

Neste artigo, você aprenderá:
- O que é o Azure Synapse Analytics e o que ele oferece.
- Por que integrar a API SERP da Bright Data no Azure Synapse Analytics é uma estratégia vencedora.
- Como construir um pipeline do Azure Synapse que coleta, transforma e analisa dados de pesquisa na web usando a API SERP da Bright Data.
Vamos começar!
O que é o Azure Synapse Analytics?
O Azure Synapse Analytics é uma plataforma de análise baseada em nuvem que reúne integração de dados, armazenamento de dados corporativos e processamento de big data em um único espaço de trabalho. Ele fornece orquestração de pipeline, pools Apache Spark e pools SQL dedicados e sem servidor, permitindo que você ingestione, transforme e consulte dados em escala a partir de um único ambiente unificado.
Seu principal objetivo é ajudar você a passar de dados brutos para insights de negócios. Isso é alcançado combinando um mecanismo de pipeline (construído no Azure Data Factory) para ingestão de dados, notebooks Apache Spark para transformações baseadas em código e pools SQL para consultar e servir Conjuntos de dados prontos para análise para painéis, modelos de ML e aplicativos downstream.
Azure Synapse Analytics vs Azure IA Foundry: qual é a diferença?
Se você já leu nosso guia sobre a integração da API SERP com o Azure AI Foundry, talvez esteja se perguntando como o Synapse Analytics difere. Os dois têm finalidades fundamentalmente diferentes:
- O Azure AI Foundry é uma plataforma unificada de desenvolvimento de IA focada na criação, implantação e gerenciamento de aplicativos, agentes e fluxos de prompt de IA. Ele fornece acesso a um catálogo de LLMs (do Azure OpenAI, Meta, Mistral, etc.) e foi projetado para o desenvolvimento com foco em IA, envolvendo engenharia de prompt, ajuste fino de modelos e fluxos de trabalho RAG.
- O Azure Synapse Analytics é uma plataforma de análise e armazenamento de dados focada na ingestão de grandes volumes de dados, na execução de transformações complexas e no fornecimento de análises estruturadas em escala. Ele se destaca em pipelines ETL/ELT, processamento de big data com Spark e inteligência de negócios baseada em SQL.
Resumindo, o Azure AI Foundry é onde você cria aplicativos e fluxos de prompt com tecnologia de IA, enquanto o Azure Synapse Analytics é onde você cria pipelines de dados que coletam, transformam e armazenam dados para análise e relatórios.
Na verdade, eles se complementam perfeitamente. Você pode usar o Synapse para criar a base de dados, coletando e armazenando dados da web em escala, e então alimentar esses dados selecionados no AI Foundry para análise alimentada por LLM. Neste tutorial, você verá como o Synapse Analytics pode se integrar à API SERP da Bright Data para criar um pipeline completo de dados da web que coleta resultados de pesquisa, os transforma com o Spark e fornece análises via SQL.
Por que integrar a API SERP da Bright Data ao Azure Synapse Analytics
O Azure Synapse Analytics oferece um poderoso conector REST em seu mecanismo de pipeline que permite chamar qualquer API REST e enviar os resultados diretamente para o Azure Data Lake Storage. Isso abre as portas para a ingestão de fontes de dados externas em seus fluxos de trabalho de análise. No entanto, para injetar dados de pesquisa na web em tempo real em seu data warehouse, você precisa de uma fonte de dados confiável, escalável e estruturada.
É aí que entra a API SERP da Bright Data. A API SERP permite pesquisar programaticamente consultas em mecanismos de pesquisa, incluindo Google, Bing, DuckDuckGo, Yandex e outros, e recuperar o conteúdo completo da SERP. Ela retorna dados em vários formatos, incluindo JSON analisado, HTML bruto e Markdown pronto para IA, fornecendo uma fonte confiável de dados novos e verificáveis.
Essa abordagem é especialmente útil para:
- Pipelines de rastreamento de palavras-chave de SEO para monitorar suas classificações de pesquisa em milhares de palavras-chave diariamente e identificar tendências ao longo do tempo.
- Armazéns de inteligência competitiva para coletar dados de visibilidade dos concorrentes e combiná-los com métricas internas para análise estratégica.
- Conjuntos de dados de pesquisa de mercado para agregar tendências de resultados de pesquisa em todos os setores, regiões e períodos de tempo para relatórios em grande escala.
- Análise de desempenho de conteúdo para rastrear como seu conteúdo é classificado para palavras-chave alvo e medir o impacto dos esforços de SEO.
Ao combinar os recursos de orquestração de pipeline e armazenamento de dados do Azure Synapse com a API SERP da Bright Data, você pode criar pipelines de dados que coletam, transformam e analisam continuamente dados de pesquisa na web em escala, sem manter nenhuma Infraestrutura de scraping.
Como construir um pipeline de dados SERP no Azure Synapse com a Bright Data
Nesta seção guiada, você verá como integrar a API SERP da Bright Data a um pipeline do Azure Synapse como parte de um rastreador diário de classificação de palavras-chave. Esse pipeline consiste em cinco etapas principais:
- Configuração do espaço de trabalho: você cria um espaço de trabalho do Azure Synapse com uma conta vinculada do Data Lake Storage.
- Configuração da fonte de dados: você cria um serviço vinculado REST apontando para a API SERP da Bright Data, com armazenamento seguro de credenciais.
- Pipeline de ingestão: um pipeline do Synapse chama a API SERP para um conjunto de palavras-chave rastreadas e envia os resultados JSON brutos para o seu data lake.
- Transformação Spark: um notebook Apache Spark achata e normaliza os dados SERP brutos em tabelas Delta prontas para análise.
- Análise SQL: consultas SQL sem servidor analisam as tendências de classificação e as visualizações são criadas para painéis do Power BI.
Observação: este é apenas um exemplo, e você pode aproveitar a API SERP em muitos outros cenários e casos de uso. Por exemplo, você também pode criar pipelines para Monitoramento de preços competitivos ou alimentar dados SERP em modelos de aprendizado de máquina.
Siga as instruções abaixo para criar um pipeline de dados da web com a API SERP da Bright Data no Azure Synapse Analytics!
Pré-requisitos
Para acompanhar esta seção do tutorial, certifique-se de ter:
- Uma conta da Microsoft.
- Uma assinatura do Azure (mesmo a versão de avaliação gratuita é suficiente).
- Uma conta Bright Data com uma zona API SERP ativa e uma chave API (com permissões de administrador).
Siga a documentação oficial da Bright Data para configurar sua zona API SERP e obter sua chave API. Guarde sua chave API e o nome da zona em um local seguro, pois você precisará deles em breve.
Etapa 1: crie um espaço de trabalho do Azure Synapse
Os pipelines do Azure Synapse só estão disponíveis em um espaço de trabalho do Synapse, portanto, o primeiro passo é criar um.
Faça login em sua conta do Azure e pesquise Azure Synapse Analytics na barra de pesquisa na parte superior do Portal do Azure:
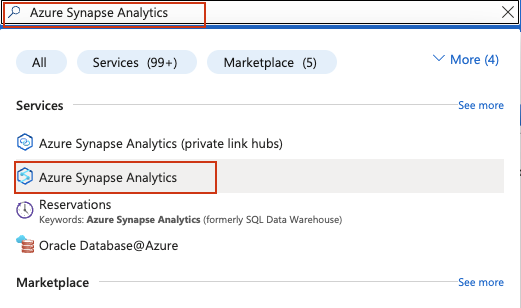
Na página de gerenciamento do Synapse Analytics, clique em Criar. Preencha o formulário de criação:
- Selecione sua assinatura do Azure.
- Selecione um grupo de recursos existente ou crie um novo.
- Dê um nome ao seu espaço de trabalho, como
bright-data-serp-pipeline. - Escolha uma região próxima a você.
