

Neste guia, você descobrirá:
- Por que o Perplexity é uma boa opção para raspagem da Web com tecnologia de IA
- Como fazer scraping de um site em Python com um tutorial passo a passo
- A principal limitação dessa abordagem de raspagem da Web e como contorná-la
Vamos começar!
Por que usar o Perplexity para raspagem da Web?
O Perplexity é um mecanismo de pesquisa com tecnologia de IA que utiliza grandes modelos de linguagem para gerar respostas detalhadas às consultas dos usuários. Ele recupera informações em tempo real, resume-as e pode responder com fontes citadas.
A utilização do Perplexity para raspagem da Web reduz o processo de extração de dados de conteúdo HTML não estruturado a um simples prompt. Isso elimina a necessidade de análise manual de dados, facilitando significativamente a extração de informações relevantes.
Além disso, o Perplexity foi desenvolvido para cenários avançados de rastreamento da Web, graças aos seus recursos de descoberta e exploração de páginas da Web.
Para obter mais informações, consulte nosso guia sobre o uso de IA para raspagem da Web.
Casos de uso
Alguns exemplos de casos de uso de raspagem com a tecnologia Perplexity são:
- Páginas que mudam de estrutura com frequência: Pode se adaptar a páginas dinâmicas em que os layouts e os elementos de dados mudam com frequência, como em sites de comércio eletrônico como a Amazon.
- Rastreamento de sites grandes: pode ajudar a descobrir e navegar pelas páginas ou realizar pesquisas orientadas por IA que guiam o processo de raspagem.
- Extração de dados de páginas complexas: Para sites com estruturas difíceis de analisar, o Perplexity pode automatizar a extração de dados sem exigir uma lógica de análise personalizada extensa.
Cenários
Alguns exemplos em que a raspagem com o Perplexity é útil são:
- Geração Aumentada por Recuperação (RAG): Aprimoramento dos insights de IA por meio da integração de raspagem de dados em tempo real. Para obter um exemplo prático usando um modelo de IA semelhante, leia nosso guia sobre como criar um chatbot RAG com dados SERP.
- Agregação de conteúdo: Reunir notícias, postagens de blog ou artigos de várias fontes para gerar resumos ou análises.
- Raspagem de mídia social: Extração de dados estruturados de plataformas com conteúdo dinâmico ou atualizado com frequência.
Como realizar a raspagem da Web com o Perplexity em Python
Para esta seção, usaremos uma página de produto específica da sandbox “Ecommerce Test Site to Learn Web Scraping“:

Essa página representa um ótimo exemplo de destino porque as páginas de produtos de comércio eletrônico geralmente têm estruturas diferentes, exibindo vários tipos de dados. É isso que torna a raspagem da Web de comércio eletrônico tão desafiadora – e onde a IA pode ajudar.
Em particular, o raspador com tecnologia Perplexity aproveitará a IA para extrair esses detalhes do produto da página sem a necessidade de lógica de análise manual:
- SKU
- Nome
- Imagens
- Preço
- Descrição
- Tamanhos
- Cores
- Categoria
Observação: o exemplo a seguir será em Python para simplificar e devido à popularidade dos SDKs envolvidos. Ainda assim, você pode obter o mesmo resultado usando JavaScript ou qualquer outra linguagem de programação.
Siga as etapas abaixo para saber como extrair dados da Web com o Perplexity!
Etapa 1: Configure seu projeto
Antes de começar, verifique se o Python 3 está instalado em seu computador. Se não estiver, faça o download e siga as instruções de instalação.
Em seguida, execute o comando abaixo para inicializar uma pasta para seu projeto de raspagem:
mkdir perplexity-scraperO diretório perplexity-scraper servirá como pasta de projeto para seu projeto de raspagem da Web usando o Perplexity.
Navegue até a pasta em seu terminal e crie um ambiente virtual Python dentro dela:
cd perplexity-scraper
python -m venv venvAbra a pasta do projeto em seu IDE Python preferido. O Visual Studio Code com a extensão Python ou o PyCharm Community Edition são excelentes opções.
Crie um arquivo scraper.py na pasta do projeto, que agora deve ter a seguinte aparência:

Neste momento, o scraper.py é apenas um script Python vazio, mas em breve conterá a lógica para a coleta de dados da Web do LLM.
Em seguida, ative o ambiente virtual no terminal do seu IDE. No Linux ou macOS, execute:
source venv/bin/activateDe forma equivalente, no Windows, use:
venv/Scripts/activateExcelente! Seu ambiente Python agora está configurado para raspagem da Web com o Perplexity.
Etapa 2: Recupere sua chave de API do Perplexity
Como a maioria dos provedores de IA, a Perplexity expõe seus modelos por meio de APIs. Para acessá-los programaticamente, primeiro você precisa resgatar uma chave de API da Perplexity. Você pode consultar a “Configuração inicial” oficial ou seguir as etapas guiadas abaixo.
Se você ainda não tiver uma conta no Perplexity, crie uma e faça login. Em seguida, navegue até a página “API” e clique em “Setup” (Configuração) para adicionar um método de pagamento, caso ainda não o tenha feito:

Observação: você não será cobrado nesta etapa. A Perplexity armazena seus detalhes de pagamento apenas para uso futuro da API. Você pode usar um cartão de crédito/débito, o Google Pay ou qualquer outro método de pagamento compatível.
Quando o método de pagamento estiver configurado, você verá a seção a seguir:

Compre alguns créditos clicando em “+ Buy Credits” e aguarde até que eles sejam adicionados à sua conta. Quando os créditos estiverem disponíveis, o botão “+ Generate” (Gerar) na seção API Keys (Chaves de API) ficará ativo. Pressione-o para gerar sua chave de API do Perplexity:

Uma chave de API será exibida:

Copie a chave e armazene-a em um local seguro. Para simplificar, nós a definiremos como uma constante no scraper.py:
PERPLEXITY_API_KEY="<YOUR_PERPLEXITY_API_KEY>"Importante: nos scripts de raspagem do Perplexity em produção, evite armazenar chaves de API em texto simples. Em vez disso, armazene segredos como esses em variáveis de ambiente ou em um arquivo .env gerenciado com bibliotecas como python-dotenv.
Maravilhoso! Você está pronto para usar o OpenAI SDK para fazer solicitações de API para os modelos da Perplexity em Python.
Etapa 3: Configurar o Perplexity no Python
A última frase da etapa anterior não contém um erro de digitação, embora mencione o OpenAI SDK. Isso ocorre porque a API do Perplexity é totalmente compatível com a OpenAI. Na verdade, a maneira recomendada de se conectar à API da Perplexity usando Python é por meio do SDK da OpenAI.
Como primeira etapa, instale o OpenAI Python SDK. Em um ambiente virtual ativado, execute:
pip install openaiEm seguida, importe-o para seu script scraper.py:
from openai import OpenAIPara se conectar ao Perplexity em vez do OpenAI, configure o cliente da seguinte forma:
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")Muito bom! A configuração do Perplexity Python está concluída e você está pronto para fazer solicitações de API para seus modelos.
Etapa 4: obtenha o HTML da página de destino
Agora, você precisa recuperar o HTML da página de destino. Você pode fazer isso com um poderoso cliente HTTP Python, como o Requests.
Em um ambiente virtual ativado, instale o Requests com:
pip install requestsEm seguida, importe a biblioteca em scraper.py:
import requestsUse o método get() para enviar uma solicitação GET ao URL da página:
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)O servidor de destino responderá com o HTML bruto da página.
Se você imprimir response.content, verá o documento HTML completo:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- omitted for brevity... -->
<title>Ajax Full-Zip Sweatshirt – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>Agora você tem o HTML exato da página de destino em Python. Vamos analisá-lo e extrair dele os dados de que precisamos!
Etapa 5: converter o HTML da página em Markdown (opcional)
Aviso: Esta etapa não é tecnicamente necessária, mas pode economizar muito tempo e dinheiro. Portanto, definitivamente vale a pena considerá-la.
Reserve um momento para explorar como outras tecnologias de raspagem da Web com tecnologia de IA, como Crawl4AI e ScrapeGraphAI, lidam com HTML bruto. Você perceberá que ambas oferecem opções para converter HTML em Markdown antes de passar o conteúdo para o LLM configurado.
Por que eles fazem isso? Há dois motivos principais:
- Eficiência de custos: A conversão para Markdown reduz o número de tokens enviados para a IA, ajudando você a economizar dinheiro.
- Processamento mais rápido: Menos dados de entrada significa custos computacionais mais baixos e respostas mais rápidas.
Para obter mais informações, leia nosso guia sobre por que os novos agentes de IA escolhem Markdown em vez de HTML.
É hora de replicar a lógica de conversão de HTML para Markdown para reduzir o uso de tokens!
Comece abrindo a página da Web de destino no modo de navegação anônima (para ter certeza de que está operando em uma nova sessão). Em seguida, clique com o botão direito do mouse em qualquer lugar da página e selecione “Inspecionar” para abrir as ferramentas do desenvolvedor.
Examine a estrutura da página. Você verá que todos os dados relevantes estão contidos no elemento HTML identificado pelo seletor CSS #main:

Tecnicamente, você poderia enviar todo o HTML bruto para a Perplexity para análise de dados. No entanto, isso incluiria muitas informações desnecessárias, como cabeçalhos e rodapés. Em vez disso, usar o conteúdo dentro de #main como dados brutos de entrada garante que você esteja lidando apenas com os dados mais relevantes. Isso reduzirá o ruído e limitará as alucinações da IA.
Para extrair apenas o elemento #main, você precisa de uma biblioteca de análise de HTML do Python, como a Beautiful Soup. Em seu ambiente virtual Python ativado, instale-a com este comando:
pip install beautifulsoup4Se você não estiver familiarizado com sua API, leia nosso guia sobre raspagem da Web da Beautiful Soup.
Agora, importe-o no scraper.py:
from bs4 import BeautifulSoupUse o Beautiful Soup para:
- Analisar o HTML bruto obtido com Requests
- Selecione o elemento
#main - Obter seu conteúdo HTML
Consiga isso com este snippet:
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)Se você imprimir main_html, verá algo parecido com isto:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<div class="woocommerce-notices-wrapper"
id="notices-wrapper"
data-testid="notices-wrapper"
data-sorting="notices">
</div>
<div id="product-309"
class="product type-product post-309 status-publish first outofstock
product_cat-hoodies-sweatshirts has-post-thumbnail
shipping-taxable purchasable product-type-variable">
<!-- omitted for brevity... -->
</div>
</main>Use a ferramenta Tokenizer da OpenAI para verificar a quantos tokens o HTML selecionado corresponde:

Em seguida, estime o custo de enviar esses tokens para a API da Perplexity usando a calculadora de preços de API do LLM:

Como você pode ver, essa abordagem resulta em mais de 20.000 tokens. Isso significa de US$ 0,21 a cerca de US$ 0,63 por solicitação. Em um projeto de grande escala com milhares de páginas, isso é muito!
Para reduzir o consumo de tokens, converta o HTML extraído em Markdown usando uma biblioteca como markdownify. Instale-a em seu projeto de raspagem com a tecnologia Perplexity com:
pip install markdownifyImportar markdownify em scraper.py:
from markdownify import markdownifyEm seguida, use-o para converter o HTML de #main para Markdown:
main_markdown = markdownify(main_html)O processo de conversão de dados produzirá o resultado abaixo:

Pelo elemento “size” no final das duas áreas de texto, você pode ver que a versão Markdown dos dados de entrada é muito menor do que o HTML #main original. Além disso, após a inspeção, você notará que ela ainda contém todos os dados principais a serem extraídos!
Use o Tokenizer da OpenAI novamente para verificar quantos tokens a nova entrada Markdown consome:

Com esse truque simples, você reduziu 20.658 tokens para 950 tokens – uma redução de mais de 95%. Isso também se traduz em uma enorme redução nos custos da API da Perplexity por solicitação:
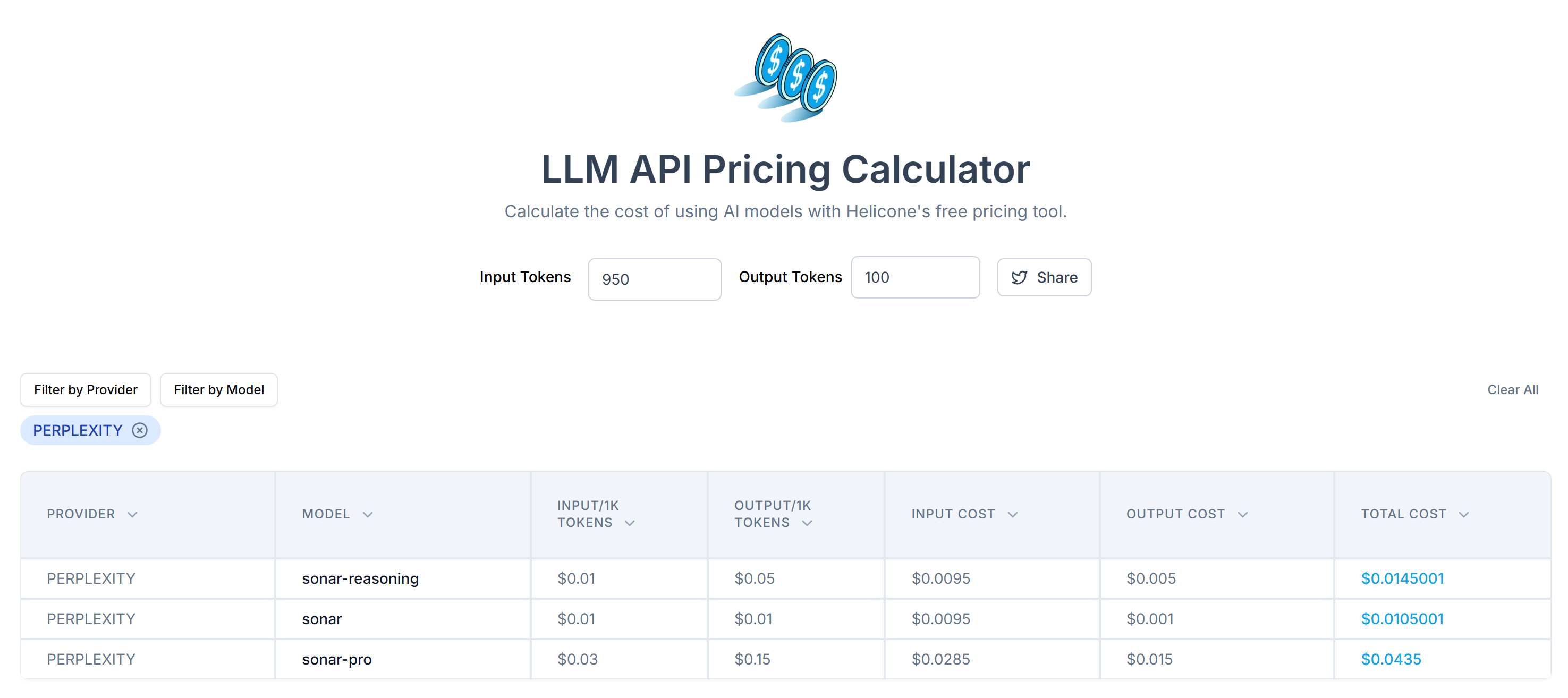
O custo cai de cerca de US$ 0,21 a US$ 0,63 por solicitação para apenas US$ 0,014 a US$ 0,04 por solicitação!
Etapa nº 6: usar a perplexidade para análise de dados
Siga estas etapas para extrair dados usando o Perplexity:
- Escreva um prompt bem estruturado para extrair dados JSON no formato desejado a partir da entrada Markdown
- Envie uma solicitação ao modelo LLM da Perplexity usando o OpenAI Python SDK
- Analisar o JSON retornado
Implemente as duas primeiras etapas com o código a seguir:
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.contentA variável prompt instrui o Perplexity a extrair dados estruturados do conteúdo do main_markdown. Para melhorar os resultados, é recomendável definir um prompt claro para o sistema, para que ele saiba como se comportar e o que fazer.
Observação: o Perplexity ainda se baseia na antiga sintaxe herdada da OpenAI para fazer chamadas de API. Se você tentar usar a sintaxe responses.create() mais recente, encontrará o seguinte erro:
httpx.HTTPStatusError: Client error '404 Not Found' for url 'https://api.perplexity.ai/responses'Agora, product_raw_string deve conter dados JSON no seguinte formato:
"```json
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "$69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.nnMint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": ["XS", "S", "M", "L", "XL"],
"colors": ["Blue", "Green", "Red"],
"category": "Hoodies & Sweatshirts"
}
```"Como você pode ver, o Perplexity retorna os dados no formato Markdown.
Para implementar a etapa 3 do algoritmo no início desta seção, é necessário extrair o conteúdo JSON bruto usando uma regex. Em seguida, você pode analisar os dados JSON resultantes para o dicionário Python json.loads():
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)Não se esqueça de importar json e re da Biblioteca Padrão do Python:
import json
import reObservação: se você for um usuário Perplexity Tier-3, poderá ignorar a etapa de análise de regex configurando a API para retornar dados diretamente em um formato JSON estruturado. Encontre mais informações no guia “Structured Outputs” do Perplexity.
Depois de analisar o dicionário product_data, você pode acessar os campos para processamento adicional de dados. Por exemplo:
price = product_data["price"]
price_eur = price * USD_EUR
