

Este tutorial orienta você na extração manual de dados públicos do Airbnb usando Python. Os dados coletados podem ajudar a analisar tendências de mercado, desenvolver estratégias de preços competitivas, realizar análises de sentimentos a partir de avaliações de hóspedes ou criar sistemas de recomendação.
Além disso, explore as soluções avançadas da Bright Data. Seus proxies especializados e navegadores fáceis de coletar simplificam e aprimoram o processo de extração de dados.
Como extrair dados do Airbnb
Antes de começarmos, é recomendável ter algum conhecimento básico sobre Scraping de dados da web e HTML. Além disso, certifique-se de instalar o Python no seu computador, caso ainda não o tenha. Oguia oficial do Pythonfornece instruções detalhadas sobre como fazer isso. Se você já tem o Python instalado, certifique-se de que ele esteja atualizado para o Python 3.7.9 ou mais recente. Também recomendamos a leitura do tutorial completo sobre Scraping de dados da web com Python antes de começar.
Depois de instalar o Python, inicie seu terminal ou interface de linha de comando e inicie a criação de um novo diretório de projeto com os seguintes comandos:
mkdir airbnb-scraper && cd airbnb-scraper
Depois de criar um novo diretório de projeto, você precisa configurar algumas bibliotecas adicionais que serão usadas para Scraping de dados. Especificamente, você utilizará Requests, uma biblioteca que habilita solicitações HTTP em Python; pandas, uma biblioteca robusta dedicada à manipulação e análise de dados; Beautiful Soup (BS4) para analisar conteúdo HTML; e Playwright para automatizar tarefas baseadas em navegador.
Para instalar essas bibliotecas, abra seu terminal ou shell e execute os seguintes comandos:
pip3 install beautifulsoup4
pip3 install requests
pip3 install pandas
pip3 install playwright
playwright install
Certifique-se de que o processo de instalação seja concluído sem erros antes de prosseguir para a próxima etapa deste tutorial.
Observação: o último comando (ou seja,
playwright install) é necessário para instalar os binários do navegador.
Estrutura e objetos de dados do Airbnb
Antes de começar a extrair dados do Airbnb, é fundamental se familiarizar com sua estrutura. A página principal do Airbnb apresenta uma barra de pesquisa fácil de usar, permitindo que você procure opções de acomodação, experiências e até mesmo aventuras.
Ao inserir seus critérios de pesquisa, os resultados são apresentados em formato de lista, exibindo as propriedades com seus nomes, preços, localizações, classificações e outros detalhes pertinentes. Vale a pena notar que esses resultados de pesquisa podem ser filtrados com base em vários parâmetros, como faixa de preço, tipo de propriedade e datas de disponibilidade.
Se você quiser mais resultados de pesquisa do que os apresentados inicialmente, pode utilizar os botões de paginação localizados na parte inferior da página. Cada página normalmente hospeda várias listagens, permitindo que você navegue por propriedades adicionais. Os filtros encontrados na parte superior da página oferecem a oportunidade de refinar sua pesquisa de acordo com suas necessidades e preferências.
Para ajudá-lo a entender a estrutura HTML do site do Airbnb, siga estas etapas:
- Acesse o site do Airbnb.
- Insira o local desejado, o intervalo de datas e o número de hóspedes na barra de pesquisa e pressione Enter.
- Inicie as ferramentas de desenvolvedor do navegador clicando com o botão direito do mouse em um cartão de propriedade e selecionando Inspecionar.
- Explore o layout HTML para identificar as tags e os atributos que abrangem os dados que você deseja extrair.
Extraia uma listagem do Airbnb
Agora que você sabe mais sobre a estrutura do Airbnb, configure o Playwright para navegar até uma listagem do Airbnb e coletar dados. Neste exemplo, você coletará o nome da listagem, a localização, os detalhes de preço, os detalhes do proprietário e as avaliações.
