

Neste tutorial, você explorará:
- A definição de scraping de comércio eletrônico e por que ele é útil
- Os tipos de ferramentas de scraping de comércio eletrônico
- Os dados que você pode extrair de plataformas de comércio eletrônico
- Como criar um script de scraping de comércio eletrônico com Python
- Os desafios do scraping em sites de comércio eletrônico
Vamos começar!
O que é Scraping de dados de sites de comércio eletrônico?
O scraping de dados de sites de comércio eletrônico é o processo de extrair dados de plataformas de varejo online, como Amazon, Walmart, eBay e sites semelhantes. Embora isso possa ser feito copiando os dados manualmente, geralmente é realizado usando ferramentas ou scripts automatizados.
Os dados extraídos de sites de comércio eletrônico podem ajudar empresas, pesquisadores e desenvolvedores a:
- Analisar as flutuações dos preços dos produtos
- Acompanhar pontuações de avaliações
- Identificar tendências de mercado
- Estudar os concorrentes
Essas informações permitem a tomada de decisões informadas e o planejamento estratégico.
Observe que uma ferramenta de extração de dados de comércio eletrônico é comumente chamada de Scraper de comércio eletrônico.
Tipos de scrapers de comércio eletrônico
Abaixo está uma lista de alguns dos tipos mais populares de ferramentas de Scraper de comércio eletrônico:
- Scripts personalizados: scripts personalizados para extrair dados específicos de comércio eletrônico usando linguagens de Scraping de dados, como Python ou JavaScript.
- Scrapers sem código: ferramentas fáceis de usar que permitem a extração de dados sem codificação, ideais para usuários sem conhecimentos técnicos. Descubra os melhores Scrapers sem código.
- API de Scraping de dados: interfaces que fornecem dados estruturados de comércio eletrônico programaticamente, geralmente com suporte para extração em tempo real ou em grande escala.
- Extensões de scraping: complementos baseados em navegador que simplificam a coleta de dados diretamente das páginas da web de comércio eletrônico enquanto você as navega.
Neste artigo, vamos nos concentrar especificamente na criação de um bot personalizado de Scraping de dados de comércio eletrônico.
Dados a serem extraídos de sites de comércio eletrônico
Os scrapers de comércio eletrônico geralmente ajudam a recuperar os seguintes dados:
- Detalhes do produto: nomes, descrições, especificações e imagens.
- Informações sobre preços: preços atuais, descontos e tendências históricas de preços.
- Avaliações dos clientes: classificações, conteúdo das avaliações e feedback dos clientes.
- Categorias e tags: classificação e categorização de produtos.
