

Neste tutorial, você verá:
- O que é o Qwen3 e o que o diferencia de um LLM
- Por que ele é adequado para tarefas de raspagem da Web
- Como usar o Qwen3 localmente para raspagem da Web com o Hugging Face
- Suas principais limitações e como contorná-las
- Algumas alternativas ao Qwen3 para raspagem com tecnologia de IA
Vamos mergulhar de cabeça!
O que é o Qwen3?
Qwen3 é a última geração de LLMs desenvolvida pela equipe Qwen da Alibaba Cloud. O modelo é de código aberto e pode ser explorado livremente no GitHub – disponívelsob a licença Apache 2.0. Isso é ótimo para pesquisa e desenvolvimento.
Os principais recursos do Qwen3 incluem:
- Raciocínio híbrido: Ele pode alternar entre um “modo de pensamento” para raciocínio lógico complexo (como matemática ou codificação) e um “modo de não pensamento” para respostas mais rápidas e de uso geral. Isso permite que você controle a profundidade do raciocínio para otimizar o desempenho e a eficiência de custos.
- Diversos modelos: O Qwen3 oferece um conjunto abrangente de modelos, incluindo modelos densos (variando de 0,6B a 32B parâmetros) e modelos Mixture-of-Experts (MoE) (como as variantes 30B e 235B).
- Recursos aprimorados: Ele apresenta avanços significativos em raciocínio, acompanhamento de instruções, recursos de agente e suporte multilíngue (abrangendo mais de 100 idiomas e dialetos).
- Dados de treinamento: O Qwen3 foi treinado em um enorme conjunto de dados de aproximadamente 36 trilhões de tokens, quase o dobro de seu antecessor, o Qwen2.5.
Por que usar o Qwen3 para raspagem da Web?
O Qwen3 facilita a raspagem da Web automatizando a interpretação e a estruturação de conteúdo não estruturado em páginas HTML. Isso elimina a necessidade de análise manual de dados. Em vez de escrever uma lógica complexa para extrair dados, o modelo entende a estrutura da página para você.
Contar com o Qwen3 para análise de dados da Web é especialmente útil ao lidar com desafios comuns de raspagem da Web, como:
- Layouts de página que mudam com frequência: Um cenário popular é a Amazon, onde cada página de produto pode mostrar dados diferentes.
- Dados não estruturados: O Qwen3 pode extrair informações valiosas de textos confusos e de forma livre sem precisar de seletores codificados ou lógica regex.
- Conteúdo difícil de analisar: Para páginas com estrutura inconsistente ou complexa, um LLM como o Qwen3 elimina a necessidade de lógica de análise personalizada.
Para se aprofundar no assunto, leia nosso guia sobre o uso de IA para raspagem da Web.
Outra grande vantagem é que o Qwen3 é de código aberto. Isso significa que você pode executá-lo localmente em sua própria máquina de forma gratuita, sem depender de APIs de terceiros ou pagar por LLMs premium como o da OpenAI. Isso lhe dá controle total sobre sua arquitetura de raspagem.
Como realizar a raspagem da Web com o Qwen3 em Python
Nesta seção, a página de destino será a página do produto “Affirm Water Bottle” da sandbox “Ecommerce Test Site to Learn Web Scraping“:
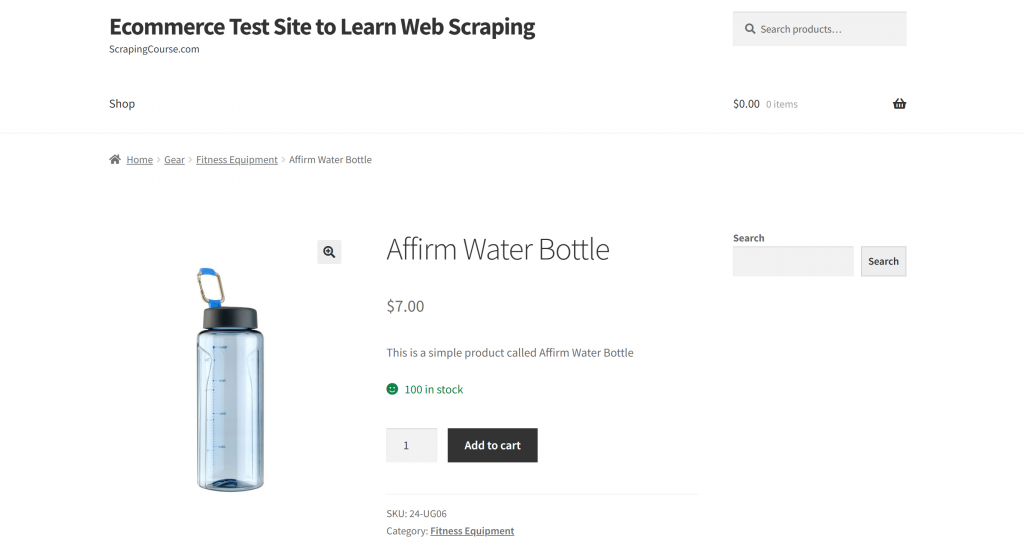
Essa página serve como um exemplo sólido porque as páginas de produtos de comércio eletrônico geralmente têm estruturas inconsistentes, exibindo vários tipos de dados. Essa variabilidade é o que torna a raspagem da Web de comércio eletrônico particularmente desafiadora – e também onde a IA pode fazer uma grande diferença.
