

Neste guia, você aprenderá:
- O que é o Pipedream e por que usá-lo.
- O motivo pelo qual você deve integrá-lo a um plug-in de raspagem incorporado.
- Benefícios da integração do Pipedream com a arquitetura de raspagem da Bright Data.
- Um tutorial passo a passo para criar um fluxo de trabalho de raspagem da Web com o Pipedream.
Vamos nos aprofundar no assunto!
Visão geral do Pipedream: Automatize e integre com facilidade
O Pipedream é uma plataforma para criar e executar fluxos de trabalho que conectam vários aplicativos e provedores de terceiros. Em detalhes, ele oferece funcionalidades sem código e com pouco código. Graças a esses recursos, você pode automatizar processos e integrar sistemas por meio de componentes pré-criados ou código personalizado.
Veja a seguir um detalhamento de seus principais recursos:
- Criador de fluxo de trabalho visual: Defina fluxos de trabalho usando uma interface visual, conectando componentes pré-criados para aplicativos populares. Atualmente, ele oferece integrações para mais de 2700 aplicativos.
- Sem código/baixo código: Não requer conhecimento técnico. Ainda assim, para necessidades complexas, os aplicativos da Pipedream podem incorporar nós de código personalizados. As linguagens de programação compatíveis são Node.js, Python, Go e Bash.
- Arquitetura orientada por eventos: Os fluxos de trabalho são acionados por eventos como HTTP/webhooks, horário programado, e-mails recebidos, entre outros. Assim, o fluxo de trabalho permanece inativo e não consome recursos até que ocorra um evento de acionamento específico.
- Execução sem servidor: A funcionalidade principal do Pipedream gira em torno de seu tempo de execução sem servidor. Isso significa que você não precisa provisionar ou gerenciar servidores. O Pipedream executa fluxos de trabalho em um ambiente escalável e sob demanda.
- Fluxos de trabalho de criação de IA: Deal with String, uma IA dedicada a escrever agentes personalizados que exigem apenas a inserção de prompts. Você também pode usá-la se não tiver uma familiaridade especial com o Pipedream. Você pode escrever um prompt e deixar que a IA crie um fluxo de trabalho para você.
Por que não codificar? Os benefícios de uma integração de raspagem pronta para uso
O Pipedream oferece suporte a ações de código. Elas permitem que você escreva scripts completos do zero em sua linguagem preferida (entre as suportadas). Tecnicamente, isso significa que você poderia criar um bot de raspagem inteiramente dentro do Pipedream usando esses nós.
Por outro lado, fazer isso não simplifica necessariamente o processo de criação de um fluxo de trabalho de raspagem. Você ainda enfrentará os desafios e os obstáculos habituais relacionados às proteções antirraspagem.
Portanto, é mais prático, eficaz e rápido contar com um plug-in de raspagem integrado que lide com essas complexidades para você. Essa é exatamente a experiência proporcionada pela integração do Bright Data no Pipedream.
Abaixo está uma lista dos motivos mais importantes para confiar no plug-in de raspagem pronto para uso da Bright Data:
- Autenticação fácil: O Pipedream armazena com segurança sua chave da API da Bright Data (necessária para autenticação) e oferece facilidade de uso. Você não precisa escrever nenhum código personalizado para autenticação e tem a certeza de não expor sua chave.
- Superação de sistemas anti-bot: Nos bastidores, as APIs da Bright Data lidam com todos os desafios de raspagem da Web, desde a rotação de proxy e gerenciamento de IP até a solução de CAPTCHAs e análise de dados. Dessa forma, garante que seu fluxo de trabalho do Pipedream receba dados da Web consistentes e de alta qualidade.
- Dados estruturados: Após a raspagem, você obtém dados estruturados e organizados sem escrever nenhuma linha de código. O plug-in cuida da estruturação dos dados para você.
Principais vantagens de combinar o Pipedream com o Bright Data Plugin
Ao conectar os recursos de automação do Pipedream com a Bright Data, você pode:
- Acesse dados novos: O objetivo da raspagem da Web é recuperar dados da Web, e a Bright Data o ajuda com isso. Ainda assim, os dados mudam com o tempo. Portanto, se você não quiser que suas análises fiquem desatualizadas, precisará continuar extraindo dados novos. É nesse ponto que o poder do Pipedream é útil (por exemplo, por meio de acionadores de agendamento).
- Integre a IA em seus fluxos de trabalho de raspagem: O Pipedream se integra a vários LLMs, como o ChatGPT e o Gemini. Isso permite que você automatize várias tarefas que exigiriam horas de trabalho manual. Por exemplo, você pode criar um fluxo de trabalho RAG para monitorar uma lista de produtos da concorrência em um site de comércio eletrônico.
- Simplifique os aspectos técnicos: Os sites empregam técnicas sofisticadas de bloqueio antirrastreamento que são atualizadas quase toda semana. A integração da Bright Data contorna os bloqueios para você, pois cuida de todas as soluções anti-bot.
É hora de ver a integração do Bright Data em ação em um fluxo de trabalho de raspagem do Pipedream!
Crie um fluxo de trabalho de raspagem alimentado por IA com o Pipedream e a Bright Data: Tutorial passo a passo
Nesta seção guiada, você aprenderá a criar um fluxo de trabalho do Pipedream que usa o Bright Data para recuperar dados de um produto da Amazon. Em particular, a página de destino será:
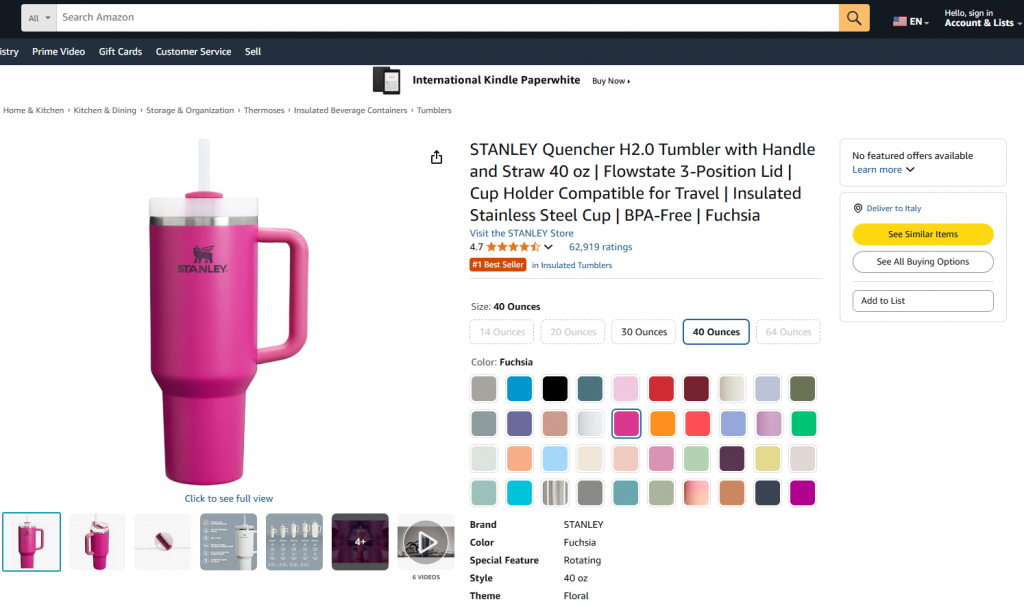
O objetivo é mostrar a você como criar um fluxo de trabalho do Pipedream que faça o seguinte:
- Recupera os dados da página da Web de destino usando a integração do Bright Data.
