

A criação de modelos especializados que entendam seu domínio geralmente requer mais do que engenharia imediata ou geração aumentada por recuperação (RAG). Os modelos disponíveis publicamente são poderosos, mas não têm o conhecimento mais recente ou o gosto específico que seu caso de uso exige. Como temos dados da Web, que vão desde artigos, documentações, listagens de produtos e transcrições de vídeos, essa lacuna pode ser preenchida por meio de um ajuste fino.
Nesta postagem do blog, você aprenderá:
- Como coletar e preparar dados da Web específicos de um domínio usando os raspadores e conjuntos de dados da Bright Data.
- Como fazer o ajuste fino de um modelo de GPT de código aberto com os dados coletados
- Como avaliar e implementar seu modelo ajustado para tarefas do mundo real.
Vamos nos aprofundar!
O que é ajuste fino
Em palavras simples, o ajuste fino é o processo de pegar um modelo que já foi pré-treinado em um conjunto de dados grande e geral e adaptá-lo para ter um bom desempenho em um novo conjunto de dados ou tarefa, geralmente mais específico. Ao fazer o ajuste fino, você está alterando os pesos do modelo em vez de construí-lo do zero. Alterar os pesos é o que faz com que ele se comporte de forma diferente ou da maneira que você deseja.
Os dados da Web são úteis para o ajuste fino porque oferecem:
- Atualidade: São atualizados continuamente para capturar as últimas tendências, eventos e tecnologias.
- Diversidade: Acesso a diferentes estilos de redação, fontes e pensamentos, o que reduz o viés de conjuntos de dados restritos.
O processo de ajuste fino funciona como mostrado aqui:
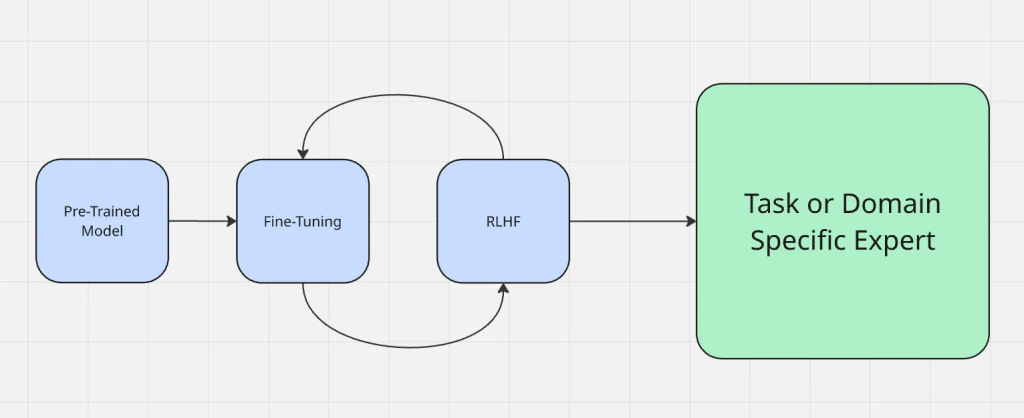
O ajuste fino é diferente de outros métodos de adaptação comumente usados, como a engenharia de solicitação e a geração aumentada por recuperação. A engenharia de prompts altera a forma como você faz perguntas a um modelo, mas não altera o modelo em si. O RAG adiciona uma fonte de conhecimento externa no tempo de execução, como se estivesse fornecendo o contexto de algo novo. O ajuste fino, por outro lado, atualiza diretamente os parâmetros do modelo, o que o torna mais confiável para produzir resultados precisos do domínio sem contexto adicional a cada vez.
Ao contrário da geração aumentada por recuperação (RAG), que enriquece um modelo com contexto externo em tempo de execução, o ajuste fino adapta o próprio modelo. Se você quiser se aprofundar nas compensações, consulte RAG vs. ajuste fino.
