
Neste artigo, você aprenderá:
- Como construir um sistema RAG pronto para produção usando o Google ADK e o Vertex IA RAG Engine
- Como implementar a pesquisa híbrida com recuperação semântica e por palavra-chave
- Como evitar alucinações por meio de fundamentação e citação adequadas
- Como processar conteúdo multimodal, incluindo texto, imagens e tabelas
- Como aprimorar seu RAG com dados da web em tempo real usando a integração Bright Data (opcional)
Vamos começar!
O desafio da gestão moderna do conhecimento
A documentação técnica é armazenada em wikis, as especificações dos produtos são encontradas em PDFs, os dados dos clientes estão em bancos de dados e o conhecimento institucional reside em e-mails. Os funcionários passam horas procurando informações e muitas vezes encontram respostas desatualizadas ou incompletas. Modelos de linguagem grandes treinados com dados gerais não podem acessar seu conhecimento proprietário. Eles frequentemente cometem erros quando questionados sobre informações específicas da empresa.
Os agentes RAG resolvem isso recuperando o contexto relevante da sua base de conhecimento antes de gerar respostas. Isso fundamenta a IA em informações factuais, reduz alucinações e fornece citações transparentes para verificação.
O que estamos construindo: sistema inteligente de agentes RAG
Criaremos um agente RAG pronto para produção que pega documentos de várias fontes, os processa em partes pesquisáveis, os transforma em representações vetoriais, recupera o contexto relevante usando uma pesquisa híbrida e gera respostas corretas com citações adequadas, evitando imprecisões.
O sistema irá gerenciar:
- Recebimento de documentos do Cloud Storage, Drive e arquivos locais
- Fragmentação inteligente com sobreposição e manutenção de metadados
- Recuperação híbrida que combina similaridade semântica e correspondência de palavras-chave
- Conteúdo multimodal que inclui imagens e tabelas
- Geração de citações para verificação de respostas
- Detecção e prevenção de erros
Pré-requisitos
Configure seu ambiente de desenvolvimento com:
- Python 3.10 ou superior – necessário para compatibilidade com o Google ADK.
- Projeto Google Cloud – Crie um projeto no Google Cloud Console com faturamento habilitado.
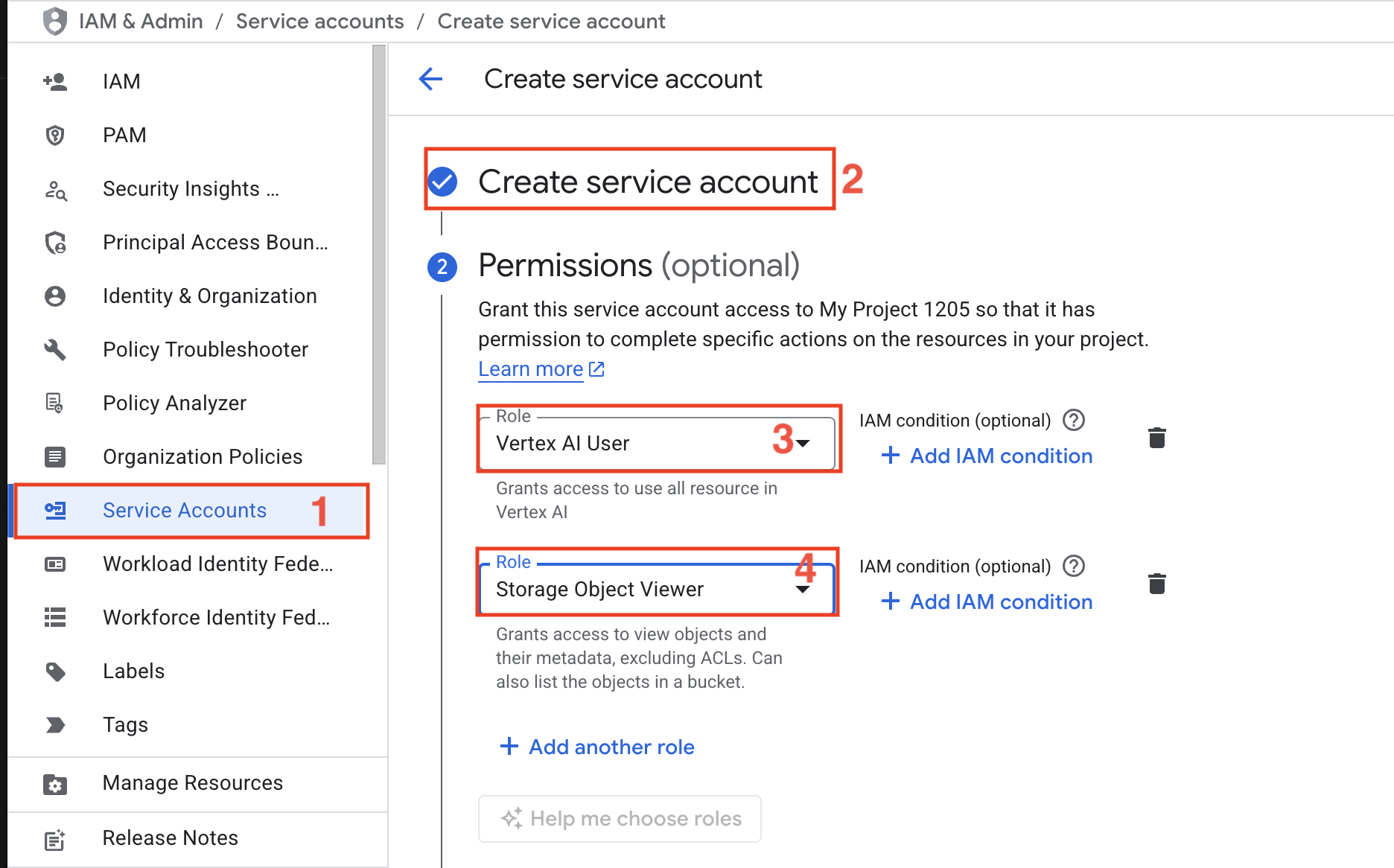
- Conta de serviço – Crie uma conta de serviço com as funções Vertex IA User e Storage Object Viewer.
- Google ADK – Kit de desenvolvimento de agentes para criar agentes de IA; consulte a documentação.
