

Neste tutorial, você aprenderá:
- O que é o Crawl4AI e o que ele oferece para raspagem da Web
- Os cenários ideais para usar o Crawl4AI com um LLM como o DeepSeek
- Como criar um scraper Crawl4AI com tecnologia DeepSeek em uma seção guiada.
Vamos mergulhar de cabeça!
O que é o Craw4AI?
O Crawl4AI é um rastreador e raspador da Web de código aberto, pronto para IA, projetado para integração perfeita com modelos de linguagem grandes (LLMs), agentes de IA e pipelines de dados. Ele oferece extração de dados em tempo real e em alta velocidade, além de ser flexível e fácil de implantar.
Os recursos que ele oferece para raspagem da Web com IA são:
- Criado para LLMs: Gera Markdown estruturado otimizado para geração aumentada por recuperação (RAG) e ajuste fino.
- Controle flexível do navegador: Oferece suporte ao gerenciamento de sessões, proxies e ganchos personalizados.
- Inteligência heurística: Usa algoritmos inteligentes para otimizar a análise de dados.
- Código-fonte totalmente aberto: Sem necessidade de chaves de API; implementável via Docker e plataformas de nuvem.
Saiba mais na documentação oficial.
Quando usar o Crawl4AI e o DeepSeek para raspagem da Web
O DeepSeek oferece modelos LLM poderosos, de código aberto e gratuitos que causaram impacto na comunidade de IA devido à sua eficiência e eficácia. Além disso, esses modelos se integram perfeitamente ao Crawl4AI.
Ao aproveitar o DeepSeek no Crawl4AI, você pode extrair dados estruturados até mesmo das páginas da Web mais complexas e inconsistentes. Tudo isso sem a necessidade de uma lógica de análise predefinida.
Abaixo estão os principais cenários em que a combinação DeepSeek + Crawl4AI é especialmente útil:
- Mudanças frequentes na estrutura do site: Os raspadores tradicionais quebram quando os sites atualizam sua estrutura HTML, mas a IA se adapta dinamicamente.
- Layouts de página inconsistentes: Plataformas como a Amazon têm diferentes designs de páginas de produtos. Um LLM pode extrair dados de forma inteligente, independentemente das diferenças de layout.
- Análise de conteúdo não estruturado: A extração de insights de análises de texto livre, postagens de blog ou discussões em fóruns torna-se fácil com o processamento com base no LLM.
Raspagem da Web com o Craw4AI e o DeepSeek: Guia passo a passo
Neste tutorial guiado, você aprenderá a criar um raspador da Web com tecnologia de IA usando o Crawl4AI. Como mecanismo LLM, usaremos o DeepSeek.
Especificamente, você verá como criar um raspador de IA para extrair dados da página G2 para a Bright Data:
Siga as etapas abaixo e saiba como realizar a coleta de dados da Web com o Crawl4AI e o DeepSeek!
Pré-requisitos
Para seguir este tutorial, verifique se você atende aos seguintes pré-requisitos:
- Python 3+ instalado em seu computador
- Uma conta do GroqCloud
- Uma conta da Bright Data
Não se preocupe se você ainda não tiver uma conta do GroqCloud ou do Bright Data. Você será orientado sobre a configuração delas nas próximas etapas.
Etapa 1: Configuração do projeto
Execute o seguinte comando para criar uma pasta para seu projeto de raspagem do Crawl4AI DeepSeek:
mkdir crawl4ai-deepseek-scraperNavegue até a pasta do projeto e crie um ambiente virtual:
cd crawl4ai-deepseek-scraper
python -m venv venvAgora, carregue a pasta crawl4ai-deepseek-scraper em seu IDE Python favorito. O Visual Studio Code com a extensão Python ou o PyCharm Community Edition são duas ótimas opções.
Dentro da pasta do projeto, crie:
scraper.py: O arquivo que conterá a lógica de raspagem alimentada por IA.models/: Um diretório para armazenar modelos de dados do LLM do Crawl4AI baseados em Pydantic..env: Um arquivo para armazenar variáveis de ambiente de forma segura.
Depois de criar esses arquivos e pastas, a estrutura do seu projeto deverá ter a seguinte aparência:

Em seguida, ative o ambiente virtual no terminal do seu IDE.
No Linux ou macOS, execute este comando:
./env/bin/activateDe forma equivalente, no Windows, execute:
env/Scripts/activateExcelente! Agora você tem um ambiente Python para a coleta de dados da Web do Crawl4AI com o DeepSeek.
Etapa 2: Instalar o Craw4AI
Com seu ambiente virtual ativado, instale o Crawl4AI por meio do pacote pip crawl4ai:
pip install crawl4aiObserve que a biblioteca tem várias dependências, portanto, a instalação pode demorar um pouco.
Depois de instalado, execute o seguinte comando em seu terminal:
crawl4ai-setupO processo:
- Instale ou atualize os navegadores Playwright necessários (Chromium, Firefox, etc.).
- Realiza verificações no nível do sistema operacional (por exemplo, garantir que as bibliotecas de sistema necessárias estejam instaladas no Linux).
- Confirma que seu ambiente está configurado corretamente para rastreamento na Web.
Depois de executar o comando, você verá uma saída semelhante a esta:
[INIT].... → Running post-installation setup...
[INIT].... → Installing Playwright browsers...
[COMPLETE] ● Playwright installation completed successfully.
[INIT].... → Starting database initialization...
[COMPLETE] ● Database backup created at: C:Usersantoz.crawl4aicrawl4ai.db.backup_20260219_092341
[INIT].... → Starting database migration...
[COMPLETE] ● Migration completed. 0 records processed.
[COMPLETE] ● Database initialization completed successfully.
[COMPLETE] ● Post-installation setup completed!Incrível! O Crawl4AI agora está instalado e pronto para ser usado.
Etapa 4: Inicializar o scraper.py
Como o Crawl4AI requer código assíncrono, comece criando um script assíncrono básico:
import asyncio
async def main():
# Scraping logic...
if __name__ == "__main__":
asyncio.run(main())Agora, lembre-se de que o projeto envolve integrações com serviços de terceiros, como o DeepSeek. Para implementar isso, você precisará contar com chaves de API e outros segredos. Nós os armazenaremos em um arquivo .env.
