

Neste guia, você aprenderá:
- Por que o Scraping de dados é um método excelente para enriquecer LLMs com dados do mundo real
- Os benefícios e desafios do uso de dados coletados em fluxos de trabalho LangChain
- Uma biblioteca para integração simplificada de scraping no LangChain
- Como criar uma integração completa de Scraping de dados do LangChain em um tutorial passo a passo
Vamos começar!
Usando o Scraping de dados para potencializar suas aplicações LLM
O scraping de dados da web envolve a recuperação de dados de páginas da web. Esses dados podem então ser usados para alimentar aplicativos RAG (Retrieval-Augmented Generation) integrando-os com LLMs (Large Language Models).
Os sistemas RAG exigem acesso a dados ricos, atualizados, em tempo real, específicos de domínio ou expansivos que não estão prontamente disponíveis em Conjuntos de dados estáticos que você pode comprar ou baixar online. O scraping de dados preenche essa lacuna, fornecendo informações estruturadas extraídas de várias fontes, como artigos de notícias, listas de produtos e mídias sociais.
Saiba mais em nosso artigo sobre a coleta de dados de treinamento LLM.
Benefícios e desafios do uso de dados coletados no LangChain
O LangChain é uma estrutura poderosa para a criação de fluxos de trabalho orientados por IA, permitindo a integração simplificada de LLMs com diversas fontes de dados. Ele se destaca na análise de dados, resumos e respostas a perguntas, combinando LLMs com conhecimento específico do domínio em tempo real. No entanto, a aquisição de dados de alta qualidade é sempre um problema.
O scraping de dados da web pode resolver esse problema, mas traz vários desafios, incluindo medidas anti-bot, CAPTCHAs e sites dinâmicos. Manter Scrapers compatíveis e eficientes também pode ser demorado e tecnicamente complexo. Para obter mais detalhes, consulte nosso guia sobre medidas anti-scraping.
Esses obstáculos podem retardar o desenvolvimento de aplicativos alimentados por IA que dependem de dados em tempo real. A solução? A API Web Scraper da Bright Data— uma ferramenta pronta para uso que oferece pontos finais de scraping para centenas de sites.
Com recursos avançados como rotação de IP, Resolução de CAPTCHA e renderização de JavaScript, a Bright Data automatiza a extração de dados para você. Isso garante uma coleta de dados confiável, eficiente e sem complicações, tudo acessível por meio de chamadas de API simples.
Ferramentas LangChain Bright Data
Agora, embora você possa integrar a API de Scraping de Dados da Bright Data e outras ferramentas de scraping diretamente ao seu fluxo de trabalho LangChain, isso exigiria lógica personalizada e código padrão. Para economizar tempo e esforço, você deve preferir o pacote oficial de integração LangChain Bright Data langchain-brightdata.
Este pacote permite que você se conecte aos serviços da Bright Data dentro dos fluxos de trabalho do LangChain. Em particular, ele expõe as seguintes classes:
BrightDataSERP: integra-se à API SERP da Bright Data para realizar consultas em mecanismos de pesquisa com segmentação geográfica.BrightDataUnblocker: funciona com o Web Unlocker da Bright Data para acessar sites que podem ser restritos geograficamente ou protegidos por sistemas anti-bot.BrightDataWebScraperAPI: faz interface com a API Web Scraper da Bright Data para extrair dados estruturados de vários domínios.
Neste tutorial, vamos nos concentrar no uso da classe BrightDataWebScraperAPI. Hora de ver como!
LangChain Scraping de dados com tecnologia Bright Data: guia passo a passo
Nesta seção, você aprenderá como construir um fluxo de trabalho de Scraping de dados com LangChain. O objetivo é utilizar o LangChain para recuperar conteúdo de um perfil do LinkedIn usando a API Web Scraper da Bright Data e, em seguida, usar o OpenAI para avaliar se o candidato é uma boa opção para uma vaga de emprego específica.
Usaremos minha página de perfil público do LinkedIn como referência, mas qualquer outro perfil do LinkedIn também funcionará:
Observação: o que estamos criando aqui é apenas um exemplo. O código que você está prestes a escrever é facilmente adaptável a diferentes cenários. Isso significa que ele também pode ser ampliado com recursos adicionais do LangChain. Por exemplo, você poderia até criar um chatbot RAG com base nos dados SERP.