Por que usar dados da Web para ajuste fino
Os dados da Web são fornecidos em formatos ricos e recentes (artigos, listas de produtos, postagens em fóruns, transcrições de vídeo e até mesmo texto derivado de vídeo), o que oferece uma vantagem que nem os conjuntos de dados estáticos nem os sintéticos podem igualar. Essa variedade ajuda um modelo a lidar com diferentes tipos de entrada de forma mais eficaz.
Aqui estão alguns exemplos de diferentes contextos em que os dados da Web se destacam:
- Dados de mídia social: Os tokens das plataformas sociais ajudam os modelos a entender a linguagem informal, as gírias e as tendências em tempo real, que são essenciais para aplicativos como análise de sentimentos ou bots de bate-papo.
- Conjuntos de dados estruturados: Os tokens de fontes estruturadas, como catálogos de produtos ou relatórios financeiros, permitem uma compreensão precisa e específica do domínio, essencial para sistemas de recomendação ou previsão financeira.
- Contexto de nicho: As startups e os aplicativos especializados se beneficiam de tokens provenientes de conjuntos de dados relevantes adaptados aos seus casos de uso, como documentos jurídicos para tecnologia jurídica ou revistas médicas para IA médica.
Os dados da Web introduzem variedade e contexto naturais, melhorando o realismo e a robustez em um modelo ajustado.
Estratégias de coleta de dados
Os raspadores em grande escala e os provedores de conjuntos de dados, como a Bright Data, possibilitam a coleta de grandes volumes de conteúdo da Web de forma rápida e confiável. Isso permite que você crie conjuntos de dados específicos do domínio sem gastar meses na coleta manual.
A Bright Data criou a infraestrutura de coleta de dados da Web mais diversificada e confiável do setor, construída com várias fontes e saídas de rede diferentes. Embora os dados da Web não se limitem a texto simples. A Bright data pode capturar entradas multimodais, como metadados, atributos de produtos e transcrições de vídeos, que ajudam um modelo a aprender um contexto mais rico.
A coleta de dados usando scrapes brutos deve ser evitada, pois eles quase sempre contêm ruído, conteúdo irrelevante ou artefatos de formatação. A filtragem, a eliminação de duplicação e a limpeza estruturada são etapas importantes para garantir que o conjunto de dados de treinamento melhore o desempenho em vez de introduzir confusão.
Preparação de dados da Web para ajuste fino
- Conversão de scrapes brutos em pares estruturados de entrada/saída. Os dados não processados raramente estão prontos para o treinamento como estão. A primeira etapa envolve a conversão dos dados em pares estruturados de entrada/saída. Por exemplo, uma documentação sobre ajuste fino pode ser formatada em um prompt como “What is fine-tuning?” (O que é ajuste fino?) com a resposta original como saída de destino. Esse tipo de estrutura garante que o modelo aprenda com exemplos bem definidos em vez de texto desorganizado.
- Manuseio de diversos formatos: JSON, CSV, transcrições, páginas da Web. Os dados da Web geralmente vêm em diferentes formatos, como JSON de APIs, exportações de CSV, HTML bruto ou transcrições de vídeos. A padronização dos dados da Web em um formato consistente, como JSONL, simplifica o gerenciamento e a alimentação dos pipelines de treinamento.
- Empacotamento de conjuntos de dados para treinamento eficiente. Para melhorar os resultados e o processo de treinamento, os conjuntos de dados são frequentemente “organizados”, o que significa que vários exemplos mais curtos são combinados em uma única sequência para reduzir o desperdício de tokens e otimizar o uso da memória da GPU durante o ajuste fino.
- Equilíbrio entre dados específicos de domínio e dados gerais da Web. Encontrar um equilíbrio é importante. Um excesso de dados de um único domínio pode tornar o modelo estreito e superficial, enquanto o excesso de dados gerais pode diluir o conhecimento especializado visado. Os melhores resultados geralmente vêm da combinação de uma base sólida de dados gerais da Web com exemplos específicos do domínio com curadoria.
