

Ao final deste tutorial, você entenderá:
- Por que o PyTorch é uma ótima opção para construir um fluxo de trabalho de aprendizado de máquina multimodal.
- A necessidade de uma fonte confiável de dados confiáveis de Conjuntos de dados contendo vários milhões de registros, como os fornecidos pela Bright Data.
- Como aproveitar os Conjuntos de dados da Bright Data no PyTorch para ajustar um modelo de ML para classificação de imagens de produtos em um processo multimodal.
Vamos começar!
Por que usar o PyTorch para aprendizado de máquina multimodal
Os dados são tão valiosos quanto os insights que eles proporcionam. Para as empresas, aproveitar os dados com a abordagem certa pode levar a decisões mais inteligentes, refinar estratégias e melhorar resultados, como retenção de clientes e desempenho de marketing.
O aprendizado de máquina moderno permite processar não apenas dados estruturados, como classificações ou números de vendas, mas também dados não estruturados, como imagens, texto e até mesmo vídeo. Isso abre as portas para insights multimodais. Por exemplo, combinar imagens de avaliações com texto pode proporcionar uma compreensão mais rica do que impulsiona o envolvimento do cliente.
Este artigo é baseado no PyTorch, uma estrutura de aprendizado de máquina Python amplamente utilizada para construir e treinar redes neurais profundas. A biblioteca oferece suporte a uma longa lista de tarefas, incluindo classificação de imagens, processamento de linguagem natural e fluxos de trabalho combinados, nos quais vários tipos de dados são analisados juntos.
Algumas aplicações comuns do PyTorch incluem:
- Avaliação da qualidade da imagem do produto: determine automaticamente se as imagens são visualmente atraentes e prováveis de envolver os clientes.
- Analisar o sentimento do cliente: extrair insights de avaliações textuais para entender as opiniões e a satisfação dos usuários.
- Criação de sistemas de recomendação: combinar recursos de texto e imagem para gerar sugestões de produtos mais precisas e personalizadas.
- Modelagem preditiva com dados multimodais: use informações visuais e textuais juntas para prever tendências, vendas ou comportamento do cliente.
Como obter dados multimodais de alta qualidade para sua empresa
Não importa o tipo de aprendizado de máquina ou aplicação de IA que você esteja desenvolvendo, é importante lembrar que esses sistemas são tão eficazes quanto os dados com os quais são treinados.
Em aplicações multimodais, a obtenção de dados pode ser particularmente desafiadora, pois requer a coleta de informações em formatos textuais e visuais. É aí que entram os provedores de dados confiáveis, como a Bright Data.
A Bright Data oferece um conjunto de soluções prontas para IA e aprendizado de máquina para empresas de todos os tamanhos, desde startups até grandes corporações:
- APIs Web Scraper: fornecem acesso programático a dados estruturados de centenas de sites populares, permitindo a coleta automatizada de dados novos da web em grande escala.
- Mercado de conjuntos de dados: oferece conjuntos de dados multimodais prontos para uso com bilhões de entradas, incluindo imagens, texto e campos estruturados.
- Serviços gerenciados de aquisição de dados: soluções totalmente gerenciadas e de nível empresarial que permitem que as equipes adquiram e mantenham dados sem construir ou manter pipelines de scraping.
- Serviços de anotação de dados: soluções de anotação escaláveis e personalizáveis para tarefas de NLP, visão computacional e reconhecimento de fala.
Essas soluções capacitam pesquisadores, pequenas e médias empresas e grandes corporações a coletar e integrar dados públicos da web com eficiência. Isso pode ser aproveitado para alimentar fluxos de trabalho de aprendizado de máquina multimodal, treinar modelos sofisticados de IA, desenvolver agentes inteligentes e construir sistemas de análise e inteligência de negócios.
Como construir um pipeline de análise de aprendizado de máquina multimodal usando PyTorch com um conjunto de dados da Bright Data
Nesta seção guiada, você aprenderá como treinar um modelo de aprendizado de máquina no conjunto de dados“Produtos Amazon”da Bright Data, que contém dados textuais e de imagem.
Vamos supor que você venda produtos online e entenda a importância de apresentá-los com imagens adequadas. O objetivo é usar o PyTorch para treinar um modelo de aprendizado de máquina em imagens de produtos de comércio eletrônico, juntamente com suas informações de classificação. Esse modelo então se encarregará de avaliar automaticamente se uma imagem de produto é “boa” ou “ruim”.
Graças a esse fluxo de trabalho de ML multimodal, sua empresa pode avaliar programaticamente a probabilidade de suas imagens de produtos atraírem clientes e gerarem engajamento.
Observação: este é apenas um exemplo. Ao utilizar o PyTorch junto com os Conjuntos de dados e feeds de dados da Bright Data, você pode cobrir muitos outros casos de uso e cenários.
Siga as instruções abaixo!
Pré-requisitos
Para acompanhar esta seção, certifique-se de ter:
- Python 3.9 ou superior instalado localmente.
- Uma conta Bright Data.
Além disso, familiaridade com o modelo ResNet-18 e como funciona o ajuste fino será útil para compreender totalmente a lógica de classificação de imagens multimodal do PyTorch.
Etapa 1: criar um projeto JupyterLab
Ao trabalhar com dados multimodais, é útil visualizar seus Conjuntos de dados. Por esse motivo, o JupyterLab é uma excelente escolha como ambiente de desenvolvimento. Depois que seu fluxo de trabalho estiver desenvolvido, o código poderá ser facilmente convertido em um pipeline de aprendizado de máquina pronto para produção.
