
Nesta postagem do blog, você aprenderá:
- Por que o Kubeflow Pipelines deve incluir um componente dedicado à coleta de dados da web.
- Uma aplicação dessa abordagem a um pipeline específico de análise de sentimentos do TikTok.
- Como implementar esse pipeline conectando-se aos feeds de dados de comentários do TikTok por meio de uma solução específica de scraping.
Vamos começar!
Por que o Kubeflow Pipelines se beneficia de dados estruturados coletados por Scraping de dados da web
Os fluxos de trabalho modernos de aprendizado de máquina e IA dependem muito de dados de alta qualidade. Por outro lado, os pipelines tradicionais geralmente ingestam Conjuntos de dados estáticos ou arquivos pré-processados. No entanto, essas fontes podem se tornar obsoletas rapidamente, deixando os modelos treinados com informações desatualizadas.
É aí que entram os dados estruturados coletados no Scraping de dados da web! Ao coletar dados contextuais em tempo real da web, os pipelines podem se manter alinhados com as últimas tendências, o comportamento do usuário e o conteúdo emergente.
Os pipelines Kubeflow, projetados para fluxos de trabalho de ML modulares, reproduzíveis e escaláveis, se beneficiam imensamente da integração de componentes de coleta de dados da web. Esses componentes fornecem feeds atualizados e estruturados que podem ser automaticamente incorporados, filtrados e processados a jusante.
Ter um componente de coleta de dados da web em seu pipeline certamente ajuda a melhorar a precisão do modelo. Portanto, adicionar um componente dedicado à coleta de dados da web — ou mesmo vários componentes para diferentes fontes — faz sentido do ponto de vista estratégico. Isso permite que seus pipelines se adaptem, sejam retreinados e gerem insights continuamente em tempo quase real, criando uma base sólida para qualquer projeto impulsionado por IA.
Apresentando o pipeline Kubeflow para análise de sentimentos no TikTok
Para entender melhor como um componente de coleta de dados da web aprimora os pipelines do Kubeflow, vamos considerar um exemplo do mundo real. Imagine que você deseja criar um fluxo de trabalho de análise de dados que pegue um conjunto de postagens do TikTok e analise seu conteúdo para avaliar o sentimento.
Você poderia projetar um pipeline de dois componentes:
- Componente de dados de comentários do TikTok: recupera dados estruturados de comentários de postagens do TikTok por meio de Scraping de dados.
- Componente de análise de dados: enriquece esses comentários com insights de sentimento (
positivo,negativoouneutro).
O problema é que o scraping do TikTok (ou de muitas outras plataformas populares) é notoriamente desafiador. Isso se deve a medidas anti-scraping, como CAPTCHAs, desafios de JavaScript, bloqueios de IP e limites de taxa. Dimensionar esse processo só aumenta a complexidade, pois a limitação e as proibições podem facilmente interromper a coleta de dados.
Para evitar esses problemas, faz sentido alimentar o componente de coleta de dados da web com um serviço de dados da web de primeira linha, como o Bright Data. O Bright Data permite um scraping de dados em grande escala e confiável com uma infraestrutura altamente escalável, apoiada por 150 milhões de IPs Proxy em 195 países, uma taxa de sucesso de 99,95% e 99,99% de tempo de atividade.
Em detalhes, utilizaremos o TikTok Scraper, uma API de Scraping de dados projetada para simplificar a coleta estruturada de dados de postagens do TikTok. Essa é uma das muitas APIs de Scraping de dados disponíveis para recuperar dados de domínios populares. Da mesma forma, você pode usar a API Filter Dataset para buscar dados filtrados dos Conjuntos de dados da Bright Data, alimentando seus pipelines de ML/IA com dados prontos para uso.
Como construir um pipeline Kubeflow com um componente de dados de Scraping de dados dinâmico
Nesta seção guiada, você verá como construir o pipeline Kubeflow para a análise de sentimentos do TikTok apresentada anteriormente.
Siga as etapas abaixo!
Pré-requisitos
Para seguir este tutorial, você precisará de:
- Docker instalado e em execução em sua máquina.
- Python 3.10+ instalado localmente.
- Uma conta Bright Data com sua chave API devidamente configurada (não se preocupe em configurá-la agora, pois você será orientado em uma subseção dedicada).
Um conhecimento básico de como o Kubeflow Pipelines funciona também ajudará você a entender as instruções abaixo.
O sistema operacional recomendado para executar os exemplos abaixo é Linux, macOS ou WSL (Windows Subsystem for Linux).
Etapa 1: Configuração do projeto
Comece abrindo seu terminal e criando um novo diretório para o projeto Kubeflow Pipelines:
mkdir kfp-bright-data-pipelineVá para o diretório do projeto e crie um ambiente virtual Python dentro dele:
cd kfp-bright-data-pipeline
python -m venv .venvEm seguida, abra a pasta do projeto em seu IDE Python preferido. Recomendamos o Visual Studio Code com a extensão Python ou o PyCharm Community Edition.
Crie um novo arquivo chamado tiktok_sentiment_analysis_kfp_pipeline.py na raiz do diretório do projeto. Sua estrutura deve ficar assim:
kfp-bright-data-pipeline/
├── .venv/
└── tiktok_sentiment_analysis_kfp_pipeline.py # <-----------No terminal do IDE, ative o ambiente virtual. No Linux ou macOS, execute:
source venv/bin/activateDa mesma forma, no Windows, execute:
venv/Scripts/activateCom o ambiente virtual ativado, instale a dependência necessária:
pip install kfpA única biblioteca necessária é a kfp, que permite construir e compilar pipelines de aprendizado de máquina portáteis e escaláveis.
Por fim, abra tiktok_sentiment_analysis_kfp_pipeline.py e importe os módulos necessários:
from kfp import dsl, compiler
from kfp.dsl import Input, Output, DatasetÉ isso! Agora você tem um ambiente de desenvolvimento Python onde pode construir seu pipeline Kubeflow.
Etapa 2: Comece a usar o Bright Data
O primeiro componente do seu pipeline recuperará dados da web em tempo real usando as APIs de Scraping de dados da Bright Data. Antes de implementá-lo, você precisa configurar corretamente sua conta Bright Data.
Como usaremos as APIs de Scraping de dados, reserve alguns minutos para revisar a documentação oficial. Resumidamente, essas APIs fornecem feeds de dados estruturados de sites populares, prontos para serem consumidos em fluxos de trabalho de ML/IA (ou qualquer outro caso de uso compatível).
