
Neste artigo, você aprenderá:
- O que é o Alteryx One e quais recursos ele oferece.
- Por que conectá-lo a dados web da Bright Data torna os workflows mais informativos.
- Como definir um workflow automatizado no Alteryx One usando dados web estruturados e atualizados, obtidos por meio do web scraping da Bright Data.
Vamos começar!
O que é o Alteryx One?
Alteryx One é uma plataforma de analytics unificada e baseada em IA. Ela reúne preparação de dados, analytics, automação e IA em um único ambiente. Em detalhes, ajuda organizações a se conectarem a múltiplas fontes de dados, criar workflows reutilizáveis e operacionalizar insights em escala.
Os principais recursos oferecidos pelo Alteryx One são:
- Analytics nativo em IA: Integre IA aos workflows de analytics para detectar padrões, gerar insights e apoiar modelagem preditiva sem ferramentas separadas.
- Preparação de dados pronta para IA: Conecte, limpe e transforme dados de múltiplas fontes em conjuntos de dados confiáveis e prontos para análise, com governança integrada.
- Automação de workflows: Automatize tarefas repetitivas de analytics e processos de ponta a ponta, reduzindo o esforço manual e melhorando a consistência.
- Workspace de analytics unificado: Ofereça um único ambiente onde as equipes podem criar, executar e gerenciar workflows de analytics de forma colaborativa.
- Governança e segurança empresarial: Garanta conformidade, rastreamento de linhagem e controle de acesso para que o analytics possa escalar com segurança em grandes organizações.
- Integrações extensíveis: Conecte-se a sistemas empresariais e LLMs para incorporar analytics diretamente nos ecossistemas de dados existentes.
Como a Bright Data Apoia o Alteryx One
Os workflows do Alteryx One são tão poderosos quanto os dados que consomem. Claro, a plataforma oferece recursos robustos para preparação de dados, analytics e automação. No entanto, a qualidade, atualidade e confiabilidade dos dados de entrada determinam, em última análise, a precisão dos resultados. É aqui que a Bright Data desempenha um papel fundamental como provedor de dados web de nível empresarial!
A Bright Data fornece dados web estruturados em larga escala por meio de uma infraestrutura global de proxies com mais de 400 milhões de IPs em 195 países. Com 99,99% de uptime e uma taxa de sucesso de 99,95%, ela oferece a confiabilidade necessária para pipelines de analytics em produção.
Para uma integração direta com o Alteryx One, você pode começar recuperando dados web atualizados usando as Web Scraping APIs da Bright Data ou acessando dados web estáticos por meio dos datasets da Bright Data. Esses dados podem ser entregues automaticamente ao Amazon S3 (ou qualquer outro destino de entrega comum) em formato estruturado.