- Ingere os dados em um LLM.
- Solicita que o LLM analise os dados e crie um resumo do produto a partir deles.
Siga as etapas abaixo para saber como criar, testar e implementar esse fluxo de trabalho no Pipedream.
Requisitos
Para reproduzir este tutorial, você precisa:
- Uma conta do Pipedream (uma conta gratuita é suficiente).
- Uma chave de API da Bright Data.
- Uma chave de API da OpenAI.
Se você ainda não os tiver, use os links acima e siga as instruções para configurar tudo.
Também é útil ter esse conhecimento para seguir o tutorial:
- Familiaridade com a infraestrutura e os produtos da Bright Data (especialmente a API do Web Scraper).
- Conhecimento básico de processamento de IA (por exemplo, LLMs).
- Conhecimento de como funcionam os acionadores e as chamadas de API por meio de webhooks.
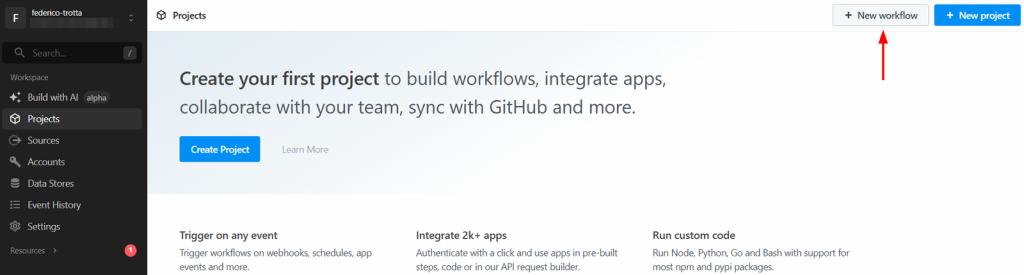
Etapa 1: criar um novo fluxo de trabalho do Pipedream
Faça login na sua conta do Pipedream e vá para o painel de controle. Em seguida, crie um novo fluxo de trabalho clicando no botão “Novo fluxo de trabalho”:
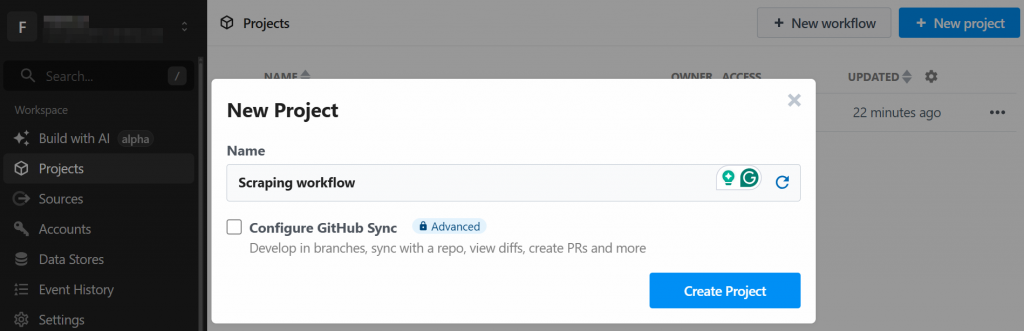
O sistema solicitará que você crie um novo projeto. Dê um nome a ele e clique no botão “Create Project” quando terminar:
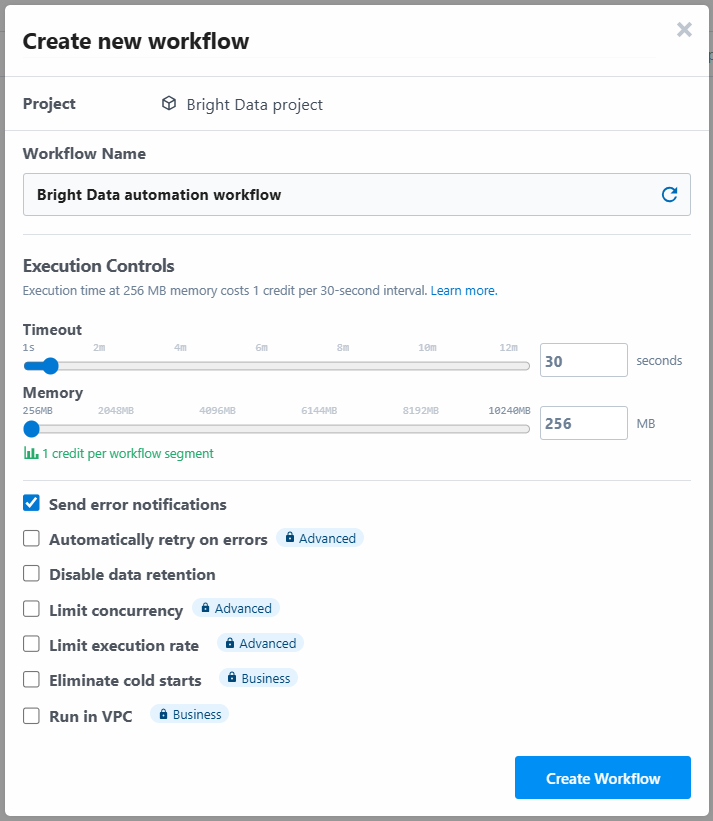
A ferramenta solicitará que você atribua um nome ao fluxo de trabalho e defina suas configurações. Você pode deixar as configurações como estão e pressionar o botão “Create Workflow” no final:
Veja abaixo como aparece a interface do usuário de seu novo fluxo de trabalho:
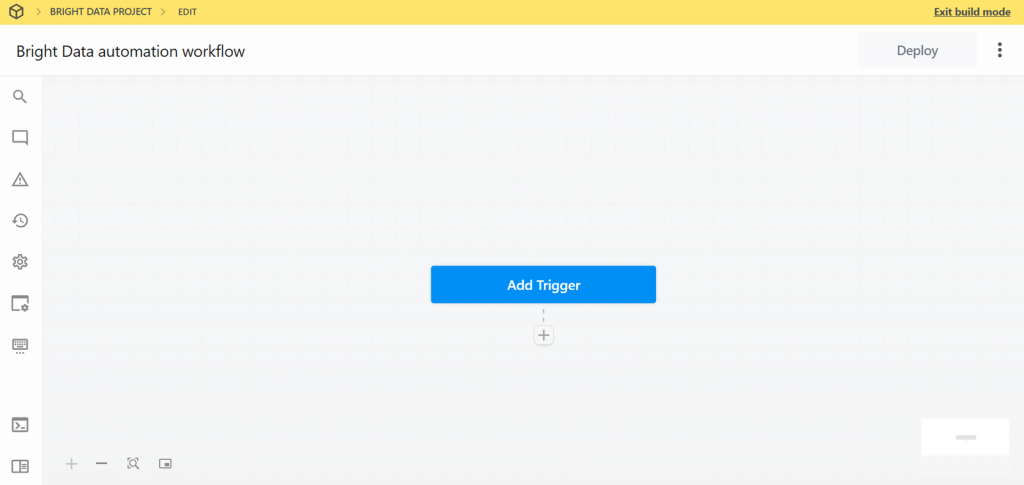
Muito bem! Você criou um novo fluxo de trabalho no Pipedream. Agora você está pronto para adicionar integrações de plugins a ele.
