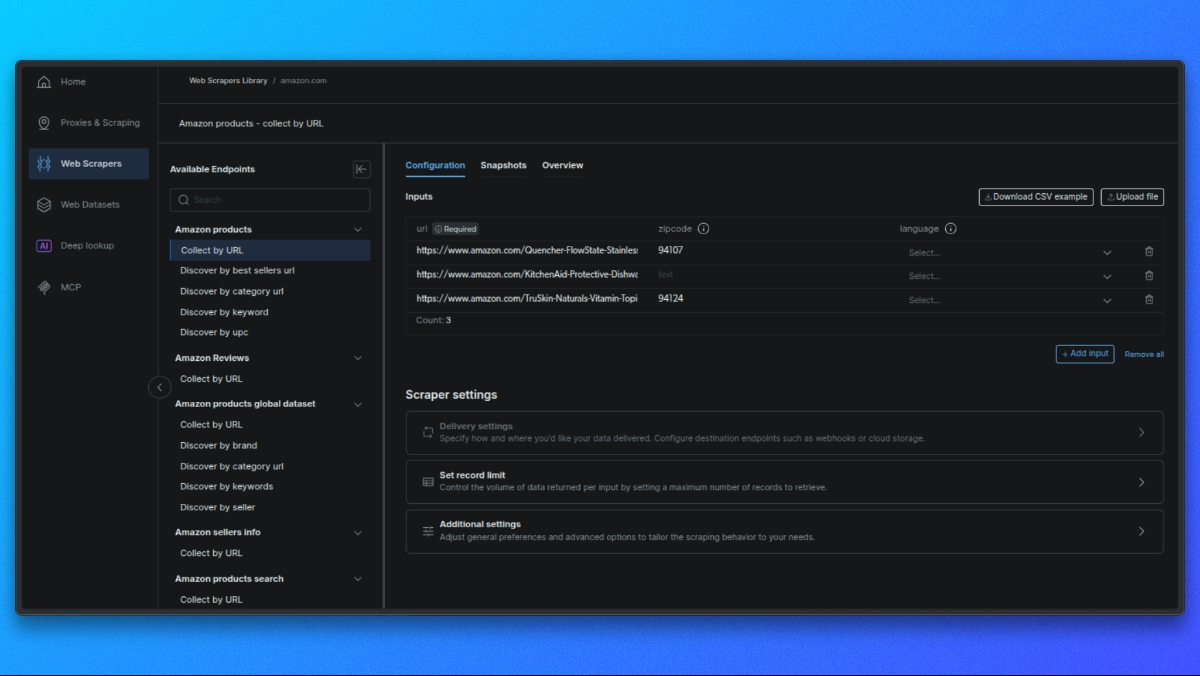
No painel central, você verá um formulário para configurar sua solicitação:
- Entrada única: cole uma URL do produto, ASIN ou palavra-chave.
- CSV em massa: carregue um arquivo CSV com várias entradas para processamento em lote.
Configurações opcionais: - Esquema de saída: selecione apenas os campos necessários.
- Armazenamento externo: configure S3, GCS ou Azure para entrega direta.
- URL do webhook: defina um webhook para receber os resultados automaticamente.
Faça a solicitação de API
Aqui está um exemplo básico usando curl para uma página de produto:
curl -i --silent --compressed "https://api.brightdata.com/dca/trigger?customer=hl_ee3f47e5&zone=YOUR_ZONE_NAME"
-H "Content-Type: application/json"
-H "Authorization: Bearer YOUR_API_KEY"
-d '{
"input": {
"url": "https://www.amazon.com/dp/B08L5TNJHG"
}
}'Substitua YOUR_ZONE_NAME e YOUR_API_KEY pela sua zona e chave API reais.
### Recupere seus resultados
- Para trabalhos em tempo real (até 20 URLs), você obterá os resultados diretamente.
- Para trabalhos em lote, você receberá um ID de trabalho para consultar os resultados ou obtê-los por meio de webhook/armazenamento externo.
Agora, vamos ver como criar um scraper personalizado com os proxies residenciais da Bright Data.
Configuração do projeto
Você pode seguir este tutorial usando o código do projeto disponível no repositório.
Antes de começar, certifique-se de que os seguintes pré-requisitos estejam instalados no seu sistema.
Pré-requisitos
Este projeto requer:
- Python 3.10+
- pip para gerenciamento de dependências
- Node.js 18+ (exigido pelo Vercel)
- Vercel CLI
Além disso, você precisará de:
- Uma conta Bright Data
- Acesso ao Web MCP da Bright Data
- Claude Desktop
Instalando dependências
Instale as dependências Python necessárias usando o arquivo requirements.txt fornecido:
pip install -r requirements.txtIsso instala todas as bibliotecas usadas para busca de páginas, automação do navegador, análise de HTML e extração de dados.
Certificado CA da Bright Data
Este projeto usa um certificado Bright Data CA para verificação TLS ao encaminhar solicitações através do Proxy.