- Para o Data Lake Storage Gen2, selecione Criar novo e forneça um nome de conta de armazenamento (deve ser todo em minúsculas, com 3 a 24 caracteres, globalmente exclusivo, por exemplo,
serppipelinelake). Crie um novo sistema de arquivos chamadoraw.
Clique em Revisar + Criar e, em seguida, em Criar para iniciar a implantação.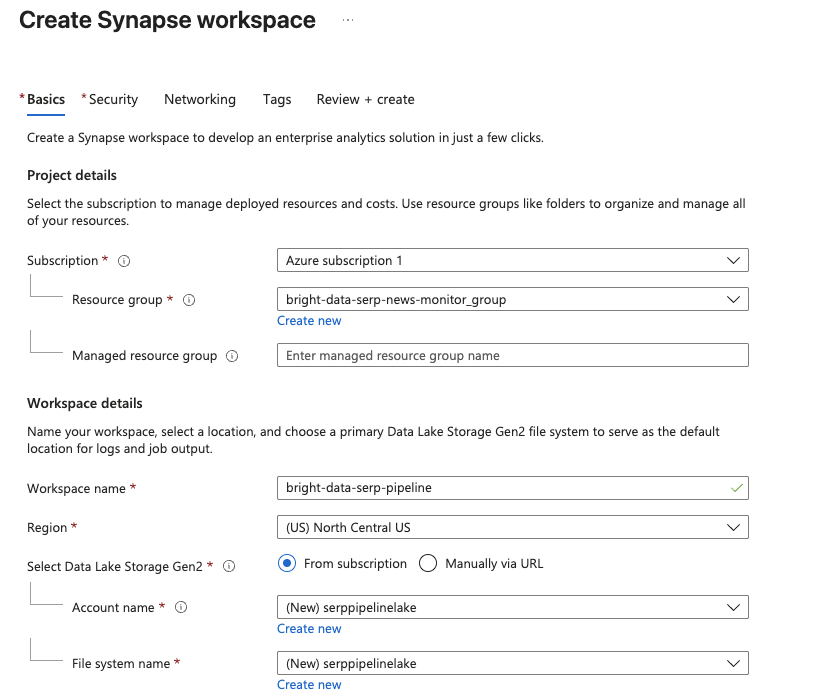
O processo de inicialização pode levar alguns minutos. Quando estiver concluído, você verá uma página de confirmação. Clique em Ir para o recurso e, em seguida, clique em Abrir o Synapse Studio para iniciar o ambiente de desenvolvimento baseado na web.
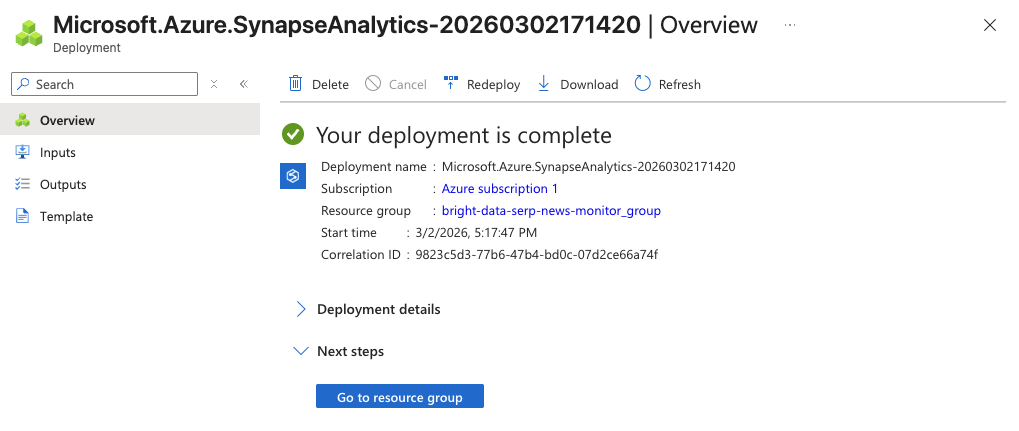
Agora você tem um espaço de trabalho Synapse onde pode criar pipelines, escrever notebooks Spark e executar consultas SQL.
Etapa 2: criar um pool Apache Spark
Para executar os notebooks de transformação mais adiante neste tutorial, você precisa de um pool Apache Spark em seu espaço de trabalho.
- No Synapse Studio, vá para Gerenciar > Pools Apache Spark > Novo.
- Dê um nome ao pool, como
sparkpool. - Defina o tamanho do nó como Pequeno (4 vCores/32 GB), o que é suficiente para transformações de dados SERP.
- Habilite o Autoscale e defina o intervalo para 3 a 5 nós.
- Clique em Revisar + Criar e, em seguida, em Criar.
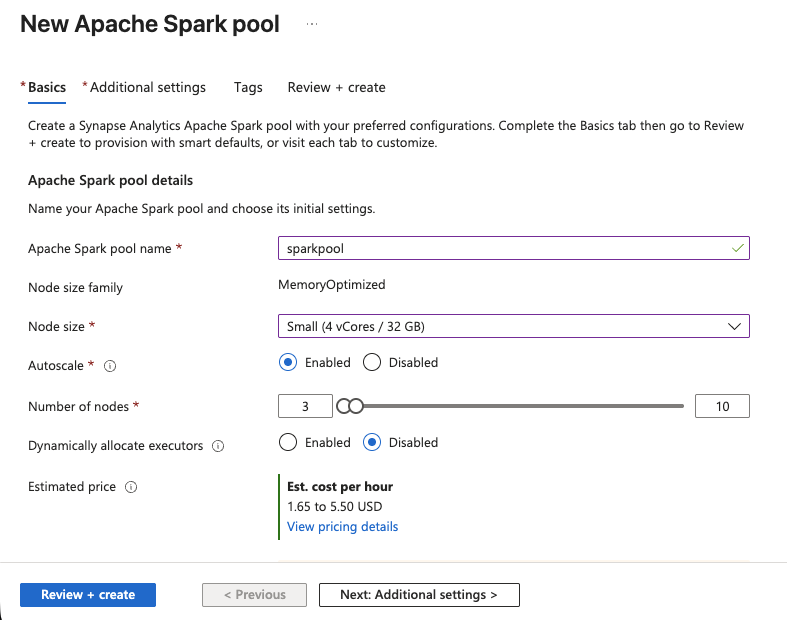
O pool Spark estará pronto em alguns instantes. Agora você tem poder de computação para executar notebooks PySpark.
Etapa 3: criar o pipeline de ingestão
Agora você criará um pipeline Synapse que chama a API SERP da Bright Data para um conjunto de palavras-chave rastreadas e envia os resultados para o seu data lake.
Crie um novo pipeline
- Vá para Integrar > + > Pipeline.
- Nomeie-o como
IngestSERPData.
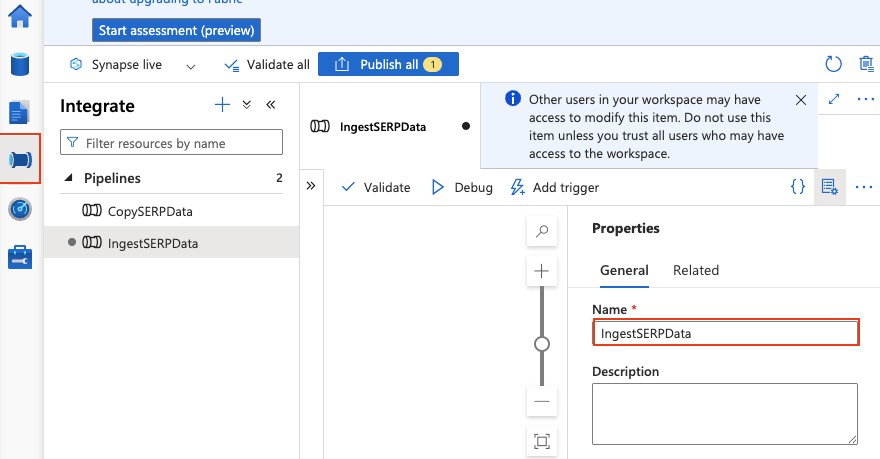
Adicione parâmetros ao pipeline
Clique no fundo da tela do pipeline para abrir as propriedades do pipeline. Vá para a guia Parâmetros e adicione:
| Nome | Tipo | Valor padrão |
|---|---|---|
Palavras-chave |
Matriz | ["ferramentas de Scraping de dados", "serviço de Proxy", "API de extração de dados"] |
Estas são as palavras-chave cujas classificações você deseja acompanhar. Você pode modificar esta lista a qualquer momento.