Etapa 2: Adicionar um acionador
No Pipedream, todo fluxo de trabalho começa com um acionador. Ao clicar em “Adicionar gatilho”, você verá os gatilhos que pode escolher:
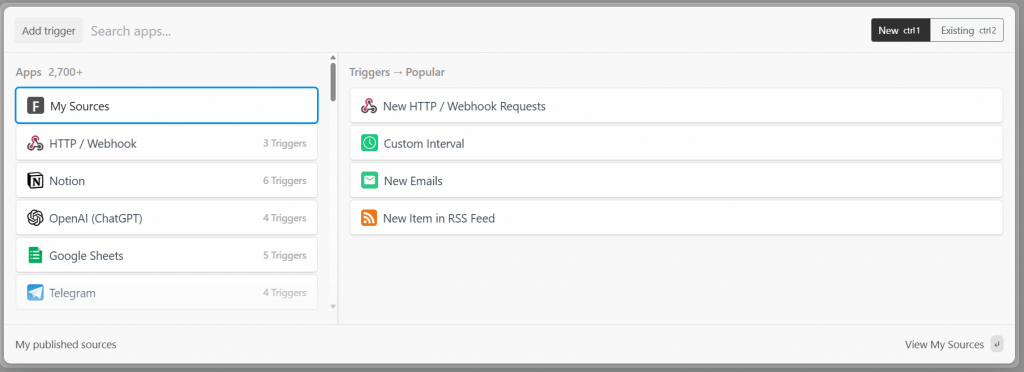
Nesse caso, selecione o acionador “New HTTP/Webhook Requests” (Novas solicitações HTTP/Webhook), que é necessário para se conectar à Bright Data. Deixe os dados do espaço reservado como estão e clique no botão “Save and continue” (Salvar e continuar):
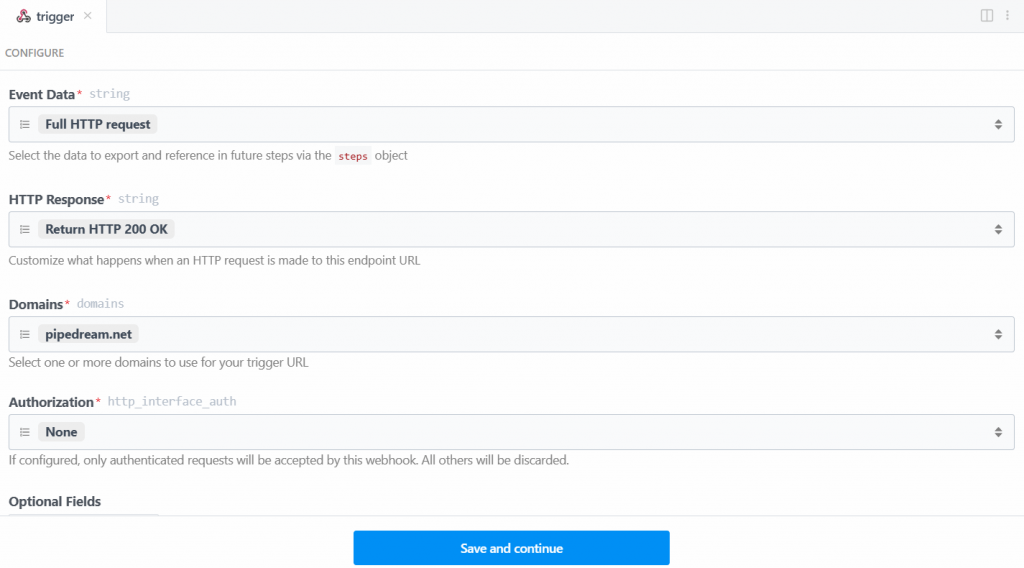
Para que o acionador funcione, você precisa gerar um evento. Portanto, clique em “Generate Test Event” (Gerar evento de teste):
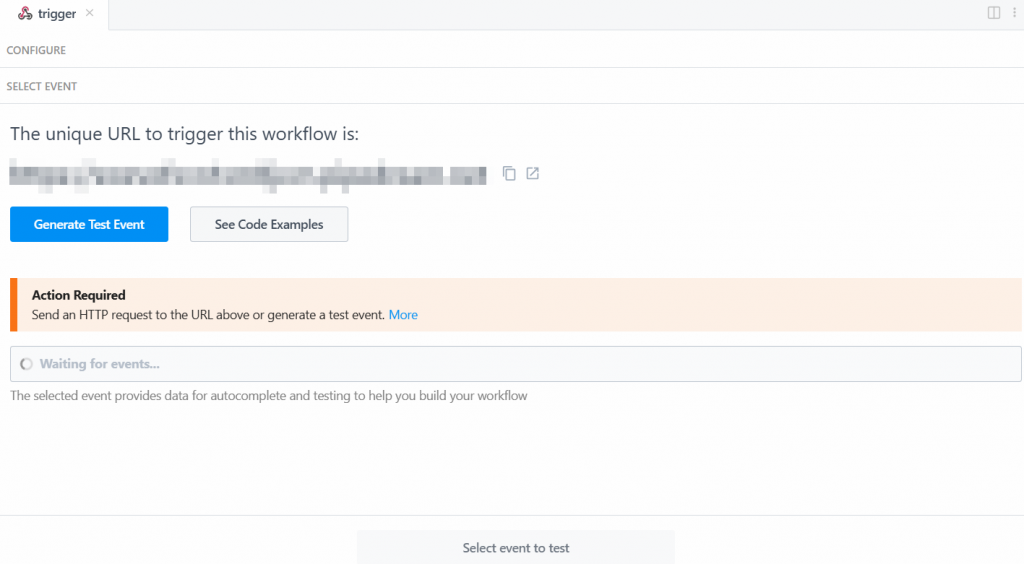
O sistema fornece a você um valor predefinido de um evento de teste da seguinte forma:
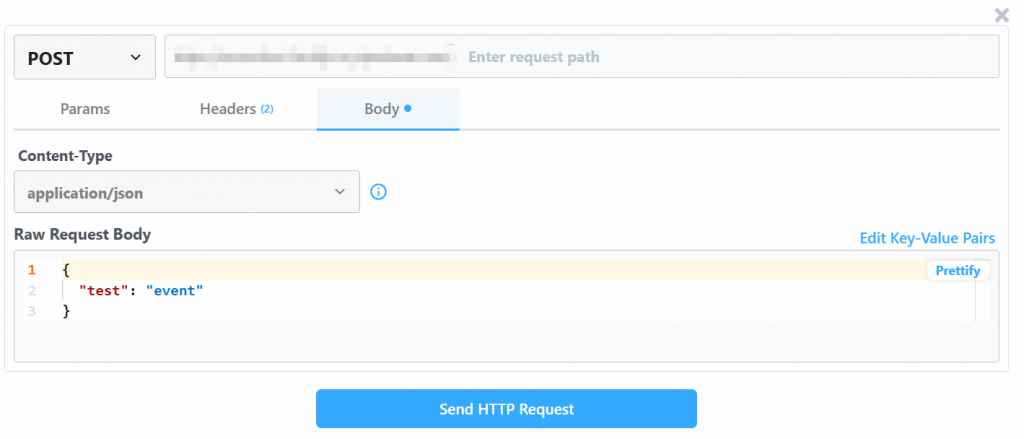
Altere o valor “Raw Request Body” com:
{
"url": "https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8",
"zipcode": "94107",
"language": ""
}O motivo é que o acionador gerado pelo Pipedream iniciará a chamada para a API do Amazon Scraper da Bright Data. O ponto de extremidade (que será configurado posteriormente) exige dados de entrada nesse formato específico de carga útil. Você pode verificar isso verificando a seção “API Request Builder” do raspador “Collect by URL” no Aamzon Web Scrapers da Bright Data:
