

A geração aumentada por recuperação (RAG) e o ajuste fino são dois conceitos muito diferentes em IA e servem a dois propósitos muito diferentes. A RAG permite que um LLM acesse informações externas durante o tempo de execução. O ajuste fino permite que o LLM ajuste seu conhecimento interno para um aprendizado mais profundo e permanente.
Ao final deste guia, você será capaz de responder às seguintes perguntas.
- O que é ajuste fino?
- O que é RAG?
- Quando você deve usar o ajuste fino?
- Quando você deve usar RAG?
- Como o RAG e o ajuste fino se complementam?
O que é ajuste fino?
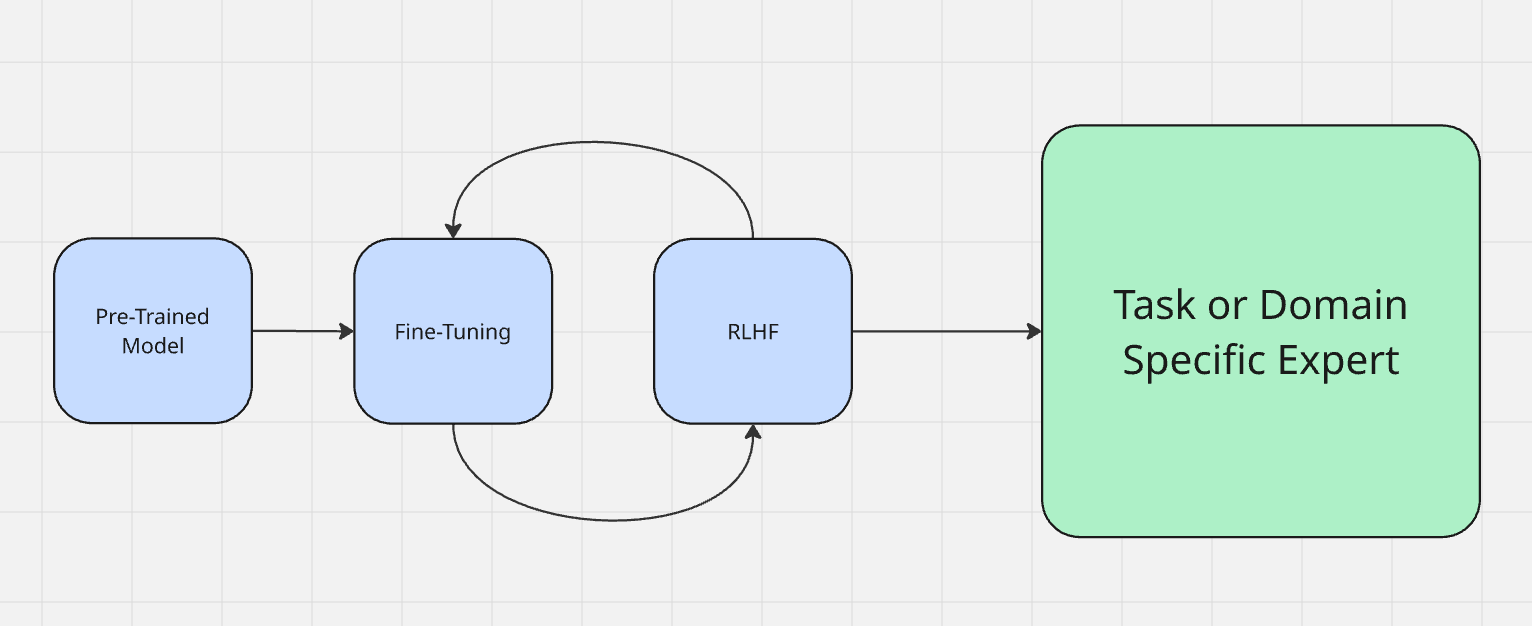
O ajuste fino é frequentemente considerado parte do processo real de treinamento do modelo. Você pode aprender mais sobre como os modelos são treinados aqui. Os modelos primeiro passam por um período chamado “pré-treinamento”. Em termos simples, é quando eles aprendem a receber entradas e gerar saídas. Quando o pré-treinamento é concluído, o modelo contém uma grande quantidade de conhecimento, mas ainda não está totalmente otimizado para aplicá-lo.
