

Neste guia, você aprenderá:
- Por que o Gemini é uma ótima solução para a coleta de dados da Web com tecnologia de IA
- Como usá-lo para extrair dados de um site em Python por meio de um tutorial guiado
- A maior limitação dessa forma de raspagem da Web e como superá-la
Vamos mergulhar de cabeça!
Por que usar o Gemini para Web Scraping?
O Gemini é uma família de modelos de IA multimodal desenvolvida pelo Google que pode analisar e interpretar textos, imagens, áudio, vídeos e códigos. O uso do Gemini para raspagem da Web simplifica a extração de dados, automatizando a interpretação e a estruturação de conteúdo não estruturado. Isso elimina a necessidade de esforço manual, especialmente quando se trata de análise de dados.
Em detalhes, esses são alguns dos casos de uso mais comuns do Gemini em raspagem da Web:
- Páginas que mudam de estrutura com frequência: O Gemini pode lidar com páginas dinâmicas em que o layout ou os elementos de dados mudam com frequência, como em sites de comércio eletrônico como a Amazon.
- Páginas com muitos dados não estruturados: Ele se destaca na extração de informações úteis de grandes volumes de texto não organizado.
- Páginas em que é difícil escrever uma lógica de análise personalizada: Para páginas com estruturas complexas ou imprevisíveis, o Gemini pode automatizar o processo sem exigir regras de análise complexas.
Os cenários de uso comum do Gemini em raspagem da Web incluem:
- RAG (Retrieval-Augmented Generation): Combinação de raspagem de dados em tempo real para aprimorar os insights de IA. Para obter um exemplo completo usando uma tecnologia de IA semelhante, siga nosso tutorial sobre como criar um chatbot RAG usando dados SERP.
- Raspagem de mídia social: Coleta de dados estruturados de plataformas com conteúdo dinâmico.
- Agregação de conteúdo: Reunir notícias, artigos ou postagens de blog de várias fontes para criar resumos ou análises.
Para obter mais informações, consulte nosso guia sobre o uso de IA para raspagem da Web.
Web Scraping com Gemini em Python: Guia passo a passo
Como site de destino desta seção, usaremos uma página de produto específica do sandbox “Ecommerce Test Site to Learn Web Scraping“:
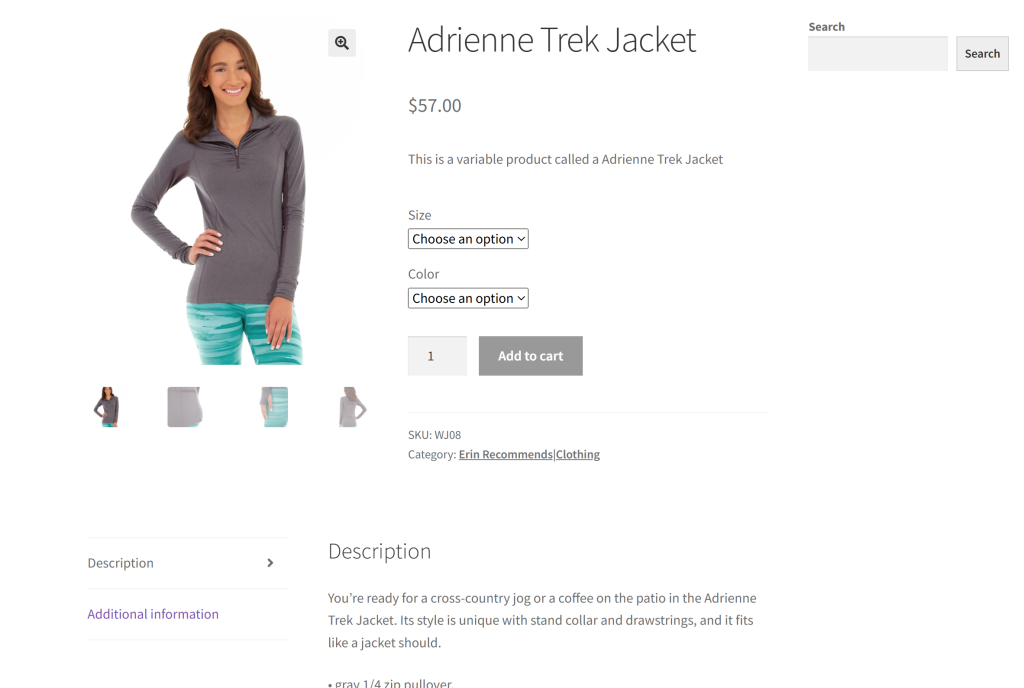
Esse é um ótimo exemplo porque a maioria das páginas de produtos de comércio eletrônico exibe diferentes tipos de dados ou tem estruturas variadas. Isso é o que torna a raspagem da Web de comércio eletrônico tão desafiadora e onde a IA pode ajudar.