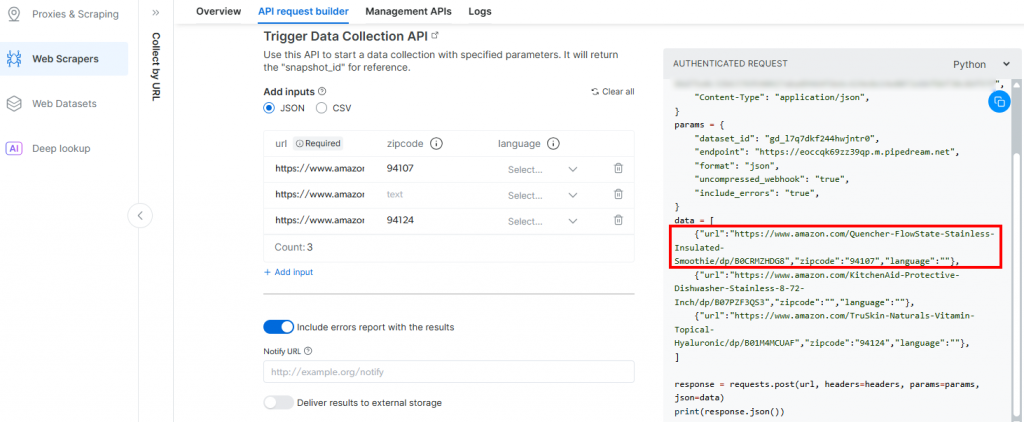
De volta à janela do Pipedream, quando terminar, clique no botão “Send HTTP Request” (Enviar solicitação HTTP). Se tudo ocorrer como esperado, você verá uma mensagem de sucesso na seção de resultados. O acionador também ficará verde:
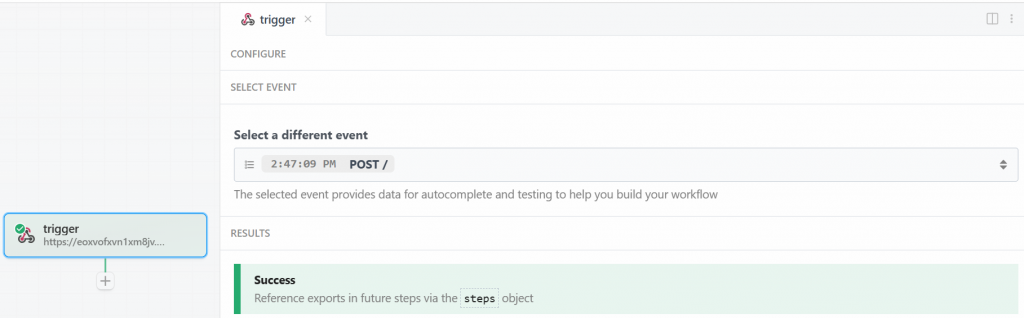
Perfeito! O acionador para iniciar a integração do Bright Data no fluxo de trabalho de raspagem do Pipedream foi configurado corretamente. Agora você está pronto para adicionar uma ação.
Etapa nº 3: adicionar a etapa de ação de dados brilhantes
Após o acionador, você pode adicionar uma etapa de ação no fluxo de trabalho do Pipedream. O que você quer agora é conectar a etapa de dados brilhantes ao acionador. Para isso, clique no “+” abaixo do acionador e procure por “bright data”:
O Pipedream fornece a você várias ações do plug-in Bright Data. Selecione-o para ver todas elas:
As opções que você tem são:
- Crie qualquer solicitação de API da Bright Data: Crie solicitações autenticadas para as APIs da Bright Data.
- Use qualquer API da Bright Data em Node.js/Python: Conecte sua conta da Bright Data ao Pipedream e personalize as solicitações no Node.js/Python.
- Use a IA para gerar uma ação personalizada da Bright Data: Peça à IA para gerar um código personalizado para a Bright Data.