- Informações do vendedor: nomes, avaliações e detalhes de contato do vendedor.
- Detalhes de envio: custos, prazos de entrega e políticas de envio.
- Disponibilidade de estoque: níveis de estoque e notificações de falta de estoque.
- Dados de marketing: listagens de produtos, estratégias de preços, promoções e descontos sazonais.
Agora, aprenda a criar um Scraper de comércio eletrônico em Python!
Como criar um Scraper de comércio eletrônico
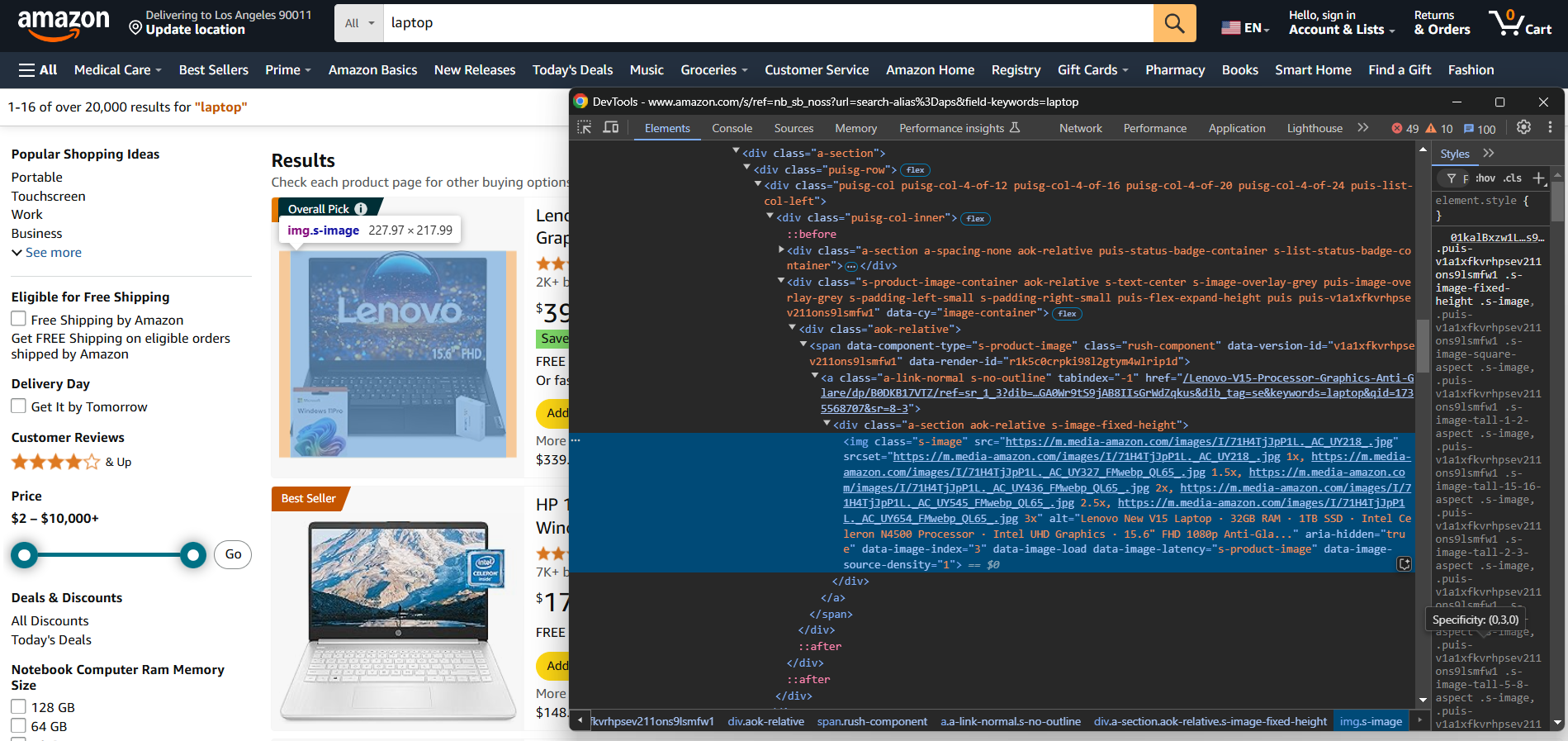
Para criar manualmente um Scraper de comércio eletrônico, primeiro você precisa se familiarizar com o site de destino. Inspecione a página de destino com o DevTools para:
- Entender sua estrutura
- Determinar quais dados você pode extrair
- Decidir quais bibliotecas de scrapping usar
Para sites de comércio eletrônico mais simples, as duas bibliotecas Python a seguir são suficientes:
- Requests: para enviar solicitações HTTP. Ela ajuda você a obter o conteúdo HTML bruto de uma página da web.
- Beautiful Soup: para parsing de documentos HTML e XML. Simplifica a navegação e a extração de dados da estrutura HTML de uma página. Saiba mais em nosso guia sobre scraping com Beautiful Soup.
Você pode instalar ambas com:
pip install requests beautifulsoup4
Para plataformas de comércio eletrônico que carregam dados dinamicamente ou dependem muito da renderização JavaScript, você precisará de ferramentas de automação de navegador, como o Selenium. Para obter mais informações, consulte nosso tutorial sobre scraping com Selenium.
Você pode instalar o Selenium com:
pip install selenium
Em seguida, o processo de Scraping de dados é o seguinte:
- Conecte-se ao site de destino: use Requests ou Selenium para recuperar e realizar o Parsing do HTML da página.
- Selecione os elementos de interesse: localize elementos específicos (por exemplo, imagem do produto, preço, descrição) na estrutura HTML e selecione-os com seletores CSS ou expressões XPath.
- Extraia os dados: obtenha as informações desejadas desses elementos HTML.
- Limpe os dados: processe os dados extraídos para remover conteúdo desnecessário ou reformate-os, se necessário.
- Exportar os dados: salve os dados limpos em um formato preferido, como JSON ou CSV.
As vantagens dessa abordagem incluem ter controle total sobre o processo de extração de dados e a capacidade de personalizá-lo para atender a requisitos específicos. No entanto, isso requer conhecimento técnico para design e manutenção. Além disso, cada site de comércio eletrônico necessita de seu próprio script.
Nos próximos capítulos, você encontrará exemplos de scripts de scraping de comércio eletrônico em Python para extrair dados da Amazon, Walmart e eBay!