Instale o python-dotenv para carregar variáveis de ambiente:
pip install python-dotenvAntes de definir main(), carregue as variáveis de ambiente do arquivo .env com load_dotenv():
load_dotenv()Importar load_dotenv da biblioteca python-dotenv:
from dotenv import load_dotenvPerfeito! O scraper.py está pronto para hospedar alguma lógica de raspagem acionada por IA.
Etapa nº 5: Crie seu primeiro raspador de IA
Dentro da função main() em scraper.py, adicione a seguinte lógica usando um rastreador Crawl4AI básico:
# Browser configuration
browser_config = BrowserConfig(
headless=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# print the first 1000 characters
print(f"Parsed Markdown data:n{result.markdown[:1000]}")No trecho acima, os pontos principais são:
BrowserConfig: Controla como o navegador é iniciado e se comporta, incluindo configurações como o modo headless e agentes de usuário personalizados para raspagem da Web.CrawlerRunConfig: Define o comportamento de rastreamento, como estratégia de cache, regras de seleção de dados, tempos limite e muito mais.headless=True: configura o navegador para ser executado no modo headless – sema GUI – para economizar recursos.CacheMode.BYPASS: essa configuração garante que o rastreador obtenha conteúdo novo diretamente do site em vez de depender de dados armazenados em cache.crawler.arun(): Esse método inicia o rastreador assíncrono para extrair dados do URL especificado.result.markdown: O conteúdo extraído é convertido no formato Markdown, o que facilita a análise e a análise.
Não se esqueça de adicionar as seguintes importações:
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheModeNo momento, o scraper.py deve conter:
import asyncio
from dotenv import load_dotenv
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
# Load secrets from .env file
load_dotenv()
async def main():
# Browser configuration
browser_config = BrowserConfig(
headless=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# print the first 1000 characters
print(f"Parsed Markdown data:n{result.markdown[:1000]}")
if __name__ == "__main__":
asyncio.run(main())Se você executar o script, verá um resultado como o abaixo:
[INIT].... → Crawl4AI 0.4.248
[FETCH]... ↓ https://www.g2.com/products/bright-data/reviews... | Status: True | Time: 0.83s
[SCRAPE].. ◆ Processed https://www.g2.com/products/bright-data/reviews... | Time: 1ms
[COMPLETE] ● https://www.g2.com/products/bright-data/reviews... | Status: True | Total: 0.83s
Parsed Markdown data:Isso é suspeito, pois o conteúdo Markdown analisado está vazio. Para investigar mais a fundo, imprima o status da resposta:
print(f"Response status code: {result.status_code}")Dessa vez, o resultado incluirá:
Response status code: 403O resultado analisado pelo Markdown está vazio porque a solicitação do Crawl4AI foi bloqueada pelos sistemas de detecção de bots do G2. Isso fica claro pelo código de status 403 Forbidden retornado pelo servidor.
Isso não deveria ser surpreendente, pois o G2 tem medidas anti-bot rigorosas em vigor. Em particular, ele frequentemente exibe CAPTCHAs, mesmo quando acessado por meio de um navegador comum:

Nesse caso, como nenhum conteúdo válido foi recebido, o Crawl4AI não pôde convertê-lo em Markdown. Na próxima etapa, exploraremos como contornar essa restrição. Para ler mais, dê uma olhada no nosso guia sobre como contornar CAPTCHAs em Python.
Etapa 6: Configurar a API do Web Unlocker
O Crawl4AI é uma ferramenta avançada com mecanismos de desvio de bots incorporados. No entanto, ele não pode contornar sites altamente protegidos como o G2, que empregam medidas rigorosas e de alto nível contra bots e scraping.
Contra esses sites, a melhor solução é usar uma ferramenta dedicada projetada para desbloquear qualquer página da Web, independentemente de seu nível de proteção. O produto de raspagem ideal para essa tarefa é o Web Unlocker da Bright Data, uma API de raspagem que:
- Simula o comportamento real do usuário para contornar a detecção de antibot
- Gerencia o gerenciamento de proxy e a resolução de CAPTCHA automaticamente
- Escalonamento contínuo sem necessidade de gerenciamento de infraestrutura
Siga as próximas instruções para integrar a API do Web Unlocker em seu scraper Crawl4AI DeepSeek.
Como alternativa, dê uma olhada na documentação oficial.
Primeiro, faça login na sua conta da Bright Data ou crie uma, caso ainda não o tenha feito. Financie sua conta ou aproveite a avaliação gratuita disponível para todos os produtos.