O objetivo do nosso raspador com tecnologia Gemini é aproveitar a IA para extrair detalhes do produto da página sem escrever uma lógica de análise manual. Os dados do produto recuperados por meio de IA incluirão:
- SKU
- Nome
- Imagens
- Preço
- Descrição
- Tamanhos
- Cores
- Categoria
Siga as etapas abaixo para saber como realizar a coleta de dados da Web com o Gemini!
Etapa 1: Configuração do projeto
Antes de começar, verifique se você tem o Python 3 instalado em seu computador. Caso contrário, faça o download e siga o assistente de instalação.
Agora, execute o seguinte comando para criar uma pasta para seu projeto de raspagem:
mkdir gemini-scrapergemini-scraper representa a pasta do projeto do seu coletor de dados da Web baseado em Python Gemini.
Navegue até ele no terminal e inicialize um ambiente virtual dentro dele:
cd gemini-scraper
python -m venv venvCarregue a pasta do projeto em seu IDE Python favorito. O Visual Studio Code com a extensão Python ou o PyCharm Community Edition são duas ótimas opções.
Crie um arquivo scraper.py na pasta do projeto, que agora deve conter essa estrutura de arquivo:

Atualmente, o scraper.py é um script Python em branco, mas em breve conterá a lógica de raspagem LLM desejada.
No terminal do IDE, ative o ambiente virtual. No Linux ou macOS, execute este comando:
./venv/bin/activateDe forma equivalente, no Windows, execute:
venv/Scripts/activateMaravilhoso! Agora você tem um ambiente Python para coleta de dados da Web com o Gemini.
Etapa 2: Configurar o Gemini
O Gemini fornece uma API que você pode chamar usando qualquer cliente HTTP, inclusive solicitações. Ainda assim, é melhor se conectar por meio do Google AI Python SDK oficial para a API do Gemini. Para instalá-lo, execute o seguinte comando no ambiente virtual ativado:
