

Neste guia, você aprenderá:
- Como identificar quando um site tem navegação complexa
- A melhor ferramenta de scraping para lidar com esses cenários
- Como extrair padrões comuns de navegação complexa
Vamos começar!
Quando um site tem uma navegação complexa?
Um site com navegação complexa é umdesafiocomumde Scraping de dadosque temos que enfrentar como desenvolvedores. Mas o que exatamente significa “navegação complexa”? No Scraping de dados, navegação complexa se refere a estruturas de sites em que o conteúdo ou as páginas não são facilmente acessíveis.
Cenários de navegação complexa geralmente envolvem elementos dinâmicos, carregamento assíncrono de dados ou interações orientadas pelo usuário. Embora esses aspectos possam melhorar a experiência do usuário, eles complicam significativamente os processos de extração de dados.
Agora, a melhor maneira de entender a navegação complexa é explorando alguns exemplos:
- Navegação renderizada em JavaScript: sites que dependem de frameworks JavaScript (como React, Vue.js ou Angular) para gerar conteúdo diretamente no navegador.
- Conteúdo paginado: sites com dados espalhados por várias páginas. Isso se torna mais complexo quando a paginação é carregada numericamente via AJAX, dificultando o acesso às páginas subsequentes.
- Rolagem infinita: páginas que carregam conteúdo adicional dinamicamente à medida que os usuários rolam para baixo, comumente vistas em feeds de mídia social e sites de notícias.
- Menus multiníveis: sites com menus aninhados que exigem vários cliques ou ações de passar o mouse para revelar camadas mais profundas de navegação (por exemplo, árvores de categorias de produtos em grandes plataformas de comércio eletrônico).
- Interfaces de mapas interativos: sites que exibem informações em mapas ou gráficos, onde os Pontos de dados são carregados dinamicamente à medida que os usuários fazem panorâmicas ou zoom.
- Guias ou acordeões: páginas em que o conteúdo fica oculto sob guias renderizadas dinamicamente ou acordeões recolhíveis cujo conteúdo não está diretamente incorporado na página HTML retornada pelo servidor.
- Filtros dinâmicos e opções de classificação: sites com sistemas de filtragem complexos, nos quais a aplicação de vários filtros recarrega a lista de itens dinamicamente, sem alterar a estrutura da URL.
Melhores ferramentas de scraping para lidar com sites de navegação complexos
Para fazer scraping de um site com navegação complexa de maneira eficaz, você deve entender quais ferramentas precisa usar. A tarefa em si é inerentemente difícil, e não usar as bibliotecas de scraping certas só tornará isso ainda mais desafiador.
O que muitas das interações complexas listadas acima têm em comum é que elas:
- Exigem alguma forma de interação do usuário ou
- São executadas no lado do cliente dentro do navegador.
Em outras palavras, essas tarefas precisam da execução de JavaScript, algo que só um navegador pode fazer. Isso significa que você não pode confiar emanalisadores HTMLsimples para essas páginas. Em vez disso, você deve usar uma ferramenta de automação de navegador como Selenium, Playwright ou Puppeteer.
Essas soluções permitem que você instrua programaticamente um navegador a realizar ações específicas em uma página da web, imitando o comportamento do usuário. Eles são frequentemente chamados denavegadores headlessporque podem renderizar o navegador sem uma interface gráfica, economizando recursos do sistema.
Descubra asmelhores ferramentas de navegador sem interface gráfica para Scraping de dados.
Como fazer scraping de padrões de navegação complexos comuns
Nesta seção do tutorial, usaremos o Selenium em Python. No entanto, você pode adaptar facilmente a lógica ao Playwright, Puppeteer ou qualquer outra ferramenta de automação de navegador. Também presumiremos que você já está familiarizado com os fundamentos doScraping de dados da web usando o Selenium.
Especificamente, abordaremos como fazer scraping dos seguintes padrões comuns de navegação complexa:
- Paginação dinâmica: sites com dados paginados carregados dinamicamente via AJAX.
- Botão “Carregar mais”: um exemplo comum de navegação baseada em JavaScript.
- Rolagem infinita: uma página que carrega dados continuamente à medida que o usuário rola para baixo.
Hora de programar!