Aqui, usaremos um raspador acionado pelo Qwen3 para extrair informações de produtos de forma inteligente sem escrever regras de análise manual.
Observação: este tutorial mostrará como usar o Hugging Face para executar modelos Qwen3 localmente e gratuitamente. Agora, existem outras opções viáveis. Elas incluem a conexão com um provedor de LLM que hospeda modelos Qwen3 ou a utilização de soluções como o Ollama.
Siga as etapas abaixo para começar a extrair dados da Web usando o Qwen3!
Etapa 1: Configure seu projeto
Antes de começar, certifique-se de que você tenha o Python 3.10+ instalado em sua máquina. Caso contrário, faça o download e siga as instruções de instalação.
Em seguida, execute o comando abaixo para criar uma pasta para seu projeto de raspagem:
mkdir qwen3-scraperO diretório qwen3-scraper servirá como a pasta do projeto para raspagem da Web usando o Qwen3.
Navegue até a pasta em seu terminal e inicialize um ambiente virtual Python dentro dela:
cd qwen3-scraper
python -m venv venvCarregue a pasta do projeto em seu IDE Python preferido. O Visual Studio Code com a extensão Python ou o PyCharm Community Edition são excelentes opções.
Crie um arquivo scraper.py na pasta do projeto, que agora deve conter:

No momento, o scraper.py é apenas um script Python vazio, mas em breve conterá a lógica para a coleta de dados da Web do LLM.
Em seguida, ative o ambiente virtual. No Linux ou macOS, execute:
source venv/bin/activateDe forma equivalente, no Windows, use:
venv/Scripts/activateObservação: as etapas a seguir o guiarão na instalação de todas as bibliotecas necessárias. Se preferir instalar tudo de uma vez, você pode usar o comando abaixo agora:
pip install transformers torch accelerate requests beautifulsoup4 markdownifyFantástico! Seu ambiente Python está totalmente configurado para raspagem da Web com o Qwen3.
Etapa 2: Configurar o Qwen3 no Hugging Face
Conforme mencionado no início desta seção, usaremos o Hugging Face para executar um modelo Qwen3 localmente. Isso agora é possível porque o Hugging Face recentemente adicionou suporte para modelos Qwen3.
Primeiro, verifique se você está em um ambiente virtual ativado. Em seguida, instale as dependências necessárias do Hugging Face executando:
pip install transformers torch accelerateEm seguida, em seu arquivo scraper.py, importe as classes necessárias da biblioteca de transformadores da Hugging Face:
from transformers import AutoModelForCausalLM, AutoTokenizerAgora, use essas classes para carregar um tokenizador e o modelo Qwen3:
model_name = "Qwen/Qwen3-0.6B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)Neste caso, estamos usando o modelo Qwen/Qwen3-0.6B, mas você pode escolher entre mais de 40 outros modelos Qwen3 disponíveis na Hugging Face.
Muito bom! Agora você tem tudo pronto para utilizar o Qwen3 em seu script Python.