pip install google-generativeaiEm seguida, importe-o em seu arquivo scraper.py:
import google.generativeai as genaiPara que o SDK funcione, você precisa de uma chave de API Gemini. Se você ainda não recuperou sua chave de API
siga a documentação oficial do Google. Especificamente, faça login na sua conta do Google e entre no Google AI Studio. Navegue até a página“Get API Key” e você verá o seguinte modal:
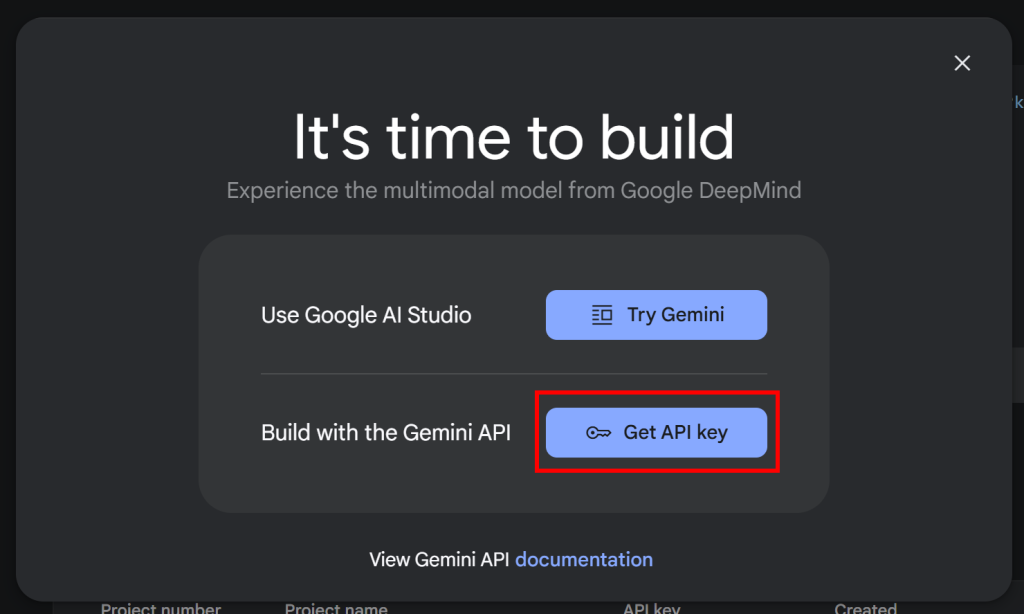
Clique no botão “Get API key” (Obter chave de API), e a seção a seguir será exibida:
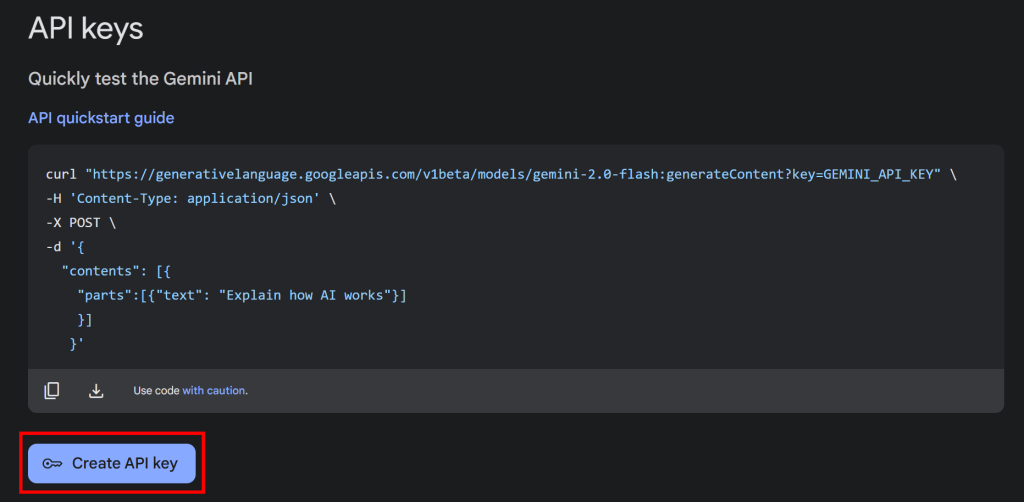
Agora, pressione “Create API key” (Criar chave de API) para gerar sua chave de API do Gemini:
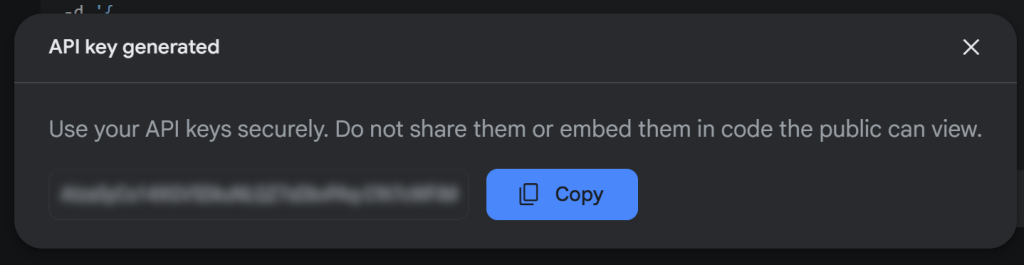
Copie a chave e guarde-a em um local seguro.
Observação: a camada gratuita do Gemini é suficiente para este exemplo. A camada paga só é necessária se você precisar de limites de taxa mais altos ou quiser garantir que seus avisos e respostas não sejam usados para melhorar os produtos do Google. Para obter mais detalhes, consulte a página de faturamento do Gemini.
Para usar a chave da API do Gemini no Python, você pode defini-la como uma variável de ambiente:
export GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>Ou, como alternativa, armazene-o diretamente em seu script Python como uma constante:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"E passe-o para o genai como uma configuração, da seguinte forma:
genai.configure(api_key=GEMINI_API_KEY)Nesse caso, seguiremos a segunda abordagem. No entanto, lembre-se de que ambos os métodos funcionam, pois o google-generativeai tenta ler automaticamente a chave de API de GEMINI_API_KEY se você não a passar manualmente.