Se você ainda não tem uma conta, crie uma. Caso contrário, faça login e abra o painel do usuário. A partir daí, navegue até a seção “Scrapers”: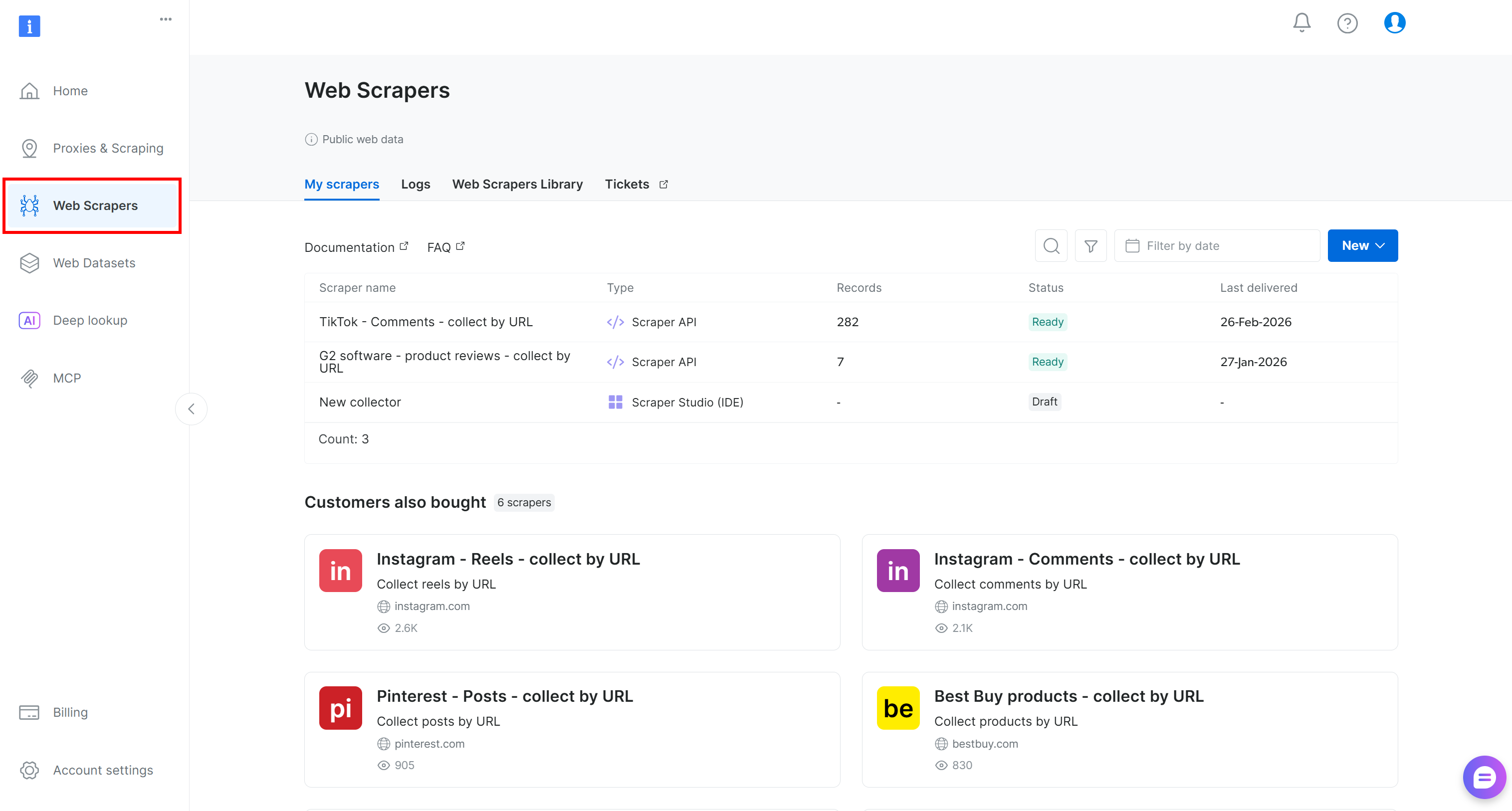
Vá para a guia “Biblioteca de Scrapers”. Você encontrará mais de 120 Scrapers prontos para algumas das plataformas mais populares da Internet.
Neste tutorial, procure por “tiktok.com”, pois nosso objetivo é recuperar