O Alteryx One pode então importar esse dataset diretamente do S3, onde ele é processado por meio de um workflow sem código. Por fim, os resultados processados são gravados de volta no S3 (ou em qualquer destino preferido) para uso posterior.
O resultado é um pipeline de analytics automatizado de ponta a ponta. Aqui, a Bright Data garante a ingestão de dados confiável e de nível empresarial, enquanto o Alteryx One transforma esses dados em insights acionáveis.
Crie um Workflow Automatizado de Análise de Dados no Alteryx One com Dados Web da Bright Data
Neste capítulo passo a passo, você será guiado pela configuração de um workflow automatizado no Alteryx One.
Para demonstrar esse tipo de workflow de automação web, você utilizará os seguintes componentes:
- O Yahoo Finance Scraper da Bright Data para coletar dados de ações em tempo real, configurando-o para entrega no Amazon S3.
- Um workflow do Alteryx One que importa os dados, os ordena por volume e os divide em dois datasets: um para ações positivas e outro para ações negativas. Em seguida, grava os resultados processados de volta no Amazon S3.
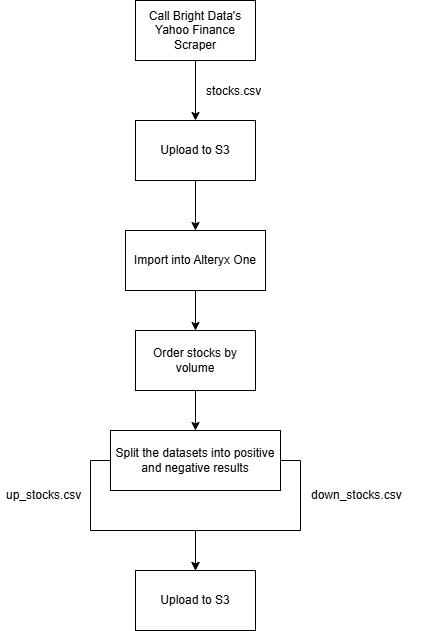
Siga as instruções abaixo para criar este workflow!
Pré-requisitos
Para seguir esta seção, certifique-se de ter:
- Uma conta no Alteryx One (mesmo uma em teste gratuito é suficiente).
- Um bucket S3 definido em sua conta AWS.
- Uma conta na Bright Data com uma chave de API configurada. Siga as instruções oficiais para gerar sua chave de API.
Neste tutorial, assumiremos que seu bucket S3 se chama bright-data-datasets. No entanto, qualquer outro nome de bucket também funcionará.
Passo #1: Configure a API de Scraping da Bright Data
O primeiro passo no seu pipeline de automação de dados web é recuperar os dados de origem da web. Para isso, você utilizará o Yahoo Finance Scraper da Bright Data para coletar dados financeiros em tempo real. Vamos começar!
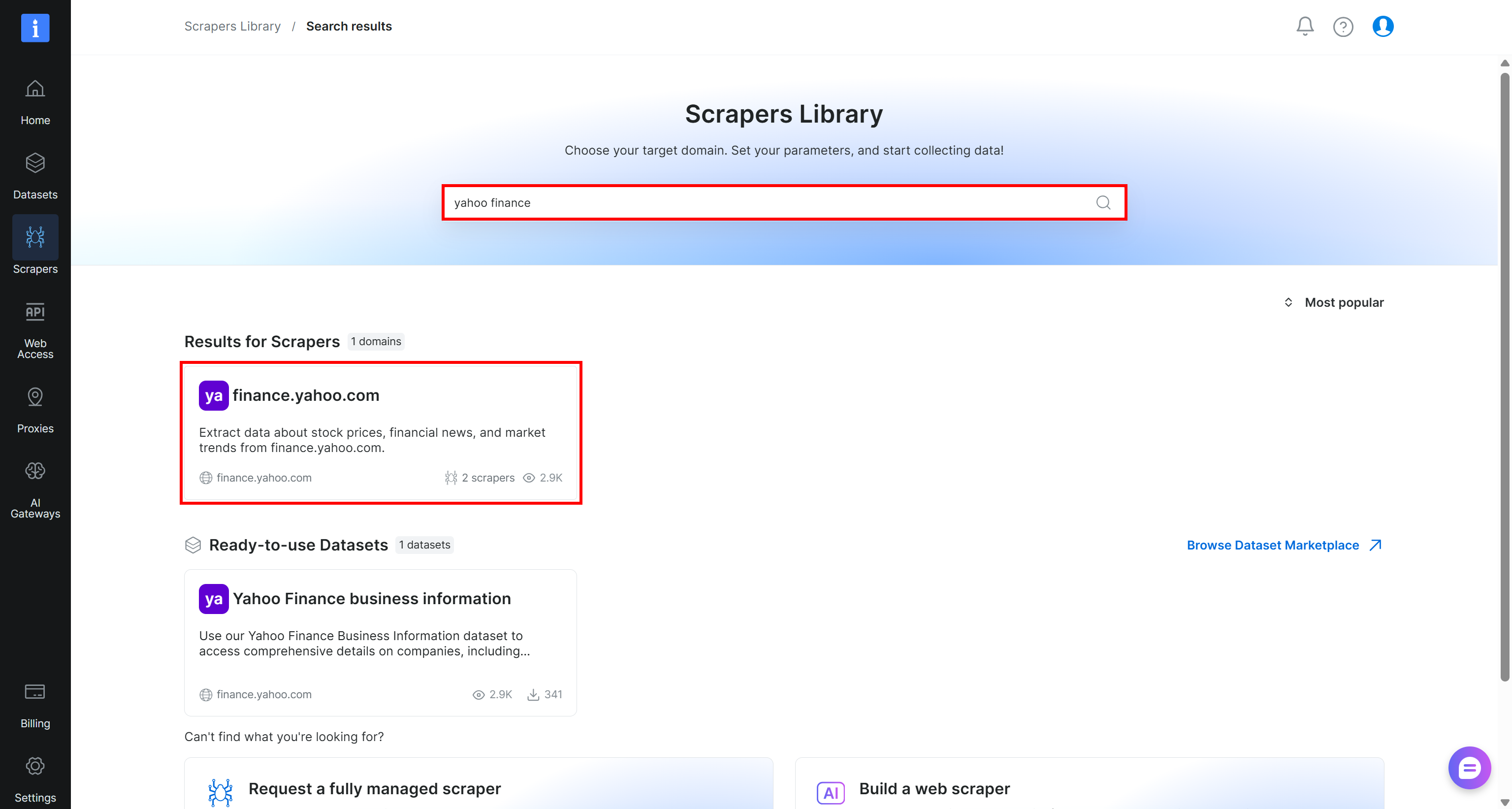
Comece criando uma conta na Bright Data, caso ainda não tenha uma. Caso contrário, faça login na sua conta existente. No painel de controle, navegue até a página “Scrapers > Scrapers Library”:
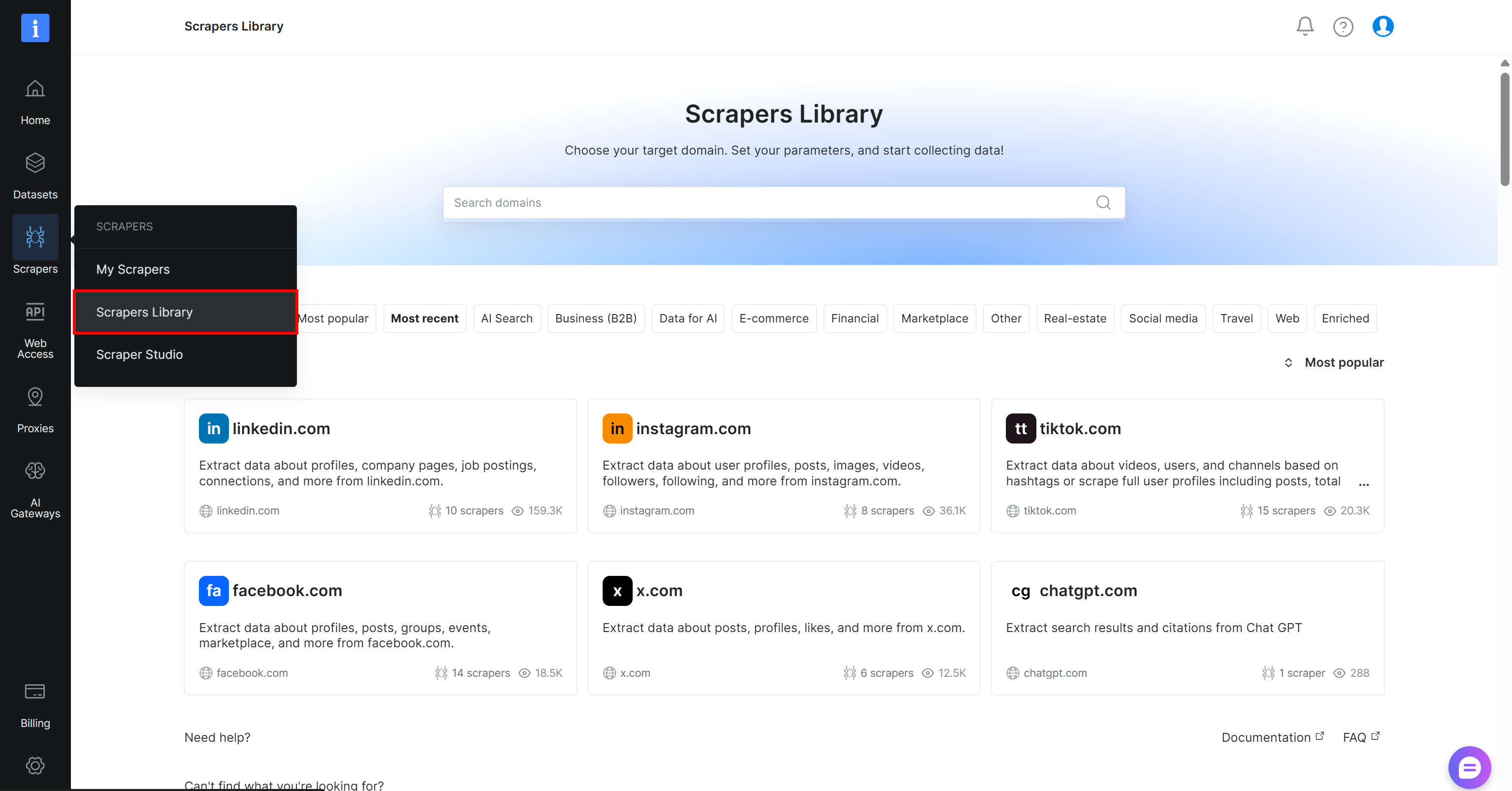
Pesquise por “yahoo finance” e selecione o scraper “finance.yahoo.com”:
Na página do Yahoo Finance Scraper, revise os requisitos de entrada e o esquema de saída do scraper:
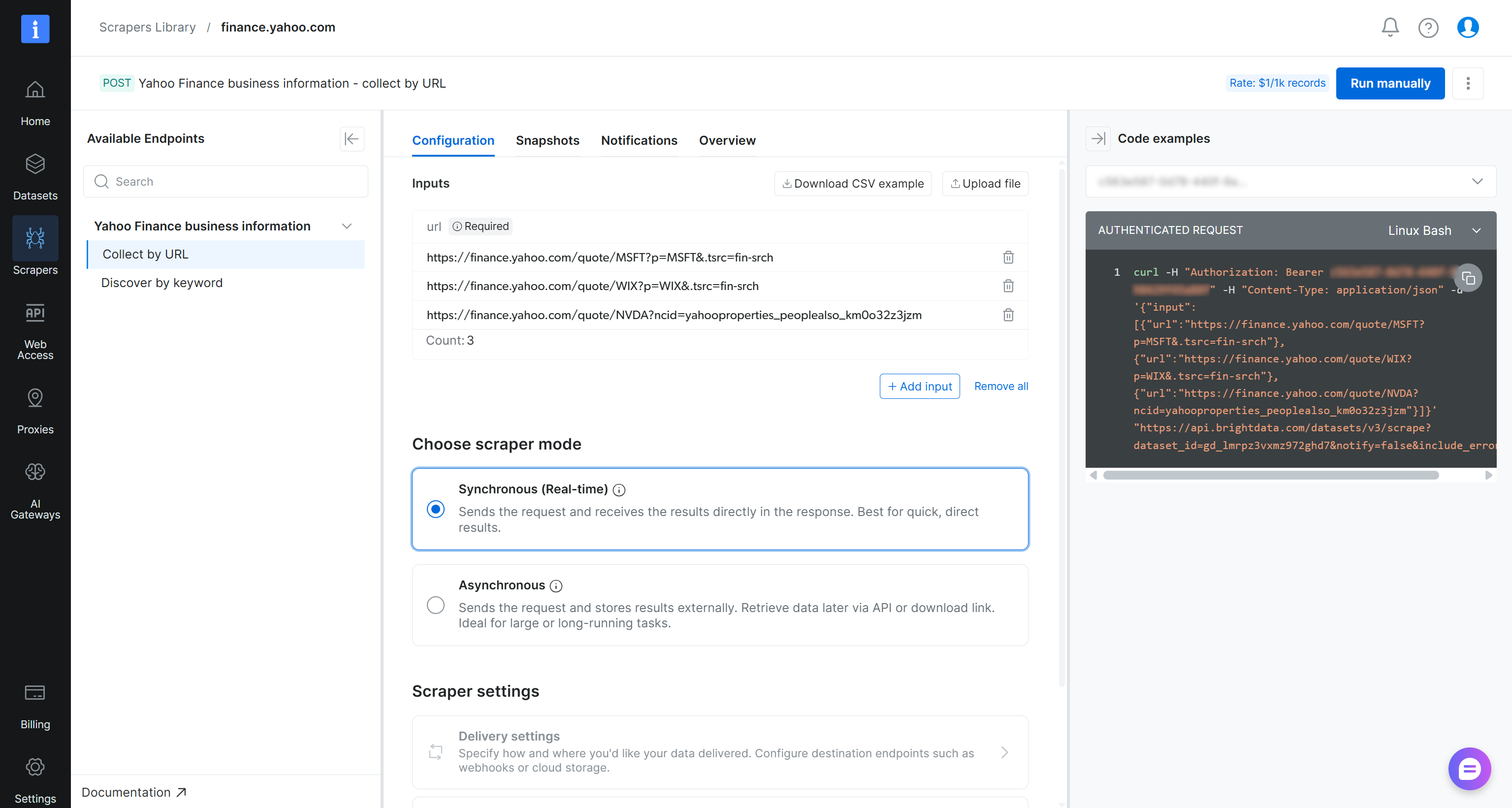
Em linhas gerais, o scraper aceita uma ou mais URLs de páginas de ações do Yahoo Finance como entrada e retorna dados financeiros estruturados em tempo real. Exatamente o que precisamos!
Passo #2: Configure a Entrega para o S3
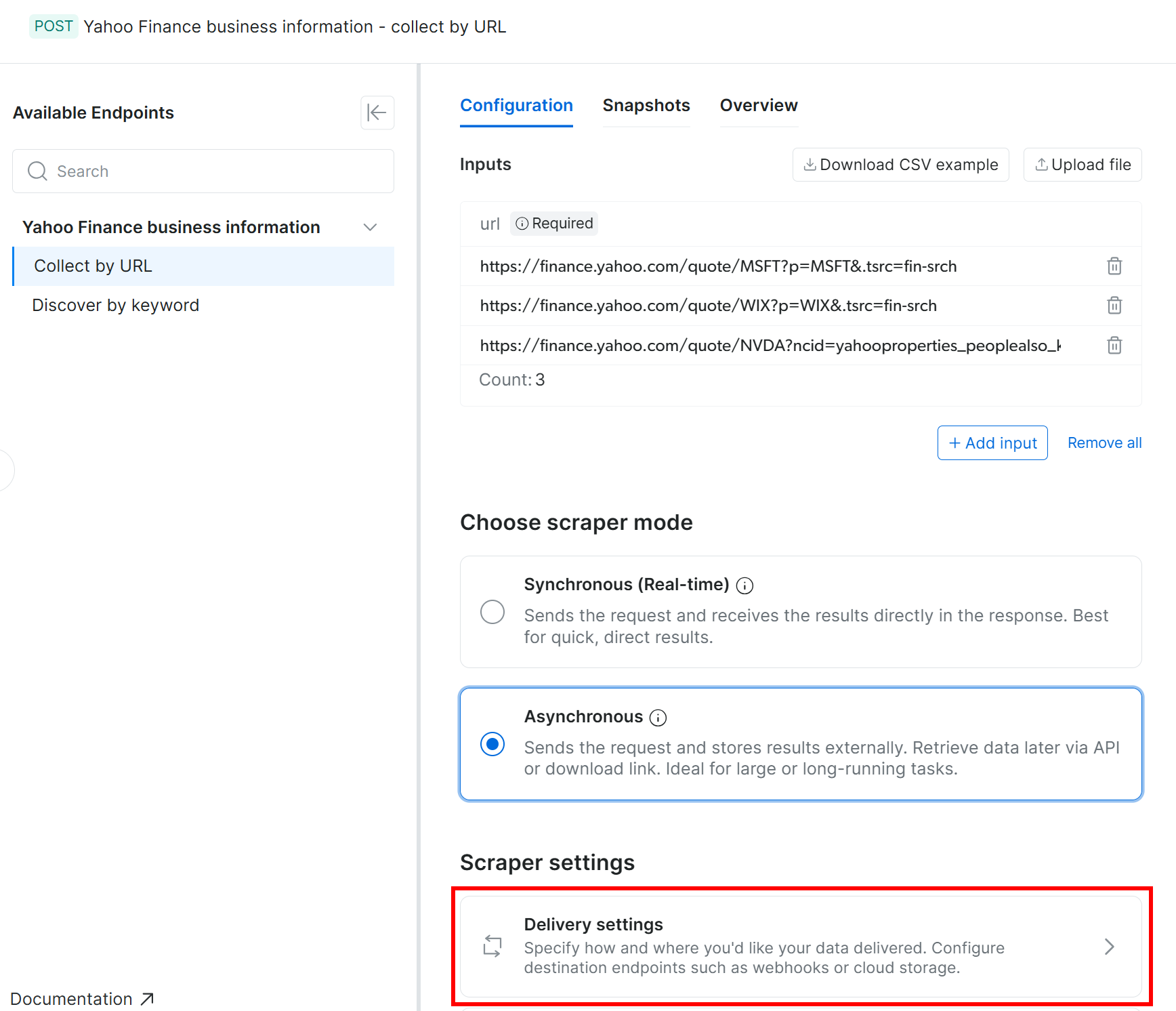
As Web Scraping APIs da Bright Data suportam entrega automática de dados coletados para o Amazon S3 (além de vários outros provedores de armazenamento em nuvem e métodos de entrega). Para habilitar a entrega ao Amazon S3, você primeiro precisa alternar o scraper para o modo assíncrono.