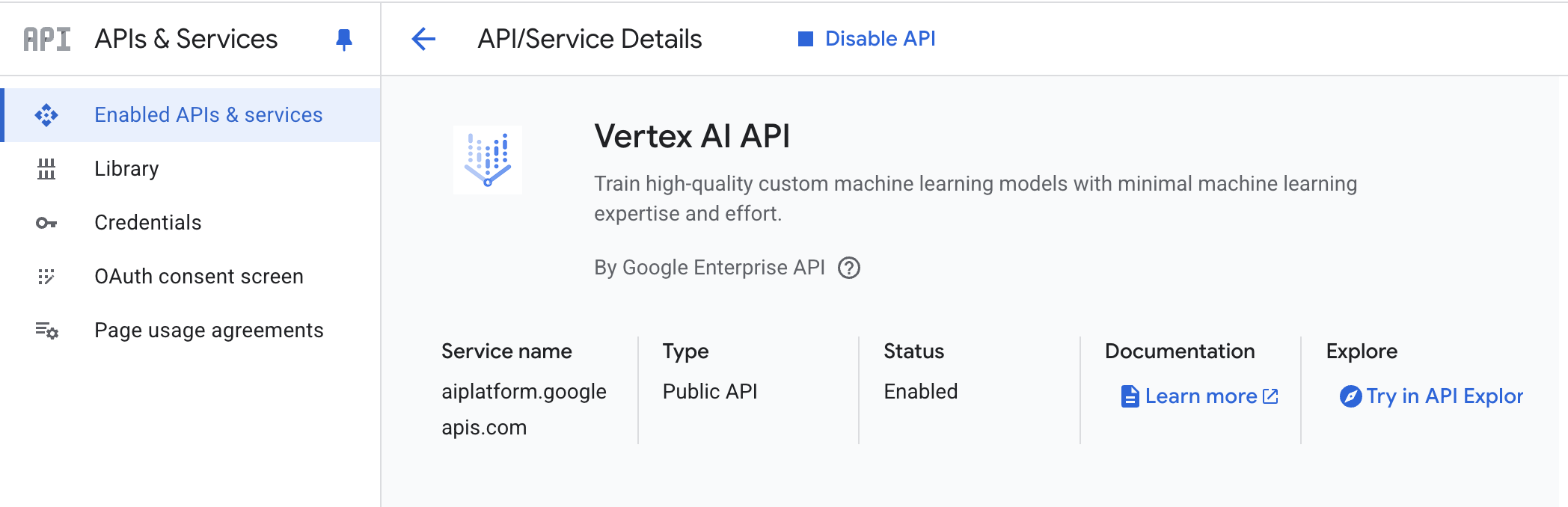
- API do Vertex AI – habilite a API do Vertex AI em seu projeto do Google Cloud
- Ambiente virtual Python – Mantém as dependências isoladas; consulte a documentação
venv.
Configuração do ambiente
Crie o diretório do seu projeto e instale as dependências:
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install google-genai google-cloud-aiplatform google-cloud-storage langchain-google-vertexai pypdf python-dotenv pandas pillowCrie um novo arquivo chamado rag_agent.py e adicione as seguintes importações:
import os
import json
import PyPDF2
import fitz
import time
import vertexai
from google import genai
from vertexai.preview import rag
from pathlib import Path
from vertexai.preview.generative_models import GenerativeModel, Tool
from google.cloud import storage
from typing import List, Dict, Any, Optional
from datetime import datetime
from dotenv import load_dotenv
from google.api_core.exceptions import ResourceExhausted
from google.genai import types
load_dotenv()Crie um arquivo .env com suas credenciais:
GOOGLE_CLOUD_PROJECT="your-project-id"
GOOGLE_CLOUD_LOCATION="us-central1"
GOOGLE_APPLICATION_CREDENTIALS="path/to/service-account-key.json"
GENAI_API_KEY="sua-chave-API-genai"
GCS_BUCKET_NAME="nome-do-seu-bucket"Você precisa de:
- ID do projeto: seu identificador do projeto Google Cloud no console
- Localização: região para recursos da IA (recomenda-se us-east1)
- Chave da conta de serviço: arquivo de chave JSON baixado do IAM & Admin
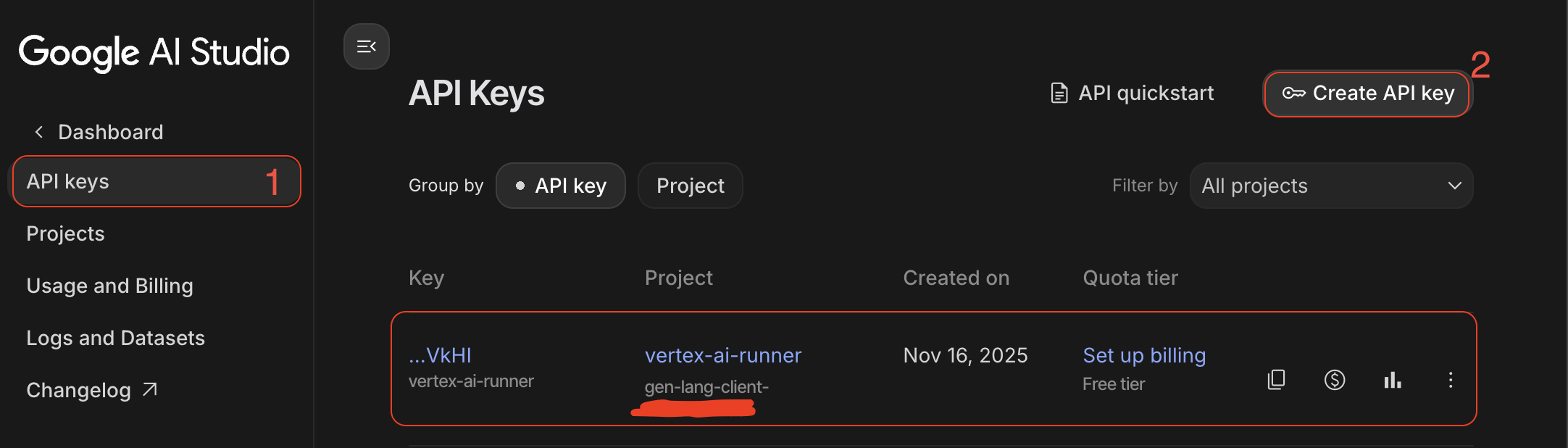
- Chave da API de IA: crie a partir do Google AI Studio
- Bucket GCS: bucket do Cloud Storage para armazenamento de documentos
Criação do sistema RAG Agent
Etapa 1: configuração do Google ADK
Configure o cliente Google ADK e inicialize o Vertex AI com a autenticação adequada. O cliente lida com todas as interações com os serviços de IA generativa do Google.
def initialize_adk():
"""Inicialize o Vertex IA com a autenticação adequada."""
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = os.getenv("GOOGLE_APPLICATION_CREDENTIALS")
vertexai.init(
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION")
)
print(f"✓ Vertex IA inicializado")
# Inicialize o sistema
initialize_adk()A inicialização estabelece conexões com o cliente GenAI para operações do agente e com o Vertex AI para recursos RAG. Ela valida as credenciais e confirma a configuração do projeto antes de prosseguir.