Siga as etapas abaixo para começar!
Pré-requisitos
Para concluir este tutorial, você precisará do seguinte:
- Python 3+ instalado em sua máquina
- Uma chave API OpenAI
- Uma conta Bright Data
Não se preocupe se você não tiver algum desses itens. Nós o orientaremos durante todo o processo, desde a instalação do Python até a obtenção de suas credenciais OpenAI e Bright Data.
Etapa 1: Configuração do projeto
Primeiro, verifique se o Python 3 está instalado em sua máquina. Se não estiver, baixe e instale-o.
Execute este comando no terminal para criar uma pasta para o seu projeto:
mkdir langchain-scrapinglangchain-scraping conterá seu projeto de scraping Python LangChain.
Em seguida, navegue até a pasta do projeto e inicialize um ambiente virtual Python dentro dela:
cd langchain-scraping
python3 -m venv venvObservação: no Windows, use python em vez de python3.
Agora, abra o diretório do projeto em seu IDE Python favorito. O PyCharm Community Edition ou o Visual Studio Code com a extensão Python são adequados.
Dentro do langchain-scraping, adicione um arquivo script.py. Este é um script Python vazio, mas em breve conterá sua lógica de Scraping de dados LangChain.
No terminal do IDE, no Linux ou macOS, ative o ambiente virtual com o comando abaixo:
source venv/bin/activateOu, no Windows, execute:
venv/Scripts/activateÓtimo! Agora você está totalmente configurado.
Etapa 2: instale as bibliotecas necessárias
O projeto de scraping Python LangChain depende das seguintes bibliotecas:
python-dotenv: para carregar variáveis de ambiente de um arquivo.env. Será usado para gerenciar as chaves API da Bright Data e da OpenAI.langchain-openai: integrações LangChain para OpenAI por meio de seu SDKopenai.langchain-brightdata: integração do LangChain com os serviços de scraping do Bright Data.
Em um ambiente virtual ativado, instale todas as dependências com este comando:
pip install python-dotenv langchain-openai langchain-brightdataÓtimo! Você está pronto para escrever alguma lógica de scraping.
Etapa 3: Prepare seu projeto
Em script.py, adicione a seguinte importação:
from dotenv import load_dotenvEm seguida, crie um arquivo .env na pasta do seu projeto para armazenar todas as suas credenciais. Aqui está como deve ficar a estrutura atual do arquivo do seu projeto:

Instrua o python-dotenv a carregar as variáveis de ambiente do .env com esta linha no script.py:
load_dotenv()Ótimo! É hora de configurar a solução API Web Scraper da Bright Data.
Etapa 4: Configure a API Web Scraper
Como mencionado no início deste artigo, o Scraping de dados traz vários desafios. Felizmente, isso se torna significativamente mais fácil com uma solução completa como as APIs Web Scraper da Bright Data. Essas APIs permitem que você recupere conteúdo analisado de mais de 120 sites sem esforço.
Para configurar a API de Scraping de Dados no LangChain usando langchain_brightdata, siga as instruções abaixo. Para uma introdução geral à solução de Scraping de Dados da Bright Data, consulte a documentação oficial.