Etapa 3: obtenha o HTML da página de destino
Agora, é hora de recuperar o conteúdo HTML da página de destino. Você pode fazer isso usando um poderoso cliente HTTP Python, como o Requests.
Em seu ambiente virtual ativado, instale a biblioteca Requests:
pip install requestsEm seguida, em seu arquivo scraper.py, importe a biblioteca:
import requestsUse o método get() para enviar uma solicitação HTTP GET para o URL da página:
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)O servidor responderá com o HTML bruto da página. Para ver o conteúdo HTML completo, você pode imprimir response.content:
print(response.content)O resultado deve ser esta cadeia de caracteres HTML:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- omitted for brevity... -->
<title>Affirm Water Bottle – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>Agora você tem o HTML completo da página de destino disponível em Python. Vamos passar a analisá-lo e extrair os dados de que precisamos usando o Qwen3!
Etapa 4: converter o HTML da página em Markdown (opcional, mas recomendado)
Observação: esta etapa não é estritamente necessária. No entanto, ela pode economizar muito tempo localmente (e dinheiro se você estiver usando provedores Qwen3 pagos). Portanto, definitivamente vale a pena considerá-la.
Reserve um momento para explorar como outras ferramentas de raspagem da Web com tecnologia de IA, como o Crawl4AI e o ScrapeGraphAI, lidam com HTML bruto. Você notará que ambas oferecem opções para converter HTML em Markdown antes de passar o conteúdo para o LLM configurado.
Por que eles fazem isso? Há dois motivos principais:
- Eficiência de custos: A conversão de markdown reduz o número de tokens enviados para a IA, ajudando você a economizar dinheiro.
- Processamento mais rápido: Menos dados de entrada significa custos computacionais mais baixos e respostas mais rápidas.
Para obter mais informações, leia nosso guia sobre por que os novos agentes de IA escolhem Markdown em vez de HTML.
Nesse caso, como o Qwen3 é executado localmente, a eficiência de custo não é importante porque você não está conectado a um provedor de LLM de terceiros. O que realmente importa aqui é o processamento mais rápido. Por quê? Porque pedir ao modelo Qwen3 escolhido (que é um dos menores modelos disponíveis, aliás) para processar toda a página HTML pode facilmente levar uma CPU i7 a 100% de uso por vários minutos.
Isso é demais, pois você não quer superaquecer ou congelar seu laptop ou PC. Portanto, a redução do tamanho da entrada por meio da conversão para Markdown faz todo o sentido.
É hora de replicar a lógica de conversão de HTML para Markdown e reduzir o uso de tokens!
Primeiro, abra a página da Web de destino no modo anônimo para garantir uma nova sessão. Em seguida, clique com o botão direito do mouse em qualquer lugar da página e selecione “Inspect” (Inspecionar) para abrir o DevTools. Agora, examine a estrutura da página. Você verá que todos os dados relevantes estão contidos no elemento HTML identificado pelo seletor CSS #main:
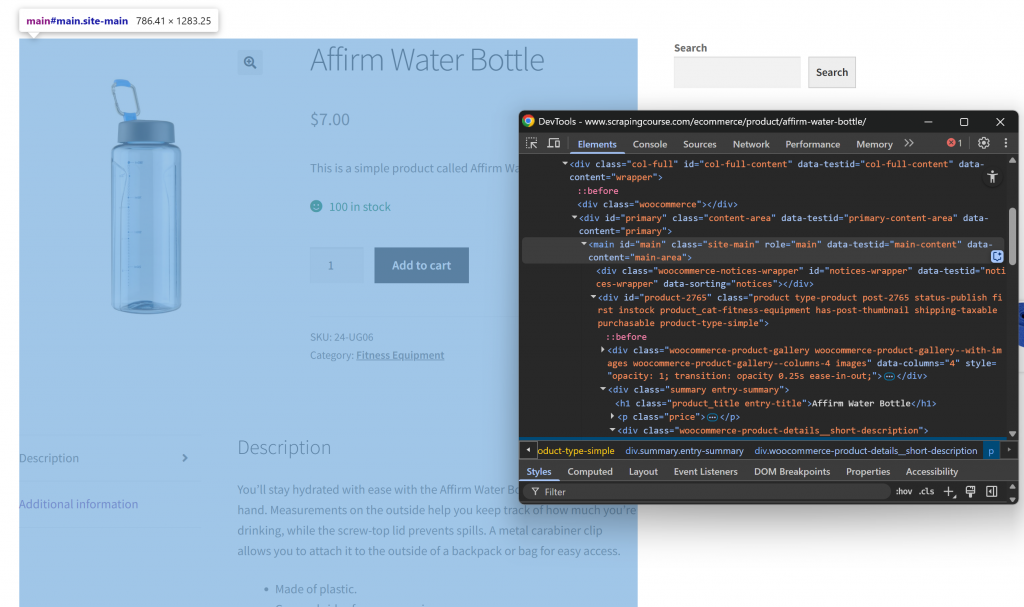
Ao se concentrar no conteúdo dentro de #main no processo de conversão de HTML para Markdown, você extrai somente a parte da página com dados relevantes. Isso evita a inclusão de cabeçalhos, rodapés e outras seções que não sejam de seu interesse. Dessa forma, o resultado final do Markdown será muito mais curto.