Etapa 2: Configuração do mecanismo RAG da IA do Vertex AI
Crie um corpus RAG que sirva como base para sua base de conhecimento. O corpus armazena documentos indexados, gerencia incorporações e lida com consultas de recuperação.
def create_rag_corpus(corpus_name: str, description: str) -> str:
"""Crie um novo corpus RAG para armazenamento e recuperação de documentos."""
tente:
corpus = rag.create_corpus(
display_name=corpus_name,
description=description,
embedding_model_config=rag.EmbeddingModelConfig(
publisher_model="publishers/google/models/text-embedding-004"
)
)
corpus_id = corpus.name.split('/')[-1]
print(f"✓ Corpus RAG criado: {corpus_name}")
print(f"✓ ID do corpus: {corpus_id}")
print(f"✓ Modelo de incorporação: text-embedding-004")
retornar corpus_id
exceto Exception como e:
imprimir(f"Erro ao criar corpus: {str(e)}")
levantar
def configurar_parâmetros_de_recuperação(corpus_id: str) -> Dict[str, Any]:
"""Configurar parâmetros de recuperação para desempenho de pesquisa ideal."""
retrieval_config = {
"corpus_id": corpus_id,
"similarity_top_k": 10,
"vector_distance_threshold": 0.5,
"filter": {},
"ranking_config": {
"rank_service": "default",
"alpha": 0.5
}
}
imprimir(f"✓ Parâmetros de recuperação configurados")
imprimir(f" - Resultados Top K: {retrieval_config['similarity_top_k']}")
imprimir(f" - Limite de distância: {retrieval_config['vector_distance_threshold']}")
imprimir(f" - Alfa de pesquisa híbrida: {retrieval_config['ranking_config']['alpha']}")
retornar retrieval_configA criação do corpus usa o modelo text-embedding-004 do Google para embeddings semânticos de alta qualidade. A configuração de recuperação equilibra a similaridade semântica e a correspondência de palavras-chave por meio do parâmetro alfa, em que 0,5 fornece ponderação igual.
Etapa 3: Pipeline de ingestão de documentos
Crie um pipeline robusto de ingestão de documentos que lida com vários formatos de arquivo, extrai texto limpo e preserva metadados importantes para uma recuperação aprimorada.
def extrair_texto_de_pdf(caminho_do_arquivo: str) -> Dict[str, Any]:
"""Extraia texto e metadados de documentos PDF."""
com open(caminho_do_arquivo, 'rb') como arquivo:
pdf_reader = PyPDF2.PdfReader(arquivo)
metadata = {
'source': file_path,
'num_pages': len(pdf_reader.pages),
'title': pdf_reader.metadata.get('/Title', ''),
'author': pdf_reader.metadata.get('/Author', ''),
'created_date': str(datetime.now())
}
text_content = []
para page_num, page em enumerate(pdf_reader.pages):
page_text = page.extract_text()
text_content.append({
'page': page_num + 1,
'text': page_text,
'char_count': len(page_text)
})
retornar {
'metadados': metadados,
'conteúdo': conteúdo_texto,
'texto_completo': ' '.join([p['texto'] para p em conteúdo_texto])
}
def pré-processar_documento(texto: str) -> str:
"""Limpar e normalizar o texto do documento para uma indexação ideal."""
texto = ' '.join(texto.split())
texto = texto.replace('x00', '')
texto = texto.replace('rn', 'n')
lines = text.split('n')
cleaned_lines = [
line for line in lines
if len(line.strip()) > 3
and not line.strip().isdigit()
]
return 'n'.join(cleaned_lines)A estratégia de fragmentação usa limites de frases para evitar quebrar o meio do pensamento, implementa sobreposição para preservar o contexto entre fragmentos e mantém metadados sobre as posições dos fragmentos para citações precisas. O tamanho do fragmento de 1000 caracteres equilibra a precisão da recuperação com a integridade do contexto.
Etapa 4: Incorporação e indexação
Carregue documentos no corpus RAG e gere incorporações vetoriais para pesquisa semântica. O sistema lida automaticamente com a geração de incorporações e a otimização de índices.
def chunk_document(text: str, chunk_size: int = 1000, overlap: int = 200) -> List[Dict[str, Any]]:
"""Divida o documento em fragmentos sobrepostos para uma recuperação ideal."""
chunks = []
start = 0
text_length = len(text)
chunk_id = 0
enquanto start < text_length:
end = start + chunk_size
se end < text_length:
last_period = text.rfind('.', start, end)
se last_period != -1 e last_period > start:
end = last_period + 1
chunk_text = text[start:end].strip()
se chunk_text:
chunks.append({
'chunk_id': chunk_id,
'text': chunk_text,
'start_char': início,
'end_char': fim,
'char_count': len(chunk_text)
})
chunk_id += 1
início = fim - sobreposição
imprimir(f"✓ Criados {len(chunks)} pedaços com {overlap} caracteres sobrepostos")
retornar pedaços
def upload_file_to_gcs(local_path: str, gcs_bucket: str) -> str:
"""Carregar documento no Google Cloud Storage para ingestão RAG."""
storage_client = storage.Client()
bucket = storage_client.bucket(gcs_bucket)
blob_name = f"rag-docs/{Path(local_path).name}"
blob = bucket.blob(blob_name)
blob.upload_from_filename(local_path)
gcs_uri = f"gs://{gcs_bucket}/{blob_name}"
print(f"✓ Carregado para o GCS: {gcs_uri}")
retornar gcs_uri
def importar_documentos_para_corpus(corpus_id: str, file_uris: Lista[str]) -> str:
"""Importar documentos para o corpus RAG e gerar embeddings."""
imprimir(f"⚡ Iniciando importação de {len(file_uris)} documentos...")
response = rag.import_files(
corpus_name=f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}",
paths=file_uris,
chunk_size=1000,
chunk_overlap=200
)
tente:
se hasattr(resposta, 'resultado'):
imprima("⏳ Aguardando a conclusão da operação de importação (isso pode levar um minuto)...")
resposta.resultado()
caso contrário:
imprima("✓ Solicitação de importação enviada.")
exceto Exceção como e:
imprima(f"⚠️ Observação sobre a espera: {e}")
imprimir(f"✓ Documentos importados e indexação acionada.")
retornar getattr(resposta, 'nome', 'operação_desconhecida')
def criar_índice_vetorial(corpus_id: str, index_config: Dict[str, Any]) -> str:
"""Criar índice vetorial otimizado para pesquisa rápida de similaridade."""
index_settings = {
'corpus_id': corpus_id,
'distance_measure': 'COSINE',
'algorithm': 'TREE_AH',
'leaf_node_embedding_count': 1000,
'leaf_nodes_to_search_percent': 10
}
print(f"✓ Índice vetorial criado com algoritmo TREE_AH")
print(f"✓ Medida de distância: similaridade COSINE")
print(f"✓ Otimizado para {index_settings['leaf_nodes_to_search_percent']}% de cobertura de pesquisa")
return corpus_idO processo de importação lida com o Parsing, a fragmentação e a geração de incorporação de documentos automaticamente. O algoritmo TREE_AH fornece uma pesquisa rápida e aproximada do vizinho mais próximo, mantendo uma alta recuperação. A similaridade COSINE mede a distância angular entre vetores de incorporação para correspondência semântica.