Normalmente, ajustamos um modelo usando o aprendizado por reforço a partir do feedback humano (RLHF). Ao fazer o ajuste fino, você realmente conversa com o modelo para testar sua saída. Por exemplo, se um modelo diz “o céu é verde”, ele precisa ser corrigido para dizer “o céu é azul”. Ao fazer o ajuste fino, você avalia a saída da máquina e reforça o comportamento desejado — semelhante a dizer “bom garoto!” ao seu cachorro por bom comportamento ou enrolar um jornal por mau comportamento.
Ao ajustar um LLM, você o prepara para sua tarefa real no mundo real. Existem dois tipos principais de ajuste.
- Adaptação de domínio: imagine que você deseja criar um especialista em programação com um modelo básico como o DeepSeek. Você tem um modelo forte com uma base decente, mas ele ainda não é um verdadeiro especialista em nada. Claro, ele entende comandos shell e a maioria dos códigos Python, mas precisa de especialização. É aí que você o ensinaria os pontos mais delicados da ciência da computação e da codificação com coisas como StackOverflow e LeetCode. Quando o ajuste fino estiver concluído, você terá um modelo que pode escrever códigos mais rápido e melhor do que qualquer ser humano.
- Adaptação de tarefas: a adaptação de tarefas consiste em se adaptar à tarefa em questão. Nos LLMs atuais, vemos isso mais comumente em bate-papos reais. No início de 2026, o ChatGPT-4o recebeu um ajuste muito intenso para corresponder ao sentimento da pessoa com quem estava conversando. Nesse caso, o RLHF foi usado para incentivar o bot a refletir o sentimento do usuário. Se o usuário fala tecnicamente, o GPT também fala. Se o usuário fala sobre direito, o GPT fala em jargão jurídico. Se o usuário parece religioso, o GPT se torna religioso (sim, de verdade).
O ajuste fino é usado para influenciar a tomada de decisão e as inferências reais do modelo.
O que é RAG?
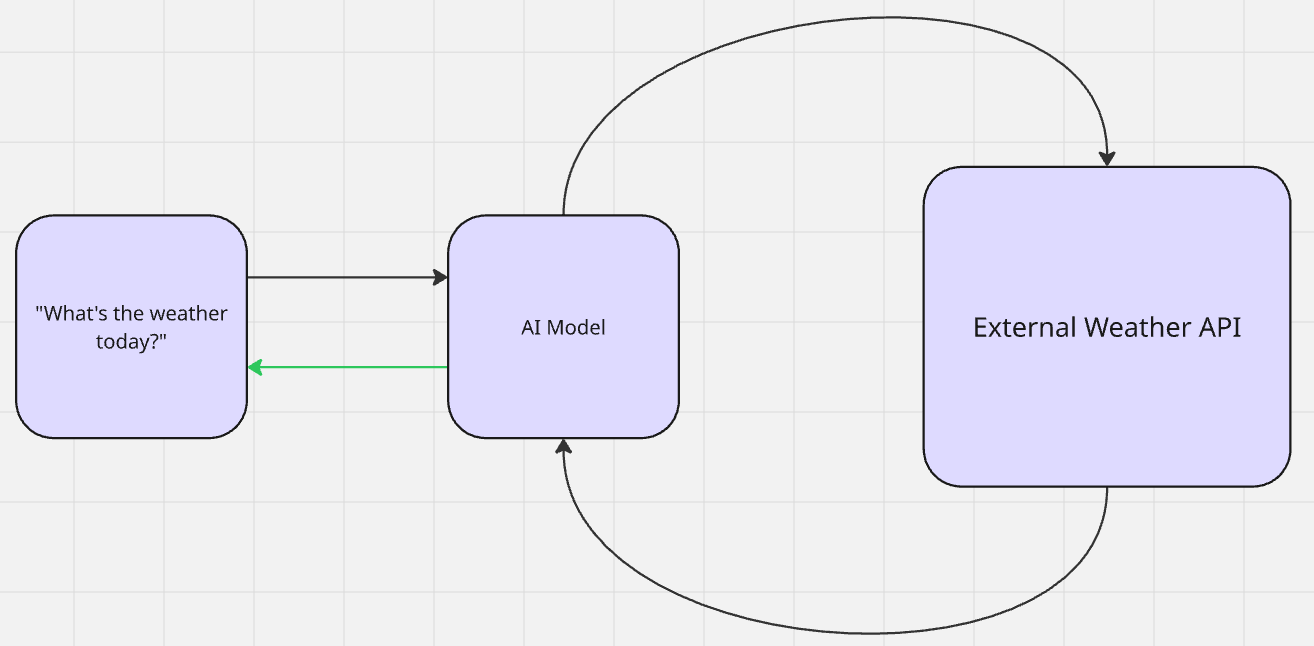
Com o RAG, não ocorre nenhum aprendizado real. Uma IA recupera dados extras para relevância contextual e gera resultados. Depois que o resultado é criado, o modelo retorna ao seu estado anterior à recuperação. Essa é uma forma de aprendizado zero-shot. O modelo consulta as informações sem nenhum contexto prévio. Em seguida, ele usa seu pré-treinamento para fazer inferências e gerar resultados.