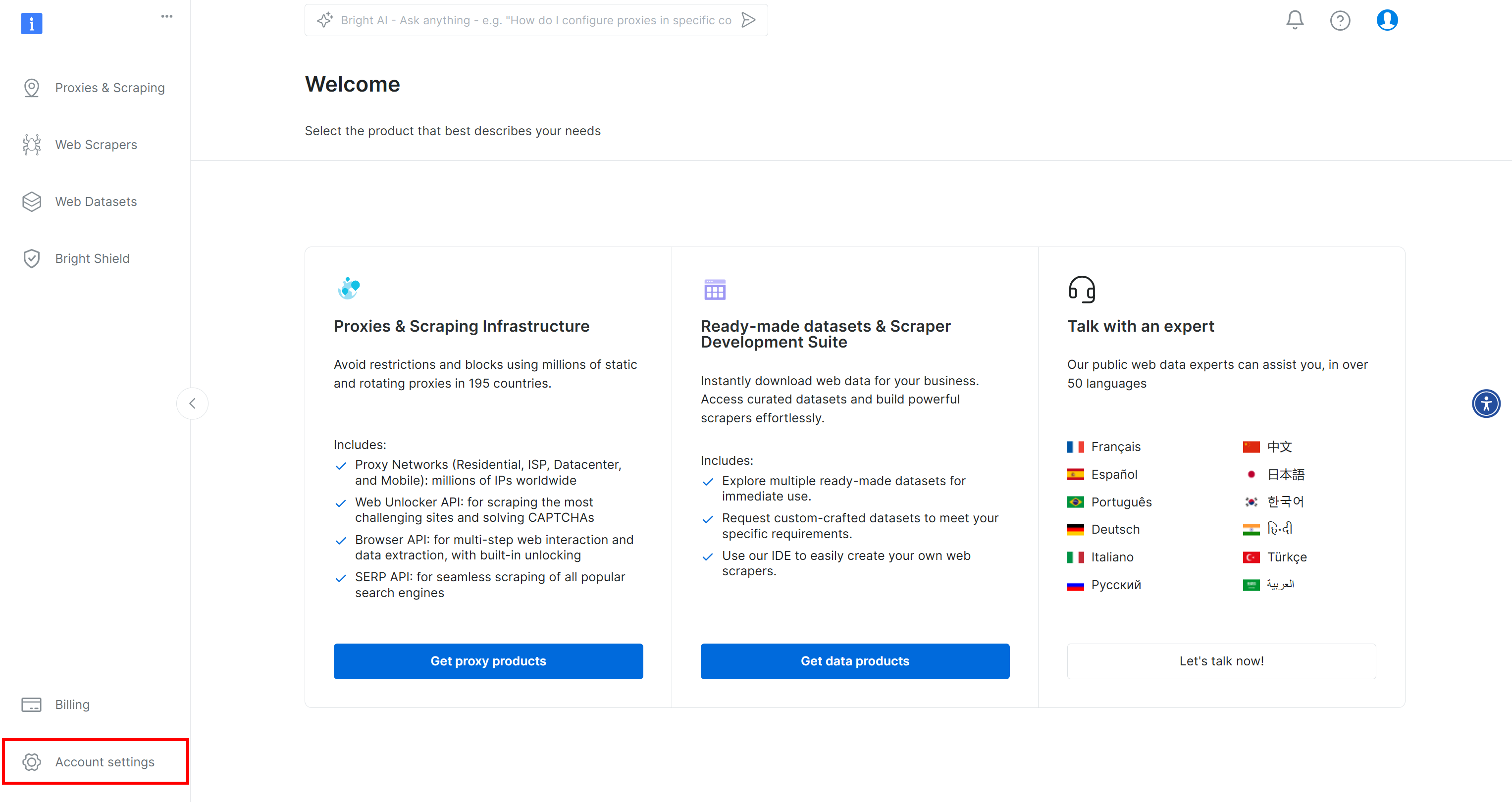
Se ainda não o fez, crie uma conta Bright Data. Após fazer login, você será direcionado para o painel da sua conta. A partir daqui, clique no botão “Configurações da conta” localizado na parte inferior esquerda:
Na página “Configurações da conta”, se você já criou um token da API da Bright Data, clique em “…” e selecione a opção “Copiar token”:
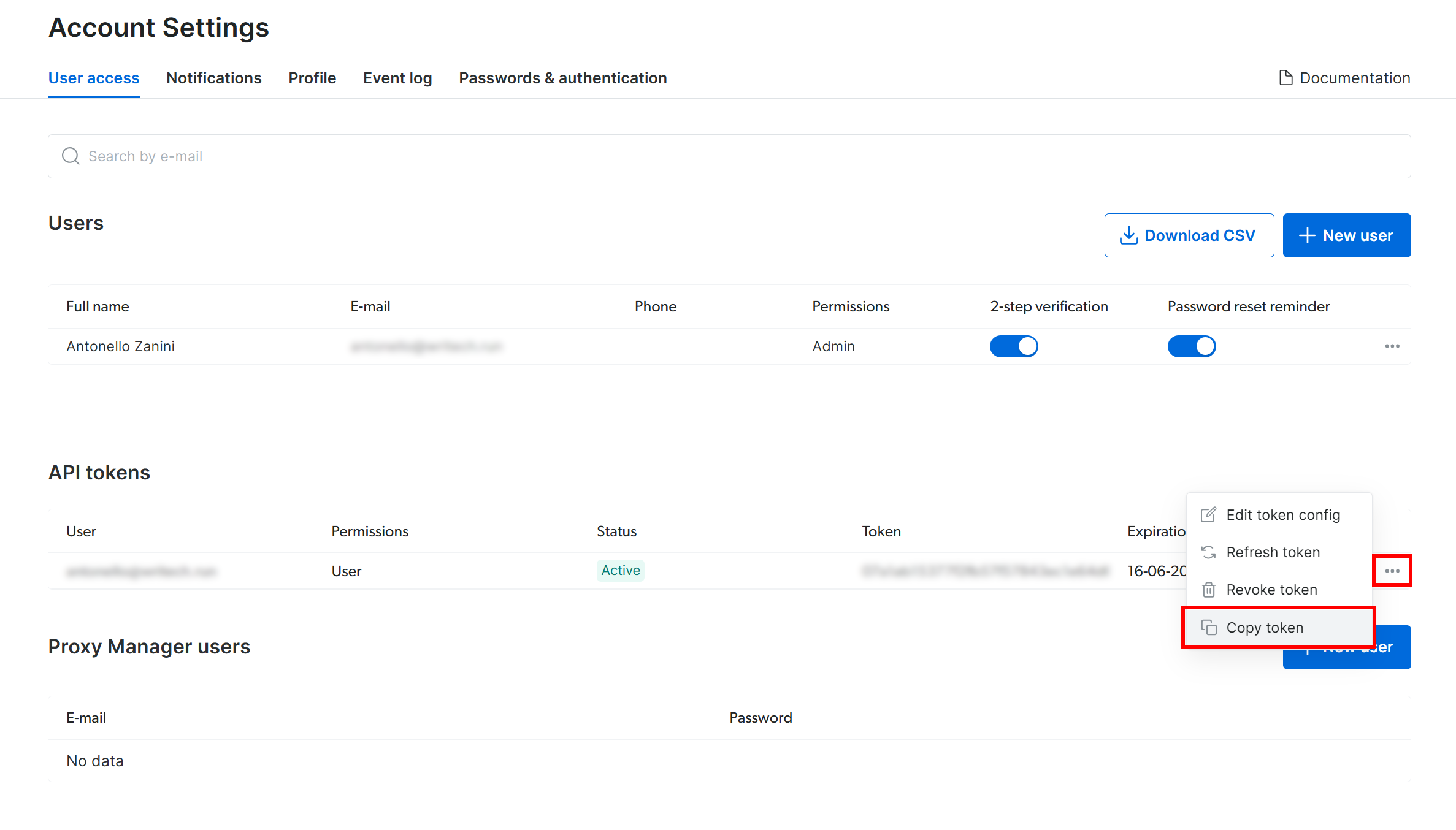
Caso contrário, clique no botão “Adicionar token”:
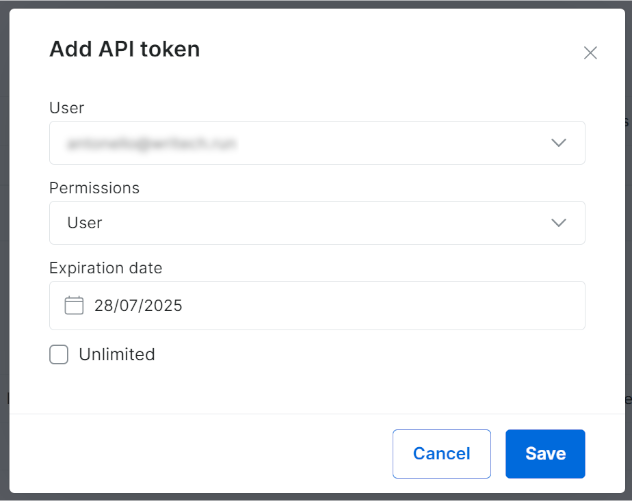
A seguinte janela modal será exibida. Configure seu token API da Bright Data e pressione o botão “Salvar”:
Você receberá seu novo token API:
Copie o valor da sua chave API Bright Data.