dados de comentários ao vivo das postagens do TikTok e executar uma análise de sentimentos sobre eles.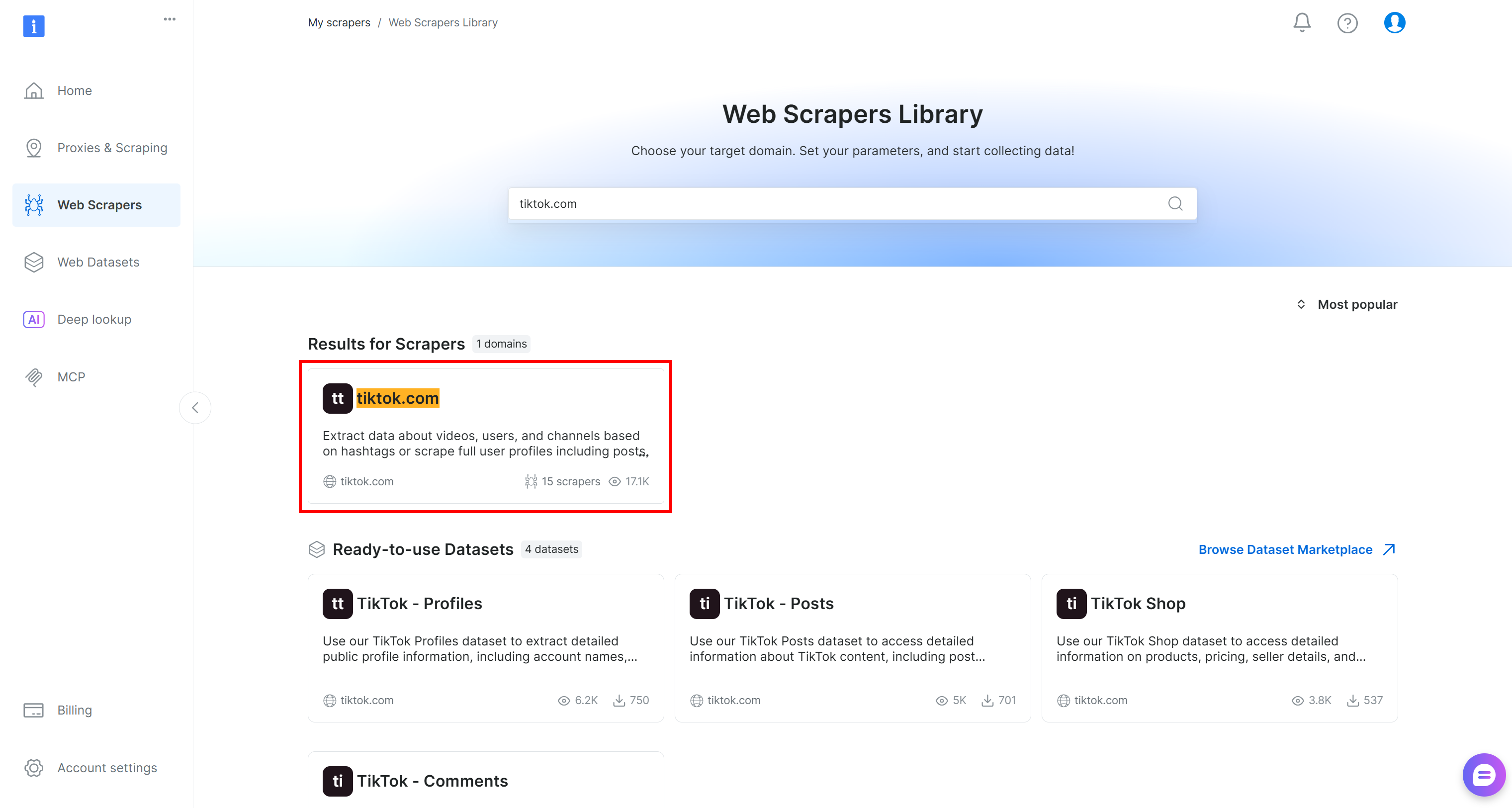
Na página do Scraper do TikTok, explore os endpoints de scraping disponíveis.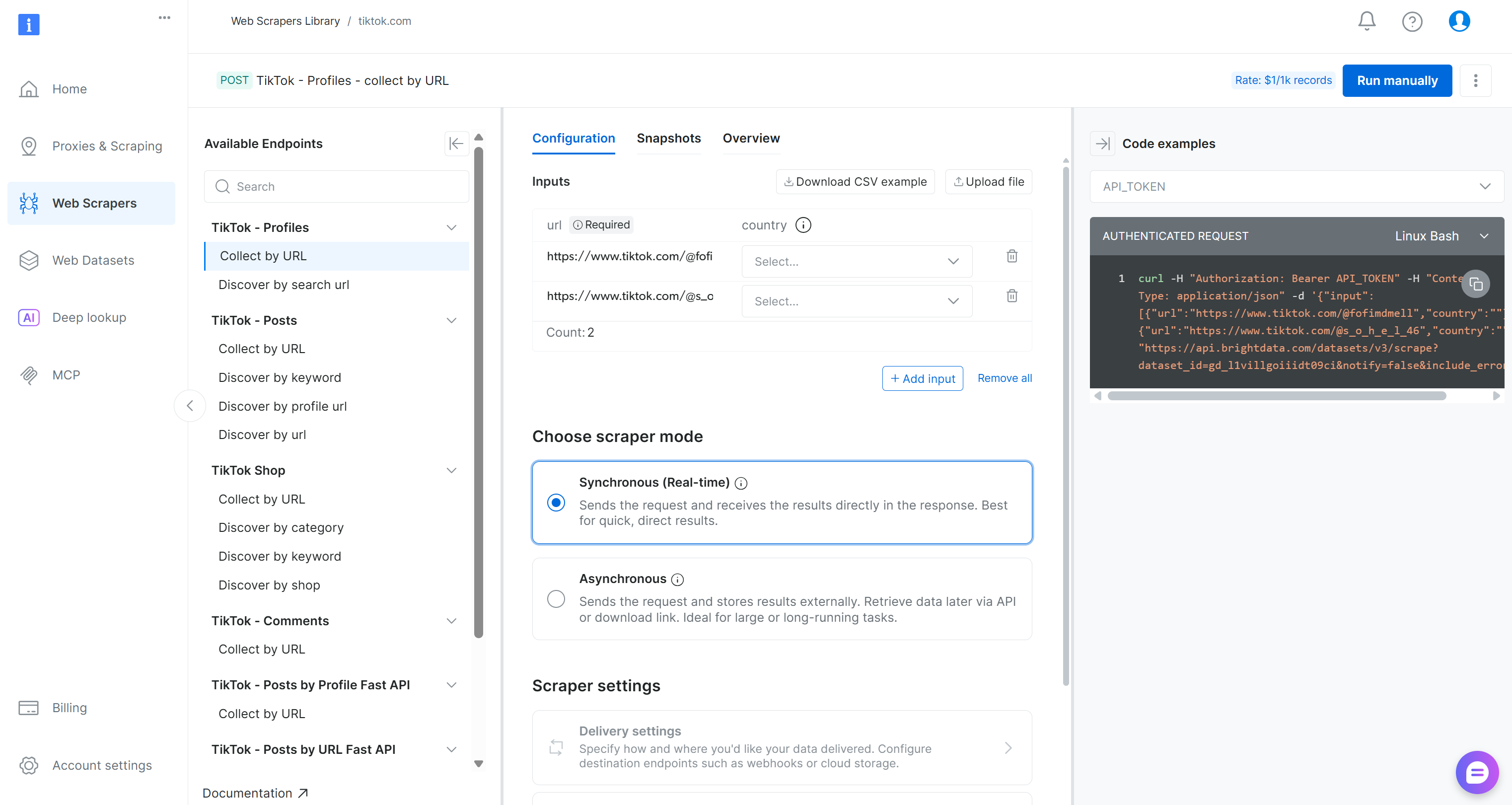
Aqui, você pode configurar parâmetros de entrada, inspecionar formatos de solicitação/resposta, revisar exemplos de chamadas de API e muito mais.
