

Neste tutorial, você aprenderá:
- Por que faz sentido recuperar dados do Bilibili por meio de Scraping de dados.
- Que tipos de dados você pode extrair do Bilibili.
- Como construir um pipeline de scraping e download do Bilibili para coletar dados de vídeo para treinamento de IA (e outros casos de uso).
- Por que um Scraper dedicado ao Bilibili é a melhor opção para aplicativos de nível empresarial prontos para produção.
Evite a complexidade:o Bilibili Scraper da Bright Dataoferece dados de vídeo prontos para uso em escala empresarial, com bypass anti-bot integrado e 99,99% de tempo de atividade.
Vamos mergulhar no assunto!
Por que fazer scraping do Bilibili: possíveis casos de uso
O Bilibili é uma plataforma de vídeo com sede em Xangai, frequentemente descrita como o “YouTube da China”. Lançada em 2009, ela se tornou uma potência da Geração Z, com mais de 294 milhões de usuários ativos mensais e mais de 3 bilhões de visualizações de vídeo diárias.
Originalmente centrada em ACG (Anime, Comics e Games), agora abrange tecnologia, educação, estilo de vida, música, esportes eletrônicos e transmissão ao vivo. O Bilibili é conhecido por seus comentários em tempo real “danmu” e sua comunidade altamente engajada. Ele combina conteúdo gerado pelo usuário, cultura de influenciadores, jogos e publicidade no mesmo ecossistema digital.
Dado o rápido crescimento do Bilibili, obter acesso aos dados da plataforma oferece suporte a muitos casos de uso, tais como:
- Treinamento de IA em vídeo: Conjuntos de dados de vídeo em grande escala do Bilibili podem alimentar visão computacional, reconhecimento de fala, LLMs multimodais, sistemas de recomendação e modelos de moderação de conteúdo. Isso é possível graças a metadados ricos, transcrições, sinais de engajamento e conteúdo audiovisual bruto.
- Inteligência de tendências e conteúdo: analise categorias, tags, visualizações e métricas de engajamento para identificar tópicos emergentes, criadores em rápido crescimento e formatos virais entre o público da Geração Z e comunidades impulsionadas por ACG.
- Análise de criadores e influenciadores: acompanhe o desempenho dos uploaders, o crescimento dos seguidores, as taxas de engajamento e a frequência de publicação para avaliar o impacto dos KOL (Key Opinion Leader) e otimizar as estratégias de marketing de influência na China.
- Análise do sentimento do público: explore danmu (comentários rápidos) e comentários padrão para entender as reações dos espectadores, o tom emocional, as referências culturais e os padrões de feedback em tempo real em grande escala.
- Benchmarking competitivo: compare canais de marcas, campanhas patrocinadas e líderes de categoria monitorando visualizações, interações e estratégias de conteúdo em nichos semelhantes.
- Pesquisa de entrada no mercado e localização: avalie as preferências de conteúdo, o uso da linguagem e os temas em alta para adaptar produtos, campanhas e mensagens ao público nativo digital da China.
Dados que você pode recuperar do Bilibili
Ao coletar dados do Bilibili, existem vários campos de dados que você pode segmentar. Eles dependem dos tipos específicos de páginas das quais você está coletando e de seus objetivos gerais. Portanto, existem várias categorias de dados interessantes do Bilibili que valem a pena explorar.
Metadados de vídeo
Ao selecionar um vídeo específico do Bilibili, você pode coletar:
- Informações básicas: título, descrição, URL da imagem de capa, ID do vídeo, duração do vídeo, etc.
- Detalhes do upload: data e hora da publicação e categoria/partição (por exemplo, “Anime”, “Tecnologia” ou “Música”).
- Categorização: tags, palavras-chave e se o vídeo está marcado como conteúdo original ou reimpressão.
- Estatísticas de engajamento: total de visualizações, curtidas, moedas, favoritos e compartilhamentos.
- Comentários: os comentários exibidos diretamente no vídeo. Isso inclui o texto do comentário, data e hora, cor, tamanho da fonte e modo de exibição.
- Legendas: transcrições geradas pela IA ou fornecidas pelo usuário que fez o upload.
Perfis de usuários e criadores
Ao focar em uma página de criador do Bilibili, você pode extrair:
- Informações de identidade: nome de usuário, ID do usuário, gênero, foto do perfil, etc.
- Métricas sociais: número de seguidores, número de pessoas seguidas e total de curtidas recebidas em todos os vídeos.
- Detalhes pessoais: biografia do usuário, data de nascimento e nível da conta.
- Status da conta: selo de verificação (por exemplo, “Músico Oficial”) e nível de assinatura (por exemplo, VIP/Membro Big).
- Lista de trabalhos: todos os vídeos publicados publicamente por um criador específico.
Dados de pesquisa e descoberta
Você também pode usar o sistema de pesquisa do Bilibili para recuperar:
- Resultados de pesquisa: listas de vídeos, usuários ou transmissões ao vivo que correspondam a palavras-chave específicas.
- Dados de tendências: palavras-chave de pesquisa populares e classificações diárias/semanais.
- Informações de transmissão ao vivo: ID da sala, título da transmissão, status ao vivo e contagem de espectadores simultâneos (índice de popularidade).
Criação de um Scraper do Bilibili e um pipeline de download de vídeos em Python: um guia passo a passo
Nesta seção guiada, você aprenderá como extrair metadados de vídeos do Bilibili da página da categoria “Tecnologia”: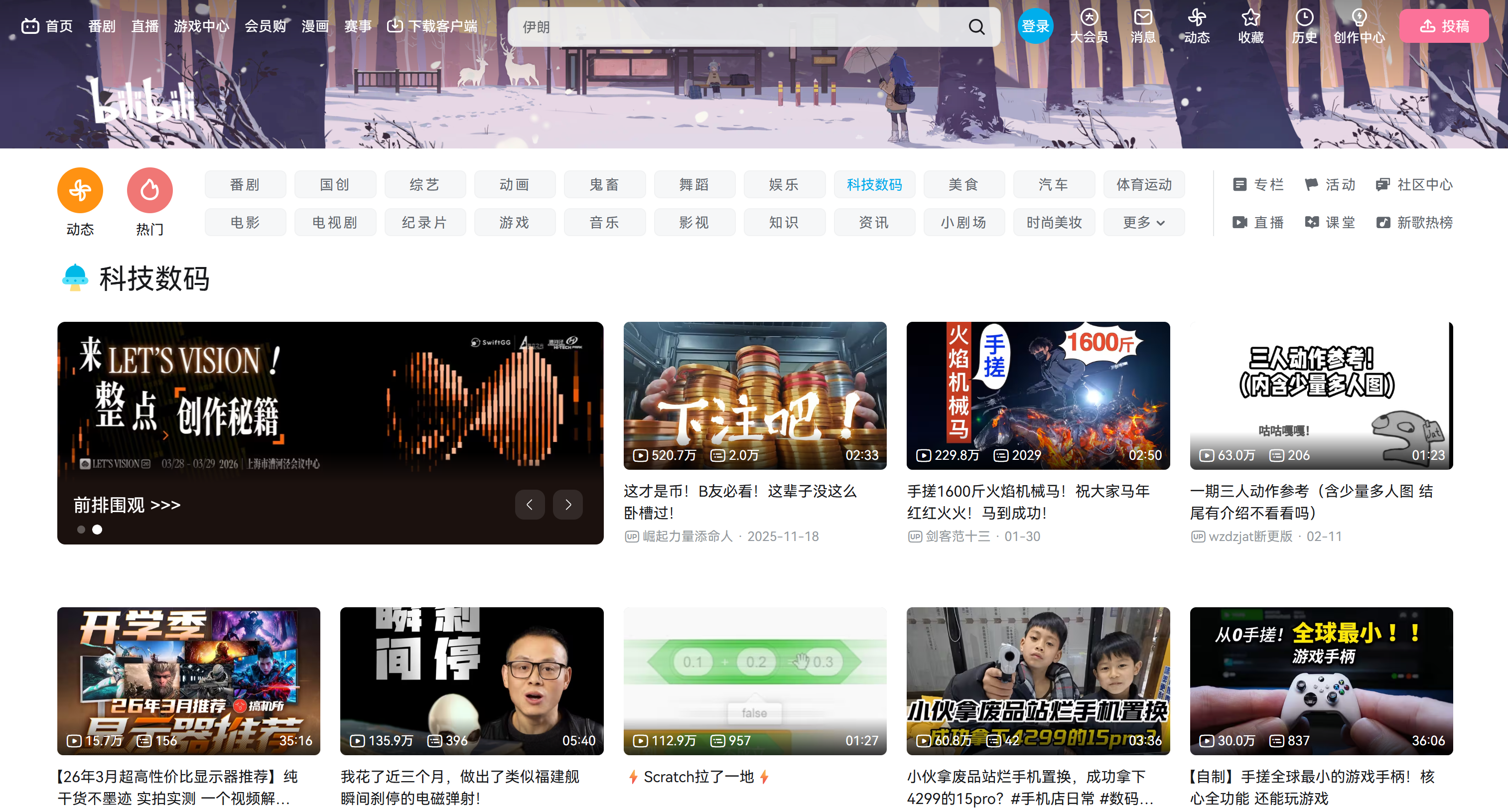
Observe que este é apenas um exemplo. A mesma lógica pode ser aplicada a qualquer outra página de categoria, incluindo a página inicial principal.
Usando as URLs dos vídeos extraídas dessa página, você criará um segundo script para baixá-los um por um. Com os arquivos de vídeo baixados, você finalmente poderá alimentá-los diretamente em seus pipelines de treinamento de IA/ML.
Siga as instruções abaixo!
Pré-requisitos
Para seguir este tutorial, certifique-se de ter:
- Python 3.10 instalado localmente.
- FFmpeg instalado localmente.
- Familiaridade com o funcionamento da automação do navegador.
- Conhecimento básico de como
o yt-dlpfunciona.