Comece criando uma pasta de projeto dedicada e navegue até ela:
mkdir pytorch-brightdata-product-image-analysis
cd pytorch-brightdata-product-image-analysisEm seguida, inicialize um ambiente virtual dentro dela:
python -m venv .venvNo macOS/Linux, ative o ambiente virtual com:
source .venv/bin/activateOu, no Windows, execute:
.venvScriptsactivateCom o ambiente virtual ativo, instale o JupyterLab através do pacote jupyterlab:
pip install jupyterlabInicie o JupyterLab com:
jupyter labA interface do JupyterLab será aberta em http://localhost:8888/lab/ no seu navegador. Crie um novo notebook clicando no botão “Python 3 (ipykernel)” na seção “Notebook”:
Você verá um arquivo Untitled.ipynb:
Dê ao seu novo notebook um nome como “Bright Data + PyTorch” e salve-o.
Concluído! Agora você tem um ambiente Python totalmente configurado, pronto para desenvolver fluxos de trabalho de aprendizado de máquina multimodal por meio do PyTorch.
Etapa 2: instale e importe as dependências necessárias
No seu notebook, adicione uma nova célula de código com o seguinte comando pip
!pip install pillow tqdm requests scikit-learn torch torchvision pandasExecute este bloco para instalar todas as bibliotecas necessárias:
pillow: para carregar e processar imagens.tqdm: para exibir barras de progresso para loops, úteis para rastrear o carregamento e o treinamento de dados.requests: Para baixar imagens de URLs por meio de solicitações HTTP.scikit-learn: fornece ferramentas comotrain_test_splitpara dividir Conjuntos de dados.torch: A biblioteca principal do PyTorch para construir e treinar modelos de aprendizado de máquina.torchvision: fornece Conjuntos de dados, modelos pré-treinados e transformações de imagens.pandas: Lida com dados estruturados, como arquivos CSV, e facilita a manipulação de dados.
Em outra célula de código, importe todos os módulos necessários:
import os
import io
import json
import requests
from PIL import Image, ImageStat
from tqdm import tqdm
from sklearn.model_selection import train_test_split
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models
from tqdm import tqdm
from PIL import ImageÓtimo! Com essas duas células, seu notebook está totalmente pronto para lidar com Conjuntos de dados multimodais da Bright Data e realizar o processamento de imagens e textos usando o PyTorch.
Etapa 3: baixe o conjunto de dados da Bright Data
Agora que seu notebook está configurado para o desenvolvimento do PyTorch, é hora de obter o componente mais importante deste fluxo de trabalho: os dados de entrada!
Para este tutorial, usaremos o conjunto de dados“produtos da Amazon”, um dos muitos Conjuntos de dados de comércio eletrônico disponíveis na Bright Data. No momento da redação deste artigo, esse conjunto de dados contém mais de 311 milhões de entradas, cada uma com 87 campos de dados. Para cada produto, esses campos listam as URLs das imagens, a classificação das avaliações, o ASIN do produto e muitas outras informações.
Observação: você pode coletar dados estruturados atualizados de plataformas como Amazon, eBay, Walmart e muitas outras usando o Bright Data eCommerce Scraper.
Para começar, se você ainda não tem uma conta Bright Data, crie uma. Caso contrário, faça login e acesse a página“Dataset marketplace”(Mercado de conjuntos de dados) da sua conta:
Selecione o conjunto de dados “Amazon products” entre os “Mais populares”:
Você chegará à página dos Conjuntos de dados: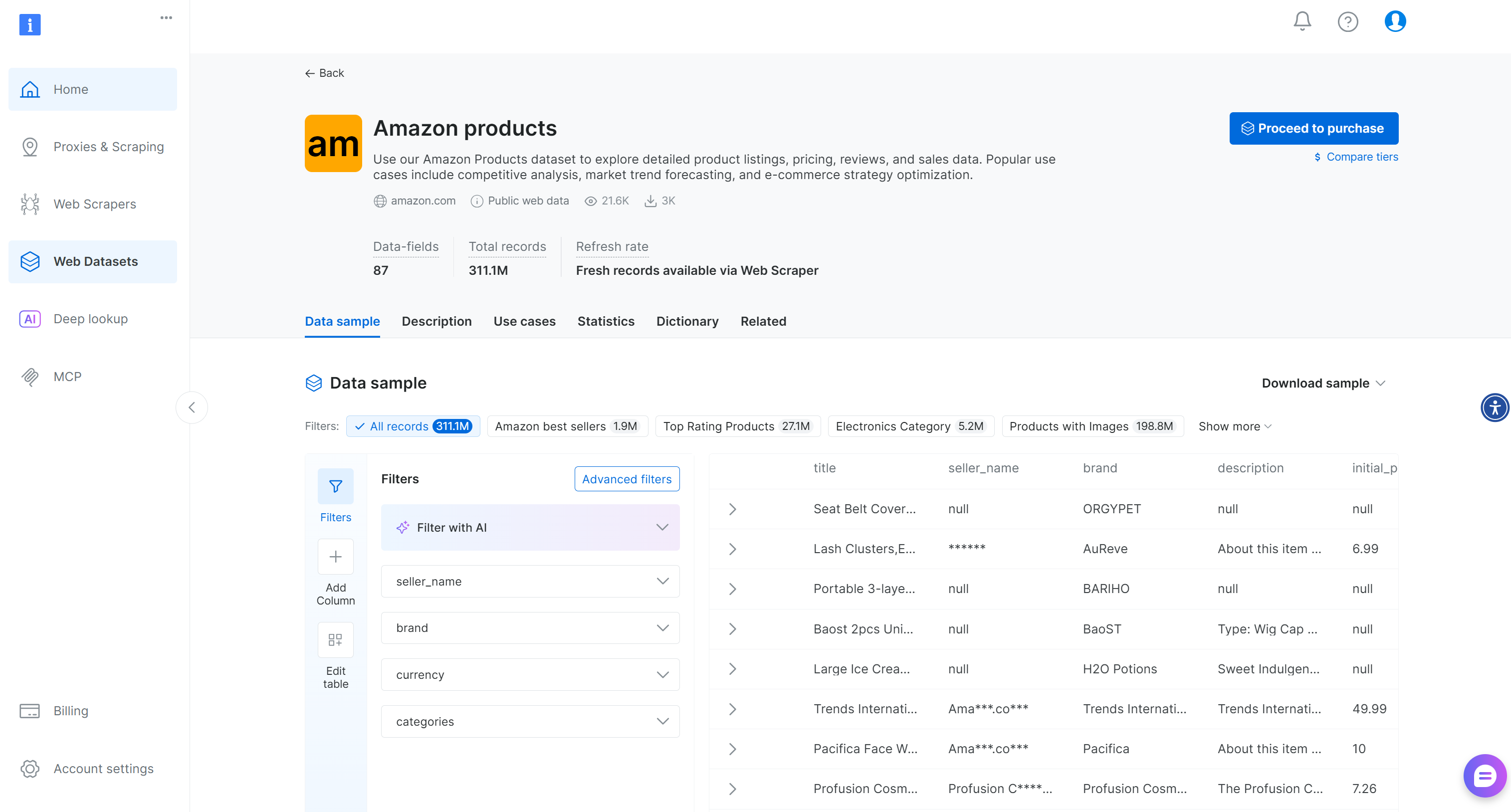
Aqui, você pode filtrar as entradas manualmente ou usar filtros alimentados por IA para criar subconjuntos adaptados às suas necessidades. Observe que esses filtros também podem ser aplicados programaticamente por meio da API de filtro, que permite criar instantâneos de Conjuntos de dados com base em critérios específicos.