Para selecionar apenas o HTML no elemento #main, você precisa de uma biblioteca de análise de HTML do Python, como a Beautiful Soup. Em seu ambiente virtual ativado, instale-a com este comando:
pip install beautifulsoup4Se você não estiver familiarizado com sua API, siga nosso guia sobre raspagem da Web da Beautiful Soup.
Em seguida, importe-o no scraper.py:
from bs4 import BeautifulSoupAgora, use o Beautiful Soup para:
- Analisar o HTML bruto obtido com Requests
- Selecione o elemento
#main - Extrair seu conteúdo HTML
Implemente as três microetapas acima com este snippet:
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get the outer HTML of the selected element
main_html = str(main_element)Se você imprimir main_html, verá algo parecido com isto:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- omitted for brevity... -->
<div id="product-2765" class="product type-product post-2765 status-publish first instock product_cat-fitness-equipment has-post-thumbnail shipping-taxable purchasable product-type-simple">
<!-- omitted for brevity... -->
</div>
</main>Essa string é muito menor do que a página HTML completa, mas ainda contém cerca de 13.402 caracteres.
Para reduzir ainda mais o tamanho sem perder dados importantes, converta o HTML extraído em Markdown. Primeiro, instale a biblioteca markdownify:
pip install markdownifyImportar markdownify em scraper.py:
from markdownify import markdownifyEm seguida, use-o para converter o HTML de #main em Markdown:
main_markdown = markdownify(main_html)O processo de conversão de dados deve produzir um resultado como o abaixo:
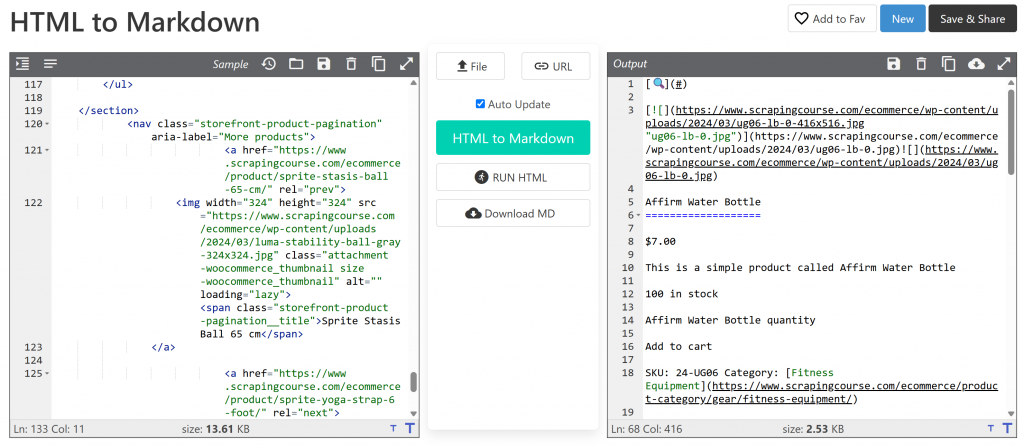
A versão Markdown tem cerca de 2,53 KB, em comparação com os 13,61 KB do HTML #main original. Isso representa uma redução de 81% no tamanho! Além disso, o que importa é que a versão Markdown retém todos os principais dados que você precisa extrair.