Para este pipeline, localize o Scraper “Coletar por URL” no menu suspenso “TikTok – Comentários”: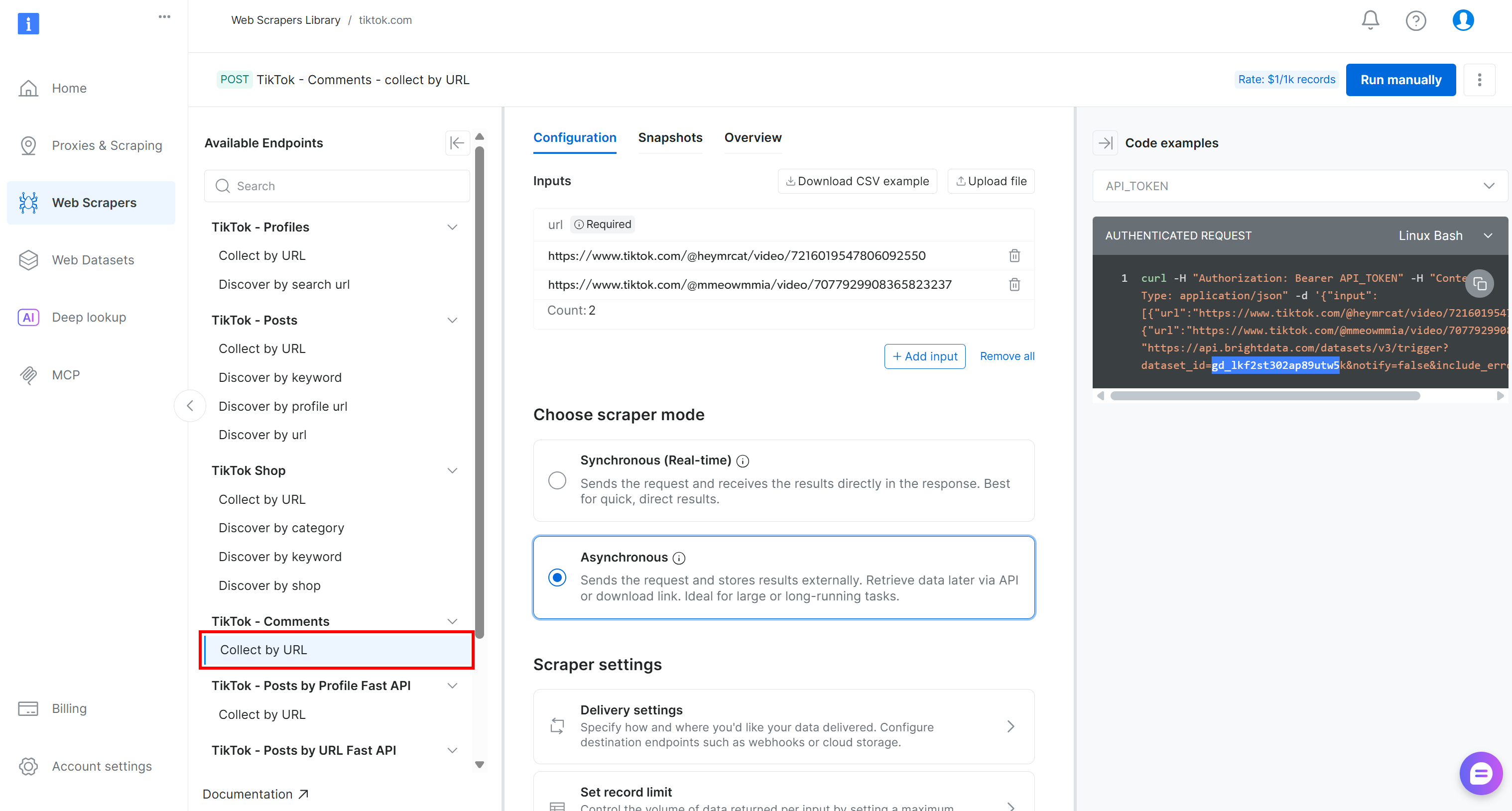
Esse é o endpoint desenvolvido pela Bright Data que você usará no componente de coleta de dados do seu pipeline Kubeflow.
Anote o ID do conjunto de dados:
gd_lkf2st302ap89utw5kVocê precisará dele para acionar a API específica de Scraping de dados para a coleta de dados de comentários do TikTok.
Além disso, como você pode ver no trecho à direita, as chamadas da API Bright Data para as APIs de Scraping de dados são autenticadas usando um API_TOKEN. Esse valor deve ser substituído pela sua chave API Bright Data, que é o método recomendado para autenticar solicitações de API.
Recupere sua chave API conforme explicado na documentação e guarde-a em um local seguro. Você a utilizará na próxima etapa!
Etapa 3: Defina o componente de coleta de dados da Web
Implemente o componente do pipeline Kubeflow para coleta de dados da web, integrando-o à API de Scraping de dados da Bright Data para scraping do TikTok:
@dsl.component(
base_image="python:3.10",
packages_to_install=["requests"]
)
def collect_tiktok_comments(post_urls: list, output_dataset: Output[Dataset]):
import requests, time, json, os
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Substitua pela sua chave API Bright Data
# O ID da API de Scraping de dados Bright Data "TikTok – Comentários → Coletar por URL"
TIKTOK_DATASET_ID = "gd_lkf2st302ap89utw5k"
# Os cabeçalhos HTTP comuns a todas as solicitações para a Bright Data
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", "Content-Type": "application/json"}
# Acione a API de Scraping de dados da Bright Data nas postagens do TikTok inseridas
trigger = requests.post(
f"https://api.brightdata.com/conjuntos_de_datos/v3/trigger?dataset_id={TIKTOK_DATASET_ID}",
headers=headers,
json={"input": [{"url": u} for u in post_urls]},
)
trigger.raise_for_status()
# Recuperar o ID do instantâneo de dados
snapshot_id = trigger.json()["snapshot_id"]
# Consultar o endpoint do instantâneo para verificar se o instantâneo
# contendo os dados de interesse foi produzido
scraped_data = []
status = "running"
enquanto status estiver em ["running", "building", "starting"]:
progress = requests.get(f"https://api.brightdata.com/conjuntos-de-dados/v3/snapshot/{snapshot_id}?format=json", headers=headers)
progress.raise_for_status()
# Acesse os dados da resposta JSON
response_data = progress.json()
# Se a resposta não incluir um status, significa que ela contém os dados coletados
if isinstance(response_data, dict) and "status" in response_data:
# Extraia o status atual do instantâneo
status = progress.json()["status"]
# Aguardando 5 segundos para a próxima verificação
time.sleep(5)
else:
scraped_data = response_data
break
# Armazene o conjunto de dados coletados
with open(output_dataset.path, "w", encoding="utf-8") as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=2)Observação: certifique-se de substituir o espaço reservado <YOUR_BRIGHT_DATA_API_KEY> pela chave da API Bright Data que você recuperou anteriormente. Em um pipeline pronto para produção, evite codificar segredos em seus componentes. Em vez disso, gerencie-os com segurança, conforme explicado na documentação.
