

Neste artigo, você aprenderá:
- O que é o Azure IA Foundry e o que ele oferece.
- Por que a integração com a API SERP da Bright Data no Azure IA Foundry é uma estratégia vencedora.
- Como criar um fluxo de prompt de IA do Azure do mundo real conectando-se à API SERP.
Vamos nos aprofundar!
O que é o Azure IA Foundry?
O Azure IA Foundry é uma plataforma unificada que fornece um conjunto de ferramentas e serviços para criar, implantar e gerenciar aplicativos, agentes e fluxos de IA. Em outras palavras, ela atua como uma “fábrica de IA”, padronizando o processo de criação de sistemas de IA.
Seu principal objetivo é ajudá-lo a passar do conceito à produção. Isso é alcançado oferecendo acesso a uma ampla gama de modelos e recursos de provedores de IA, como Azure OpenAI, Meta e Mistral, juntamente com ferramentas para desenvolvimento, implantação e monitoramento contínuo.
Por que integrar a API SERP da Bright Data em um Azure IA Foundry?
O Azure IA Foundry apresenta uma longa lista de LLMs, mas, independentemente de qual você escolher, o conhecimento deles é estático. Por exemplo, um LLM não tem conhecimento das notícias de hoje sobre ações, dos resultados esportivos de ontem à noite etc. Isso pode resultar em respostas “obsoletas” ou “alucinadas”.
Para superar essa limitação, você pode criar um sistema para “aterrar” um LLM com dados em tempo real da Internet. Essa abordagem é especialmente comum em fluxos de trabalho RAG(Retrieval-Augmented Generation), em que o LLM recebe informações externas antes de gerar uma resposta, garantindo que sua saída seja baseada em fatos atuais.
O Azure IA vem com uma ferramenta de aterramento integrada, mas ela é limitada ao Bing como fonte de dados, o que nem sempre é o ideal. Uma alternativa mais profissional e flexível é a API SERP da Bright Data!
A API SERP permite que você execute programaticamente consultas de pesquisa em mecanismos de pesquisa e recupere o conteúdo completo da SERP, fornecendo uma fonte confiável de dados novos e verificáveis que podem ser perfeitamente integrados em agentes de IA e fluxos de trabalho de LLM. Explore todos os seus recursos na documentação oficial.
No Azure IA Foundry, a integração de APIs de terceiros pode ser implementada em agentes e fluxos. Aqui, vamos nos concentrar especificamente nos fluxos de prompt, que são particularmente adequados para cenários de RAG.
Como recuperar o contexto de pesquisa na Web em um fluxo de prompt do Azure IA com a API SERP
Nesta seção guiada, você verá como integrar a API SERP da Bright Data em um fluxo de IA do Azure como parte de um fluxo de prompt de análise de notícias. Esse fluxo de trabalho consiste em quatro etapas principais:
- Recebimento de entrada: Você fornece ao fluxo de trabalho um tópico de seu interesse para recuperar notícias relevantes.
- Obtenção de notícias: um nó Python especializado pega o tópico de entrada e o envia para a API SERP da Bright Data para obter artigos de notícias do Google.
- Análise de notícias: Um LLM processa os dados recuperados pela API SERP para identificar quais itens de notícias valem a pena ler.
- Geração de saída: O relatório Markdown produzido lista cada item de notícia extraído da SERP, juntamente com uma breve descrição e uma pontuação que indica a sua leitura.
Observação: este é apenas um exemplo, e você pode tirar proveito da API SERP em muitos outros cenários e casos de uso.
Siga as instruções abaixo para criar um fluxo de trabalho no estilo RAG com base em dados novos da API SERP da Bright Data no Azure IA Foundry!
Pré-requisitos
Para acompanhar esta seção do tutorial, certifique-se de ter:
- Uma conta da Microsoft.
- Uma assinatura do Azure (até mesmo a avaliação gratuita é suficiente).
- Uma conta da Bright Data com uma chave de API ativa (com permissões de administrador ).
Siga o guia oficial da Bright Data para obter sua chave de API. Guarde-a em um local seguro, pois você precisará dela em breve.
Etapa 1: criar um Hub de IA do Azure
Os fluxos de prompt de IA do Azure só estão disponíveis nos Hubs de IA do Azure, portanto, a primeira etapa é criar um.
Para fazer isso, faça login em sua conta do Azure e abra o serviço Azure IA Foundry clicando em seu ícone ou procurando por ele na barra de pesquisa:
Você deverá acessar a página de gerenciamento “IA Foundry”:
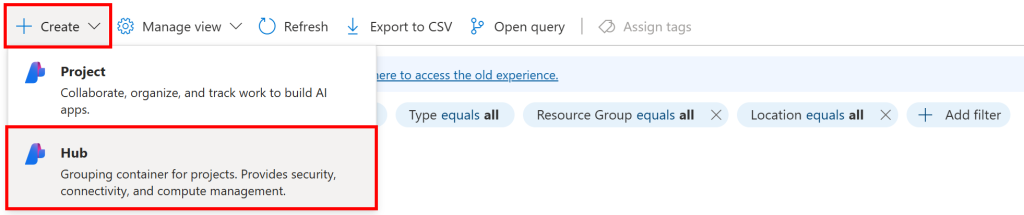
Aqui, clique no botão “Create” (Criar) e selecione a opção “Hub”:
Em seguida, preencha o formulário de criação do Azure IA Hub, conforme mostrado abaixo:
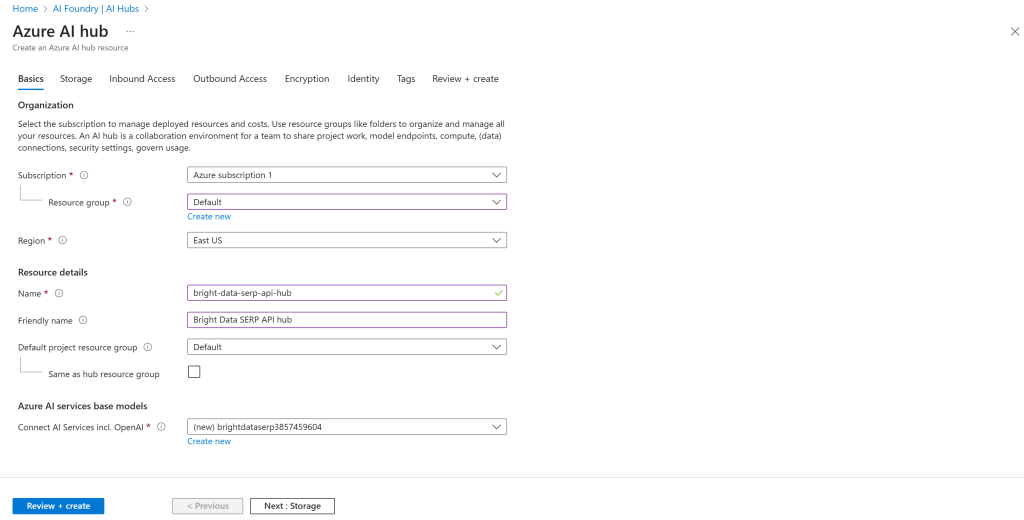
Escolha uma região, selecione um grupo de recursos existente (ou crie um novo, se necessário) e dê um nome ao seu Hub, como bright-data-serp-ai-hub.
Em seguida, clique no botão “Review + Create” (Revisar + Criar). Você verá um resumo:
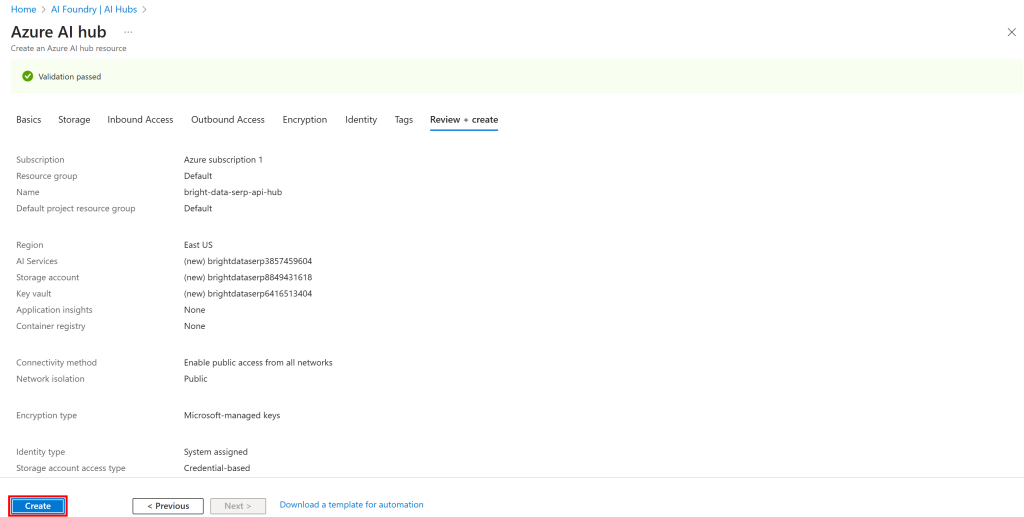
Se tudo estiver correto, clique em “Create” (Criar) para iniciar a implantação.
