

A criação de uma solução confiável de extração de dados da Web começa com a infraestrutura correta. Neste guia, você criará um aplicativo de página única que aceita qualquer URL de página da Web pública e um prompt de linguagem natural. Em seguida, ele raspa, analisa e retorna um JSON limpo e estruturado, automatizando totalmente o processo de extração.
A pilha combina a infraestrutura de raspagem anti-bot da Bright Data, o back-end seguro do Supabase e as ferramentas de desenvolvimento rápido da Lovable em um fluxo de trabalho contínuo.
O que você construirá
Aqui está o pipeline de dados completo que você criará, desde a entrada do usuário até a saída e o armazenamento de JSON estruturado:
User Input
↓
Authentication
↓
Database Logging
↓
Edge Function
↓
Bright Data Web Unlocker (Bypasses anti-bot protection)
↓
Raw HTML
↓
Turndown (HTML → Markdown)
↓
Clean structured text
↓
Google Gemini AI (Natural language processing)
↓
Structured JSON
↓
Database Storage
↓
Frontend Display
↓
User ExportAqui está uma rápida olhada na aparência do aplicativo finalizado:
Autenticação de usuários: Os usuários podem se inscrever ou fazer login com segurança usando a tela de autenticação fornecida pelo Supabase.

Interface de extração de dados: Após o login, os usuários podem inserir o URL de uma página da Web e um prompt de linguagem natural para recuperar dados estruturados.
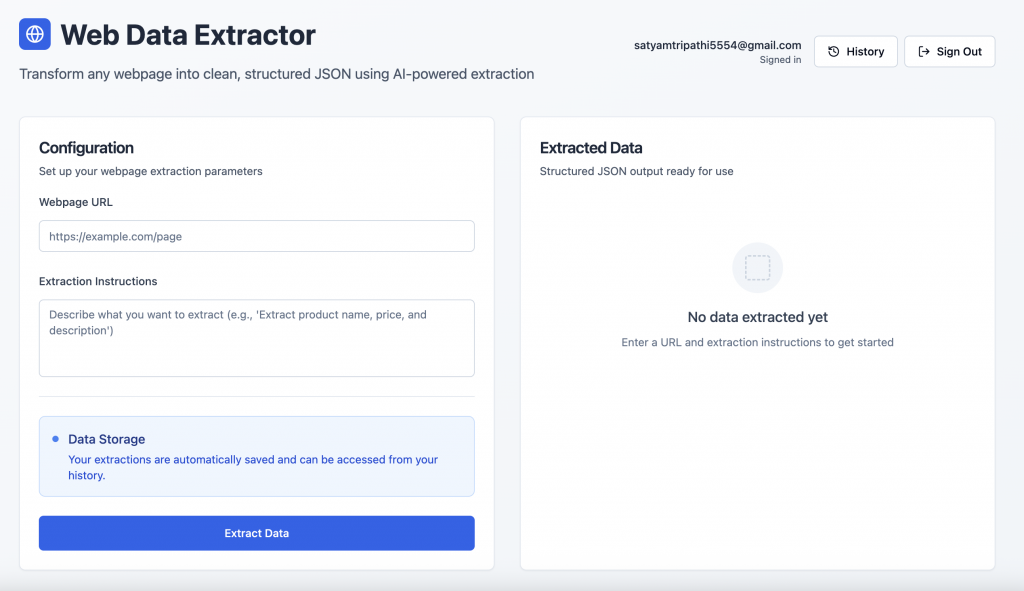
Visão geral da pilha de tecnologia
Veja a seguir um detalhamento de nossa pilha e a vantagem estratégica que cada componente oferece.
- Dados brilhantes: A raspagem da Web geralmente esbarra em bloqueios, CAPTCHAs e detecção avançada de bots. A Bright Data foi criada especificamente para lidar com esses desafios. Ele oferece:
- Rotação automática de proxy
- Solução de CAPTCHA e proteção contra bots
- Infraestrutura global para acesso consistente
- Renderização de JavaScript para conteúdo dinâmico
- Tratamento automatizado do limite de taxa
Para este guia, usaremos o Web Unlocker da Bright Data, uma ferramenta criada para fins específicos que obtém de forma confiável o HTML completo até mesmo das páginas mais protegidas.