Verifique se o FFmpeg está instalado em sua máquina com este comando:
ffmpeg -versionVocê deverá ver algo semelhante a isto: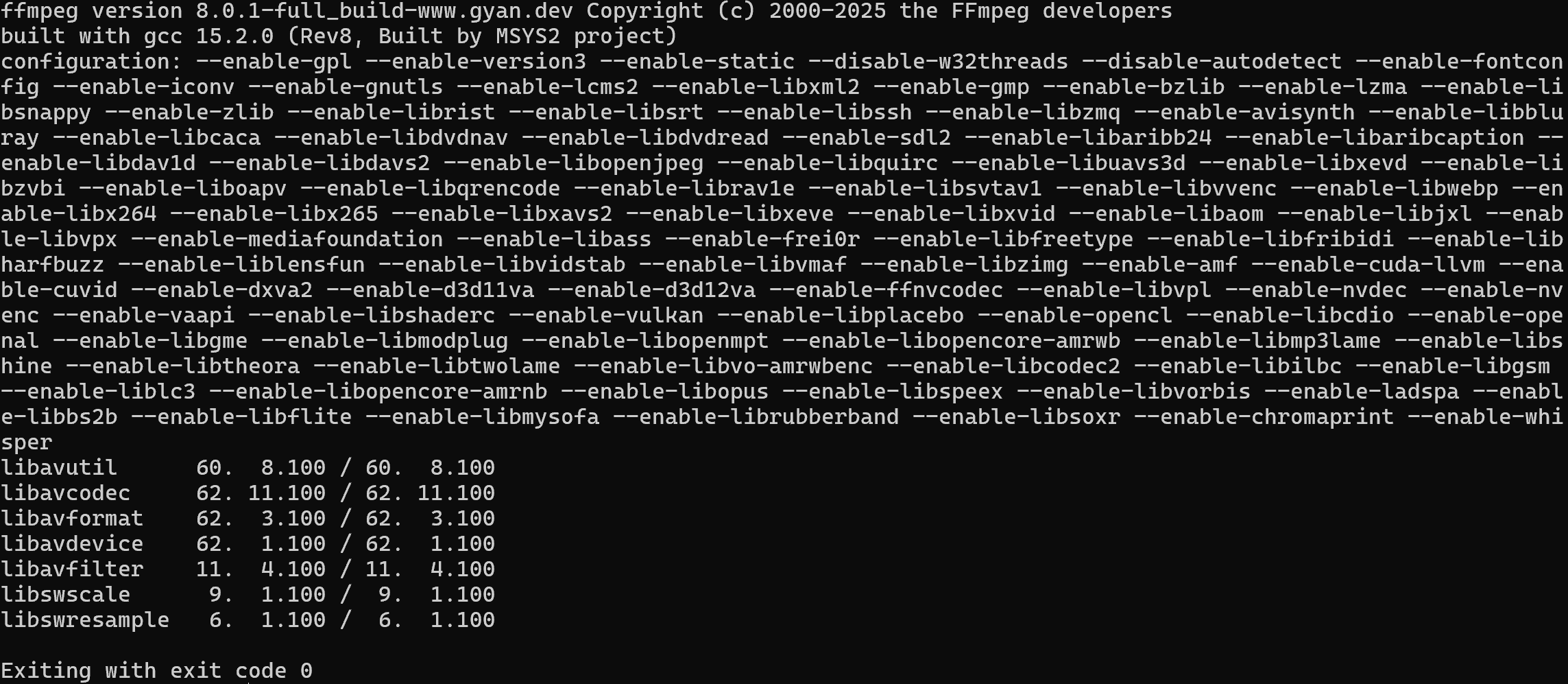
Se você receber um erro, instale o FFmpeg seguindo o guia de instalação oficial para o seu sistema operacional.
Etapa 0: familiarize-se com o Bilibili
Antes de escrever qualquer código, dedique algum tempo explorando o site de destino. Você precisa entender se ele é estático ou dinâmico, pois seu plano de Scraping de dados depende disso.
Se o site for estático, um cliente HTTP simples e uma abordagem de Parsing de HTML podem ser suficientes. Se for dinâmico, você precisará de uma ferramenta de automação de navegador. Saiba mais em nosso guia sobre conteúdo estático x dinâmico para Scraping de dados.
Visite a página de destino no seu navegador e comece a interagir com ela. Observe como a página usa um padrão de interface de usuário de rolagem infinita: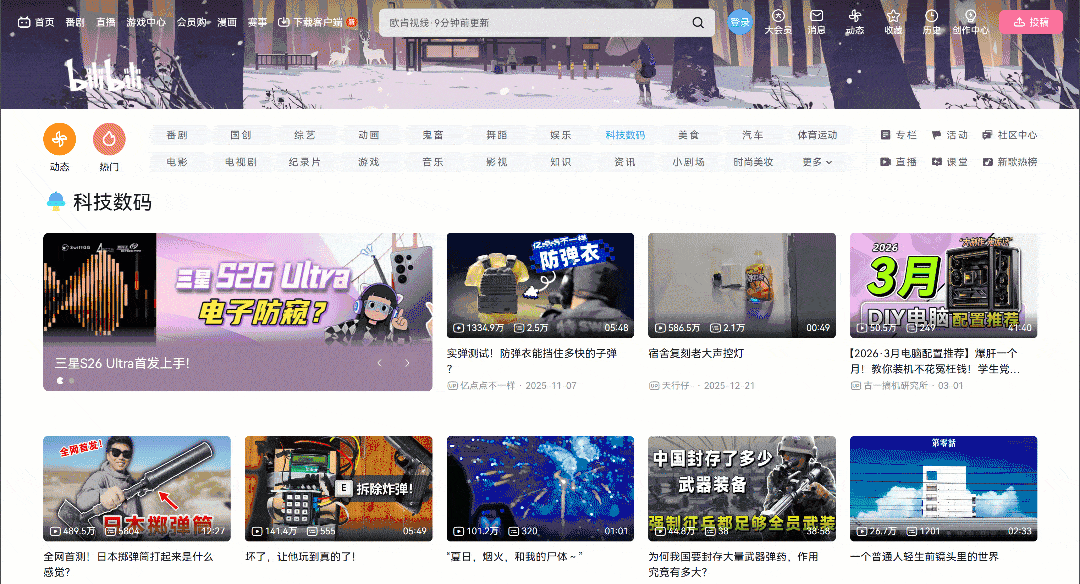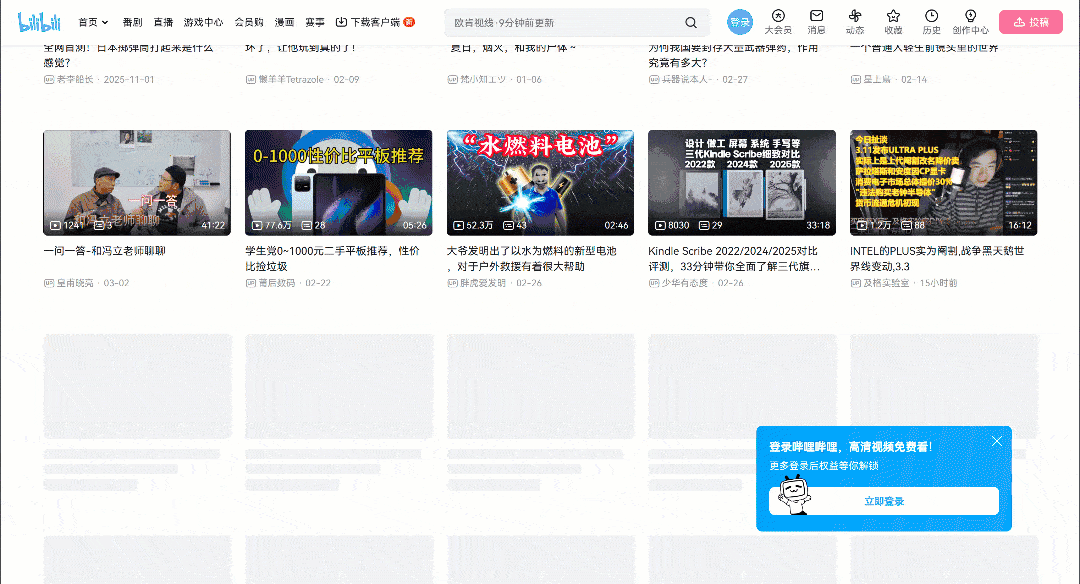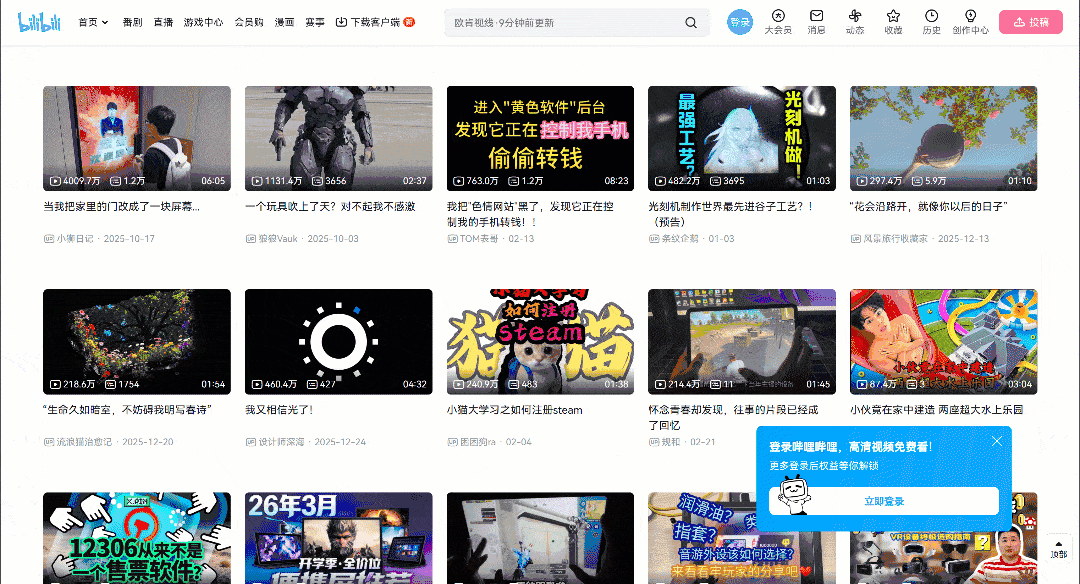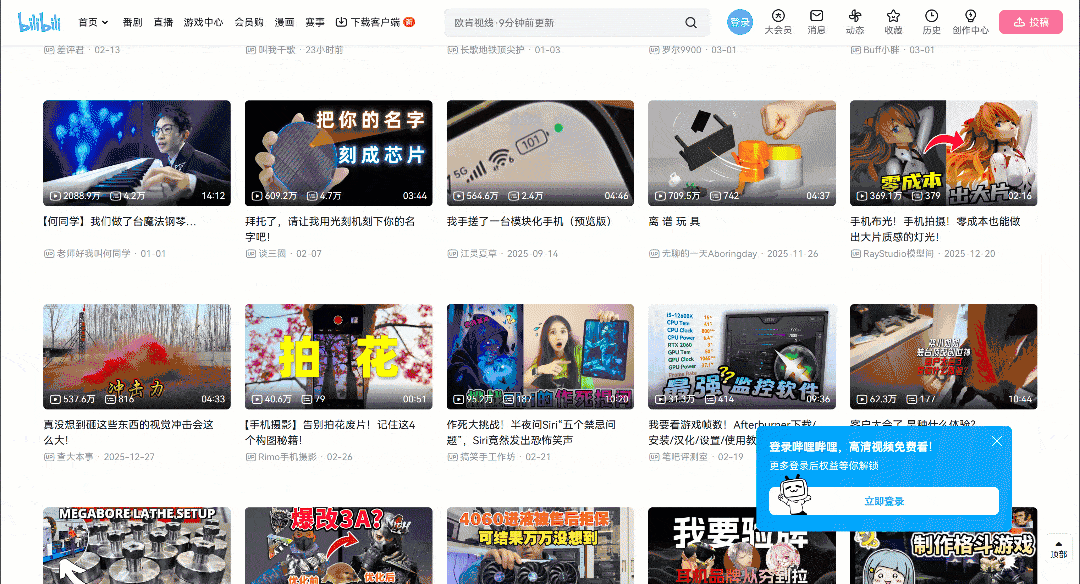
À medida que você rola para baixo, novos cartões de vídeo são carregados automaticamente. Esse comportamento é um indicador de que o site é dinâmico. Mais especificamente, ele depende do JavaScript para buscar e renderizar novos dados com base na interação do usuário.