Extração da Amazon
- Página de destino: página de pesquisa “laptop” na Amazon
- URL da página de destino: https://www.amazon.com/s?k=laptop&ref=nb_sb_noss
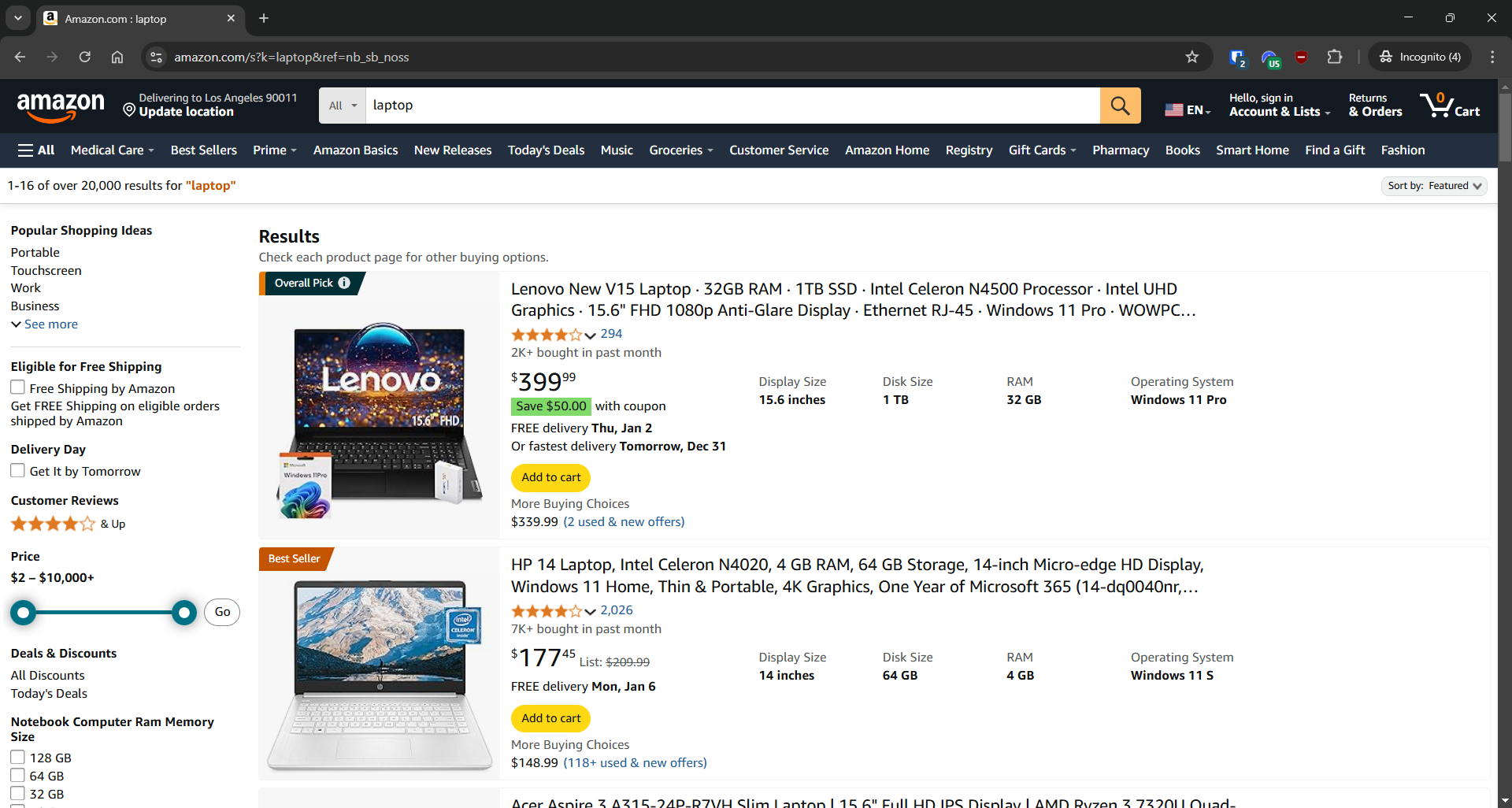
A Amazon possui medidas anti-scraping projetadas para bloquear solicitações que não se originam de um navegador. Para contornar essas restrições, você precisa usar uma ferramenta de automação de navegador como o Selenium:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import json
# Inicializar o WebDriver
driver = webdriver.Chrome(service=Service())
# Abrir a página inicial da Amazon no navegador
driver.get("https://amazon.com/")
# Preencha o formulário de pesquisa
search_input_element = driver.find_element(By.ID, "twotabsearchtextbox")
search_input_element.send_keys("laptop")
# Localize o botão de pesquisa e clique nele
search_button_element = driver.find_element(By.ID, "nav-search-submit-button")
search_button_element.click()
# Agora você está na página de destino
# Onde armazenar os dados coletados
products = []
# Selecione todos os elementos do produto na página
product_elements = driver.find_elements(By.CSS_SELECTOR, "[role="listitem"][data-asin]")
# Itere sobre eles
for product_element in product_elements:
# Lógica de extração
url_element = product_element.find_element(By.CSS_SELECTOR, ".a-link-normal")
url = url_element.get_attribute("href")
name_element = product_element.find_element(By.CSS_SELECTOR, "h2")
name = name_element.text
image_element = product_element.find_element(By.CSS_SELECTOR, "img[data-image-load]")
image = image_element.get_attribute("src")
# Preencha um novo objeto com os dados coletados
product = {
"url": url,
"name": name,
"image": image
}
# Adicione-o à lista de produtos coletados
products.append(product)
# Exporte os dados para um arquivo JSON
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)
Execute o scraper do Amazon eCommerce acima e, se a Amazon não mostrar um CAPTCHA, ele gerará o seguinte resultado:
[
{
"url": "https://www.amazon.com/A315-24P-R7VH-Display-Quad-Core-Processor-Graphics/dp/B0BS4BP8FB/ref=sr_1_3?crid=1W7R6D59KV9L1&dib=eyJ2IjoiMSJ9.iBCtzwnCm6CE8Bx8hKmQ8ez6PkzMg3asWNhAxvflBg3pKVi5IxQUSDpcaksihO-jEO1nyLGkdoGk_2hNyQ7EWOa6epS_hZHxqV7msqdtcEZv4irFZRnYHcP5YnEwKu17BjsYS_IPI1tFVDS65v_roSCu_IiBNfotAEHSx4zOwQ4u1CRKfvnLjIX4VlECydRjsKaAQ-mErT89tyBUCfEGjzKPPZxwHi3Y0MoieuPceL8.jIuIrqzxNYISYPLHifRJq289Vy9Z6hqT8vmMcUQw9HY&dib_tag=se&keywords=laptop&qid=1735572968&sprefix=l%2Caps%2C271&sr=8-3",
"name": "Notebook Acer Aspire 3 A315-24P-R7VH Slim | Tela IPS Full HD de 15,6 polegadas | Processador AMD Ryzen 3 7320U Quad-Core | Placa de vídeo AMD Radeon | 8 GB de LPDDR5 | SSD NVMe de 128 GB | Wi-Fi 6 | Windows 11 Home no modo S",
"image": "https://m.media-amazon.com/images/I/61gKkYQn6lL._AC_UY218_.jpg"
},
// omitido por brevidade...
