

Scraping de dados é uma técnica que você pode usar para extrair dados de páginas da web. É especialmente útil quando o site de destino não oferece uma API, a API não pode ser usada ou não retorna os dados exatos que você deseja.
Regex, abreviação de “expressão regular”, é um poderoso padrão gramatical para extrair dados de textos e é comumente usado para Scraping de dados. Regex define um padrão que pode ser correspondido em textos e é comumente usado para encontrar e extrair informações de textos. Como tal, é amplamente utilizado no Scraping de dados.
Neste artigo, você aprenderá como usar regex emPython para Scraping de dados. Ao final do artigo, você saberá como fazer Scraping de dados em sites estáticos e dinâmicos e terá uma compreensão de algumas das limitações que poderá enfrentar.
O que é Regex
Uma expressão regular é definida usando tokens que correspondem a um padrão específico. Descrever todos os tokens em detalhes está fora do escopo deste artigo, mas a tabela a seguir lista alguns tokens comumente usados que você provavelmente encontrará:
| Token | Correspondências |
|---|---|
| Qualquer caractere não especial | O caractere fornecido |
^ |
Início de uma string |
$ |
Fim de uma string |
. |
Qualquer caractere exceto n |
* |
Zero ou mais ocorrências do elemento anterior |
? |
Zero ou uma ocorrência do elemento anterior |
+ |
Uma ou mais ocorrências dos caracteres anteriores |
{Dígito} |
Número exato do elemento anterior |
d |
Qualquer dígito |
s |
Qualquer caractere de espaço em branco |
w |
Qualquer caractere de palavra |
D |
Inverso de d |
S |
Inverso de s |
W |
Inverso de w |
Para saber mais sobre regex e obter alguma experiência prática, visiteregexr.com. Além disso,este artigocompartilha algumas dicas importantes para otimizar o desempenho do regex.
Usando expressões regulares em Python para Scraping de dados
Neste tutorial, você criará um Scraper web simples em Python usando regex para extrair dados de páginas da web.
Para começar, crie um diretório para o seu projeto:
mkdir web_scraping_with_regex
cd web_scraping_with_regex
Em seguida, crie um ambiente virtual Python:
python -m venv venv
E ative-o:
source ./venv/bin/activate
Para escrever o Scraper, você precisa instalar duas bibliotecas:
requestspara buscar páginas da webbeautifulsoup4para parsing do conteúdo HTML e localização de elementos
Execute o seguinte comando para instalar as bibliotecas:
pip install beautifulsoup4 requests
Observação: antes de fazer o scraping de qualquer site, certifique-se de verificar os termos e condições para ver se você tem permissão para fazer isso. Você não deve fazer o scraping de um site se isso for proibido.
Raspando um site de comércio eletrônico
Nesta seção, você criará um Scraper da web para fazer o scraping de umsite de comércio eletrônico simples efictício. Você fará o scraping da primeira página e extrairá os títulos e preços dos livros.
Para fazer isso, crie um arquivo chamado scraper.py e importe os módulos necessários:
import requests
from bs4 import BeautifulSoup
import re
Observação: o módulo
reé um módulo Python integrado que funciona com regex.