Por causa disso, uma simples solicitação HTTP não será suficiente. Você precisa de uma ferramenta de automação do navegador para renderizar e extrair o conteúdo corretamente. Neste tutorial, usaremos o Playwright, mas ferramentas como Selenium, SeleniumBase ou NODRIVER também funcionariam.
Etapa 1: Configure seu projeto Playwright
Comece iniciando seu terminal e criando um novo diretório para o seu Scraper Bilibili:
mkdir bilibili-ScraperVá para o diretório do projeto e crie um ambiente virtual Python dentro dele:
cd bilibili-Scraper
python -m venv .venvEm seguida, carregue a pasta do projeto em seu IDE Python preferido. O Visual Studio Code com a extensão Python e o PyCharm Community Edition são boas opções.
Crie um novo arquivo chamado scraper.py na raiz do diretório do projeto, que deve ficar assim:
bilibili-Scraper/
├── .venv/
└── scraper.py # <-----------No terminal integrado do seu IDE, ative o ambiente virtual. No Linux/macOS, execute:
source .venv/bin/activateDe forma equivalente, no Windows, execute:
.venv/Scripts/activateCom o ambiente virtual ativado, instale o playwright com:
pip install playwrightConclua a instalação baixando os binários necessários do navegador:
python -m playwright installAgora, adicione a seguinte configuração básica do Playwright ao Scraper.py:
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
# Inicie uma instância controlada do Chromium no modo headful
browser = await p.chromium.launch(headless=False) # Defina como True na produção
context = await browser.new_context()
page = await context.new_page()
# Lógica de scraping...
# Feche o navegador e libere seus recursos
await browser.close()
if __name__ == "__main__":
asyncio.run(main())Este trecho inicializa uma instância do navegador Chromium e permite que o Playwright o controle.
Durante o desenvolvimento, é útil manter headless=False para que você possa acompanhar visualmente o que o navegador está fazendo. Em produção, considere definir headless=True para reduzir o uso de recursos e acelerar a execução, ativando o modo headless.
Muito bem! Agora você tem um ambiente Python pronto para o Scraping de dados da web do Bilibili por meio da automação do navegador.
Etapa 2: conecte-se ao site de destino
Use o Playwright para navegar até a página da web de destino, que é a página da categoria “Tecnologia” do Bilibili:
# A página “Tecnologia” do Bilibili
target_bilibili_page = "https://www.bilibili.com/c/tech/"