Para este tutorial, precisamos apenas de um pequeno conjunto de dados de amostra para demonstrar um fluxo de trabalho de ML multimodal, portanto, o conjunto de dados de amostra gratuito é suficiente. Para um fluxo de trabalho pronto para produção ou empresarial, você precisa baixar um conjunto de dados completo criado de acordo com suas necessidades específicas.
Para baixar o conjunto de dados de amostra, abra o menu suspenso “Amostra de conjunto de dados” e selecione “Baixar como CSV”: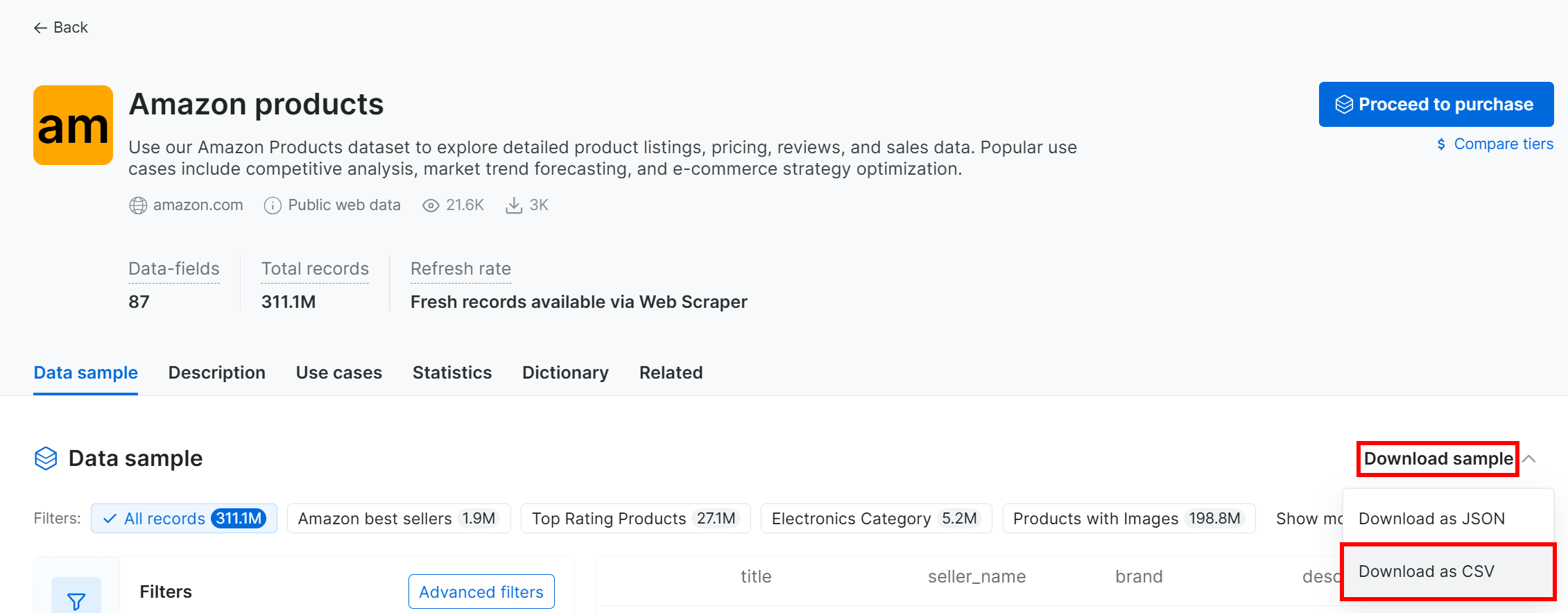
Você receberá um arquivo chamado Amazon products.csv, contendo 1 mil produtos (~7,3 MB). Renomeie-o para amazon_products.csv e coloque-o na pasta do seu projeto: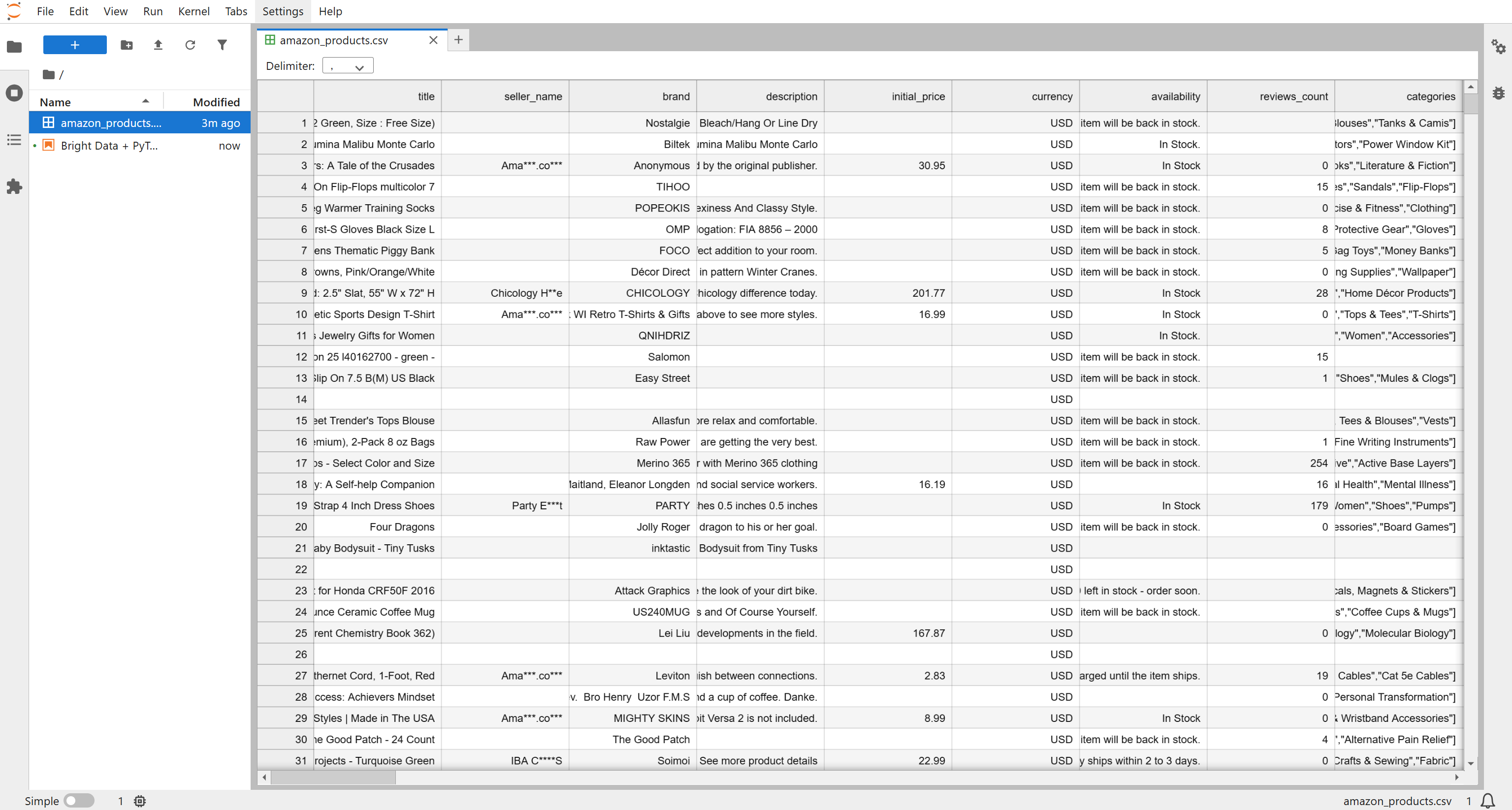
Dos 87 campos disponíveis, os relevantes para este fluxo de trabalho multimodal são:
asin: o identificador exclusivo do produto na Amazon.image_url: a URL da imagem principal do produto.images: uma matriz no formato JSON contendo URLs de imagens adicionais do produto.rating: a classificação média das avaliações dos clientes, em uma escala de 1 a 5.
Esses campos permitem combinar dados visuais (imagens) com dados numéricos estruturados (classificações) em um fluxo de trabalho multimodal PyTorch ML. Fantástico! Agora você tem o conjunto de dados de entrada.
Etapa 4: definir a lógica para baixar e rotular imagens de produtos
De volta ao notebook, inicialize a lógica principal adicionando as funções para download e rotulagem de imagens. Essas duas funções formam os blocos de construção para implementar o processo de classificação de imagens de ML, que requer as seguintes etapas:
- Colete dados do produto, incluindo
image_url, matrizde imagens,classificaçãoeasindo conjunto de dados “Produtos Amazon” da Bright Data. - Extraia e deduplique URLs de imagens para cada entrada de produto.
- Baixe as imagens de todos os URLs e armazene-as localmente.
- Rotule as imagens, combinando heurística visual (fundo branco, resolução) e avaliações de revisão.
- Preparar um conjunto de dados PyTorch usando as imagens rotuladas, adequado para treinar um modelo CNN (Convolutional Neural Network).