O processo de inicialização pode levar alguns minutos. Quando estiver concluído, você verá uma página de confirmação como esta:
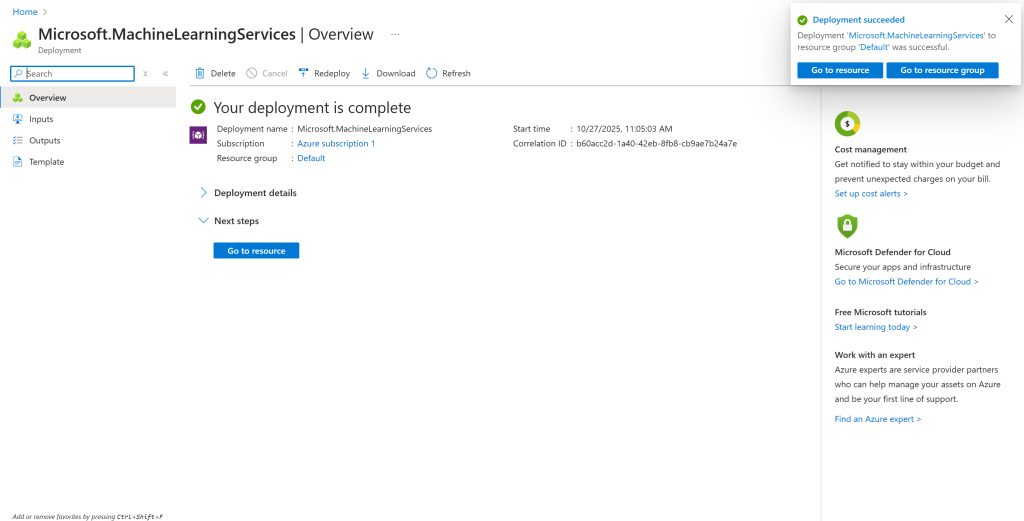
Maravilhoso! Agora você tem um Hub de IA do Azure onde pode criar um projeto e inicializar seu fluxo de prompt.
Etapa 2: criar um projeto no IA Hub
Para gerenciar um fluxo de prompt, primeiro você precisa criar um projeto no IA Hub. Comece clicando na opção “IA Hubs” no menu à esquerda:
Clique no nome do seu Hub e, na seção à direita que aparece, selecione “Create project” (Criar projeto):
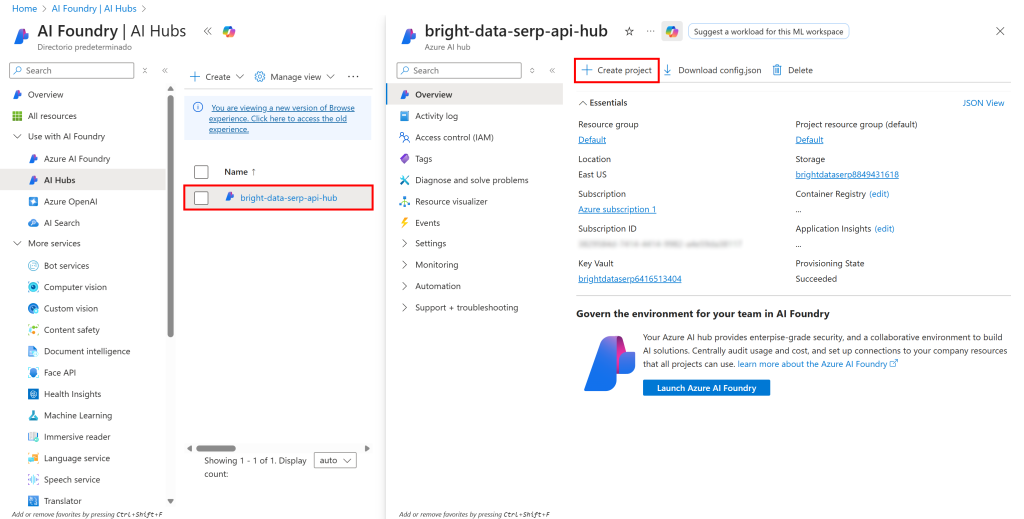
Preencha o formulário de criação de projeto. Desta vez, dê ao seu projeto um nome como serp-api-flow:
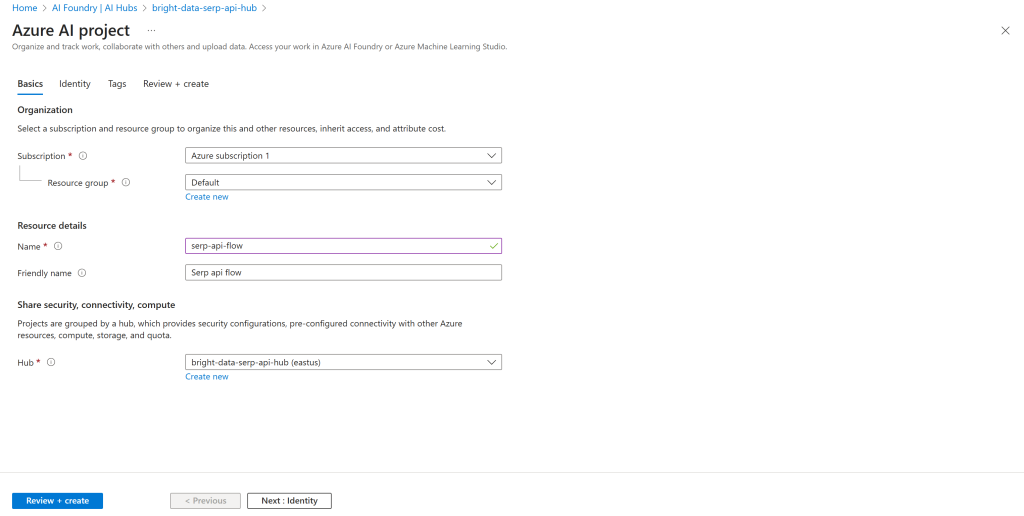
Clique no botão “Review + create” e, em seguida, verifique se tudo está correto na seção de resumo. Por fim, pressione “Create” (Criar) para implantar o projeto.
Aguarde alguns instantes para que o projeto seja inicializado. Quando estiver pronto, você o verá listado na página “IA Hubs”. Clique nele:
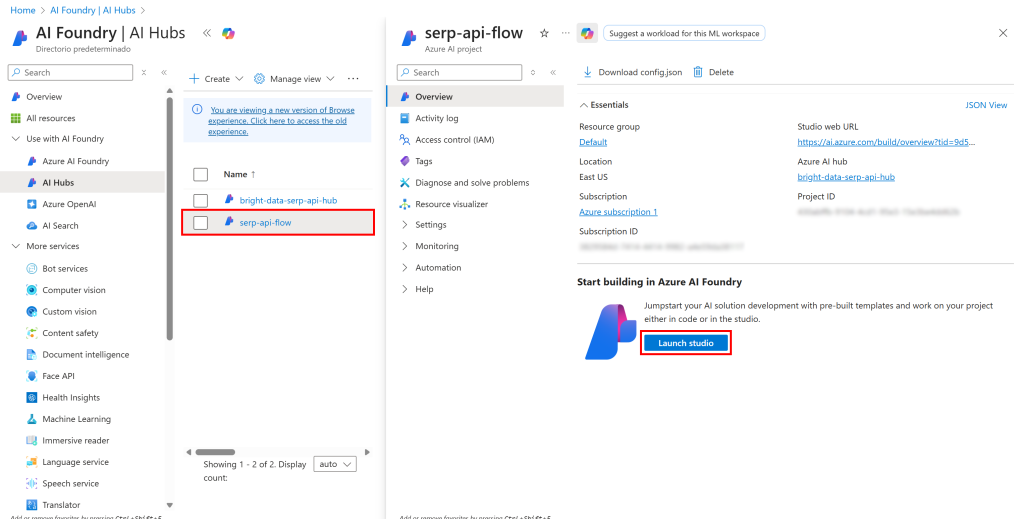
Pressione o botão “Launch studio” para abri-lo no estúdio do Azure IA Foundry:
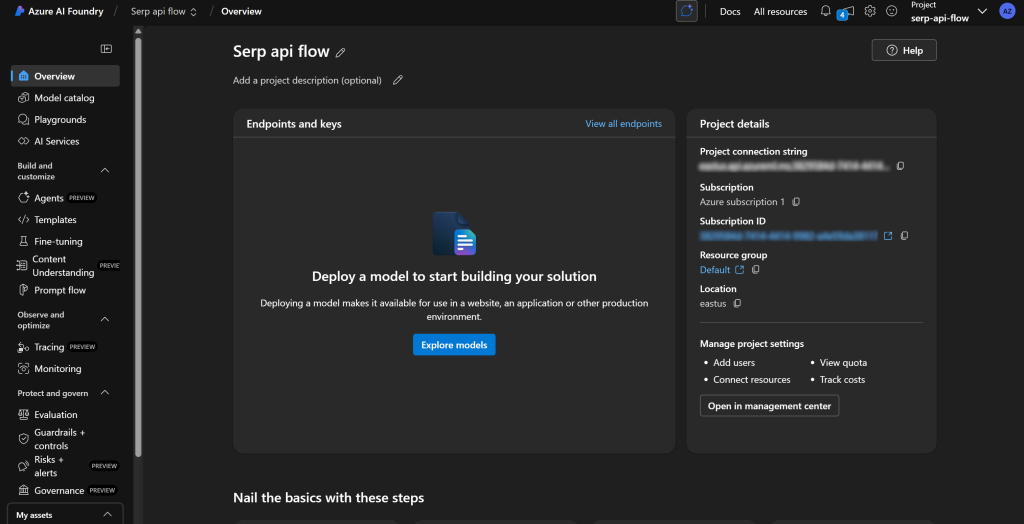
Observe na parte superior que você está operando no projeto “Serp api flow”. Se esse não for o caso (por exemplo, se você tiver vários projetos), certifique-se de selecionar o correto.