# Navegue até a página de destino
await page.goto(target_bilibili_page)A função goto() instrui o navegador controlado a visitar a URL especificada e aguardar o carregamento da página.
É isso! Agora você está conectado à página de destino do Bilibili.
O próximo passo é automatizar a interação de rolagem para que novos cartões de vídeo sejam carregados dinamicamente. Quando o conteúdo adicional aparecer, você estará pronto para extrair os dados desses elementos HTML.
Etapa 3: carregar novos cartões de vídeo
Como mencionado anteriormente, a página inicial e as páginas de categorias do Bilibili dependem do padrão de interface do usuário de rolagem infinita. Inicialmente, apenas alguns cartões de vídeo são visíveis. Conforme você rola para baixo, mais conteúdo é carregado dinamicamente via JavaScript.
Especificamente, a página é carregada inicialmente com um número fixo de elementos de cartões de vídeo dentro de um elemento HTML .head-cards: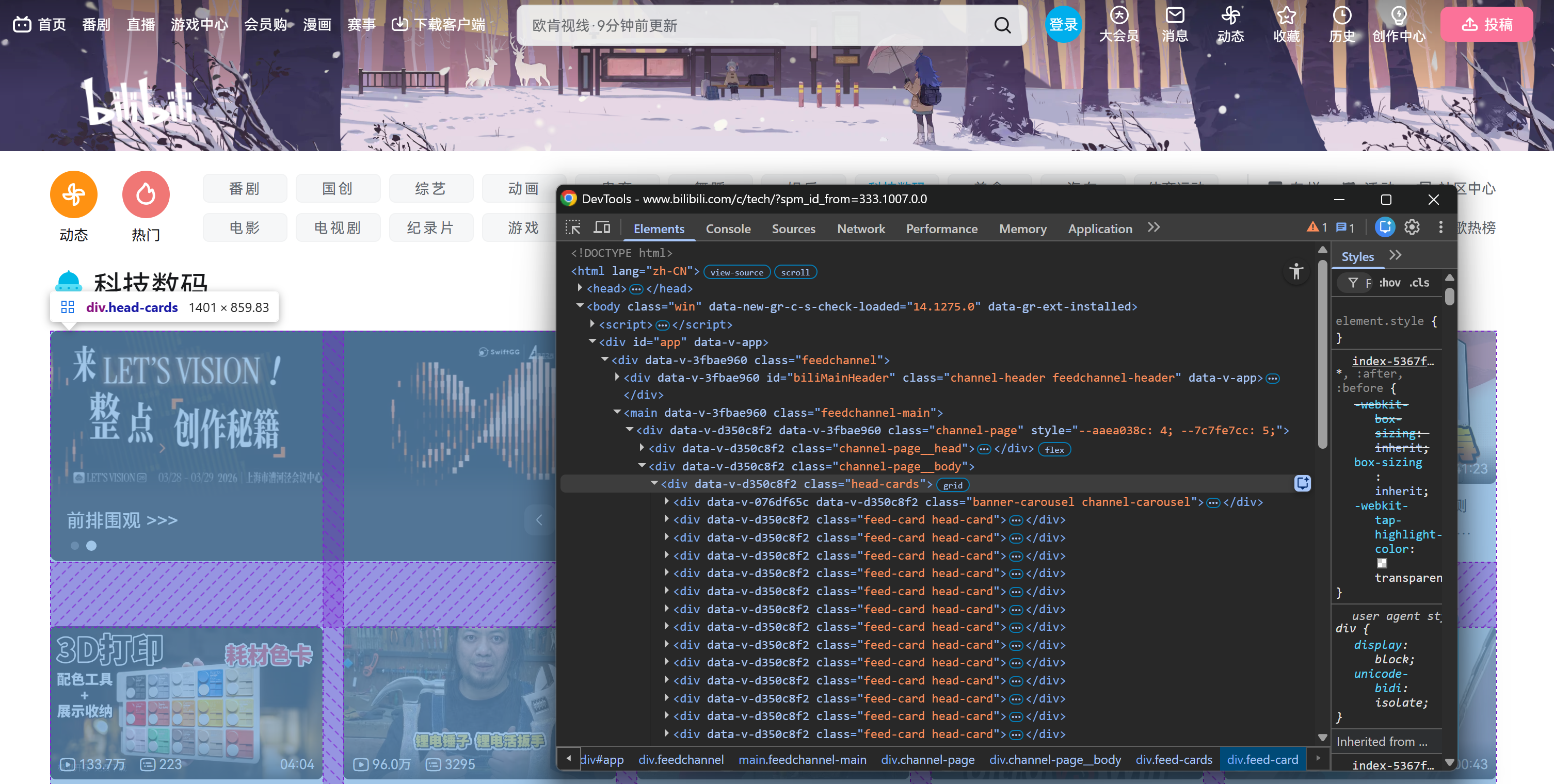
Depois de rolar para baixo, um contêiner .feed-cards é adicionado à página. Essa seção é preenchida dinamicamente com novos cartões de vídeo à medida que você continua rolando: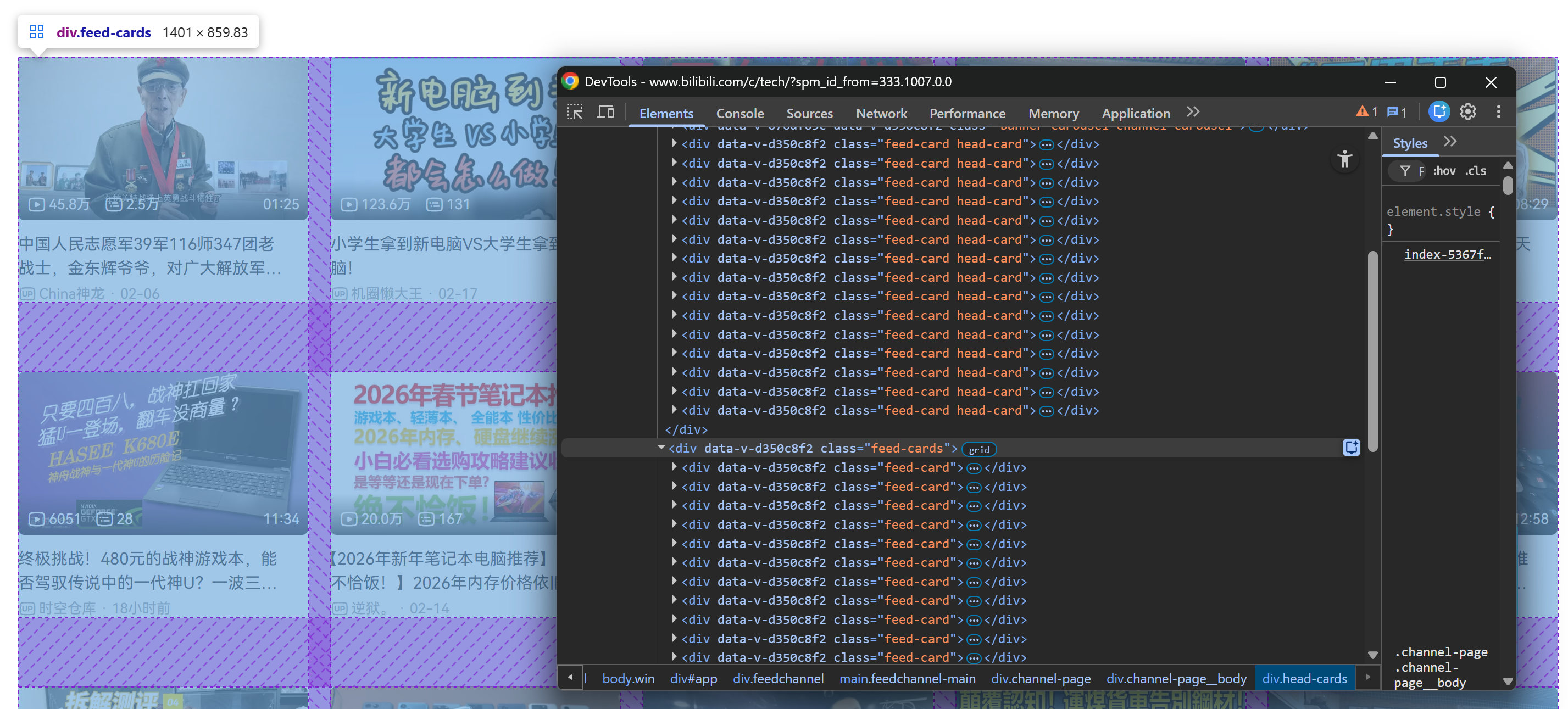
O que importa aqui é que todos os cartões de vídeo (sejam eles estaticamente presentes no carregamento inicial da página ou carregados dinamicamente durante a rolagem) podem ser selecionados por meio deste seletor CSS:
.feed-cardNeste tutorial de scraping do Bilibili, vamos supor que você deseja recuperar pelo menos 50 vídeos. Para isso, você precisa simular várias interações de rolagem. O Playwright não fornece uma API específica para rolagem, então você executará um script JavaScript simples diretamente no contexto da página:
for _ in range(3):
# Permitir carregamento lento
await asyncio.sleep(1)
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# Permitir carregamento lento
await asyncio.sleep(2) Este loop executa window.scrollTo() três vezes, rolando da parte superior para a parte inferior da página em cada iteração. As chamadas asyncio.sleep() são importantes porque:
- Elas fazem com que o comportamento de rolagem pareça mais natural.
- Elas reduzem o risco de acionar mecanismos anti-bot.
- Elas dão tempo para que o conteúdo carregado de forma preguiçosa seja totalmente renderizado antes da próxima rolagem.