Escolha de um modelo de base
A escolha do modelo de base correto tem um impacto direto no desempenho do seu sistema ajustado. Não existe uma solução única para todos, especialmente considerando a variedade de ofertas dentro de cada família de modelos. Dependendo do seu tipo de dados, dos resultados desejados e do orçamento, um modelo pode atender melhor às suas necessidades do que outro.
Para escolher o modelo certo para começar, siga esta lista de verificação:
- De qual modalidade ou modalidades seu modelo precisará?
- Qual é o tamanho de seus dados de entrada e saída?
- Qual é a complexidade das tarefas que você está tentando executar?
- Qual é a importância do desempenho em relação ao orçamento?
- Qual é o grau de importância da segurança do assistente de IA para seu caso de uso?
- Sua empresa tem um acordo existente com o Azure ou o GCP?
Por exemplo, se estiver lidando com vídeos ou textos extremamente longos (horas de centenas de milhares de palavras), o Gemini 1.5 pro pode ser a escolha ideal, fornecendo uma janela de contexto de até 1 milhão de tokens.
Vários modelos de código aberto são candidatos fortes para o ajuste fino de dados da Web, incluindo os modelos Gemma 3, Llama 3.1, Mistral 7B ou Falcon. As versões menores são práticas para a maioria dos projetos de ajuste fino, enquanto as maiores se destacam quando seu domínio precisa de alta cobertura e precisão. Você também pode consultar este guia sobre a adaptação do Gemma 3 para o ajuste fino.
Ajuste fino com dados brilhantes
Para demonstrar como os dados da Web alimentam o ajuste fino, vamos examinar um exemplo usando o Bright Data como fonte. Neste exemplo, usaremos a API Scraper da Bright Data para coletar informações de produtos da Amazon e, em seguida, fazer o ajuste fino de um modelo Llama 4 na Hugging Face.
Etapa 1: coleta do conjunto de dados
Usando a API de raspagem da Web da Bright Data, você pode recuperar dados estruturados de produtos (título, produtos, descrições, avaliações etc.) com apenas algumas linhas de Python.
O objetivo desta etapa é criar um pequeno projeto que:
- Ativa um ambiente virtual Python
- Chama a API do Web Scraper da Bright Data
- Salva os resultados em amazon-data.json
Pré-requisitos
- Python 3.10 ou superior
- Um token de API da Bright Data
- Um ID de coletor da Bright Data (do painel da Bright Data) /cp/scrapers
- Uma OPENAI_API_KEY, pois estaremos ajustando um modelo GPT-4.
Crie uma pasta de projeto
mkdir web-scraper u0026u0026 cd web-scrapper
Crie e ative um ambiente virtual
Ative um ambiente virtual, e você deverá ver (venv) no início do prompt do shell.
//macOS/Linux (bash or zsh):npython3 -m venv venvnsource venv/bin/activatennWindowsnpython -m venv venvn.venvScriptsActivate.ps1
Instale as dependências
Esta é uma biblioteca para fazer solicitações HTTP na Web
pip install requests
Quando isso estiver concluído, você estará pronto para obter os dados de interesse usando as APIs do raspador da Bright Data.
Definir a lógica de raspagem
O snippet a seguir acionará o coletor da Bright Data (por exemplo, produtos da Amazon), pesquisará até que a extração seja concluída e salvará os resultados em um arquivo JSON local.