Ótimo! Prepare-se para definir seu fluxo de prompt de IA do Azure.
Etapa nº 3: implantar um LLM
Para usar os nós LLM em seus fluxos de prompt, o Azure exige que você primeiro implante um dos modelos de IA disponíveis.
Para fazer isso, no menu à esquerda, selecione a opção “Catálogo de modelos”. Na página do catálogo, pesquise o modelo de IA que você deseja usar. Por exemplo, vamos supor que você queira usar o gpt-5-mini.
Procure por “gpt-5-mini” e selecione-o:
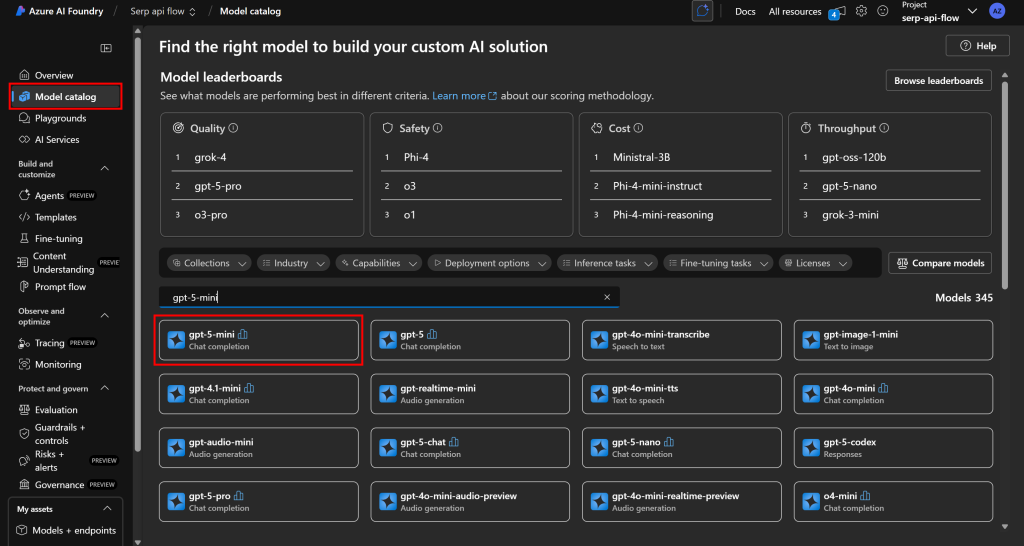
Na página do modelo, clique em “Use this model” (Usar este modelo) para adotá-lo:
Na janela modal exibida, clique no botão “Create resource and deploy” (Criar recurso e implantar) e aguarde até que o modelo termine de ser implantado:
Esse processo pode levar alguns minutos, portanto, seja paciente. Quando a implantação estiver concluída, você verá o modelo disponível em seu projeto de IA do Azure da seguinte forma:
Maravilhoso! Agora você tem um mecanismo LLM pronto para alimentar seu fluxo de prompt.
Etapa 4: criar um novo fluxo de prompt
Finalmente chegou a hora de começar a trabalhar em seu fluxo de prompt. Comece selecionando “Prompt flow” no menu à esquerda e, em seguida, clique no botão “Create” (Criar):
No modal “Create a new flow” (Criar um novo fluxo), clique em “Create” (Criar) no cartão “Standard flow” (Fluxo padrão) para iniciar um novo fluxo de prompt básico:
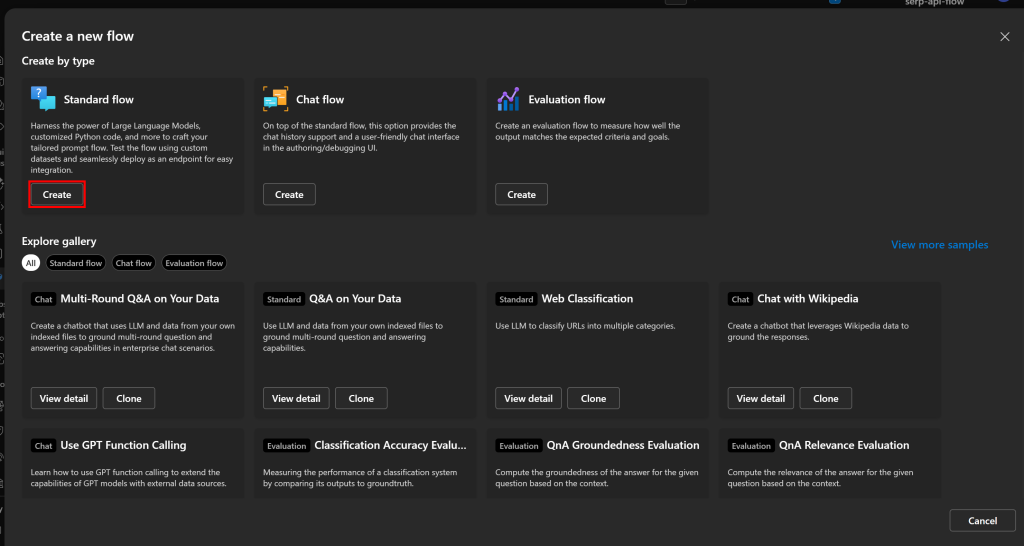
Você será solicitado a inserir um nome de fluxo. Chame-o de algo como bright-data-serp-api-flow:
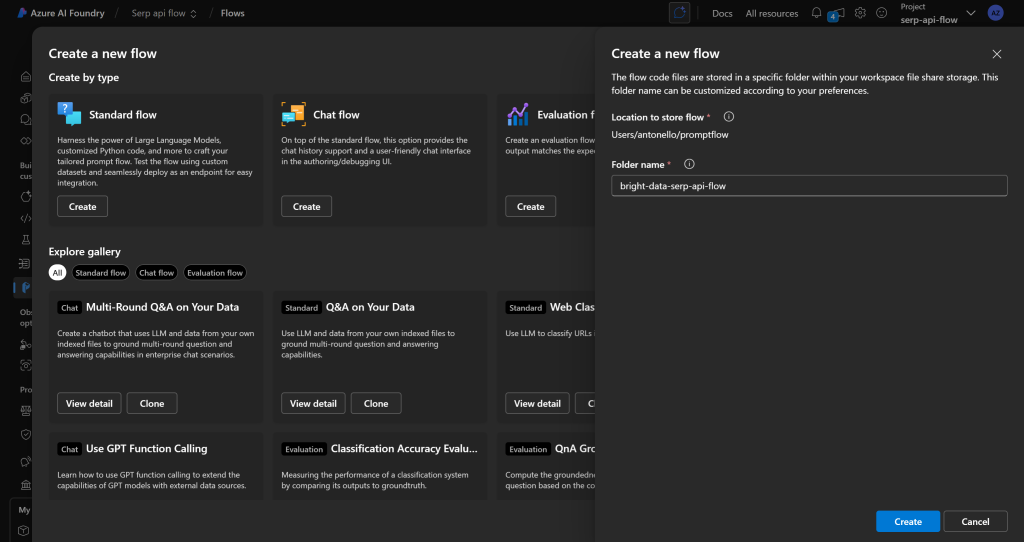
Pressione o botão “Create” (Criar), aguarde a inicialização do fluxo de prompt e você deverá obter um fluxo como este:
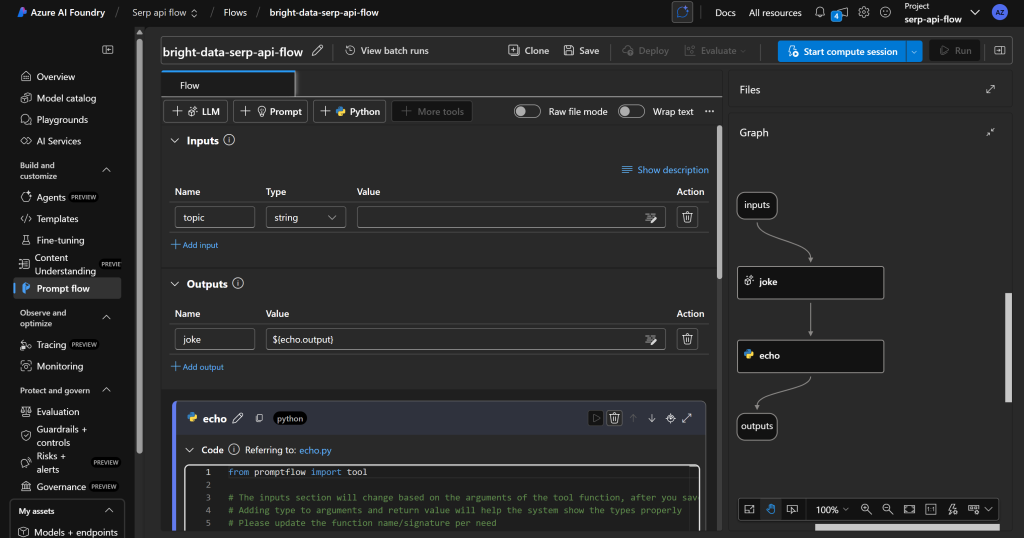
Como você pode ver, à direita, há uma representação DAG(Directed Acyclic Graph) do seu fluxo.