Em seguida, você precisa fazer uma solicitação GET à página da web de destino para obter o conteúdo HTML da página:
page = requests.get('https://books.toscrape.com/')
Passe esses dados para o Beautiful Soup, que realiza o Parsing da estrutura HTML da página da web:
soup = BeautifulSoup(page.content, 'html.parser')
Para descobrir como os elementos estão estruturados em HTML, use a ferramentaInspecionar Elemento. Abra apágina da webno navegador e pressioneCtrl + Shift + Ipara abrir oInspetor. Como você pode ver na captura de tela, os produtos são armazenados em elementoslicom classecol-xs-6 col-sm-4 col-md-3 col-lg-3. O título do livro pode ser encontrado em elementosa, lendo seu atributotitle, e os preços são armazenados em elementospcom classeprice_color:
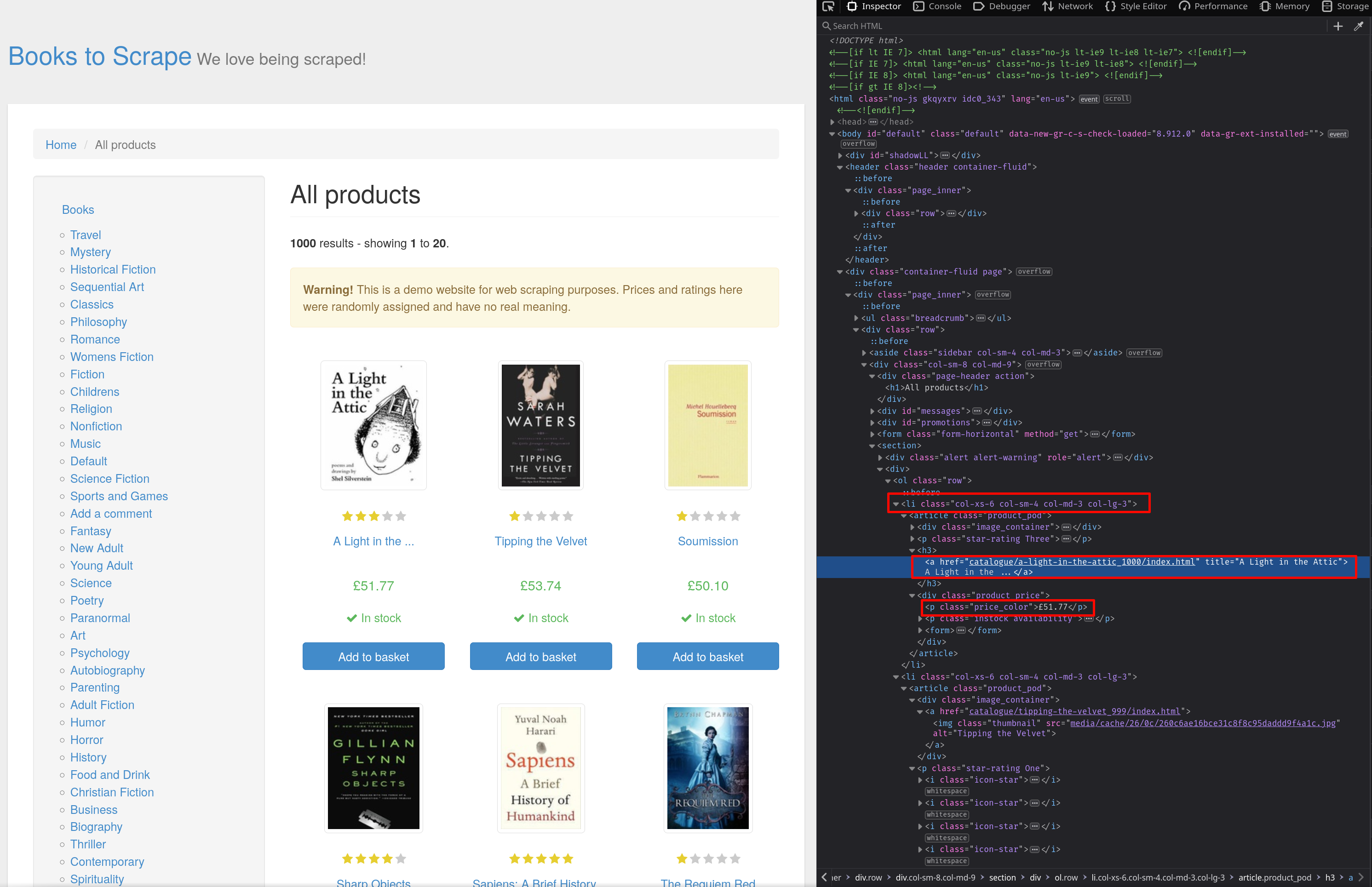
Use o método find_all do Beautiful Soup para encontrar todos os elementos li com classe col-xs-6 col-sm-4 col-md-3 col-lg-3:
livros = soup.find_all("li", class_="col-xs-6 col-sm-4 col-md-3 col-lg-3")
conteúdo = str(livros)
A variável content agora contém o texto HTML dos elementos li, e você pode usar regex para extrair os títulos e preços.