Substitua sua chave de API na string de chave de API aqui
import requestsnimport jsonnimport timenndef trigger_amazon_products_scraping(api_key, urls):n url = u0022https://api.brightdata.com/datasets/v3/triggeru0022nn params = {n u0022dataset_idu0022: u0022gd_l7q7dkf244hwjntr0u0022,n u0022include_errorsu0022: u0022trueu0022,n u0022typeu0022: u0022discover_newu0022,n u0022discover_byu0022: u0022best_sellers_urlu0022,n }n data = [{u0022category_urlu0022: url} for url in urls]nn headers = {n u0022Authorizationu0022: fu0022Bearer {api_key}u0022,n u0022Content-Typeu0022: u0022application/jsonu0022,n }nn response = requests.post(url, headers=headers, params=params, json=data)nn if response.status_code == 200:n snapshot_id = response.json()[u0022snapshot_idu0022]n print(fu0022Request successful! Response: {snapshot_id}u0022)n return response.json()[u0022snapshot_idu0022]n else:n print(fu0022Request failed! Error: {response.status_code}u0022)n print(response.text)nndef poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):n snapshot_url = fu0022https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=jsonu0022n headers = {n u0022Authorizationu0022: fu0022Bearer {api_key}u0022n }nn print(fu0022Polling snapshot for ID: {snapshot_id}...u0022)nn while True:n response = requests.get(snapshot_url, headers=headers)nn if response.status_code == 200:n print(u0022Snapshot is ready. Downloading...u0022)n snapshot_data = response.json()nn with open(output_file, u0022wu0022, encoding=u0022utf-8u0022) as file:n json.dump(snapshot_data, file, indent=4)nn print(fu0022Snapshot saved to {output_file}u0022)n returnn elif response.status_code == 202:n print(Fu0022Snapshot is not ready yet. Retrying in {polling_timeout} seconds...u0022)n time.sleep(polling_timeout)n else:n print(fu0022Request failed! Error: {response.status_code}u0022)n print(response.text)n breaknnif __name__ == u0022__main__u0022:n BRIGHT_DATA_API_KEY = u0022your_api_keyu0022n urls = [n u0022https://www.amazon.com/gp/bestsellers/office-products/ref=pd_zg_ts_office-productsu0022n ]n snapshot_id = trigger_amazon_products_scraping(BRIGHT_DATA_API_KEY, urls)n poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, u0022amazon-data.jsonu0022)
Execute o código
python3 web_scraper.py
Você deverá ver:
- Uma ID de instantâneo impressa
- Raspagem concluída.
- Salvo em amazon-data.json (…itens)
O processo cria automaticamente os dados que contêm nossos dados extraídos. Essa é a estrutura esperada dos dados:
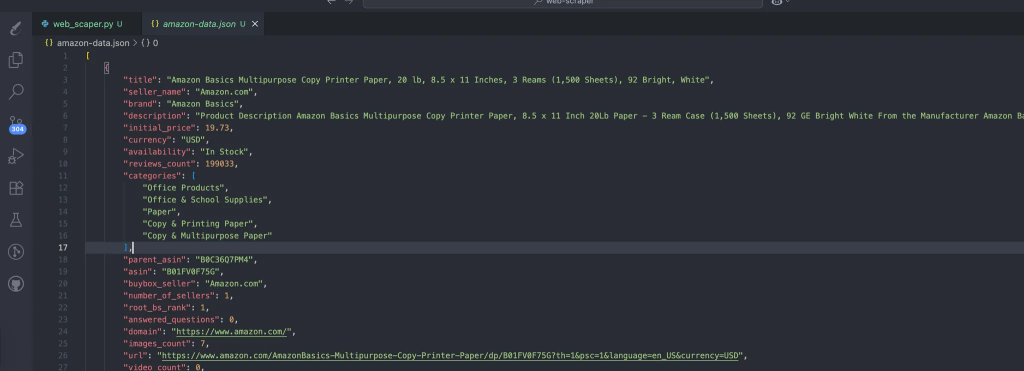
Etapa 2: transformar JSON em pares de treinamento
Crie o prepare_pair.py na raiz do projeto, com o seguinte snippet para estruturar nossos dados no formato JSONL e deixá-los prontos para a etapa de ajuste fino.