Crie um novo script Python, airbnb_scraper.py, e adicione o seguinte código:
import asyncio
from playwright.async_api import async_playwright
import pandas as pd
async def scrape_airbnb():
async with async_playwright() as pw:
# Inicie um novo navegador
browser = await pw.chromium.launch(headless=False)
page = await browser.new_page()
# Vá para a URL do Airbnb
await page.goto('https://www.airbnb.com/s/homes', timeout=600000)
# Aguardar o carregamento das listagens
await page.wait_for_selector('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr')
# Extrair informações
results = []
listings = aguardar page.query_selector_all('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr')
para listagem em listagens:
resultado = {}
# Nome da propriedade
nome_elemento = aguardar listagem.query_selector('div[data-testid="listing-card-title"]')
if name_element:
result['property_name'] = await page.evaluate("(el) => el.textContent", name_element)
else:
result['property_name'] = 'N/A'
# Localização
location_element = await listing.query_selector('div[data-testid="listing-card-subtitle"]')
result['location'] = aguardar location_element.inner_text() se location_element, caso contrário, 'N/A'
# Preço
price_element = aguardar listing.query_selector('div._1jo4hgw')
result['price'] = aguardar price_element.inner_text() se price_element, caso contrário, 'N/A'
results.append(result)
# Fechar navegador
aguardar browser.close()
retornar resultados
# Executar o scraper e salvar os resultados em um arquivo CSV
resultados = asyncio.run(scrape_airbnb())
df = pd.DataFrame(resultados)
df.to_csv('airbnb_listings.csv', index=False)
A função scrape_airbnb() abre um navegador de forma assíncrona, acessa a página inicial de listagens do Airbnb e coleta detalhes como nome da propriedade, localização e preço de cada listagem. Se um elemento não for encontrado, ele é marcado como N/A. Após o processamento, os dados adquiridos são armazenados em um DataFrame do pandas e salvos como um arquivo CSV chamado airbnb_listings.csv.
Para executar o script, execute python3 airbnb_scraper.py no seu terminal ou shell. Seu arquivo CSV deve ficar assim:
property_name,location,price
"Brand bei Bludenz, Áustria", a 343 quilômetros de distância, "€ 2.047
por noite"
"Saint-Nabord, França", a 281 quilômetros de distância, "€ 315
por noite"
"Kappl, Áustria", a 362 quilômetros de distância, "€ 1.090
por noite"
"Fraisans, França", a 394 quilômetros de distância, "€ 181
por noite"
"Lanitz-Hassel-Tal, Alemanha", a 239 quilômetros de distância, "€ 185
por noite"
"Hohentannen, Suíça", a 291 quilômetros de distância, "€ 189
por noite"
...saída omitida...
Aprimore o scraping de dados da Web com os proxies da Bright Data
A extração de dados de sites pode, por vezes, apresentar desafios, como bloqueios de IP e bloqueios geográficos. É aqui que os proxiesda Bright Data se tornam úteis, permitindo-lhe contornar esses obstáculos e melhorar os seus esforços de extração de dados.
Depois de executar o script anterior algumas vezes, você pode perceber que deixou de receber dados. Isso pode acontecer se o seu IP for detectado pelo Airbnb e eles o bloquearem de fazer scraping do site deles.
Para mitigar os desafios associados, implementar proxies para o scraping é uma abordagem prática. Aqui estão algumas das vantagens de empregar proxies para o Scraping de dados:
- contornar restrições de IP
- rodar endereços IP
- O balanceamento de carga garante a distribuição do tráfego de rede ou aplicativo por vários recursos, evitando que qualquer componente se torne um gargalo e fornecendo redundância em caso de falha.
Como integrar proxies da Bright Data ao seu script Python
Com os benefícios mencionados anteriormente, você pode ver por que alguém pode querer incorporar os proxies da Bright Data em um script Python. A boa notícia é que isso é fácil de fazer. Basta criar uma conta na Bright Data, configurar suas definições de Proxy e, em seguida, implementá-las em seu código Python.
Para começar, você precisa criar uma conta Bright Data. Para isso, acesse o site da Bright Data e selecione Teste grátis; em seguida, siga as instruções.