Como as placas de vídeo são carregadas dinamicamente, você não pode presumir que elas estarão presentes imediatamente após a rolagem. Em vez disso, você deve esperar explicitamente até que a 50ª placa seja anexada ao DOM. No Playwright, faça isso com:
fiftieth_card = page.locator(".feed-card").nth(49)
await fiftieth_card.wait_for(state="attached")Este código cria um localizador Playwright para o 50º elemento .feed-card (nth(49) porque a indexação começa em 0). Em seguida, ele espera até que esse elemento seja anexado ao DOM com wait_for().
Agora, se você executar o script no modo headful (headless=False), verá o navegador rolando autonomamente três vezes: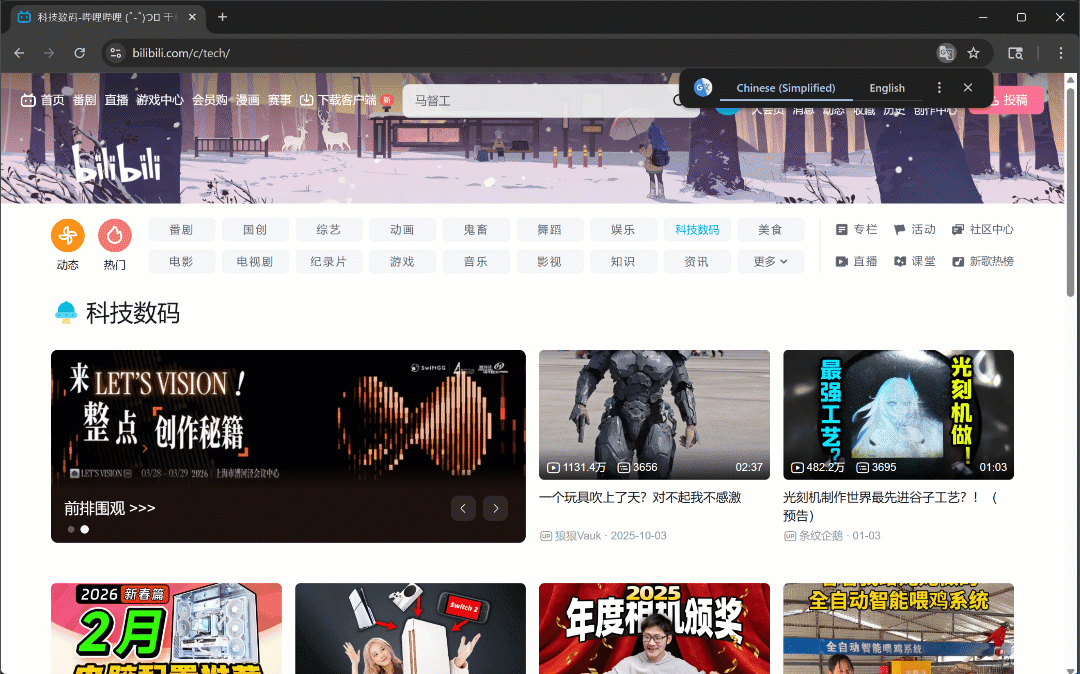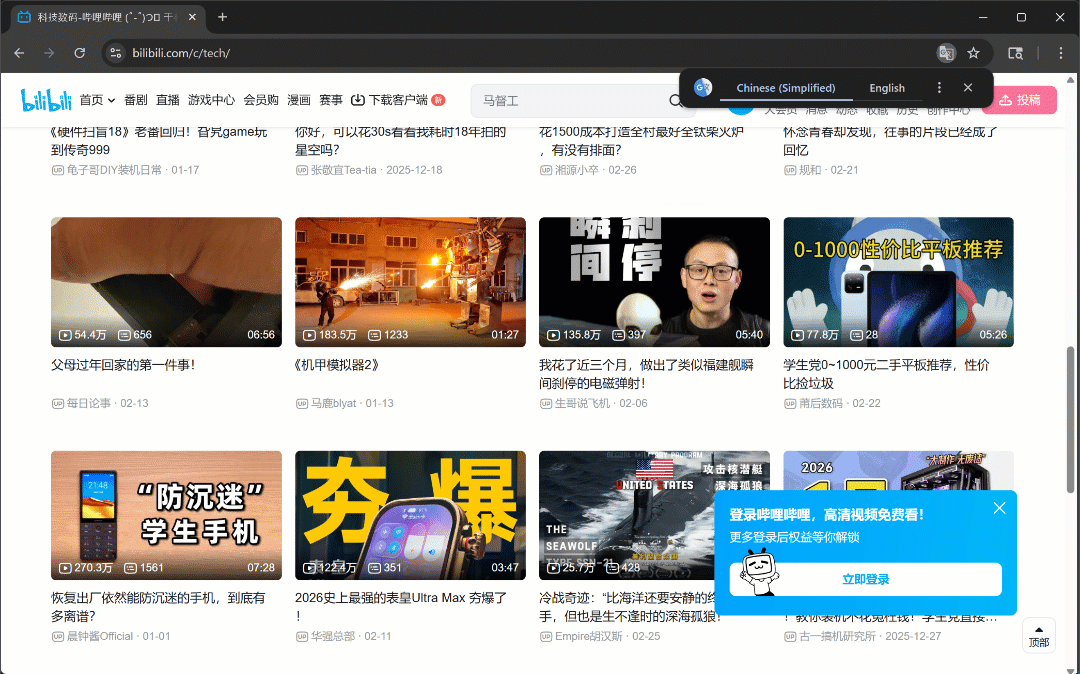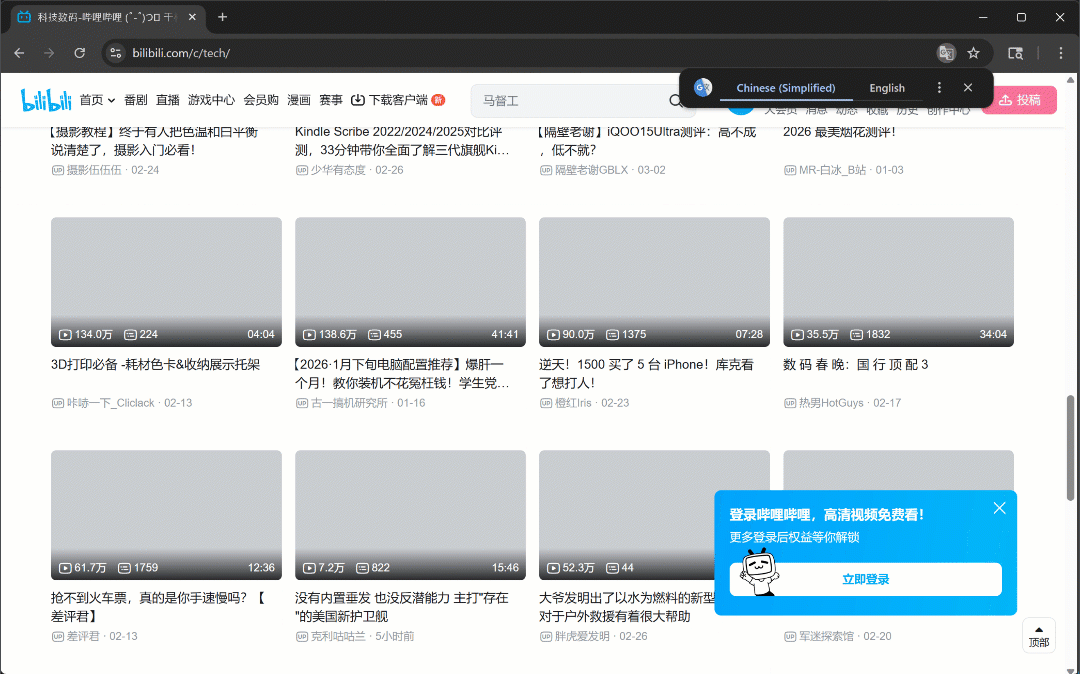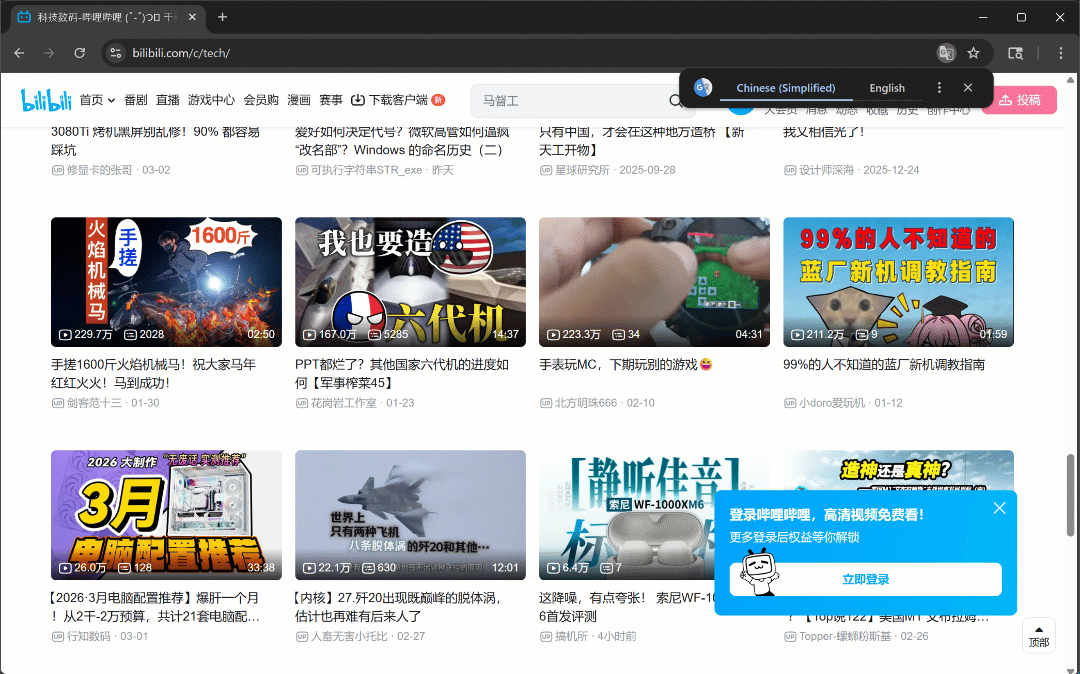
Conforme o esperado, novos cartões de vídeo são carregados após cada rolagem.
Após esta etapa, você pode ter certeza de que pelo menos 50 placas de vídeo estão presentes na página. Fantástico!
Etapa 4: familiarize-se com a estrutura da placa de vídeo
Para extrair os dados corretos, primeiro você precisa entender como cada placa de vídeo está estruturada no DOM.
Comece clicando com o botão direito do mouse em uma das placas de vídeo dentro da seção .head-cards e inspecionando nas ferramentas de desenvolvedor do navegador: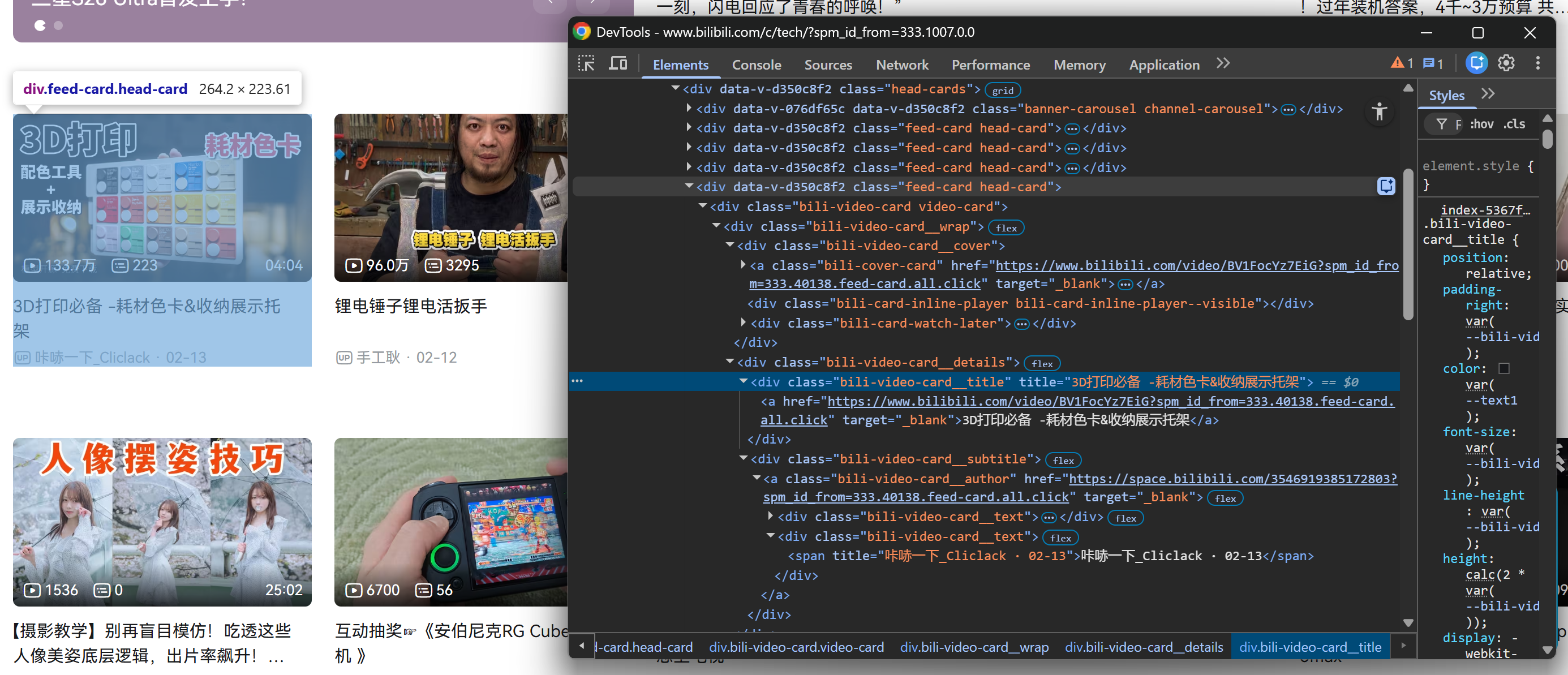
Em seguida, repita o mesmo processo para uma placa de vídeo dentro da seção .feed-cards carregada: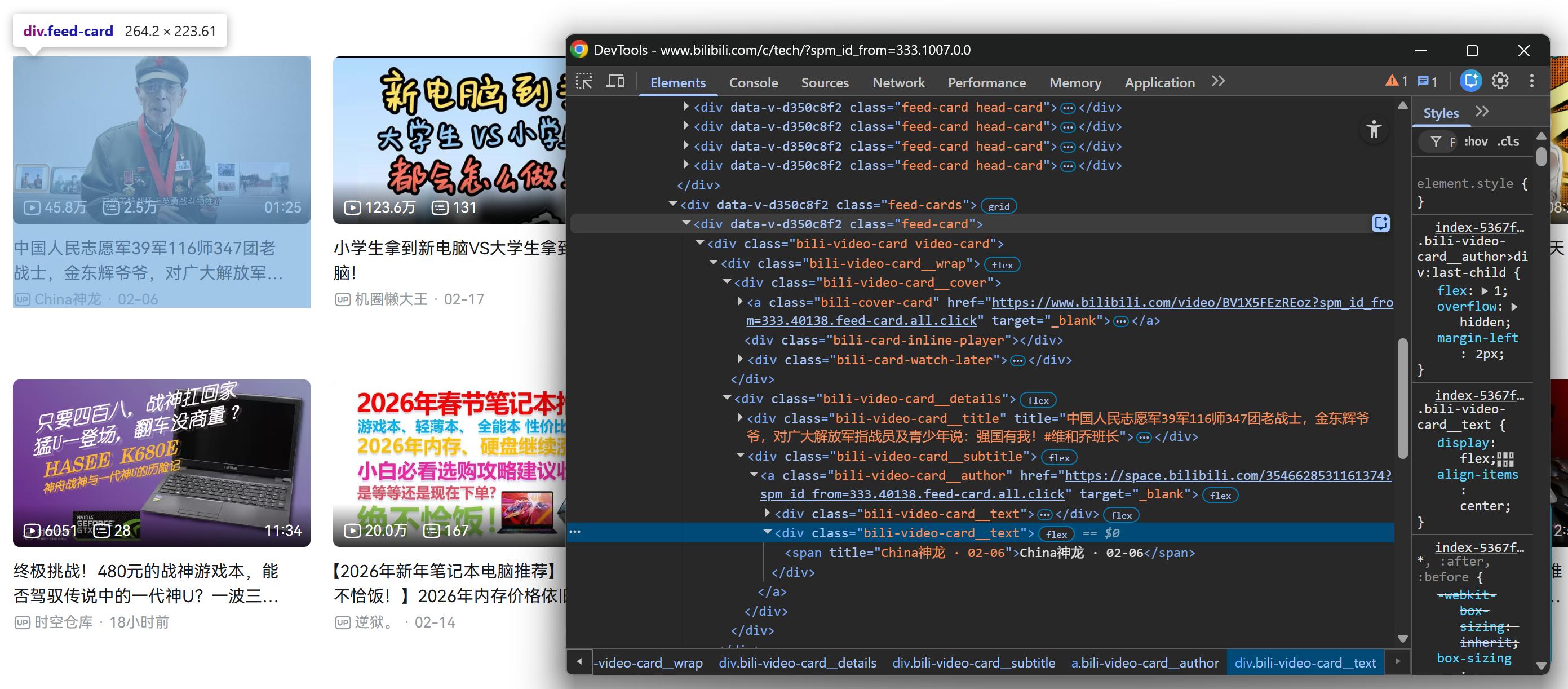
Felizmente, todos os elementos .feed-card compartilham a mesma estrutura interna. Isso significa que você não precisa distinguir entre placas de vídeo carregadas na renderização inicial da página e placas de vídeo carregadas dinamicamente após a rolagem. Você pode selecionar todas elas usando os mesmos seletores!
Observe como, a partir de cada cartão de vídeo, você pode coletar:
- O título do vídeo do elemento
.bili-video-card__title a. - A URL do vídeo do atributo
hrefdo mesmo nó<a>do título. - A legenda bruta (que contém o nome do autor + data de publicação) do
span[title] .bili-video-card__subtitle. - A URL do perfil do autor do elemento
.bili-video-card__author.
Perfeito! Agora que você entende a estrutura DOM, o próximo passo é traduzir esse conhecimento em lógica programática de extração de dados do Bilibili.
Etapa 5: extraia os dados do vídeo