Certifique-se de que o arquivo do certificado exista no seguinte caminho:
certs/brightdata-ca.crtEste arquivo é passado para o cliente HTTP durante as solicitações. Se estiver ausente ou referenciado incorretamente, as solicitações da Amazon falharão devido a erros de verificação TLS.
Configuração do Vercel
Este projeto foi projetado para ser executado como uma função sem servidor Vercel.
O arquivo api/search.py serve como ponto de entrada da API e é executado pelo Vercel em resposta às solicitações HTTP recebidas.
Certifique-se de que o Vercel CLI esteja instalado e autenticado:
vercel login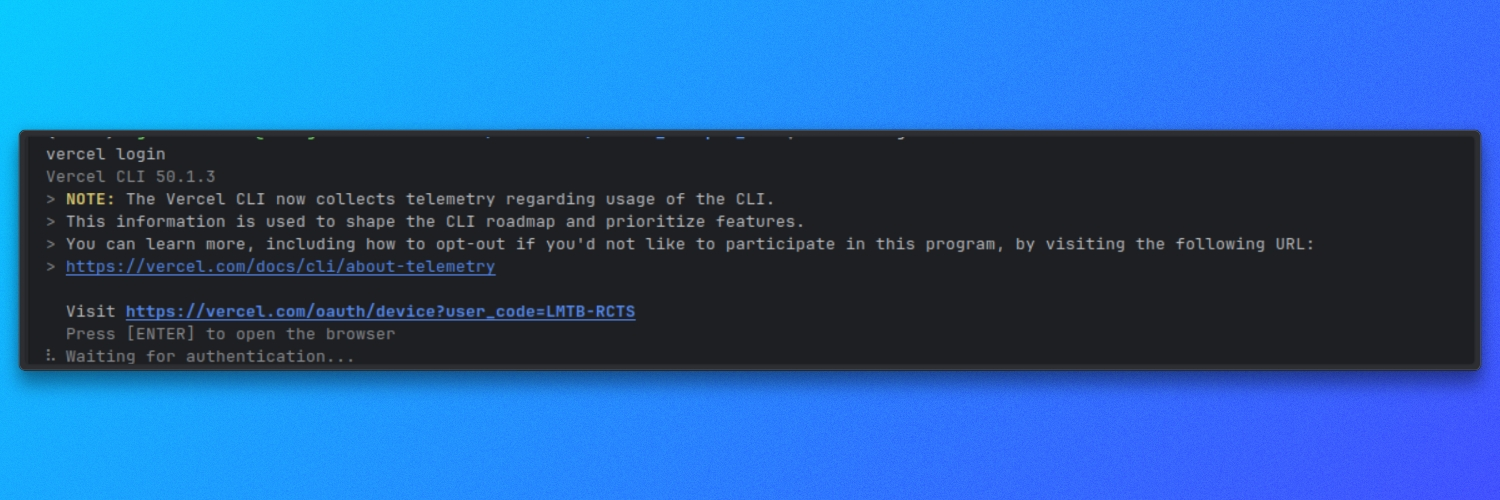
Variáveis de ambiente
O projeto usa configuração baseada no ambiente para definições de tempo de execução.
Crie um arquivo .env na raiz do projeto e defina as variáveis necessárias, conforme especificado no repositório. Esses valores controlam como o scraper busca, renderiza e processa as páginas da Amazon.
Com as dependências instaladas e as variáveis de ambiente configuradas, o projeto está pronto para uso.