Paginação dinâmica
A página de destino para este exemplo é a sandbox de scraping“Filmes vencedores do Oscar: AJAX e Javascript”:
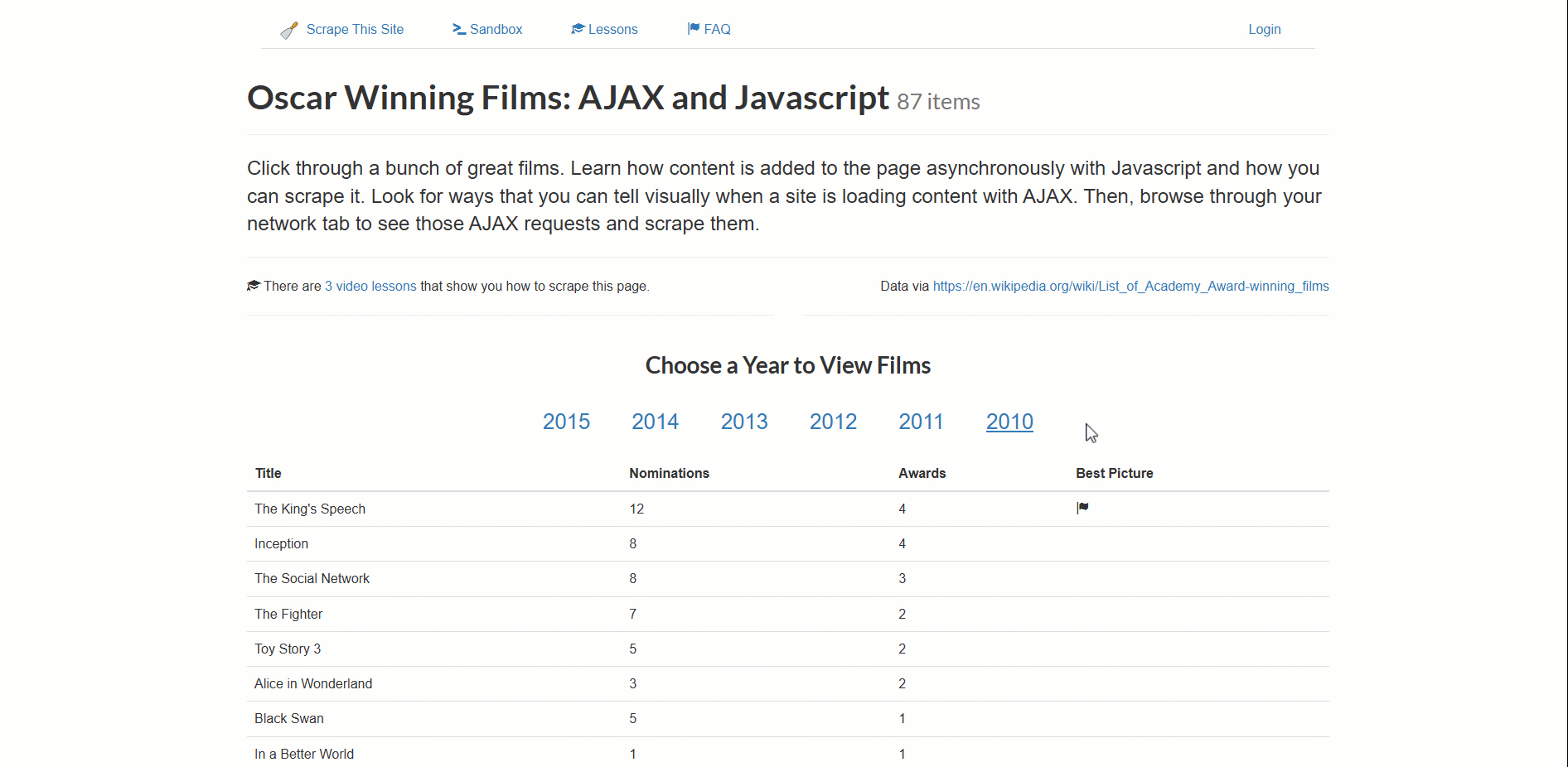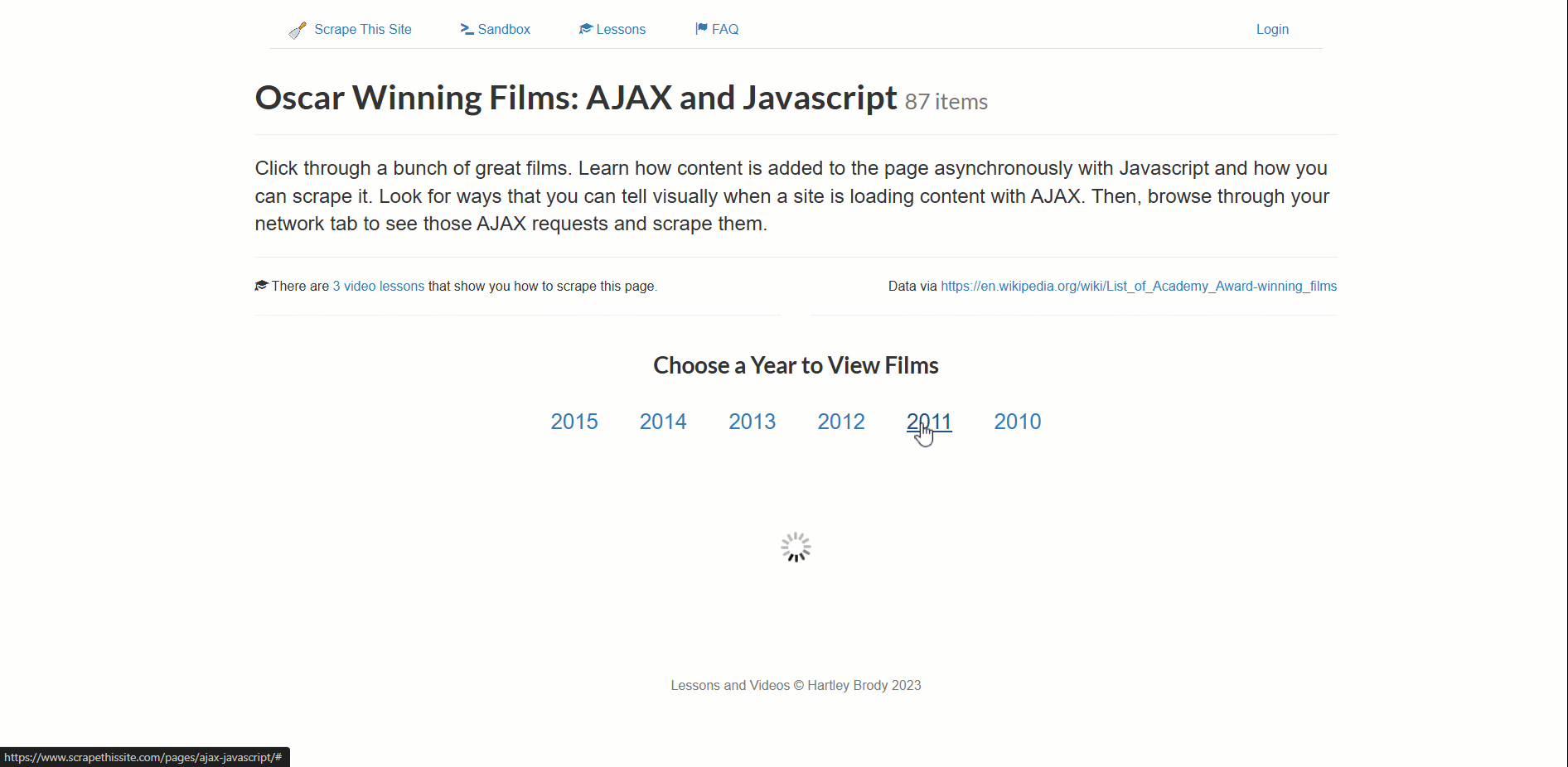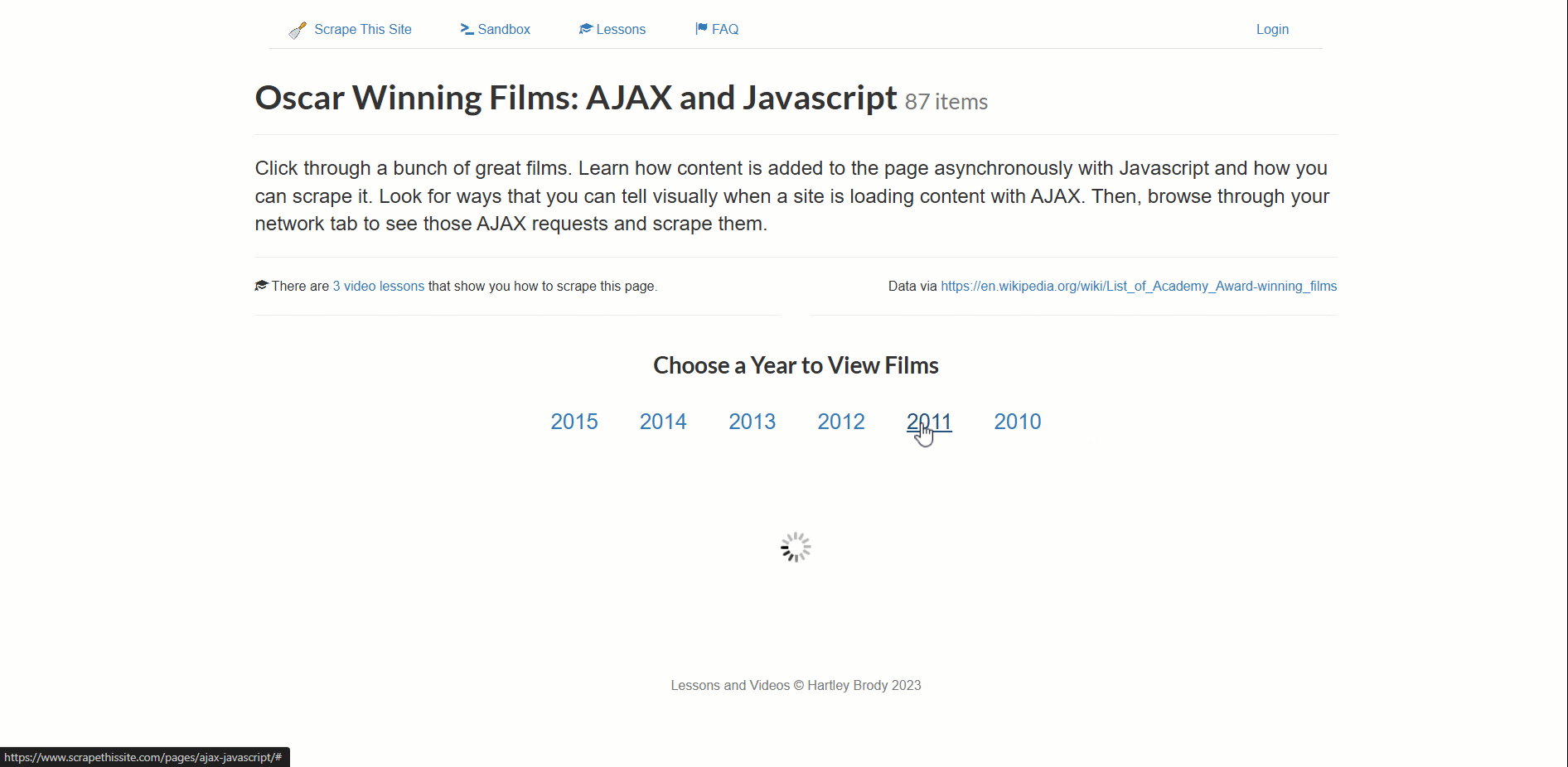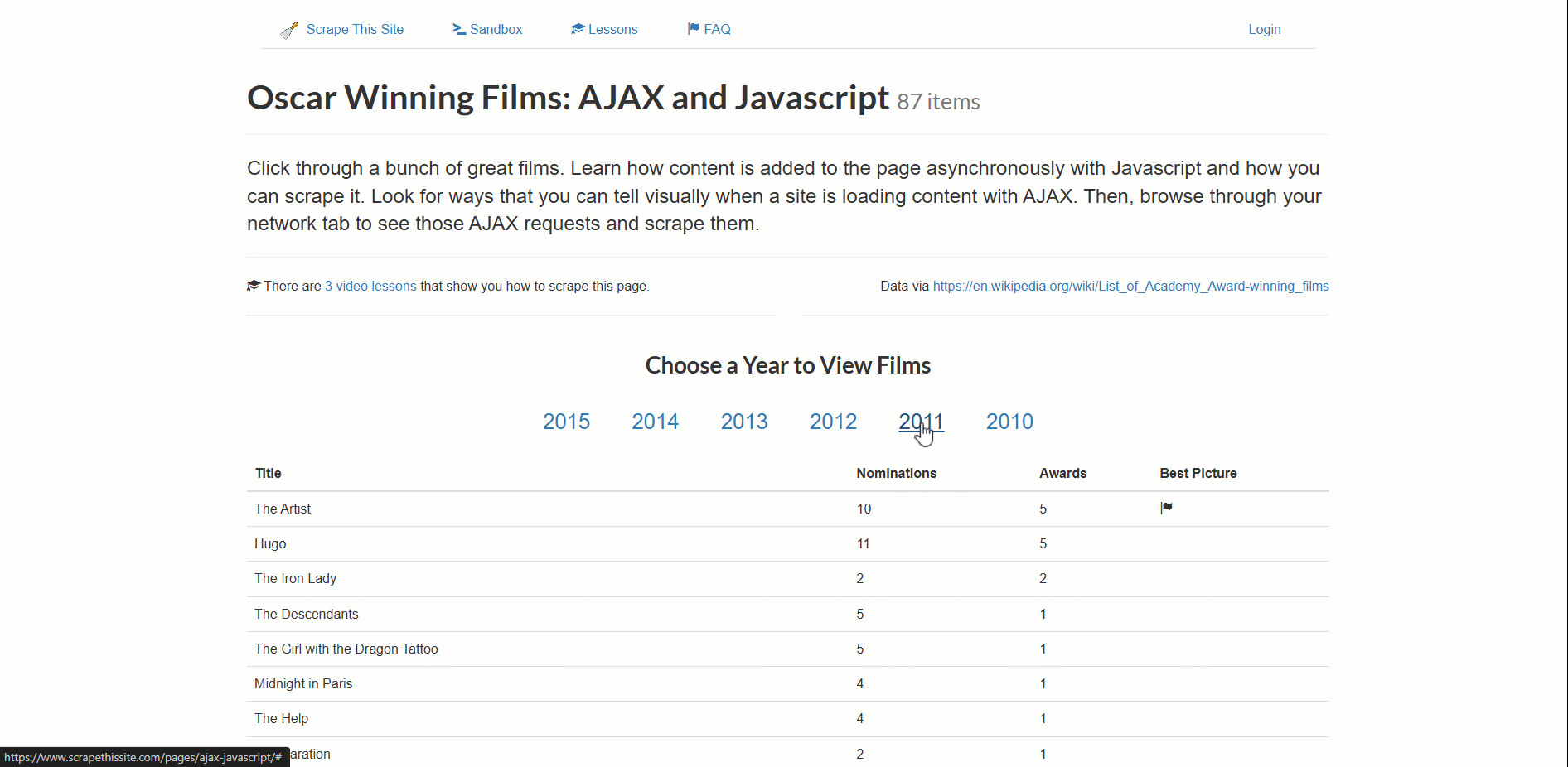
Este site carrega dinamicamente dados de filmes vencedores do Oscar, paginados por ano.
Para lidar com uma navegação tão complexa, a abordagem é:
- Clique em um novo ano para acionar o carregamento dos dados (um elemento carregador será exibido).
- Aguarde até que o elemento carregador desapareça (os dados agora estão totalmente carregados).