No Kubeflow Pipelines, um componente é uma unidade independente (definida por meio da anotação dsl.component ) que executa uma tarefa específica. Neste caso, o componente recupera dados da web da Bright Data. Cada componente é empacotado em um contêiner Docker.
Para este componente, a imagem base é um ambiente Python 3.10. Em seguida, a bibliotecade solicitações é incluída porque é usada para fazer solicitações HTTP aos pontos de extremidade da API da Bright Data. No momento da implantação, quando o componente é construído, a imagem Python 3.10 será puxada e as solicitações serão instaladas automaticamente.
A Bright Data oferece suporte à entrega de dados síncrona e assíncrona por meio de suas APIs de Scraping de dados. O método síncrono é ideal para recuperação rápida de dados, enquanto o método assíncrono é mais adequado para Conjuntos de dados maiores. Para um pipeline pronto para produção, geralmente é recomendável confiar na abordagem assíncrona.
No método assíncrono, quando você solicita dados, eles podem não estar disponíveis imediatamente. Em vez disso, a Bright Data gera um instantâneo dos dados solicitados, o que pode levar alguns segundos ou mais. Isso requer um mecanismo de polling, no qual você verifica repetidamente se o instantâneo está disponível antes de recuperá-lo.
Dado esse contexto, veja abaixo como o código do componente de dados da web funciona, passo a passo:
- Envie uma solicitação de dados: o componente envia uma chamada de API para a Bright Data para começar a gerar o instantâneo dos dados solicitados.
- Pesquise o endpoint do instantâneo: o componente chama repetidamente o endpoint do instantâneo para verificar o status. Se a resposta contiver um campo
de status“em execução”, o instantâneo ainda está sendo preparado. Se o campode statusestiver ausente, significa que o instantâneo está pronto e contém os dados coletados. - Recuperar os dados: assim que o instantâneo estiver pronto, o componente extrai os dados da resposta da API e os disponibiliza para os componentes downstream no pipeline.
Incrível! O componente do pipeline Kubeflow para coleta de dados da web está completo.
Etapa 4: construir o componente de análise de sentimentos
Os dados coletados do TikTok serão recuperados como uma matriz JSON com a seguinte estrutura: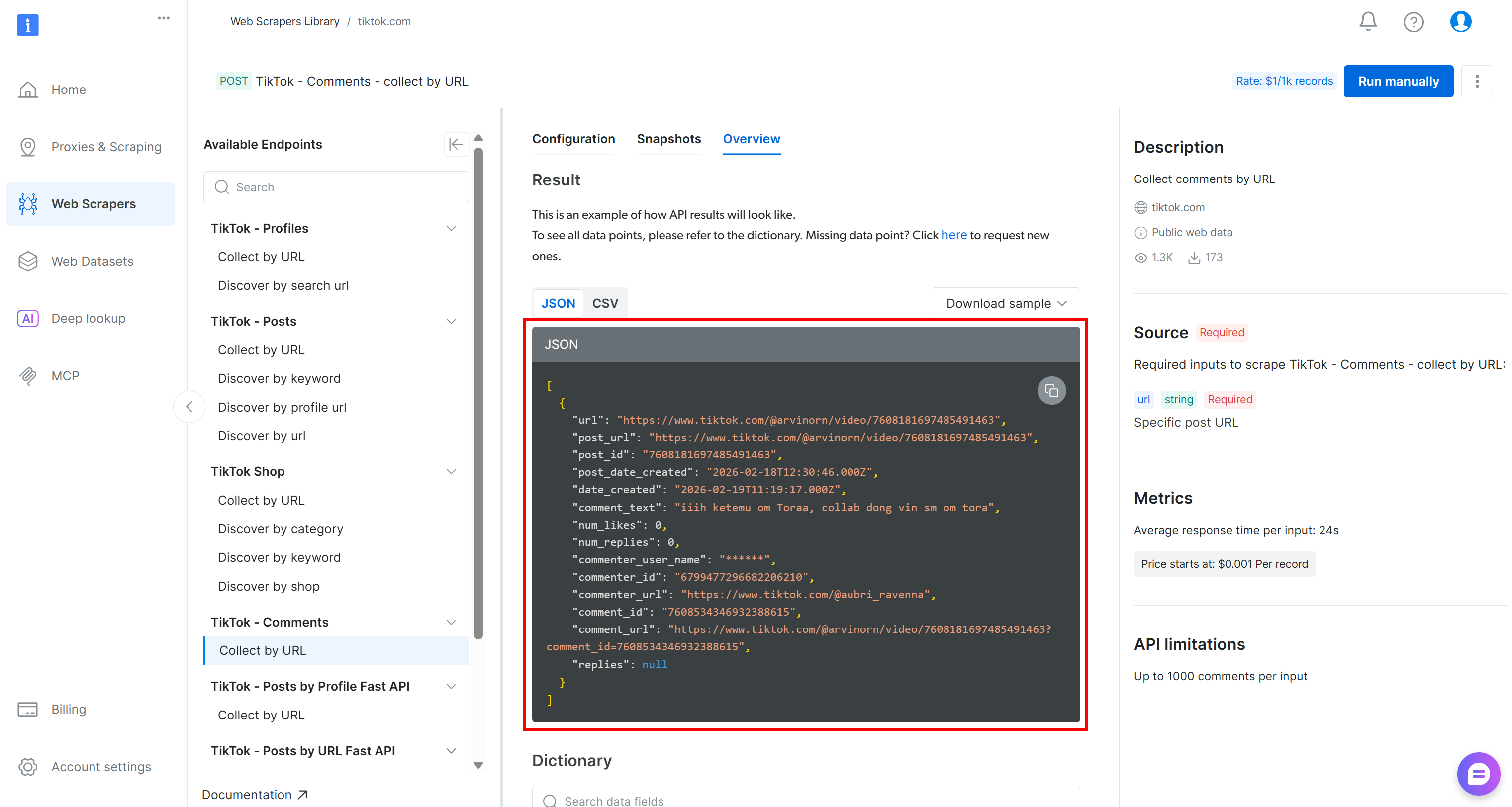
Para realizar a análise de sentimento desses dados, você pode passar o campo comment_text para uma ferramenta de análise de sentimento como o VADER Sentiment Analysis. O VADER é uma ferramenta baseada em léxico e regras projetada especificamente para capturar sentimentos expressos nas mídias sociais. É claro que você também pode usar outros métodos de análise de sentimento, incluindo modelos baseados em IA.