Em vez disso, à esquerda, você encontrará um editor visual no qual poderá definir os nós do fluxo. Todas as alterações feitas à esquerda são automaticamente refletidas no DAG à direita.
Por padrão, o fluxo padrão inclui um exemplo simples que pede à IA para contar uma piada.
Comece do zero, excluindo todos os nós existentes e pressionando “Start compute session” (Iniciar sessão de computação) para ativar sua plataforma de desenvolvimento de fluxo:
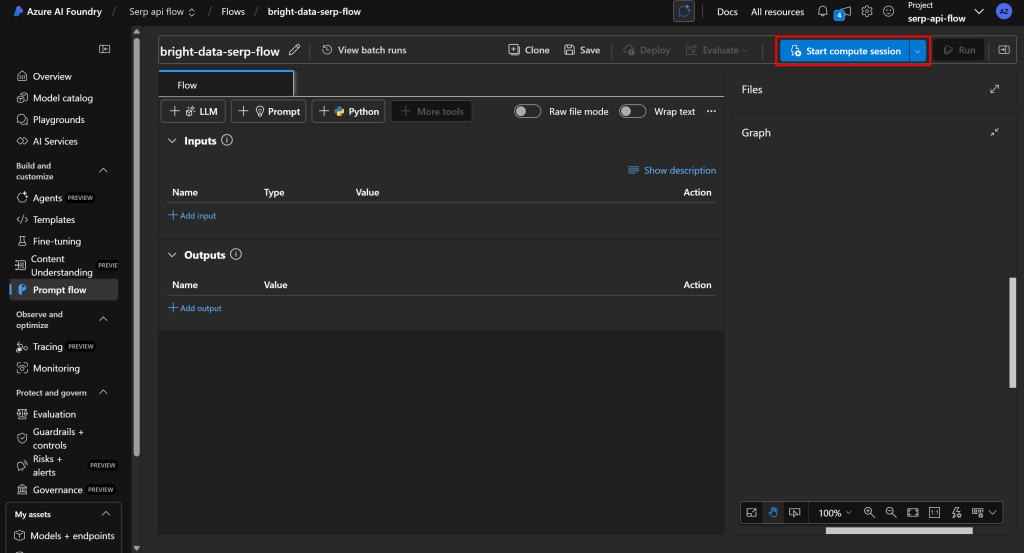
Observação: ao iniciar uma sessão de computação, o Azure tenta automaticamente iniciar a instância de computação padrão. No entanto, pode levar vários minutos ou até horas para alocar o recurso. Para evitar longos tempos de espera, considere iniciar manualmente a sessão de computação usando uma configuração personalizada em sua própria instância de computação.
Muito bem! Agora você tem uma tela em branco pronta para ser transformada em um fluxo de prompt de IA do Azure alimentado pela API SERP da Bright Data.
Etapa 5: projetar seu fluxo de prompt
Antes de criar o fluxo, você deve definir claramente os nós que ele incluirá.
Nesse caso, o objetivo é criar um fluxo de recuperação e avaliação de notícias. Com base em um tópico, esse fluxo se baseará na API SERP da Bright Data para buscar artigos de notícias relacionados do Google e, em seguida, passá-los para um LLM para avaliação com base no valor da leitura. Dessa forma, você pode identificar rapidamente quais artigos valem a pena ler.
Para conseguir isso, seu fluxo consistirá em quatro nós:
- Um nó de entrada que aceita o tópico para realizar a pesquisa de notícias na Web.
- Um nó de ferramenta Python que chama a API SERP da Bright Data usando o tópico fornecido.
- Um nó LLM que processa os dados SERP retornados pela API para identificar e avaliar os artigos de notícias.
- Um nó de saída que exibe o relatório final gerado pelo LLM.
Nas etapas a seguir, você aprenderá a implementar esse fluxo de prompt de IA do Azure!
Etapa nº 6: adicionar o nó de entrada
Todo fluxo deve incluir um nó de entrada e um nó de saída. Portanto, os nós de entrada e saída não podem ser removidos e já fazem parte do fluxo.
Para configurar o nó de entrada, vá para a seção “Inputs” (Entradas) do seu fluxo e clique no botão “Add button” (Adicionar botão):
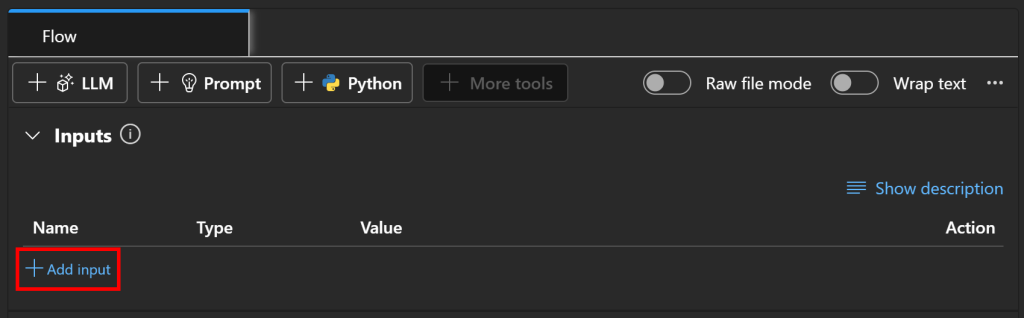
Defina a entrada como tópico e defina seu tipo como string:
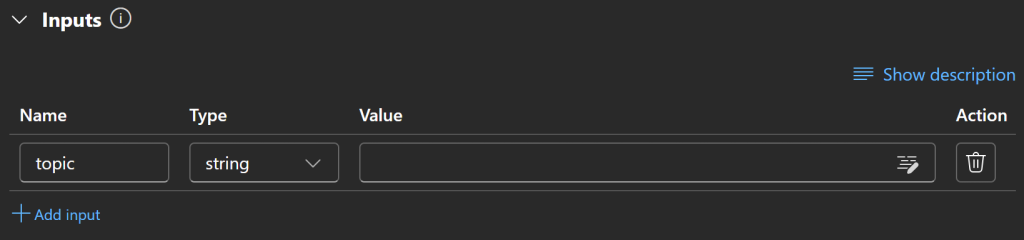
Incrível! O nó de entrada agora está configurado.
Etapa 7: prepare-se para chamar a API SERP
Antes de criar o nó Python personalizado que chama a API SERP da Bright Data, você precisa realizar algumas etapas preparatórias. Elas não são estritamente necessárias, mas simplificarão a integração e a tornarão mais segura.
Primeiro, para facilitar as chamadas à API, instale o Bright Data Python SDK. Esse SDK fornece métodos convenientes para interagir com os produtos da Bright Data, incluindo a API SERP (em vez de chamá-los diretamente via API usando um cliente HTTP). Você pode saber mais sobre ele na documentação oficial.