Na aba “Configuration”, selecione a opção “Asynchronous”. Em seguida, clique em “Delivery settings”:
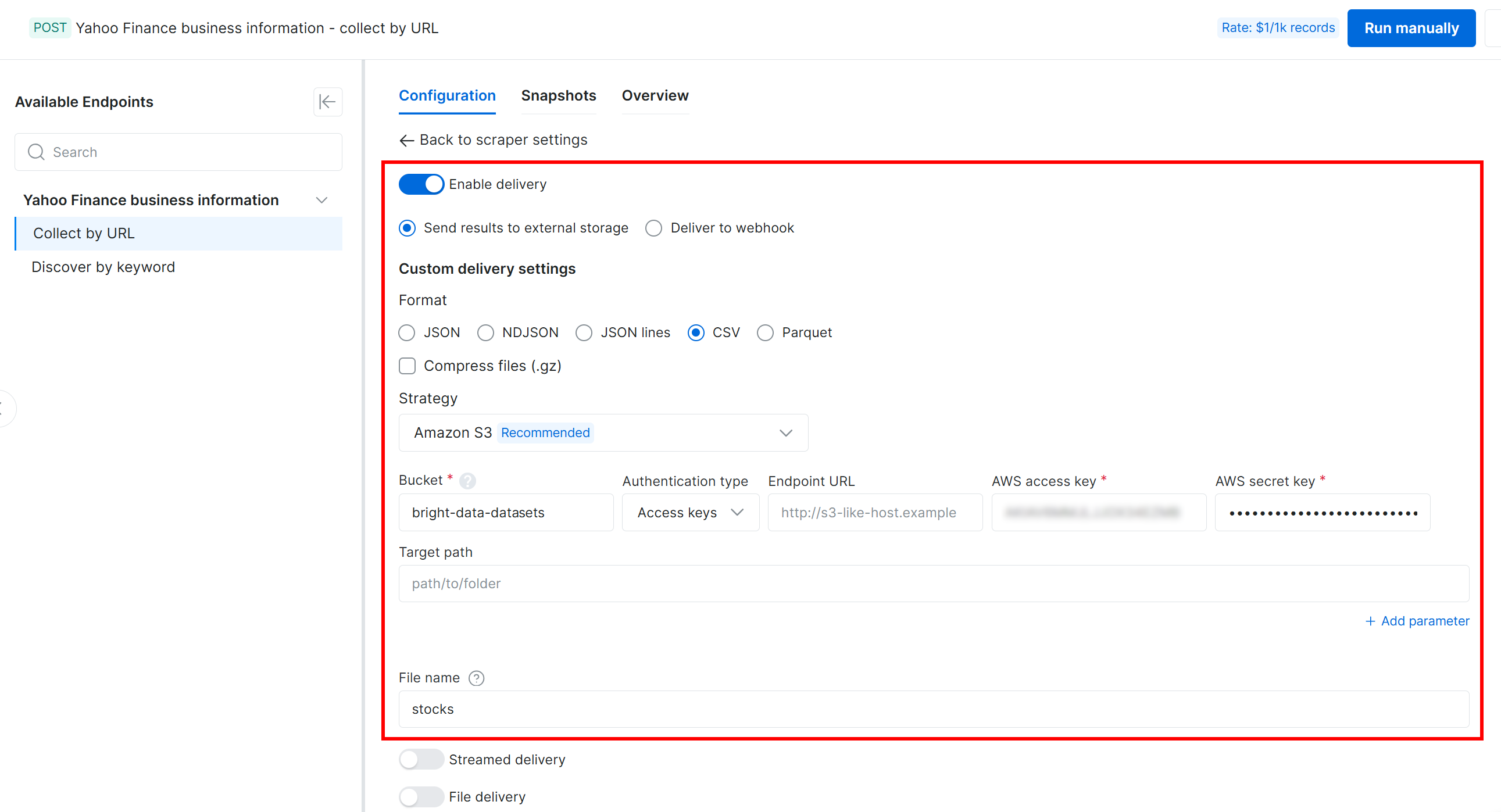
Em seguida, configure a entrega para o seu bucket Amazon S3 usando as seguintes configurações:
- Ative o toggle “Enable delivery”.
- Defina o formato de saída dos dados como CSV.
- Selecione “Amazon S3” como destino de armazenamento.
- Insira o nome do seu bucket S3 (neste exemplo,
bright-data-datasets). (Você pode deixar o campo “Endpoint URL” vazio.) - Deixe o campo “Target path” vazio para fazer o upload do arquivo na pasta raiz do bucket.
- Defina a opção “Authentication type” como “Access keys”.
- Cole seu AWS Access Key ID e AWS Secret Access Key.
- Defina o nome do arquivo como
stocks.
Com essa configuração, a Web Scraping API é executada em modo assíncrono. Em vez de retornar os dados imediatamente, a Bright Data cria um job de scraping que é executado em sua infraestrutura. Quando o job é concluído, os dados coletados são automaticamente enviados para o seu bucket Amazon S3. Prático e sem intervenção manual!
Passo #3: Execute a Tarefa de Recuperação de Dados Web
Para verificar se o workflow de extração de dados web funciona corretamente, adicione algumas URLs de ações do Yahoo Finance como entrada. Neste exemplo, assumiremos que você deseja acompanhar as 10 principais ações da Nasdaq (ou seja, NVDA, AAPL, GOOGL, MSFT, AMZN, TSLA, META, AVGO, WMT e AMD).
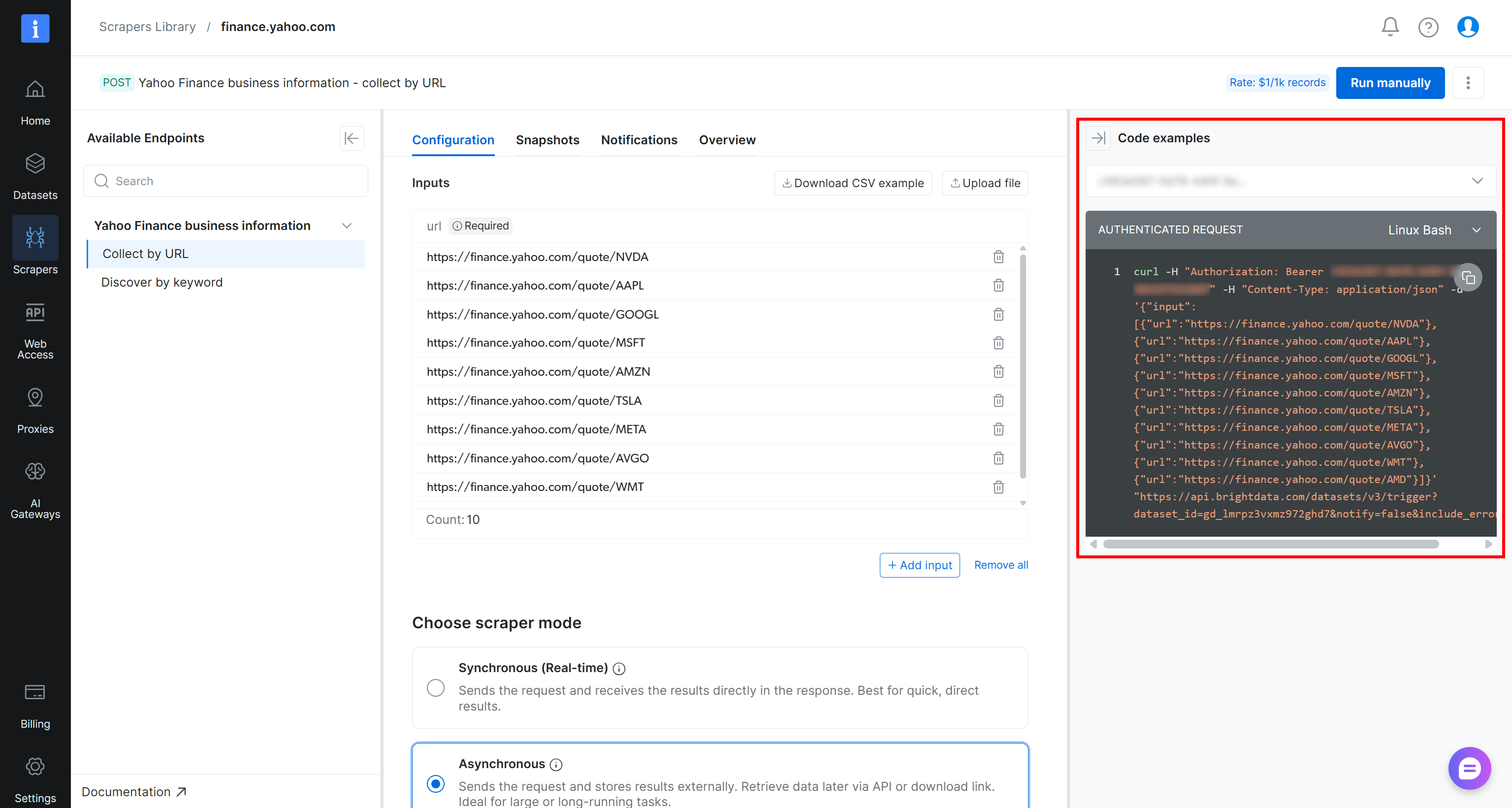
Para acionar a tarefa de scraping de forma programática, você pode usar o snippet cURL fornecido na página do scraper:
curl -H "Authorization: Bearer <YOUR_BRIGHT_DATA_API_KEY>" -H "Content-Type: application/json" -d '{"input":[{"url":"https://finance.yahoo.com/quote/NVDA"},{"url":"https://finance.yahoo.com/quote/AAPL"},{"url":"https://finance.yahoo.com/quote/GOOGL"},{"url":"https://finance.yahoo.com/quote/MSFT"},{"url":"https://finance.yahoo.com/quote/AMZN"},{"url":"https://finance.yahoo.com/quote/TSLA"},{"url":"https://finance.yahoo.com/quote/META"},{"url":"https://finance.yahoo.com/quote/AVGO"},{"url":"https://finance.yahoo.com/quote/WMT"},{"url":"https://finance.yahoo.com/quote/AMD"}]}' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lmrpz3vxmz972ghd7¬ify=false&include_errors=true"Como alternativa, você pode executar o seguinte script Python:
# pip install requests
import requests
import json
headers = {
"Authorization": "Bearer <YOUR_BRIGHT_DATA_API_KEY>",
"Content-Type": "application/json",
}
data = json.dumps({
"input": [{"url":"https://finance.yahoo.com/quote/NVDA"},{"url":"https://finance.yahoo.com/quote/AAPL"},{"url":"https://finance.yahoo.com/quote/GOOGL"},{"url":"https://finance.yahoo.com/quote/MSFT"},{"url":"https://finance.yahoo.com/quote/AMZN"},{"url":"https://finance.yahoo.com/quote/TSLA"},{"url":"https://finance.yahoo.com/quote/META"},{"url":"https://finance.yahoo.com/quote/AVGO"},{"url":"https://finance.yahoo.com/quote/WMT"},{"url":"https://finance.yahoo.com/quote/AMD"}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lmrpz3vxmz972ghd7¬ify=false&include_errors=true",
headers=headers,
data=data
)
print(response.json())Em ambos os casos, certifique-se de substituir <YOUR_BRIGHT_DATA_API_KEY> pela sua chave de API da Bright Data.
Nota: Para uma abordagem ainda mais simples, execute a tarefa clicando no botão “Run manually” diretamente no painel de controle.