O VADER está incluído no NLTK, um dos kits de ferramentas Python mais populares para processamento de linguagem natural. Um fluxo de trabalho típico é:
- Leia a matriz JSON de entrada (os comentários coletados do TikTok) do componente anterior.
- Use
pandaspara simplificar a filtragem e seleção de dados. - Passar os dados de texto para o VADER Sentiment Analyzer via
nltk. - Salve os resultados analisados para serem usados pelos componentes downstream.
Juntando tudo, o componente de análise de sentimentos pode ser implementado como:
@dsl.component(
base_image="python:3.10",
packages_to_install=["pandas", "nltk"]
)
def sentiment_analysis(input_dataset: Input[Dataset], sentiment_output: Output[Dataset]):
import pandas as pd
from nltk.sentiment import SentimentIntensityAnalyzer
import nltk
# Baixe o léxico de sentimentos VADER (usado pelo NLTK para pontuação de sentimentos)
nltk.download("vader_lexicon")
# Carregue o conjunto de dados de entrada contendo comentários do TikTok
df = pd.read_json(input_dataset.path)
# Inicialize o analisador de sentimentos
sia = SentimentIntensityAnalyzer()
# Aplicar a análise de sentimento a cada comentário e classificá-lo como positivo, negativo ou neutro
df["sentiment"] = df["comment_text"].apply(lambda t: (
"positive" se sia.polarity_scores(str(t))["compound"] >= 0.05 else
"negativo" se sia.polarity_scores(str(t))["compound"] <= -0,05, caso contrário, "neutro"
))
# Salvar os resultados no conjunto de dados de saída para componentes downstream
df.to_json(sentiment_output.path, orient="records")Ótimo! Os dois componentes principais do pipeline (ou seja, coleta de dados da web e análise de sentimentos) agora foram totalmente implementados.
Etapa 5: Finalizar o pipeline do Kubeflow
Agora que os dois componentes estão prontos, você pode combiná-los em um único pipeline Kubeflow usando uma função anotada com dsl.pipeline:
@dsl.pipeline(name="TikTok Sentiment Pipeline")
def tiktok_sentiment_pipeline():
# Lista de URLs de postagens do TikTok para extrair comentários
tiktok_post_urls = [
"https://www.tiktok.com/@nike/video/7600211777267272991",
"https://www.tiktok.com/@nike/video/7556252854294482189"
]
# Coletar comentários do TikTok usando o componente de Scraping de dados da Bright Data
collect_task = collect_tiktok_comments(post_urls=tiktok_post_urls)
# Realizar análise de sentimento nos comentários coletados
sentiment_task = sentiment_analysis(
input_dataset=collect_task.outputs["output_dataset"]
)Este pipeline primeiro executa o componente de coleta de comentários do TikTok em dois vídeos de destino do mesmo perfil (@nike). Mais especificamente, os dois vídeos do TikTok foram selecionados porque apresentam novos tênis. Realizar uma análise de sentimento sobre eles é fundamental para entender o que o público pensa sobre o lançamento.
O conjunto de dados produzido por meio da API de Scraping de dados Bright Data é então passado para o componente de análise de sentimentos downstream. A etapa de análise de sentimentos processa os comentários coletados e gera um novo conjunto de dados contendo rótulos de sentimentos (positivos, negativos ou neutros). Essa saída pode ser usada por componentes downstream adicionais, como relatórios ou visualização.
Excelente! O pipeline do Kubeflow agora está totalmente definido.
Etapa 6: Compilar o pipeline
A etapa final é compilar o pipeline em um arquivo de pipeline Kubeflow YAML:
if __name__ == "__main__":
compiler.Compiler().compile(
pipeline_func=tiktok_sentiment_pipeline,
package_path="tiktok_sentiment_analysis_kfp_pipeline.yaml"
)Quando você executa o script tiktok_sentiment_analysis_kfp_pipeline.py, esse código gera um arquivo chamado tiktok_sentiment_analysis_kfp_pipeline.yaml. Esse arquivo YAML contém a especificação completa do pipeline necessária para a implantação do Kubeflow. Missão cumprida!
Etapa 7: Código final
Abaixo está o pipeline Kubeflow completo que você deve ter no seu arquivo tiktok_sentiment_analysis_kfp_pipeline.py:
# tiktok_sentiment_analysis_kfp_pipeline.py
# pip install kfp
from kfp import dsl, compiler
from kfp.dsl import Input, Output, Dataset
@dsl.component(
base_image="python:3.10",
packages_to_install=["requests"]
)
def collect_tiktok_comments(post_urls: list, output_dataset: Output[Dataset]):
import requests, time, json, os
BRIGHT_DATA_API_KEY = "<SUA_CHAVE_API_BRIGHT_DATA>" # Substitua pela sua chave API Bright Data
# O ID da API de Scraping de dados Bright Data "TikTok – Comentários → Coletar por URL"
TIKTOK_DATASET_ID = "gd_lkf2st302ap89utw5k"
# Os cabeçalhos HTTP comuns a todas as solicitações para a Bright Data
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", "Content-Type": "application/json"}
# Acione a API de Scraping de dados da Bright Data nas postagens do TikTok inseridas
trigger = requests.post(
f"https://api.brightdata.com/conjuntos_de_datos/v3/trigger?dataset_id={TIKTOK_DATASET_ID}",
headers=headers,
json={"input": [{"url": u} for u in post_urls]},
)
trigger.raise_for_status()
# Recuperar o ID do instantâneo de dados
snapshot_id = trigger.json()["snapshot_id"]