O SDK está disponível como o pacote brightdata-sdk. Para instalá-lo em seu fluxo, clique no botão “Compute session running” à esquerda e selecione a opção “Install packages from requirements.txt”:
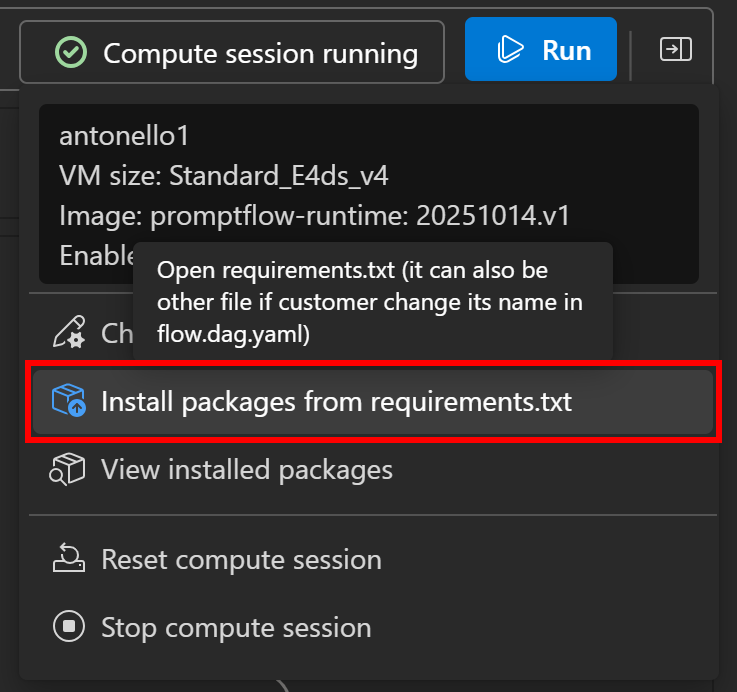
Um arquivo requirements.txt será aberto em seu painel de definição de fluxo. Adicione a seguinte linha a ele e clique na opção “Save and install” (Salvar e instalar):

Depois de instalado, você poderá usar o Bright Data Python SDK nos nós da ferramenta Python personalizada.
Em seguida, como a API SERP requer autenticação por meio de uma chave de API – e você não deseja codificá-la em seu fluxo – você deve armazená-la com segurança como um segredo no Azure. Para isso, abra o “Centro de gerenciamento” no menu à esquerda (geralmente é a última opção):
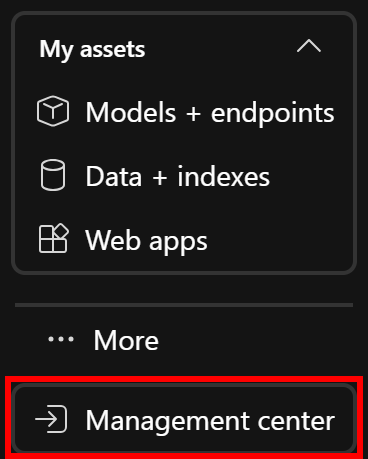
Na visão geral do gerenciamento de projetos, clique em “Nova conexão” na seção “Recursos conectados”:
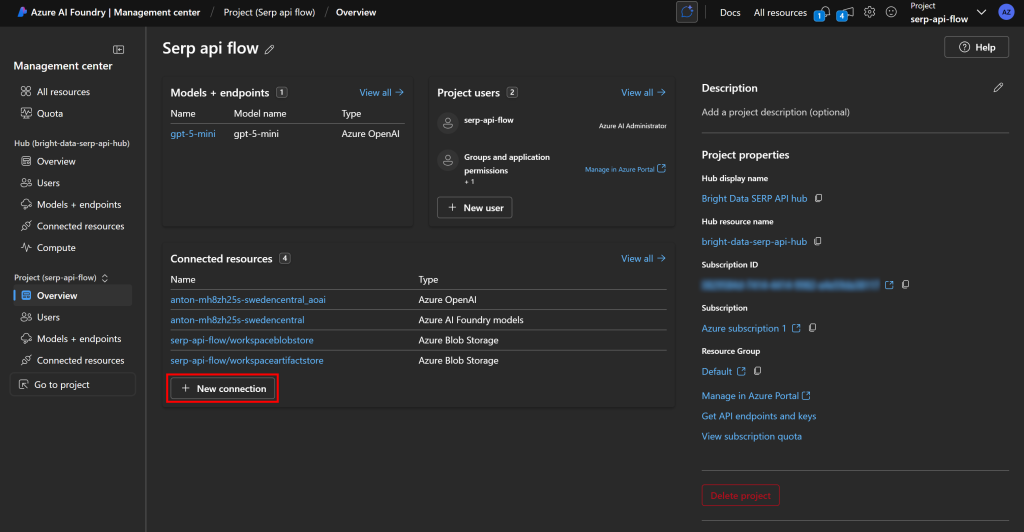
Na janela modal exibida, selecione a opção “Custom keys” (Chaves personalizadas):
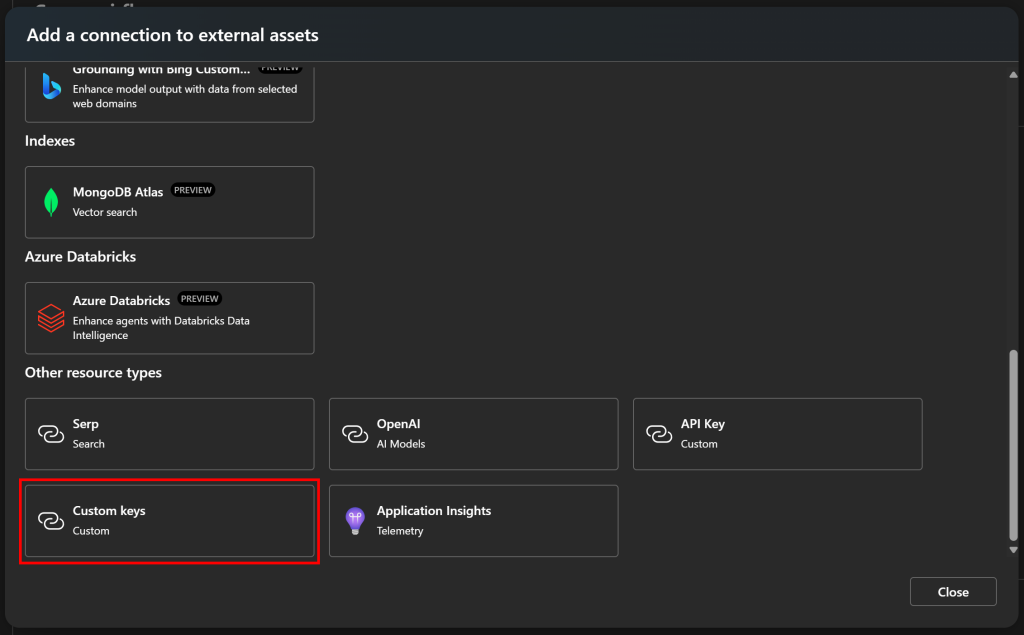
É assim que você pode armazenar chaves de API personalizadas no Azure IA Foundry.
Agora, crie uma nova chave secreta chamada algo como BRIGHT_DATA_API_KEY e cole sua chave da API Bright Data no campo de valor. Certifique-se de marcar a opção “is secret” (é secreta). Em seguida, dê à sua conexão um nome reconhecível, como bright-data:
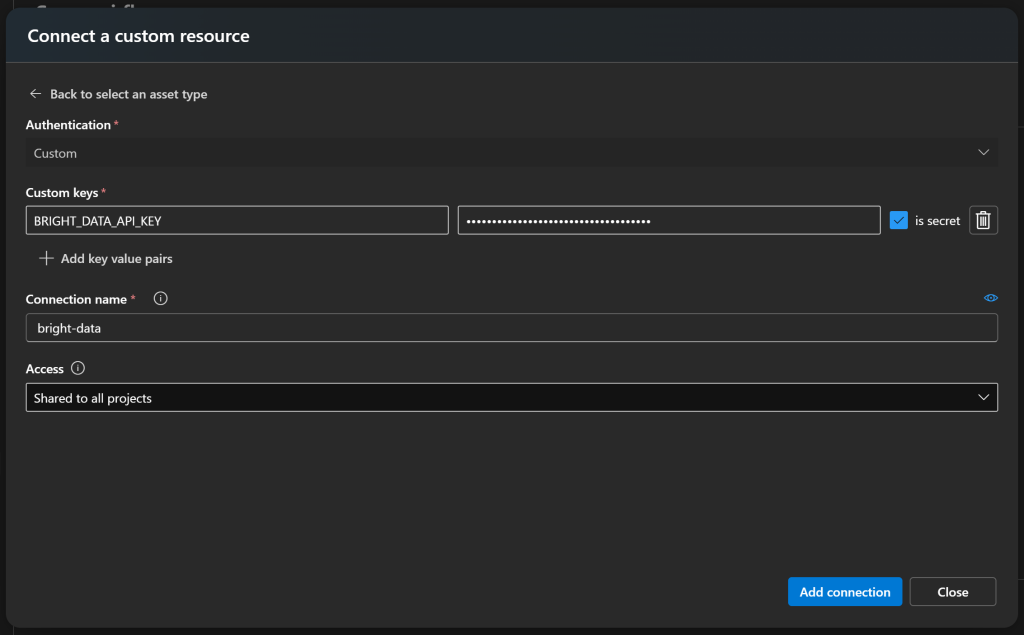
Por fim, pressione “Add connection” (Adicionar conexão) para salvar.