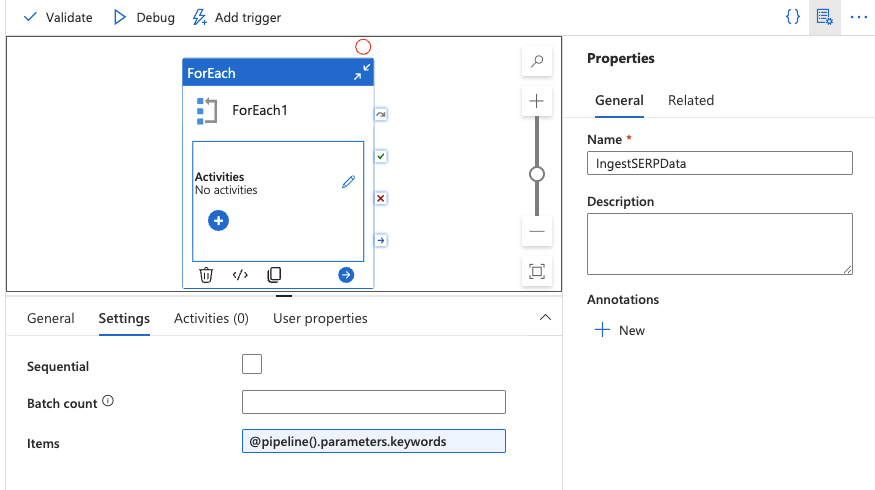
Adicione uma atividade ForEach
- Arraste uma atividade ForEach para a tela a partir do painel Atividades.
- Na guia Configurações, defina o campo Itens como:
@pipeline().parameters.keywords
Isso irá iterar sobre cada palavra-chave em sua matriz.
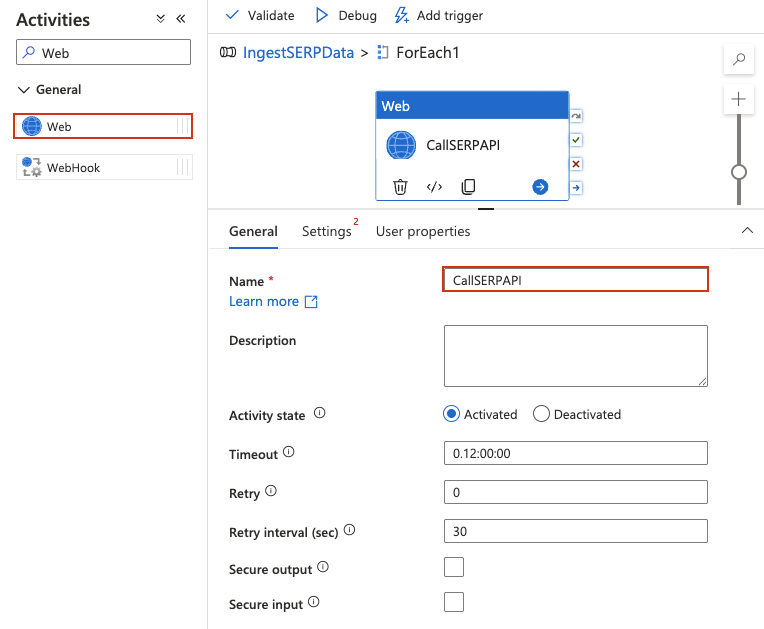
Adicione uma atividade Web dentro do ForEach
Uma atividade Web chama uma API REST diretamente, sem a necessidade de Conjuntos de dados ou serviços vinculados para a solicitação em si.
- Clique duas vezes na atividade ForEach para abrir sua tela interna. Você deverá ver o cabeçalho do designer mudar para indicar que você está dentro do escopo ForEach (semelhante a uma trilha de navegação
IngestSERPData > ForEach1). - No painel Atividades à esquerda, expanda Geral e arraste uma atividade Web para a tela interna.
- Dê um nome a ela, como
CallSERPAPI.
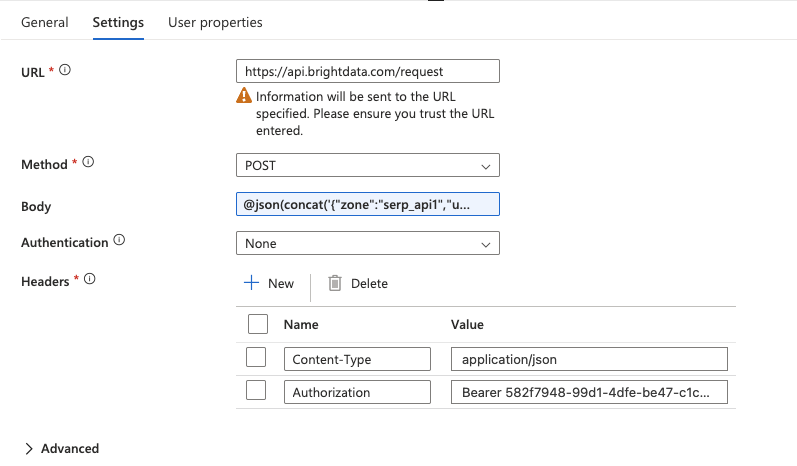
Configure a atividade da Web
Clique na atividade Web para selecioná-la, vá para a guia Configurações e configure:
- URL: digite o endpoint completo da API diretamente no campo:
https://api.brightdata.com/request- Método: Selecione
POSTno menu suspenso. - Cabeçalhos: Clique em + Adicionar cabeçalho duas vezes para adicionar: Nome Valor
Tipo de conteúdoapplication/jsonAutorizaçãoPortador SUA_CHAVE_DE_API_BRIGHT_DATA - Corpo: é aqui que você passa a solicitação da API SERP com a palavra-chave atual do loop ForEach. Digite a seguinte expressão diretamente no campo Corpo (não use o pop-up “Adicionar conteúdo dinâmico”):
@concat('{"zona":"YOUR_SERP_API_ZONA","url":"https://www.google.com/search?q=',replace(item(),' ','+'),'&hl=en&gl=us","format":"raw","data_format":"json"}')Substitua YOUR_SERP_API_ZONE pelo nome real da sua zona no painel do Bright Data.
Importante: O
@deve ser o primeiro caractere no campo, sem espaços à esquerda. Isso indica ao Synapse para avaliar o texto como uma expressão. Se inserido corretamente, o campo destacará a expressão. Se aparecer como texto simples, exclua e digite novamente, garantindo que@esteja na posição zero.O que isso faz: a função
item()retorna a palavra-chave atual do loop ForEach (por exemplo,“ferramentas de Scraping de dados”). A funçãoreplace()substitui os espaços por caracteres+para formar um parâmetro de consulta de URL válido. A funçãoconcat()cria o corpo completo da solicitação JSON como uma única string.
- Autenticação: defina como
Nenhuma(a autenticação já é tratada pelo cabeçalho Authorization).