Lembre-se de que a página de destino contém vários cartões de vídeo. Portanto, primeiro você precisa de uma estrutura de dados para armazenar os resultados extraídos. Uma lista é perfeita para isso:
videos = []Em seguida, itere por todos os cartões de vídeo e aplique a lógica de extração descrita anteriormente:
para i no intervalo (feed_card_count):
# Obter o cartão de vídeo atual para extrair os dados
cartão = feed_cards.nth(i)
localizador_título = cartão.localizador(".bili-video-card__title a")
título = aguardar localizador_título.inner_text() se aguardar localizador_título.count() senão Nenhum
video_url = aguardar localizador_título.obter_atributo("href") se aguardar localizador_título.contar() senão Nenhum
localizador_legenda = placa.localizador(".bili-video-card__subtitle span[title]")
legenda = aguardar localizador_legenda.texto_interno() se aguardar localizador_legenda.contar() senão Nenhum
localizador_autor = localizador.localizador(".bili-video-card__author")
url_autor = aguardar localizador_autor.obter_atributo("href") se aguardar localizador_autor.contar() senão Nenhum
author_name = None
date = None
if subtitle and "·" in subtitle:
parts = [p.strip() for p in subtitle.split("·")]
if len(parts) >= 2:
author_name = parts[0]
date = parts[1]
# Armazene os dados coletados
video = {
"title": title,
"video_url": video_url,
"subtitle": subtitle,
"author": {
"name": author_name,
"url": author_url
},
"date": date
}
videos.append(video)O trecho acima percorre cada cartão de vídeo e:
- Extrai o título, a URL do vídeo, a legenda bruta e a URL do perfil do autor.
- Parses a string da legenda (que segue o formato
“<NOME_DO_AUTOR> · <DATA>”) para extrair separadamente o nome do autor e a data do vídeo. - Cria um dicionário
de vídeosestruturado e o anexa à listade vídeos.
Ao final do loop for, a lista de vídeos conterá mais de 50 objetos de vídeo Bilibili estruturados. Ótimo!
Etapa 6: Exporte os dados coletados
Para facilitar o processamento dos dados coletados, exporte-os para um arquivo videos.json:
import json
with open("videos.json", "w", encoding="utf-8") as f:
json.dump(videos, f, ensure_ascii=False, indent=2)Se você executar o Scraper.py agora, ele deverá gerar um arquivo videos.json contendo dados estruturados de vídeos do Bilibili, assim: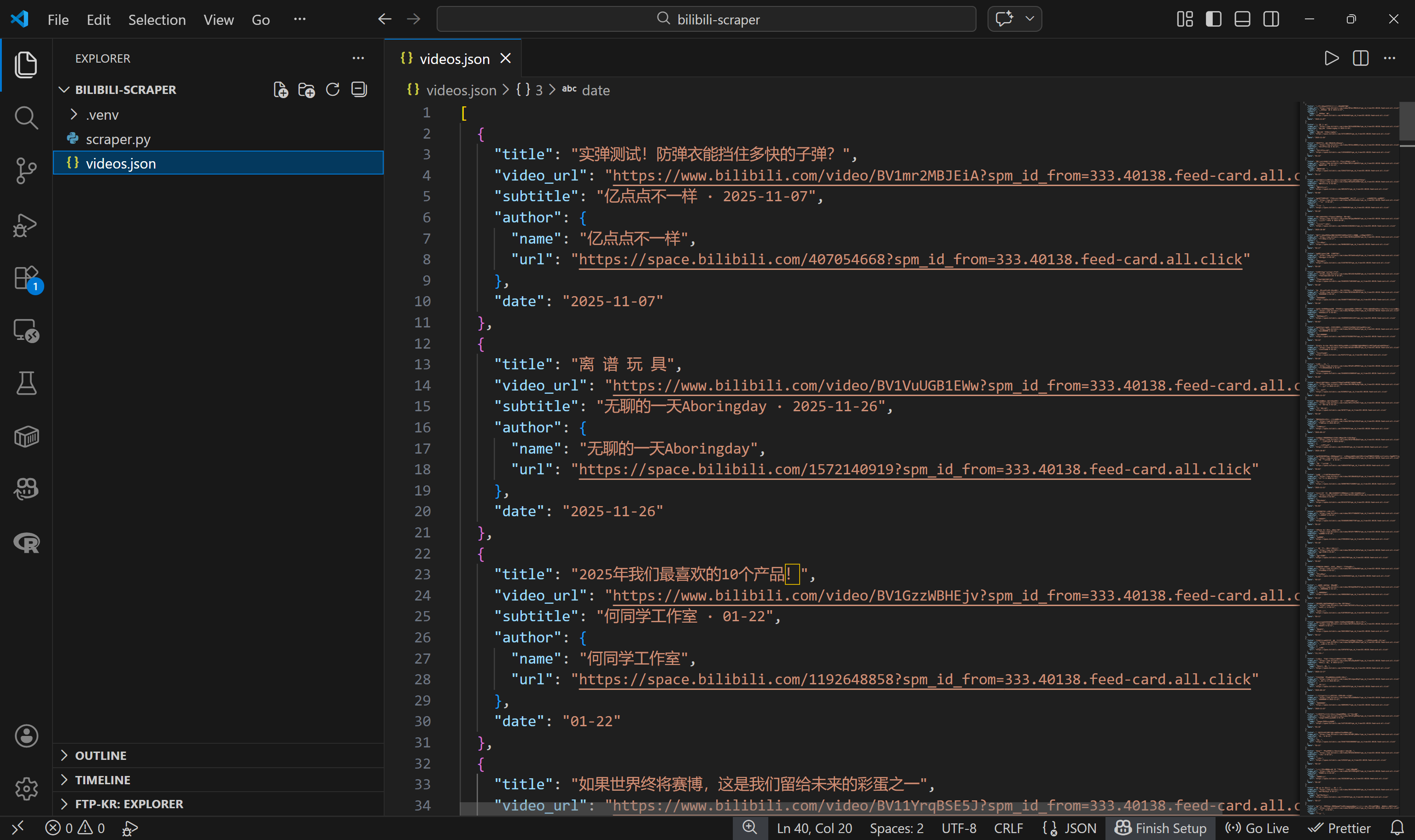
Missão cumprida! Você começou com uma página contendo muitos cartões de vídeo e agora tem seus metadados armazenados em um arquivo JSON estruturado.