Ótimo! Volte para o seu fluxo. Você está pronto para ver como usar o SDK Python da Bright Data e sua chave de API armazenada para chamar a API SERP em apenas algumas linhas de código.
Etapa 8: Definir um nó Python personalizado para chamar a API SERP da Bright Data
Na tela de fluxo, clique no botão “Python” para criar um novo nó de ferramenta Python:

Dê um nome ao seu nó, como serp_api, e pressione o botão “Add” (Adicionar):

Na área de texto do código, adicione o seguinte código Python:
from promptflow import tool
from promptflow.connections import CustomConnection
from brightdata import bdclient
@tool
def serp_api(search_input: str, bd_conn: CustomConnection) -> str:
# Inicializar o cliente Bright Data SDK
cliente = bdclient(api_token=bd_conn.BRIGHT_DATA_API_KEY)
# Recuperar o SERP do Google no formato Markdown
serp_page = client.search(
search_input,
data_format="markdown",
country="us"
)
return serp_pageNo Azure IA Foundry, os nós Python devem definir ferramentas como funções anotadas com @tool. Nesse caso, a função serp_api() aceita a string de entrada de pesquisa e uma conexão personalizada como entradas.
A partir da conexão personalizada, a função lê a BRIGHT_DATA_API_KEY que você definiu anteriormente e a usa para inicializar uma instância do cliente Bright Data API Python SDK. Em seguida, esse cliente é usado para chamar a API SERP por meio do método search(), com as opções data_format="markdown" e country="US" para retornar a página SERP extraída da versão americana do Google em Markdown. (que é ideal para a ingestão de IA).
Em seguida, role para baixo e defina os elementos de entrada para o nó. Primeiro, pressione “Validate and parse input” (Validar e analisar entrada) para permitir que o nó reconheça entradas válidas. Configure as entradas identificadas mapeando:
bd_connparabright-data(sua conexão personalizada definida anteriormente).search_inputpara${input.topic}para que a entrada de pesquisa do nó de entrada seja passada para a API SERP.
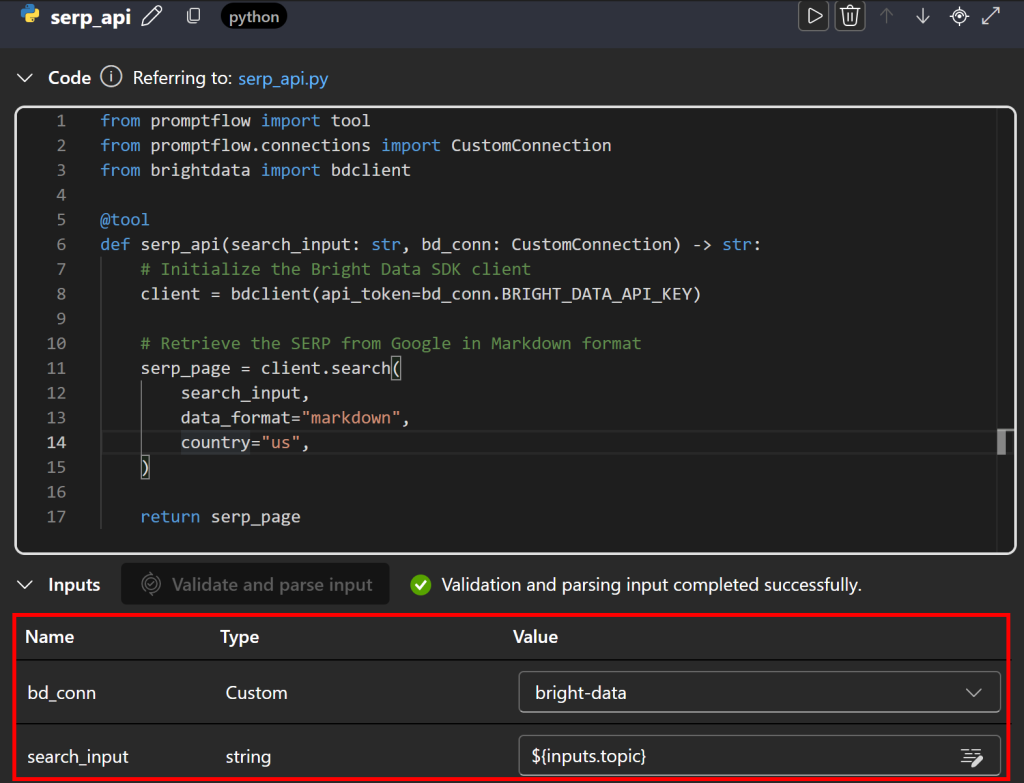
Excelente! A integração da API SERP da Bright Data no Azure IA Foundry agora está concluída.
Etapa 9: Especificar o nó LLM
Agora que você tem a página SERP correspondente ao tópico de pesquisa inicial, alimente-a em um LLM para extração e avaliação de notícias. Adicione um nó LLM pressionando o botão “LLM” logo abaixo da guia “Flow” (Fluxo):

Dê ao seu nó de LLM um nome como llm e confirme clicando em “Add” (Adicionar):

Esse nó é onde você define a lógica central do seu fluxo de prompt. Para atingir o objetivo de extração e avaliação de notícias, você pode escrever um prompt como este:
# sistema:
Você é um assistente de análise de notícias encarregado de identificar os artigos de notícias mais relevantes para um determinado tópico.
# Usuário:
Dada a página SERP abaixo, extraia os itens de notícias mais importantes e avalie cada um deles em uma escala de 1 a 5, com base no grau de valor da leitura.
Retornar um relatório formatado em Markdown contendo:
* Título da notícia
* URL da notícia
* Descrição curta (não mais do que 20 palavras)
* Valor de leitura (1-5)
PÁGINA DA SERP:
{{serp_page}}A seção # sistema define a função e o comportamento geral do assistente, enquanto a seção # usuário fornece a tarefa específica e as instruções para processar a entrada.
Em seguida, configure o nó do LLM para se conectar ao modelo de IA implantado anteriormente (na Etapa 3):
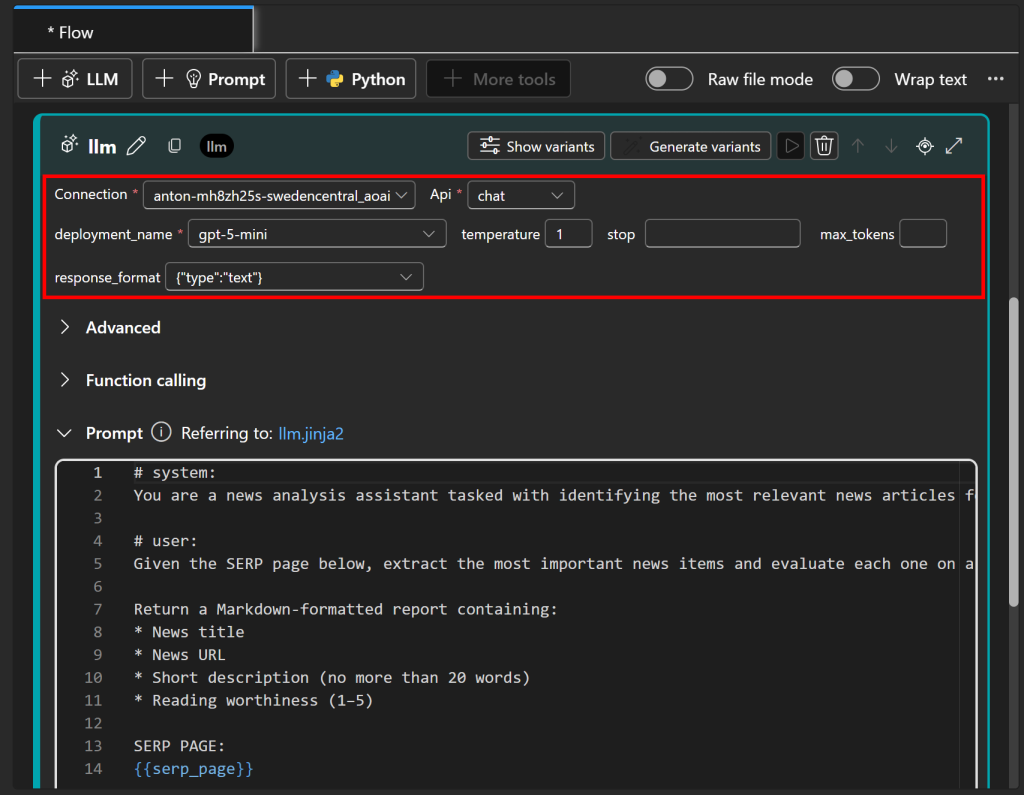
Observe que o prompt contém um parâmetro serp_page, que precisa ser definido como a saída do nó serp_api definido anteriormente. Configure-o na seção “Inputs” pressionando “Validate and parse input” e atribuindo serp_page a ${serp_api.output}:
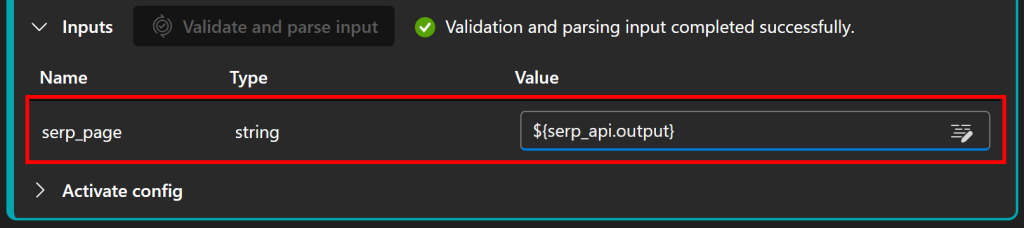
Legal! Seu fluxo de IA do Azure agora tem um “cérebro” LLM em funcionamento, capaz de processar resultados de SERP e gerar relatórios de notícias avaliados.