Em seguida, navegue até “Proxies & Scraping” no painel e selecione a opção “unblocker” na tabela:
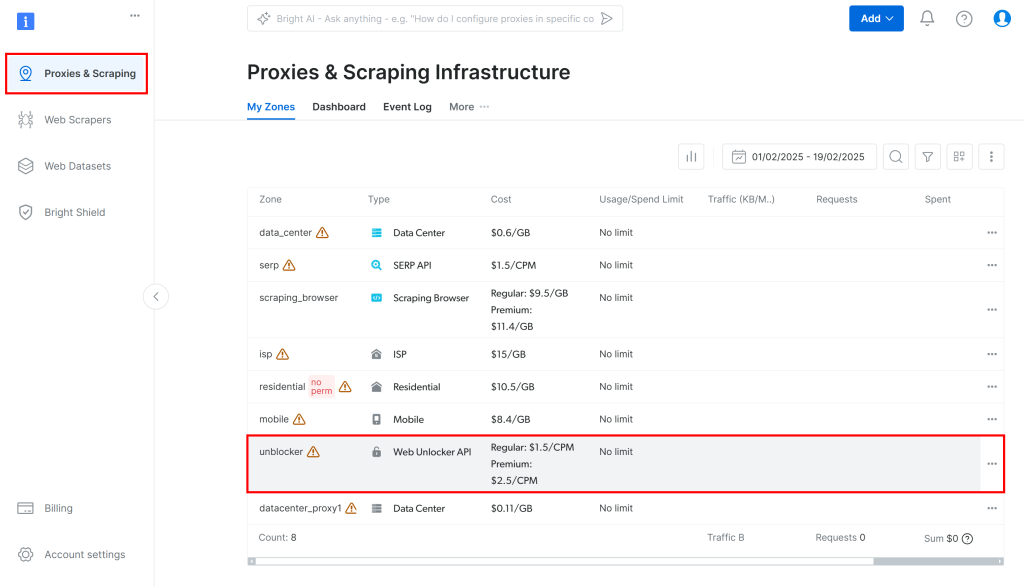
Isso o levará à página de configuração da API do Web Unlocker mostrada abaixo:
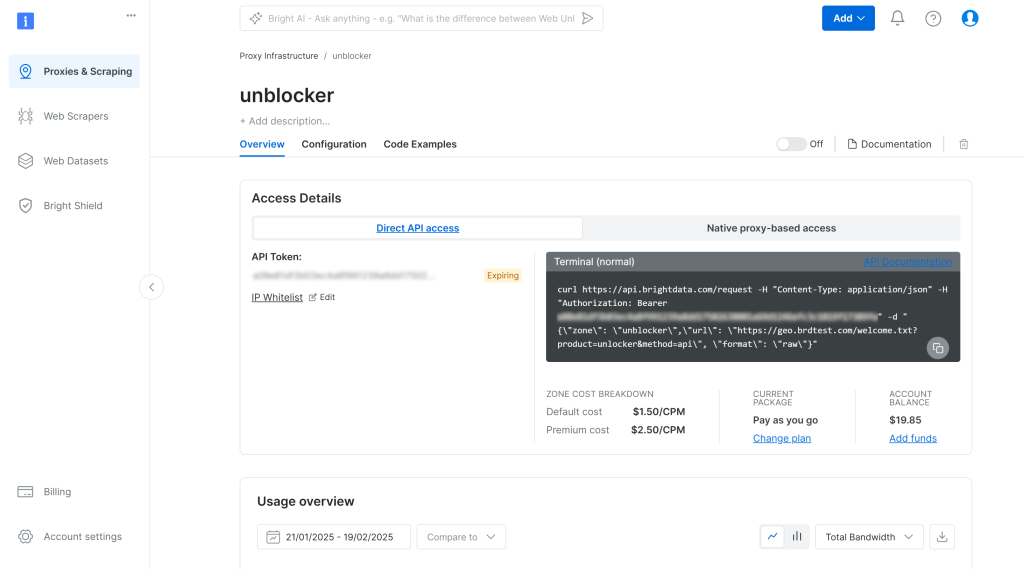
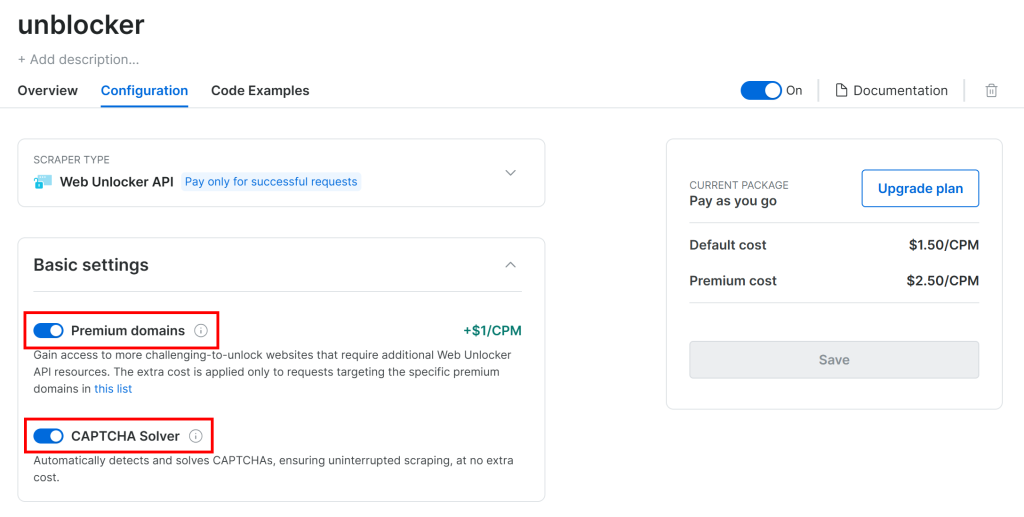
Aqui, ative a API do Web Unlocker clicando no botão de alternância:

O G2 é protegido por defesas anti-bot avançadas, incluindo CAPTCHAs. Portanto, verifique se as duas opções a seguir estão ativadas na página “Configuration” (Configuração):
O Crawl4AI opera navegando pelas páginas em um navegador controlado. Na parte interna, ele se baseia na função goto() do Playwright, que envia uma solicitação HTTP GET para a página da Web de destino. Por outro lado, a API do Web Unlocker funciona por meio de solicitações POST.
Isso não é um problema, pois você ainda pode usar a API do Web Unlocker com o Crawl4AI, configurando-o como um proxy. Isso permite que o navegador do Crawl4AI envie solicitações por meio do produto da Bright Data, recebendo de volta páginas HTML desbloqueadas.
Para acessar suas credenciais de proxy da API do Web Unlocker, acesse a guia “Native proxy-based access” (Acesso nativo baseado em proxy) na página “Overview” (Visão geral):
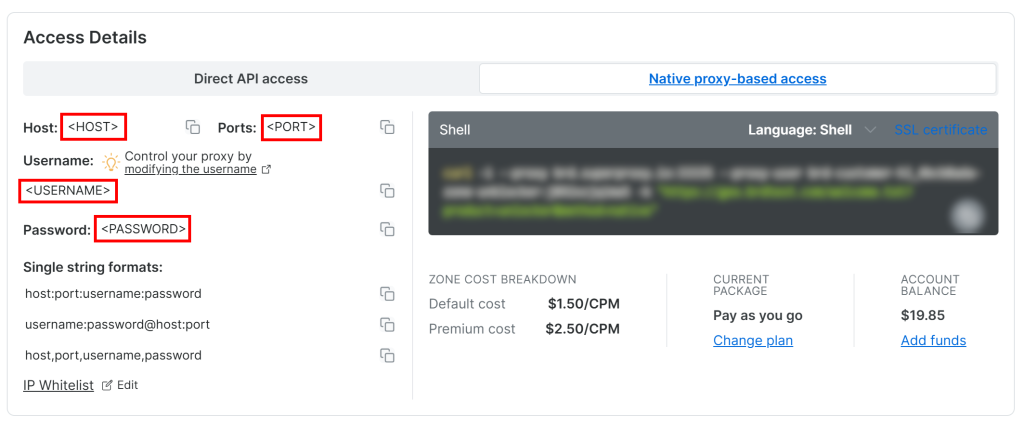
Copie as seguintes credenciais da página:
<HOST><PORT><USERNAME><PASSWORD>
Em seguida, use-as para preencher seu arquivo .env com essas variáveis de ambiente:
PROXY_SERVER=https://<HOST>:<PORT>
PROXY_USERNAME=<USERNAME>
PROXY_PASSWORD=<PASSWORD>Fantástico! O Web Unlocker agora está pronto para integração com o Crawl4AI.