Adicione um gatilho de programação
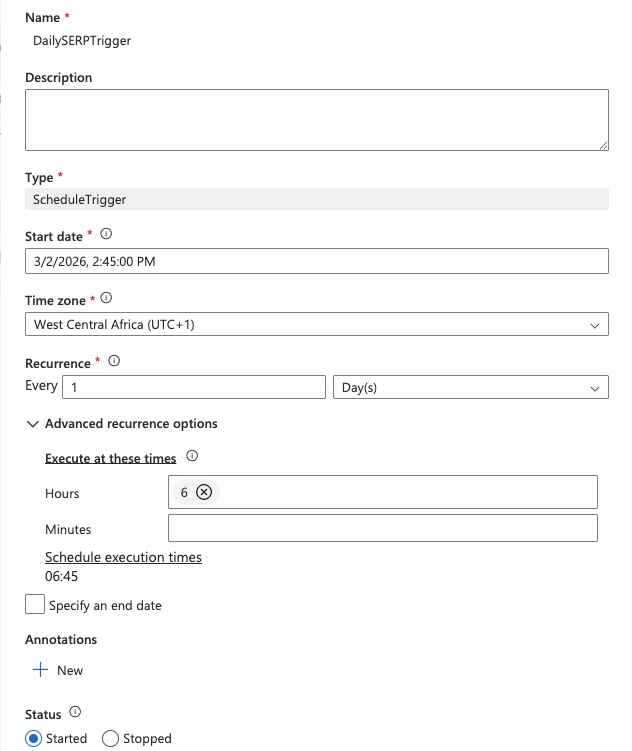
- De volta à tela principal do pipeline, clique em Adicionar gatilho > Novo/Editar.
- Selecione Novo e defina uma recorrência diária (por exemplo, 6:00 UTC).
- Clique em OK e, em seguida, em Publicar tudo para salvar e implantar o pipeline.
Para testá-lo imediatamente, clique em Acionar agora > OK. Navegue até Monitorar > Execuções do pipeline para observar a execução. Você deverá ver o pipeline ser bem-sucedido e encontrar arquivos JSON em seu data lake no caminho raw/serp/.
Retorne à tela principal do pipeline
Clique no nome do pipeline (IngestSERPData) na trilha de navegação na parte superior do designer para retornar à tela principal. Você deverá ver a atividade ForEach com um indicador mostrando que ela contém atividades secundárias.
Adicione um gatilho de programação
- Clique em Adicionar gatilho > Novo/Editar na parte superior do designer do pipeline.
- No menu suspenso, selecione Novo.
- Dê um nome ao gatilho (por exemplo,
DailySERPTrigger), defina o Tipo como Programação e configure:
- Data de início: data de hoje
- Recorrência: a cada
1dia - Nestas horas:
6(para 6:00 UTC)
- Clique em OK e confirme os parâmetros do gatilho.
- Clique em Publicar tudo na parte superior do Synapse Studio para salvar e implantar tudo.
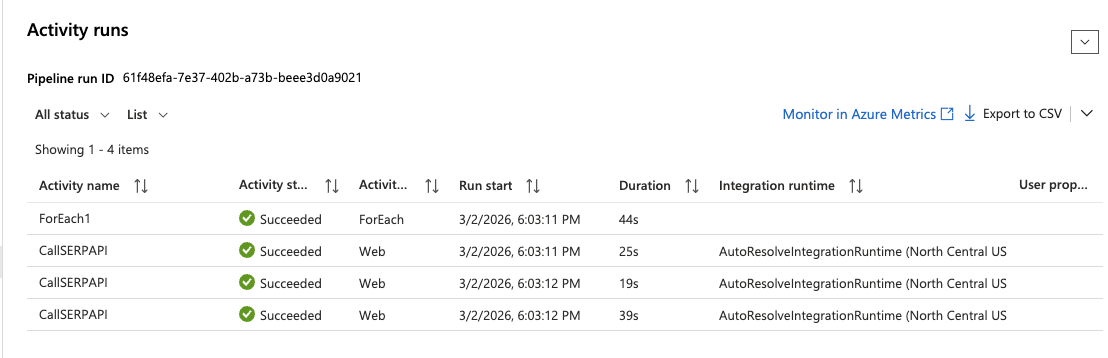
Teste o pipeline
Para executar o pipeline imediatamente, sem esperar pelo acionador programado:
- Clique em Acionar agora > OK na parte superior do designer do pipeline.
- Navegue até Monitorar > Execuções do pipeline no menu à esquerda.
- Aguarde a conclusão da execução. Você deverá ver um status verde de Sucesso.
- Clique na execução e expanda a atividade ForEach para inspecionar cada execução da atividade da Web. Clique em qualquer iteração
CallSERPAPIpara ver a resposta completa da API na seção Saída.
Etapa 4: coletar e transformar dados com o Apache Spark
A atividade da Web na Etapa 3 validou que a integração da API SERP funciona e demonstrou a orquestração do pipeline com agendamento. Para a etapa de coleta e transformação de dados, você usará um notebook Apache Spark que chama a API SERP diretamente usando Python, salva as respostas brutas em seu data lake e as transforma em tabelas Delta prontas para análise.
Essa abordagem é padrão na engenharia de dados; os pipelines lidam com a orquestração e o agendamento, enquanto os notebooks lidam com a lógica real de processamento de dados.
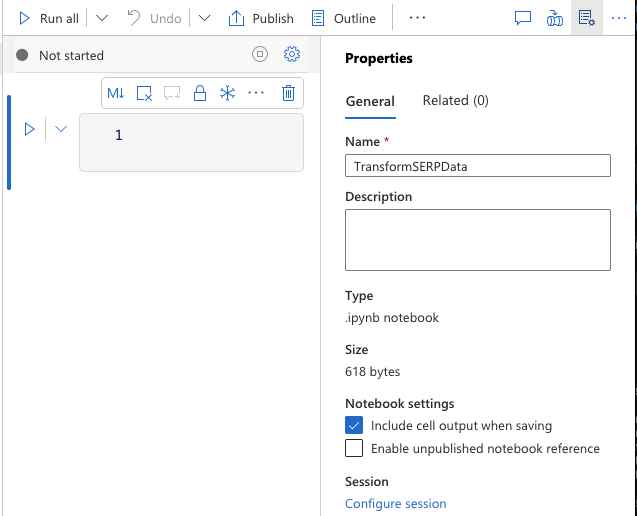
Crie um notebook Spark
- Navegue até Desenvolver > + > Notebook.
- Nomeie-o como
TransformSERPData. - Anexe-o ao seu pool Apache Spark
sparkpool. - Certifique-se de que PySpark (Python) esteja selecionado como idioma.