Etapa 5: Desenvolvimento de agente com ADK
Crie a arquitetura central do agente que gerencia o contexto, lida com as consultas do usuário e coordena a recuperação com a geração de respostas.
class RAGAgent:
"""Agente RAG inteligente com gerenciamento de contexto e fundamentação."""
def __init__(self, corpus_id: str, model_name: str = "gemini-2.5-flash"):
self.corpus_id = corpus_id
self.model_name = model_name
self.conversation_history = []
self.rag_tool = Tool.from_retrieval(
retrieval=rag.Retrieval(
source=rag.VertexRagStore(
rag_corpora=[f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}"],
similarity_top_k=5,
vector_distance_threshold=0.3
)
)
)
self.model = GenerativeModel(
model_name=model_name,
tools=[self.rag_tool]
)
print(f"✓ Agente RAG inicializado com {model_name}")
imprimir(f"✓ Conectado ao corpus: {corpus_id}")
def gerenciar_contexto(self, consulta: str, histórico_máximo: int = 5) -> Lista[Dict[str, str]]:
"""Gerenciar contexto de conversa com truncamento do histórico."""
histórico_de_conversação.append({
'função': 'usuário',
'conteúdo': consulta,
'carimbo_de_data': datetime.now().isoformat()
})
se len(histórico_de_conversação) > histórico_máximo * 2:
histórico_de_conversas = histórico_de_conversas[-histórico_máximo * 2:]
histórico_formatado = []
para msg em histórico_de_conversas:
histórico_formatado.append({
'função': msg['função'],
'partes': [msg['conteúdo']]
})
retornar histórico formatado
def construir_prompt_fundamentado(self, consulta: str, contexto_recuperado: Lista[Dict[str, Qualquer]]) -> str:
"""Construir prompt com instruções fundamentadas explícitas."""
texto_contexto = "nn".join([
f"[Fonte {i+1}]: {ctx['texto']}"
para i, ctx em enumerate(contexto_recuperado)
])
prompt = f"""Você é um assistente de IA útil com acesso a uma base de conhecimento.
Responda à seguinte pergunta usando APENAS as informações fornecidas no contexto abaixo.
INSTRUÇÕES IMPORTANTES:
1. Baseie sua resposta estritamente no contexto fornecido.
2. Se o contexto não contiver informações suficientes, diga isso explicitamente.
3. Cite fontes específicas usando a notação [Fonte X].
4. Não adicione informações de seu conhecimento geral.
5. Se você não tiver certeza, reconheça isso.
CONTEXTO:
{context_text}
PERGUNTA:
{query}
RESPOSTA:"""
return promptO agente mantém o histórico de conversas para interações com várias voltas, gerencia o tamanho da janela de contexto para evitar limites de tokens e cria prompts com instruções explícitas para reduzir alucinações. A integração da ferramenta RAG permite a recuperação automática durante a geração.
Etapa 6: Processamento e recuperação de consultas
Implemente uma pesquisa híbrida que combine compreensão semântica com correspondência de palavras-chave para obter precisão de recuperação ideal.
def hybrid_search(
self,
corpus_id: str,
query: str,
semantic_weight: float = 0.7,
top_k: int = 10
) -> List[Dict[str, Any]]:
"""Executar pesquisa híbrida com repetição automática em limites de cota."""
rag_resource = rag.RagResource(
rag_corpus=f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}"
)
max_retries = 3
base_delay = 90
para tentativa no intervalo (max_retries):
tente:
imprimir(f"🔍 Pesquisando corpus (Tentativa {tentativa + 1})...")
resultados = rag.retrieval_query(
rag_resources=[rag_resource],
text=query,
similarity_top_k=top_k,
vector_distance_threshold=0.5
)
# Se bem-sucedido, processe e retorne os resultados
retrieved_chunks = []
para i, context em enumerate(results.contexts.contexts):
retrieved_chunks.append({
'rank': i + 1,
'text': context.text,
'source': context.source_uri se hasattr(context, 'source_uri') senão 'unknown',
'distance': context.distance se hasattr(context, 'distance') senão 0.0
})
imprimir(f"✓ Recuperados {len(retrieved_chunks)} trechos relevantes")
retornar retrieved_chunks
exceto ResourceExhausted:
tempo_de_espera = base_delay * (2 ** tentativa)
imprimir(f"⚠️ Cota atingida (Limite: 5/min). Esfriando por {tempo_de_espera}s...")
time.sleep(tempo_de_espera)
exceto Exception como e:
print(f"❌ Erro de recuperação: {str(e)}")
raise
print("❌ Número máximo de tentativas atingido. Falha na recuperação.")
retornar []
def rerank_results(
self,
results: List[Dict[str, Any]],
query: str,
model_name: str = "gemini-2.5-flash")
-> List[Dict[str, Any]]:
"""Reordenar os resultados recuperados com base na relevância da consulta."""
if not results:
return []
rerank_prompt = f"""Classifique a relevância de cada passagem para a consulta em uma escala de 0 a 10.
Consulta: {query}
Passagens:
{chr(10).join([f"{i+1}. {r['text'][:200]}..." para i, r em enumerate(resultados)])}
Retorne apenas uma lista de pontuações separadas por vírgulas (por exemplo, 8,6,9,3,7)."""
model = GenerativeModel(nome_do_modelo)
resposta = model.generate_content(rerank_prompt)
if response.text:
try:
scores = [float(s.strip()) for s in response.text.strip().split(',')]
for i, score in enumerate(scores[:len(results)]):
results[i]['rerank_score'] = score
results.sort(key=lambda x: x.get('rerank_score', 0), reverse=True)
print(f"✓ Resultados reclassificados usando pontuação LLM")
except Exception as e:
print(f"Aviso: falha na reclassificação, usando a ordem original: {str(e)}")
return resultsA pesquisa híbrida recupera candidatos usando similaridade vetorial e, em seguida, a reclassificação usa o LLM para pontuar a relevância com base no contexto específico da consulta. Essa abordagem em duas etapas equilibra eficiência e precisão.
Etapa 7: Geração de respostas e fundamentação
Gere respostas com citações adequadas e implemente a prevenção de alucinações por meio de uma verificação rigorosa de fundamentação.
def generate_grounded_response(
self,
agent: 'RAGAgent',
query: str,
retrieved_context: List[Dict[str, Any]],
temperature: float = 0.2
) -> Dict[str, Any]:
"""Gerar resposta com citações e prevenção de alucinações."""
grounded_prompt = agent.build_grounded_prompt(query, retrieved_context)
chat = agent.model.start_chat()
response = chat.send_message(
grounded_prompt,
generation_config={
'temperature': temperature,
'top_p': 0.8,
'top_k': 40,
'max_output_tokens': 1024
}
)
return {
'answer': response.text,
'sources': retrieved_context,
'query': query,
'timestamp': datetime.now().isoformat()
}
def verify_grounding(
self,
response: str,
sources: List[Dict[str, Any]],
model_name: str = "gemini-2.5-flash"
) -> Dict[str, Any]:
"""Verifique se as afirmações da resposta estão fundamentadas no material de origem."""
verification_prompt = f"""Analise se a resposta a seguir é totalmente comprovada pelas fontes fornecidas.