O primeiro passo é construir uma expressão regular que corresponda aos títulos e preços do texto. Para isso, você precisa usar o Inspect Element novamente.
Observe que os títulos dos livros estão armazenados no atributo title dos elementos a, e os elementos a têm a seguinte aparência:
<a href="..." title="...">
Para corresponder ao conteúdo das aspas duplas após o título, use a expressão regular clássica .*?. O . corresponde a um único caractere, o * corresponde a zero ou mais ocorrências do elemento precedente (neste caso, qualquer coisa correspondente a .), e o ? corresponde a zero ou uma ocorrência do elemento precedente (neste caso, qualquer coisa correspondente a .*). Juntos, eles são usados para corresponder ao conteúdo das aspas duplas nesta expressão completa:
<a href=".*?" title="(.*?)"
Os parênteses ao redor do.*?são usados para criar umgrupo de captura. Os grupos de captura memorizam as informações sobre a correspondência do padrão e, em expressões complicadas, são usados para identificar e referir-se a padrões já correspondidos. No entanto, neste caso, o grupo de captura é usado para extrair o texto correspondido. Sem o grupo de captura, o texto ainda corresponderia, mas você não conseguiria acessar o texto correspondido.
Para extrair o preço, use a mesma expressão regular (.*?). Os preços são armazenados em elementos p com a classe price_color, portanto, a expressão regular completa é <p class="price_color">(.*?)</p>.
Defina os dois padrões:
re_book_title = r'<a href=".*?" title="(.*?)"'
re_prices = r'<p class="price_color">(.*?)</p>'
Observação:caso você esteja se perguntando por que o
?é necessário após.*,esta resposta do Stack Overflowexplica bem a função do?.
Agora você pode usar re.findall() para encontrar todas as correspondências regex da string HTML:
titles = re.findall(re_book_title, content)
prices = re.findall(re_prices, content)
Por fim, itere sobre as correspondências e imprima os resultados:
for i in zip(titles, prices):
print(f"{i[0]}: {i[1]}")
Você pode executar este código com python scraper.py. A saída fica assim:
A Light in the Attic: £51,77
Tipping the Velvet: £53,74
Soumission: £50,10
Sharp Objects: £47,82
Sapiens: A Brief History of Humankind: £54,23
The Requiem Red: £22,65
The Dirty Little Secrets of Getting Your Dream Job: £33,34
The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull: £ 17,93
The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics: £ 22,60
The Black Maria: £ 52,15
Starving Hearts (Triangular Trade Trilogy, #1): £ 13,99
Sonetos de Shakespeare: £ 20,66
Liberte-me: £ 17,46
A Preciosa Vida de Scott Pilgrim (Scott Pilgrim #1): £ 52,29
Rasgue tudo e recomece: £ 35,02
Nossa banda pode ser sua vida: cenas do underground indie americano, 1981-1991: £ 57,25
Olio: £ 23,88
Mesaerion: As melhores histórias de ficção científica 1800-1849: £ 37,59
Libertarianismo para iniciantes: £ 51,33
É apenas o Himalaia: £ 45,17
Raspando uma página da Wikipedia
Agora, vamos criar um Scraper que possa raspar umapágina da Wikipediae extrair informações sobre todos os links.