Com esse truque simples, você reduziu um trecho de HTML volumoso em uma string Markdown compacta. Isso acelerará muito a análise de dados LLM local via Qwen3!
Etapa 5: usar o Qwen3 para análise de dados
Para fazer com que o Qwen3 extraia os dados corretamente, você precisa escrever um prompt eficaz. Comece analisando a estrutura da página de destino:
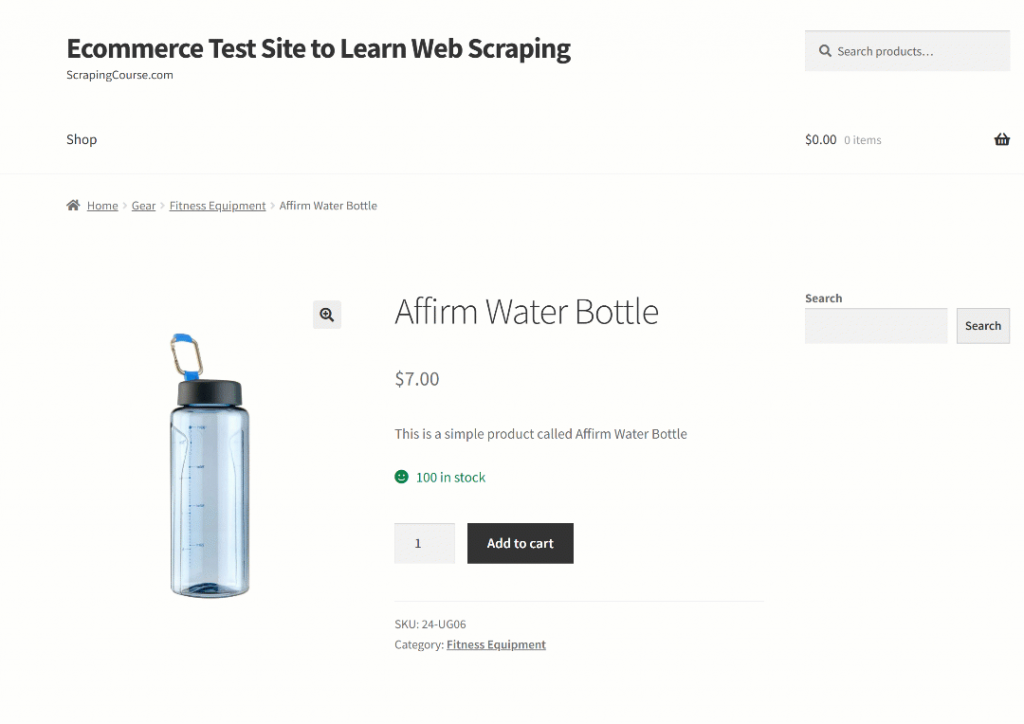
A seção superior da página é consistente em todos os produtos. Por outro lado, a tabela “Additional information” (Informações adicionais) muda de acordo com o produto. Como você pode querer que seu prompt funcione em todas as páginas de produtos na plataforma, você pode descrever sua tarefa em termos gerais, como a seguir:
Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
<MARKDOWN_PRODUCT_CONTENT>Esse prompt instrui o Qwen3 a extrair dados estruturados do conteúdo main_markdown. Para obter resultados confiáveis, é uma boa ideia tornar seu prompt o mais claro e específico possível. Isso ajuda o modelo a entender exatamente o que você espera.
Agora, use o Hugging Face para executar o prompt, conforme explicado na documentação oficial:
# Define tge data extraction prompt
prompt = prompt = f"""Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
{main_markdown}
"""
# Execute the prompt
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Retrieve the output in text format
product_raw_string = tokenizer.decode(output_ids, skip_special_tokens=True).strip("n")O código acima usa apply_chat_template() para formatar a mensagem de entrada e gera uma resposta do modelo Qwen3 configurado.
Observação: um detalhe importante é a configuração de enable_thinking=False em apply_chat_template(). Por padrão, essa opção é definida como True, o que ativa o modo de “raciocínio” interno do modelo. Essa tarefa é útil para a solução de problemas complexos, mas desnecessária e potencialmente contraproducente para tarefas simples, como raspagem da Web. Desativá-la garante que o modelo se concentre puramente na extração sem adicionar explicações ou suposições.