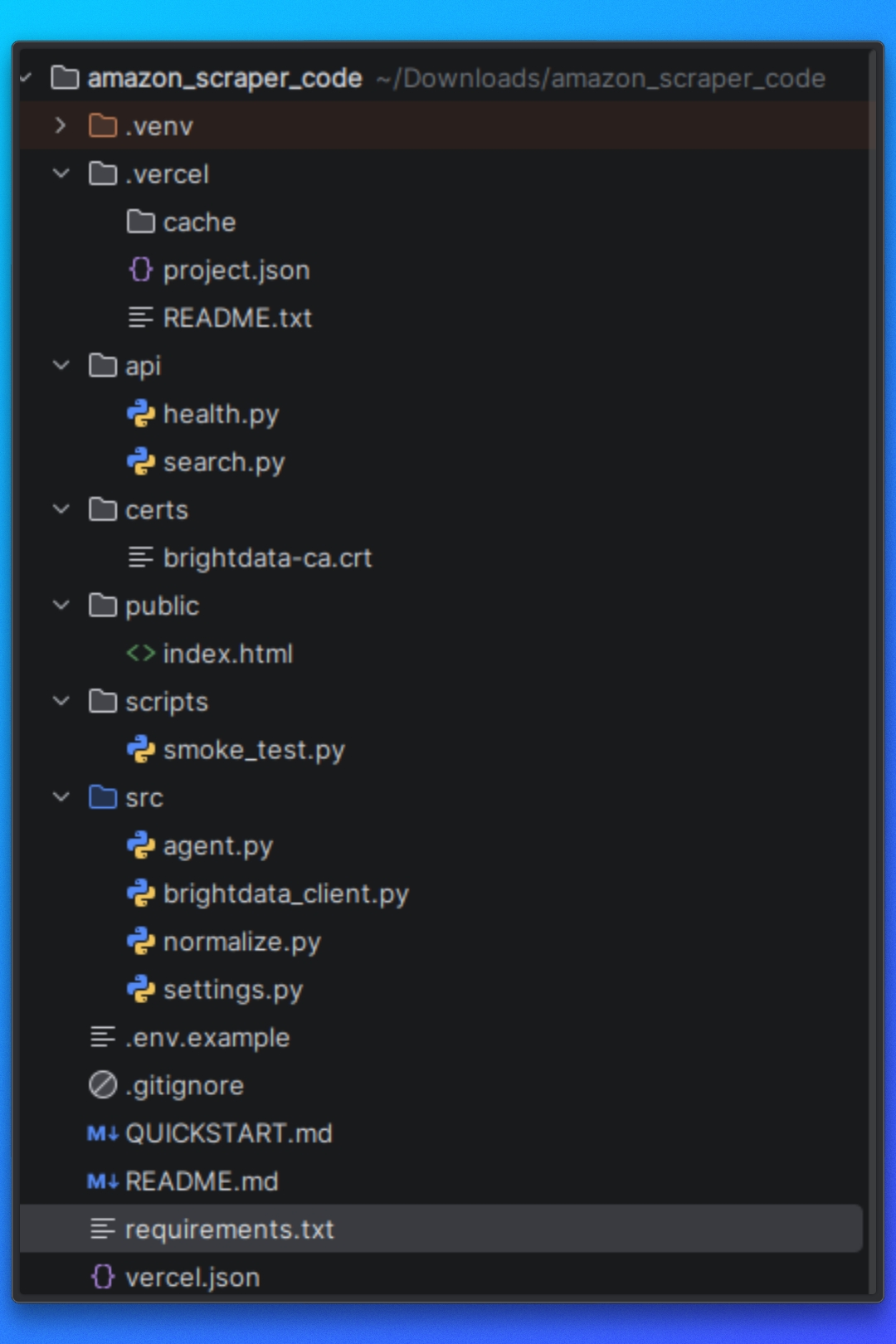
Entendendo a estrutura do projeto
Antes de executar o scraper, precisamos entender como o projeto está organizado e como o pipeline de scraping flui do início ao fim.
O projeto é estruturado em torno de uma separação clara de responsabilidades.
Configuração
Esta parte do projeto define os alvos da Amazon, as opções de tempo de execução e o comportamento do scraper. Essas configurações controlam o que é raspado e como o scraper opera.
Busca e renderização de páginas
Esta parte do projeto é responsável por carregar as páginas da Amazon e retornar HTML utilizável. Ela lida com a navegação, o carregamento da página e a execução do JavaScript para que a lógica downstream funcione com o conteúdo totalmente renderizado.
Lógica de extração
Quando o HTML está disponível, a camada de extração analisa a página e extrai dados estruturados. Isso inclui a lógica para as páginas de resultados de pesquisa da Amazon e para as páginas de produtos individuais.
Fluxo de execução
O fluxo de execução coordena a busca, a renderização, a extração e a saída. Ele garante que cada etapa seja executada na ordem correta.
Tratamento da saída
Os dados extraídos são gravados em disco em um formato estruturado, facilitando a inspeção ou o consumo em outros fluxos de trabalho.
Essa estrutura mantém o scraper modular e facilita a reutilização de componentes individuais, especialmente ao integrar métodos de busca externos, como o Web MCP da Bright Data, mais adiante neste tutorial.
Com essa visão geral em mãos, podemos passar para a configuração dos destinos da Amazon e definir quais dados o scraper deve coletar.
Configurando os alvos da Amazon
Nesta seção, configuraremos duas coisas:
- A palavra-chave de pesquisa da Amazon que queremos coletar
- As credenciais da Bright Data necessárias para buscar páginas da Amazon com sucesso
1. Passando a palavra-chave de pesquisa da Amazon
Enviamos nossa palavra-chave da Amazon usando um parâmetro de consulta chamado q.
Isso é feito em api/search.py. A API lê q da URL da solicitação e para imediatamente se ela estiver faltando:
# api/search.py
query = query_params.get("q", [None])[0]
if not query:
self._send_json_response(400, {"error": "Missing required parameter: q"})
returnO que isso significa:
Devemos chamar o endpoint com ?q=...
Se esquecermos q, receberemos uma resposta 400 e o scraper não será executado
Definindo quantos produtos queremos
Também podemos controlar quantos produtos retornamos usando o parâmetro opcional limit.