{
"url": "https://www.amazon.com/Lenovo-Newest-Flagship-Chromebook-HubxcelAccesory/dp/B0CBJ46QZX/ref=sr_1_8?crid=1W7R6D59KV9L1&dib=eyJ2IjoiMSJ9.iBCtzwnCm6CE8Bx8hKmQ8ez6PkzMg3asWNhAxvflBg3pKVi5IxQUSDpcaksihO-jEO1nyLGkdoGk_2hNyQ7EWOa6epS_hZHxqV7msqdtcEZv4irFZRnYHcP5YnEwKu17BjsYS_IPI1tFVDS65v_roSCu_IiBNfotAEHSx4zOwQ4u1CRKfvnLjIX4VlECydRjsKaAQ-mErT89tyBUCfEGjzKPPZxwHi3Y0MoieuPceL8.jIuIrqzxNYISYPLHifRJq289Vy9Z6hqT8vmMcUQw9HY&dib_tag=se&keywords=laptop&qid=1735572968&sprefix=l%2Caps%2C271&sr=8-8",
"name": "O mais recente Chromebook da Lenovo, computador portátil fino e leve com ecrã tátil FHD de 14 polegadas, processador MediaTek Kompanio 520 de 8 núcleos, 4 GB de RAM, 64 GB de eMMC, WiFi 6, Chrome OS+HubxcelAccesory, Abyss Blue",
"image": "https://m.media-amazon.com/images/I/61KlKRdsQ7L._AC_UY218_.jpg"
}
]
Observe que a Amazon ainda pode exibir um CAPTCHA e bloquear sua solicitação, mesmo que você esteja fazendo isso através do Selenium. Nesse caso, você deve verificar o SeleniumBase como alternativa. Caso contrário, continue lendo o artigo, pois apresentaremos uma solução definitiva.
Para um passo a passo completo, confira nosso tutorial detalhado sobre Scraping de dados na Amazon.
Raspagem do Walmart
- Página de destino: página de pesquisa “teclado” no Walmart
- URL da página de destino: https://www.walmart.com/search?q=keyboard
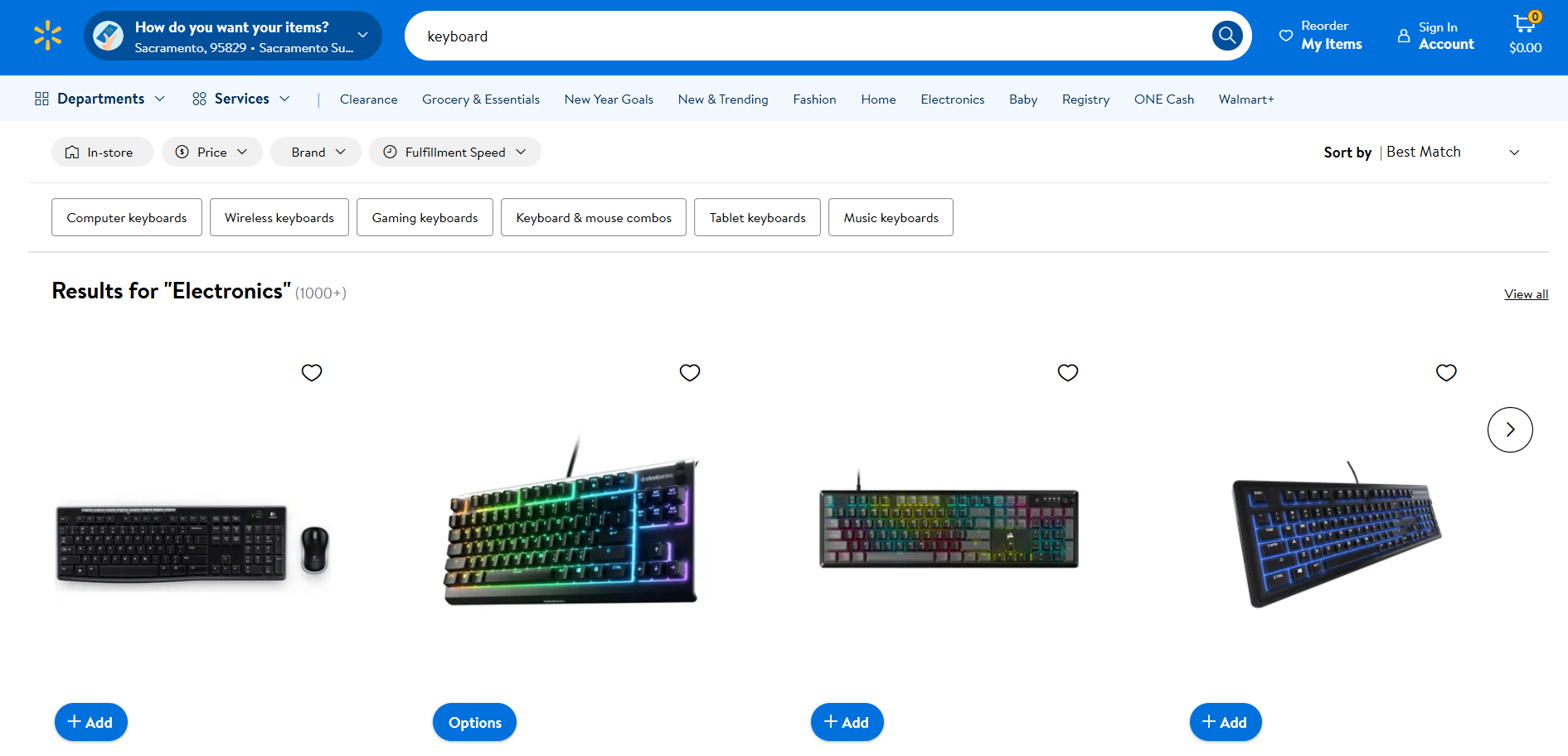
Assim como a Amazon, o Walmart usa soluções anti-bot para bloquear solicitações provenientes de clientes HTTP automatizados. Portanto, você pode fazer o scraping com o Selenium conforme abaixo:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import json
# Inicialize o WebDriver
driver = webdriver.Chrome(service=Service())
# Navegue até a página de destino
driver.get("https://www.walmart.com/search?q=keyboard")
# Onde armazenar os dados extraídos
products = []
# Selecione todos os elementos do produto na página
product_elements = driver.find_elements(By.CSS_SELECTOR, ".carousel-4[data-testid="carousel-container"] li")
# Iterar sobre eles
para product_element em product_elements:
# Lógica de extração
url_element = product_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
name_element = product_element.find_element(By.CSS_SELECTOR, "h3")
name = name_element.get_attribute("innerText")
image_element = product_element.find_element(By.CSS_SELECTOR, "img[data-testid="productTileImage"]")
image = image_element.get_attribute("src")
# Preencha um novo objeto com os dados extraídos
produto = {
"url": url,
"nome": nome,
"imagem": imagem
}
# Adicione-o à lista de produtos extraídos
produtos.append(produto)