FONTES:
{chr(10).join([f"Fonte {i+1}: {s['text']}" para i, s em enumerate(sources)])}
RESPOSTA:
{response}
Verifique cada afirmação na resposta. Responda com JSON:
{{
"is_grounded": verdadeiro/falso,
"unsupported_claims": ["afirmação1", "afirmação2"],
"confidence_score": 0,0-1,0
}}"""
model = GenerativeModel(model_name)
verification_response = model.generate_content(verification_prompt)
tente:
json_text = verificação_resposta.text.strip()
se '```json' em json_text:
json_text = json_text.split('```json')[1].split('```')[0].strip()
verificação_resultado = json.loads(json_text)
imprimir(f"✓ Verificação de aterramento concluída")
imprimir(f" - Aterrado: {verification_result.get('is_grounded', False)}")
imprimir(f" - Confiança: {verification_result.get('confidence_score', 0.0):.2f}")
retornar resultado_da_verificação
exceto Exceção como e:
imprimir(f"Aviso: falha na verificação de fundamentação: {str(e)}")
retornar {'está_fundamentado': Verdadeiro, 'pontuação_de_confiança': 0.5}A verificação de fundamentação verifica se cada afirmação na resposta pode ser rastreada até os documentos de origem. A geração de baixa temperatura (0,2) reduz o embelezamento criativo e melhora a precisão factual.
Etapa 8: Implementação multimodal do RAG
Estenda o sistema RAG para lidar com imagens, tabelas e outros conteúdos não textuais para uma recuperação abrangente de conhecimento.
def extrair_imagens_de_pdf(self, caminho_pdf: str, diretório_saída: str) -> Lista[Dict[str, Qualquer]]:
"""Extraia imagens de documentos PDF para indexação multimodal."""
doc = fitz.open(caminho_pdf)
imagens = []
os.makedirs(output_dir, exist_ok=True)
for page_num in range(len(doc)):
page = doc[page_num]
image_list = page.get_images()
for img_index, img in enumerate(image_list):
xref = img[0]
imagem_base = doc.extract_image(xref)
bytes_imagem = imagem_base["image"]
# Salvar imagem
nome_arquivo_imagem = f"página{page_num + 1}_img{img_index + 1}.png"
caminho_imagem = os.path.join(output_dir, nome_arquivo_imagem)
com open(image_path, "wb") como img_file:
img_file.write(image_bytes)
images.append({
'page': page_num + 1,
'image_path': image_path,
'format': base_image['ext'],
'size': len(image_bytes)
})
imprimir(f"✓ Extraiu {len(imagens)} imagens do PDF")
retornar imagens
def processar_conteúdo_da_tabela(self, texto_da_tabela: str) -> Dict[str, Any]:
"""Processa e estrutura os dados da tabela para melhorar a recuperação."""
linhas = texto_da_tabela.strip().split('n')
se não houver linhas:
retornar {}
cabeçalhos = [h.strip() para h em linhas[0].split('|') se h.strip()]
linhas = []
para linha em linhas[1:]:
células = [c.strip() para c em linha.split('|') se c.strip()]
se len(células) == len(cabeçalhos):
row_dict = dict(zip(headers, cells))
rows.append(row_dict)
return {
'headers': headers,
'rows': rows,
'row_count': len(rows),
'column_count': len(headers)
}
def create_multimodal_embedding(
self,
text: str,
image_path: Optional[str] = None,
table_data: Optional[Dict[str, Any]] = None
) -> Dict[str, Any]:
"""Cria uma incorporação unificada para conteúdo multimodal."""
combined_text = text
if table_data and table_data.get('rows'):
table_desc = f"nTabela com {table_data['row_count']} linhas e colunas: {', '.join(table_data['headers'])}n"
combined_text += table_desc
if image_path:
combined_text += f"n[Image: {Path(image_path).name}]"
retornar {
'texto': texto_combinado,
'tem_imagem': caminho_da_imagem não é None,
'tem_tabela': dados_da_tabela não é None,
'modalidades': soma([bool(texto), bool(caminho_da_imagem), bool(dados_da_tabela)])
}O processamento multimodal extrai e indexa imagens e tabelas juntamente com o texto. A abordagem de incorporação unificada combina metadados descritivos de todas as modalidades em texto pesquisável. Isso permite que consultas como “mostre-me a tabela de preços do relatório do terceiro trimestre” recuperem os dados da tabela e o contexto circundante.
Etapa 9: integração do agente Google ADK
Integre o Agent Development Kit (ADK) do Google para criar uma interface de agente melhorada que se conecta ao backend do Vertex AI RAG Engine. O ADK oferece recursos de agente aprimorados, incluindo chamada de ferramentas, conversas com várias respostas e respostas estruturadas.
class ADKRAGAgent:
"""Wrapper do Google ADK Agent que usa o Vertex AI RAG Engine como back-end."""
def __init__(self, corpus_id: str, project_id: str, location: str):
"""Inicialize o ADK Agent com recursos RAG."""
self.corpus_id = corpus_id
self.project_id = project_id
self.location = location
self.rag_agent = RAGAgent(corpus_id)
self.client = genai.Client(
vertexai=True,
project=project_id,
location=location
)
self.model_name = "gemini-2.0-flash-001"
print(f"✓ Agente Google ADK inicializado")
print(f" - Estrutura: Google ADK (genai.Client)")
print(f" - Backend: Vertex IA RAG Engine")
print(f" - Project: {project_id}")
print(f" - Location: {location}")
print(f" - RAG Corpus: {corpus_id}")
def create_rag_search_tool(self) -> types.Tool:
"""Criar ferramenta de pesquisa RAG para agente ADK."""
def rag_search(query: str) -> str:
"""
Pesquisar o corpus RAG e retornar respostas fundamentadas.
Argumentos:
query: A pergunta do usuário a ser pesquisada
Retorna:
Uma resposta fundamentada com citações da base de conhecimento
"""
tente:
resultados = self.rag_agent.hybrid_search(
self.corpus_id,
query,
semantic_weight=0.7,
top_k=10)
se não houver resultados:
retorne "Nenhuma informação relevante encontrada na base de conhecimento."
reranked = self.rag_agent.rerank_results(results, query)
response = self.rag_agent.generate_grounded_response(
self.rag_agent,
query,
reranked[:5]
)
verification = self.rag_agent.verify_grounding(
response['answer'],
response['sources']
)
answer = response['answer']
if not verification.get('is_grounded', True):
answer += f"nn[Confiança: {verification.get('confidence_score', 0):.0%}]"
return answer
except Exception as e:
return f"Erro ao pesquisar na base de conhecimento: {str(e)}"
rag_tool = types.Tool(
function_declarations=[
types.FunctionDeclaration(
name="rag_search",
description="Pesquise na base de conhecimento da empresa usando RAG (Retrieval-Augmented Generation) para encontrar respostas precisas e fundamentadas para perguntas sobre documentação técnica, especificações de produtos e guias do usuário.",
parâmetros={
"tipo": "objeto",
"propriedades": {
"consulta": {
"tipo": "string",
"descrição": "A pergunta ou consulta de pesquisa do usuário"
}
},
"obrigatório": ["consulta"]
}
)
]
)
self.rag_search_function = rag_search
return rag_tool
def create_agent(self) -> Dict[str, Any]:
"""Crie a configuração do Google ADK Agent com a ferramenta RAG."""
rag_tool = self.create_rag_search_tool()
agent_instructions = """Você é um agente RAG (Retrieval-Augmented Generation) inteligente com acesso a uma base de conhecimento empresarial.