Ainda em api/search.py, analisamos o limite, convertemos para um número inteiro e o restringimos a um intervalo seguro:
# api/search.py
limit_str = query_params.get("limit", [None])[0]
limit = DEFAULT_SEARCH_LIMIT
if limit_str:
try:
limit = int(limit_str)
limit = min(limit, MAX_SEARCH_LIMIT)
limit = max(1, limit)
exceto ValueError:
limite = DEFAULT_SEARCH_LIMITPortanto:
Se não passarmos o limite, usamos o padrão.
Se passarmos algo inválido, voltamos ao padrão.
Se passarmos um valor maior do que o permitido, ele será limitado.
Os valores padrão e máximo são definidos em src/settings.py:
# src/settings.py
DEFAULT_SEARCH_LIMIT = 10
MAX_SEARCH_LIMIT = 50Se quisermos alterar o comportamento padrão, é aqui que o fazemos.
2. Mapeando nossa consulta para o endpoint de pesquisa da Amazon
Depois de obtermos q, buscamos os resultados da pesquisa da Amazon através da Bright Data usando fetch_products(query, limit):
# api/search.py
raw_response = fetch_products(query, limit)O endpoint da Amazon que está sendo rastreado é definido em src/brightdata_client.py:
# src/brightdata_client.py
AMAZON_SEARCH_URL = "https://www.amazon.com/s"E quando buscamos os resultados, passamos nossa palavra-chave para a Amazon usando o parâmetro k:
# src/brightdata_client.py
r = requests.get(
AMAZON_SEARCH_URL,
params={"k": query},
proxies=proxies,
headers=headers,
timeout=60,
verify=BRIGHTDATA_CA_CERT_PATH,
)Isso significa:
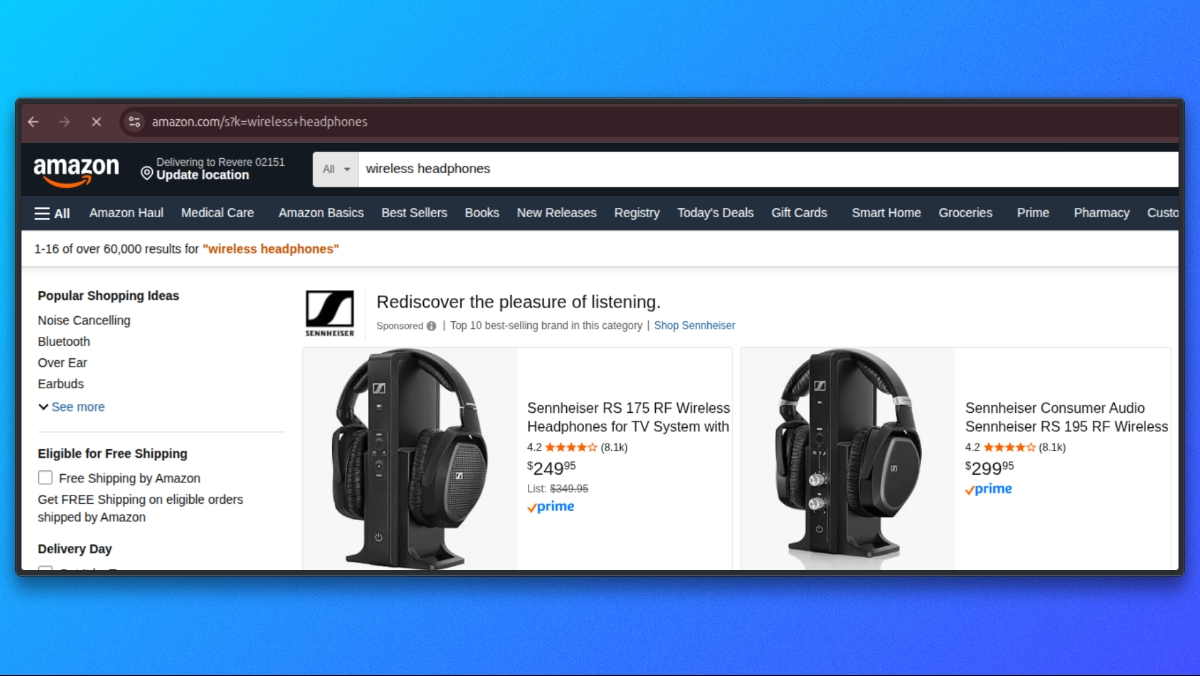
- Nosso parâmetro API é
q - O parâmetro de pesquisa da Amazon é
k - Se fornecermos q=fones de ouvido sem fio, a solicitação será enviada à Amazon como
https://www.amazon.com/s?k=wireless+headphones
3. Configurando as credenciais da Bright Data
Para enviar solicitações através da Bright Data, precisamos das credenciais do Proxy disponíveis como variáveis de ambiente.