Incrível! Agora você pode usar o Gemini SDK para fazer solicitações de API para o LLM em Python.
Etapa 3: obtenha o HTML da página de destino
Para conectar-se ao servidor de destino e recuperar o HTML de suas páginas da Web, usaremos o Requests, o cliente HTTP mais popular em Python. Em um ambiente virtual ativado, instale-o com:
pip install requestsEm seguida, importe-o no scraper.py:
import requestsUse-o para enviar uma solicitação GET à página de destino e recuperar seu documento HTML:
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)response.content agora conterá o HTML bruto da página. É hora de analisá-lo e se preparar para extrair dados dele!
Etapa 4: converter o HTML em Markdown
Se você comparar outras tecnologias de raspagem de IA, como o Crawl4AI, perceberá que elas permitem que você use seletores CSS para direcionar elementos HTML. Em seguida, essas bibliotecas convertem o HTML dos elementos selecionados em texto Markdown. Por fim, elas processam esse texto com um LLM.
Já se perguntou por quê? Bem, há dois motivos principais para esse comportamento:
- Reduzir o número de tokens enviados para a IA, ajudando você a economizar dinheiro (já que nem todos os provedores de LLM são gratuitos como a Gemini).
- Tornar o processamento de IA mais rápido, pois menos dados de entrada significam custos computacionais mais baixos e respostas mais rápidas.
Para obter um passo a passo completo, consulte nosso guia sobre raspagem da Web usando o CrawlAI e o DeepSeek.
Vamos tentar replicar essa lógica e ver se ela realmente faz sentido. Comece inspecionando a página de destino, abrindo-a em uma janela anônima (para abrir uma nova sessão). Em seguida, clique com o botão direito do mouse em qualquer lugar da página e selecione a opção “Inspecionar”.
Examine a estrutura da página. Você verá que todos os dados relevantes estão contidos no elemento HTML identificado pelo seletor CSS #main:
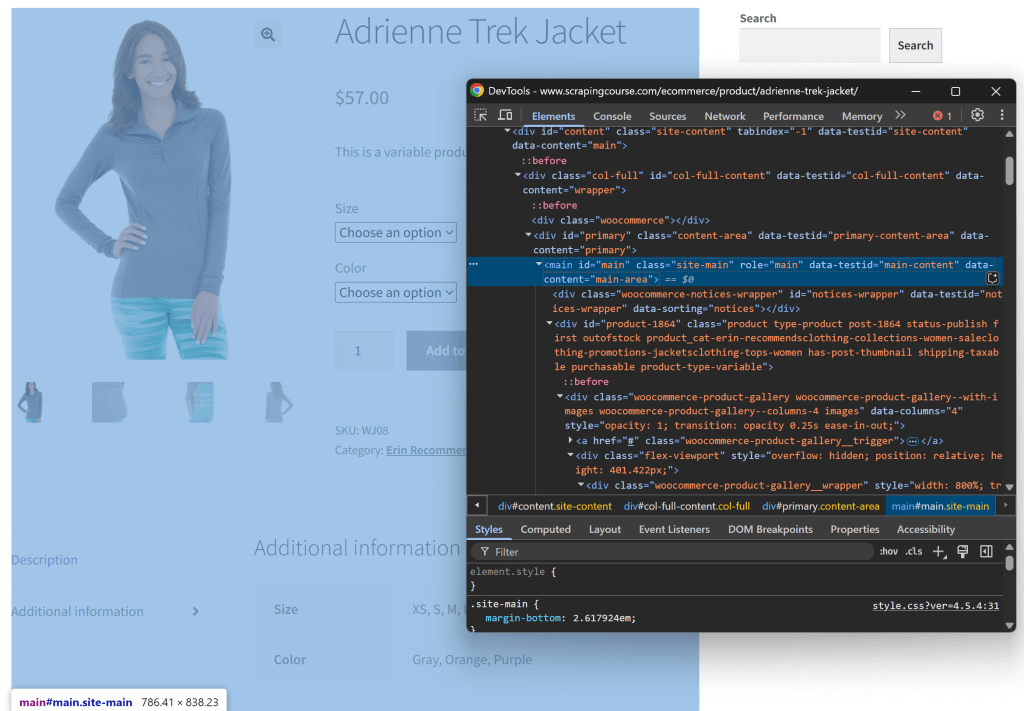
Você poderia enviar todo o HTML bruto para o Gemini, mas isso introduziria muitas informações desnecessárias (como cabeçalhos e rodapés). Em vez disso, ao passar apenas o conteúdo #main, você reduz o ruído e evita alucinações da IA.