# Exportar dados para um arquivo JSON
com open("products.json", "w", encoding="utf-8") como json_file:
json.dump(products, json_file, indent=4)
Execute o Scraper do Walmart e você obterá:
[
{
"url": "https://www.walmart.com/sp/track?bt=1&eventST=click&plmt=sp-search-middle~desktop~Results%20for%20%22Electronics%22&pos=1&tax=3944_1089430_132959_1008621_7197407&rdf=1&rd=https%3A%2F%2Fwww.walmart.com%2Fip%2FLogitech-920-004536-Mk270-Teclado-Rato-USB-Sem fios-Combo-Preto%2F28540111%3FclassType%3DREGULAR%26adsRedirect%3Dtrue&adUid=094fb4ae-62f3-4954-ae99-b2938550d72c&mloc=sp-search-middle&pltfm=desktop&pgId=keyboard&pt=search&spQs=sAX_0l4wzWXzBji34bVpmheXU7_ETXGbDXcA9LhcshG_YbqBx24VWzt7yesHivpt1lpckuNhxQqbLidA-d8L4agqx_YPQVlj2EfM_TnEyfsSWiTEkvBaqgkaMzy6bgIZ4eC8t9-qqz7qtb7uXMz3cH92UCf5EEgQlfKwnxJ-SAF1EW1ouCjC10Ur3hELs3143xQPjxNUSUoN8FIF12fxJmTlSlTe4makoj1s2NoubYTqnlJLs3pohowJCRFT76Vl&storeId=3081&couponState=na&bkt=ace1_default%7Cace2_default%7Cace3_default%7Ccoldstart_off%7Csearch_default&classType=REGULAR",
"name": "Logitech Wireless Combo MK270",
"image": "https://i5.walmartimages.com/seo/Logitech-920-004536-Mk270-Keyboard-Mouse-USB-Wireless-Combo-Black_99591453-341e-4c5b-937e-b2ab9b321519.3860011d84a23ccd0732e46474590b15.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
},
{
"url": "https://www.walmart.com/sp/track?bt=1&eventST=click&plmt=sp-search-middle~desktop~Results%20for%20%22Electronics%22&pos=2&tax=3944_1089430_132959_1008621_7197407&rdf=1&rd=https%3A%2F%2Fwww.walmart.com%2Fip%2FSteelSeries-Apex-3-TKL-RGB-Teclado-para-jogos-sem-teclado numérico-resistente à água e ao pó-PC e USB-A%2F996783321%3FclassType%3DVARIANT%26adsRedirect%3Dtrue&adUid=094fb4ae-62f3-4954-ae99-b2938550d72c&mloc=sp-search-middle&pltfm=desktop&pgId=keyboard&pt=search&spQs=Dp3ons-xIcmPw9Ze7UUZuW3PD9Dto_vYCLjglme5vSy5Ze1p4NXg3uzApRy4mgfB-dGDchsq6FDoaZeMy6Dmeagqx_YPQVlj2EfM_TnEyfv_0r9GA9WwEd1cWbcx63Diahe72Zw6lw8suSf-OFKKH6UaiJl_8Qtpar-x0VhgrMsbqG7gDKh5DkQZql3HeMLncWSwburhSEjvpT1dXlDoWKxUrZwxZhOMry-uCqhuSb7Y6B-xZGrNPjYyel0nw11Z&storeId=3081&couponState=na&bkt=ace1_default%7Cace2_default%7Cace3_default%7Ccoldstart_off%7Csearch_default&classType=VARIANT",
"name": "Teclado para jogos SteelSeries Apex 3 TKL RGB - Sem teclado numérico - Resistente à água e poeira - PC e USB-A",
"image": "https://i5.walmartimages.com/seo/SteelSeries-Apex-3-TKL-RGB-Gaming-Keyboard-Tenkeyless-Water-Dust-Resistant-PC-and-USB-A_876430c2-eed8-404a-aa55-1c66193daf8e.8c617e57ba48bc49d003f917f85cb535.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
},
// omitido por brevidade...