No seu arquivo .env, armazene essas informações como uma variável de ambiente BRIGHT_DATA_API_KEY:
BRIGHT_DATA_API_KEY="<SUA_CHAVE_DA_API_BRIGHT_DATA>"Substitua <SUA_CHAVE_DA_API_BRIGHT_DATA> pelo valor que você copiou do modal/tabela.
Agora, em script.py, importe langchain_brightdata:
from langchain_brightdata import BrightDataWebScraperAPINenhuma outra ação é necessária, pois langchain_brightdata tenta automaticamente ler a chave da API Bright Data da variável de ambiente BRIGHT_DATA_API_KEY.
Pronto! Agora você pode usar a API Web Scraper no LangChain.
Etapa 5: Use o Bright Data para Scraping de dados
O langchain_brightdata oferece suporte à integração com a API Web Scraper da Bright Data por meio da classe BrightDataWebScraperAPI.
Abaixo está uma visão geral de como essa classe funciona:
- Ela faz uma solicitação síncrona à API de Scraping de dados configurada, aceitando a URL da página a ser raspada.
- Uma tarefa de scraping baseada em nuvem é iniciada para recuperar e realizar o Parsing dos dados da URL especificada.
- A biblioteca aguarda o término da tarefa de scraping e, em seguida, retorna os dados coletados no formato JSON.
Para integrar o Scraping de dados ao seu fluxo de trabalho LangChain, defina uma função reutilizável com o seguinte código:
def get_scraped_data(url, dataset_type):
# Inicialize a classe de integração da API LangChain Bright Data Scraper
web_scraper_api = BrightDataWebScraperAPI()
# Recuperar os dados de interesse conectando-se à API Web Scraper
results = web_scraper_api.invoke({
"url": url,
"dataset_type": dataset_type
})
return resultsA função aceita os seguintes argumentos:
url: A URL da página da qual os dados serão recuperados.dataset_type: especifica o tipo de API Web Scraper a ser usado para extrair dados da página. Por exemplo,"linkedin_person_profile"instrui a API Web Scraper a extrair dados da URL do perfil público do LinkedIn fornecida.
Neste exemplo, chame-a da seguinte forma:
url = "https://linkedin.com/in/antonello-zanini"
scraped_data = get_scraped_data(url, "linkedin_person_profile")scraped_data conterá dados como estes:
{
"input": {
"url": "https://linkedin.com/in/antonello-zanini"
},
"id": "antonello-zanini",
"name": "Antonello Zanini",
# Omitido por brevidade...
"about": "Sou engenheiro de software freelancer, editor técnico e redator técnico com centenas...",
"current_company": {
"name": "Freelance"
},
"current_company_name": "Freelance",
# Omitido por motivos de concisão...
"idiomas": [
{
"título": "Italiano",
"subtítulo": "Proficiência nativa ou bilíngue"
},
{
"título": "Inglês",
"subtítulo": "Proficiência profissional total"
},
{
“title”: “Espanhol”,
“subtitle”: “Proficiência profissional completa”
}
],
“recommendations_count”: 32,
“recommendations”: [
# Omitido por motivos de concisão...
],
“posts”: [
# Omitido por motivos de concisão...
],
"activity": [
# Omitido por motivos de concisão...
],
# Omitido por motivos de concisão...
}Em detalhes, ele armazena todas as informações disponíveis na versão pública da página do perfil do LinkedIn alvo, mas estruturadas no formato JSON. Para obter esses dados, a API Web Scraper contornou todos os mecanismos anti-bot ou anti-scraping para você.
Incrível! Você acabou de aprender a usar a API Scraper da Bright Data Web para Scraping de dados no LangChain.
Etapa 6: Prepare-se para usar os modelos OpenAI
Este exemplo depende dos modelos OpenAI para integração LLM no LangChain. Para usar esses modelos, você deve configurar uma chave API OpenAI em suas variáveis de ambiente.
Portanto, adicione a seguinte linha ao seu arquivo .env:
OPENAI_API_KEY="<SUA_CHAVE_API_OPEN>"Substitua <SUA_CHAVE_API_OPENAI> pelo valor da sua chave API OpenAI. Se você não sabe como obter uma, siga o guia oficial.
Agora, em script.py, importe langchain_openai desta forma:
from langchain_openai import ChatOpenAIVocê não precisa fazer mais nada. O langchain_openai procurará automaticamente sua chave API OpenAI na variável de ambiente OPENAI_API_KEY.