Quando você pergunta ao Gemini: “Como está o tempo hoje?”, ele pesquisa (recupera) o tempo (aumenta seu conhecimento) e, em seguida, informa (gera) a saída.
Existem dois tipos principais de RAG: passivo e ativo. Isso é melhor demonstrado na geração mais recente de modelos de chat com memórias armazenadas.
- RAG passivo: as “memórias” são armazenadas em um banco de dados vetorial e referenciadas posteriormente para contexto. Quando um LLM sabe seu nome ou preferências, isso é RAG passivo. As informações referenciadas devem ser estáticas e permanentes. A única maneira de remover as “memórias” é por meio da exclusão manual.
- RAG ativo: pense no nosso exemplo do tempo anterior. O tempo muda todos os dias. O modelo realiza uma pesquisa ativa (provavelmente por meio de uma API) sobre o tempo. Quando tem certeza de que entende o tempo, ele o repete para você com sua própria “personalidade” personalizada.
Os pipelines RAG seguem exatamente este fluxo de trabalho: recuperar os dados -> aumentar a inferência -> gerar a saída.
Quando você deve fazer o ajuste fino?
O ajuste fino é mais útil quando você deseja definir como seu modelo realmente pensa. Quando você deseja que o conhecimento e a inferência sejam permanentes, deve fazer um ajuste fino. Se o seu LLM precisa entender verdadeiramente os dados, você deve fazer um ajuste fino.
Se a saída produzida pelo seu modelo não estiver totalmente correta, se o processo de raciocínio parecer um pouco errado, você precisa fazer o ajuste fino.
- Tom e personalidade: se você tem uma atitude ou entonação específica em mente para o seu modelo, faça o ajuste fino. Isso é particularmente útil em chatbots personalizados. Quando o Grok 3 chocou o mundo com personalidades definidas pelo usuário, isso se deveu principalmente ao ajuste fino.
- Casos extremos e precisão: quando seu modelo encontra problemas com casos extremos ou não consegue representar seus dados de treinamento adequadamente, é necessário fazer um ajuste fino. Isso é particularmente verdadeiro para modelos usados em diagnósticos médicos. Um modelo com alucinações sobre leis pode levar a processos judiciais. Um modelo com alucinações sobre condições médicas é perigoso para o paciente.
- Tamanho do modelo e redução de custos: o ajuste fino pode reduzir significativamente o tamanho e o custo operacional do seu modelo. Por exemplo, a equipe Llama conseguiu destilar os resultados do GPT-4 para o GPT-3.5. Você pode ler mais sobre isso na documentação de ajuste fino aqui.
- Novas tarefas e habilidades: se você deseja adicionar uma capacidade real que ainda não existe em um modelo pré-treinado, é necessário ajustá-lo. Imagine que você tem um modelo treinado para usar apenas inglês, mas precisa de resultados em espanhol — nenhuma quantidade de engenharia de prompt ou RAG resolverá isso, você precisa fazer um ajuste fino.
Quando você deve usar RAG?
O RAG é mais adequado para modelos que já pensam corretamente. Se o seu modelo produzir a saída correta após o ajuste fino, provavelmente é hora de adicionar o RAG para acesso a dados externos. Sem o contexto adequado, os modelos muitas vezes se tornam inúteis para muitas tarefas — não importa o quão inteligentes sejam.