Para selecionar apenas #main, você precisa de uma ferramenta de análise de HTML do Python, como a Beautiful Soup. Portanto, instale-a com:
pip install beautifulsoup4Se você não estiver familiarizado com sua sintaxe, consulte nosso guia sobre raspagem da Web da Beautiful Soup.
Agora, importe-o no scraper.py:
from bs4 import BeautifulSoupUse o Beautiful Soup para analisar o HTML bruto recuperado via Requests, selecionar o elemento #main e extrair seu HTML:
# Parse the HTML with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Extract the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)Se você imprimir main_html, verá algo parecido com isto:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- omitted for brevity... -->
</main>Agora, verifique quantos tokens esse HTML geraria e estime o custo se você estivesse usando a camada paga da Gemini. Para fazer isso, use uma ferramenta como a Token Calculator:
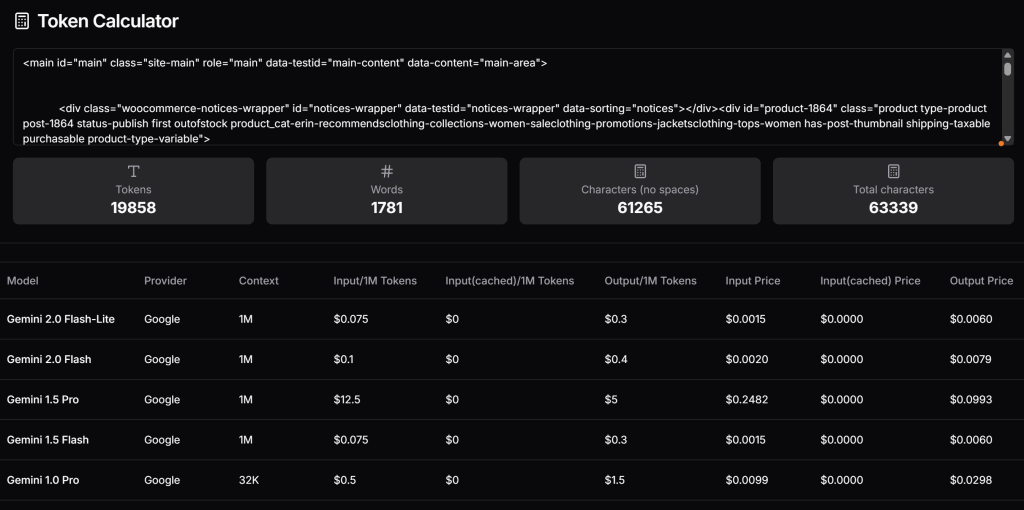
Como você pode ver, essa abordagem equivale a quase 20.000 tokens, custando cerca de US$ 0,25 por solicitação para o Gemini 1.5 Pro. Em um projeto de raspagem em grande escala, isso pode facilmente se tornar um problema!
Tente converter o HTML extraído em Markdown – semelhante ao que o Crawl4AI faz. Primeiro, instale uma biblioteca HTML para Markdown, como a markdownify:
pip install markdownifyImportar markdownify em scraper.py:
from markdownify import markdownifyEm seguida, use o markdownify para converter o HTML extraído em Markdown:
main_markdown = markdownify(main_html)A string main_markdown resultante contém algo parecido com isto:
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back.jpg)
Adrienne Trek Jacket
====================
$57.00
This is a variable product called a Adrienne Trek Jacket
| | |
| --- | --- |
| Size | Choose an optionXSSMLXL |
| Color | Choose an optionGrayOrangePurple[Clear](#) |
Adrienne Trek Jacket quantity
Add to cart
SKU: WJ08
Category: [Erin Recommends|Clothing](https://www.scrapingcourse.com/ecommerce/product-category/clothing/women/tops-women/jacketsclothing-tops-women/promotions-jacketsclothing-tops-women/women-saleclothing-promotions-jacketsclothing-tops-women/collections-women-saleclothing-promotions-jacketsclothing-tops-women/erin-recommendsclothing-collections-women-saleclothing-promotions-jacketsclothing-tops-women/)
* [Description](#tab-description)
* [Additional information](#tab-additional_information)
Description
-----------
You’re ready for a cross-country jog or a coffee on the patio in the Adrienne Trek Jacket. Its style is unique with stand collar and drawstrings, and it fits like a jacket should.