Etapa 10: definir o nó de saída
A etapa final é configurar o nó de saída. Na seção “Outputs” (Saídas), clique em “Add output” (Adicionar saída):

Defina o nome da saída como relatório e atribua-o à saída do nó LLM usando a variável ${llm.output}:
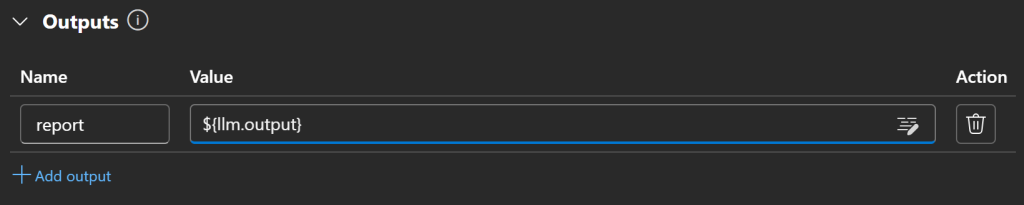
Quando terminar, pressione “Save” para salvar seu fluxo de prompt:

Parabéns! Seu fluxo de IA do Azure agora está totalmente implementado.
Etapa 11: Juntar tudo
Se você observar a seção “Graph” (Gráfico) do seu ambiente de desenvolvimento de fluxo, verá um DAG como o que está abaixo:
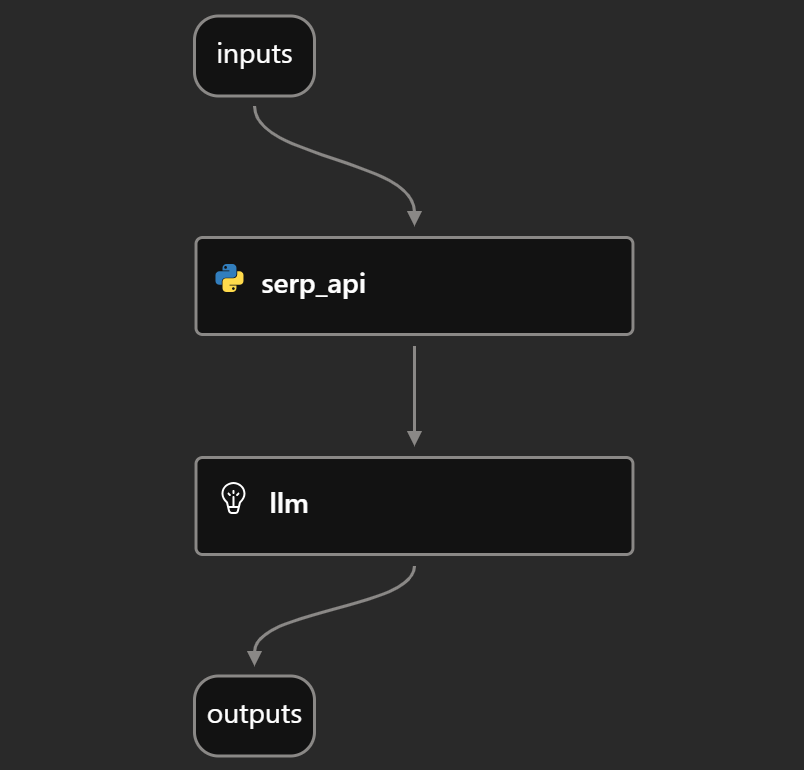
Isso representa claramente o fluxo de análise de notícias descrito na Etapa 5, mostrando como a entrada, a chamada da API SERP, a avaliação LLM e a saída estão conectadas.
Etapa 12: iniciar o fluxo de prompt
Para testar seu fluxo de prompt de IA do Azure, vamos usar o tópico de exemplo “notícias do mercado de ações”. No nó “Inputs” (Entradas), preencha o “Value” (Valor) do tópico com a string “stock market news” (notícias do mercado de ações):
Em seguida, pressione o botão “Run” (Executar) no canto superior direito para executar o fluxo:

Você verá cada nó ficar verde gradualmente à medida que os dados passam pelo fluxo até chegar ao nó “Outputs” (Saídas):
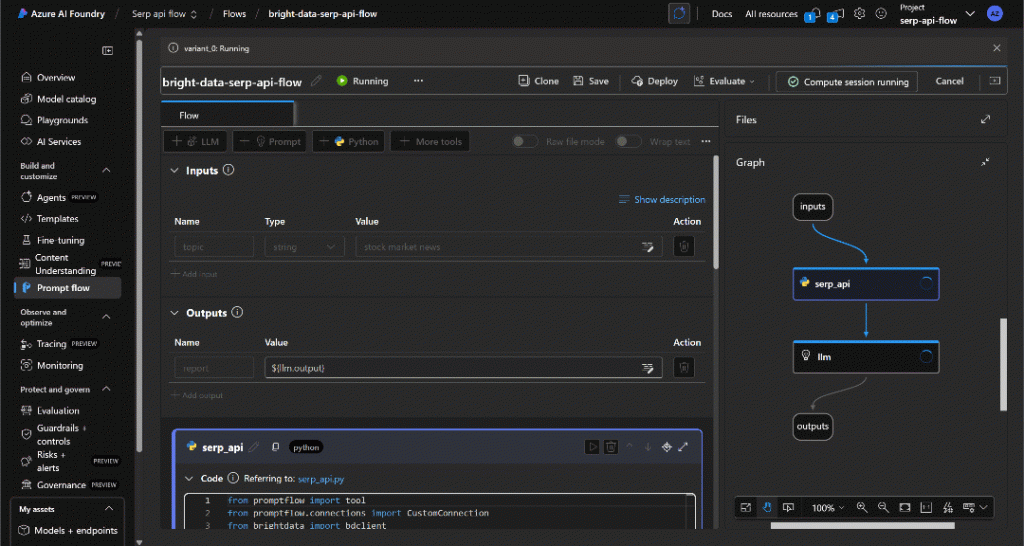
Quando a execução for concluída, você receberá uma notificação como esta:

Clique em “View outputs” (Exibir saídas) para explorar o resultado do fluxo:
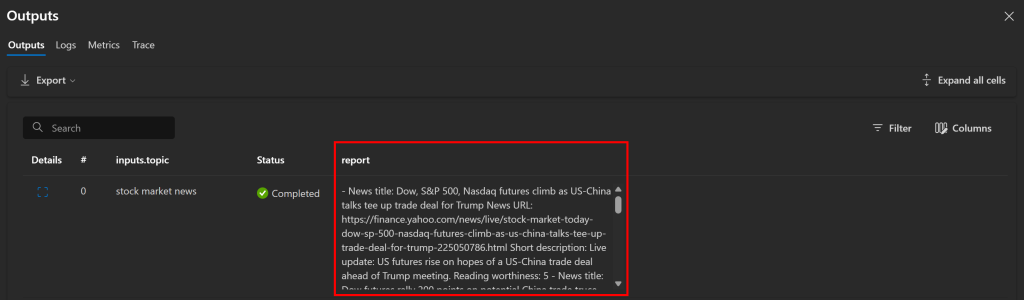
Como esperado, o fluxo produz um relatório Markdown contendo os artigos de notícias. Nesse caso, ele inclui:
- **Título da notícia:** Dow, S&P 500, futuros da Nasdaq sobem enquanto as negociações entre EUA e China preparam um acordo comercial para Trump
**URL da notícia:** [Yahoo Finance](https://finance.yahoo.com/news/live/stock-market-today-dow-sp-500-nasdaq-futures-climb-as-us-china-talks-tee-up-trade-deal-for-trump-225050786.html)
**Short description:** Atualização ao vivo: os futuros dos EUA sobem com a esperança de um acordo comercial EUA-China antes da reunião de Trump.