Etapa nº 7: Integrar a API do Web Unlocker
O BrowserConfig oferece suporte à integração de proxy por meio do objeto proxy_config. Para integrar a API do Web Unlocker ao Crawl4AI, preencha esse objeto com as variáveis de ambiente do seu arquivo .env e passe-o para o construtor do BrowserConfig:
# Bright Data's Web Unlocker API proxy configuration
proxy_config = {
"server": os.getenv("PROXY_SERVER"),
"username": os.getenv("PROXY_USERNAME"),
"password": os.getenv("PROXY_PASSWORD")
}
# Browser configuration
browser_config = BrowserConfig(
headless=True,
proxy_config=proxy_config,
)Lembre-se de importar os da biblioteca padrão do Python:
import osLembre-se de que a API do Web Unlocker introduz uma sobrecarga de tempo devido à rotação de IPs por meio do proxy e à eventual resolução do CAPTCHA. Para levar isso em conta, você deve:
- Aumentar o tempo limite de carregamento da página para 3 minutos
- Instrua o rastreador a aguardar que o DOM seja totalmente carregado antes de analisá-lo
Faça isso com a seguinte configuração do CrawlerRunConfig:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded", # wait until the DOM of the page has been loaded
page_timeout=180000, # wait up to 3 mins for page load
)Observe que mesmo a API do Web Unlocker não é perfeita ao lidar com sites complexos como o G2. Raramente, a API de raspagem pode não conseguir recuperar a página desbloqueada, fazendo com que o script seja encerrado com o seguinte erro:
Error: Failed on navigating ACS-GOTO:
Page.goto: net::ERR_HTTP_RESPONSE_CODE_FAILURE at https://www.g2.com/products/bright-data/reviewsFique tranquilo, você só será cobrado por solicitações bem-sucedidas. Portanto, não há necessidade de se preocupar em reiniciar o script até que ele funcione. Em um script de produção, considere a implementação de uma lógica de nova tentativa automática.
Quando a solicitação for bem-sucedida, você receberá um resultado como este:
Response status code: 200
Parsed Markdown data:
* [Home](https://www.g2.com/products/bright-data/</>)
* [Write a Review](https://www.g2.com/products/bright-data/</wizard/new-review>)
* Browse
* [Top Categories](https://www.g2.com/products/bright-data/<#>)
Top Categories
* [AI Chatbots Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/ai-chatbots>)
* [CRM Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/crm>)
* [Project Management Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/project-management>)
* [Expense Management Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/expense-management>)
* [Video Conferencing Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/video-conferencing>)