import json, random, osnnINPUT = u0022amazon-data.jsonu0022nOUTPUT = u0022pairs.jsonlu0022nSYSTEM = u0022You are an expert copywriter. Generate concise, accurate product descriptions.u0022nndef make_example(item):n title = item.get(u0022titleu0022) or item.get(u0022nameu0022) or u0022Unknown productu0022n brand = item.get(u0022brandu0022) or u0022Unknown brandu0022n features = item.get(u0022featuresu0022) or item.get(u0022bulletsu0022) or []n features_str = u0022, u0022.join(features) if isinstance(features, list) else str(features)n target = item.get(u0022descriptionu0022) or item.get(u0022aboutu0022) or u0022u0022n user = fu0022Write a crisp product description.nTitle: {title}nBrand: {brand}nFeatures: {features_str}nDescription:u0022n assistant = target.strip()[:1200] # keep it tightn return {u0022systemu0022: SYSTEM, u0022useru0022: user, u0022assistantu0022: assistant}nndef main():n if not os.path.exists(INPUT):n raise SystemExit(fu0022Missing {INPUT}u0022)n data = json.load(open(INPUT, u0022ru0022, encoding=u0022utf-8u0022))n pairs = [make_example(x) for x in data if isinstance(x, dict)]n random.shuffle(pairs)n with open(OUTPUT, u0022wu0022, encoding=u0022utf-8u0022) as out:n for ex in pairs:n out.write(json.dumps(ex, ensure_ascii=False) + u0022nu0022)n print(fu0022Wrote {len(pairs)} examples to {OUTPUT}u0022)nnif __name__ == u0022__main__u0022:n main()
Execute o seguinte comando:
python3 prepare_pairs.py
E deve gerar o seguinte resultado no arquivo:
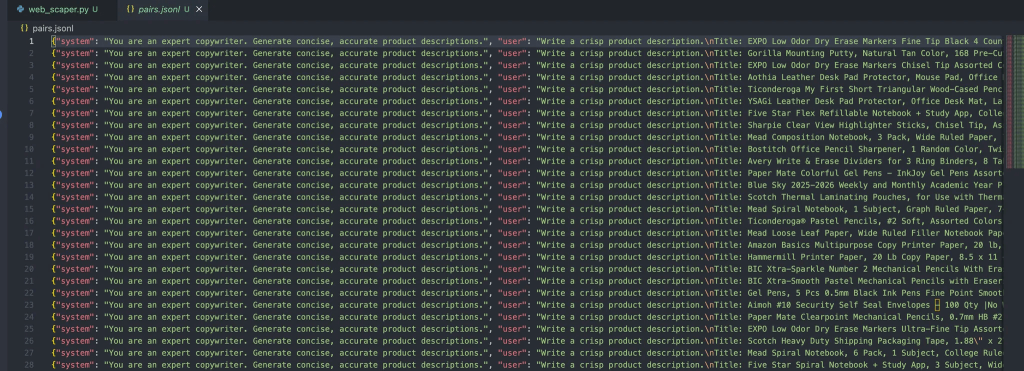
Cada mensagem nesse objeto contém três funções:
- Sistema: Fornece o contexto inicial para o assistente.
- Usuário: a entrada do usuário.
- Assistente: a resposta do assistente.