Ótimo! É hora de usar os modelos OpenAI em seu script de scraping LangChain.
Etapa 7: Gere o prompt LLM
Defina uma variável f-string que receba os dados coletados e gere um prompt para o LLM. Neste caso, o prompt inclui sua solicitação de RH e incorpora os dados coletados do candidato:
prompt = f"""
“Você acha que este candidato é adequado para uma vaga remota de engenheiro de software? Por quê?
Responda em no máximo 150 palavras.
CANDIDATO:
'{scraped_data}'
"""Neste exemplo, você está criando um fluxo de trabalho de IA para consultoria de RH usando o LangChain. Graças à flexibilidade da API Web Scraper (que suporta mais de 120 domínios) combinada com LLMs, você pode facilmente adaptar essa abordagem para alimentar uma ampla gama de outros fluxos de trabalho do LangChain.
💡 Ideia: para obter ainda mais flexibilidade, considere ler o prompt do arquivo .env.
No exemplo atual, o prompt completo será:
Você acha que este candidato é adequado para uma vaga remota de engenheiro de software? Por quê?
Responda em no máximo 150 palavras.
CANDIDATO:
'{
"input": {
"url": "https://linkedin.com/in/antonello-zanini"
},
"id": "antonello-zanini",
"name": "Antonello Zanini",
// omitido por brevidade...
"about": "Sou engenheiro de software freelancer, editor técnico e redator técnico com centenas...",
},
[omitido por brevidade...]'Se você passar isso para o ChatGPT, deverá obter o resultado desejado:
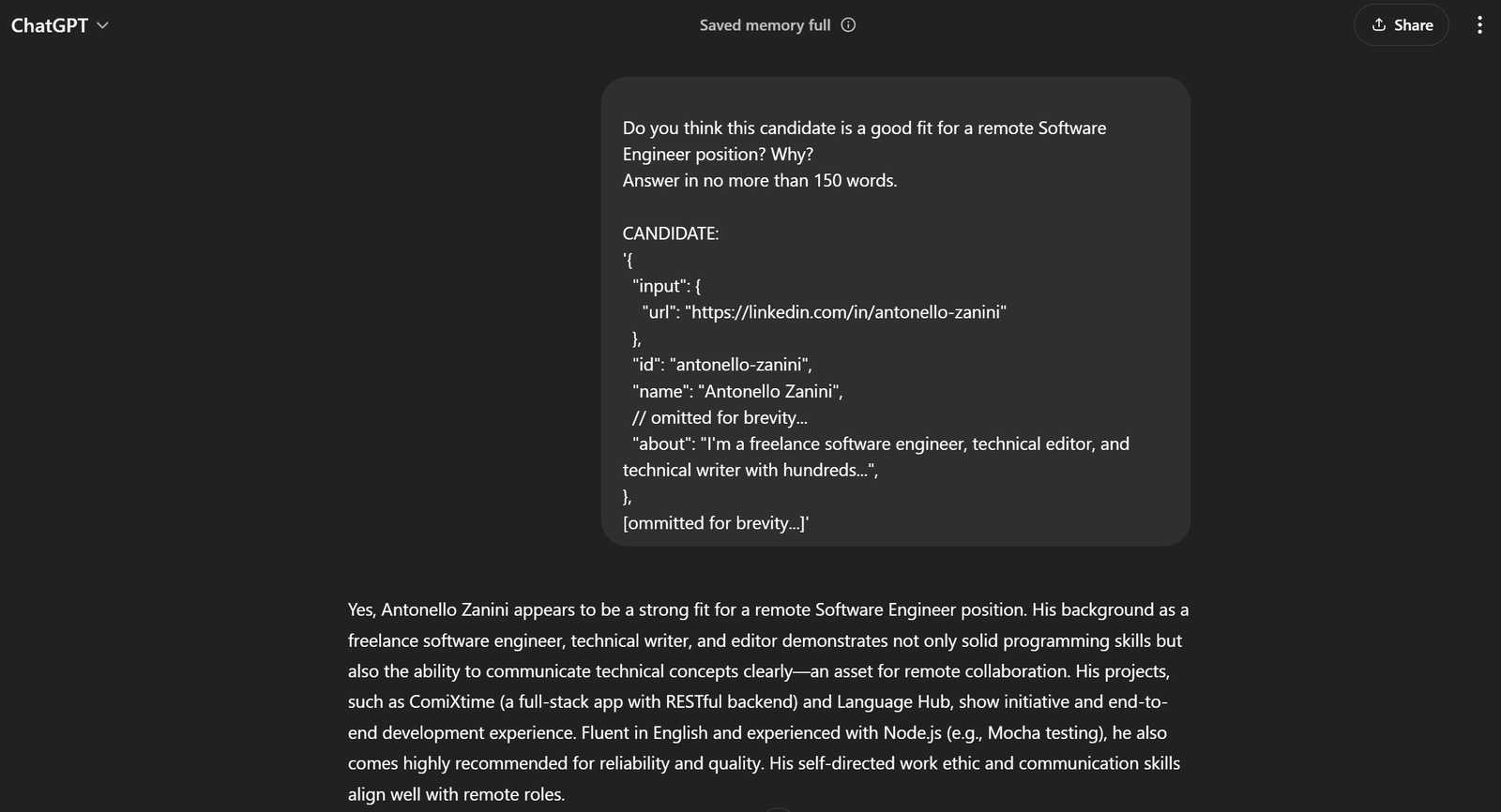
Isso é suficiente para dizer que o prompt funciona perfeitamente!