{
"url": "https://www.walmart.com/ip/DEP-06-Portable-Digital-Piano-with-X-Stand/7598762909?classType=REGULAR",
"name": "Piano digital portátil Donner com 88 teclas, teclado sintético, suporte em X, pedal, acompanhamento automático para iniciantes, 128 tons, 83 ritmos, compatível com USB/MIDI/Melodics, conexão sem fio",
"image": "https://i5.walmartimages.com/seo/DEP-06-Portable-Digital-Piano-with-X-Stand_1175fc1e-c191-4c71-9e9a-7e4a13274487.6673e0430c23d122744cfb63ccc8c155.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
}
]
Para obter mais orientações, leia nosso artigo sobre Scraping de dados do Walmart.
Scraping do eBay
- Página de destino: página de pesquisa “mouse” no eBay
- URL da página de destino: https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=mouse&_sacat=0
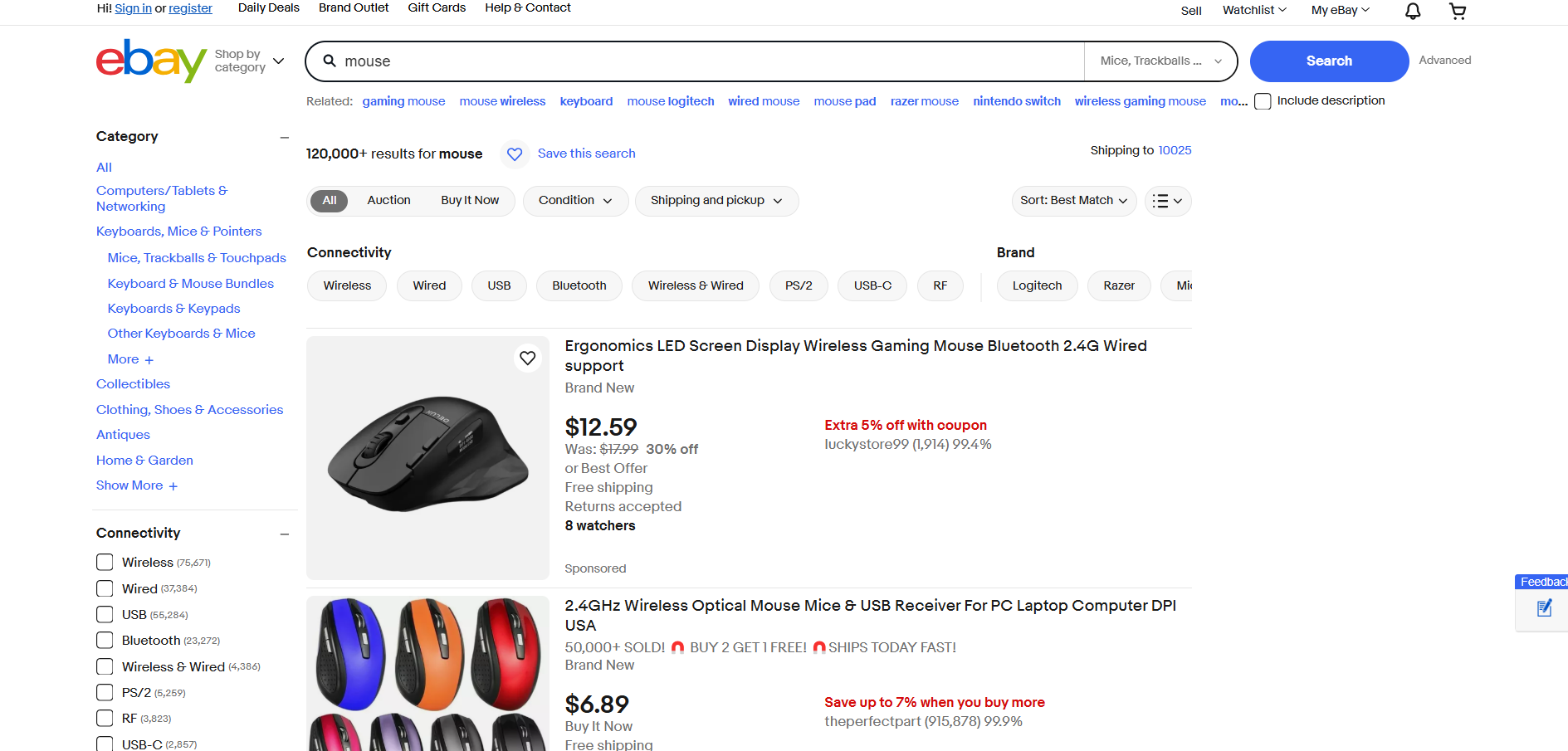
O eBay não usa JavaScript para renderizar produtos ou carregar dados dinamicamente. Assim, ele pode ser raspado com Requests e Beautiful Soup da seguinte maneira:
import requests
from bs4 import BeautifulSoup
import json
# Página de destino
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=mouse&_sacat=0"
# Enviar uma solicitação GET para a página de pesquisa do eBay
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
# Analisar o conteúdo da página com BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Onde armazenar os dados coletados
products = []
# Selecionar todos os elementos do produto na página
product_elements = soup.select("li.s-item")
# Iterar sobre eles
para product_element em product_elements:
# Lógica de extração
url_element = product_element.select("a[data-interactions]")[0]
url = url_element["href"]
name_element = product_element.select("[role="heading"]")[0]
name = name_element.text