Uma vez acionada, a solicitação de scraping será enviada à infraestrutura em nuvem da Bright Data, onde a tarefa de extração terá início. Você pode monitorar seu status em tempo real pelo painel de controle da Bright Data:
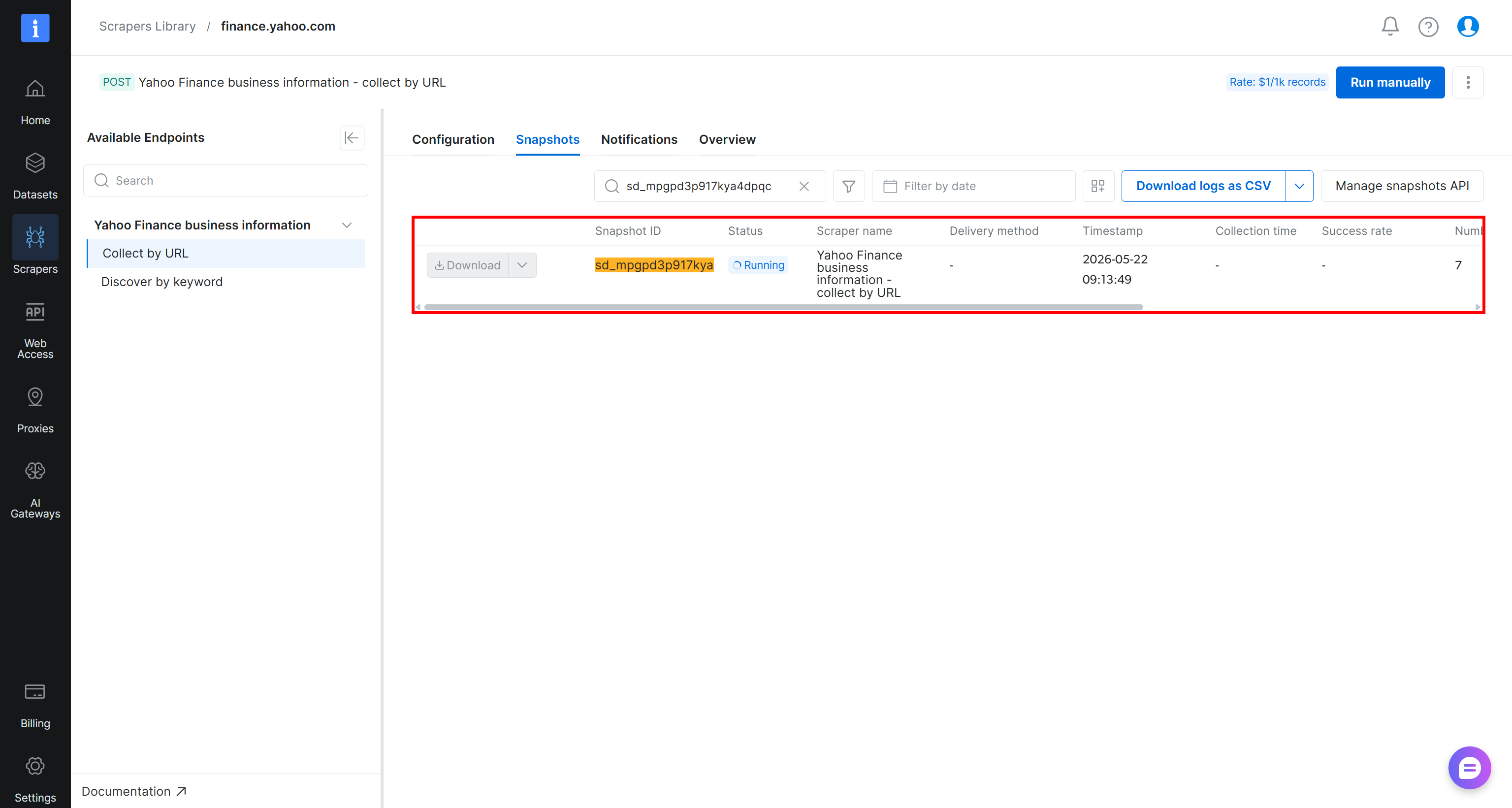
Quando o status da tarefa mudar para “Ready”, abra seu bucket Amazon S3. Você deverá notar um novo arquivo chamado stocks.csv:

Baixe o arquivo stocks.csv e abra-o. Você verá algo assim:
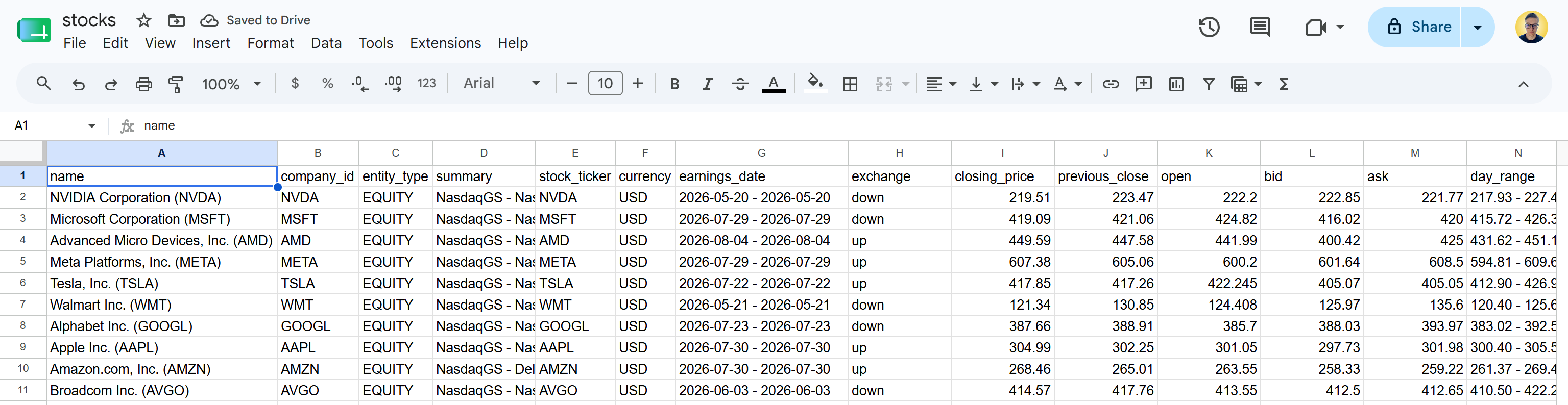
Esses são os mesmos dados de ações disponíveis nas páginas do Yahoo Finance especificadas. A API do Yahoo Finance Scraper da Bright Data recuperou os dados de ações e os transformou em um formato CSV estruturado.
Para entender melhor como os dados coletados estão estruturados e quais colunas estão disponíveis, consulte a seção “Dictionary” na aba “Overview” da página do scraper do Yahoo Finance:
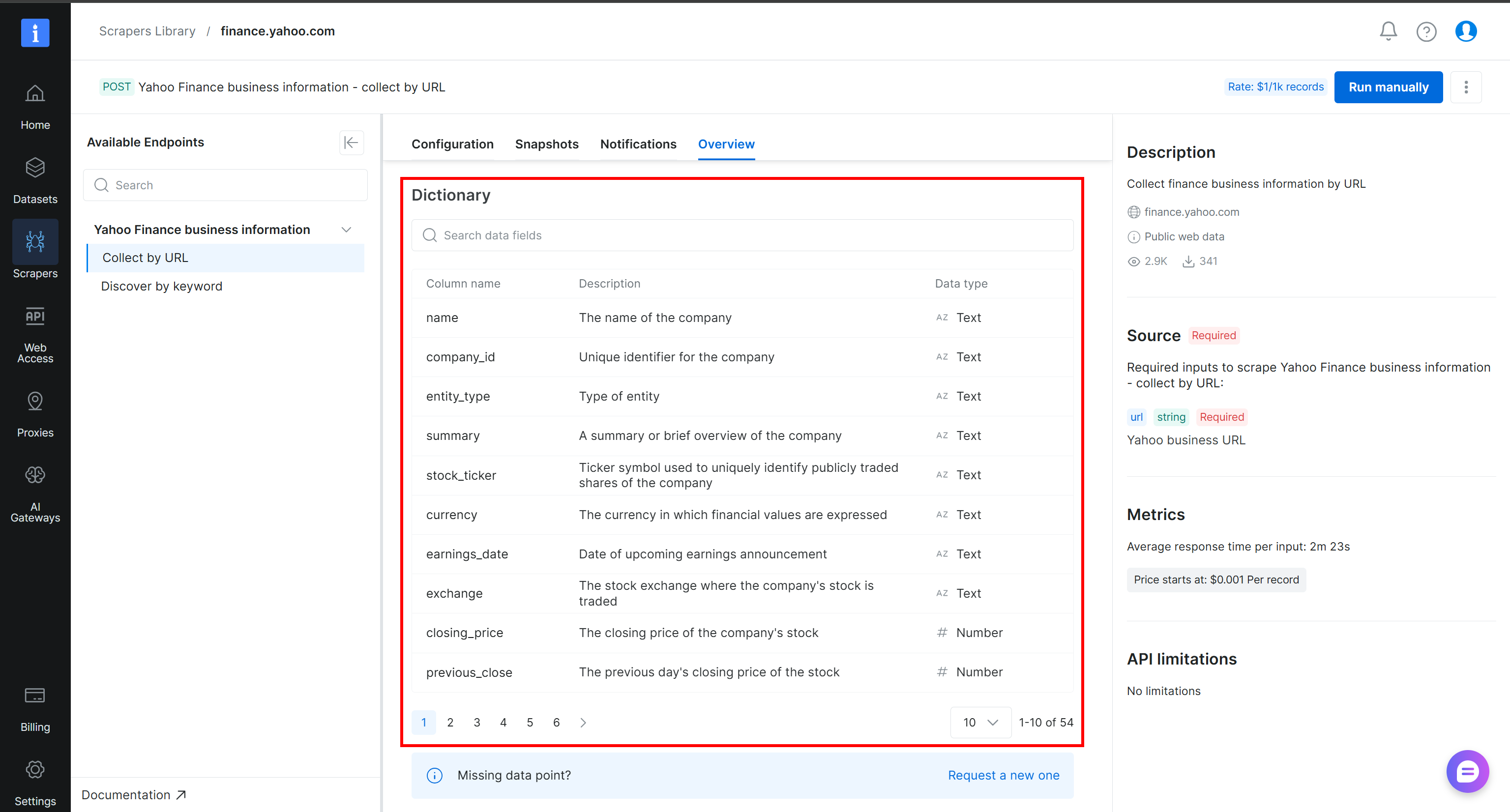
Ótimo! Agora você tem os dados necessários para criar seu pipeline de dados web no Alteryx One.
Passo #4: Conecte o Alteryx One à Fonte de Dados S3
Atualmente, os dados de origem coletados são entregues ao Amazon S3. O próximo passo é conectar sua conta do Alteryx One a esse bucket S3 para que os workflows possam acessar e analisar os dados conforme necessário.