Faça login na sua conta Bright Data e clique no cartão de crédito na barra de navegação à esquerda para acessar o Faturamento. Aqui, você precisa inserir seu método de pagamento preferido para ativar sua conta:
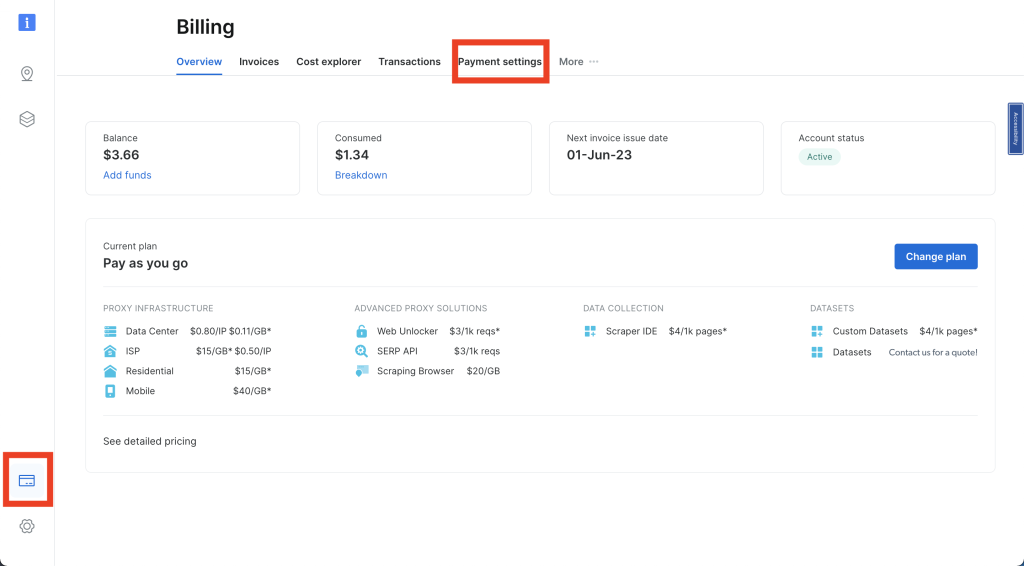
Em seguida, clique no ícone de alfinete na barra de navegação à esquerda para acessar a página Proxies e Infraestrutura de scraping; depois clique em Adicionar > Proxies residenciais:
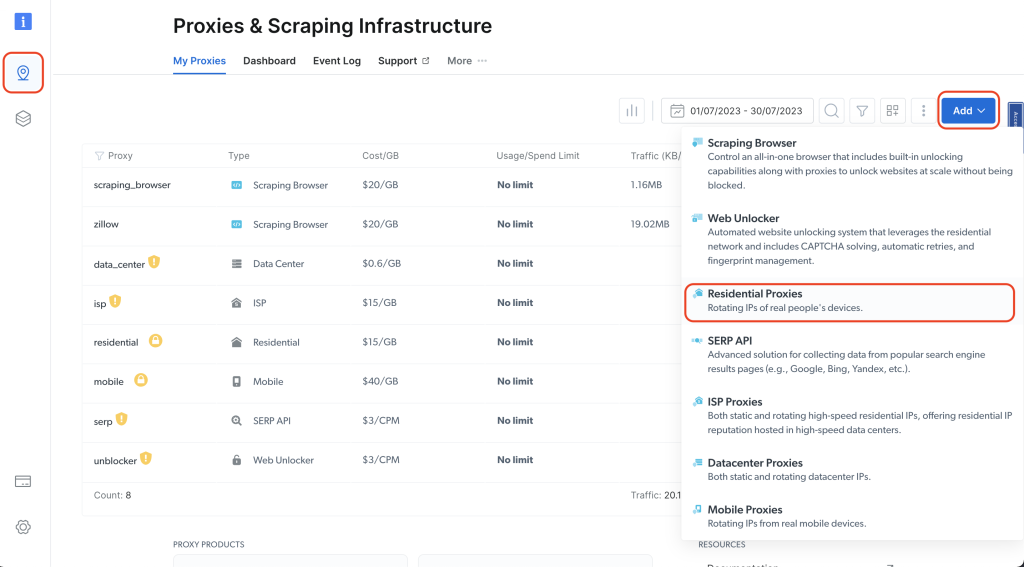
Dê um nome ao seu Proxy (por exemplo, proxy_residencial1) e use a opção Compartilhado em Tipo de IP. Em seguida, clique em Adicionar:

Depois de criar seu Proxy residencial, anote os parâmetros de acesso, pois você precisará usar esses detalhes em seu código:
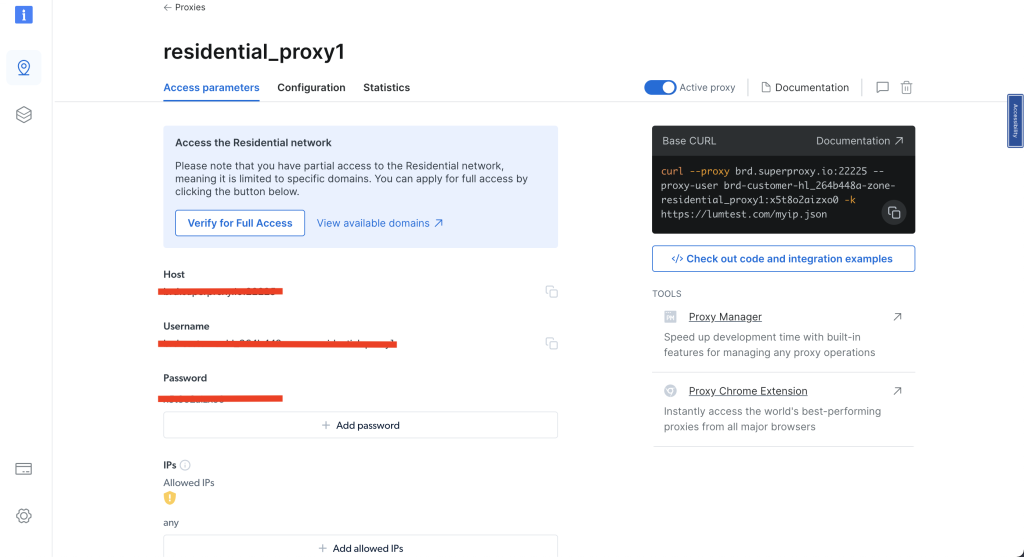
Para poder usar o Proxy residencial da Bright Data, você precisa configurar um certificado para o seu navegador. Você pode encontrar instruções sobre como instalar o certificado neste tutorial da Bright Data.
Crie um novo script Python airbnb_scraping_proxy.py e adicione o seguinte código:
from playwright.sync_api import sync_playwright
import pandas as pd
def run(playwright):
browser = playwright.chromium.launch()
context = browser.new_context()
# Configure o Proxy
proxy_username='YOUR_BRIGHTDATA_PROXY_USERNAME'
proxy_password='SUA_SENHA_DE_PROXY_BRIGHTDATA'
proxy_host = 'SEU_HOST_DE_PROXY_BRIGHTDATA'