* [Online Backup Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/online-backup>)
* [E-Commerce Platforms](https://www.g2.com/products/brigExcelente! Dessa vez, o G2 respondeu com um código de status 200 OK. Isso significa que a solicitação não foi bloqueada e que o Crawl4AI conseguiu analisar com êxito o HTML em Markdown, conforme pretendido.
Etapa 8: Configuração do Groq
O GroqCloud é um dos poucos provedores que oferece suporte aos modelos de IA do DeepSeek por meio de APIs compatíveis com OpenAI – mesmo em um plano gratuito. Portanto, ele será a plataforma usada para a integração do LLM no Crawl4AI.
Se você ainda não tiver uma conta Groq, crie uma. Caso contrário, basta fazer login. No painel do usuário, navegue até “API Keys” (Chaves de API) no menu à esquerda e clique no botão “Create API Key” (Criar chave de API):
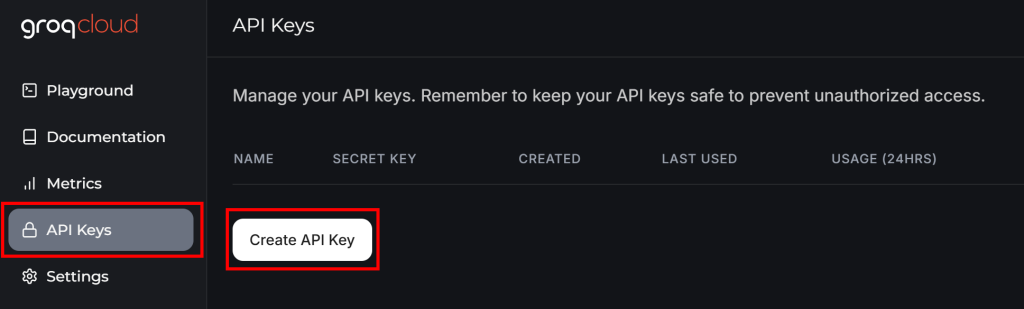
Será exibida uma janela pop-up:
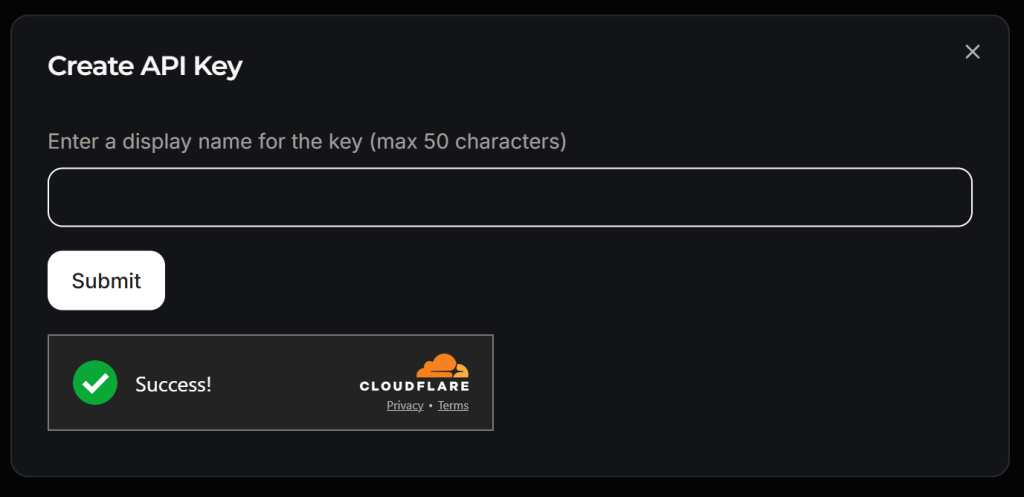
Dê um nome à sua chave de API (por exemplo, “Crawl4AI Scraping”) e aguarde a verificação antibot pela Cloudflare. Em seguida, clique em “Submit” (Enviar) para gerar sua chave de API:
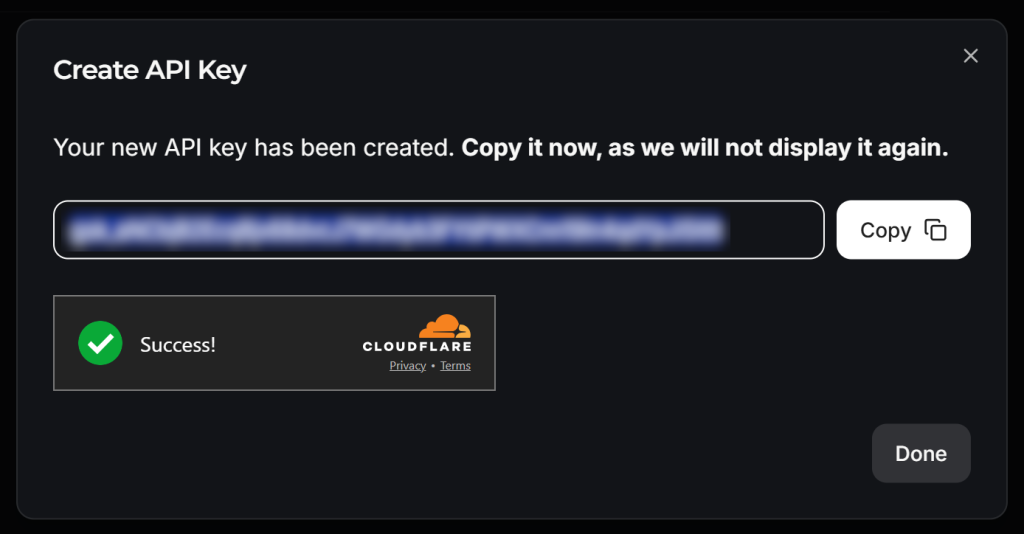
Copie a chave da API e adicione-a ao seu arquivo .env, conforme abaixo:
LLM_API_TOKEN=<YOUR_GROK_API_KEY>Substituir pela chave de API real fornecida pelo Groq.
Lindo! Você está pronto para usar o DeepSeek para raspagem de LLM com o Crawl4AI.
Etapa 9: Defina um esquema para seus dados extraídos
O Crawl4AI realiza a raspagem do LLM seguindo uma abordagem baseada em esquema. Nesse contexto, um esquema é uma estrutura de dados JSON que define:
- Um seletor de base que identifica o elemento “contêiner” na página (por exemplo, uma linha de produto, um cartão de postagem de blog).
- Campos que especificam os seletores CSS/XPath para capturar cada parte dos dados (por exemplo, texto, atributo, bloco HTML).
- Tipos aninhados ou de lista para estruturas repetidas ou hierárquicas.
Para definir o esquema, você deve primeiro identificar os dados que deseja extrair da página de destino. Para fazer isso, abra a página de destino no modo anônimo em seu navegador:
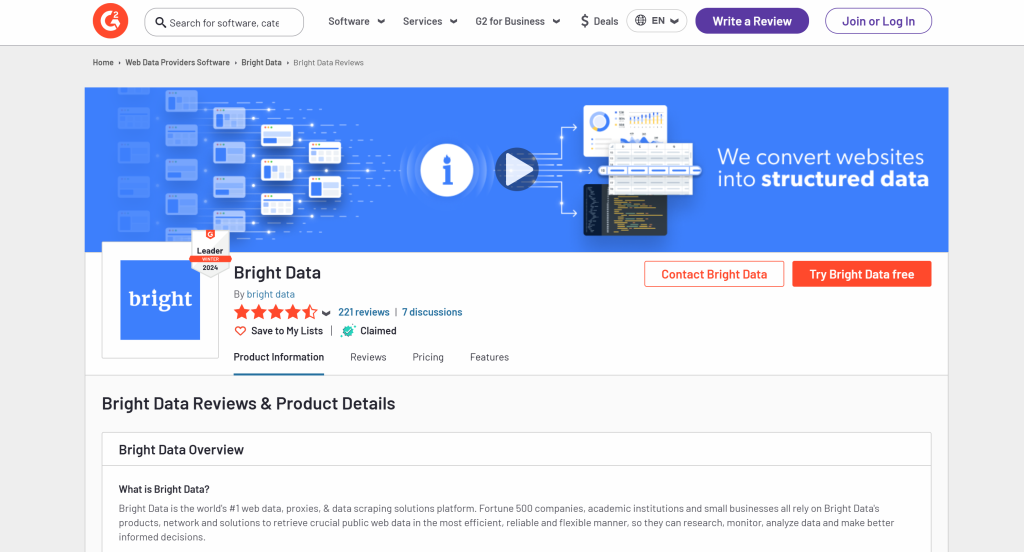
Nesse caso, suponha que você esteja interessado nos seguintes campos:
name: O nome do produto/empresa.image_url: O URL da imagem do produto/empresa.descrição: Uma breve descrição do produto/empresa.review_score: A pontuação média da avaliação do produto/empresa.number_of_reviews: O número total de avaliações.reivindicado: Um booleano que indica se o perfil da empresa é reivindicado pelo proprietário.