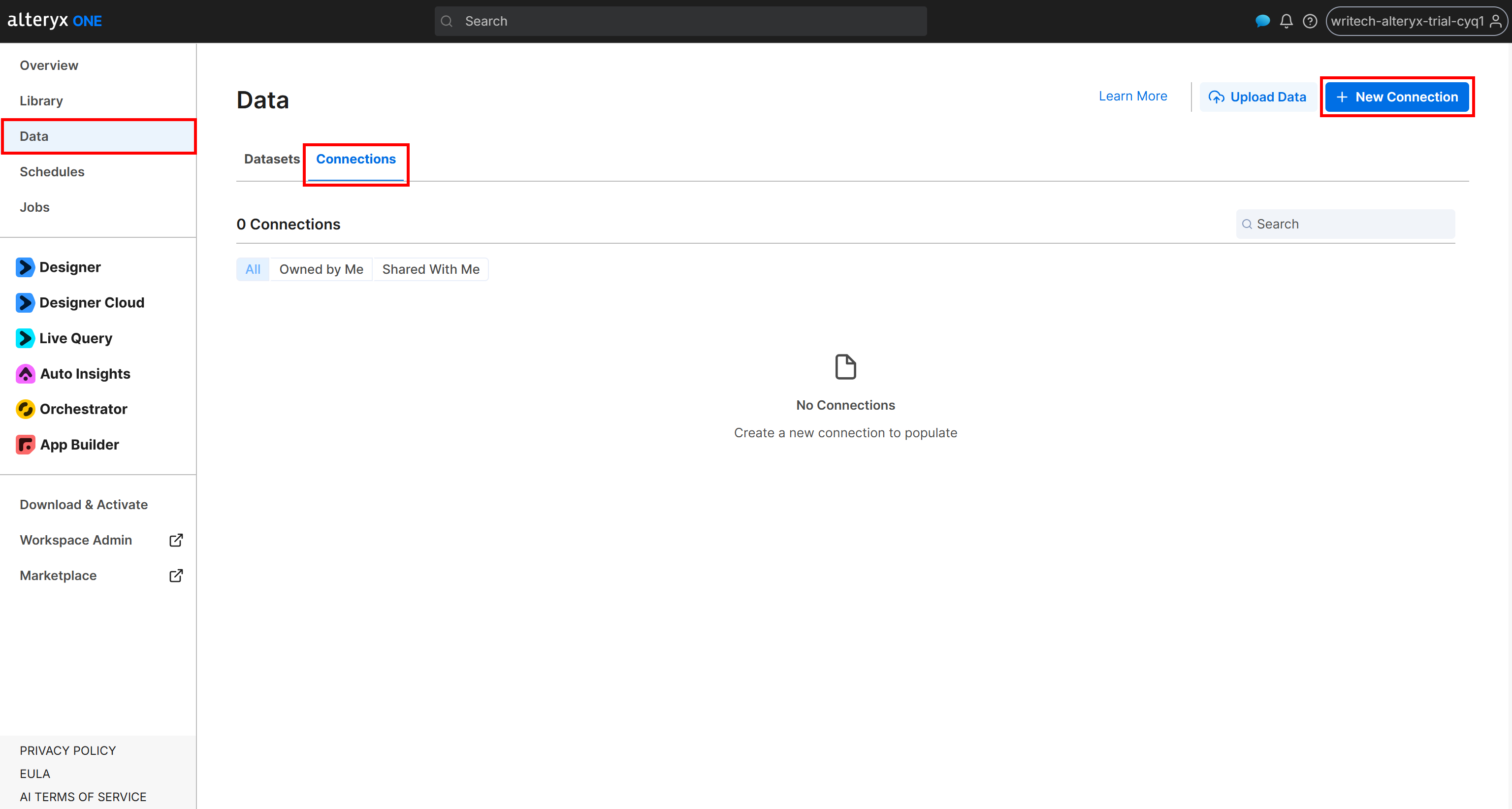
Para criar uma conexão com seu bucket Amazon S3, faça login no Alteryx One. Navegue até a página “Data” e abra a aba “Connections”. Em seguida, clique em “New Connection”:
Em seguida, preencha o formulário de conexão “External Amazon S3” da seguinte forma:
- Connection Name: Bright Data S3 (ou qualquer nome de sua preferência).
- Default Bucket:
bright-data-datasets(ou o nome real do seu bucket). - Access Key ID e Secret Access Key: Seu AWS Access Key ID e AWS Secret Access Key.
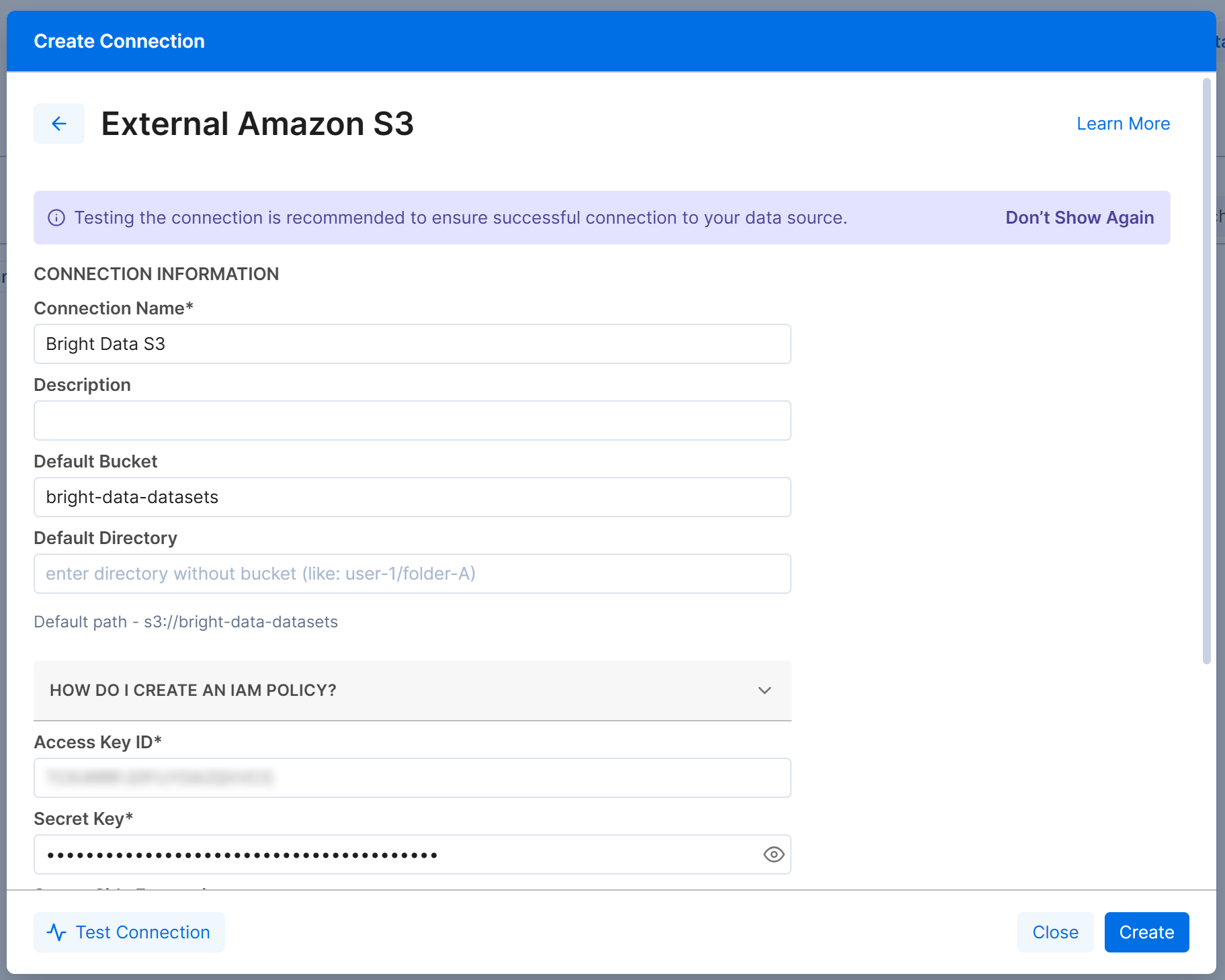
Clique em “Create” e a conexão com o Amazon S3 aparecerá na aba “Connections”:
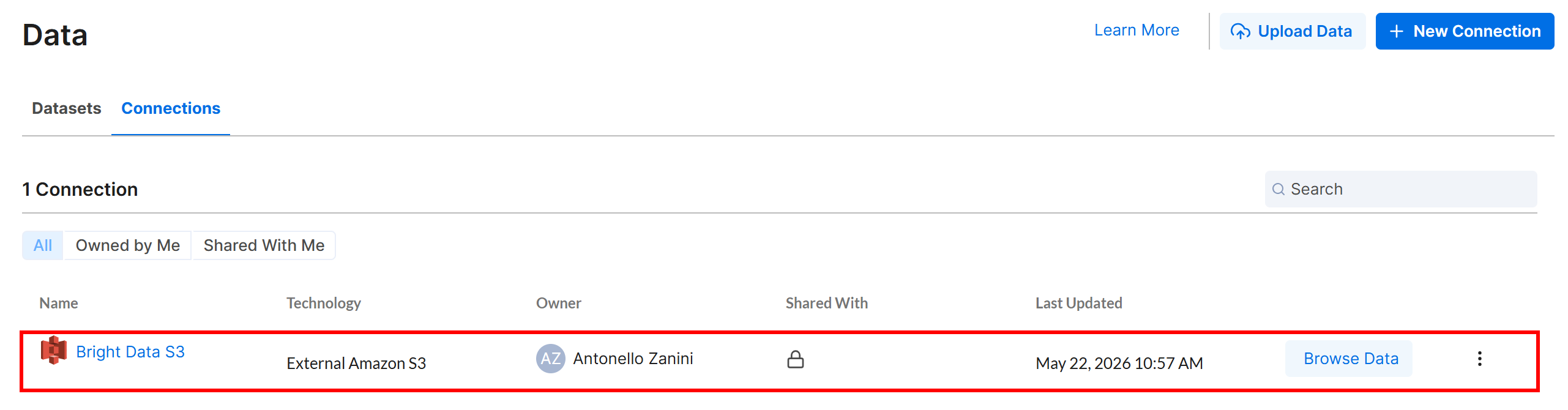
Excelente! Agora é hora de definir um workflow no Alteryx One que leia os dados de entrada do seu bucket Amazon S3, onde a API do Yahoo Finance Scraper armazena sua saída.