# ...Fantástico! Você utilizou com sucesso o Perplexity para coleta de dados da Web. Só falta exportar os dados extraídos conforme necessário.
Etapa nº 7: Exportar os dados extraídos
Atualmente, você tem os dados extraídos armazenados em um dicionário Python. Para salvá-los como um arquivo JSON, use o seguinte código:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Isso gerará um arquivo product.json contendo os dados extraídos no formato JSON.
Muito bem! Seu coletor de dados da Web baseado no Perplexity está pronto.
Etapa #8: Juntar tudo
Aqui está o código completo de seu script de raspagem usando o Perplexity para análise de dados:
from openai import OpenAI
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import re
import json
# Your Perplexity API key
PERPLEXITY_API_KEY = "<YOUR_PERPLEXITY_API_KEY>" # replace with your API key
# Conffigure the OpenAI SDK to connect to Perplexity
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")
# Retrieve the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)
# Convert the #main HTML to Markdown
main_markdown = markdownify(main_html)
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.content
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Execute o script de raspagem com:
python scraper.pyAo final da execução, um arquivo product.json será gerado na pasta do seu projeto. Abra-o e você encontrará dados estruturados como estes:
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.n• Mint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Blue",
"Green",
"Red"
],
"category": "Hoodies & Sweatshirts"
}E pronto! O script transformou dados não estruturados de uma página HTML em um arquivo JSON bem organizado, tudo graças à raspagem da Web com a tecnologia Perplexity.
Próximas etapas
Para levar seu raspador acionado pelo Perplexity para o próximo nível, considere estas melhorias:
- Torne-o reutilizável: Modifique o script para aceitar o prompt e o URL de destino como argumentos de linha de comando. Isso tornará o raspador mais flexível e adaptável a diferentes casos de uso e projetos.
- Proteja as credenciais da API: Armazene sua chave de API do Perplexity em um arquivo .env e use python-dotenv para carregá-la com segurança. Essa abordagem evita a codificação de credenciais confidenciais no script, melhorando a segurança ao manter os segredos privados e separados da base de código.
- Implemente o rastreamento da Web: Aproveite os recursos de pesquisa e rastreamento com tecnologia de IA da Perplexity para um rastreamento inteligente e otimizado. Configure o raspador para navegar pelas páginas vinculadas, extraindo dados estruturados de várias fontes.
Superando a maior limitação desse método de raspagem da Web
Qual é a maior limitação dessa abordagem baseada em IA para raspagem da Web? A solicitação HTTP feita por solicitações!