proxy_auth=f'{proxy_username}:{proxy_password}'
proxy_server = f'http://{proxy_auth}@{proxy_host}'
context = browser.new_context(proxy={
'server': proxy_server,
'username': proxy_username,
'password': proxy_password
})
page = context.new_page()
page.goto('https://www.airbnb.com/s/homes')
# Aguarda o carregamento da página
página.aguarda_carregamento("networkidle")
# Extraia os dados
resultados = página.avalia_em_seletor_todos('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr', '''(listagens) => {
retornar listagens.map(listagem => {
retornar {
nome_da_propriedade: listagem.querySelector('div[data-testid="listing-card-title"]')?.innerText || 'N/A',
localização: listagem.querySelector('div[data-testid="listing-card-subtitle"]')?.innerText || 'N/A',
price: listagem.querySelector('div._1jo4hgw')?.innerText || 'N/A'
}
})
}''')
df = pd.DataFrame(resultados)
df.to_csv('airbnb_listings_scraping_proxy.csv', index=False)
# Fechar o navegador
browser.close()
com sync_playwright() como playwright:
run(playwright)
Este código usa a biblioteca Playwright para iniciar um navegador Chromium com um servidor Proxy específico. Ele navega até a página inicial do Airbnb, extrai detalhes como nomes de propriedades, localizações e preços das listagens e salva os dados em um arquivo CSV usando pandas. Após a extração dos dados, o navegador é fechado.