Etapa 8: Integrar o OpenAI
Passe o prompt que você gerou anteriormente para um objeto ChatOpenAI LangChain configurado no modelo de IA GPT-4o mini:
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)No final do processamento da IA, response.content deve conter um resultado semelhante à avaliação gerada pelo ChatGPT na etapa anterior. Acesse essa resposta de texto com:
avaliação = response.contentUau! A lógica de Scraping de dados do LangChain está completa.
Etapa 9: Exporte os dados processados pela IA
Agora, você só precisa exportar os dados gerados pelo modelo de IA selecionado via LangChain para um formato legível por humanos, como um arquivo JSON.
Primeiro, inicialize um dicionário com os dados desejados. Em seguida, exporte e salve-o como um arquivo JSON, conforme mostrado abaixo:
export_data = {
"url": url,
"evaluation": evaluation
}
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)Importe json da biblioteca padrão do Python:
import jsonParabéns! Seu script está pronto.
Etapa 10: adicione alguns registros
O processo de scraping de dados usando o Scraping de dados IA e análise ChatGPT pode levar algum tempo. Isso é normal devido à sobrecarga envolvida no scraping e no processamento de dados de serviços de terceiros. Portanto, é uma boa prática incluir registros para acompanhar o progresso do script.
Faça isso adicionando instruções de impressão nas etapas principais do script, como segue:
url = "https://linkedin.com/in/antonello-zanini"
print(f"Raspando dados com a API Web Scraper de {url}...")
scraped_data = get_scraped_data(url, "linkedin_person_profile")
print("Dados raspados com sucesso")
print("Criando o prompt de IA...")
prompt = f"""
"Você acha que este candidato é adequado para uma vaga remota de engenheiro de software? Por quê?
Responda em no máximo 150 palavras.
CANDIDATO:
'{scraped_data}'
"""
print("Prompt criadon")
print("Enviando prompt para o ChatGPT...")
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)
evaluation = response.content
print("Resposta recebida do ChatGPT")
print("Exportando dados para JSON"...)
export_data = {
"url": url,
"evaluation": evaluation
}
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)
print(f"Dados exportados para '{file_name}'")Observe que cada etapa do fluxo de trabalho de Scraping de dados do LangChain é claramente registrada. A execução no terminal agora será muito mais fácil de acompanhar.
Etapa 11: Junte tudo
Seu arquivo script.py final deve conter:
from dotenv import load_dotenv
from langchain_brightdata import BrightDataWebScraperAPI
from langchain_openai import ChatOpenAI
import json
# Carregue as variáveis de ambiente do arquivo .env
load_dotenv()
def get_scraped_data(url, dataset_type):
# Inicialize a classe de integração da API LangChain Bright Data Scraper
web_scraper_api = BrightDataWebScraperAPI()
# Recuperar os dados de interesse conectando-se à API Web Scraper
results = web_scraper_api.invoke({
"url": url,
"dataset_type": dataset_type
})
return results
# Recuperar o conteúdo da página da web fornecida
url = "https://linkedin.com/in/antonello-zanini"
print(f"Retirados dados com a API Web Scraper de {url}...")