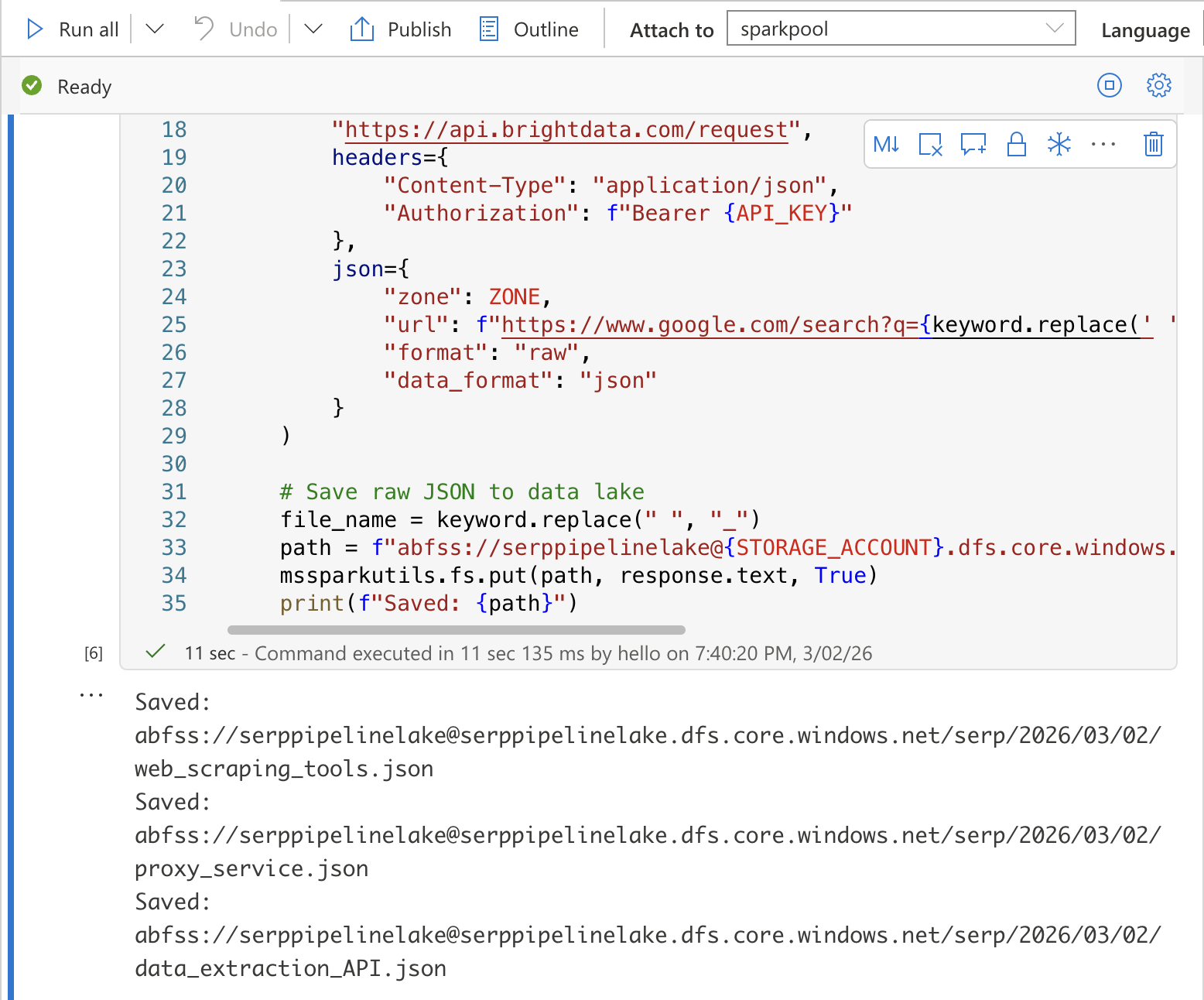
Célula 1: Colete dados SERP e salve no data lake
Na primeira célula, adicione o seguinte código. Isso chama a API SERP da Bright Data para cada palavra-chave e salva as respostas JSON brutas no seu data lake:
import requests
import json
from datetime import datetime
from notebookutils import mssparkutils
# Configuração
API_KEY = "SUA_CHAVE_API_BRIGHT_DATA"
Zona = "SUA_ZONA_DE_API_SERP"
STORAGE_ACCOUNT = "SUA_CONTA_DE_ARMAZENAMENTO"
import requests
import json
from datetime import datetime
from notebookutils import mssparkutils
# Colete dados SERP para cada palavra-chave
today = datetime.utcnow().strftime("%Y/%m/%d")
para palavra-chave em PALAVRAS-CHAVE:
# Chamar a API SERP da Bright Data
resposta = requests.post(
"https://api.brightdata.com/request",
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
},
json={
"zona": ZONA,
"url": f"abfss://[email protected]/serp/{today}/{file_name}.json"
}
)
# Salvar JSON bruto no data lake
file_name = keyword.replace(" ", "_")
path = f"abfss://raw@{STORAGE_ACCOUNT}.dfs.core.windows.net/serp/{today}/{file_name}.json"
mssparkutils.fs.put(path, response.text, True)
print(f"Salvo: {path}")Substitua YOUR_BRIGHT_DATA_API_KEY, YOUR_SERP_API_ZONE e YOUR_STORAGE_ACCOUNT pelos seus valores reais.
Dica de segurança: em produção, armazene sua chave de API no Azure Key Vault e recupere-a usando
mssparkutils.credentials.getSecret("your-keyvault-name", "BRIGHT_DATA_API_KEY")em vez de codificá-la.
Execute a célula pressionando Shift + Enter. Você deverá ver uma saída confirmando que cada arquivo foi salvo no data lake.
Célula 2: Transforme e simplifique os dados SERP
Em uma nova célula, adicione o código de transformação que lê o JSON bruto e o simplifica em uma tabela estruturada:
from pyspark.sql.functions import explode, col, current_timestamp
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, ArrayType
# Leia os dados SERP brutos do data lake
serp_raw = spark.read.option("multiline", "true").json(
f"abfss://serppipelinelake@{STORAGE_ACCOUNT}.dfs.core.windows.net/serp/{today}/*.json")
# Achatar: extrair a palavra-chave de general.query e expandir os resultados orgânicos
serp_flattened = serp_raw.select(
col("general.query").alias("keyword"),
col("general.language").alias("language"),
col("general.location").alias("location"),
explode(col("organic")).alias("result")
).select(
"palavra-chave",
"idioma",
"localização",
col("result.rank").cast("int").alias("rank"),
col("result.title").alias("title"),
col("result.link").alias("url"),
col("result.source").alias("source"),
col("result.description").alias("snippet"),
current_timestamp().alias("collected_at"))
# Mostrar uma pré-visualização
display(serp_flattened)Execute a célula. Você deverá ver uma tabela de pré-visualização mostrando os resultados SERP simplificados com colunas para palavra-chave, classificação, título, URL, snippet e carimbo de data/hora da coleta.