image_element = product_element.select("img")[0]
image = image_element["src"]
# Preencher um novo objeto com os dados coletados
product = {
"url": url,
"name": name,
"image": image
}
# Adicionar à lista de produtos coletados
products.append(produto)
# Exportar dados para um arquivo JSON
com open("produtos.json", "w", encoding="utf-8") como json_file:
json.dump(produtos, json_file, indent=4)Inicie o script de Scraping de dados do site de comércio eletrônico eBay e ele produzirá:
[
{
"url": "https://www.ebay.com/itm/193168148815?_skw=mouse&itmmeta=01JGC679WKT327K11R9YCGMQAN&hash=item2cf9b8094f:g:8F4AAOSw3B1drMr-&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKlr8NKoodwElhyHbl4CwcBMRqdGJme95%2F3tIll4uI7QYBk4%2BUBpwVvwiXdAl2%2BcILZ9axc%2BdHSZStWWMxWVyq4JdZ6r52PrRP2aS1jUoFoJ11vL4KyH2S8R5ha71xBtDFcGA2%2BtzhTzcR7J25kxuxbyd%2Frd4YnKbTPKwhn2Q0TP8qL30BJKcj4FnJYP0zhgO4WOGgOCHQhM21%2BanVk%2Fl0eg1H8mqCU91mkgKAt8KghFmw%3D%3D%7Ctkp%3ABlBMULSenYaDZQ",
"name": "Mouse óptico sem fio de 2,4 GHz e receptor USB para PC, laptop e computador DPI EUA",
"image": "https://i.ebayimg.com/images/g/8F4AAOSw3B1drMr-/s-l500.webp"
},
{
"url": "https://www.ebay.com/itm/356159975164?_skw=mouse&itmmeta=01JGC679WKE9V782ZXT15SEPHP&hash=item52ecc9eefc:g:0ikAAOSwHStnD33Q&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKlZ7pO0lYrvftkZhnT7ja625fcsjcktK0eaub2HNzEgsmo3b2VehoA4tffYdt0xiTXwHb%2BzYU4NBZ5onBh68cyKWhhMJowbRvnCwuwy2IQIRlkeijpbRtJNJPuaaiDZdV0eabGGkps8433kCR6fcX1xEodUxujoeYUjp0VP81OWcl%2BbBGd70%2Fq45HC3SXg4k%2FlK0%2FqR80yJYexSEfzUq7%2BN3Sa6Y01uCo5XPWFLHzRoSw%3D%3D%7Ctkp%3ABlBMULSenYaDZQ",
"name": "Mouse sem fio para jogos com tela LED ergonômica e suporte para Bluetooth 2.4G com fio",
"image": "https://i.ebayimg.com/images/g/0ikAAOSwHStnD33Q/s-l500.webp"
},
// omitido por brevidade...