Crie um novo arquivo chamado wiki_scraper.py. Assim como antes, comece importando as bibliotecas, fazendo uma solicitação GET e realizando o Parsing do conteúdo:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get('https://en.wikipedia.org/wiki/Web_scraping')
soup = BeautifulSoup(page.content, 'html.parser')
Para encontrar todos os links, use o método find_all():
links = soup.find_all("a")
content = str(links)
Os textos dos links são armazenados no atributo title, e os URLs dos links são armazenados no atributo href. Você pode usar a mesma expressão regular (.*?) para extrair as informações. A expressão completa fica assim:
<a href="(.*?)" title="(.*?)">.*?</a>
Observe que o terceiro .*? não está em um grupo de captura porque você não está interessado no conteúdo das tags a.
Como antes, use findall() para encontrar todas as correspondências e imprimir o resultado:
re_links = r'<a href="(.*?)" title="(.*?)">.*?</a>'
links = re.findall(re_links, content)
for i in links:
print(f"{i[0]} => {i[1]}")
Ao executar isso com python wiki_scraper.py, você obtém a seguinte saída:
SAÍDA TRUNCADA POR MOTIVOS DE CONCISÃO
/wiki/Category:Scraping de dados => Categoria:Scraping de dados
/wiki/Category:CS1_maint:_multiple_names:_authors_list => Categoria:CS1 maint: nomes múltiplos: lista de autores
/wiki/Category:CS1_Danish-language_sources_(da) => Categoria:CS1 Fontes em língua dinamarquesa (da)
/wiki/Category:CS1_French-language_sources_(fr) => Categoria:CS1 fontes em francês (fr)
/wiki/Categoria:Artigos_com_breve_descrição => Categoria:Artigos com breve descrição
/wiki/Categoria:Breve_descrição_corresponde_ao_Wikidata => Categoria:Breve descrição corresponde ao Wikidata
/wiki/Categoria:Artigos_que_precisam_de_referências_adicionais_a_partir_de_abril_de_2023 => Categoria:Artigos que precisam de referências adicionais a partir de abril de 2023
/wiki/Categoria:Todos os artigos que precisam de referências adicionais => Categoria:Todos os artigos que precisam de referências adicionais
/wiki/Categoria:Artigos com escopo geográfico limitado a partir de outubro de 2015 => Categoria:Artigos com escopo geográfico limitado a partir de outubro de 2015
/wiki/Categoria:Centrado nos Estados Unidos => Categoria:Centrado nos Estados Unidos
/wiki/Categoria:Todos os artigos com afirmações sem fontes => Categoria:Todos os artigos com afirmações sem fontes
/wiki/Categoria:Artigos com afirmações sem fontes de abril de 2023 => Categoria:Artigos com afirmações sem fontes de abril de 2023
Raspagem de um site dinâmico
Até agora, todas as páginas da web que você raspou eram estáticas. Raspar páginas da web dinâmicas é um pouco mais difícil, pois requer uma ferramenta de automação de navegador comoo Selenium. A seguir está um exemplo de raspagem da página inicialdo OpenWeatherMappara Londres e uso de regex e Selenium para raspar a temperatura atual:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
driver = webdriver.Firefox()
driver.get("https://openweathermap.org/city/2643743")
elem = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CSS_SELECTOR, ".current-temp")))
content = elem.get_attribute('innerHTML')
re_temp = r'<span .*?>(.*?)</span>'
temp = re.findall(re_temp, content)
print(repr(temp))
driver.close()
Este código usa o Selenium para iniciar uma instância do Firefox e usa o seletor CSS para selecionar o elemento com a temperatura atual. Em seguida, usa a expressão regular <span .*?>(.*?)</span> para extrair a temperatura.
Se você estiver procurando por mais informações para ajudá-lo a começar a fazer scraping de dados de páginas da web dinâmicas com o Selenium, confiraeste tutorial.