- Ajuste uma CNN para prever a qualidade da imagem (“BOA” vs “RUIM”) usando o conjunto de dados rotulado.
- Avalie o modelo em um conjunto de testes.
- Use o modelo para avaliar automaticamente novas imagens de produtos.
Em uma nova célula de código em seu notebook, escreva as funções para baixar e rotular imagens de produtos:
def download_image(url):
# Envie uma solicitação GET para a URL da imagem
response = requests.get(url)
# Leia o conteúdo da resposta em um objeto BytesIO
image_bytes = io.BytesIO(response.content)
# Abra a imagem com PIL e converta para o modo RGB
image = Image.open(image_bytes).convert("RGB")
return image
def label_image(image, rating):
# Obtenha a largura e a altura da imagem
w, h = image.size
# Recorte os 10 pixels superiores para analisar o brilho da borda
border = image.crop((0, 0, w, 10))
# Calcule as estatísticas (média) para a borda
stat = ImageStat.Stat(border)
# Brilho médio nos canais RGB
brightness = sum(stat.mean) / 3
# Determinar se a imagem tem fundo branco
is_white_bg = brilho > 240
# Determinar se a imagem tem baixa resolução (lado menor < 400px)
is_low_res = min(image.size) < 400
# Rótulo heurístico: 1=bom se fundo branco e não baixa resolução, caso contrário 0=ruim
rótulo_heurístico = 1 se (is_white_bg e não is_low_res) caso contrário 0
# Se a classificação estiver ausente ou for zero, confiar apenas na heurística
se classificação for None ou classificação == 0:
retornar rótulo_heurístico
# Normalizar a classificação para o intervalo 0-1
r = classificação / 5
# Aplicar supervisão fraca para ajustar o rótulo com base em classificações extremas
if heuristic_label == 1 and r < 0.5: # classificação muito baixa → marcar como ruim
return 0
if heuristic_label == 0 and r > 0.9: # classificação excelente → marcar como bom
return 1
# Caso contrário, manter o rótulo heurístico
return heuristic_labelA função download_image() simplesmente baixa uma imagem de uma determinada URL e a retorna como uma instância PIL Image. Em vez disso, a função label_image() implementa uma avaliação multimodal das imagens dos produtos, combinando pistas visuais e dados textuais/numéricos, como classificações dos clientes.