- Supabase:O Supabase fornece uma base de back-end segura para aplicativos modernos, apresentando:
- Autenticação integrada e tratamento de sessão
- Um banco de dados PostgreSQL com suporte em tempo real
- Edge Functions para lógica sem servidor
- Armazenamento seguro de chaves e controle de acesso
- Lovable: O Lovable simplifica o desenvolvimento com ferramentas baseadas em IA e integração nativa com o Supabase. Ele oferece:
- Geração de código orientada por IA
- Andaimes de front-end/backend perfeitos
- React + Tailwind UI pronta para uso
- Prototipagem rápida para aplicativos prontos para produção
- Google Gemini AI:O Gemini transforma HTML bruto em JSON estruturado usando prompts de linguagem natural. Ele é compatível com:
- Compreensão e análise precisas do conteúdo
- Suporte a entradas grandes para contexto de página inteira
- Extração de dados escalonável e econômica
Pré-requisitos e configuração
Antes de iniciar o desenvolvimento, verifique se você tem acesso aos seguintes itens:
- Conta da Bright Data
- Registre-se em brightdata.com
- Criar uma zona do Web Unlocker
- Obtenha sua chave de API nas configurações da conta
- Conta do Google AI Studio
- Visite o Google AI Studio
- Criar uma nova chave de API
- Projeto Supabase
- Registre-se em supabase.com
- Crie uma nova organização e, em seguida, configure um novo projeto
- No painel de seu projeto, vá para Edge Functions → Secrets → Add New Secret. Adicione segredos como
BRIGHT_DATA_API_KEYeGEMINI_API_KEYcom seus respectivos valores
- Conta adorável
- Registre-se em lovable.dev
- Vá para seu perfil → Configurações → Integrações
- Em Supabase, clique em Connect Supabase (Conectar Supabase)
- Autorize o acesso à API e vincule-o à organização do Supabase que você acabou de criar
Criar o aplicativo passo a passo com os prompts do Lovable
Abaixo está um fluxo estruturado e baseado em prompts para desenvolver seu aplicativo de extração de dados da Web, do frontend ao backend, banco de dados e análise inteligente.
Etapa 1 – Configuração do front-end
Comece projetando uma interface de usuário limpa e intuitiva.
Build a modern web data extraction app using React and Tailwind CSS. The UI should include:
- A gradient background with card-style layout
- An input field for the webpage URL
- A textarea for the extraction prompt (e.g., "Extract product title, price, and ratings")
- A display area to render structured JSON output
- Responsive styling with hover effects and proper spacingEtapa 2 – Conectar o Supabase e adicionar autenticação
Para vincular seu projeto do Supabase:
- Clique no ícone do Supabase no canto superior direito do Lovable
- Selecione Connect Supabase
- Escolha a organização e o projeto que você criou anteriormente
O Lovable integrará seu projeto do Supabase automaticamente. Depois de vinculado, use o prompt abaixo para ativar a autenticação:
Set up complete Supabase authentication:
- Sign up and login forms using email/password
- Session management and auto-persistence
- Route protection for unauthenticated users
- Sign out functionality
- Create user profile on signup
- Handle all auth-related errorsA Lovable gerará o esquema SQL e os acionadores necessários – revise-os e aprove-os para finalizar seu fluxo de autenticação.