Se o seu objetivo é simplesmente extrair dados do Bilibili, o tutorial pode terminar aqui (apenas certifique-se de verificar a etapa final para obter o script completo). Se você quiser ir além e realmente baixar os vídeos, continue lendo…
Etapa 7: Prepare-se para baixar os vídeos do Bilibili
A maneira mais fácil de baixar vídeos do Bilibili a partir das URLs que você coletou anteriormente é utilizando o yt-dlp.
O yt-dlp é um downloader de áudio/vídeo rico em recursos que suporta centenas de sites, incluindo o Bilibili. Ele pode ser usado tanto a partir da linha de comando quanto por meio de uma API Python programática. Aqui, vamos utilizá-lo programaticamente por meio de sua API Python.
Com seu ambiente virtual ativado, instale o yt-dlp:
pip install yt-dlpEm seguida, adicione um novo arquivo chamado video-downloader.py à raiz do seu projeto:
bilibili-Scraper/
├── .venv/
├── scraper.py
└── video-downloader.py # <-----------Este arquivo conterá a lógica de download de vídeos do Bilibili com tecnologia yt-dlp.
O script video-downloader.py precisa:
- Ler o arquivo
videos.json. - Extrair o
video_urlpara cada vídeo. - Usar a classe
YoutubeDLdoyt_dlppara baixar os arquivos de vídeo.
Abaixo está a implementação:
import os
import json
from yt_dlp import YoutubeDL
INPUT_FILE = "videos.json"
OUTPUT_DIR = "./videos"
# Carregar os dados do vídeo do arquivo JSON de entrada
with open(INPUT_FILE, "r", encoding="utf-8") as f:
videos = json.load(f)
print(f"Carregados {len(videos)} vídeos de {INPUT_FILE}n")
# Certifique-se de que a pasta de saída existe
os.makedirs(OUTPUT_DIR, exist_ok=True)
ydl_opts = {
"format": "bestvideo+bestaudio/best",
"outtmpl": f"{OUTPUT_DIR}/%(title)s.%(ext)s",
"merge_output_format": "mp4",
}
com YoutubeDL(ydl_opts) como ydl:
para índice, vídeo em enumerate(vídeos, início=1):
url_do_vídeo = vídeo.get("url_do_vídeo")
imprimir(f"[{índice}/{len(vídeos)}] Baixando: {vídeo.get('título')}")
tente:
ydl.download([video_url])
imprimir(f"Vídeo #{index} baixadon")
exceto Exceção como e:
imprimir(f"Falha no download do vídeo #{index}: {e}n")Uau! Menos de 35 linhas de código foram suficientes para atingir o objetivo.
Etapa #8: Baixe os arquivos de vídeo
Certifique-se de que o ffmpeg esteja instalado localmente e execute o script video-downloader.py. No terminal, você deverá ver algo assim: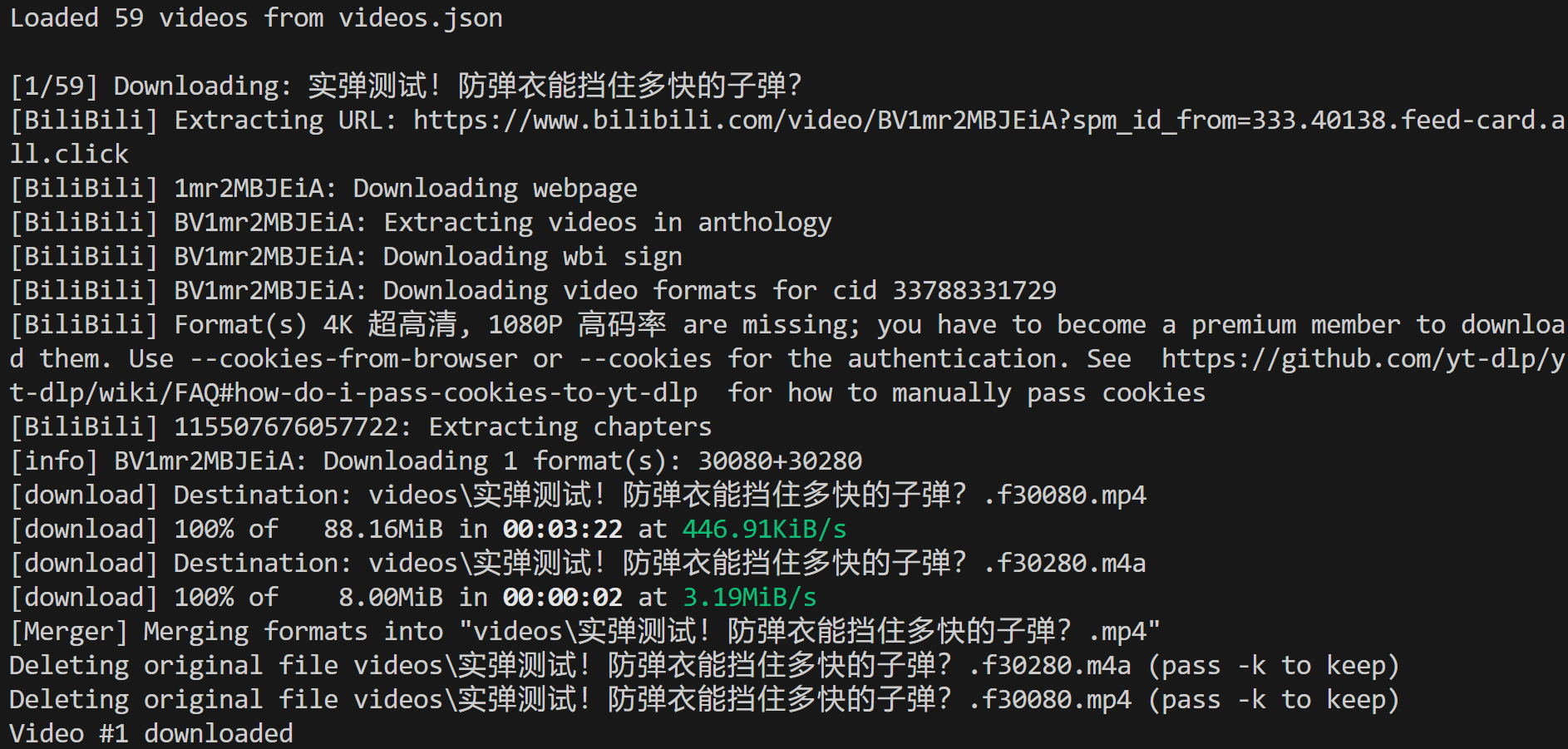
Isso mostra que 59 vídeos foram carregados do arquivo de entrada videos.json e o primeiro foi baixado com sucesso para o caminho local:
./videos/实弹测试!防弹衣能挡住多快的子弹?.mp4No Visual Studio Code, você verá o arquivo de vídeo MP4 aparecer nesse caminho exato: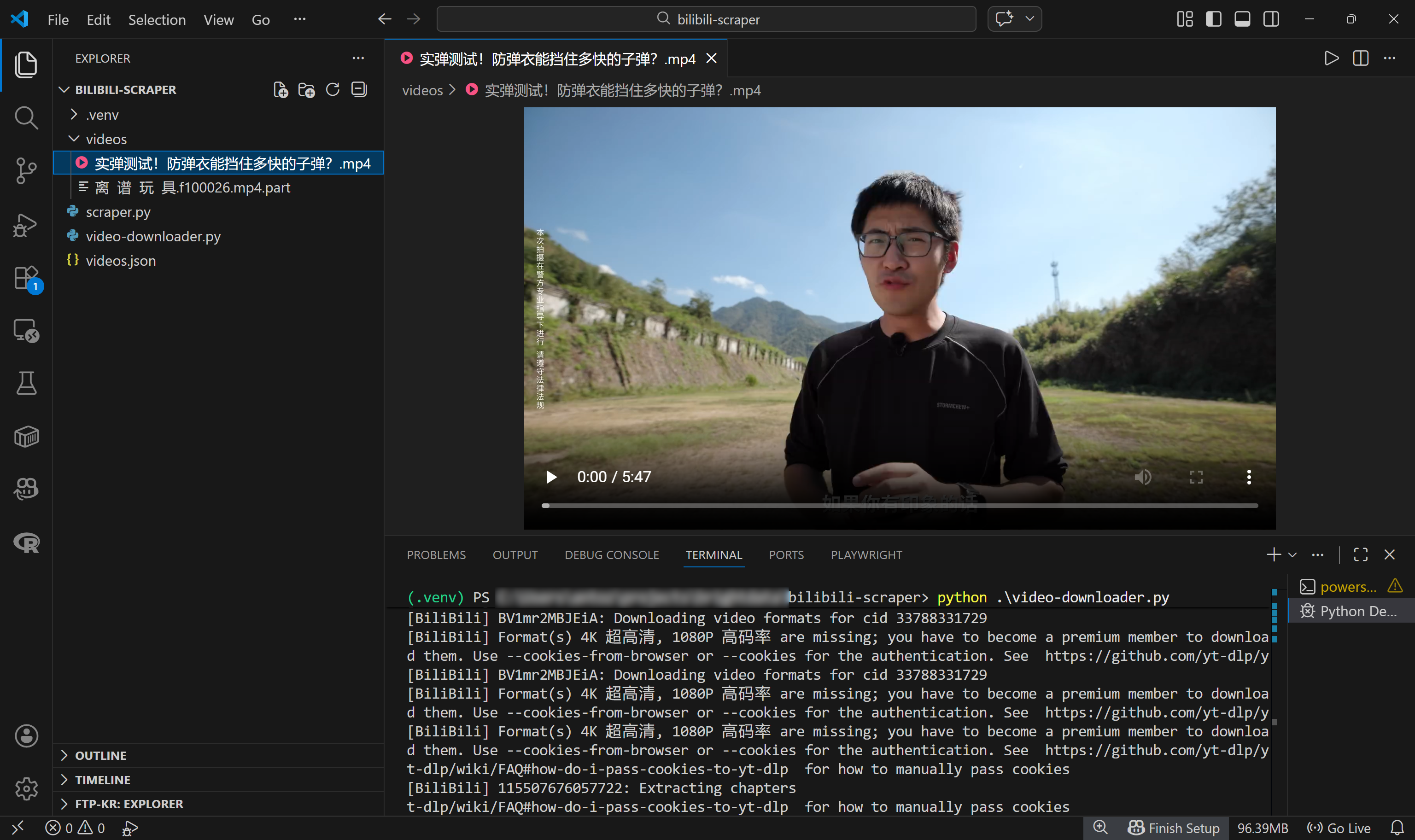
Incrível! Agora você tem um sistema Bilibili totalmente automatizado que não apenas descobre novos vídeos, mas também os baixa. Com esses arquivos, você pode até mesmo treinar modelos de IA por meio de um pipeline de ML multimodal.