label_image() primeiro aplica heurística — verificando se há fundo branco e resolução suficiente — para atribuir um rótulo inicial de “bom” ou “ruim”. Em seguida, se houver uma classificação disponível, a função ajusta o rótulo da seguinte maneira:
- Avaliações muito baixas substituem uma imagem visualmente boa.
- Avaliações excelentes salvam uma imagem de aparência ruim.
Essa lógica faz sentido porque, mesmo que uma imagem pareça boa, uma avaliação ruim indica que ela não é benéfica. Por outro lado, uma avaliação excelente pode destacar uma imagem bem-sucedida, apesar das imagens ruins. Assim, tanto as informações visuais quanto as numéricas são consideradas ao atribuir o rótulo final.
Ótimo! É hora de importar os Conjuntos de dados e preparar suas entradas de produto para aplicar essas duas funções em todas as imagens.
Etapa 5: carregue o conjunto de dados e prepare-se para baixar todas as imagens
Se você inspecionar o arquivo amazon_products.csv, verá que as imagens dos produtos estão armazenadas em dois campos de dados:
image_url: URL para a imagem principal do produto.images: uma string no formato JSON contendo uma matriz de todas as imagens adicionais do produto.
Em um novo bloco de código, carregue o CSV e recupere todas as imagens de cada produto usando uma função auxiliar:
def extract_image_list(row):
image_urls = []
# Verifique se há um único image_url principal e adicione-o se ele existir e não estiver vazio
if isinstance(row.get("image_url"), str) and row["image_url"].strip():
image_urls.append(row["image_url"].strip())
# Verifique o campo “images”, que pode ser uma string JSON ou uma lista Python
images_field = row.get("images")
if isinstance(images_field, str):
# Decodifique a string JSON em uma lista Python
decoded = json.loads(images_field)
if isinstance(decoded, list):
# Adicione todas as imagens da lista ao image_urls
image_urls.extend(decoded)
# Desduplique as URLs convertendo-as em um conjunto e, em seguida, de volta em uma lista
return list(set(image_urls))
# Carregue o CSV de produtos da Amazon em um DataFrame
df = pd.read_csv("amazon_products.csv")
# Excluir linhas que não tenham os campos obrigatórios
df = df.dropna(subset=["asin", "image_url", "images", "rating"])
# Aplicar a função extract_image_list a cada linha para gerar uma lista de todos os URLs de imagens exclusivos
df["all_image_urls"] = df.apply(extract_image_list, axis=1)O conjunto de dados importado agora tem uma nova coluna chamada all_image_urls. Ela armazena uma lista sem duplicatas de todos os URLs de imagens, combinando a imagem principal e quaisquer imagens adicionais. Na próxima etapa, você acessará esse campo para baixar e processar todas as imagens de cada produto!
Etapa 6: baixe e rotule todas as imagens
Em uma célula, implemente a lógica para baixar todas as imagens dos produtos em uma pasta local images/ e rotulá-las:
# Crie a pasta “images” se ela ainda não existir
os.makedirs("images", exist_ok=True)
# Inicialize uma lista para armazenar metadados para cada imagem baixada e rotulada
records = []
# Itere sobre cada linha de produto no DataFrame com uma barra de progresso
for idx, row in tqdm(df.iterrows(), total=len(df)):
# Acesse os campos de dados do produto necessários
url_list = row["all_image_urls"]
rating = float(row["rating"])
asin = row.get("asin")
# Itere sobre cada URL de imagem para este produto para baixá-la e rotulá-la
for i, url in enumerate(url_list):
# Baixe a imagem
image = download_image(url)
if image is None:
continue
# Construa um nome de arquivo usando ASIN e o índice da imagem
filename = f"{asin}_{i}.jpg"
path = os.path.join("images", filename)
# Salve a imagem baixada no disco
image.save(path)
# Rotular a imagem usando as informações multimodais
label = label_image(image, rating)
# Armazenar metadados relevantes para esta imagem
records.append({
"asin": asin,
"image_path": path,
"image_url": url,
"label": label
})
# Converta a lista de registros em um DataFrame e exporte-a para um arquivo CSV
labeled_df = pd.DataFrame(records)
labeled_df.to_csv("labeled_images.csv", index=False)Ao executar este bloco de código em seu notebook, o processo de download será iniciado. Serão baixadas mais de 2.500 imagens, portanto, aguarde alguns minutos.