Suas capacidades:
- Pesquisar documentação técnica, especificações de produtos e guias do usuário
- Fornecer respostas precisas e fundamentadas com citações
- Lidar com conversas de várias voltas com consciência do contexto
- Verificar a precisão das informações antes de responder
Diretrizes:
1. Sempre use a ferramenta rag_search para encontrar informações antes de responder
2. Forneça respostas específicas e detalhadas com base nos documentos recuperados
3. Inclua citações e fontes relevantes
4. Se as informações não forem encontradas, indique isso claramente
5. Mantenha o contexto da conversa em várias consultas
Seja útil, preciso e profissional em todas as respostas."""
agent_config = {
'model': self.model_name,
'instructions': agent_instructions,
'tools': [rag_tool],
'display_name': 'RAG Agent with Vertex IA (Google ADK + Vertex IA RAG Engine)'
}
print(f"✓ Configuração do agente Google ADK criada")
print(f" - Modelo: {self.model_name}")
print(f" - Ferramentas: Pesquisa RAG (Vertex IA RAG Engine)")
retornar agent_config
def chat(self, agent_config: Dict[str, Any], query: str, session_id: str = "default") -> str:
"""Envie uma mensagem para o agente ADK e obtenha uma resposta usando o Google GenAI."""
self.rag_agent.manage_context(query)
tente:
resposta = self.client.models.generate_content(
modelo=agent_config['model'],
conteúdo=query,
config=types.GenerateContentConfig(
instrução_do_sistema=agent_config['instructions'],
ferramentas=agent_config['tools'],
temperatura=0.2)
)
if response.candidates and len(response.candidates) > 0:
candidate = response.candidates[0]
if candidate.content and candidate.content.parts:
for part in candidate.content.parts:
if hasattr(part, 'function_call') and part.function_call:
function_name = part.function_call.name
argumentos_da_função = parte.chamada_da_função.argumentos
imprimir(f" → Ferramenta de chamada do agente ADK: {nome_da_função}")
se nome_da_função == "rag_search":
argumento_da_consulta = argumentos_da_função.obter("consulta", consulta)
resultado_da_ferramenta = self.rag_search_function(argumento_da_consulta)
resposta = self.client.models.generate_content(
modelo=agent_config['model'],
conteúdo=[
tipos.Conteúdo(função="usuário", partes=[tipos.Parte(texto=query)]),
tipos.Conteúdo(função="modelo", partes=[parte]),
tipos.Conteúdo(
função="função",
partes=[tipos.Parte(
resposta_função=tipos.RespostaFunção(
nome=nome_função,
resposta={"resultado": resultado_ferramenta}
)
)]
)
],
config=types.GenerateContentConfig(
system_instruction=agent_config['instructions'],
tools=agent_config['tools'],
temperature=0.2
)
)
elif hasattr(part, 'text') and part.text:
answer = part.text
self.rag_agent.conversation_history.append({
'role': 'assistant',
'content': resposta,
'timestamp': datetime.now().isoformat()
})
retornar resposta
se resposta.candidatos e resposta.candidatos[0].conteúdo.partes:
para parte em resposta.candidatos[0].conteúdo.partes:
se hasattr(parte, 'texto') e parte.texto:
resposta = parte.texto
self.rag_agent.conversation_history.append({
'role': 'assistente',
'content': resposta,
'timestamp': datetime.now().isoformat()
})
retorne resposta
retorne "Nenhuma resposta gerada."
exceto Exception como e:
error_msg = f"Erro no chat do agente ADK: {str(e)}"
print(f"❌ {error_msg}")
retornar error_msgA integração ADK adiciona a estrutura de agente do Google ao seu agente RAG existente. A classe ADKRAGAgent configura um genai.Client para operações do agente e usa seu RAGAgent para recuperação. O método create_rag_search_tool define uma função que o agente pode chamar, permitindo que ele pesquise sua base de conhecimento usando o Vertex IA RAG Engine.
O mecanismo de chamada da ferramenta permite que o agente determine automaticamente quando pesquisar a base de conhecimento com base nas consultas do usuário. Quando uma pesquisa é necessária, ele executa o pipeline de pesquisa híbrido, reordena os resultados, gera respostas fundamentadas e verifica a precisão antes de fornecer as respostas. O método de chat gerencia todo o fluxo da conversa, incluindo a execução da ferramenta e o gerenciamento de contexto de várias voltas.
Etapa 10: potencialize seu RAG com dados da web em tempo real da Bright Data
Embora seu sistema RAG seja excelente para recuperar informações de sua base de conhecimento interna, os aplicativos de IA corporativos geralmente exigem dados novos e em tempo real de fontes externas. É aqui que a plataforma de dados da web da Bright Data se torna inestimável, permitindo que seu agente RAG acesse informações ao vivo de toda a web, mantendo sua base de conhecimento atualizada e abrangente.
Por que integrar a Bright Data ao seu sistema RAG?
1. Mantenha sua base de conhecimento atualizada
- Atualize automaticamente seu corpus RAG com as informações mais recentes sobre produtos, dados de preços, inteligência da concorrência e tendências de mercado
- Elimine dados obsoletos que levam a respostas de IA desatualizadas
- Programe atualizações periódicas de dados para manter a precisão
2. Vá além dos documentos internos
- Acesse dados em tempo real de mais de 120 sites populares, incluindo plataformas de comércio eletrônico, sites de notícias, mídias sociais e fontes específicas do setor
- Aumente sua documentação técnica com documentação de API ao vivo, discussões da comunidade e especificações atualizadas
- Incorpore avaliações, comentários e dados de opinião dos clientes para aprimorar sua base de conhecimento sobre o produto
3. Habilite o aprimoramento dinâmico de consultas
- Quando seu agente RAG detectar uma consulta que exija informações atuais (preços, disponibilidade, notícias recentes), busque automaticamente os dados mais recentes
- Combine conhecimento interno com dados externos da web para obter respostas abrangentes
- Forneça aos usuários tanto o contexto histórico quanto informações atualizadas
4. Escale a coleta de dados sem esforço
- Não há necessidade de gerenciar proxies, lidar com CAPTCHAs ou sistemas anti-bot
- A Bright Data cuida de toda a infraestrutura, desbloqueio e qualidade dos dados
- Concentre-se no desenvolvimento de IA enquanto a Bright Data cuida da aquisição de dados
Implementação: adicionando a Bright Data ao seu pipeline RAG
Vamos ampliar seu sistema RAG com os recursos da Bright Data. Adicionaremos três padrões de integração: integração de Conjuntos de dados para dados pré-coletados, API de Scraping de dados para raspagem em tempo real e AI Scrapers para insights enriquecidos gerados por IA.