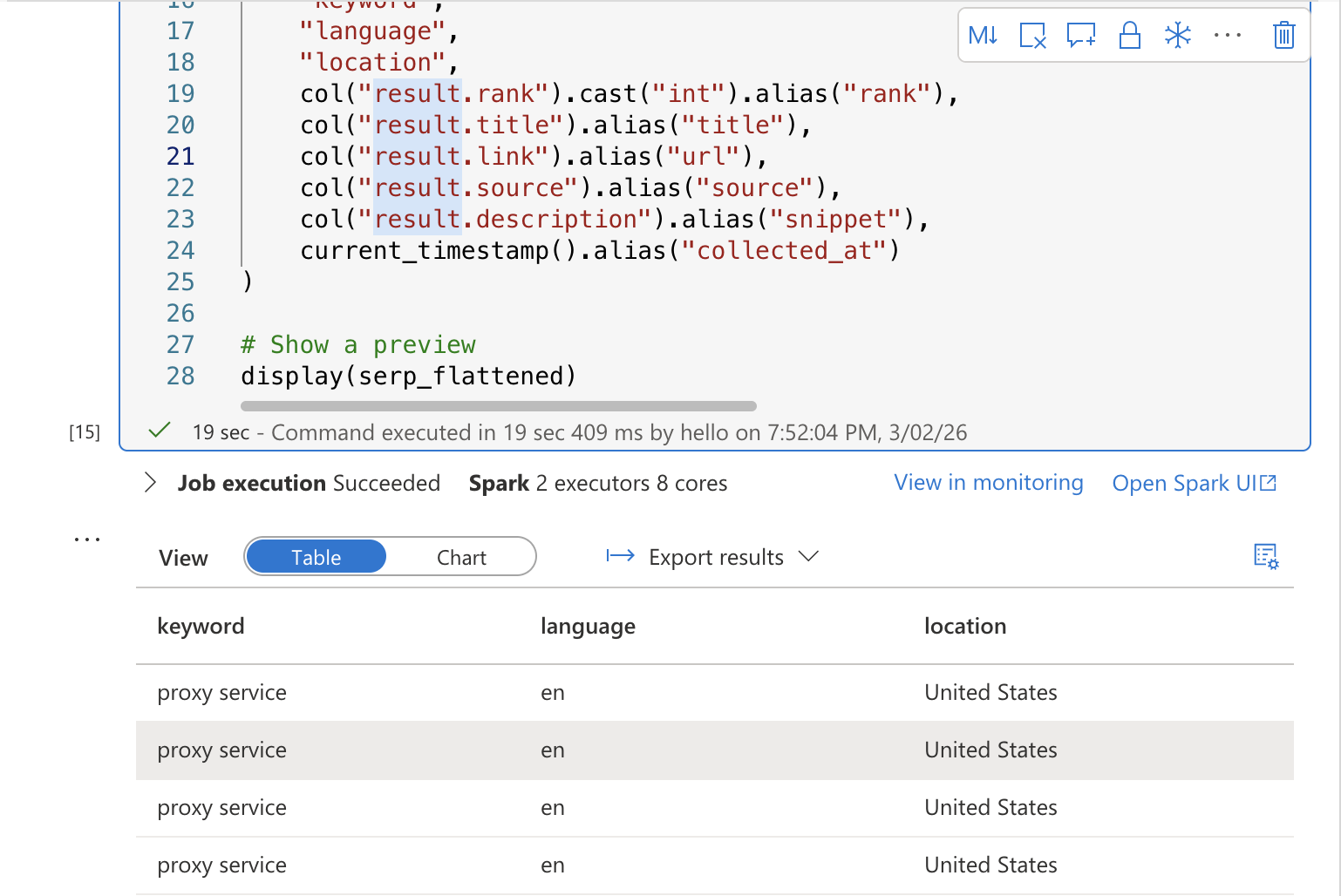
Célula 3: salvar em uma tabela Delta
Em uma terceira célula, grave os dados transformados em uma tabela Delta para análise SQL:
# Grave os dados transformados como uma tabela Delta em seu data lake
serp_flattened.write.format("delta").mode("append").save(
f"abfss://[email protected]/curated/serp_rankings"
)
print("Dados gravados em curated/serp_rankings") 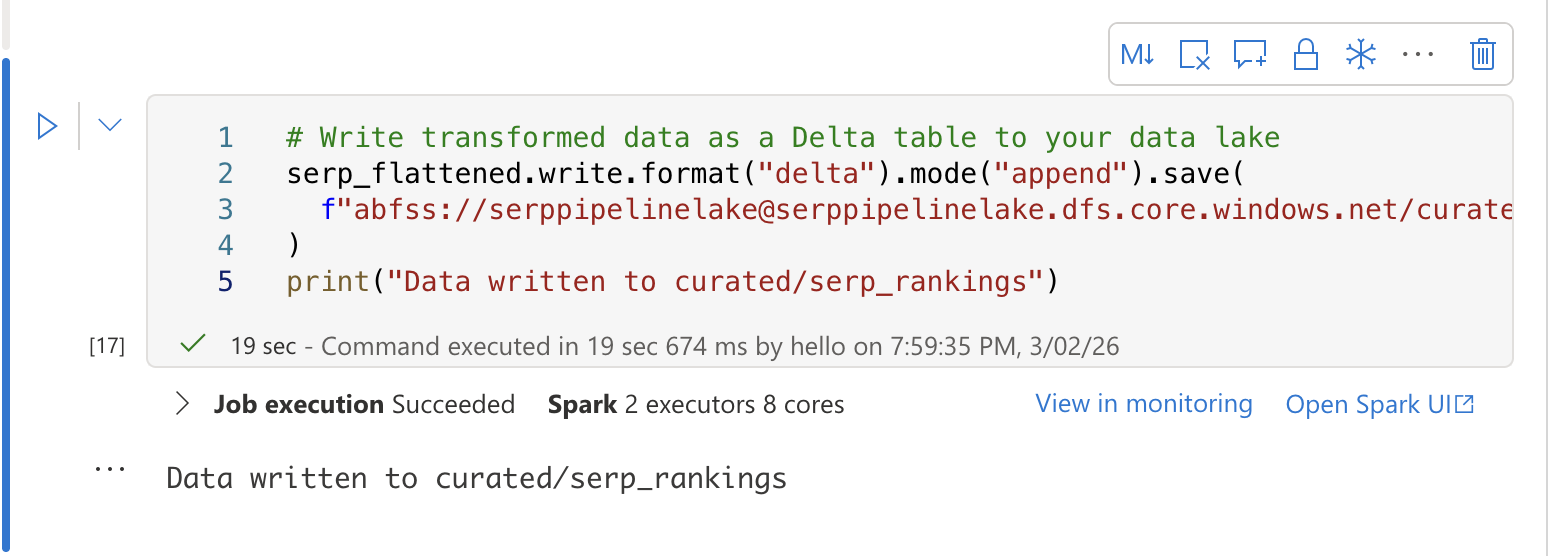
Adicione o notebook ao seu pipeline
- Volte ao seu pipeline
IngestSERPDatano hub Integrate. - Arraste uma atividade Notebook para a tela, fora e após a atividade ForEach.
- Na guia Configurações, selecione seu notebook
TransformSERPDatae anexe-o aosparkpool. - Conecte a atividade ForEach à atividade Notebook com uma dependência de sucesso (arraste a seta verde).
- Clique em Publicar tudo para salvar.
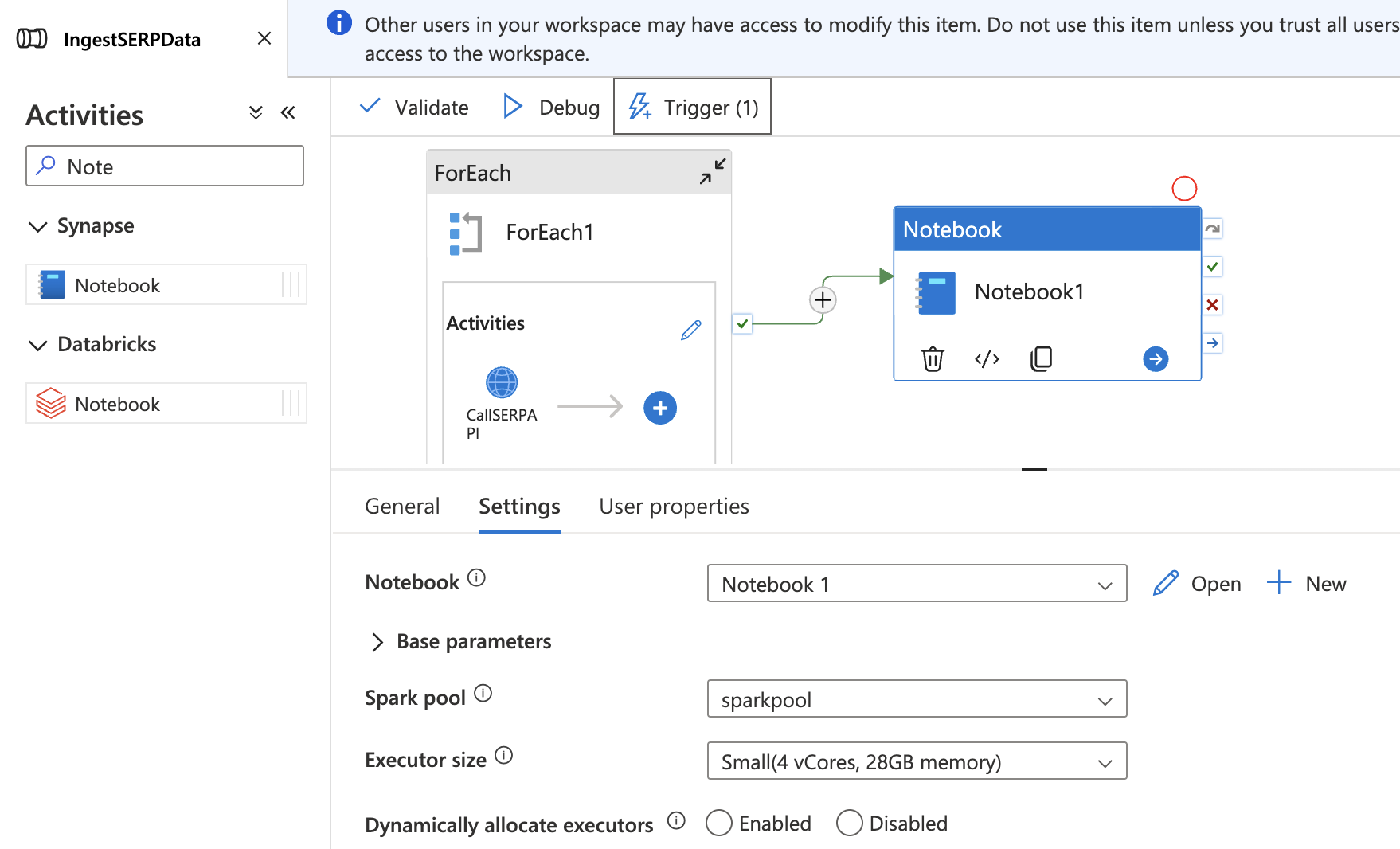
Agora, o pipeline completo é executado de ponta a ponta: coletar dados SERP → enviar para o data lake → transformar em uma tabela Delta.