Para este tutorial, selecione a opção “Use any Bright Data API in Python”. Isso é o que você verá:
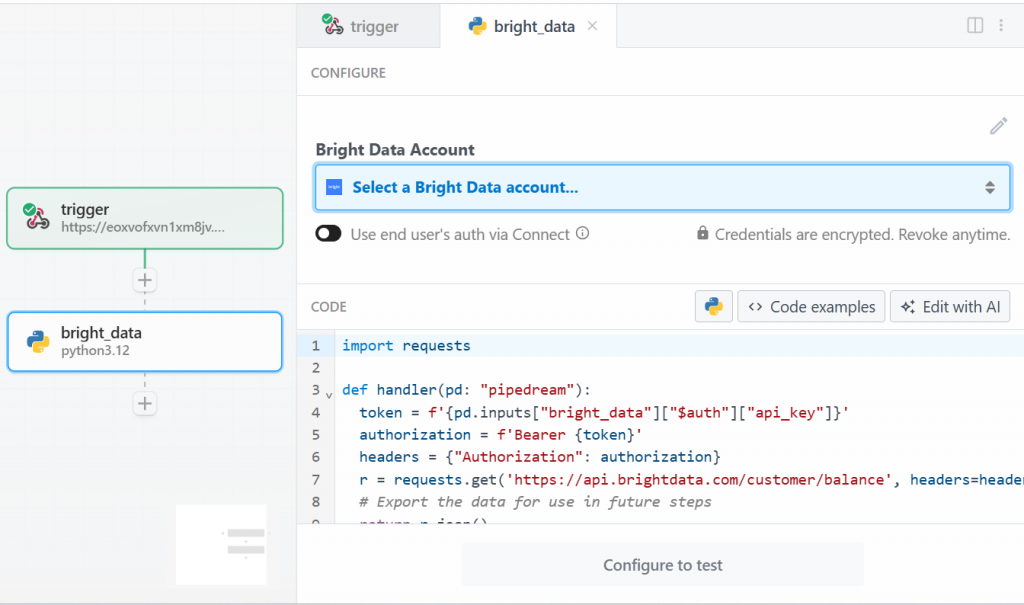
Primeiro, clique em “Select a Bright Data account” (Selecionar uma conta da Bright Data) em “Bright Data Account” (Conta da Bright Data) e adicione sua chave de API da Bright Data. Se você ainda não tiver feito isso, siga o guia oficial para configurar uma chave de API da Bright Data.
Em seguida, exclua o código na seção “CODE” e escreva o seguinte:
import requests
import json
import time
def handler(pd: "pipedream"):
# Retrieve the Bright Data API key from Pipedream's authenticated accounts
api_key = pd.inputs["bright_data"]["$auth"]["api_key"]
# Get the target Amazon product URL from the trigger data
amazon_product_url = pd.steps["trigger"]["event"]["body"]["url"]
# Configure the Bright Data API request
brightdata_api_endpoint = "https://api.brightdata.com/datasets/v3/trigger"
params = { "dataset_id": "gd_l7q7dkf244hwjntr0", "include_errors": "true" }
payload_data = [{"url": amazon_product_url}]
headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" }
# Initiate the data collection job
print(f"Triggering Bright Data dataset with URL: {amazon_product_url}")
trigger_response = requests.post(brightdata_api_endpoint, headers=headers, params=params, json=payload_data)
# Check if the trigger request was successful
if trigger_response.status_code == 200:
response_json = trigger_response.json()
# Extract the snapshot ID, which is needed to poll for results.
snapshot_id = response_json.get("snapshot_id")
# Handle cases where the trigger is successful but no snapshot ID is provided
if not snapshot_id:
print("Trigger successful, but no snapshot_id was returned.")
return {"error": "Trigger successful, but no snapshot_id was returned.", "response": response_json}
# Begin polling for the completed snapshot using its ID
print(f"Successfully triggered. Snapshot ID is {snapshot_id}. Now starting to poll for results.")
final_scraped_data = poll_and_retrieve_snapshot(api_key, snapshot_id)
# Return the final scraped data from the workflow
return final_scraped_data
else:
# If the trigger failed, log the error and exit the Pipedream workflow
print(f"Failed to trigger. Error: {trigger_response.status_code} - {trigger_response.text}")
pd.flow.exit(f"Error: Failed to trigger Bright Data scrape. Status: {trigger_response.status_code}")
def poll_and_retrieve_snapshot(api_key, snapshot_id, polling_timeout=20):
# Construct the URL for the specific snapshot
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
# Set the authorization header for the API request
headers = { "Authorization": f"Bearer {api_key}" }
print(f"Polling snapshot for ID: {snapshot_id}...")
# Loop until the snapshot is ready
while True:
response = requests.get(snapshot_url, headers=headers)
# If status is 200, the data is ready
if response.status_code == 200:
print("Snapshot is ready. Returning data...")
return response.json()
# If status is 202, the data is not ready yet. Wait and retry
elif response.status_code == 202:
print(f"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
# If any other status code is received, an error occurred.
else:
print(f"Polling failed! Error: {response.status_code}")
print(response.text)
return {"error": "Polling failed", "status_code": response.status_code, "details": response.text}Esse código faz o seguinte:
- A função
handler()gerencia o fluxo de trabalho no nível do Pipedream. Ela:- Recupera a chave da API da Bright Data, depois que você a armazenou no Pipedream.
- Configura a solicitação da API do Bright Data no lado da URL de destino, ID do conjunto de dados e todos os dados específicos necessários para ela.
- Gerencia a resposta. Se algo der errado, você verá os erros nos registros do Pipedream.
- A função
poll_and_retrieve_snapshot()pesquisa a API Bright Data em busca de um instantâneo até que ele esteja pronto. Quando estiver pronta, ela retorna os dados solicitados. Se algo der errado, ela gerencia os erros e os mostra nos registros.