Após a conclusão, a saída na sua célula de código deverá mostrar uma barra de progresso de 100%:
Agora, a pasta images/ no diretório do seu projeto conterá todas as imagens de produtos baixadas dos Conjuntos de dados: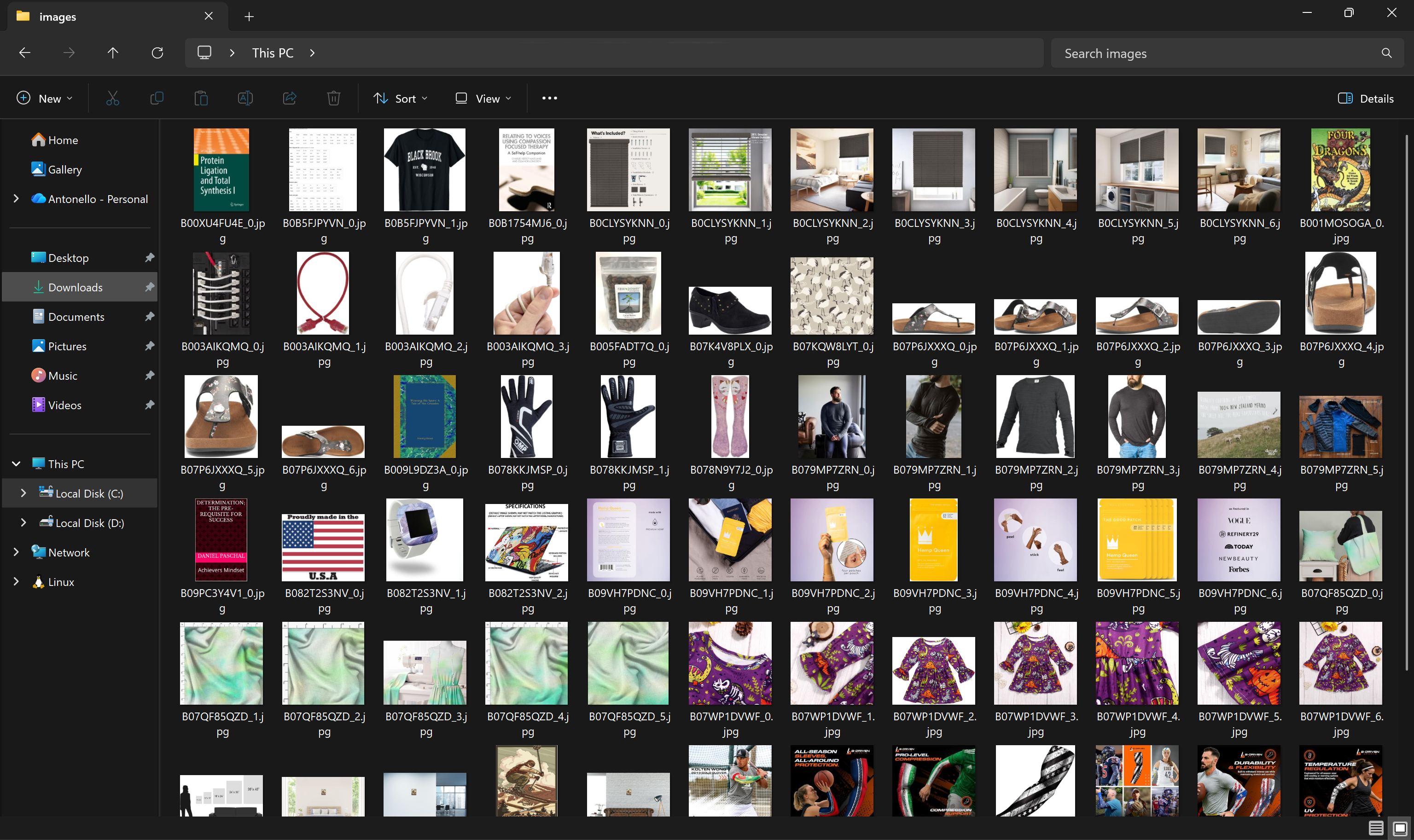
Além disso, o arquivo labeled_images.csv será criado localmente e preenchido com as informações de rotulagem de cada imagem:
Ótimo! Agora você tem todas as imagens locais e informações de rotulagem necessárias para treinar o modelo de aprendizado de máquina em um processo multimodal.
Etapa 7: Prepare os Conjuntos de dados de treinamento e teste
Adicione um novo bloco para ler as informações de rotulagem da imagem do arquivo labeled_images.csv e utilize-o para produzir conjuntos de dados de treinamento e teste que você usará para o ajuste fino do modelo de ML:
# Defina uma classe PyTorch Dataset personalizada para imagens de produtos
class ProductImageDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df
self.transform = transform
def __len__(self):
# Retorne o número total de amostras no conjunto de dados
return len(self.df)
def __getitem__(self, idx):
# Obtenha o caminho da imagem e o rótulo para um determinado índice
path, label = self.df.iloc[idx]["image_path"], self.df.iloc[idx]["label"]
# Carregue a imagem e converta para RGB
image = Image.open(path).convert("RGB")
# Aplicar transformações, se fornecidas (por exemplo, redimensionamento, conversão de tensor)
if self.transform:
image = self.transform(image)
# Retornar o tensor da imagem e o rótulo como um tensor torch
return image, torch.tensor(label, dtype=torch.long)
# Carregar o CSV das imagens rotuladas
rotulado_df = pd.read_csv("imagens_rotuladas.csv")
# Dividir o conjunto de dados em conjuntos de treinamento e teste, mantendo a distribuição de rótulos equilibrada
treinamento_df, teste_df = treinamento_teste_divisão(
rotulado_df,
tamanho_teste=0,2,
estratificar=rotulado_df["rótulo"]
)
# Defina transformações para redimensionar as imagens para 224x224 e convertê-las em tensores
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# Inicialize os objetos do conjunto de dados
train_ds = ProductImageDataset(train_df, transform)
test_ds = ProductImageDataset(test_df, transform)
# Envolva os Conjuntos de dados em DataLoaders para agrupamento e embaralhamento
train_dl = DataLoader(train_ds, batch_size=32, shuffle=True)
test_dl = DataLoader(test_ds, batch_size=32)Este trecho prepara as imagens de produtos rotuladas para treinar uma CNN PyTorch. Ele faz isso definindo um Dataset personalizado e aplicando estas transformações de imagem:
transforms.Resize((224, 224)): Redimensiona as imagens para224×224. Isso é importante porque as imagens no conjunto de dados têm diferentes resoluções e proporções, enquanto as CNNs esperam que todas as entradas tenham o mesmo tamanho fixo.transforms.ToTensor(): os modelos PyTorch operam em tensores em vez de imagens PIL brutas. Isso converte cada imagem em um tensor normalizado de forma(C, H, W)(canais, altura, largura), tornando-a compatível com a CNN.