Padrão 1: integração de Conjuntos de dados para dados históricos
Use o Dataset Marketplace da Bright Data para preencher rapidamente seu corpus RAG com dados estruturados de alta qualidade.
import requests
from typing import List, Dict
import json
class BrightDataRAGEnhancer:
"""Aprimore o sistema RAG com os recursos de dados da web da Bright Data."""
def __init__(self, api_key: str, rag_agent: RAGAgent):
self.api_key = api_key
self.rag_agent = rag_agent
self.base_url = "https://api.brightdata.com"
def fetch_dataset_data(
self,
dataset_id: str,
filters: Dict[str, Any] = None,
limit: int = 1000
) -> Lista[Dict[str, Any]]:
"""Buscar dados do Bright Data Dataset Marketplace."""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
endpoint = f"{self.base_url}/Conjuntos de datos/v3/snapshot/{dataset_id}"
params = {
"format": "json",
"limit": limit
}
if filters:
params["filter"] = json.dumps(filters)
response = requests.get(endpoint, headers=headers, params=params)
response.raise_for_status()
print(f"✓ Recuperados {len(response.json())} registros do conjunto de dados {dataset_id}")
return response.json()
def ingest_dataset_to_rag(
self,
corpus_id: str,
dataset_records: List[Dict[str, Any]],
text_fields: List[str]
) -> None:
"""Processar registros do conjunto de dados e adicioná-los ao corpus RAG."""
processed_chunks = []
para registro em registros_do_conjunto_de_dados:
# Combinar campos de texto especificados em conteúdo pesquisável
texto_combinado = " ".join([
str(registro.get(campo, ""))
para campo em campos_de_texto
se registro.get(campo)
])
se texto_combinado.strip():
# Adicionar metadados para melhor recuperação
metadata = {
"source": "bright_data_dataset",
"record_id": record.get("id", "unknown"),
"ingestion_date": datetime.now().isoformat(),
"data_type": "external_web_data"
}
# Dividir o conteúdo em partes
chunks = chunk_document(combined_text, chunk_size=1000, overlap=200)
para chunk em chunks:
chunk['metadata'] = metadata
processed_chunks.append(chunk)
imprimir(f"✓ Processou {len(processed_chunks)} partes do conjunto de dados")
# Criar arquivo temporário para upload
temp_file = "temp_dataset_content.txt"
with open(temp_file, 'w') as f:
for chunk in processed_chunks:
f.write(chunk['text'] + "nn")
# Fazer upload para o GCS e importar para o corpus
gcs_uri = upload_file_to_gcs(temp_file, os.getenv('GCS_BUCKET_NAME'))
import_documents_to_corpus(corpus_id, [gcs_uri])
os.remove(temp_file)
print(f"✓ Conteúdo do conjunto de dados adicionado ao corpus RAG")Exemplo de caso de uso: preencha seu RAG de comércio eletrônico com dados de produtos
# Primeiro, crie um corpus RAG
corpus_id = create_rag_corpus(
corpus_name="bright_data_corpus",
description="Corpus para RAG aprimorado pela Bright Data")
# Inicialize o agente RAG com o corpus
rag_agent = RAGAgent(corpus_id=corpus_id)
# Inicialize o aprimorador
enhancer = BrightDataRAGEnhancer(
api_key=os.getenv("BRIGHT_DATA_API_KEY"),
rag_agent=rag_agent)
print("✓ BrightDataRAGEnhancer inicializado com sucesso!")
# Buscar dados de produtos da Amazon
amazon_data = enhancer.fetch_dataset_data(
dataset_id="gd_l7q7dkf244hwxr90h", # Conjunto de dados de produtos da Amazon
filters={"category": "Electronics"},
limit=5000
)
# Ingestão no corpus RAG
enhancer.ingest_dataset_to_rag(
corpus_id=corpus_id,
dataset_records=amazon_data,
text_fields=["title", "description", "features", "reviews"]
)Padrão 2: integração da API do Web Scraper em tempo real
Para obter informações dinâmicas e atualizadas, integre a API Web Scraper da Bright Data diretamente no pipeline de consulta do seu agente RAG.
def scrape_real_time_data(
self,
scraper_id: str,
inputs: List[Dict[str, Any]],
wait_for_completion: bool = True)
-> List[Dict[str, Any]]:
"""Execute o Scraping de dados da web em tempo real usando os Scrapers da Bright Data."""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# Acionar o Scraper
trigger_url = f"{self.base_url}/dca/trigger"
params = {
"Scraper": Scraper_id,
"queue_next": 1
}
response = requests.post(
trigger_url,
headers=headers,
params=params,
json=inputs
)
response.raise_for_status()
snapshot_id = response.json().get("snapshot_id")
print(f"✓ Scraper acionado. ID do snapshot: {snapshot_id}")
if not wait_for_completion:
return {"snapshot_id": snapshot_id, "status": "processing"}
# Pesquisar resultados
results_url = f"{self.base_url}/dca/conjuntos-de-dados"
params = {"id": snapshot_id}
max_retries = 30
para i em intervalo(max_retries):
time.sleep(10) # Esperar 10 segundos entre pesquisas
results_response = requests.get(results_url, headers=headers, params=params)
if results_response.status_code == 200:
data = results_response.json()
print(f"✓ Scraping concluído. Recuperados {len(data)} registros")
return data
elif results_response.status_code == 202:
imprimir(f"⏳ Ainda processando... ({i+1}/{max_retries})")
continuar
else:
imprimir(f"❌ Erro ao recuperar resultados: {results_response.status_code}")
break
retornar []
def create_dynamic_rag_tool(self) -> types.Tool:
"""Cria uma ferramenta RAG com aumento de dados da web em tempo real."""
def augmented_rag_search(query: str, include_live_data: bool = False) -> str:
"""
Pesquisa a base de conhecimento com enriquecimento opcional de dados da web em tempo real.
Argumentos:
query: A pergunta do usuário
include_live_data: Se deve buscar dados novos da web
Retorna:
Resposta fundamentada combinando dados internos e externos
"""
# Primeiro, pesquisar a base de conhecimento interna
resultados_internos = self.rag_agent.hybrid_search(
corpus_id=self.rag_agent.corpus_id,
query=query,
top_k=5
)
resultados_combinados = resultados_internos
# Se a consulta exigir informações atuais, buscar dados em tempo real
if include_live_data or self._requires_fresh_data(query):
print("🌐 Buscando dados da web em tempo real...")