Em src/settings.py, carregamos as configurações da Bright Data assim:
# src/settings.py
BRIGHTDATA_USERNAME = os.getenv('BRIGHTDATA_USERNAME', '')
BRIGHTDATA_PASSWORD = os.getenv('BRIGHTDATA_PASSWORD', '')
BRIGHTDATA_PROXY_HOST = os.getenv('BRIGHTDATA_PROXY_HOST', 'brd.superproxy.io')
BRIGHTDATA_PROXY_PORT = os.getenv('BRIGHTDATA_PROXY_PORT', 'your_port)No seu arquivo .env, adicione as seguintes credenciais:
BRIGHTDATA_USERNAME=seu_nome_de_usuário_brightdata
BRIGHTDATA_PASSWORD=sua_senha_brightdata
BRIGHTDATA_PROXY_HOST=brd.superproxy.io
BRIGHTDATA_PROXY_PORT=sua_portaQuando executamos o scraper, esses valores são usados para construir a URL do Proxy Bright Data dentro de src/brightdata_client.py:
# src/brightdata_client.py
proxy_url = (
f"http://{BRIGHTDATA_USERNAME}:{BRIGHTDATA_PASSWORD}"
f"@{BRIGHTDATA_PROXY_HOST}:{BRIGHTDATA_PROXY_PORT}")
proxies = {"http": proxy_url, "https": proxy_url}Se não definirmos BRIGHTDATA_USERNAME ou BRIGHTDATA_PASSWORD, o scraper falhará logo no início com um erro claro:
# src/brightdata_client.py
if not BRIGHTDATA_USERNAME or not BRIGHTDATA_PASSWORD:
raise ValueError(
"Credenciais de Proxy Bright Data não configuradas. "
"Defina BRIGHTDATA_USERNAME e BRIGHTDATA_PASSWORD."
)Com nossa palavra-chave e as credenciais do Bright Data configuradas, estamos prontos para buscar páginas da Amazon.
Buscando páginas da Amazon
Nesta fase, já validamos a entrada e configuramos o Bright Data. Agora vamos nos concentrar em onde a solicitação da Amazon é executada e quais são as premissas mínimas que ela faz.
Todas as solicitações da Amazon são enviadas de src/brightdata_client.py.
Ponto final de pesquisa da Amazon
Definimos o endpoint de pesquisa da Amazon uma vez e o reutilizamos para todas as solicitações de pesquisa:
# src/brightdata_client.py
AMAZON_SEARCH_URL = "https://www.amazon.com/s"Cabeçalhos de solicitação
Enviamos cabeçalhos genéricos, semelhantes aos do navegador, para garantir que a Amazon retorne o layout HTML padrão para desktop. Esses cabeçalhos não estão vinculados ao sistema operacional do usuário.
# src/brightdata_client.py
headers = {
"User-Agent": (
"Mozilla/5.0 "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0 Safari/537.36"
),
"Accept-Language": "en-US,en;q=0.9",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
}Enviando a solicitação
Com o endpoint, os cabeçalhos e a configuração do Proxy já definidos, executamos a solicitação da Amazon:
# src/brightdata_client.py
response = requests.get(
AMAZON_SEARCH_URL,
params={"k": query},
proxies=proxies,
headers=headers,
timeout=60,
verify=BRIGHTDATA_CA_CERT_PATH,)
response.raise_for_status()
html = response.text or ""No final dessa chamada, html contém o conteúdo bruto da página de pesquisa da Amazon.
Com a fase de busca concluída, agora podemos passar para o parsing do HTML e extrair links de produtos e metadados da página de resultados de pesquisa da Amazon.
Extraindo resultados de pesquisa
Depois que a página de pesquisa da Amazon é buscada, a próxima etapa é extrair as listagens de produtos do HTML retornado. Toda essa etapa ocorre dentro do src/brightdata_client.py.
Após a conclusão da solicitação, passamos o HTML bruto para o analisador interno:
products = _parse_amazon_search_html(html, limit=limit)
return {"products": products}Toda a lógica de extração dos resultados da pesquisa está dentro de _parse_amazon_search_html.
Parsing o HTML
Começamos analisando o HTML bruto em uma árvore DOM usando o BeautifulSoup. Isso nos permite consultar a estrutura da página de maneira confiável.
soup = BeautifulSoup(html, "lxml")Também normalizamos o limite solicitado para garantir que sempre extraímos pelo menos um item:
max_items = max(1, int(limite)) if isinstance(limite, int) else 10Localizando contêineres de resultados de pesquisa
As páginas de pesquisa da Amazon incluem muitos elementos que não são listagens de produtos. Para isolar os resultados reais, primeiro direcionamos o contêiner de resultados de pesquisa principal da Amazon:
containers = soup.select('div[data-component-type="s-search-result"]')Como alternativa, também procuramos elementos que contenham um atributo data-asin válido:
fallback = soup.select('div[data-asin]:not([data-asin=""])')Se o seletor principal não retornar resultados, mas o alternativo sim, mudamos para o alternativo:
if not containers and fallback:
containers = fallbackIsso nos dá resiliência contra pequenas variações de layout, mantendo a extração restrita às entradas reais do produto.