- Certifique-se de que a tabela com os dados foi renderizada corretamente na página.
- Extraia os dados assim que estiverem disponíveis.
Em detalhes, veja abaixo como você pode implementar essa lógica usando o Selenium em Python:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
# Configure as opções do Chrome para o modo headless
options = Options()
options.add_argument("--headless")
# Crie uma instância do driver web do Chrome
driver = webdriver.Chrome(service=Service(), options=options)
# Conecte-se à página de destino
driver.get("https://www.scrapethissite.com/pages/ajax-javascript/")
# Clique no botão de paginação "2012"
element = driver.find_element(By.ID, "2012")
element.click()
# Aguarde até que o carregador não esteja mais visível
WebDriverWait(driver, 10).until(
lambda d: d.find_element(By.CSS_SELECTOR, "#loading").get_attribute("style") == "display: none;")
# Os dados agora devem estar carregados...
# Aguarde até que a tabela esteja presente na página
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".table")))
# Onde armazenar os dados coletados
films = []
# Coletar dados da tabela
table_body = driver.find_element(By.CSS_SELECTOR, "#table-body")
rows = table_body.find_elements(By.CSS_SELECTOR, ".film")
for row in rows:
title = row.find_element(By.CSS_SELECTOR, ".film-title").text
nominations = row.find_element(By.CSS_SELECTOR, ".film-nominations").text
prêmios = linha.find_element(By.CSS_SELECTOR, ".film-awards").text
ícone_melhor_filme = linha.find_element(By.CSS_SELECTOR, ".film-best-picture").find_elements(By.TAG_NAME, "i")
melhor_filme = True se ícone_melhor_filme else False
# Armazene os dados coletados
films.append({
"title": title,
"nominations": nominations,
"awards": awards,
"best_picture": best_picture
})
# Lógica de exportação de dados...
# Feche o driver do navegador
driver.quit()
Esta é a análise do código acima:
- O código configura uma instância do Chrome sem interface gráfica.