Observação: substitua
proxy_username,proxy_passwordeproxy_hostpelos seus parâmetros de acesso à Bright Data.
Para executar o script, execute python3 airbnb_scraping_proxy.py em seu terminal ou shell. Os dados extraídos são salvos em um arquivo CSV chamado airbnb_listings_scraping_proxy.csv. Seu arquivo CSV deve ficar assim:
property_name,location,price
"Sithonia, Grécia",Lagomandra,"$3.305
por noite"
"Apraos, Grécia","1.080 quilômetros de distância","$237
por noite"
"Magnisia, Grécia", Milopotamos Paralympic, "$200
por noite"
"Vourvourou, Grécia", 861 quilômetros de distância, "$357
por noite"
"Rovies, Grécia", "1.019 quilômetros de distância", "$1.077
por noite"
...saída omitida...
Raspando o Airbnb com o navegador de raspagem da Bright Data
O processo de scraping pode ser ainda mais eficiente com o Navegador de scraping da Bright Data. Essa ferramenta foi projetada especificamente para scraping de dados, oferecendo uma série de benefícios, incluindo desbloqueio automático, fácil escalabilidade e capacidade de burlar softwares de detecção de bots.
Acesse o painel do Bright Data e clique no ícone de alfinete para acessar a página Proxies e infraestrutura de scraping; em seguida, clique em Adicionar > Navegador de scraping:
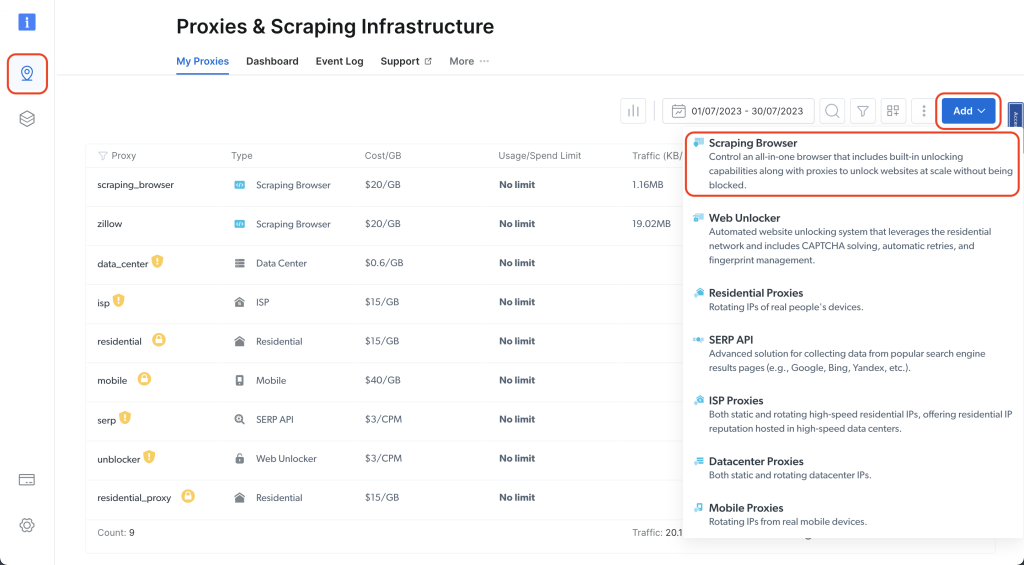
Dê um nome (por exemplo, scraping_browser) e clique em Adicionar:

Em seguida, selecione Parâmetros de acesso e registre seu nome de usuário, host e senha — esses detalhes serão necessários mais adiante neste guia:
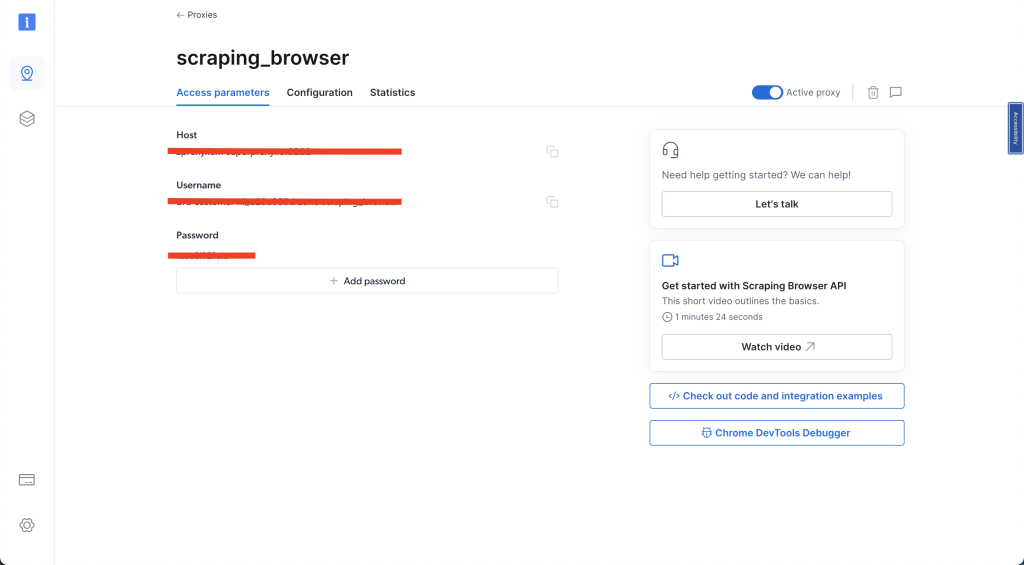
Após concluir essas etapas, crie um novo script Python chamado airbnb_scraping_brower.py e adicione o seguinte código:
import asyncio
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
import pandas as pd
username='SEU_NOME_DE_USUÁRIO_BRIGHTDATA'
password='SUA_SENHA_BRIGHTDATA'
auth=f'{username}:{password}'