Lembre-se do nosso exemplo anterior sobre o clima. Você poderia ter o modelo mais inteligente do planeta, mas sem acesso a dados em tempo real, seu modelo não poderia fornecer o clima — ou qualquer informação em tempo real, aliás. O RAG faz sentido para as seguintes necessidades de dados.
- Dados em tempo real: já abordamos isso com o clima. Isso inclui notícias, projeções financeiras, monitoramento de sistemas e outros fluxos de dados em rápida evolução.
- Assistentes de pesquisa ou biblioteca: às vezes, as pessoas só precisam ser direcionadas ao recurso correto. Quando você faz uma pergunta com o Gemini ou o Brave Search, obtém uma resposta direta. O modelo vasculha a documentação e indica os recursos relevantes.
- Suporte ao cliente: quando você precisa de um LLM para operar o helpdesk e responder a perguntas gerais, o RAG é rápido e eficaz. Os modelos de IA já sabem como responder a perguntas e ler documentação, eles só precisam de acesso ao conteúdo certo.
- Saída personalizada: lembra-se de como mencionamos anteriormente o tom refletido pelo usuário do GPT? Isso não é magia medieval. O modelo está consultando fatos armazenados em um banco de dados. Se a OpenAI tivesse que retreinar modelos para cada usuário, ela não existiria.
Como decidir entre eles
Se o seu modelo precisa pensar melhor, você deve fazer um ajuste fino. Se o seu modelo precisa de informações externas, use o RAG. Na realidade, estamos caminhando para sistemas híbridos. Depois de lançá-lo ao público, seu modelo precisa pensar com clareza e acessar os dados certos. A tabela abaixo ajudará você a decidir quando usar cada um deles em seu projeto.
| Situação | Melhor escolha | Por quê? |
|---|---|---|
| A saída parece errada ou desalinhada | Ajustar | Você está corrigindo o raciocínio, o tom ou o comportamento |
| A saída está correta, mas falta detalhes | RAG | Você está perdendo fatos externos ou específicos do domínio |
| Você precisa de fatos atualizados ou dados em tempo real | RAG | Modelos estáticos não podem aprender após o treinamento |
| Você deseja um desempenho forte em um novo domínio | Ajuste | Você está adicionando conhecimento profundo e internalizado |
| Você precisa de precisão e atualização | Ambos | Ajuste fino para lógica, RAG para conhecimento externo |
Ferramentas da Bright Data para RAG e ajuste fino
Aqui na Bright Data, oferecemos conjuntos de ferramentas robustas para atender às suas necessidades de ajuste fino e RAG. Se você precisa de Conjuntos de dados de treinamento ou pipelines em tempo real, nossos sistemas têm o que você precisa.
Ajuste fino
- Conjuntos de dados: obtenha dados históricos de toda a Internet — atualizados diariamente. Se você está procurando mídias sociais, listas de produtos ou até mesmo a Wikipedia, nós temos — prontos para treinamento.
- API de arquivo: treine em fontes multimodais e outras com petabytes de dados adicionados diariamente.
- Anotação: acelere seu treinamento usando um serviço de anotação flexível com sua escolha de rotulagem assistida por IA e supervisionada por humanos.
RAG
- API de pesquisa: faça pesquisas na web em tempo real usando qualquer mecanismo de pesquisa importante com parâmetros personalizados, como imagens ou compras.
- API Unlocker: use nossos serviços de Proxy gerenciados para rastrear praticamente qualquer site na web.
- Navegador de agente: automação completa do navegador para seu agente de IA.
- Servidor MCP: conecte seu agente de IA às nossas ferramentas com integração perfeita.
Conclusão
O ajuste fino ensina seu modelo a pensar. O RAG dá ao seu modelo acesso a dados externos sem precisar retreinar ou sobrecarregar o modelo. Na realidade, você deve usar os dois — apenas em diferentes estágios de desenvolvimento.
Ao entender quando e por que usar o ajuste fino e o RAG, você pode tomar decisões informadas com seus próprios modelos de IA. Esteja você criando um especialista em um domínio específico ou dando a ele acesso a dados em tempo real, nossas ferramentas estão aqui para você, assim como nós.
Inscreva-se para o teste grátis e comece hoje mesmo!