{
"url": "https://www.ebay.com/itm/116250548048?_skw=mouse&itmmeta=01JGC679WN076MJ17QJ9P4FA5J&hash=item1b11129750:g:gr8AAOSwsSFmkXG3&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKkArX38iC0VVXTpfv4BzqCegsh22yxmsDAwZAmd4RxM9JlEMfuVRoYGVZFVCeurJYwAjWd2YK3%2BNs6m5rQHZXISyWtev1lEvfVVKP4Rd5QeC2KzLgqXOvp1lWiK5b31kfujkmKjF%2BEaR1kplulwrgUvzMO%2F78F%2BFukgIAoL8dE4nRD9jo%2BieiAgIpLBUcs8AmCy5vk65gt1JGonUOncRksGYciF%2FJg6arB9%2FVOYYq7N8A%3D%3D%7Ctkp%3ABlBMULyenYaDZQ",
"name": "Razer x Sanrio Kuromi DeathAdder Gaming Mouse and Mouse Pad Combo",
"image": "https://i.ebayimg.com/images/g/gr8AAOSwsSFmkXG3/s-l500.webp"
}
]
Incrível! Você acabou de ver alguns exemplos de scripts Python para extração de dados de comércio eletrônico!
Desafios no Scraping de dados de sites de comércio eletrônico e como superá-los
Nos exemplos acima, nos concentramos em extrair detalhes básicos, como nome do produto, URL e URL da imagem, de alguns sites de comércio eletrônico. Embora essa simplicidade faça com que a extração de dados de comércio eletrônico pareça fácil, a realidade é muito mais complexa por vários motivos:
- Estruturas de página dinâmicas: as plataformas de comércio eletrônico atualizam frequentemente seus designs de página, exigindo manutenção constante dos scripts.
- Páginas de produtos diversificadas: produtos diferentes podem exibir conjuntos variados de dados e usar layouts totalmente diferentes.
- Preços dinâmicos: extrair dados precisos sobre preços pode ser um desafio devido a promoções temporárias, descontos ou ofertas específicas para cada região.
Além disso, os principais sites de comércio eletrônico, como a Amazon, empregam medidas avançadas contra a extração de dados, como CAPTCHAs:
Ou, de forma semelhante, desafios de JavaScript:

Para superar esses bloqueios, você pode:
- Aprender técnicas avançadas de coleta: leia nosso guia sobre como contornar CAPTCHAs com Python e confira tutoriais detalhados sobre coleta para dicas práticas.
- Usar ferramentas avançadas de automação: utilize ferramentas robustas como o Playwright Stealth para coletar dados de sites com mecanismos anti-bot.
Ainda assim, a solução mais eficiente é usar uma API dedicada para Scraper de comércio eletrônico.
A API eCommerce Scraper da Bright Data é uma solução confiável para extrair dados de plataformas de comércio eletrônico como Amazon, Target, Walmart, Lazada, Shein, Shopee e muito mais. Os principais benefícios incluem:
- Recuperar detalhes estruturados, como título do produto, nome do vendedor, marca, descrição, avaliações, preço inicial, moeda, disponibilidade, categorias e muito mais.
- Elimine preocupações com o gerenciamento de servidores, Proxies ou como evitar bloqueios de sites.
- Evite interrupções causadas por CAPTCHAs ou desafios de JavaScript.
Otimize seu processo de scraping de comércio eletrônico hoje mesmo!
Conclusão
Neste artigo, você aprendeu o que é um Scraper de comércio eletrônico e o tipo de dados que ele pode extrair de páginas da web de comércio eletrônico. Não importa o quão sofisticado seja o seu script de Scraping de dados de comércio eletrônico, a maioria dos sites ainda pode detectar atividades automatizadas e bloqueá-lo.
A solução é uma poderosa API de Scraper de comércio eletrônico projetada especificamente para recuperar dados de comércio eletrônico de forma confiável de várias plataformas. Essas APIs oferecem dados estruturados e abrangentes, incluindo:
- API de Scraper da Amazon: faça scraping da Amazon e colete dados como título, nome do vendedor, marca, descrição, avaliações, preço inicial, moeda, disponibilidade, categorias, ASIN, número de vendedores e muito mais.
- API do Scraper do eBay: colete dados como ASIN, nome do vendedor, ID do comerciante, URL, URL da imagem, marca, visão geral do produto, descrição, tamanhos, cores, preço final e muito mais.
- API Walmart Scraper: colete dados como URL, SKU, preço, URL da imagem, páginas relacionadas, disponível para entrega e retirada, marca, categoria, ID do produto e descrição, e muito mais.
- Target Scraper API: colete dados como URL, ID do produto, título, descrição, classificação, número de avaliações, preço, desconto, moeda, imagens, nome do vendedor, ofertas, política de envio e muito mais.
- API Lazada Scraper: extraia dados como URL, título, classificação, avaliações, preço inicial e final, moeda, imagem, nome do vendedor, descrição do produto, SKU, cores, promoções, marca e muito mais.
- API Shein Scraper: recupere dados como nome do produto, descrição, preço, moeda, cor, estoque, tamanho, número de avaliações, imagem principal, código do país, domínio e muito mais.
- API Shopee Scraper: extraia dados como URL, ID, título, classificação, avaliações, preço, moeda, estoque, favoritos, imagem, URL da loja, classificações, data de adesão, seguidores, vendidos, marca e muito mais.
Para coletar dados de produtos específicos, considere nossa API de Scraping de dados. Se você não gosta de criar Scrapers, explore nossos Conjuntos de dados de comércio eletrônico prontos para uso.
Crie uma conta gratuita na Bright Data hoje mesmo para experimentar nossas APIs de Scraper ou explorar nossos Conjuntos de dados.