- O script abre a página de destino e clica no botão de paginação “2012” para acionar o carregamento dos dados.
- O Selenium aguarda o carregador desaparecer usando
WebDriverWait(). - Depois que o carregador desaparece, o script aguarda o aparecimento da tabela.
- Depois que os dados são totalmente carregados, o script extrai os títulos dos filmes, as indicações, os prêmios e se o filme ganhou o Oscar de Melhor Filme. Ele armazena esses dados em uma lista de dicionários.
O resultado será:
[
{
"title": "Argo",
"nominations": "7",
"awards": "3",
"best_picture": true
},
// ...
{
"title": "Curfew",
"nominations": "1",
"awards": "1",
"best_picture": false
}
]
Observe que nem sempre existe uma única maneira ideal de lidar com esse padrão de navegação. Outras opções podem ser necessárias, dependendo do comportamento da página. Exemplos:
- Use
WebDriverWait()em combinação com condições esperadas para aguardar o aparecimento ou desaparecimento de elementos HTML específicos. - Monitore o tráfego de solicitações AJAX para detectar quando um novo conteúdo é buscado. Isso pode envolver o uso de registros do navegador.
- Identifique a solicitação de API acionada pela paginação e faça solicitações diretas para buscar os dados programaticamente (por exemplo, usando abiblioteca
de solicitações).
Botão “Carregar mais”
Para representar cenários de navegação complexos baseados em JavaScript envolvendo interação do usuário, escolhemos o exemplo do botão “Carregar mais”. O conceito é simples: uma lista de itens é exibida e itens adicionais são carregados quando o botão é clicado.
Desta vez, o site de destino será a páginade exemplo “Carregar mais”do Curso de Scraping:
Para lidar com esse padrão complexo de navegação, siga estas etapas:
- Localize o botão “Carregar mais” e clique nele.
- Aguarde até que os novos elementos sejam carregados na página.
Veja como você pode implementar isso com o Selenium:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
# Configure as opções do Chrome para o modo headless
options = Options()
options.add_argument("--headless")
# Crie uma instância do driver web do Chrome
driver = webdriver.Chrome(options=options)
# Conecte-se à página de destino
driver.get("https://www.scrapingcourse.com/button-click")
# Coleta o número inicial de produtos
initial_product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Localiza o botão “Carregar mais” e clica nele
load_more_button = driver.find_element(By.CSS_SELECTOR, "#load-more-btn")
load_more_button.click()
# Aguardar até que o número de itens de produto na página tenha aumentado
WebDriverWait(driver, 10).until(lambda driver: len(driver.find_elements(By.CSS_SELECTOR, ".product-item")) > initial_product_count)
# Onde armazenar os dados coletados
products = []
# Extrair detalhes do produto
product_elements = driver.find_elements(By.CSS_SELECTOR, ".product-item")
for product_element in product_elements:
# Extrair detalhes do produto
name = product_element.find_element(By.CSS_SELECTOR, ".product-name").text
image = product_element.find_element(By.CSS_SELECTOR, ".product-image").get_attribute("src")
price = product_element.find_element(By.CSS_SELECTOR, ".product-price").text
url = product_element.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
# Armazenar os dados extraídos
products.append({
"name": name,
"image": image,
"price": price,
"url": url
})
# Lógica de exportação de dados...
# Fechar o driver do navegador
driver.quit()
Para lidar com essa lógica de navegação, o script:
- Registra o número inicial de produtos na página
- Clica no botão “Carregar mais”
- Aguarda até que a contagem de produtos aumente, confirmando que novos itens foram adicionados
Essa abordagem é inteligente e genérica, pois não requer saber o número exato de elementos a serem carregados. Ainda assim, lembre-se de que outros métodos são possíveis para obter resultados semelhantes.