Etapa nº 3: Carregamento do arquivo para ajuste fino
Quando o arquivo estiver pronto, as próximas etapas são apenas conectá-lo aos pipelines de ajuste fino do OpenAI com as seguintes etapas:
Instalar as dependências do OpenAI
pip install openai
Crie um upload.py para fazer upload de seu conjunto de dados
Esse script lerá o arquivo pairs.jsonl que já temos
from openai import OpenAInclient = OpenAI(api_key=u0022your_api_key_hereu0022)nnwith open(u0022pairs.jsonlu0022, u0022rbu0022) as f:n uploaded = client.files.create(file=f, purpose=u0022fine-tuneu0022)nnprint(uploaded)
Execute o seguinte comando:
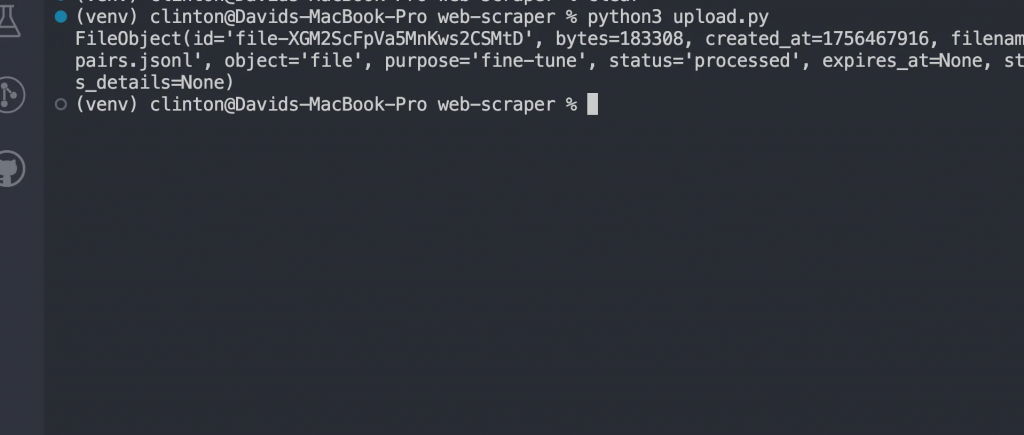
python3 upload.py
Agora você deve ver uma resposta como:
Ajuste fino do modelo
Crie um arquivo fine-tune.py e substitua o FILE_ID pelo ID do arquivo carregado que obtivemos na resposta acima e execute o arquivo:
from openai import OpenAInclient = OpenAI()nn# replace with your uploaded file idnFILE_ID = u0022file-xxxxxxu0022nnjob = client.fine_tuning.jobs.create(n training_file=FILE_ID,n model=u0022gpt-4o-mini-2024-07-18u0022n)nnprint(job)
Isso deve nos dar a seguinte resposta:
Monitorar até o término do treinamento
Depois de iniciar o trabalho de ajuste fino, o modelo precisa de tempo para ser treinado em seu conjunto de dados. Dependendo do tamanho do conjunto de dados, isso pode levar de alguns minutos a horas.
Mas você não quer adivinhar quando ele estará pronto; em vez disso, escreva e execute este código em monitor.py
from openai import OpenAInclient = OpenAI()nnjobs = client.fine_tuning.jobs.list(limit=1)nprint(jobs)
Em seguida, execute o arquivo com python3 [manage.py](http://manage.py) no terminal, e ele deverá mostrar detalhes como:
- Se o treinamento foi bem-sucedido ou falhou.
- Quantos tokens foram treinados
- O ID do novo modelo com ajuste fino.
Nesta seção, você só deve seguir em frente quando o campo de status indicar
u0022succeededu0022
Converse com seu modelo ajustado
Quando o trabalho estiver concluído, você terá seu próprio modelo GPT personalizado. Para usá-lo, abra o chat.py, atualize o MODEL_ID com o que foi retornado do trabalho de ajuste fino e execute o arquivo:
from openai import OpenAInclient = OpenAI()nn# replace with your fine-tuned model idnMODEL_ID = u0022ft:gpt-4o-mini-2024-07-18:your-org::custom123u0022nnwhile True:n user_input = input(u0022User: u0022)n if user_input.lower() in [u0022quitu0022, u0022qu0022]:n breaknn response = client.chat.completions.create(n model=MODEL_ID,n messages=[n {u0022roleu0022: u0022systemu0022, u0022contentu0022: u0022You are a helpful assistant fine-tuned on domain data.u0022},n {u0022roleu0022: u0022useru0022, u0022contentu0022: user_input}n ]n )n print(u0022Assistant:u0022, response.choices[0].message.content)
Essa etapa prova que o ajuste fino funcionou. Em vez de usar o modelo básico de uso geral, agora você está conversando com um modelo treinado especificamente nos seus dados.
É aqui que você verá seus resultados ganharem vida.