Fantástico! Você acabou de instruir o Qwen3 a executar a raspagem da Web na página de destino.
Agora, tudo o que resta é ajustar a saída e exportá-la para JSON.
Etapa nº 6: Converter a saída do Qwen3
A saída produzida pelo modelo Qwen3-0.6B pode variar ligeiramente entre as execuções. Esse é um comportamento típico dos LLMs, especialmente de modelos menores como o usado aqui.
Assim, às vezes a variável product_raw_string conterá os dados desejados como uma string JSON simples. Outras vezes, ela pode envolver o JSON em um bloco de código Markdown, como este:
```jsonn{n "sku": "24-UG06",n "name": "Affirm Water Bottle",n "images": ["https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/ug06-lb-0.jpg"],n "price": "$7.00",n "description": "You’ll stay hydrated with ease with the Affirm Water Bottle by your side or in hand. Measurements on the outside help you keep track of how much you’re drinking, while the screw-top lid prevents spills. A metal carabiner clip allows you to attach it to the outside of a backpack or bag for easy access.",n "category": "Fitness Equipment",n "additional_information": {n "Activity": "Yoga, Recreation, Sports, Gym",n "Gender": "Men, Women, Boys, Girls, Unisex",n "Material": "Plastic"n }n}n```Para lidar com ambos os casos, você pode usar uma expressão regular para extrair o conteúdo JSON quando ele aparecer dentro de um bloco Markdown. Caso contrário, trate a string como JSON bruto. Em seguida, você pode analisar os dados JSON resultantes para o dicionário Python json.loads():
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)Aqui vamos nós! Neste ponto, você analisou os dados extraídos em um objeto Python utilizável. A última etapa é exportar os dados extraídos para um formato mais fácil de usar.
Etapa nº 7: Exportar os dados extraídos
Agora que você tem os dados do produto em um dicionário Python, pode salvá-los em um arquivo JSON como este:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Isso criará um arquivo chamado product.json contendo os dados estruturados do produto.
Muito bem! Seu raspador da Web Qwen3 agora está completo.
Etapa #8: Juntar tudo
Aqui está o código final de seu script de raspagem Qwen3 scraper.py:
from transformers import AutoModelForCausalLM, AutoTokenizer
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
import re
# The Qwen3 model to use for web scraping
model_name = "Qwen/Qwen3-0.6B"
# Load the tokenizer and the Qwen3 model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# Fetch the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/affirm-water-bottle/"
response = requests.get(url)
# Parse the HTML of the target page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get the outer HTML of the selected element and convert it to Markdown
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Define tge data extraction prompt
prompt = prompt = f"""Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
{main_markdown}
"""
# Execute the prompt
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Retrieve the output in text format
product_raw_string = tokenizer.decode(output_ids, skip_special_tokens=True).strip("n")
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Execute o script com:
python scraper.pyNa primeira vez que você executar o script, o Hugging Face baixará automaticamente o modelo Qwen3 selecionado. Esse modelo tem cerca de 1,5 GB, portanto, o download pode levar algum tempo, dependendo da velocidade de sua internet. No terminal, você verá resultados como:
model.safetensors: 100%|██████████████████████████████████████████████████████████| 1.50G/1.50G [00:49<00:00, 30.2MB/s]
generation_config.json: 100%|█████████████████████████████████████████████████████████████████| 239/239 [00:00<?, ?B/s]O script pode demorar um pouco para ser concluído, pois o PyTorch sobrecarregará sua CPU para carregar e executar o modelo.
Quando o script for concluído, ele criará um arquivo chamado product.json na pasta do projeto. Abra esse arquivo e você verá dados estruturados do produto como este:
{
"sku": "24-UG06",
"name": "Affirm Water Bottle",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/ug06-lb-0.jpg"
],
"price": "$7.00",
"description": "You’ll stay hydrated with ease with the Affirm Water Bottle by your side or in hand. Measurements on the outside help you keep track of how much youu2019re drinking, while the screw-top lid prevents spills. A metal carabiner clip allows you to attach it to the outside of a backpack or bag for easy access.",
"category": "Fitness Equipment",
"additional_information": {
"Activity": "Yoga, Recreation, Sports, Gym",
"Gender": "Men, Women, Boys, Girls, Unisex",
"Material": "Plastic"
}
}Observação: o resultado exato pode variar um pouco devido à natureza dos LLMs, que podem estruturar o conteúdo extraído de diferentes maneiras.