Limitação da expressão regular para Scraping de dados
Expressões regulares são ferramentas poderosas para correspondência de padrões e extração de informações de textos. Os desenvolvedores geralmente aprendem regex e tentam usá-la para Scraping de dados. No entanto, regex por si só não é adequada para Scraping de dados. Regex funciona em texto e não tem conceito ou compreensão das estruturas HTML. Isso significa que os resultados são altamente dependentes da maneira como o código HTML é escrito. Por exemplo, no exemplo da Wikipedia, você deve ter notado que alguns links não foram extraídos corretamente:

Se você editar o código Python e adicionar print(content) para imprimir a string HTML retornada pelo Beautiful Soup, verá que o culpado se parece com isto:
<a href="#cite_ref-9">^</a>
Aqui, o atributo title está faltando, mas na regex, você assumiu a estrutura <a href="(.*?)" title="(.*?)">.*?</a>. Como a expressão regular não tem noção dos elementos HTML, em vez de gerar um erro ou interromper a correspondência, o padrão .*? continuou a corresponder caracteres cegamente até conseguir corresponder " title="(.*?)">.*?</a> para concluir o padrão. Isso acabou engolindo as próximas tags a e mostra que o uso de expressões regulares pode causar efeitos indesejados se o código HTML for escrito de maneira inesperada.
Além disso, HTML não é uma linguagem regular, o que significa que regex sozinho não pode ser usado para analisar dados HTML arbitrários. Estaresposta do Stack Overflowé um clássico cult entre os desenvolvedores por criticar os desenvolvedores que tentam analisar HTML com regex. No entanto, existem algumas situações em que você pode usar regex para analisar e extrair dados HTML.
Por exemplo, se você tiver um conjunto conhecido e limitado de código HTML e estiver totalmente ciente de como o código está estruturado, poderá usar regex. Por exemplo, se você sabe que todas as tags a no HTML têm os atributos href e title e estão em conformidade com um padrão fixo, pode usar regex para extrair informações. No entanto, uma solução melhor e mais robusta é usar um analisador HTML como o Beautiful Soup para encontrar elementos e extrair dados textuais deles.
Depois de extrair os dados textuais, você pode usar regex para processá-los ainda mais. Por exemplo, aqui está uma versão modificada do Scraper da Wikipedia que usa o Beautiful Soup para extrair os atributos href e title e, em seguida, usa regex para filtrar todas as tags que contêm caracteres não alfanuméricos:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get('https://en.wikipedia.org/wiki/Web_scraping')
soup = BeautifulSoup(page.content, 'html.parser')
links = soup.find_all("a")
for link in links:
href = link.get('href')
title = link.get('title')
if title == None:
title = link.string
if title == None:
continue
pattern = r"[a-zA-Z0-9]"
if re.match(pattern, title):
print(f"{href} => {title}")
Conclusão
A expressão regular é uma ferramenta poderosa para encontrar padrões em dados textuais. Graças à sua robustez, ela é frequentemente usada no Scraping de dados para extrair informações.
Neste artigo, você aprendeu o que é regex e como usá-la com o Beautiful Soup para fazer Scraping de dados em sites de comércio eletrônico, na Wikipedia e em páginas dinâmicas da web. Você também aprendeu sobre algumas das limitações do regex e como usá-lo da melhor maneira em conjunto com outra ferramenta.
Mesmo que você faça uso total do regex, o Scraping de dados é cheio de desafios. O Scraping de dados repetido pode fazer com que o endereço IP do seu Scraper seja bloqueado. Você também pode enfrentar CAPTCHAs que podem impedir que seu Scraper funcione corretamente. A Bright Dataoferece proxies poderosos que podem contornar proibições de IP. Sua rede mundial de proxies envolveproxies de data center,proxies residenciais,proxies ISP eproxies móveis. Com oWeb Unlocker, você pode contornar a detecção de bots e resolver CAPTCHAs sem complicações. Comece um teste grátis hoje mesmo!