Juntas, as transformações padronizam todas as imagens em termos de tamanho e formato, permitindo que o modelo se concentre em aprender padrões visuais em vez de lidar com entradas inconsistentes. Os Conjuntos de dados são então divididos em conjuntos de treinamento e teste, preservando as distribuições de rótulos, e envolvidos em objetos DataLoader para gerar lotes de dados de imagens e rótulos.
No geral, essa etapa garante que a CNN receba dados formatados corretamente, estabelecendo as bases para um treinamento eficaz de aprendizado de máquina multimodal. Ótimo!
Etapa 8: treinar o modelo de ML multimodal
Com os conjuntos de dados de treinamento e teste prontos, ajuste uma CNN no PyTorch para classificação de imagens com este código:
# Selecione o dispositivo para treinamento (GPU, se disponível, caso contrário, CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
# Carregue um modelo ResNet-18 pré-treinado do torchvision
model = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)
# Substitua a camada final totalmente conectada para produzir 2 classes (GOOD/BAD)
model.fc = nn.Linear(model.fc.in_features, 2)
# Mova o modelo para o dispositivo selecionado
model = model.to(device)
# Defina a função de perda para classificação
criterion = nn.CrossEntropyLoss()
# Defina o otimizador com uma pequena taxa de aprendizagem
opt = torch.optim.Adam(model.parameters(), lr=1e-4)
# Loop de treinamento para 3 épocas
for epoch in range(3):
model.train()
total_loss = 0
# Iterar sobre lotes de imagens e rótulos
para imagens, rótulos em tqdm(train_dl, desc=f"Época {epoch+1}"):
imagens, rótulos = imagens.to(device), rótulos.to(device)
opt.zero_grad()
out = model(images)
loss = criterion(out, labels)
loss.backward()
opt.step()
total_loss += loss.item()
# Imprimir perda média para o epoch
print(f"Epoch {epoch+1}: Perda média={total_loss/len(train_dl):.4f}")A célula acima ajusta uma CNN ResNet-18 pré-treinada, uma rede neural convolucional com 18 camadas de profundidade, usada principalmente para classificar imagens em várias categorias.
Nesse caso, o modelo de ML classificará as imagens dos produtos como boas ou ruins. O uso dos pesos do ImageNet acelera a convergência e aproveita os recursos já aprendidos a partir de milhões de imagens naturais. Em seguida, a camada final totalmente conectada é substituída para produzir duas classes (“BOA” e “RUIM”, conforme pretendido).
No loop, a instância CrossEntropyLoss mede o erro de classificação, enquanto o otimizador Adam atualiza os pesos do modelo. Cada época itera sobre os lotes, realizando uma passagem para frente, calculando a perda, a retropropagação e as atualizações de peso.
Execute o bloco de código e você obterá uma saída como esta: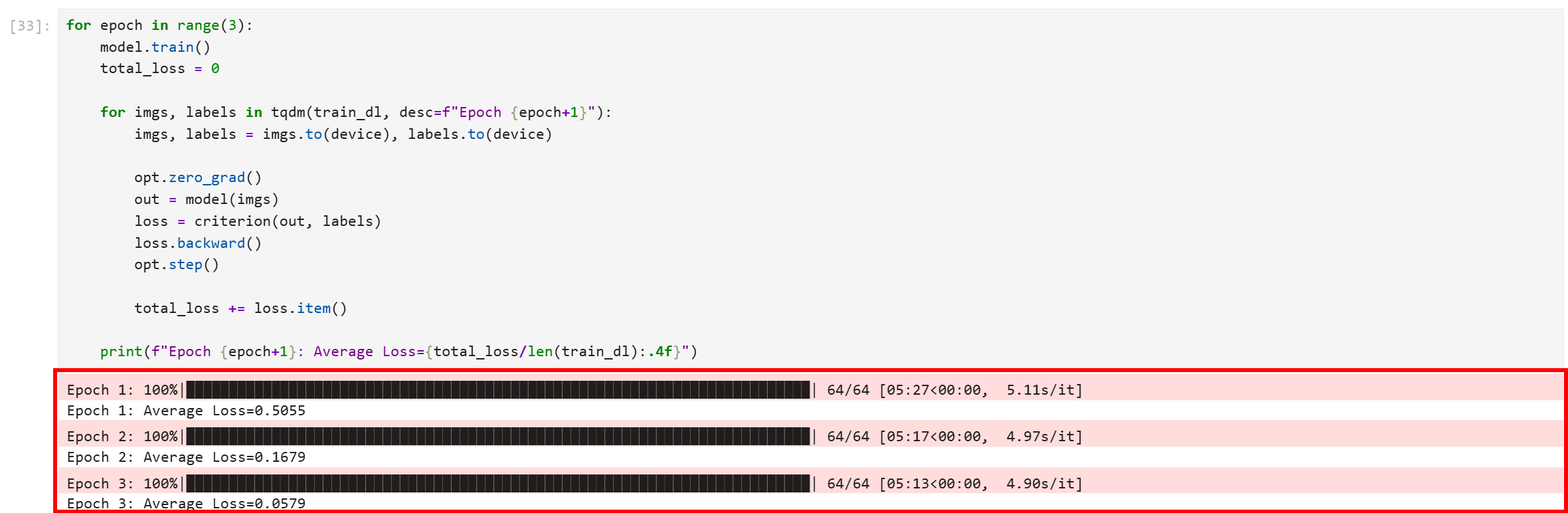
Observe que todas as três épocas foram concluídas com sucesso. A perda média final é 0,0579, o que é bastante baixo e indica que o modelo convergiu bem e aprendeu a distinguir entre as imagens de treinamento com alta confiança.