**Preço de leitura:** 5
- Título da notícia:** Mercado de ações hoje: Dow, S&P 500, Nasdaq futuros sobem com as negociações entre EUA e China preparando um acordo comercial para Trump
**URL da notícia:** [Yahoo Finance](https://finance.yahoo.com/news/live/stock-market-today-dow-sp-500-nasdaq-futures-climb-as-us-china-talks-tee-up-trade-deal-for-trump-225050786.html)
**Short description:** Os mercados sobem com o renovado otimismo comercial entre os EUA e a China durante as negociações de Trump.
**Preço de leitura:** 5
# Omitido por brevidade...Esses resultados refletem a página SERP “notícias do mercado de ações” no momento da execução do fluxo:
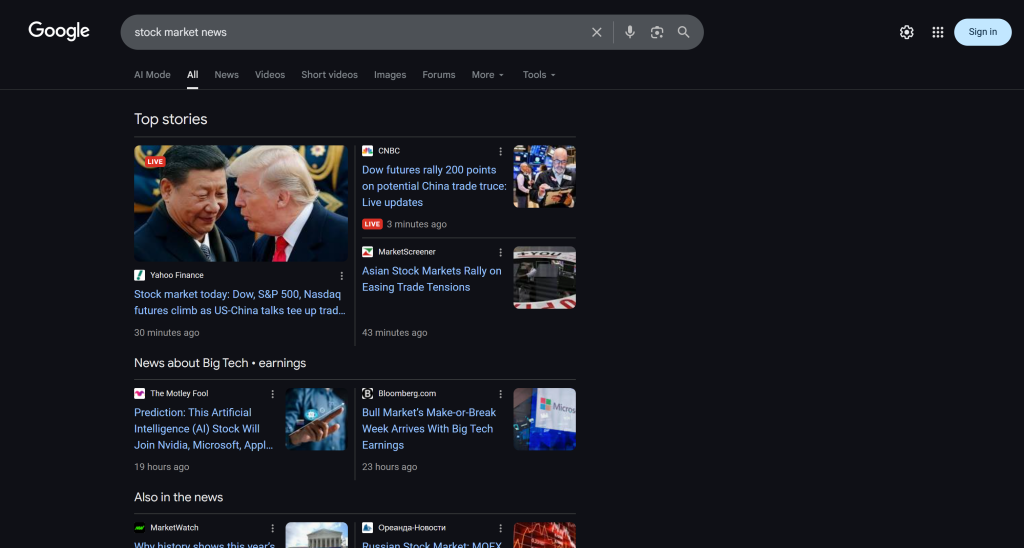
Para confirmar que a página SERP foi recuperada corretamente, inspecione a guia “output” na seção “Outputs” do nó serp_api:
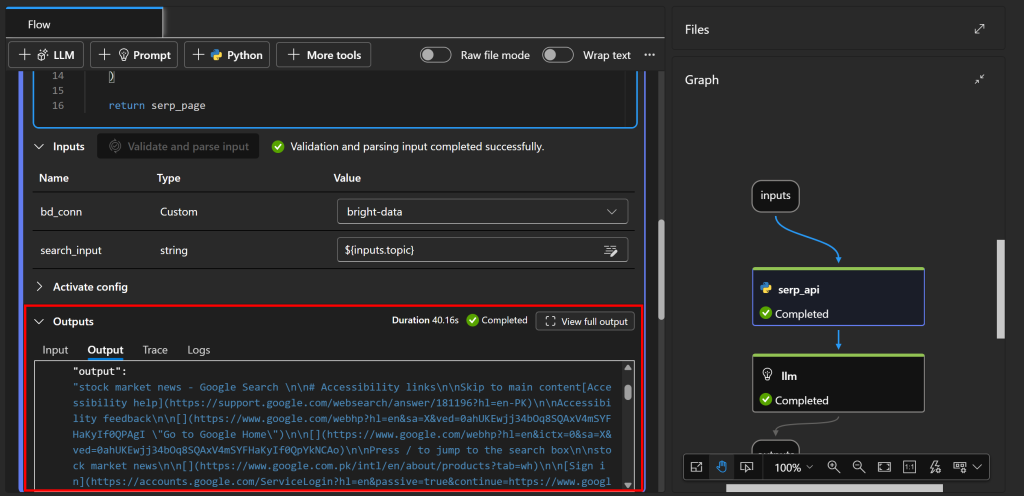
Lá, você verá a versão Markdown da SERP original. A API SERP da Bright Data fez sua mágica!
Agora, para uma inspeção completa da saída do fluxo, copie a saída do relatório em um arquivo, por exemplo, report.md. Visualize-o em um visualizador Markdown, como o Visual Studio Code:
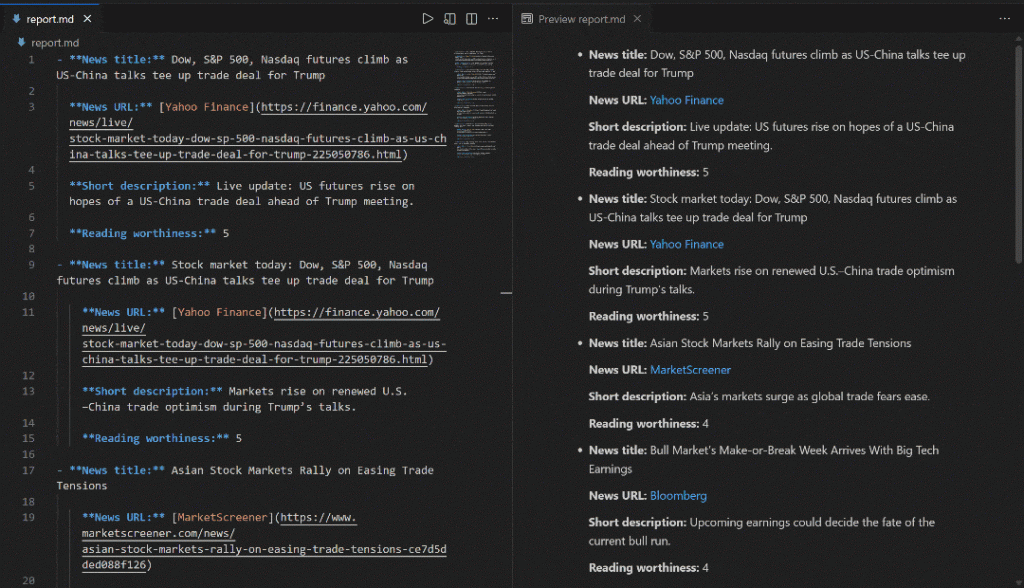
Observe como o relatório produzido pelo fluxo corresponde às notícias mostradas no SERP do Google para “notícias do mercado de ações”. A raspagem dos resultados de pesquisa do Google é notoriamente difícil devido a medidas anti-bot e limitadores de taxa. Ao usar a API SERP, você pode obter de forma confiável e fácil os resultados do Google (ou de qualquer outro mecanismo de pesquisa compatível) de diferentes regiões no formato Markdown pronto para IA, sem limitações de escalabilidade.
Este exemplo demonstra um caso de uso simples, mas você pode experimentar fluxos mais complexos, integrar outros produtos da Bright Data ou ajustar o prompt do LLM para lidar com diferentes tarefas. Muitos outros casos de uso também são suportados!
E pronto! Agora você tem um fluxo do Azure IA Foundry que recupera dados de pesquisa na Web e os usa como contexto em um fluxo de trabalho no estilo RAG.
Conclusão
Nesta postagem do blog, você aprendeu a usar a API SERP da Bright Data para buscar artigos de notícias recentes do Google e integrá-los a um fluxo de trabalho RAG no Azure IA.
O fluxo de trabalho de IA demonstrado aqui é perfeito para quem deseja criar um assistente de notícias que filtre o conteúdo, para que você leia apenas as notícias relevantes para os tópicos de seu interesse. Para criar fluxos de trabalho de IA mais avançados, explore o conjunto completo de ferramentas da Bright Data para recuperar, validar e transformar dados ao vivo da Web.
Inscreva-se em uma conta gratuita da Bright Data hoje mesmo e comece a experimentar nossas soluções de dados da Web prontas para IA!