Rolagem infinita
A rolagem infinita é uma interação comum usada por muitos sites para melhorar o envolvimento do usuário, especialmente em mídias sociais e plataformas de comércio eletrônico. Nesse caso, o alvo será a mesma página acima, mas comrolagem infinita em vez de um botão “Carregar mais”:
A maioria das ferramentas de automação de navegador (incluindo o Selenium) não oferece um método direto para rolar uma página para baixo ou para cima. Em vez disso, você precisa executar um script JavaScript na página para realizar a operação de rolagem.
A ideia é escrever um script JavaScript personalizado que role para baixo:
- Um número especificado de vezes, ou
- Até que não haja mais dados disponíveis para carregar.
Observação: cada rolagem carrega novos dados, aumentando o número de elementos na página.
Depois, você pode extrair o conteúdo recém-carregado.
É assim que você pode lidar com a rolagem infinita no Selenium:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
# Configure as opções do Chrome para o modo headless
options = Options()
# options.add_argument("--headless")
# Crie uma instância do driver web do Chrome
driver = webdriver.Chrome(options=options)
# Conecte-se à página de destino com rolagem infinita
driver.get("https://www.scrapingcourse.com/infinite-scrolling")
# Altura da página atual
scroll_height = driver.execute_script("return document.body.scrollHeight")
# Número de produtos na página
product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Número máximo de rolagens
max_scrolls = 10
scroll_count = 1
# Limitar o número de rolagens a 10
enquanto scroll_count < max_scrolls:
# Rolar para baixo
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Esperar até que o número de itens de produto na página tenha aumentado
WebDriverWait(driver, 10).until(lambda driver: len(driver.find_elements(By.CSS_SELECTOR, ".product-item")) > product_count)
# Atualizar a contagem de produtos
product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Obter a nova altura da página
new_scroll_height = driver.execute_script("return document.body.scrollHeight")
# Se nenhum novo conteúdo tiver sido carregado
if new_scroll_height == scroll_height:
break
# Atualizar a altura da rolagem e incrementar a contagem de rolagem
scroll_height = new_scroll_height
scroll_count += 1
# Extrair detalhes do produto após rolagem infinita
produtos = []
elementos_do_produto = driver.find_elements(By.CSS_SELECTOR, ".product-item")
para elemento_do_produto em elementos_do_produto:
# Extrair detalhes do produto
nome = elemento_do_produto.find_element(By.CSS_SELECTOR, ".product-name").text
image = product_element.find_element(By.CSS_SELECTOR, ".product-image").get_attribute("src")
price = product_element.find_element(By.CSS_SELECTOR, ".product-price").text
url = product_element.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
# Armazenar os dados extraídos
products.append({
"name": name,
"image": image,
"price": price,
"url": url
})
# Exportar para CSV/JSON...
# Fechar o driver do navegador
driver.quit()
Este script gerencia a rolagem infinita determinando primeiro a altura da página atual e a contagem de produtos. Em seguida, ele limita as ações de rolagem a um máximo de 10 iterações. Em cada iteração, ele:
- Rola até o final da página
- Aguarda o aumento da contagem de produtos (indicando que novo conteúdo foi carregado)
- Compara a altura da página para detectar se há mais conteúdo disponível
Se a altura da página permanecer inalterada após uma rolagem, o loop é interrompido, indicando que não há mais dados para carregar. É assim que você pode lidar com padrões complexos de rolagem infinita.
Ótimo! Agora você é um mestre em extrair dados de sites com navegação complexa.
Conclusão
Neste artigo, você aprendeu sobre sites que dependem de padrões de navegação complexos e como usar o Selenium com Python para lidar com eles. Isso demonstra que o Scraping de dados da web pode ser desafiador, mas pode se tornar ainda mais difícil devidoàs medidas anti-extração.
As empresas entendem o valor de seus dados e os protegem a todo custo, e é por isso que muitos sites implementam medidas para bloquear scripts automatizados. Essas soluções podem bloquear seu IP após muitas solicitações, apresentar CAPTCHAs e até mesmo pior.
Ferramentas tradicionais de automação de navegador, como o Selenium, não conseguem contornar essas restrições…
A solução é usar um navegador baseado em nuvem e dedicado àextração, comoo Navegador de scraping. Esse é um navegador que se integra ao Playwright, Puppeteer, Selenium e outras ferramentas, alternando automaticamente os IPs a cada solicitação. Ele pode lidar com impressões digitais do navegador, novas tentativas,Resolução de CAPTCHA e muito mais. Esqueça o bloqueio ao lidar com sites complexos!