# Consultar o endpoint do instantâneo para verificar se o instantâneo
# contendo os dados de interesse foi produzido
scraped_data = []
status = "running"
enquanto status estiver em ["running", "building", "starting"]:
progress = requests.get(f"https://api.brightdata.com/conjuntos-de-dados/v3/snapshot/{snapshot_id}?format=json", headers=headers)
progress.raise_for_status()
# Acesse os dados da resposta JSON
response_data = progress.json()
# Se a resposta não incluir um status, significa que ela contém os dados coletados
if isinstance(response_data, dict) and "status" in response_data:
# Extraia o status atual do instantâneo
status = progress.json()["status"]
# Aguardando 5 segundos para a próxima verificação
time.sleep(5)
else:
scraped_data = response_data
break
# Armazene o conjunto de dados coletados
with open(output_dataset.path, "w", encoding="utf-8") as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=2)
@dsl.component(
base_image="python:3.10",
packages_to_install=["pandas", "nltk"]
)
def sentiment_analysis(input_dataset: Input[Dataset], sentiment_output: Output[Dataset]):
import pandas as pd
from nltk.sentiment import SentimentIntensityAnalyzer
import nltk
# Baixe o léxico de sentimentos VADER (usado pelo NLTK para pontuação de sentimentos)
nltk.download("vader_lexicon")
# Carregue o conjunto de dados de entrada contendo comentários do TikTok
df = pd.read_json(input_dataset.path)
# Inicialize o analisador de sentimentos
sia = SentimentIntensityAnalyzer()
# Aplicar a análise de sentimento a cada comentário e classificar como positivo, negativo ou neutro
df["sentiment"] = df["comment_text"].apply(lambda t: (
"positive" se sia.polarity_scores(str(t))["compound"] >= 0.05 else
"negativo" se sia.polarity_scores(str(t))["compound"] <= -0,05 else "neutro"
))
# Salve os resultados no conjunto de dados de saída para componentes downstream
df.to_json(sentiment_output.path, orient="records")
@dsl.pipeline(name="TikTok Sentiment Pipeline")
def tiktok_sentiment_pipeline():
# Lista de URLs de postagens do TikTok para extrair comentários
tiktok_post_urls = [
"https://www.tiktok.com/@nike/video/7600211777267272991",
"https://www.tiktok.com/@nike/video/7556252854294482189"
]
# Coletar comentários do TikTok usando o componente de Scraping de dados da Bright Data
collect_task = collect_tiktok_comments(post_urls=tiktok_post_urls)
# Realizar análise de sentimento nos comentários coletados
sentiment_task = sentiment_analysis(
input_dataset=collect_task.outputs["output_dataset"]
)
if __name__ == "__main__":
compiler.Compiler().compile(
pipeline_func=tiktok_sentiment_pipeline,
package_path="tiktok_sentiment_analysis_kfp_pipeline.yaml"
)Inicie o script acima com:
python3 tiktok_sentiment_analysis_kfp_pipeline.pyApós executar o comando, um arquivo chamado tiktok_sentiment_analysis_kfp_pipeline.yaml deve ser gerado, conforme mostrado abaixo:
Agora você pode implantá-lo no Kubeflow para teste ou executá-lo localmente usando o Docker. Neste guia, vamos nos concentrar na segunda abordagem.
Etapa 8: teste o pipeline do Kubeflow localmente
Para executar o pipeline do Kubeflow localmente, você pode usar a classe DockerRunner. Isso requer que o Docker esteja instalado e em execução em sua máquina.
O DockerRunner executa cada tarefa do pipeline dentro de um contêiner Docker separado. Em outros termos, ele simula como o pipeline seria executado em um ambiente Kubeflow real.
Com seu ambiente virtual ativado, comece instalando a biblioteca docker necessária:
pip install docker Em seguida, adicione um arquivo run_pipeline_local.py à pasta do seu projeto:
kfp-bright-data-pipeline/
├── .venv/
├── run_pipeline_local.py # <-----------
├── tiktok_sentiment_analysis_kfp_pipeline.py
└── tiktok_sentiment_analysis_kfp_pipeline.yamlPreencha-o da seguinte forma:
# run_pipeline_local.py
# pip install docker
from kfp import local
from tiktok_sentiment_analysis_kfp_pipeline import tiktok_sentiment_pipeline
# inicialize o executor Docker local
local.init(runner=local.DockerRunner())
# Execute o pipeline como uma chamada de função Python
pipeline_task = tiktok_sentiment_pipeline()Este script importa a função tiktok_sentiment_pipeline() do tiktok_sentiment_analysis_kfp_pipeline.py e a executa através do executor Docker local, executando cada componente em seu próprio contêiner.
Para testar o pipeline, certifique-se de que o Docker esteja em execução. Em seguida, execute:
python3 run_pipeline_local.pyOs logs de execução devem mostrar uma mensagem de sucesso, semelhante ao exemplo abaixo:
A saída do pipeline será salva na pasta ./local_outputs. Hora de explorar os resultados!
Etapa 9: explorando os resultados do pipeline
Depois de executar o pipeline, abra a pasta ./local_outputs. Nela, você encontrará uma subpasta para a execução atual contendo todos os artefatos produzidos.
Comece explorando o conjunto de dados de saída produzido pelo componente collect-tiktok-comments: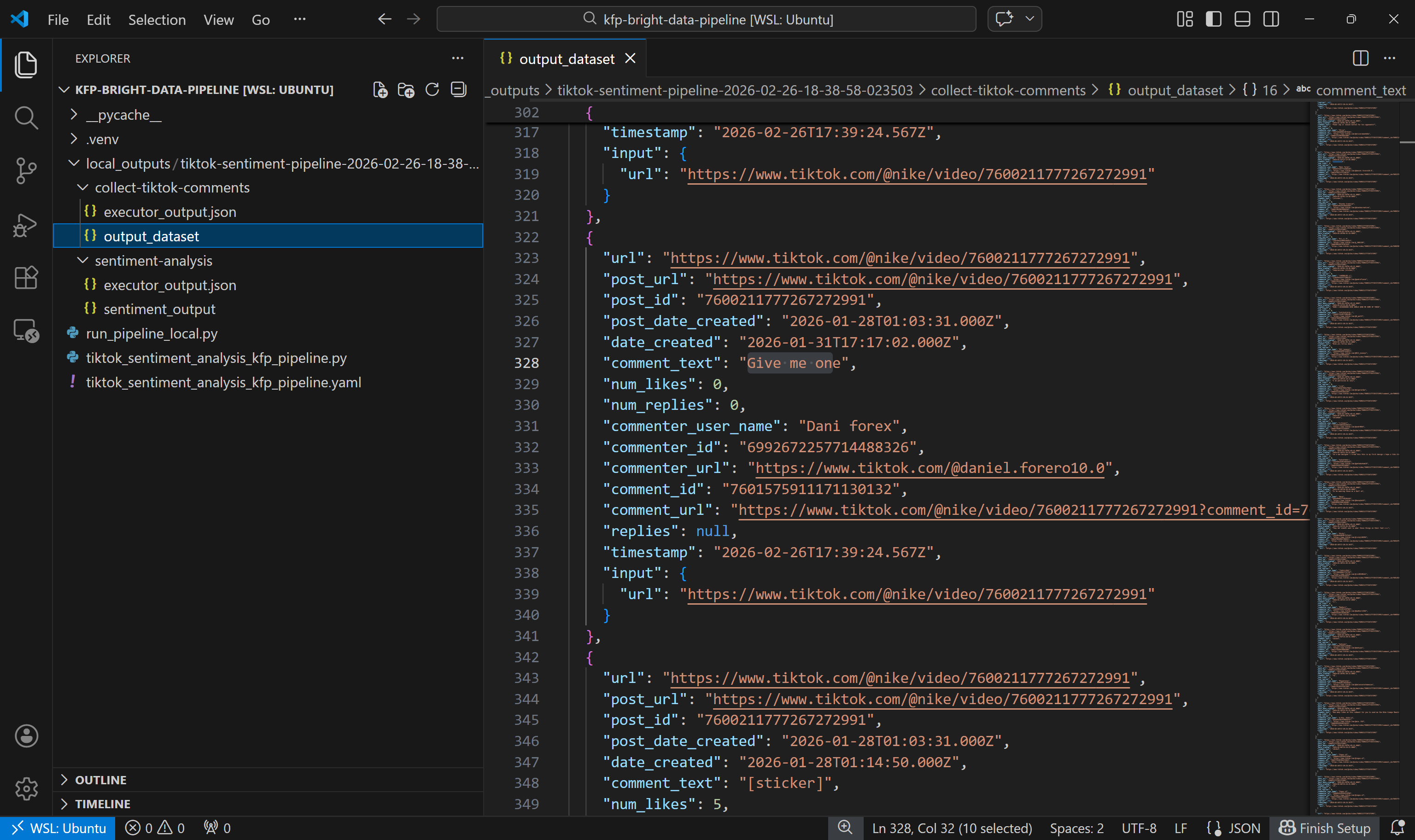
Este conjunto de dados inclui os comentários retornados pelo TikTok Scraper via Bright Data para as duas postagens especificadas, conforme esperado.