host = 'SEU_HOST_BRIGHTDATA'
browser_url = f'wss://{auth}@{host}'
async def scrape_airbnb():
async with async_playwright() as pw:
# Inicie um novo navegador
print('conectando')
browser = await pw.chromium.connect_over_cdp(browser_url)
imprimir('conectado')
página = aguardar browser.new_page()
# Ir para a URL do Airbnb
aguardar página.goto('https://www.airbnb.com/s/homes', tempo limite=120000)
imprimir('concluído, avaliando')
# Obter todo o conteúdo HTML
conteúdo_html = aguardar página.evaluate('()=>document.documentElement.outerHTML')
# Analisar o HTML com Beautiful Soup
soup = BeautifulSoup(html_content, 'html.parser')
# Extrair informações
results = []
listings = soup.select('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr')
for listing in listings:
result = {}
# Nome da propriedade
name_element = listagem.select_one('div[data-testid="listing-card-title"]')
resultado['property_name'] = name_element.text se name_element, caso contrário, 'N/A'
# Localização
location_element = listagem.select_one('div[data-testid="listing-card-subtitle"]')
result['location'] = location_element.text if location_element else 'N/A'
# Preço
price_element = listing.select_one('div._1jo4hgw')
result['price'] = price_element.text if price_element else 'N/A'
results.append(result)
# Fechar navegador
aguardar browser.close()
retornar resultados
# Executar o scraper e salvar os resultados em um arquivo CSV
resultados = asyncio.run(scrape_airbnb())
df = pd.DataFrame(resultados)
df.to_csv('airbnb_listings_scraping_browser.csv', index=False)
Este código usa o Proxy Bright Data para se conectar a um navegador Chromium e extrair detalhes da propriedade (ou seja, nome, localização e preço) do site Airbnb. Os dados obtidos são armazenados em uma lista, depois salvos em um DataFrame e exportados para um arquivo CSV chamado airbnb_listings_scraping_browser.csv.