Quando estiver pronto, clique no botão “Test” (Testar). Você verá uma mensagem de sucesso na seção “RESULTADOS”, e a etapa da ação Bright Data será colorida em verde:
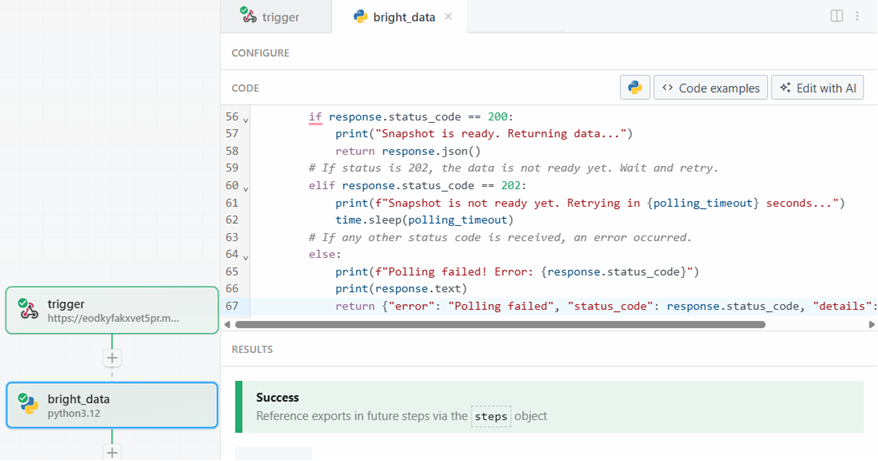
Na seção “Exports” (Exportações), em “RESULTS” (Resultados), é possível ver os dados extraídos:
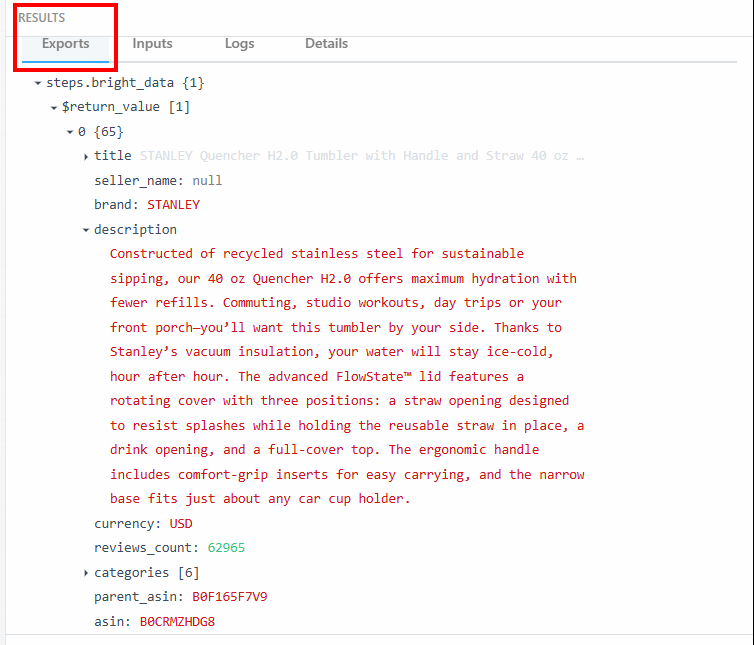
Abaixo estão os dados extraídos como texto:
steps.bright_data{
$return_value{
0{
"title":"STANLEY Quencher H2.0 Tumbler with Handle and Straw 40 oz | Flowstate 3-Position Lid | Cup Holder Compatible for Travel | Insulated Stainless Steel Cup | BPA-Free | Fuchsia",
"seller_name":"null",
"brand":"STANLEY",
"description":"Constructed of recycled stainless steel for sustainable sipping, our 40 oz Quencher H2.0 offers maximum hydration with fewer refills. Commuting, studio workouts, day trips or your front porch—you’ll want this tumbler by your side. Thanks to Stanley’s vacuum insulation, your water will stay ice-cold, hour after hour. The advanced FlowState™ lid features a rotating cover with three positions: a straw opening designed to resist splashes while holding the reusable straw in place, a drink opening, and a full-cover top. The ergonomic handle includes comfort-grip inserts for easy carrying, and the narrow base fits just about any car cup holder.",
"currency":"USD",
"reviews_count":"62965",
..OMITTED FOR BREVITY...
}
}
}Você usará esses dados e sua estrutura na próxima etapa do fluxo de trabalho.
Legal! Você coletou corretamente os dados de destino graças à ação Bright Data no Pipedream.
Etapa 4: adicionar a etapa de ação da OpenAI
Os dados de produtos da Amazon foram extraídos com sucesso pela integração do Beight Data. Agora, você pode alimentá-los em um LLM. Para isso, adicione uma nova ação clicando no botão “+” e procure por “openai”. Aqui, você pode escolher entre diferentes opções:

Selecione a opção “Build any OpenAI (ChatGPT) API request” e, em seguida, selecione a opção “Chat”:
Abaixo está a seção de configuração dessa etapa de ação:
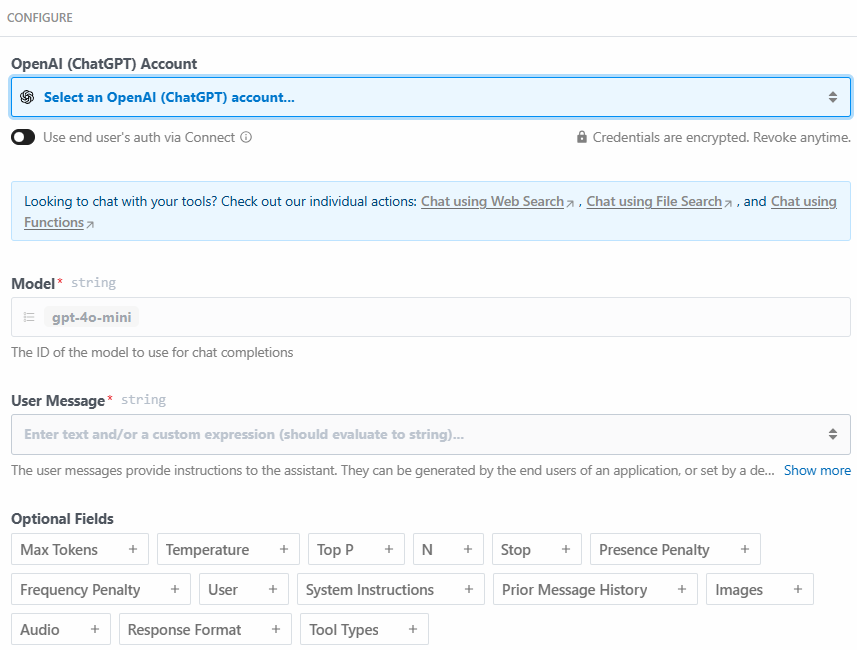
Clique em “Select an OpenAI (ChatGPT) account…” para adicionar sua chave de API da plataforma OpenAI. Em seguida, escreva o seguinte prompt na seção “User Message” (Mensagem do usuário):
Act as an expert product analyst. Consider the following data from an Amazon product page:
PRODUCT TITLE:
{{steps.bright_data.$return_value[0].title}}
BRAND:
{{steps.bright_data.$return_value[0].brand}}
DESCRIPTION:
{{steps.bright_data.$return_value[0].description}}
REVIEWS COUNT
{{steps.bright_data.$return_value[0].reviews_count}}
Based on this data, provide a concise summary of the product that should entice potential customers to buy it. The summary should include what the product is, and its most important features.O prompt solicita que o LLM:
- Agir como um analista de produto especializado. Isso é importante porque, com essa instrução, o LLM se comportará como um analista de produto especializado. Isso ajuda a tornar sua resposta específica para o setor.
- Considere os dados extraídos pela etapa Bright Data, como o título do produto e a descrição. Isso ajuda o LLM a se concentrar nos dados específicos de que você precisa.
- Forneça um resumo do produto, com base nos dados raspados. O prompt também é específico sobre o que o resumo deve conter. É aqui que você verá o poder da automação de IA para o resumo do produto. O LLM criará um resumo do produto, com base nos dados extraídos, atuando como um especialista em produtos.