Iterando pelos resultados
Iteramos pelos contêineres selecionados e paramos quando atingimos o limite solicitado:
produtos = []
para c em contêineres:
se len(produtos) >= max_items:
breakPara cada contêiner, extraímos os campos principais. Se um cartão de produto não contiver um título e uma URL, nós o ignoramos.
title = _extract_title(c)
url = _extract_url(c)
if not title or not url:
continueExtraindo campos do produto
Cada cartão de produto é analisado usando pequenas funções auxiliares, todas definidas no mesmo arquivo.
imagem = _extract_image(c)
classificação = _extract_rating(c)
avaliações = _extract_reviews_count(c)
preço = _extract_price(c)Em seguida, montamos um objeto de produto estruturado:
products.append(
{
"title": title,
"price": price,
"rating": rating,
"reviews": reviews,
"url": url,
"image": image,
}
)Auxiliares de extração de campos
Cada auxiliar se concentra em um campo e lida com marcações ausentes ou parciais com segurança.
Extração de título
def _extract_title(container) -> str:
a = container.select_one('a.a-link-normal[href*="/dp/"]')
if a:
t = a.get_text(" ", strip=True)
if t:
return t
img = container.select_one("img.s-image")
alt = img.get("alt") if img else ""
return alt.strip() if isinstance(alt, str) else ""URL do produto
def _extract_url(container) -> str:
a = container.select_one('a.a-link-normal[href*="/dp/"]')
href = a.get("href") se a, caso contrário ""
if isinstance(href, str) and href:
return "https://www.amazon.com" + href if href.startswith("/") else href
return ""Imagem
def _extract_image(container) -> Optional[str]:
img = container.select_one("img.s-image")
src = img.get("src") if img else None
return src if isinstance(src, str) and src else NoneClassificação
def _extract_rating(container) -> Optional[float]:
el = container.select_one("span.a-icon-alt")
text = el.get_text(" ", strip=True) if el else ""
if not text:
el = container.select_one('span:contains("out of 5 stars")')
text = el.get_text(" ", strip=True) se el, caso contrário, ""
se não houver texto:
retorne None
m = re.search(r"(d+(?:.d+)?)", text)
retorne float(m.group(1)) se m, caso contrário, NoneContagem de avaliações
def _extract_reviews_count(container) -> Optional[int]:
el = container.select_one("span.s-underline-text")
text = el.get_text(" ", strip=True) if el else ""
m = re.search(r"(d[d,]*)", text)
return int(m.group(1).replace(",", "")) if m else NonePreço
def _extract_price(container) -> str:
whole = container.select_one("span.a-price-whole")
frac = container.select_one("span.a-price-fraction")
whole_text = whole.get_text(strip=True).replace(",", "") if whole else ""
frac_text = frac.get_text(strip=True) se frac, caso contrário, ""
se não whole_text:
retornar ""
retornar f"${whole_text}.{frac_text}" se frac_text, caso contrário, f"${whole_text}"No final desta etapa, temos uma lista de entradas de produtos estruturadas extraídas diretamente dos resultados de pesquisa da Amazon.
Cada item inclui:
- título
- preço
- classificação
- avaliações
- URL do produto
- URL da imagem
Com a extração dos resultados da pesquisa concluída, passamos para a normalização e o retorno da resposta, que é tratada em src/normalize.py.
Normalizando a resposta
Neste ponto, nossa extração de pesquisa retorna objetos de produto, mas os campos ainda não estão padronizados. Por exemplo, o preço ainda é uma string (como “$129,99”), a contagem de avaliações pode incluir vírgulas e alguns campos podem estar faltando, dependendo do cartão.
Para tornar a resposta da API consistente, normalizamos tudo dentro de src/normalize.py.
Em api/search.py, a normalização ocorre logo após buscarmos os resultados brutos:
# api/search.py
normalized = normalize_response(raw_response, query)Essa única chamada converte a saída bruta da Bright Data em uma resposta limpa que sempre se parece com:
itens: uma lista de objetos de produto normalizadoscount: quantos itens retornamos
Normalizando uma resposta dict
normalize_response suporta vários tipos de entrada. Em nosso fluxo de API, passamos um dict como {"products": [...]} de fetch_products(...).
Aqui está o ramo dict:
# src/normalize.py
if isinstance(raw_response, dict):
products = raw_response.get("products", []) or raw_response.get("items", [])
normalized_items = [normalize_product(p) for p in products if isinstance(p, dict)]
return {"items": normalized_items[:limit], "count": len(normalized_items[:limit])}O que isso faz:
- Lê os produtos de products (ou itens, se houver)
- Normaliza cada produto usando normalize_product
- Retorna uma carga útil consistente
{"items": [...], "count": N}
Normalizando um único produto
Cada produto é normalizado por normalize_product(...).