Em seguida, observe o conjunto de dados de saída da análise de sentimento: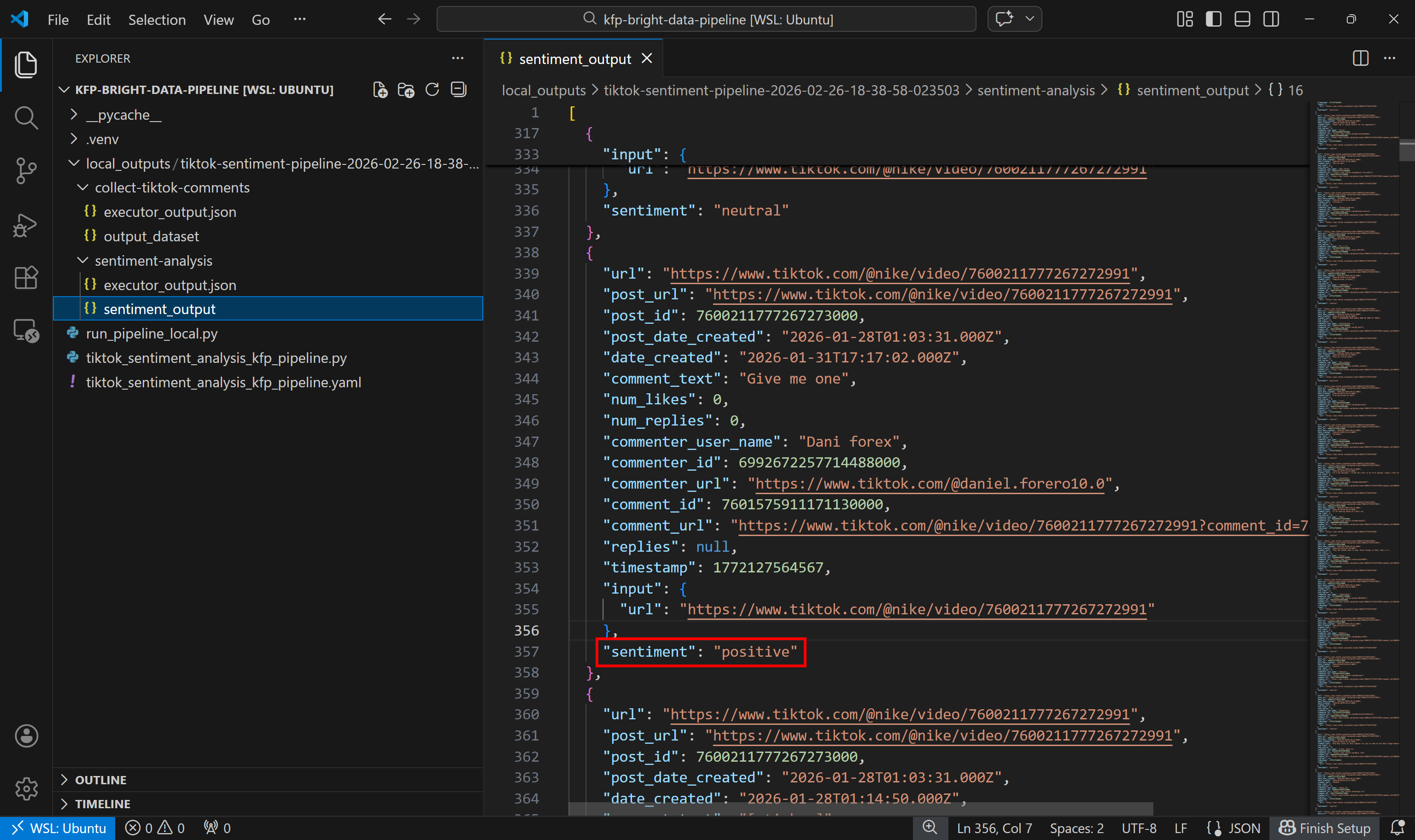
Observe como cada comentário foi rotulado como positivo, negativo ou neutro pelo componente de análise de sentimento.
Et voilà! Você acabou de ver como construir um pipeline Kubeflow que recupera dados novos da web usando o Bright Data e, em seguida, os analisa.
Conclusão
Neste tutorial, você entendeu por que os pipelines do Kubeflow se beneficiam de dados recentes recuperados por meio do Scraping de dados. Em particular, você viu a importância de ter um componente dedicado em seu pipeline para coletar dados recentes, contextuais e estruturados da web.
A Bright Data oferece suporte a isso por meio de uma ampla variedade de APIs de Scraping de dados, que atuam como feeds de dados estruturados para seus pipelines. Conforme demonstrado, graças às APIs de Scraping da Bright Data, construir um componente de coleta de dados da web em um pipeline Kubeflow é bastante simples!
Crie uma conta gratuita na Bright Data e comece a explorar nossas soluções de dados da web hoje mesmo!