Agora, na pasta models, crie um arquivo g2_product.py e preencha-o com uma classe de esquema baseada em Pydantic chamada G2Product da seguinte forma:
# ./models/g2_product.py
from pydantic import BaseModel
class G2Product(BaseModel):
"""
Represents the data structure of a G2 product/company page.
"""
name: str
image_url: str
description: str
review_score: str
number_of_reviews: str
claimed: boolSim! O processo de raspagem do LLM realizado pelo DeepSeek retornará objetos que seguem o esquema acima.
Etapa nº 10: Prepare-se para integrar o DeepSeek
Antes de concluir a integração do DeepSeek com o Crawl4AI, revise a página “Configurações > Limites” em sua conta do GroqCloud:
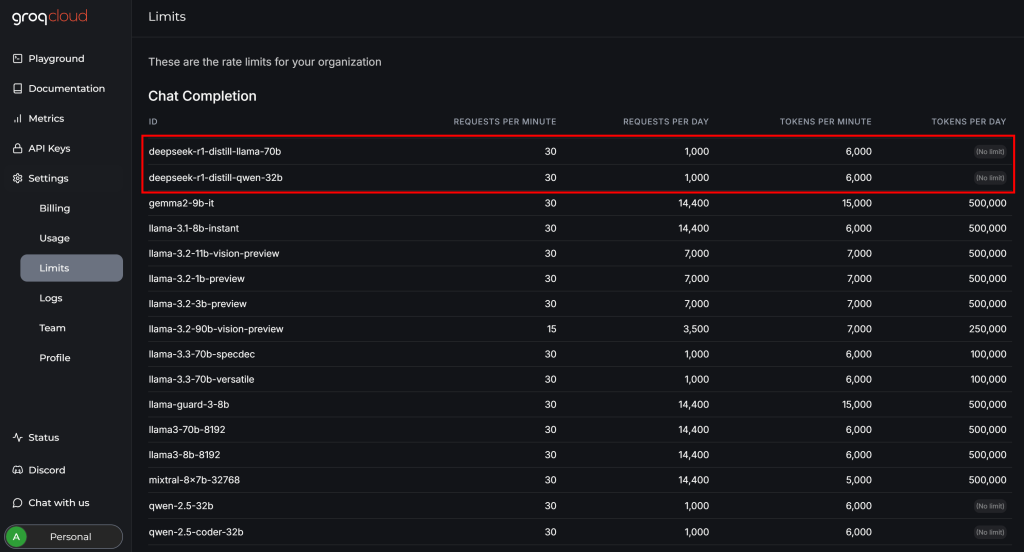
Lá, você pode ver que os dois modelos disponíveis do DeepSeek têm as seguintes limitações no plano gratuito:
- Até 30 solicitações por minuto
- Até 1.000 solicitações por dia
- Não mais do que 6.000 tokens por minuto
Embora as duas primeiras restrições não sejam um problema para este exemplo, a última representa um desafio. Uma página da Web típica pode conter milhões de caracteres, o que se traduz em centenas de milhares de tokens.
Em outras palavras, você não pode alimentar toda a página G2 diretamente nos modelos do DeepSeek via Groq devido aos limites de token. Para resolver o problema, o Crawl4AI permite selecionar apenas seções específicas da página. Essas seções – e não a página inteira – serão convertidas em Markdown e passadas para o LLM. O processo de seleção de seções se baseia em seletores CSS.
Para determinar as seções a serem selecionadas, abra a página de destino no seu navegador. Clique com o botão direito do mouse nos elementos que contêm os dados de interesse e selecione a opção “Inspect” (Inspecionar):
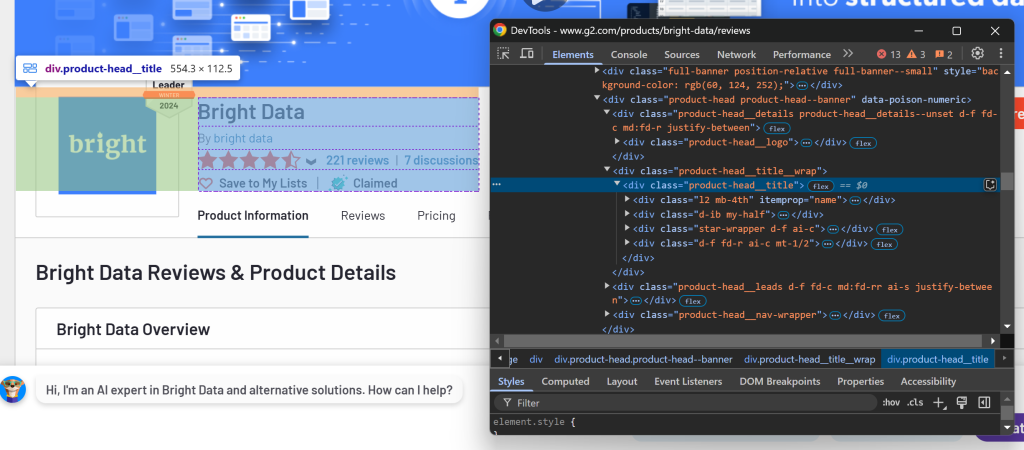
Aqui, você pode observar que o elemento .product-head__title contém o nome do produto/empresa, a pontuação da avaliação, o número de avaliações e o status reivindicado.
Agora, inspecione a seção do logotipo:
Você pode recuperar essas informações usando o seletor CSS .product-head__logo.