Você pode recuperar o título do produto com {{steps.bright_data.$return_value[0].title}} porque, conforme especificado na etapa anterior, a estrutura dos dados de saída da etapa da ação Bright Data é:
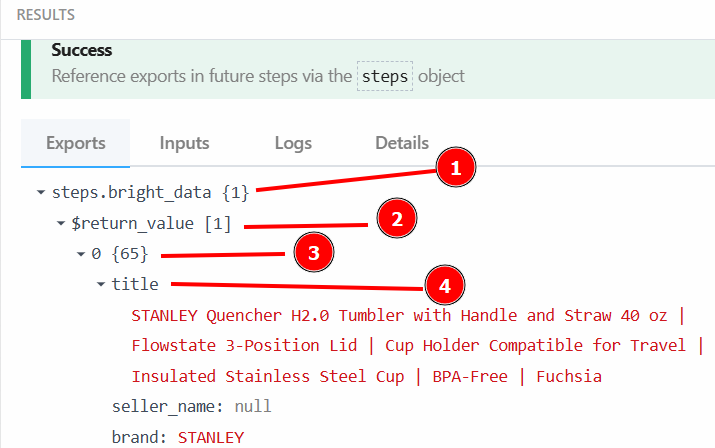
Depois de clicar em “Test” (Testar), encontre o resultado do LLM na seção “RESULTS” (Resultados) da etapa de ação do OpenAI Chat em “Generated message” (Mensagem gerada) > “content” (Conteúdo):
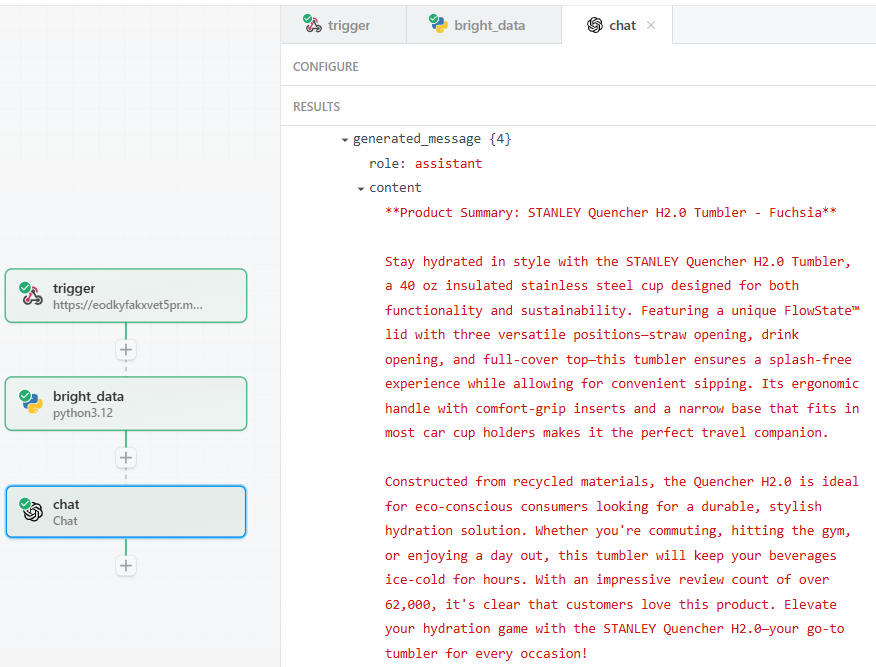
Abaixo está um possível resultado textual:
**Product Summary: STANLEY Quencher H2.0 Tumbler - Fuchsia**
Stay hydrated in style with the STANLEY Quencher H2.0 Tumbler, a 40 oz insulated stainless steel cup designed for both functionality and sustainability. Featuring a unique FlowState™ lid with three versatile positions—straw opening, drink opening, and full-cover top—this tumbler ensures a splash-free experience while allowing for convenient sipping. Its ergonomic handle with comfort-grip inserts and a narrow base that fits in most car cup holders makes it the perfect travel companion.
Constructed from recycled materials, the Quencher H2.0 is ideal for eco-conscious consumers looking for a durable, stylish hydration solution. Whether you're commuting, hitting the gym, or enjoying a day out, this tumbler will keep your beverages ice-cold for hours. With an impressive review count of over 62,000, it's clear that customers love this product. Elevate your hydration game with the STANLEY Quencher H2.0—your go-to tumbler for every occasion!Como você pode ver, o LLM forneceu o resumo do produto, atuando como um especialista no produto. O resumo informa exatamente o que o prompt pede:
- O que é o produto.
- Alguns de seus recursos importantes.
A razão pela qual você deseja extrair dados exatos – como a contagem de classificações – é para ter certeza de que o LLM não está alucinando. O resumo diz que as avaliações são mais de 62.000. Se quiser ver o número exato, você pode verificá-lo no campo “conteúdo” nos resultados:
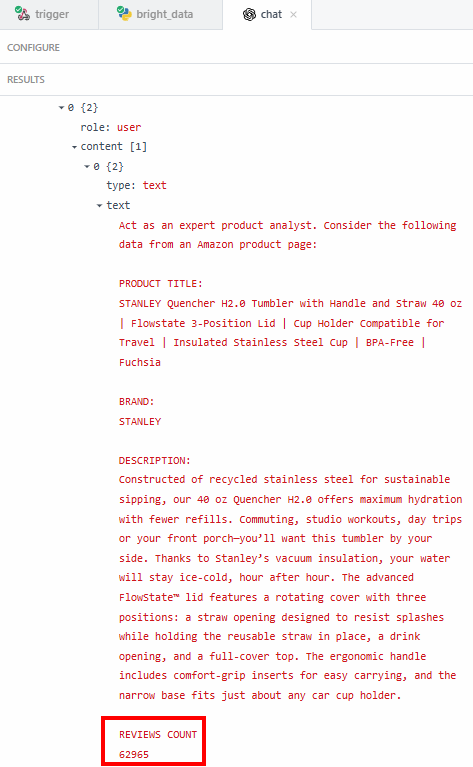
Em seguida, você precisa verificar se esse número corresponde ao mostrado na página do produto na Amazon.