O preço é analisado em um valor numérico e um código de moeda usando parse_price(...):
# src/normalize.py
price_str = raw_product.get("price", "")
price, currency = parse_price(price_str)A classificação é convertida em um float, se possível:
# src/normalize.py
rating = raw_product.get("rating")
if rating is not None:
try:
rating = float(rating)
except (ValueError, TypeError):
rating = None
else:
rating = NoneAs contagens de avaliações são normalizadas em um número inteiro, suportando as chaves reviews e reviews_count:
# src/normalize.py
reviews_count = raw_product.get("reviews") ou raw_product.get("reviews_count")
se reviews_count não for None:
tente:
reviews_count = int(str(reviews_count).replace(",", ""))
exceto (ValueError, TypeError):
contagem_de_avaliações = Nenhum
caso contrário:
contagem_de_avaliações = NenhumPor fim, retornamos um objeto de produto padronizado:
# src/normalize.py
return {
"title": raw_product.get("title", ""),
"price": price,
"currency": currency,
"rating": rating,
"reviews_count": reviews_count,
"url": raw_product.get("url", ""),
"image": raw_product.get("image"),
"source": "brightdata",
}Com a normalização concluída, agora temos uma lista de itens consistente que é segura para retornar da API e fácil para os clientes consumirem.
Executando o Scraper no Vercel
Este scraper é executado como uma função sem servidor do Vercel. Localmente, nós o executamos usando o servidor de desenvolvimento do Vercel para que as rotas api/ se comportem da mesma forma que na produção.
Executar localmente com o Vercel
Na raiz do repositório, inicie o servidor de desenvolvimento:
vercel dev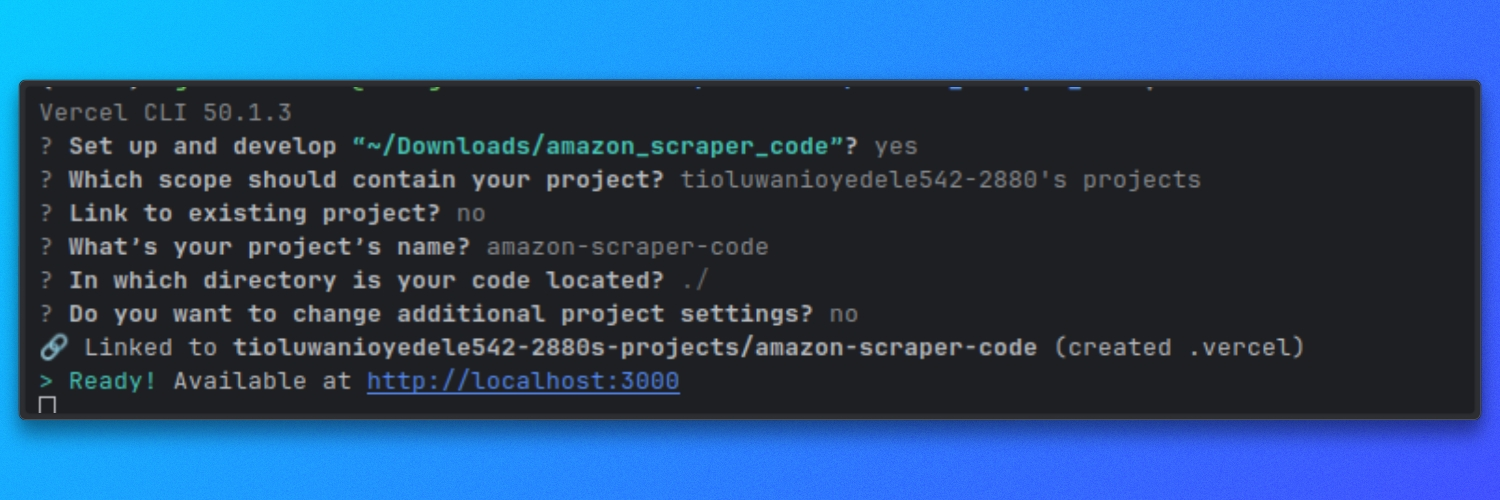
Por padrão, isso inicia o servidor em:
http://localhost
Agora temos nosso projeto completo de scraper em funcionamento. Você pode executá-lo e tentar fazer o scraping de diferentes produtos da Amazon.
Além disso, você também pode fazer scraping usando o Bright Data MCP com um agente de IA. Vamos ver como você pode fazer isso rapidamente.
Conectando o Claude Desktop ao Web MCP da Bright Data
O Claude Desktop deve ser configurado para iniciar o servidor Web MCP da Bright Data.
Abra o arquivo de configuração do Claude Desktop.
Você pode navegar até Configurações, clicar no ícone Desenvolvedor e selecionar Editar Configuração. Isso abre o arquivo de configuração usado pelo Claude Desktop.