Etapa #3 – definir o esquema do banco de dados do Supabase
Configure as tabelas necessárias para registrar e armazenar a atividade de extração:
Create Supabase tables for storing extractions and results:
- extractions: stores URL, prompt, user_id, status, processing_time, error_message
- extraction_results: stores parsed JSON output
Apply RLS policies to ensure each user can only access their own dataEtapa #4 – criar a função Supabase Edge
Essa função lida com a lógica central de raspagem, conversão e extração:
Create an Edge Function called 'extract-web-data' that:
- Fetches the target page using Bright Data's Web Unlocker
- Converts raw HTML to Markdown using Turndown
- Sends the Markdown and prompt to Google Gemini AI (gemini-2.0-flash-001)
- Returns clean structured JSON
- Handles CORS, errors, and response formatting
- Requires GEMINI_API_KEY and BRIGHT_DATA_API_KEY as Edge Function secrets
Below is a reference implementation that handles HTML fetching using Bright Data, markdown conversion with Turndown, and AI-driven extraction with Gemini:
import { GoogleGenerativeAI } from '@google/generative-ai';
import TurndownService from 'turndown';
interface BrightDataConfig {
apiKey: string;
zone: string;
}
// Constants
const GEMINI_MODEL = 'gemini-2.0-flash-001';
const WEB_UNLOCKER_ZONE = 'YOUR_WEB_UNLOCKER_ZONE';
export class WebContentExtractor {
private geminiClient: GoogleGenerativeAI;
private modelName: string;
private htmlToMarkdownConverter: TurndownService;
private brightDataConfig: BrightDataConfig;
constructor() {
const geminiApiKey: string = 'GEMINI_API_KEY';
const brightDataApiKey: string = 'BRIGHT_DATA_API_KEY';
try {
this.geminiClient = new GoogleGenerativeAI(geminiApiKey);
this.modelName = GEMINI_MODEL;
this.htmlToMarkdownConverter = new TurndownService();
this.brightDataConfig = {
apiKey: brightDataApiKey,
zone: WEB_UNLOCKER_ZONE
};
} catch (error) {
console.error('Failed to initialize WebContentExtractor:', error);
throw error;
}
}
/**
* Fetches webpage content using Bright Data Web Unlocker service
*/
async fetchContentViaBrightData(targetUrl: string): Promise<string | null> {
try {
// Append Web Unlocker parameters to the target URL
const urlSeparator: string = targetUrl.includes('?') ? '&' : '?';
const requestUrl: string = `${targetUrl}${urlSeparator}product=unlocker&method=api`;
const apiResponse = await fetch('https://api.brightdata.com/request', {
method: 'POST',
headers: {
'Authorization': `Bearer ${this.brightDataConfig.apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
zone: this.brightDataConfig.zone,
url: requestUrl,
format: 'raw'
})
});
if (!apiResponse.ok) {
throw new Error(`Web Unlocker request failed with status: ${apiResponse.status}`);
}
const htmlContent: string = await apiResponse.text();
return htmlContent && htmlContent.length > 0 ? htmlContent : null;
} catch (error) {
console.error('Failed to fetch webpage content:', error);
return null;
}
}
/**
* Converts HTML to clean Markdown format for better AI processing
*/
async convertToMarkdown(htmlContent: string): Promise<string | null> {
try {
const markdownContent: string = this.htmlToMarkdownConverter.turndown(htmlContent);
return markdownContent;
} catch (error) {
console.error('Failed to convert HTML to Markdown:', error);
return null;
}
}
/**
* Uses Gemini AI to extract specific information from markdown content
* Uses low temperature for more consistent, factual responses
*/
async extractInformationWithAI(markdownContent: string, userQuery: string): Promise<string | null> {
try {
const aiPrompt: string = this.buildAIPrompt(userQuery, markdownContent);
const aiModel = this.geminiClient.getGenerativeModel({ model: this.modelName });
const aiResult = await aiModel.generateContent({
contents: [{ role: 'user', parts: [{ text: aiPrompt }] }],
generationConfig: {
maxOutputTokens: 2048,
temperature: 0.1,
}
});
const response = await aiResult.response;
return response.text();
} catch (error) {
console.error('Failed to extract information with AI:', error);
return null;
}
}
private buildAIPrompt(userQuery: string, markdownContent: string): string {
return `You are a data extraction assistant. Below is some content in markdown format extracted from a webpage.
Please analyze this content and extract the information requested by the user.