Embora o exemplo acima tenha funcionado perfeitamente, isso se deve ao fato de o site de destino ser essencialmente um playground de raspagem da Web. Na realidade, as empresas e os proprietários de sites entendem o valor de seus dados, mesmo quando eles são acessíveis ao público. Para protegê-los, eles implementam medidas antirraspagem que podem bloquear facilmente suas solicitações HTTP automatizadas.
Nesses casos, o script falhará com erros 403 Forbidden, como:
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: <YOUR_TARGET_URL>
Além disso, essa abordagem não funciona em páginas dinâmicas da Web que dependem do JavaScript para renderização ou para buscar dados de forma assíncrona. Assim, os sites não precisam nem mesmo de defesas antibot avançadas para bloquear seu scraper com LLM.
Então, qual é a solução para todos esses problemas? Uma API de desbloqueio da Web!
A API do Web Unlocker da Bright Data é um ponto de extremidade de raspagem que você pode chamar de qualquer cliente HTTP. Ele retorna o HTML totalmente desbloqueado de qualquer URL que você passar para ele, contornando os bloqueios antirraspagem para você. Não importa quantas proteções um site-alvo tenha, uma simples solicitação ao Web Unlocker recuperará o HTML da página para você.
Para começar, siga a documentação oficial do Web Unlocker para recuperar sua chave de API. Em seguida, substitua seu código de solicitação existente da “Etapa 4” por estas linhas:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)
E assim, sem mais bloqueios, sem mais limitações! Agora você pode fazer scraping da Web usando o Perplexity sem se preocupar com bloqueios.
Conclusão
Neste tutorial, você aprendeu a usar o Perplexity em combinação com o Requests e outras ferramentas para criar um raspador alimentado por IA. Um dos maiores desafios da raspagem da Web é o risco de ser bloqueado, mas isso foi resolvido usando a API Web Unlocker da Bright Data.
Conforme discutido, ao integrar o Perplexity com a API do Web Unlocker, você pode extrair dados de qualquer site sem a necessidade de lógica de análise personalizada. Esse é apenas um dos muitos casos de uso suportados pelos produtos e serviços da Bright Data, permitindo que você implemente uma raspagem eficiente da Web orientada por IA.
Explore nossas outras ferramentas de raspagem da Web:
- Serviços de proxy: Quatro tipos de proxies para contornar restrições de localização, incluindo acesso a mais de 400M+ monthly de IPs residenciais.
- APIs do Web Scraper: Pontos de extremidade dedicados para extrair dados da Web novos e estruturados de mais de 100 domínios populares.
- API SERP: API para gerenciar o desbloqueio contínuo de SERPs e extrair páginas individuais.
- Navegador de raspagem: Um navegador de nuvem compatível com Puppeteer, Selenium e Playwright, com recursos de desbloqueio incorporados.
Inscreva-se agora na Bright Data e teste nossos serviços de proxy e produtos de raspagem gratuitamente!