Etapa 5: analise as classificações com SQL
Depois que seus dados estiverem em uma tabela Delta, você poderá consultá-los diretamente usando o pool SQL sem servidor do Synapse — sem necessidade de provisionamento adicional. O pool SQL sem servidor lê os arquivos Delta diretamente do seu data lake usando a função OPENROWSET.
Crie um banco de dados
Navegue até Desenvolver > + > Script SQL. Certifique-se de que Incorporado (sem servidor) esteja selecionado como o pool SQL na parte superior do editor de scripts. Execute o seguinte para criar um banco de dados dedicado para suas análises SERP:
CREATE DATABASE serp_analytics;Depois que o banco de dados for criado, alterne para ele selecionando serp_analytics no menu suspenso do banco de dados na parte superior do editor de scripts.
Acompanhe as mudanças na classificação ao longo do tempo
Crie um novo script SQL (ou limpe o anterior) e execute a seguinte consulta. Isso lê a tabela Delta diretamente do seu data lake usando OPENROWSET:
-- Veja como as classificações mudam dia após dia para cada palavra-chave e URL
SELECT
palavra-chave,
url,
classificação,
coletado_em,
classificação - LAG(classificação) OVER (PARTITION BY palavra-chave, url ORDER BY coletado_em) AS mudança_na_classificação
FROM OPENROWSET(
BULK 'abfss://[email protected]/curated/serp_rankings/',
FORMAT = 'DELTA')
AS serp_rankings
WHERE keyword = 'Scraping de dados'
ORDER BY collected_at DESC, rank ASC;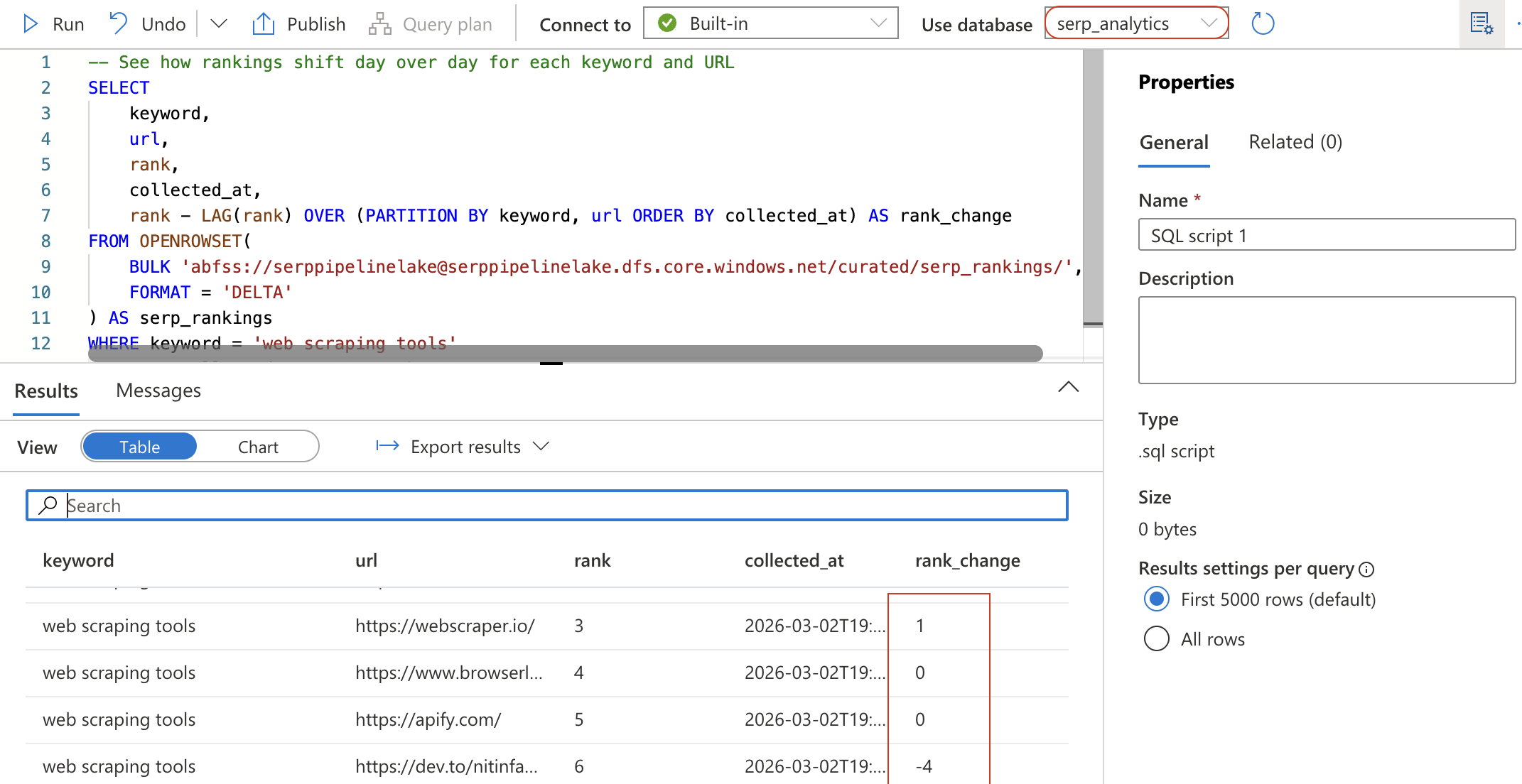
Esta consulta usa a função de janela LAG para calcular como a posição de cada URL mudou desde a coleta anterior. Um rank_change negativo significa que o URL subiu no ranking.