Observação: lembre-se de substituir o
nome de usuário,a senhaeo hostpelos seus parâmetros de acesso ao Bright Data.
Execute o código a partir do seu terminal ou shell:
python3 airbnb_scraping_browser.py
Você deverá ver um novo arquivo CSV chamado airbnb_listings_scraping_browser.csv criado em seu projeto. O arquivo deve ter a seguinte aparência:
property_name,location,price
"Benton Harbor, Michigan",Round Lake,"$514
por noite"
"Pleasant Prairie, Wisconsin",Lake Michigan,"$366
por noite"
"New Buffalo, Michigan",Lake Michigan,"$2.486
por noite"
"Fox Lake, Illinois", Lago Nippersink, "$199
por noite"
"Salem, Wisconsin", Lago Hooker, "$880
por noite"
...saída omitida...
Agora, extraia alguns dados relacionados a uma única listagem. Crie um novo script Python, airbnb_scraping_single_listing.py, e adicione o seguinte código:
import asyncio
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
import pandas as pd
username='YOUR_BRIGHTDATA_USERNAME'
password='YOUR_BRIGHTDATA_PASSWORD'
auth=f'{username}:{password}'
host = 'YOUR_BRIGHTDATA_HOST'
browser_url = f'wss://{auth}@{host}'
async def scrape_airbnb_listing():
async with async_playwright() as pw:
# Inicie um novo navegador
print('connecting')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('conectado')
page = await browser.new_page()
# Acesse a URL do Airbnb
await page.goto('https://www.airbnb.com/rooms/26300485', timeout=120000)
imprimir('concluído, avaliando')
# Aguardar o carregamento do conteúdo
aguardar página.aguardar_seletor('div.tq51prx.dir.dir-ltr h2')
# Obter todo o conteúdo HTML
conteúdo_html = aguardar página.avaliar('()=>document.documentElement.outerHTML')
# Analisar o HTML com Beautiful Soup
soup = BeautifulSoup(html_content, 'html.parser')
# Extrair o nome do host
host_div = soup.select_one('div.tq51prx.dir.dir-ltr h2')
host_name = host_div.text.split("hosted by ")[-1] if host_div else 'N/A'
print(f'Host name: {host_name}')
# Extrair avaliações
reviews_span = soup.select_one('span._s65ijh7 button')
reviews = reviews_span.text.split(" ")[0] if reviews_span else 'N/A'
print(f'Avaliações: {reviews}')
# Fechar o navegador
await browser.close()
return {
'host_name': host_name,
'reviews': reviews,
}
# Executar o scraper e salvar os resultados em um arquivo CSV
results = asyncio.run(scrape_airbnb_listing())
df = pd.DataFrame([results]) # results agora é um dicionário
df.to_csv('scrape_airbnb_listing.csv', index=False)
Neste código, você navega até a URL da listagem desejada, extrai o conteúdo HTML, faz parseamento com o Beautiful Soup para recuperar o nome do anfitrião e o número de avaliações e, finalmente, salva os detalhes extraídos em um arquivo CSV usando pandas.
Execute o código a partir do seu terminal ou shell:
python3 airbnb_scraping_single_listing.py
Você deverá ver um novo arquivo CSV chamado scrape_airbnb_listing.csv em seu projeto. O conteúdo desse arquivo deve ser semelhante a este:
host_name,reviews
Amelia,88
Todo o código deste tutorial está disponível neste repositório GitHub.