# Use a API Web Scraper para obter os dados retirados
scraped_data = get_scraped_data(url, "linkedin_person_profile")
imprimir("Dados coletados com sucesso")
imprimir("Criando o prompt de IA...")
# Definir o prompt usando os dados coletados como contexto
prompt = f"""
"Você acha que este candidato é adequado para uma vaga remota de engenheiro de software? Por quê?
Responda em no máximo 150 palavras.
CANDIDATO:
'{scraped_data}'
"""
print("Prompt criado")
# Solicite ao ChatGPT para realizar a tarefa especificada no prompt
print("Enviando prompt para o ChatGPT...")
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)
# Obter o resultado da IA
avaliação = resposta.conteúdo
imprimir("Resposta recebida do ChatGPTn")
imprimir("Exportando dados para JSON...")
# Exportar os dados produzidos para JSON
exportar_dados = {
"url": url,
"avaliação": avaliação
}
# Gravar o dicionário de saída no arquivo JSON
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)
print(f"Dados exportados para '{file_name}'")Dá para acreditar? Em cerca de 50 linhas de código, você acabou de criar um script de Scraping de dados LangChain baseado em IA.
Verifique se ele funciona com este comando:
python3 script.pyOu, no Windows:
python script.pyA saída no terminal deve ser:
Raspando dados com a API Web Scraper de https://linkedin.com/in/antonello-zanini...
Dados raspados com sucesso
Criando o prompt de IA...
Prompt criado
Enviando prompt para o ChatGPT...
Resposta recebida do ChatGPT
Exportando dados para JSON...
Dados exportados para 'analysis.json'Abra o arquivo analysis.json que apareceu no diretório do projeto e você deverá ver algo assim:
{
"url": "https://linkedin.com/in/antonello-zanini",
"evaluation": "Antonello Zanini parece ser um forte candidato para uma vaga remota de engenheiro de software. Sua experiência como engenheiro de software freelancer indica adaptabilidade e automotivação, características cruciais para o trabalho remoto. Sua experiência em redação técnica e editorial sugere fortes habilidades de comunicação, essenciais para colaborar com equipes remotas. Além disso, seu conhecimento diversificado em programação, evidenciado por publicações sobre testes de unidade e bundlers JavaScript, reforça sua expertise técnica. Ele recebeu feedback positivo significativo de clientes, enfatizando sua confiabilidade e clareza nos resultados, características essenciais para uma colaboração remota eficaz. Além disso, suas habilidades multilíngues em italiano, inglês e espanhol podem melhorar a comunicação em equipes internacionais diversificadas. No geral, a combinação de proficiência técnica, habilidades de comunicação e recomendações positivas de Antonello o tornam uma excelente opção para uma posição remota.
}Et voilà! O fluxo de trabalho do HR LangChain, enriquecido com dados em tempo real, está agora completo.
Conclusão
Neste tutorial, você descobriu por que o Scraping de dados é um método eficaz para coletar dados para seus fluxos de trabalho de IA e como analisar esses dados usando o LangChain.
Especificamente, você criou um script de Scraping de dados LangChain baseado em Python para extrair dados de uma página de perfil do LinkedIn e processá-los usando APIs OpenAI. Embora este fluxo de trabalho LangChain seja ideal para dar suporte a tarefas de RH, o código mostrado pode ser facilmente estendido para outros fluxos de trabalho e cenários.
Os principais desafios do Scraping de dados no LangChain são:
- Os sites online mudam frequentemente as estruturas das suas páginas.
- Muitos sites implementam medidas avançadas contra bots.
- Recuperar grandes volumes de dados simultaneamente pode ser complexo e caro.
A API Web Scraper da Bright Data representa uma solução eficaz para extrair dados dos principais sites, superando facilmente esses desafios. Graças à sua integração perfeita com o LangChain, é uma ferramenta inestimável para dar suporte a aplicativos RAG e outras soluções baseadas no LangChain.
Não deixe de explorar nossas ofertas adicionais para IA e LLM.
Inscreva-se agora para descobrir quais dos serviços de Proxy ou produtos de scraping da Bright Data melhor atendem às suas necessidades. Comece com um teste grátis!