Você pode esperar resultados como:
u002du002d- Generating Descriptions with Fine-Tuned Model using Synthetic Test Data u002du002d-nnPROMPT for item: ErgoPro-EL100nGENERATED (Fine-tuned):n**Introducing the ErgoPro-EL100: The Ultimate Executive Ergonomic Office Chair**nnExperience the pinnacle of comfort and support with the ComfortLuxe ErgoPro-EL100, designed to elevate your work experience. This premium office chair boasts a high-back design that cradles your upper body, providing unparalleled lumbar support and promoting a healthy posture.nnThe breathable mesh fabric ensures a cool and comfortable seating experience, while the synchronized tilt mechanism allows for seamless adjustments to your preferred working position. The padded armrests provide additional support and comfort, reducing strain on your shoulders and wrists.nnBuilt to last, the ErgoPro-EL100 features a heavy-duty nylon base that ensures stability and durability. Whether you're working long hours or simplynu002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002dnnPROMPT for item: HeightRise-FD20nGENERATED (Fine-tuned):n**Elevate Your Productivity with FlexiDesk's HeightRise-FD20 Adjustable Standing Desk Converter**nnTake your work to new heights with FlexiDesk's HeightRise-FD20, the ultimate adjustable standing desk converter. Designed to revolutionize your workspace, this innovative converter transforms any desk into a comfortable and ergonomic standing station.nn**Experience the Benefits of Standing**nnThe HeightRise-FD20 features a spacious dual-tier surface, perfect for holding your laptop, monitor, and other essential work tools. The smooth gas spring lift allows for effortless height adjustments, ranging from 6 to 17 inches, ensuring a comfortable standing position that suits your needs.nn**Durable and Reliable**nnWith a sturdy construction and non-slip rubber feetnu002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002d
Conclusão
Ao trabalhar com ajuste fino em escala da Web, é importante ser realista quanto às restrições e aos fluxos de trabalho:
- Requisitos de recursos: O treinamento em conjuntos de dados grandes e diversificados requer computação e armazenamento. Se estiver fazendo experimentos, comece com fatias menores dos seus dados antes de aumentar a escala.
- Itere gradualmente: Em vez de despejar milhões de registros na sua primeira tentativa, refine com um conjunto de dados menor. Use os resultados para identificar lacunas ou erros em seu pipeline de pré-processamento.
- Fluxos de trabalho de implantação: Trate os modelos ajustados como qualquer outro artefato de software. Dê versões a eles, integre-os ao CI/CD sempre que possível e mantenha opções de reversão caso um novo modelo tenha um desempenho inferior.
Felizmente, a Bright Data oferece a você vários serviços prontos para IA para aquisição ou criação de conjuntos de dados:
- Scraping Browser: Um navegador compatível com Playwright, Selenium e Puppeter com recursos de desbloqueio integrados.
- APIs do Web Scraper: APIs pré-configuradas para extrair dados estruturados de mais de 100 domínios principais.
- Web Unlocker: Uma API tudo em um que lida com o desbloqueio de sites com proteções antibot.
- API SERP: Uma API especializada que desbloqueia resultados de mecanismos de pesquisa e extrai dados completos de SERP.
- Dados para modelos de fundação: Acesse conjuntos de dados em conformidade e em escala da Web para potencializar o pré-treinamento, a avaliação e o ajuste fino.
- Provedores de dados: Conecte-se com provedores confiáveis para obter conjuntos de dados de alta qualidade e prontos para IA em escala.
- Pacotes de dados: Obtenha conjuntos de dados selecionados e prontos para uso – estruturados, enriquecidos e anotados.
O ajuste fino de modelos de linguagem de grande porte com dados da Web permite uma poderosa especialização de domínio. A Web oferece conteúdo novo, diversificado e multimodal, de artigos e resenhas a transcrições e metadados estruturados, que os conjuntos de dados com curadoria por si só não conseguem igualar.
Crie uma conta na Bright Data gratuitamente para testar nossa infraestrutura de dados pronta para IA!