Por fim, inspecione a seção de descrição:
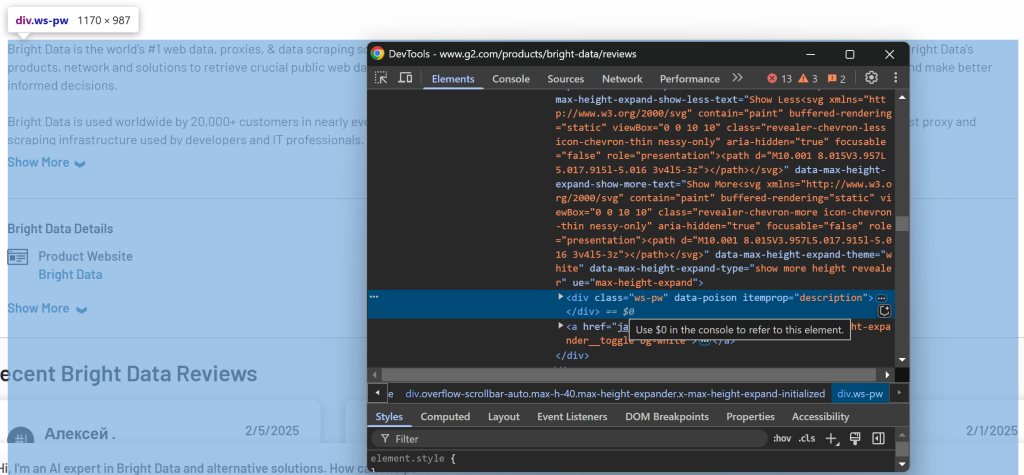
A descrição está disponível usando o seletor [itemprop="description"].
Configure esses seletores CSS no CrawlerRunConfig da seguinte forma:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000,
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]", # the CSS selectors of the elements to extract data from
)Se você executar o scraper.py novamente, obterá algo como:
Response status code: 200
Parsed Markdown data:
[](https:/www.g2.com/products/bright-data/reviews)
[Editedit](https:/my.g2.com/bright-data/product_information)
[Bright Data](https:/www.g2.com/products/bright-data/reviews)
By [bright data](https:/www.g2.com/sellers/bright-data)
Show rating breakdown
4.7 out of 5 stars
[5 star78%](https:/www.g2.com/products/bright-data/reviews?filters%5Bnps_score%5D%5B%5D=5#reviews)
[4 star19%](https:/www.g2.cA saída inclui apenas as seções relevantes em vez de toda a página HTML. Essa abordagem reduz significativamente o uso de tokens, permitindo que você permaneça dentro dos limites de free-tier do Groq e, ao mesmo tempo, extraia efetivamente os dados de interesse!
Etapa 11: Definir a estratégia de extração de LLM com base no DeepSeek
O Craw4AI oferece suporte à extração de dados baseada em LLM por meio do objeto LLMExtractionStrategy. Você pode definir um para a integração do DeepSeek conforme abaixo:
extraction_strategy = LLMExtractionStrategy(
provider=os.getenv("LLM_MODEL"),
api_token=os.getenv("LLM_API_TOKEN"),
schema=G2Product.model_json_schema(),
extraction_type="schema",
instruction=(
"Extract the 'name', 'description', 'image_url', 'review_score', and 'number_of_reviews' "
"from the content below. "
"'review_score' must be in "x/5" format. Get the entire description, not just the first few sentences."
),
input_format="markdown",
verbose=True
)Para especificar o modelo LLM, adicione a seguinte variável de ambiente ao .env:
LLM_MODEL=groq/deepseek-r1-distill-llama-70bIsso diz ao Craw4AI para usar o modelo deepseek-r1-distill-llama-70b do GroqCloud para extração de dados baseada em LLM.
Em scraper.py, importe LLMExtractionStrategy e G2Product:
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from models.g2_product import G2ProductEm seguida, passe o objeto extraction_strategy para crawler_config:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000, # 3 mins
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]",
extraction_strategy=extraction_strategy
)Quando você executa o script, o Craw4AI:
- Conecte-se à página da Web de destino por meio do proxy da API do Web Unlocker.
- Recupera o conteúdo HTML da página e filtra os elementos usando os seletores CSS especificados.
- Converta os elementos HTML selecionados para o formato Markdown.
- Envie o Markdown formatado para o DeepSeek para extração de dados.
- Diga ao DeepSeek para processar a entrada de acordo com o prompt
(instrução) fornecido e retornar os dados extraídos.
Depois de executar o crawler.arun(), você pode verificar o uso do token com:
print(extraction_strategy.show_usage())Em seguida, você pode acessar e imprimir os dados extraídos com:
result_raw_data = result.extracted_content
print(result_raw_data)Se você executar o script e imprimir os resultados, deverá ver uma saída como esta:
=== Token Usage Summary ===
Type Count
------------------------------
Completion 525
Prompt 2,002
Total 2,527
=== Usage History ===
Request # Completion Prompt Total
------------------------------------------------
1 525 2,002 2,527
None
[
{
"name": "Bright Data",
"image_url": "https://images.g2crowd.com/uploads/product/image/large_detail/large_detail_9d7645872b9abb68923fb7e2c07c9d834/bright-data.png",
"description": "Bright Data is the world's #1 web data, proxies, & data scraping solutions platform. Fortune 500 companies, academic institutions and small businesses all rely on Bright Data's products, network and solutions to retrieve crucial public web data in the most efficient, reliable and flexible manner, so they can research, monitor, analyze data and make better informed decisions. Bright Data is used worldwide by 20,000+ customers in nearly every industry. Its products range from no-code data solutions utilized by business owners, to a robust proxy and scraping infrastructure used by developers and IT professionals. Bright Data products stand out because they provide a cost-effective way to perform fast and stable public web data collection at scale, effortless conversion of unstructured data into structured data and superior customer experience, while being fully transparent and compliant.",
"review_score": "4.7/5",
"number_of_reviews": "221",
"claimed": true
}
]A primeira parte da saída (uso de token) vem de show_usage(), confirmando que estamos bem abaixo do limite de 6.000 tokens. Os dados resultantes a seguir são uma string JSON que corresponde ao esquema G2Product.
Simplesmente incrível!
Etapa 12: Manipular os dados do resultado
Como você pode ver na saída da etapa anterior, o DeepSeek normalmente retorna uma matriz em vez de um único objeto. Para lidar com isso, analise os dados retornados como JSON e extraia o primeiro elemento da matriz:
# Parse the extracted data from JSON
result_data = json.loads(result.extracted_content)
# If the returned data is an array, access its first element
if result_data:
result_data = result_data[0]Lembre-se de importar json da biblioteca padrão do Python:
import jsonNesse ponto, result_data deve ser uma instância de G2Product. A etapa final é exportar esses dados para um arquivo JSON.
Etapa 13: Exportar os dados extraídos para JSON
Use json para exportar result_data para um arquivo g2.json:
with open("g2.json", "w", encoding="utf-8") as f:
json.dump(result_data, f, indent=4)Missão concluída!