* gray 1/4 zip pullover.
* Comfortable, relaxed fit.
* Front zip for venting.
* Spacious, kangaroo pockets.
* 27″ body length.
* 95% Organic Cotton / 5% Spandex.
Additional information
----------------------
| | |
| --- | --- |
| Size | XS, S, M, L, XL |
| Color | Gray, Orange, Purple |Essa versão Markdown dos dados de entrada é muito menor do que o HTML #principal original e, ao mesmo tempo, contém todos os principais dados necessários para a raspagem.
Use a Token Calculator novamente para verificar quantos tokens a nova entrada consumiria:
Uau, reduzimos 19.858 tokens para 765 tokens – uma redução de 95%!
Etapa 5: usar o LLM para extrair dados
Para realizar a coleta de dados da Web com o Gemini, siga estas etapas:
- Escreva um prompt bem estruturado para extrair os dados desejados da entrada Markdown. Certifique-se de definir os atributos que você deseja que o resultado tenha.
- Envie uma solicitação a um modelo Gemini LLM usando
o genai, configurando-o para que a solicitação retorne dados formatados em JSON. - Analisar o JSON retornado.
Implemente a lógica acima com estas linhas de código:
# Extract structured data using Gemini
prompt = f"""Extract data from the content below. Respond with a raw string in JSON format containing the scraped data in the specified attributes:nn
JSON ATTRIBUTES: n
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# Get the response and parse it from JSON
product_raw_string = response.text
product_data = json.loads(product_raw_string)A variável prompt instrui o Gemini a extrair dados estruturados do conteúdo main_markdown. Em seguida, genai.GenerativeModel() define o modelo "gemini-2.0-flash-lite" para executar a solicitação LLM. Por fim, a string de resposta bruta no formato JSON é convertida em um dicionário Python utilizável com json.loads().
Observe a configuração "application/json" para dizer ao Gemini para retornar dados JSON.
Não se esqueça de importar json da biblioteca padrão do Python:
import jsonAgora que você tem os dados extraídos em um dicionário product_data, pode acessar seus campos para processamento adicional de dados, como no exemplo abaixo:
price = product_data["price"]
price_eur = price * USD_EUR
# ...Fantástico! Você acabou de utilizar o Gemini para coleta de dados da Web. Só falta exportar os dados extraídos.
Etapa nº 6: Exportar os dados extraídos
Atualmente, você tem os dados extraídos armazenados em um dicionário Python. Para exportá-los para um arquivo JSON, use o seguinte código:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Isso criará um arquivo product.json contendo os dados extraídos no formato JSON.
Parabéns! O coletor de dados da Web com tecnologia Gemini está concluído.
Etapa nº 7: Juntar tudo
Abaixo está o código completo de seu script de raspagem Gemini:
import google.generativeai as genai
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
# Your Gemini API key
GEMINI_API_KEY = "<YOUR_GEMINI_API_KEY>"
# Set up the Google Gemini API
genai.configure(api_key=GEMINI_API_KEY)
# Fetch the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)
# Parse the HTML of the target page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML and convert it to Markdown
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Extract structured data using Gemini
prompt = f"""Extract data from the content below. Respond with a raw string in JSON format containing the scraped data in the specified attributes:nn
JSON ATTRIBUTES: n
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# Get the response and parse it from JSON
product_raw_string = response.text
product_data = json.loads(product_raw_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Inicie o script com:
python scraper.pyUma vez executado, um arquivo product.json aparecerá na pasta do projeto. Abra-o e você verá dados estruturados como estes:
{
"sku": "WJ08",
"name": "Adrienne Trek Jacket",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back-416x516.jpg"
],
"price": "$57.00",
"description": "Youu2019re ready for a cross-country jog or a coffee on the patio in the Adrienne Trek Jacket. Its style is unique with stand collar and drawstrings, and it fits like a jacket should.nnu2022 gray 1/4 zip pullover. nu2022 Comfortable, relaxed fit. nu2022 Front zip for venting. nu2022 Spacious, kangaroo pockets. nu2022 27u2033 body length. nu2022 95% Organic Cotton / 5% Spandex.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Gray",
"Orange",
"Purple"
],
"category": "Erin Recommends|Clothing"
}E pronto! Você começou com dados não estruturados em uma página HTML e agora os tem em um arquivo JSON estruturado, graças à coleta de dados da Web com tecnologia Gemini.