E pronto! Seu script acabou de transformar o conteúdo HTML bruto em JSON limpo e estruturado. Tudo graças ao Qwen3 web scraping.
Superando a principal limitação dessa abordagem de raspagem da Web
Claro, em nosso exemplo, tudo funcionou sem problemas. Mas isso se deve apenas ao fato de estarmos extraindo um site de demonstração criado especificamente para essa finalidade.
No mundo real, a maioria dos sites está bem ciente do valor de seus dados voltados para o público. Assim, eles geralmente implementam técnicas antirrastreamento que podem bloquear rapidamente solicitações HTTP automatizadas feitas com ferramentas como requests.
Além disso, essa abordagem não funcionará em sites com muito JavaScript. Isso ocorre porque a combinação de solicitações e BeautifulSoup funciona bem para páginas estáticas, mas não consegue lidar com conteúdo dinâmico. Se não estiver familiarizado com a diferença, dê uma olhada em nosso artigo sobre conteúdo estático e dinâmico.
Outros possíveis bloqueadores incluem proibições de IP, limitadores de taxa, impressão digital TLS, CAPTCHAs e muito mais. Em resumo, a raspagem da Web não é fácil, especialmente agora que a maioria dos sites está equipada para detectar e bloquear rastreadores e bots de IA.
A solução é utilizar uma API do Web Unlocker criada para raspagem moderna da Web com solicitações. Esse serviço cuida de todo o trabalho pesado para você, inclusive a rotação de IPs, a solução de CAPTCHAs, a renderização de JavaScript e o desvio da proteção contra bots.
Tudo o que você precisa fazer é passar o URL da página de destino para o endpoint da API do Web Unlocker. A API retornará HTML totalmente desbloqueado, mesmo que a página dependa de JavaScript ou esteja protegida por sistemas antibot avançados.
Para integrá-lo ao seu script, basta substituir a linha requests.get() da Etapa 3 pelo código a seguir:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the payload with the target URL
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/affirm-water-bottle/", # Replace this with your target URL on a different scraping scenario
"format": "raw"
}
# Send the request
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)
# Get the unlocked HTML
html_content = response.textPara obter mais detalhes, consulte a documentação oficial do Web Unlocker.
Com um Web Unlocker instalado, você pode usar o Qwen3 com confiança para extrair dados estruturados de qualquer site – sem mais bloqueios, problemas de renderização ou conteúdo ausente.
Alternativas ao Qwen3 for Web Scraping
O Qwen3 não é o único LLM que você pode usar para análise automatizada de dados da Web. Explore algumas abordagens alternativas nos guias a seguir:
- Web Scraping com Gemini: Tutorial completo
- Raspagem da Web usando o Perplexity: Guia passo a passo
- Raspagem da Web do LLM com o ScrapeGraphAI
- Como criar um raspador de IA com o Crawl4AI e o DeepSeek
- Web Scraping com LLaMA 3: Transforme qualquer site em JSON estruturado
Conclusão
Neste tutorial, você aprendeu a executar o Qwen3 localmente usando o Hugging Face para criar um raspador da Web alimentado por IA. Um dos maiores obstáculos na raspagem da Web é ser bloqueado, mas isso foi resolvido usando a API Web Unlocker da Bright Data.
Conforme abordado anteriormente, a combinação do Qwen3 com a API do Web Unlocker permite que você extraia dados de praticamente qualquer site. Tudo isso sem a necessidade de lógica de análise personalizada. Essa configuração mostra apenas um dos muitos casos de uso poderosos possibilitados pela infraestrutura da Bright Data, ajudando você a criar pipelines de dados da Web escaláveis e orientados por IA.
Então, por que parar por aqui? Considere explorar as APIs do Web Scraper –pontos de extremidade dedicadospara extrair dados da Web atualizados, estruturados e totalmente compatíveis de mais de 120 sites populares.
Inscreva-se hoje mesmo em uma conta gratuita da Bright Data e comece a construir com soluções de raspagem prontas para IA!