Etapa nº 14: Juntar tudo
Seu arquivo scraper.py final deve conter:
import asyncio
from dotenv import load_dotenv
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
import os
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from models.g2_product import G2Product
import json
# Load secrets from .env file
load_dotenv()
async def main():
# Bright Data's Web Unlocker API proxy configuration
proxy_config = {
"server": os.getenv("PROXY_SERVER"),
"username": os.getenv("PROXY_USERNAME"),
"password": os.getenv("PROXY_PASSWORD")
}
# Browser configuration
browser_config = BrowserConfig(
headless=True,
proxy_config=proxy_config,
)
# LLM extraction strategy for data extraction using DeepSeek
extraction_strategy = LLMExtractionStrategy(
provider=os.getenv("LLM_MODEL"),
api_token=os.getenv("LLM_API_TOKEN"),
schema=G2Product.model_json_schema(),
extraction_type="schema",
instruction=(
"Extract the 'name', 'description', 'image_url', 'review_score', and 'number_of_reviews' "
"from the content below. "
"'review_score' must be in "x/5" format. Get the entire description, not just the first few sentences."
),
input_format="markdown",
verbose=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000, # 3 mins
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]",
extraction_strategy=extraction_strategy
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# Log the AI model usage info
print(extraction_strategy.show_usage())
# Parse the extracted data from JSON
result_data = json.loads(result.extracted_content)
# If the returned data is an array, access its first element
if result_data:
result_data = result_data[0]
# Export the scraped data to JSON
with open("g2.json", "w", encoding="utf-8") as f:
json.dump(result_data, f, indent=4)
if __name__ == "__main__":
asyncio.run(main())Em seguida, o models/g2_product.py armazenará:
from pydantic import BaseModel
class G2Product(BaseModel):
"""
Represents the data structure of a G2 product/company page.
"""
name: str
image_url: str
description: str
review_score: str
number_of_reviews: str
claimed: boolE .env terá:
PROXY_SERVER=https://<WEB_UNLOCKER_API_HOST>:<WEB_UNLOCKER_API_PORT>
PROXY_USERNAME=<WEB_UNLOCKER_API_USERNAME>
PROXY_PASSWORD=<WEB_UNLOCKER_API_PASSWORD>
LLM_API_TOKEN=<GROQ_API_KEY>
LLM_MODEL=groq/deepseek-r1-distill-llama-70bInicie seu scraper DeepSeek Crawl4AI com:
python scraper.pyA saída no terminal será semelhante a esta:
[INIT].... → Crawl4AI 0.4.248
[FETCH]... ↓ https://www.g2.com/products/bright-data/reviews... | Status: True | Time: 56.13s
[SCRAPE].. ◆ Processed https://www.g2.com/products/bright-data/reviews... | Time: 397ms
[LOG] Call LLM for https://www.g2.com/products/bright-data/reviews - block index: 0
[LOG] Extracted 1 blocks from URL: https://www.g2.com/products/bright-data/reviews block index: 0
[EXTRACT]. ■ Completed for https://www.g2.com/products/bright-data/reviews... | Time: 12.273853100006818s
[COMPLETE] ● https://www.g2.com/products/bright-data/reviews... | Status: True | Total: 68.81s
=== Token Usage Summary ===
Type Count
------------------------------
Completion 524
Prompt 2,002
Total 2,526
=== Usage History ===
Request # Completion Prompt Total
------------------------------------------------
1 524 2,002 2,526
NoneAlém disso, um arquivo g2.json aparecerá na pasta do seu projeto. Abra-o e você verá:
{
"name": "Bright Data",
"image_url": "https://images.g2crowd.com/uploads/product/image/large_detail/large_detail_9d7645872b9abb68923fb7e2c7c9d834/bright-data.png",
"description": "Bright Data is the world's #1 web data, proxies, & data scraping solutions platform. Fortune 500 companies, academic institutions and small businesses all rely on Bright Data's products, network and solutions to retrieve crucial public web data in the most efficient, reliable and flexible manner, so they can research, monitor, analyze data and make better informed decisions. Bright Data is used worldwide by 20,000+ customers in nearly every industry. Its products range from no-code data solutions utilized by business owners, to a robust proxy and scraping infrastructure used by developers and IT professionals. Bright Data products stand out because they provide a cost-effective way to perform fast and stable public web data collection at scale, effortless conversion of unstructured data into structured data and superior customer experience, while being fully transparent and compliant.",
"review_score": "4.7/5",
"number_of_reviews": "221",
"claimed": true
}Parabéns! Você começou com uma página G2 protegida por bots e usou o Crawl4AI, o DeepSeek e a API Web Unlocker para extrair dados estruturados dela, sem escrever uma única linha de lógica de análise.
Conclusão
Neste tutorial, você explorou o que é o Crawl4AI e como usá-lo em combinação com o DeepSeek para criar um scraper com tecnologia de IA. Um dos maiores desafios ao fazer scraping é o risco de ser bloqueado, mas isso foi superado com a API Web Unlocker da Bright Data.
Conforme demonstrado neste tutorial, com a combinação de Crawl4AI, DeepSeek e a API Web Unlocker, você pode extrair dados de qualquer site – mesmo aqueles que são mais protegidos, como o G2 – sem a necessidade de lógica de análise específica. Esse é apenas um dos muitos cenários suportados pelos produtos e serviços da Bright Data, que o ajudam a implementar uma raspagem da Web eficaz orientada por IA.
Explore nossas outras ferramentas de raspagem da Web que se integram ao Crawl4AI:
- Serviços de proxy: 4 tipos diferentes de proxies para contornar restrições de localização, incluindo mais de 400M+ monthly de IPs residenciais
- APIs do Web Scraper: Pontos de extremidade dedicados para extrair dados da Web novos e estruturados de mais de 100 domínios populares.
- API SERP: API para lidar com todo o gerenciamento de desbloqueio contínuo para SERP e extrair uma página
- Navegador de raspagem: Navegador compatível com Puppeteer, Selenium e Playwright com atividades de desbloqueio integradas
Inscreva-se agora na Bright Data e teste nossos serviços de proxy e produtos de raspagem gratuitamente!