Próximas etapas
Para levar seu raspador com motor Gemini para o próximo nível, considere estas melhorias:
- Torne-o reutilizável: Modifique o script para aceitar o prompt e o URL de destino como argumentos de linha de comando. Isso o tornará de uso geral e adaptável a diferentes cenários de uso.
- Implementar o rastreamento da Web: Amplie o coletor de dados para lidar com sites de várias páginas, adicionando lógica para rastreamento e paginação.
- Proteja as credenciais da API: Armazene sua chave de API Gemini em um arquivo
.enve usepython-dotenvpara carregá-la. Isso evita a exposição de sua chave de API no código.
Superando a principal limitação dessa abordagem de raspagem da Web
Qual é a maior limitação dessa abordagem de raspagem da Web? A solicitação HTTP feita pelas solicitações!
Claro, no exemplo acima, funcionou perfeitamente, mas isso se deve ao fato de o site alvo ser apenas um playground de raspagem da Web. Na realidade, as empresas e os proprietários de sites sabem o quanto seus dados são valiosos, mesmo quando estão acessíveis ao público. Para protegê-los, eles implementam medidas antirraspagem que podem bloquear facilmente suas solicitações HTTP automatizadas.
Além disso, a abordagem acima não funcionará em sites dinâmicos que dependem do JavaScript para renderização ou obtenção de dados de forma assíncrona. Portanto, os sites não precisam nem mesmo de estruturas antirrastreamento avançadas para impedir seu raspador. O uso de carregamento de conteúdo baseado em JavaScript é suficiente.
A solução para todos esses problemas? Uma API de desbloqueio da Web!
Uma API do Web Unlocker é um ponto de extremidade HTTP que você pode chamar de qualquer cliente HTTP. A principal diferença? Ela retorna o HTML totalmente desbloqueado de qualquer URL que você passar para ela, contornando qualquer bloqueio anti-scraping. Não importa quantas proteções um site-alvo tenha, uma simples solicitação ao Web Unlocker buscará o HTML da página para você.
Para começar a usar essa ferramenta e recuperar sua chave de API, siga a documentação oficial do Web Unlocker. Em seguida, substitua seu código de solicitação existente da “Etapa 3” por estas linhas:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)E assim, sem mais bloqueios, sem mais limitações! Agora você pode fazer scraping da Web usando o Gemini sem se preocupar em ser interrompido.
Conclusão
Nesta postagem do blog, você aprendeu a usar o Gemini em combinação com o Requests e outras ferramentas para criar um raspador alimentado por IA. Um dos principais desafios da raspagem da Web é o risco de ser bloqueado, mas isso foi resolvido usando a API Web Unlocker da Bright Data.
Conforme explicado aqui, ao combinar o Gemini e a API do Web Unlocker, você pode extrair dados de qualquer site sem precisar de lógica de análise personalizada. Esse é apenas um dos muitos cenários que os produtos e serviços da Bright Data suportam, ajudando você a implementar a raspagem da Web eficaz orientada por IA.
Explore nossas outras ferramentas de raspagem da Web:
- Serviços de proxy: Quatro tipos diferentes de proxies para contornar restrições de localização, incluindo mais de 150 milhões de IPs residenciais
- APIs do Web Scraper: Pontos de extremidade dedicados para extrair dados da Web novos e estruturados de mais de 100 domínios populares.
- API SERP: API para lidar com todo o gerenciamento de desbloqueio contínuo para SERP e extrair uma página
- Navegador de raspagem: Navegador compatível com Puppeteer, Selenium e Playwright com atividades de desbloqueio integradas
Inscreva-se agora na Bright Data e teste nossos serviços de proxy e produtos de raspagem gratuitamente!