Adicione a seguinte configuração e substitua YOUR_TOKEN_HERE pelo seu token da API da Bright Data:
{
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_TOKEN_HERE"
}
}
}
}Salve o arquivo e reinicie o Claude Desktop.
Assim que o Claude reiniciar, o Web MCP da Bright Data estará disponível como uma ferramenta.
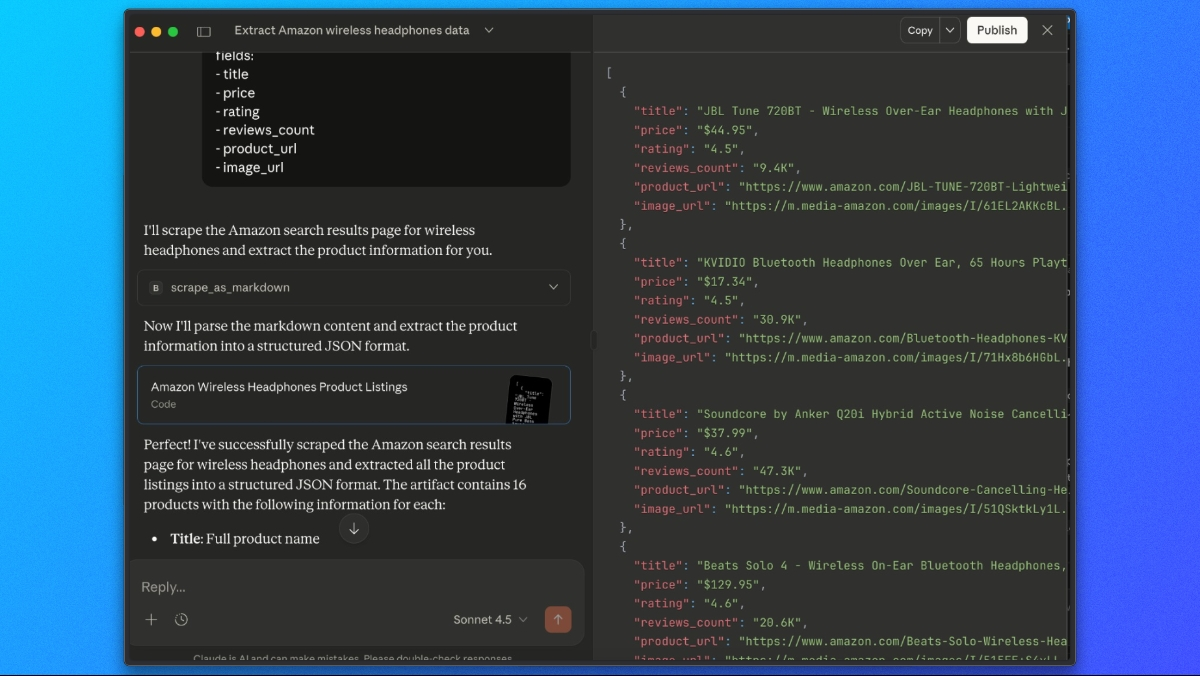
Extraindo listagens de produtos da Amazon com o Claude
Com o Web MCP da Bright Data conectado, podemos pedir ao Claude para buscar e extrair resultados de pesquisa da Amazon em uma única etapa.
Use um prompt como este:
Use a ferramenta scrape_as_markdown para acessar:
https://www.amazon.com/s?k=wireless+headphones
Em seguida, observe a saída do markdown e extraia todas as listagens de produtos para uma lista JSON com os seguintes campos:
- título
- preço
- classificação
- número de avaliações
- URL do produto
- URL da imagemO Claude irá buscar a página através do Web MCP da Bright Data, analisar o conteúdo renderizado e retornar uma resposta JSON estruturada contendo os dados do produto extraídos da Amazon.
Considerações finais
Neste tutorial, exploramos três maneiras de fazer scraping da Amazon usando a Bright Data:
- Amazon Scraper API– A maneira mais rápida de começar. Use endpoints pré-construídos para detalhes do produto, resultados de pesquisa e avaliações sem escrever nenhum código de scraping.
- Scraper personalizado com proxies da Bright Data– Crie um scraper pronto para produção como uma função sem servidor Vercel com controle total sobre a obtenção, extração e normalização.
- Claude Desktop com Web MCP– Extraia dados da Amazon de forma interativa usando extração com IA sem escrever código.
Ignore completamente a extração
Se você precisa de dados da Amazon em grande escala e prontos para produção sem construir infraestrutura, considere os Conjuntos de Dados da Amazon da Bright Data. Tenha acesso a:
- Listas de produtos, preços e avaliações pré-coletados
- Dados históricos para análise de tendências
- Conjuntos de dados prontos para uso e atualizados regularmente
- Cobertura em vários mercados da Amazon
Se você precisa de scraping em tempo real ou conjuntos de dados prontos, a Bright Data fornece a infraestrutura para acessar os dados da Amazon de forma confiável e em grande escala.