Por fim, se você já tentou fazer scraping de grandes sites de comércio eletrônico, como a Amazon, sabe como é difícil fazer isso por conta própria. Por exemplo, você pode se deparar com o famoso CAPTCHA da Amazon, que pode bloquear a maioria dos scrapers:
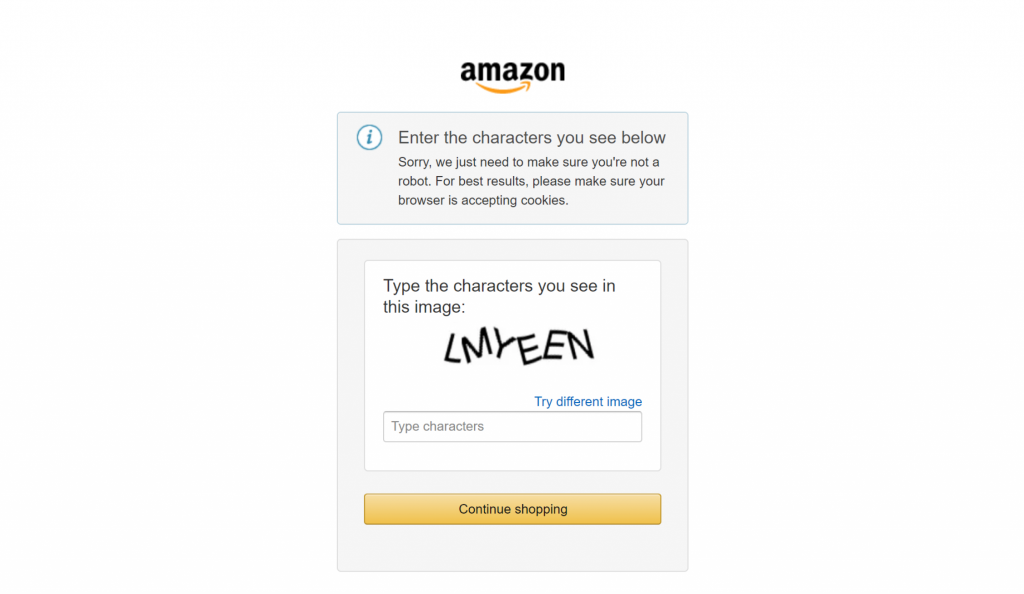
É nesse ponto que a integração da Bright Data faz toda a diferença em seus fluxos de trabalho de coleta de dados. Ela lida com todas as medidas anti-raspagem nos bastidores e garante que o processo de recuperação de dados funcione sem problemas.
Excelente! Você testou com sucesso a etapa do LLM. Agora você está pronto para implementar o fluxo de trabalho.
Etapa 5: implantar o fluxo de trabalho
Para implementar seu fluxo de trabalho, clique em um dos botões “Deploy” (Implementar):
Veja abaixo o que você verá após a implantação:
Para executar todo o fluxo de trabalho, clique em “Generate Event” (Gerar evento):
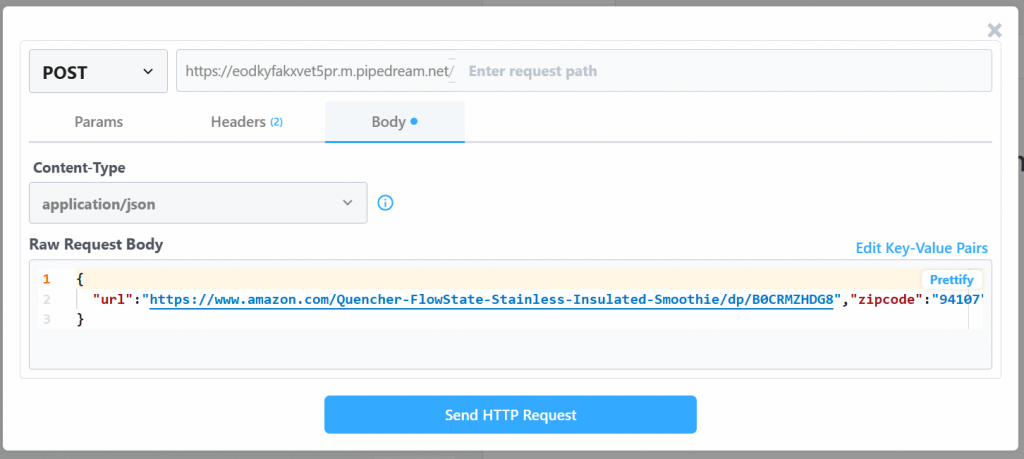
Clique em “Send HTTP Request” (Enviar solicitação HTTP) para acionar o fluxo de trabalho, e ele será totalmente executado. Para ver os resultados dos fluxos de trabalho implantados, vá para “Events history” (Histórico de eventos) na página inicial. Selecione o fluxo de trabalho de seu interesse e veja os resultados em “Exports” (Exportações):
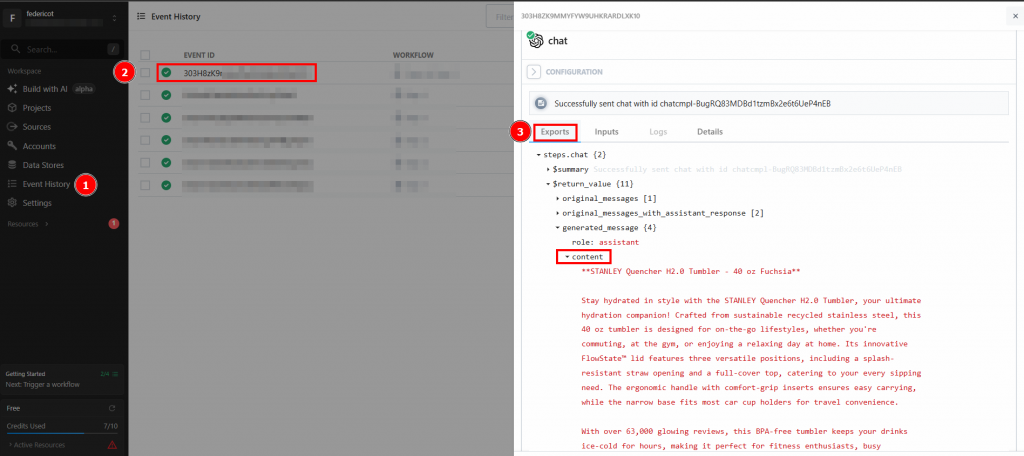
E pronto! Você criou e implantou seu primeiro fluxo de trabalho de raspagem no Pipedream usando o Bright Data.
Conclusão
Neste guia, você aprendeu a criar um fluxo de trabalho automatizado de raspagem da Web usando o Pipedream. Você viu em primeira mão como a interface intuitiva da plataforma, combinada com a integração de raspagem da Bright Data, facilita a criação de pipelines de raspagem sofisticados em questão de minutos.
O principal desafio em qualquer automação orientada por dados é garantir um fluxo consistente de dados limpos e confiáveis. O Pipedream fornece o mecanismo de automação e agendamento, enquanto a infraestrutura de IA da Bright Data lida com as complexidades da raspagem da Web e fornece dados prontos para uso. Essa sinergia permite que você se concentre na criação de valor a partir dos dados, em vez de se preocupar com os obstáculos técnicos para adquiri-los.
Crie uma conta gratuita na Bright Data e comece a fazer experiências com nossas ferramentas de dados prontas para IA hoje mesmo!