Passo #5: Inicialize o Workflow no Alteryx One
Acesse a página “Overview” e clique no botão “New Workflow with Designer Cloud”:
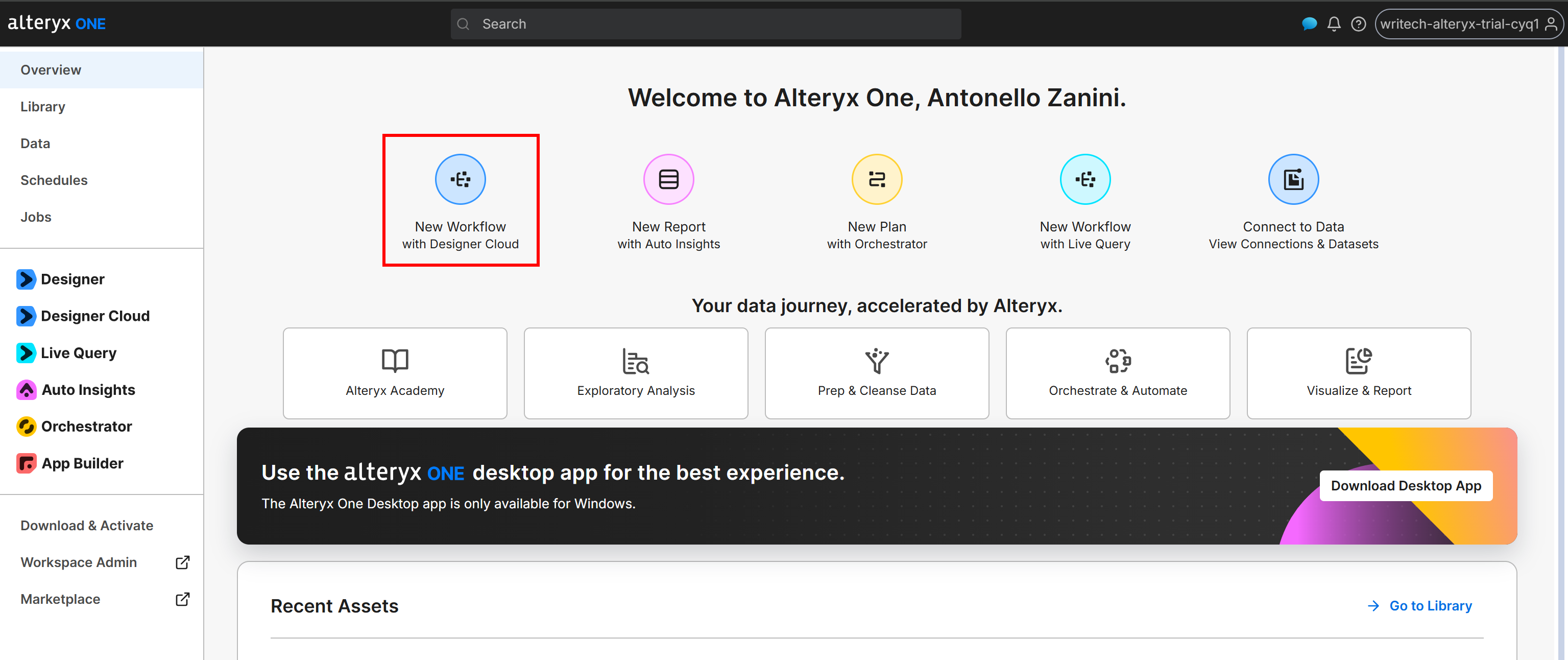
Como alternativa, você pode criar o workflow pelo aplicativo desktop do Alteryx One.
Dê um nome ao seu workflow, como “Automated Stock Analyzer”:
O primeiro passo na criação do workflow é carregar os dados de origem. Para isso, arraste o nó “Input Data” para o canvas do workflow:

Em seguida, clique duas vezes no nó para configurá-lo e conectá-lo ao seu bucket Amazon S3, selecionando o arquivo stocks.csv. Siga o assistente de configuração para importar o dataset. Após a conclusão, você deverá ver os dados carregados com sucesso:
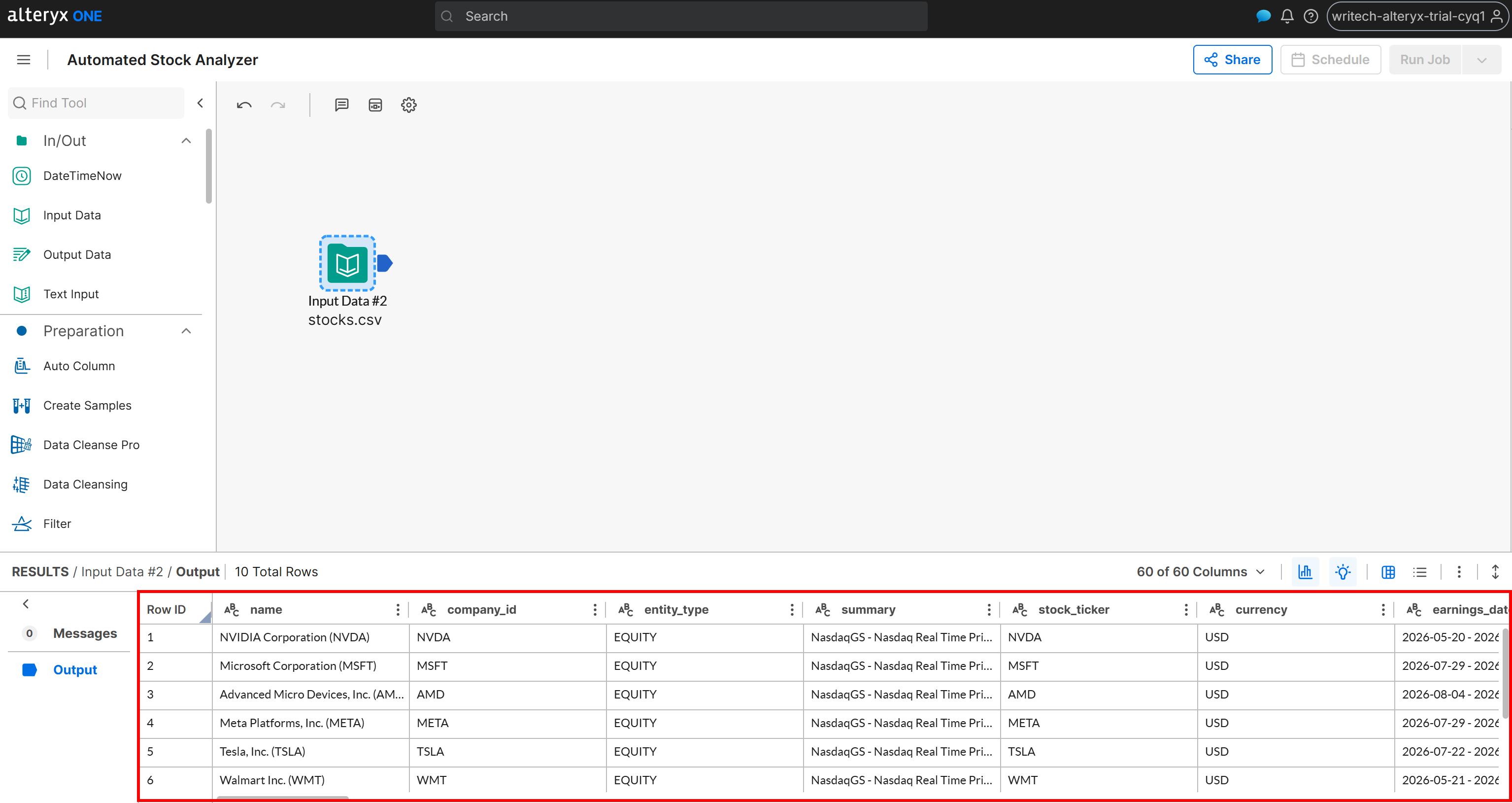
Neste ponto, o workflow tem acesso aos dados web coletados. Ótimo! Agora você pode começar a adicionar a lógica de análise de dados.
Passo #6: Defina a Lógica de Análise de Dados
Suponha que você queira que os resultados sejam ordenados por um critério específico, como o volume de negociação diário. Adicione um nó “Sort” e, na configuração de ordenação, selecione a coluna volume e defina a ordem como Ascending:
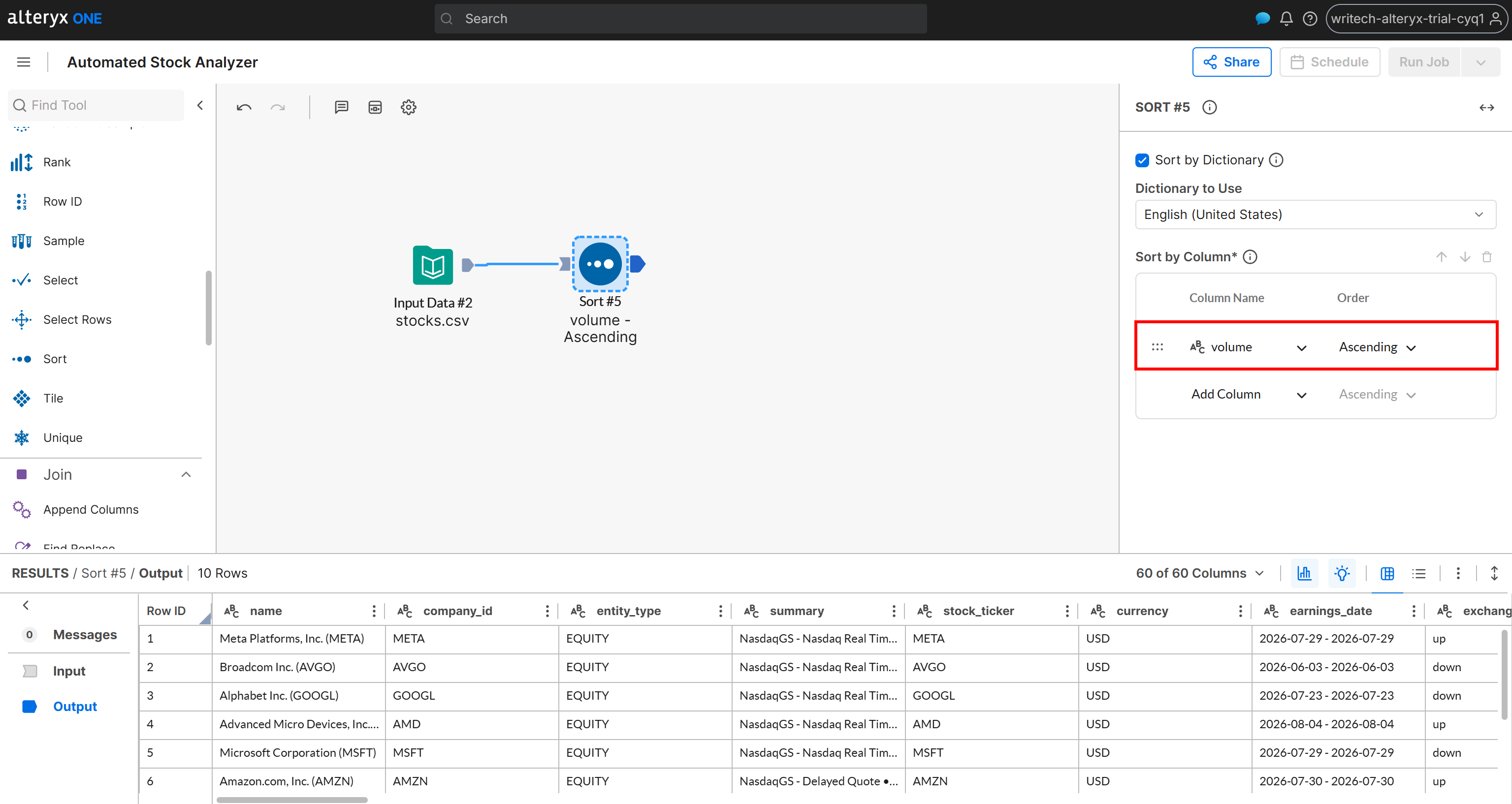
Agora, suponha que você queira dividir o dataset em dois grupos:
- Ações que fecharam o dia em território positivo.