USER REQUEST: ${userQuery}
MARKDOWN CONTENT:
${markdownContent}
Please provide a clear, structured response based on the user's request. If the requested information is not available in the content, please indicate that clearly.`;
}
/**
* Main extraction workflow: fetches webpage → converts to markdown → extracts with AI
*/
async extractDataFromUrl(websiteUrl: string, extractionQuery: string): Promise<string | null> {
try {
const htmlContent: string | null = await this.fetchContentViaBrightData(websiteUrl);
if (!htmlContent) {
console.error('Could not retrieve HTML content from URL');
return null;
}
const markdownContent: string | null = await this.convertToMarkdown(htmlContent);
if (!markdownContent) {
console.error('Could not convert HTML to Markdown');
return null;
}
const extractedInformation: string | null = await this.extractInformationWithAI(markdownContent, extractionQuery);
return extractedInformation;
} catch (error) {
console.error('Error in extractDataFromUrl:', error);
return null;
}
}
}
/**
* Example usage of the WebContentExtractor
*/
async function runExtraction(): Promise<void> {
const TARGET_WEBSITE_URL: string = 'https://example.com';
const DATA_EXTRACTION_QUERY: string = 'Extract the product title, all available prices, ...';
try {
const contentExtractor = new WebContentExtractor();
const extractionResult: string | null = await contentExtractor.extractDataFromUrl(TARGET_WEBSITE_URL, DATA_EXTRACTION_QUERY);
if (extractionResult) {
console.log(extractionResult);
} else {
console.log('Failed to extract data from the specified URL');
}
} catch (error) {
console.error(`Application error: ${error}`);
}
}
// Execute the application
runExtraction().catch(console.error);A conversão de HTML bruto em Markdown antes de enviá-lo para a Gemini AI tem várias vantagens importantes. Ela remove ruídos desnecessários do HTML, melhora o desempenho da IA fornecendo entradas mais limpas e estruturadas e reduz o uso de tokens, levando a um processamento mais rápido e econômico.
Consideração importante: O Lovable é excelente para criar aplicativos a partir de linguagem natural, mas nem sempre sabe como integrar adequadamente ferramentas externas, como Bright Data ou Gemini. Para garantir uma implementação precisa, inclua um exemplo de código de trabalho em seus prompts. Por exemplo, o método fetchContentViaBrightData The no prompt acima demonstra um caso de uso simples do Web Unlocker da Bright Data.
A Bright Data oferece várias APIs, inclusive Web Unlocker, SERP API e Scraper APIs, cada uma com seu ponto de extremidade, método de autenticação e parâmetros. Quando você configura um produto ou zona no painel da Bright Data, a guia Overview (Visão geral ) fornece trechos de código específicos da linguagem (Node.js, Python, cURL) adaptados à sua configuração. Use esses trechos como estão ou adapte-os à lógica de sua Edge Function.
Etapa 5 – conectar o frontend ao Edge Function
Quando sua Edge Function estiver pronta, integre-a ao seu aplicativo React:
Connect the frontend to the Edge Function:
- On form submission, call the Edge Function
- Log the request in the database
- Update status (processing/completed/failed) after the response
- Show processing time, status icons, and toast notifications
- Display the extracted JSON with loading statesEtapa nº 6 – adicionar histórico de extração
Forneça aos usuários uma maneira de revisar solicitações anteriores:
Create a history view that:
- Lists all extractions for the logged-in user
- Displays URL, prompt, status, duration, and date
- Includes View and Delete options
- Expands rows to show extracted results
- Uses icons for statuses (completed,failed,processing)
- Handles long text/URLs gracefully with a responsive layoutEtapa #7 – Polimento da interface do usuário e aprimoramentos finais
Refine a experiência com toques úteis na interface do usuário:
Polish the interface:
- Add toggle between "New Extraction" and "History"
- Create a JsonDisplay component with syntax highlighting and copy button
- Fix responsiveness issues for long prompts and URLs
- Add loading spinners, empty states, and fallback messages
- Include feature cards or tips at the bottom of the pageConclusão
Essa integração reúne o melhor da automação moderna da Web: fluxos de usuários seguros com o Supabase, raspagem confiável por meio do Bright Data e análise flexível e alimentada por IA com o Gemini, tudo isso por meio do construtor intuitivo e baseado em bate-papo do Lovable para um fluxo de trabalho de código zero e alta produtividade.
Pronto para criar seu próprio sistema? Comece a usar o site brightdata.com e explore as soluções de coleta de dados da Bright Data para obter acesso escalonável a qualquer site, sem nenhuma dor de cabeça com a infraestrutura.