Crie uma exibição resumida para o Power BI
Para tornar os dados facilmente consumíveis pelo Power BI, crie uma exibição que resuma as classificações diárias por palavra-chave:
CREATE VIEW daily_serp_summary AS
SELECT
keyword,
CAST(collected_at AS DATE) AS report_date,
COUNT(*) AS total_results,
AVG(CAST(rank AS FLOAT)) AS avg_rank,
MIN(rank) AS best_rank
FROM OPENROWSET(
BULK 'abfss://[email protected]/curated/serp_rankings/',
FORMAT = 'DELTA')
AS serp_rankings
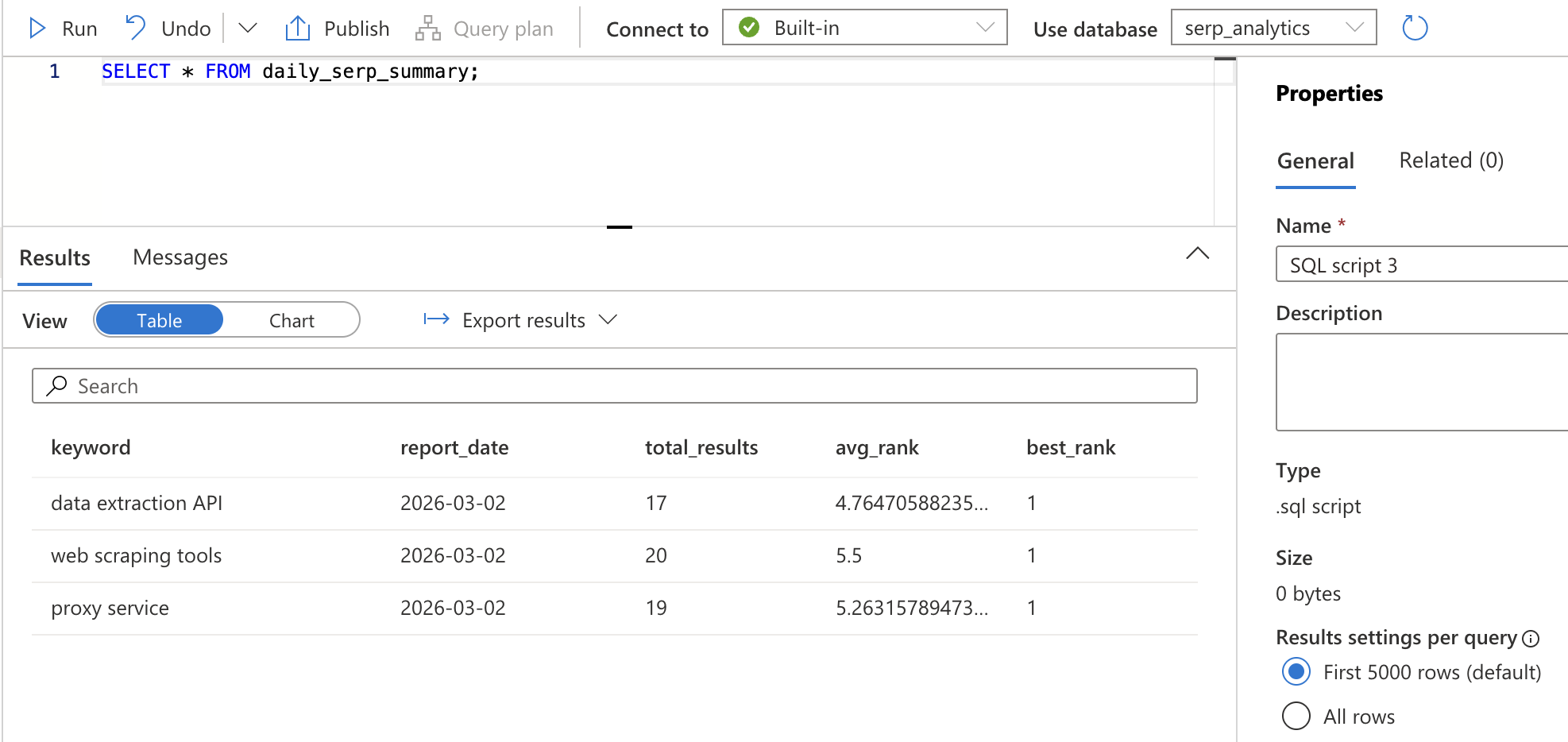
GROUP BY keyword, CAST(collected_at AS DATE);Clique em Executar. Isso cria uma exibição — uma consulta salva que pode ser referenciada pelo nome. Verifique se funciona executando:
SELECT * FROM daily_serp_summary;Você deverá ver uma linha por palavra-chave por dia, com o número total de resultados, a classificação média e a melhor classificação.
Etapa 6: inspecione os resultados
Após a execução completa do pipeline, você pode inspecionar todas as etapas no Synapse Studio.
Navegue até Monitor > Execuções do pipeline e clique na execução mais recente para inspecioná-la. Você verá uma representação visual de cada etapa, mostrando:
- A atividade ForEach com cada iteração de palavra-chave e os resultados da atividade Web.
- A atividade Notebook com os detalhes de execução da tarefa Spark.
Expanda a atividade ForEach para verificar se os dados SERP foram recuperados com sucesso para cada palavra-chave. Clique em qualquer execução da atividade Web CallSERPAPI para ver os detalhes da solicitação/resposta nas seções Entrada e Saída.
Navegue até Dados > Vinculados > sua conta de armazenamento para procurar os arquivos JSON brutos na pasta raw/serp/. Você deverá ver pastas particionadas por data com um arquivo JSON por palavra-chave.
Por fim, abra o hub Develop, vá para o seu notebook TransformSERPData e verifique a tabela Delta executando:
SELECT * FROM curated.serp_rankings ORDER BY collected_at DESC LIMIT 20;Você deverá ver linhas estruturadas com palavra-chave, classificação, título, URL, trecho e carimbo de data/hora da coleta, dados limpos e prontos para análise, criados a partir de resultados SERP brutos. A API SERP da Bright Data cuidou da parte difícil: buscar resultados de pesquisa do Google em grande escala de forma confiável, contornando medidas antibots e limitadores de taxa e retornando dados estruturados prontos para o seu pipeline.
Indo além
Este exemplo demonstra um rastreador de classificação de palavras-chave, mas você pode estender seu pipeline Synapse em várias direções:
- Substitua a chamada da API SERP pela API Web Scraper da Bright Data para coletar preços de produtos, avaliações ou listas de empregos e criar painéis de inteligência competitiva de preços.
- Adicione um segundo notebook Spark para executar análises de sentimento em trechos da SERP, pontuando cada resultado como positivo ou negativo.
- Conecte as tabelas Delta selecionadas ao Azure Machine Learning para análises preditivas, como prever mudanças na classificação ou identificar tendências de pesquisa emergentes.
- Crie uma arquitetura de nuvem híbrida em que os dados SERP são armazenados no Azure Data Lake, enquanto os dados internos confidenciais permanecem no local, com o Synapse consultando ambos por meio de consultas federadas.
- Encaminhe os dados transformados para um fluxo de prompt do Azure AI Foundry para análise alimentada por LLM, combinando a engenharia de dados do Synapse com os recursos de IA do AI Foundry.
- Integre-se a ferramentas como LangChain ou CrewAI para criar fluxos de trabalho agenticos que consomem seus dados SERP selecionados.
As possibilidades são praticamente infinitas!
Conclusão
Nesta postagem do blog, você aprendeu como usar a API SERP da Bright Data para obter resultados de pesquisa atualizados do Google e integrá-los a um pipeline de dados completo no Azure Synapse Analytics.
O pipeline demonstrado aqui é ideal para quem deseja criar um rastreador automatizado de classificação de palavras-chave que coleta continuamente dados SERP, transforma-os em tabelas prontas para análise e fornece insights por meio de consultas SQL e painéis do Power BI. Ao contrário da abordagem do Azure AI Foundry, que é ideal para engenharia de prompt com prioridade em IA e fluxos de trabalho RAG, o Azure Synapse Analytics se destaca na ingestão, transformação e armazenamento de dados em grande escala para inteligência de negócios e análise.
Para criar pipelines de dados mais avançados, explore o conjunto completo de ferramentas de Scraping de dados da Bright Data para recuperar, validar e transformar dados da web em tempo real. Para um aprofundamento nos padrões de arquitetura de pipeline de dados, o blog da Bright Data aborda os fundamentos.
Inscreva-se hoje mesmo para obter uma conta gratuita na Bright Data e comece a experimentar nossas soluções de dados da web prontas para IA!