- Ações que fecharam o dia em território negativo.
Para isso, classifique as ações com base em se o campo exchange contém “up” ou “down”. Adicione um nó “Filter” e conecte-o à saída do nó “Sort”. Em seguida, defina uma condição de filtro como:
- Column Name:
exchange - Operator: Equals
- Value:
up
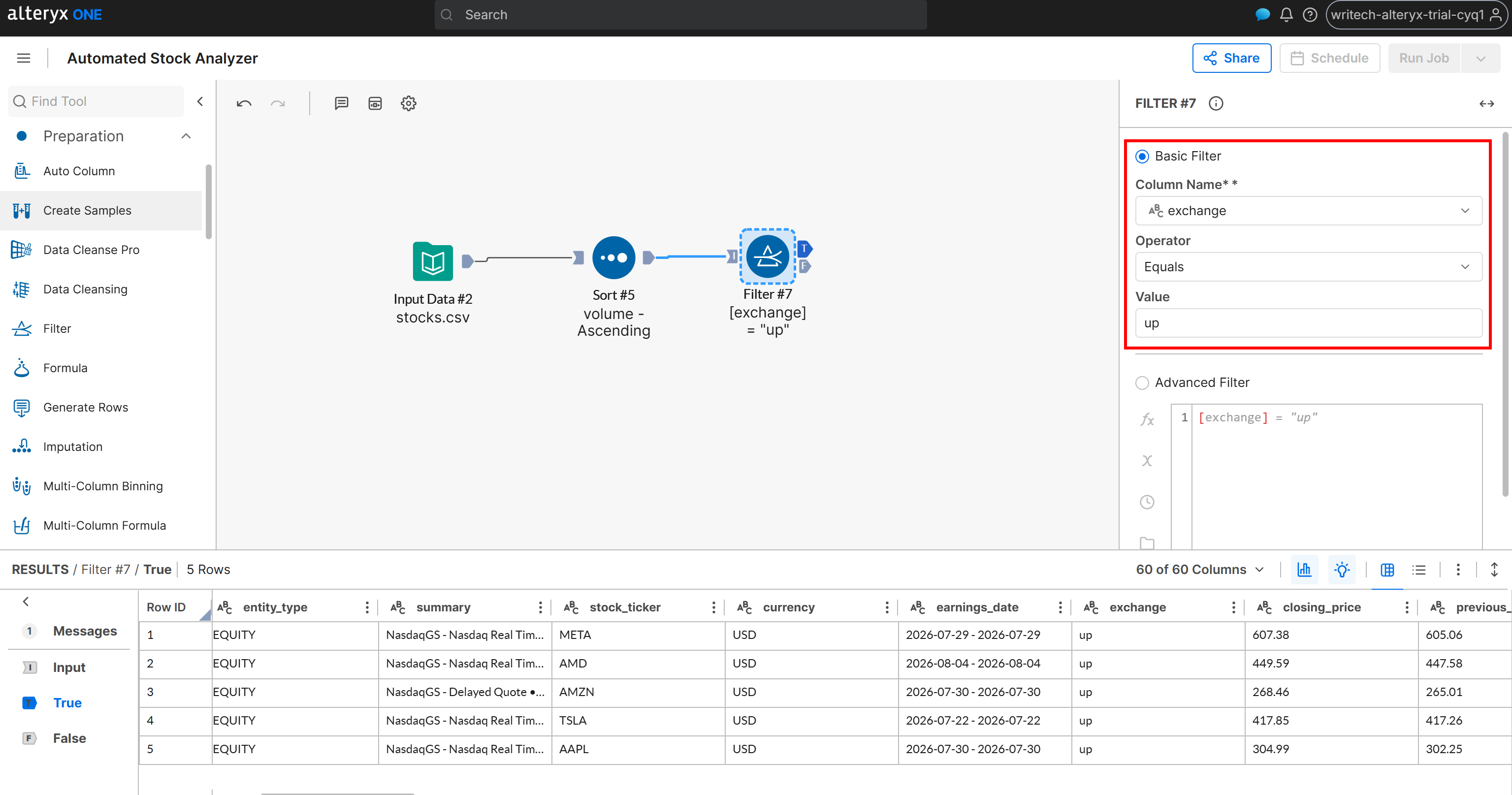
O nó Filter produz duas saídas:
T(True): Contém ações onde o campoexchangeé “up”.F(False): Contém ações onde o campoexchangenão é “up” (ou seja, é “down”).
O passo final neste simples workflow de automação web é definir os destinos de saída. Cuide disso!
Passo #7: Especifique os Arquivos de Saída
Adicione um nó “Output Data” ao canvas e conecte-o à saída T do nó “Filter”. Configure o nó “Output Data” para gravar os dados no seu bucket Amazon S3 (ou em qualquer outra fonte de dados conectada). Por exemplo, crie um arquivo chamado up_stocks.csv:
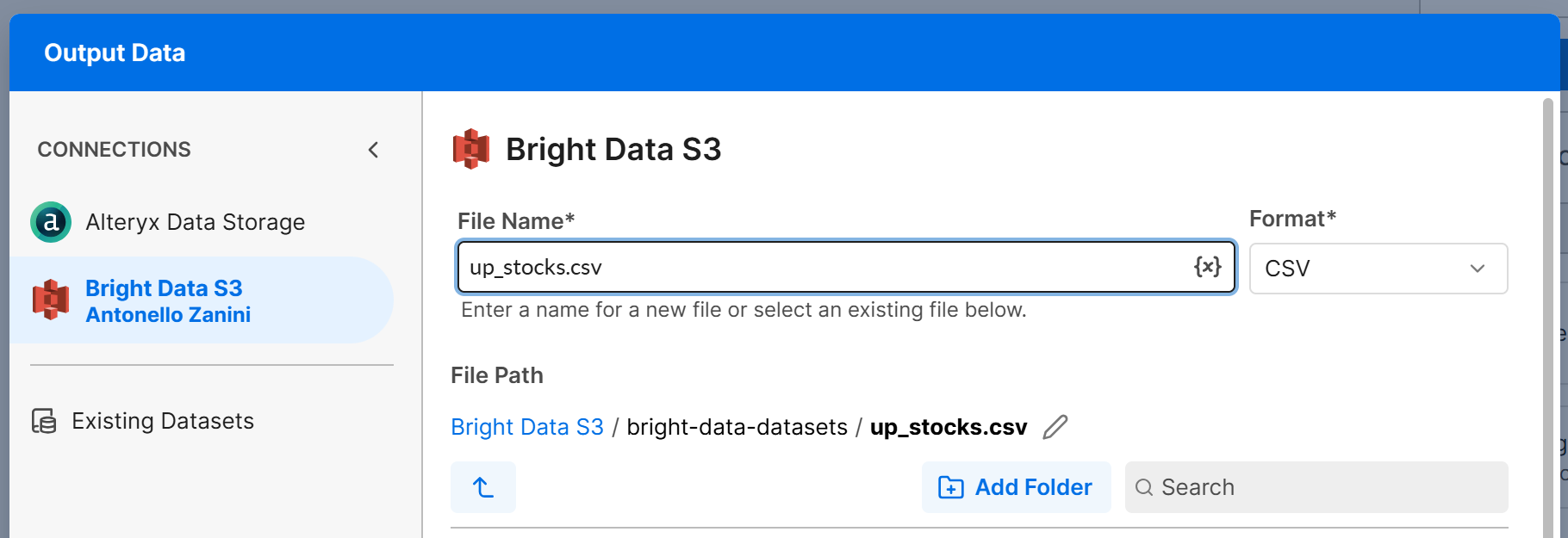
Clique em “Next” e depois em “Confirm” para salvar a configuração de saída do branch T. Repita o mesmo processo para o branch F e configure-o para gravar em um arquivo down_stocks.csv.
Este é o aspecto final do workflow:
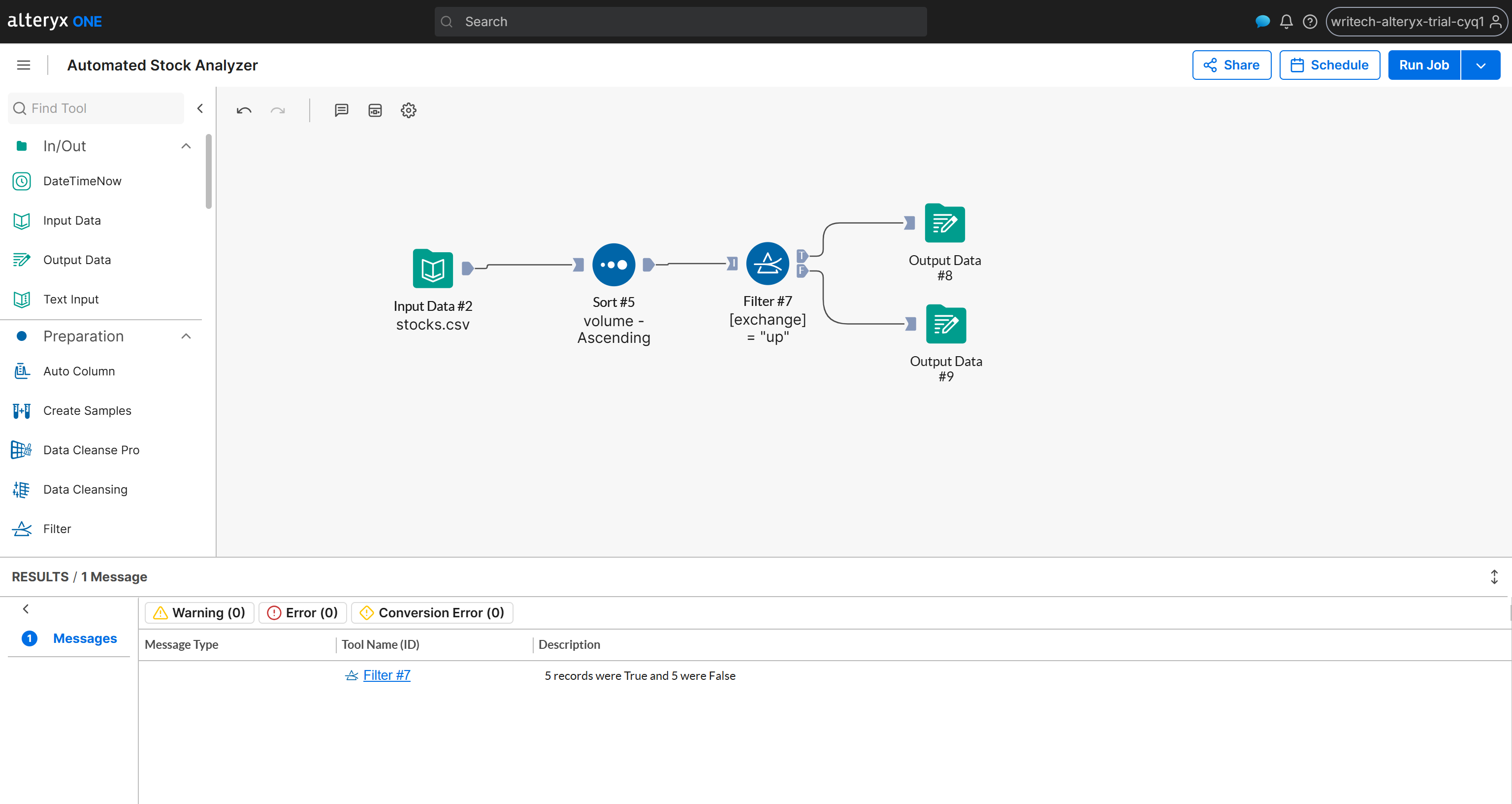
Missão cumprida! Agora você só precisa executar o workflow para verificar se tudo funciona conforme o esperado.