Benefícios de usar o navegador de scraping da Bright Data
Existem várias razões pelas quais você deve considerar escolher o navegador de scraping da Bright Data em vez de uma instância local do Chromium. Veja algumas dessas razões:
- Desbloqueio automático: o navegador de scraping da Bright Data lida automaticamente com CAPTCHAs, páginas bloqueadas e outros desafios que os sites usam para impedir scrapers. Isso reduz drasticamente as chances de seu scraper ser bloqueado.
- Escalabilidade fácil: as soluções da Bright Data são projetadas para serem facilmente escaláveis, permitindo que você colete dados de um grande número de páginas da web simultaneamente.
- Superar o software de detecção de bots: os sites modernos utilizam sistemas sofisticados de detecção de bots. O Bright Data Scraping Browser consegue imitar com sucesso o comportamento humano para superar esses algoritmos de detecção.
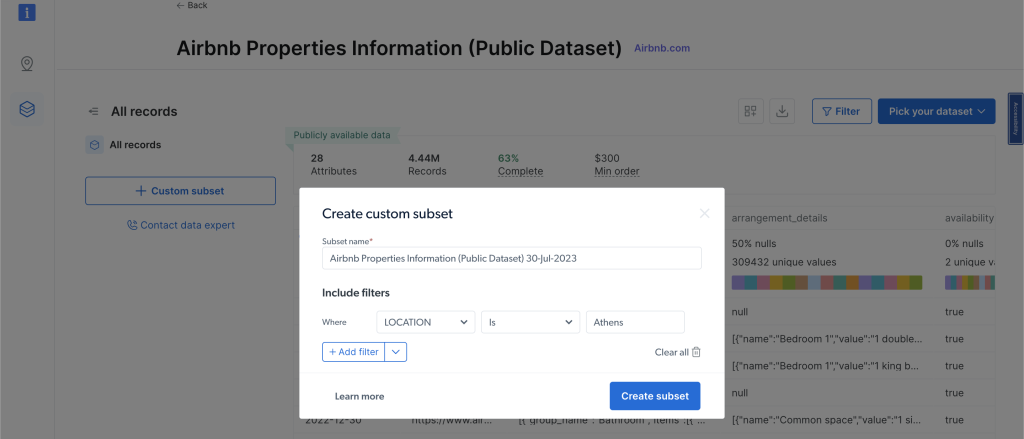
Além disso, se coletar dados manualmente ou configurar scripts parecer muito demorado ou complexo, os Conjuntos de dados personalizados da Bright Data são uma ótima alternativa. Eles oferecem um Conjuntos de dados do Airbnb que inclui informações sobre propriedades do Airbnb que você pode acessar e analisar sem precisar fazer nenhuma coleta por conta própria.
Para visualizar os conjuntos de dados, clique em Dados da Web no menu de navegação à esquerda, selecione Mercado de conjuntos de dados e pesquise Airbnb. Clique em Exibir conjunto de dados. Nesta página, você pode aplicar filtros e comprar os dados que desejar. Você paga com base no número de registros que deseja:
Conclusão
Neste tutorial, você aprendeu como extrair dados das listagens do Airbnb usando Python e viu como as ferramentas da Bright Data, como os Proxy e o Navegador de scraping, podem tornar esse trabalho ainda mais fácil.
A Bright Data oferece um conjunto de ferramentas que podem ajudá-lo a coletar dados de qualquer site, não apenas do Airbnb, de forma rápida e fácil. Essas ferramentas transformam tarefas difíceis de Scraping de Dados em tarefas simples, economizando seu tempo e esforço. Não tem certeza de qual produto você precisa? Fale com os especialistas em dados da web da Bright Data para encontrar a solução certa para suas necessidades de dados.
Interessado em fazer scraping de outros sites? Continue com os artigos abaixo:
Observação: este guia foi exaustivamente testado por nossa equipe no momento da redação, mas como os sites atualizam frequentemente seu código e estrutura, algumas etapas podem não funcionar mais como esperado.