Pronto! Você acabou de ajustar uma CNN para distinção de qualidade de imagem em comércio eletrônico.
Etapa 9: Avalie o desempenho do modelo
Para verificar o desempenho do modelo, execute uma etapa de avaliação:
# Carregue a versão de avaliação do modelo
model.eval()
# Para acompanhar as imagens processadas
correct = 0
total = 0
# Avaliando o modelo em relação ao conjunto de dados de treinamento
with torch.no_grad():
for images, labels in test_dl:
images, labels = images.to(device), labels.to(device)
out = model(images)
prediction = out.argmax(dim=1)
correct += (prediction == labels).sum().item()
total += len(labels)
# Exibir os resultados
print("Precisão do teste:", correct / total)Isso mede o quão bem o modelo ajustado generaliza em dados que nunca viu antes (o conjunto de dados de teste). Especificamente, ele realiza a avaliação do modelo por meio de inferência.
A célula de código primeiro muda o modelo para o modo de avaliação e desativa o rastreamento de gradiente para otimizar a velocidade e garantir um comportamento consistente. Em seguida, o loop itera pelo conjunto de dados de teste, comparando as previsões do modelo com os rótulos reais. Por fim, ele calcula a precisão total, fornecendo uma métrica clara da capacidade do modelo de generalizar além do conjunto de treinamento.
O resultado deve ser algo como:

Uma pontuação de precisão de teste de 0,924XXX significa que seu modelo ResNet-18 ajustado classificou corretamente mais de 92,4% das imagens de produtos em seus Conjuntos de dados de teste não vistos como “BOM” ou “RUIM”.
Isso pode ser considerado um excelente resultado para classificação binária em dados do mundo real, como imagens de produtos de comércio eletrônico. Isso sugere fortemente que o modelo aprendeu com sucesso a diferença entre recursos de boa e má qualidade de imagem e não está apenas memorizando os dados de treinamento.
Muito bem! Agora vamos aplicar o modelo ajustado em algumas imagens novas para ver se ele funciona como esperado.
Etapa 10: utilize o modelo de ML para prever a qualidade da imagem
Para validar verdadeiramente se o modelo ajustado funciona como esperado, você deve testar seu desempenho em imagens que ele nunca encontrou. Como o modelo é treinado para funcionar com qualquer imagem de produto de comércio eletrônico, você pode testá-lo com imagens de plataformas como eBay, Walmart, Alibaba ou seus próprios bancos de dados internos de produtos.
Nesta demonstração, testaremos o modelo com as duas imagens de produtos a seguir, obtidas no eBay:
Para fazer isso, adicione o seguinte código em um bloco dedicado:
def predict_image_quality(img: Image.Image) -> str:
# Defina o modelo para o modo de avaliação
model.eval()
# Aplique transformações e adicione uma dimensão de lote
x = transform(img).unsqueeze(0).to(device)
with torch.no_grad():
# Passagem direta, obtenha o índice de classe previsto e extraia-o como um escalar
prediction = model(x).argmax().item()
# Retorne a string do resultado
return "GOOD" if prediction == 1 else "BAD"
# Imagens de teste
image_urls = ["https://i.ebayimg.com/images/g/N5kAAOSwTlplqFTa/s-l500.webp", "https://i.ebayimg.com/images/g/yUsAAOSweMJd67Jd/s-l1600.webp"]
# Percorrer URLs de imagens, baixar, prever e exibir
para image_url em image_urls:
# Baixar o conteúdo da imagem usando solicitação HTTP
response = requests.get(image_url)
image = Image.open(io.BytesIO(response.content)).convert("RGB")
# Chamar a função de previsão
qualidade = predict_image_quality(imagem)
# Exibir a imagem no notebook junto com os resultados do modelo
exibir(imagem)
imprimir(image_url, "→", qualidade)Ao executar a célula, você observará as seguintes classificações:
Observe que o modelo classificou a imagem como “RUIM”. Esse é um resultado correto, pois a imagem é visivelmente de baixa qualidade, está borrada e o fundo não tem contraste nítido, não destacando o produto adequadamente.
Em vez disso, na segunda imagem, ele produz:
Desta vez, a classificação é “GOOD” (BOM), o que é um resultado convincente, considerando que a imagem é visualmente atraente, nítida e bem iluminada. Além disso, ela mostra claramente o produto.
Et voilà! Graças aos ricos Conjuntos de dados da Bright Data, você recuperou dados de produtos de comércio eletrônico (neste caso, da Amazon). Em seguida, você aplicou o PyTorch para ajustar uma CNN para reconhecimento de imagem, seguindo uma abordagem de análise de dados ML multimodal.
Conclusão
Nesta postagem do blog, você viu como implementar um sistema de aprendizado de máquina multimodal. Usamos conjuntos de dados de produtos contendo centenas de milhões de produtos da Amazon e suas imagens correspondentes.
Ao alimentar esses dados em um fluxo de trabalho PyTorch dentro de um notebook Python, você ajustou com sucesso uma CNN (rede neural convolucional) para classificar imagens de produtos de comércio eletrônico como boas ou ruins.
Este projeto atende diretamente às necessidades de pequenas e médias empresas ou grandes corporações que buscam maneiras de avaliar rapidamente a qualidade da imagem para representação de produtos, especialmente para fins de comércio eletrônico.
Tudo isso não seria possível sem os serviços de dados empresariais da Bright Data, que ajudam você a coletar dados de mais de 100 domínios, incluindo Amazon, Walmart, LinkedIn, Zillow, Airbnb, Yahoo Finance e muitos outros.
Cadastre-se hoje mesmo para obter uma conta na Bright Data e testar nossas soluções de dados gratuitamente!