Etapa 9: Código final
O arquivo scraper.py conterá o seguinte código:
# scraper.py
# pip install playwright
# python -m playwright install
import asyncio
from playwright.async_api import async_playwright
import json
async def main():
async with async_playwright() as p:
# Inicie uma instância controlada do Chromium no modo headful
browser = await p.chromium.launch()
context = await browser.new_context()
page = await context.new_page()
# A página "Tech" Bilibili de destino
target_bilibili_page = "https://www.bilibili.com/c/tech/"
# Navegue até a página de destino
await page.goto(target_bilibili_page)
# Role a página inteira para baixo 3 vezes
for _ in range(3):
# Permita o carregamento lento
await asyncio.sleep(1)
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# Permita o carregamento lento
await asyncio.sleep(2)
# Aguardar até que o 50º elemento do cartão de vídeo seja anexado ao DOM
fiftieth_card = page.locator(".feed-card").nth(49)
await fiftieth_card.wait_for(state="visible")
# Selecionar todos os cartões de feed por meio do localizador
feed_cards = page.locator(".feed-card")
feed_card_count = await feed_cards.count()
print(f"{feed_card_count} cartões de feed carregados.")
# Onde armazenar os dados coletados
videos = []
# Aplicar a lógica de coleta de dados do Bilili em cada cartão de vídeo
para i em range(feed_card_count):
# Obter o cartão de vídeo atual para extrair os dados
card = feed_cards.nth(i)
title_locator = card.locator(".bili-video-card__title a")
title = aguardar localizador_título.texto_interno() se aguardar localizador_título.contagem() senão Nenhum
url_vídeo = aguardar localizador_título.obter_atributo("href") se aguardar localizador_título.contagem() senão Nenhum
localizador_legenda = cartão.localizador(".bili-video-card__subtitle span[title]")
subtitle = aguardar subtitle_locator.inner_text() se aguardar subtitle_locator.count() senão None
author_locator = card.locator(".bili-video-card__author")
author_url = aguardar author_locator.get_attribute("href") se aguardar author_locator.count() senão None
author_name = None
date = None
if subtitle and "·" in subtitle:
parts = [p.strip() for p in subtitle.split("·")]
if len(parts) >= 2:
author_name = parts[0]
date = parts[1]
# Armazene os dados coletados
video = {
"title": title,
"video_url": video_url,
"subtitle": subtitle,
"author": {
"name": author_name,
"url": author_url
},
"date": date
}
videos.append(video)
# Fechar o navegador e liberar seus recursos
await browser.close()
# Exportar os dados coletados para um arquivo JSON
with open("videos.json", "w", encoding="utf-8") as f:
json.dump(videos, f, ensure_ascii=False, indent=2)
imprimir(f"{len(videos)} vídeos Bilibili coletados exportados para videos.json")
se __name__ == "__main__":
asyncio.run(main())Inicie com:
python Scraper.pyIsso irá gerar um arquivo videos.json contendo os dados dos vídeos Bilibili coletados. Você pode então baixar esses vídeos usando este script video-downloader.py:
# video-downloader.py
# pip install yt-dlp
import os
import json
from yt_dlp import YoutubeDL
INPUT_FILE = "videos.json"
OUTPUT_DIR = "./videos"
# Carregue os dados de vídeo do arquivo JSON de entrada
with open(INPUT_FILE, "r", encoding="utf-8") as f:
videos = json.load(f)
print(f"Carregados {len(videos)} vídeos de {INPUT_FILE}n")
# Certifique-se de que a pasta de saída existe
os.makedirs(OUTPUT_DIR, exist_ok=True)
ydl_opts = {
"format": "bestvideo+bestaudio/best",
"outtmpl": f"{OUTPUT_DIR}/%(title)s.%(ext)s",
"formato de saída combinado": "mp4",
}
com YoutubeDL(ydl_opts) como ydl:
para índice, vídeo em enumerar(vídeos, início=1):
url do vídeo = vídeo.get("url do vídeo")
imprimir(f"[{index}/{len(videos)}] Baixando: {video.get('title')}")
tentar:
ydl.download([video_url])
imprimir(f"Vídeo #{index} baixadon")
exceto Exception como e:
imprimir(f"Falha ao baixar o vídeo #{index}: {e}n")Execute com:
python video-downloader.pyO resultado será uma pasta ./videos contendo os arquivos MP4 para cada vídeo Bilibili descoberto.
Et voilà! Você acabou de aprender como criar um Scraper do Bilibili e usá-lo para alimentar um downloader com os dados dos vídeos extraídos. Esse processo ajuda a recuperar os arquivos de vídeo reais para treinamento de IA ou qualquer outro caso de uso.
Próximos passos
Agora que você tem metadados estruturados e os arquivos de vídeo reais, pode passar esses dados para um pipeline de treinamento de IA. Por exemplo, você pode extrair quadros para tarefas de visão computacional, gerar transcrições para o ajuste fino do modelo NLP, analisar sinais de áudio ou criar sistemas de recomendação com base no conteúdo do vídeo e nos metadados. A combinação de títulos, autores, datas e arquivos de vídeo brutos fornece um rico conjunto de dados multimodal pronto para experimentação.
Além disso, para acelerar a fase de download, considere paralelizar o processo para que vários vídeos sejam baixados simultaneamente. Essa abordagem ajuda a utilizar totalmente a largura de banda disponível, resultando em tempos de download mais rápidos.
Uma solução pronta para produção para scraping do Bilibili: obtenha dados de vídeo para IA
Se você executar o script de download em um grande número de vídeos, poderá eventualmente começar a ver erros como:
Não é possível baixar a página da web: Erro HTTP 412: Pré-condição falhou (causado por <HTTPError 412: Pré-condição falhou>)Isso ocorre porque o Bilibili possui proteções anti-bot. Quando a plataforma detecta tráfego suspeito (como muitas solicitações automatizadas provenientes do mesmo IP), ela começa a retornar uma resposta 412 Pré-condição falhou.
A página de erro se parece com esta:
Esse é apenas um dos desafios que você precisa enfrentar ao fazer scraping do Bilibili. Outros problemas comuns incluem mudanças estruturais nas páginas de destino, detecção baseada em impressão digital e muito mais. Embora uma configuração personalizada do Playwright + yt-dlp funcione bem para projetos de pequena escala, mantê-la ao longo do tempo pode se tornar complexo e frágil.
Para fazer scraping do Bilibili de forma confiável em grande escala, você precisa de uma infraestrutura de scraping mais robusta que lide com rotação de IP, impressão digital do navegador, Resolução de CAPTCHA e novas tentativas automáticas. É exatamente isso que o Bilibili Scraper da Bright Data oferece.
Essa API de Scraping de dados, também disponível como um Scraper sem código, recupera títulos de vídeos, datas de upload, visualizações, curtidas, comentários, favoritos, durações, nomes de uploaders, descrições, URLs e muito mais. Tudo isso enquanto contorna automaticamente os mecanismos anti-bot para você.
O que torna o Bilibili Scraper único é que ele é executado em uma infraestrutura de Proxy com mais de 150 milhões de IPs em 195 países, alcançando 99,99% de tempo de atividade, 99,95% de taxa de sucesso e suportando simultaneidade ilimitada. Isso permite cenários de scraping em grande escala e em nível empresarial, o que é fundamental considerando que o treinamento de IA multimodal requer volumes massivos de dados de vídeo.
Após recuperar as URLs dos vídeos, integre a API Web Unlocker da Bright Data em fluxos de trabalho automatizados do yt-dlp para evitar erros 412 e baixar vídeos sem bloqueios. Graças à Bright Data, você pode esquecer os limites de taxa, bloqueios ou falhas do yt-dlp para obter mais vídeos para treinar seus modelos de IA/ML.
Conclusão
Nesta postagem do blog, você viu que tipo de dados pode extrair do Bilibili e os principais casos de uso que ele suporta. Um dos cenários mais interessantes é o treinamento de IA em dados de vídeo. Com centenas de milhões de vídeos disponíveis na plataforma, o Bilibili representa uma fonte massiva de conteúdo multimídia acessível ao público.
O processo começa com um Scraper do Bilibili que você aprendeu a construir passo a passo. Ele coleta metadados de vídeo estruturados, incluindo URLs de vídeo. Você pode então passar essas URLs para um fluxo de trabalho alimentado por yt-dlp para baixar os arquivos de vídeo reais, conforme demonstrado neste guia.
A Bright Data oferece suporte ao scraping do Bilibili por meio de um Scraper dedicado e opções de integração direta com o yt-dlp para downloads confiáveis e ininterruptos. Para obter mais informações, confira nossas soluções para acessar dados de vídeo em grande escala para treinamento de LLM.
Inscreva-se hoje mesmo na Bright Data e explore nossas soluções de coleta de dados de vídeo!