Passo #8: Execute o Workflow
Clique no botão “Run Job” e aguarde a conclusão do workflow automatizado de análise de dados web com tecnologia da Bright Data:

Após a conclusão da execução, você receberá uma notificação de sucesso no Alteryx One, juntamente com um e-mail de confirmação.
Agora, inspecione a saída gerada para o cenário T:
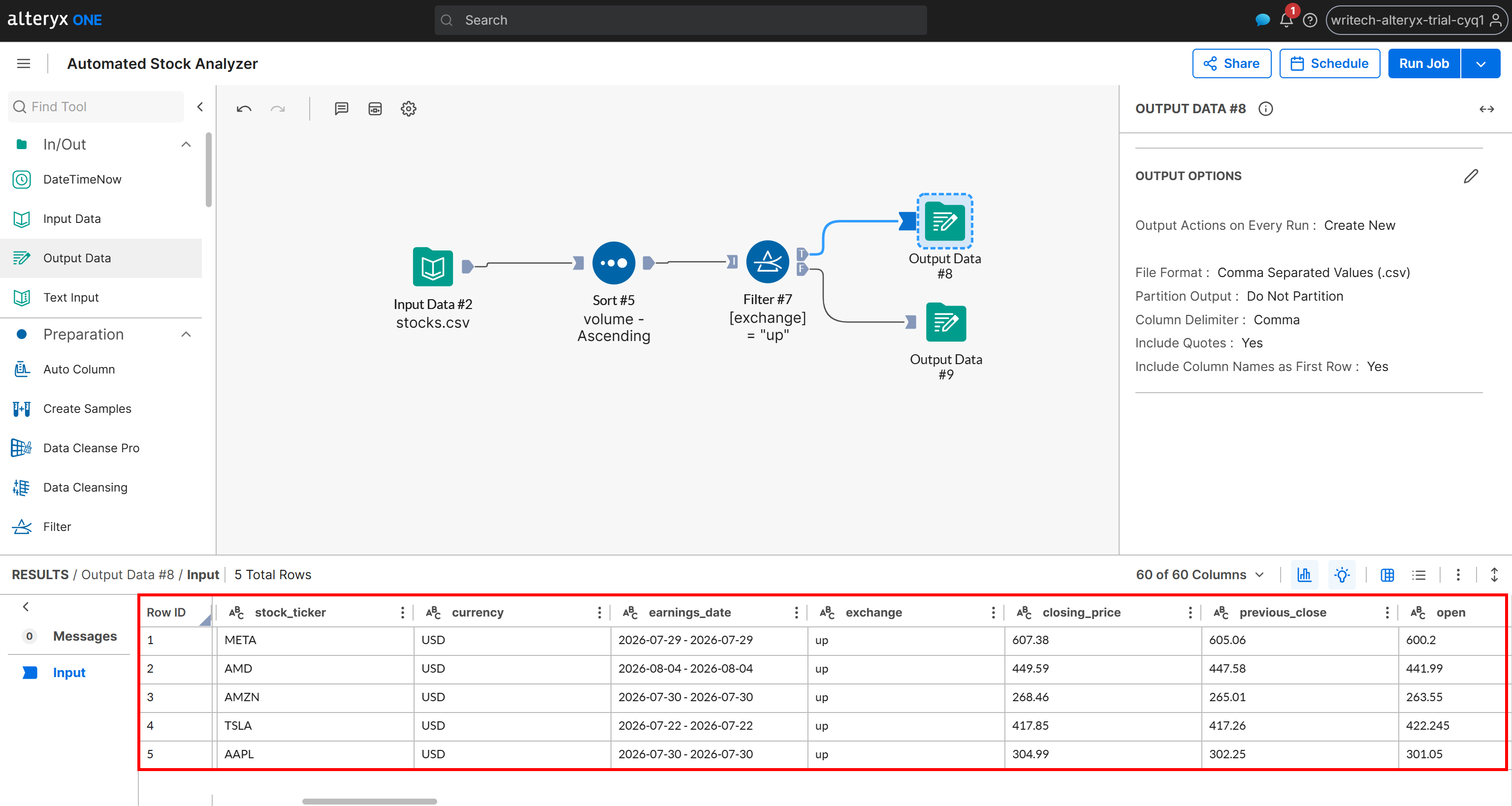
Observe que esta saída contém apenas as ações cujo status de variação é “up”, ordenadas por volume em ordem crescente. Os mesmos dados também estão disponíveis no arquivo up_stocks.csv gerado pelo pipeline e armazenado no seu bucket Amazon S3.
Em seguida, inspecione a saída gerada para o cenário F:
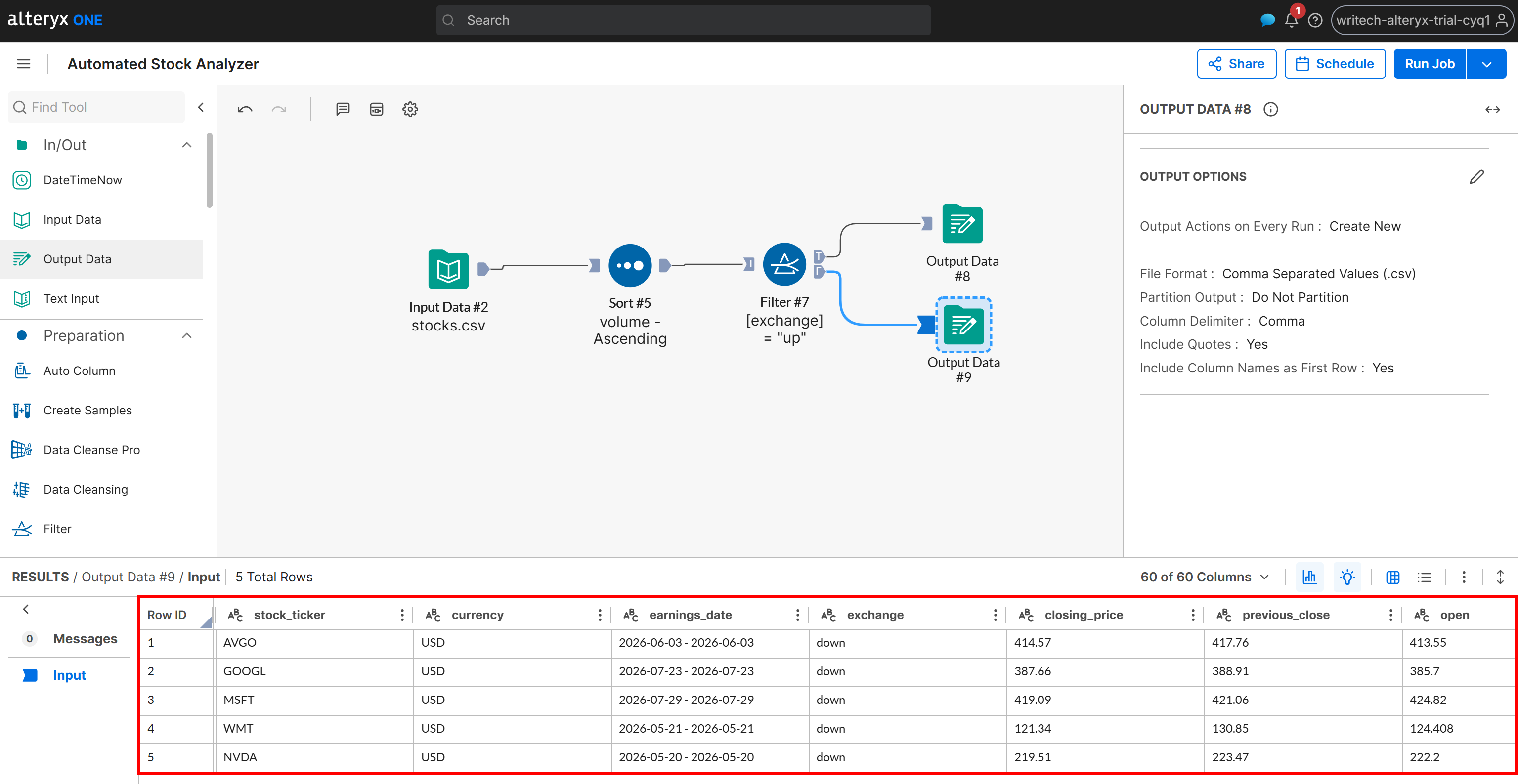
Esta saída contém apenas as ações cujo status de variação é “down”, também ordenadas por volume em ordem crescente. Os mesmos resultados são gravados no arquivo down_stocks.csv no seu bucket Amazon S3.
Et voilà! Você acabou de criar um pipeline de análise de dados web no Alteryx One com tecnologia da Bright Data. Note que este foi apenas um exemplo, e muitos outros cenários de automação de dados web são possíveis.
Próximos Passos
Tenha em mente que este foi apenas um pipeline simples de análise de dados com alguns passos de exemplo. Na prática, você pode torná-lo muito mais complexo adicionando nós de processamento adicionais (incluindo nós de IA) e até mesmo introduzindo múltiplas fontes de dados.
Por exemplo, você pode configurar outras Web Scraping APIs da Bright Data para gravar no mesmo bucket Amazon S3. Os datasets resultantes podem então ser combinados para enriquecimento e análises mais avançadas usando operações de join.
Além disso, para criar um pipeline de dados totalmente automatizado e sempre atualizado:
- Acione as Web Scraping APIs da Bright Data para atualizar os dados de origem no Amazon S3.
- Na Bright Data, configure um webhook que chame a API de execução de workflow do Alteryx One.
Conclusão
Neste tutorial, você aprendeu o que o Alteryx One oferece para a análise de dados automatizada. Especificamente, você viu como os dados recuperados pelas Web Scraping APIs da Bright Data podem ser integrados ao Alteryx One por meio do Amazon S3. Dados web de alta qualidade melhoram significativamente a precisão e o valor dos insights, levando a melhores resultados de análise.
Crie uma conta gratuita na Bright Data hoje mesmo e comece a explorar nossas soluções de dados web prontas para empresas!