# Exemplo: coletar informações de preços
if "price" in query.lower() or "cost" in query.lower():
live_data = self.scrape_real_time_data(
scraper_id="your_product_scraper_id",
inputs=[{"url": "https://example.com/products"}],
wait_for_completion=True
)
# Converter dados em tempo real em blocos pesquisáveis
for record in live_data[:3]: # Três primeiros resultados
combined_results.append({
'rank': len(combined_results) + 1,
'text': f"{record.get('title', '')}: {record.get('price', '')} - {record.get('description', '')}",
'source': f"Live web data: {record.get('url', 'unknown')}",
'distance': 0.3 # Alta relevância para dados recentes
})
# Gerar resposta com todo o contexto disponível
response = self.rag_agent.generate_grounded_response(
self.rag_agent,
query,
combined_results)
return response['answer']
retornar types.Tool(
declarações_de_função=[
types.FunctionDeclaration(
nome="augmented_rag_search",
descrição="Pesquisar base de conhecimento interna e, opcionalmente, buscar dados da web em tempo real para obter informações atuais",
parâmetros={
"type": "object",
"properties": {
"query": {"type": "string", "description": "Pergunta do usuário"},
"include_live_data": {"type": "boolean", "description": "Buscar dados recentes da web"}
},
"required": ["query"]
}
)
]
)
def _requires_fresh_data(self, query: str) -> bool:
"""Determina se a consulta requer dados em tempo real."""
fresh_data_keywords = [
"latest", "current", "today", "now", "recent",
"price", "cost", "available", "in stock"
]
return any(keyword in query.lower() for keyword in fresh_data_keywords)Padrão 3: integração do IA Scraper para inteligência aprimorada
Aproveite os AI Scrapers da Bright Data (ChatGPT, Perplexity, Gemini) para aumentar seu RAG com insights gerados por IA e contexto abrangente da web.
def query_ai_scraper(
self,
scraper_type: str,
prompt: str,
country_code: str = "us"
) -> Dict[str, Any]:
"""Consulte os scrapers de IA (ChatGPT, Perplexity, etc.) para obter um contexto enriquecido."""
scraper_ids = {
"chatgpt": "chatgpt_scraper_id",
"perplexity": "perplexity_scraper_id",
"gemini": "gemini_scraper_id"
}
inputs = [{
"prompt": prompt,
"country": country_code
}]
results = self.scrape_real_time_data(
scraper_id=scraper_ids.get(scraper_type),
inputs=inputs,
wait_for_completion=True
)
if results:
return {
"answer": results[0].get("answer", ""),
"sources": results[0].get("sources", []),
"citations": results[0].get("citations", [])
}
return {}
def criar_agente_de_inteligência_híbrida(self) -> Dict[str, Any]:
"""Cria um agente que combina RAG com inteligência de scraper de IA."""
def pesquisa_híbrida(query: str) -> str:
"""
Combina RAG interno com inteligência de scraper de IA externo.
Isso fornece:
1. Contexto da base de conhecimento interna
2. Insights gerados por IA em tempo real a partir da web
3. Respostas abrangentes e bem fundamentadas
"""
# Obter conhecimento interno
internal_answer = self.rag_agent.hybrid_search(
corpus_id=self.rag_agent.corpus_id,
query=query,
top_k=3
)
internal_context = "n".join([r['text'][:200] for r in internal_answer])
# Obter enriquecimento do Scraper de IA
print("🤖 Buscando inteligência da web aprimorada por IA...")
ai_insight = self.query_ai_scraper(
scraper_type="perplexity", # Conhecido por respostas bem fundamentadas
prompt=query
)
# Sintetizar ambas as fontes
synthesis_prompt = f"""Sintetizar uma resposta abrangente usando tanto o conhecimento interno quanto os insights externos da IA.
BASE DE CONHECIMENTO INTERNA:
{internal_context}
INSIGHTS DE IA EXTERNOS:
{ai_insight.get('answer', 'Nenhum insight externo disponível')}
FONTES:
{json.dumps(ai_insight.get('citations', []), indent=2)}
PERGUNTA: {query}
Forneça uma resposta completa que:
1. Priorize o conhecimento interno para informações específicas da empresa
2. Use insights externos para um contexto mais amplo e desenvolvimentos recentes
3. Cite claramente todas as fontes
4. Indique quando as informações vêm de fontes externas ou internas"""
model = GenerativeModel("gemini-2.0-flash-001")
response = model.generate_content(synthesis_prompt)
return response.text
return {
'search_function': hybrid_search,
'description': 'Sistema híbrido RAG + IA Scraper Intelligence'
}Executando seu sistema RAG Agent
Reúna todos os componentes em um fluxo de trabalho completo que processa documentos, lida com consultas e gera respostas fundamentadas. Além disso, baixe os documentos PDF que deseja processar e coloque-os na pasta docs/ para permitir que a IA construa um contexto sobre o seu produto.
def main():
"""Fluxo de execução principal para o sistema de agente RAG."""
print("=" * 60)
print("Sistema de agente RAG - Inicialização")
print("=" * 60)
initialize_adk()
corpus_id = create_rag_corpus(
corpus_name="enterprise-knowledge-base-3",
description="Documentação empresarial multimodal e repositório de conhecimento"
)
retrieval_config = configure_retrieval_parameters(corpus_id)
imprimir(f"n✓ Usando configuração de recuperação com top_k={retrieval_config['similarity_top_k']}")
imprimir("n" + "=" * 60)
imprimir("Pipeline de ingestão de documentos")
imprimir("=" * 60)
document_paths = [
"docs/technical_manual.pdf",
"docs/product_specs.pdf",
"docs/user_guide.pdf"
]
gcs_uris = []
all_chunks = []
extracted_images = []
para doc_path em document_paths:
if os.path.exists(doc_path):
extracted = extrair_texto_de_pdf(doc_path)
imprimir(f"n✓ Extraídas {extracted['metadata']['num_pages']} páginas de {Path(doc_path).name}")
texto_limpo = pré-processar_documento(extracted['full_text'])
imprimir(f"✓ Texto pré-processado: {len(texto_limpo)} caracteres")
trechos = trechar_documento(texto_limpo, tamanho_trecho=1000, sobreposição=200)
todos_os_trechos.extender(trechos)
imprimir(f"✓ Documento trechado em {len(trechos)} segmentos")
gcs_uri = upload_file_to_gcs(doc_path, os.getenv('GCS_BUCKET_NAME'))
gcs_uris.append(gcs_uri)
print(f"n✓ Total de segmentos criados: {len(all_chunks)}")
imprimir(f"✓ Total de imagens extraídas: {len(extracted_images)}")
se gcs_uris:
importar_documentos_para_corpus(corpus_id, gcs_uris)
index_config = {"distance_measure": "COSINE", "algorithm": "TREE_AH"}
create_vector_index(corpus_id, index_config)
time.sleep(180)
# ========================================================================
# Inicializar o Google ADK Agent com o Vertex AI RAG Engine
# ========================================================================
print("n" + "=" * 60)
print("Inicialização do Google ADK Agent")
imprimir("=" * 60)
adk_agent = ADKRAGAgent(
corpus_id=corpus_id,
project_id=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION")
)
agente = adk_agent.create_agent()
para doc_path em document_paths:
se os.path.exists(doc_path):
tente:
imagens = adk_agent.rag_agent.extract_images_from_pdf(doc_path, "extracted_images")
extracted_images.extend(imagens)
if images:
print(f"✓ Extracted {len(images)} images for multi-modal processing")
except Exception as e:
print(f"⚠️ Image extraction skipped: {str(e)}")
queries = [
"Quais são os requisitos do sistema para instalação?",
"Como configuro as definições de autenticação?",
"Quais são os níveis de preços e seus recursos?"
]
imprimir("n" + "=" * 60)
imprimir("Google ADK Agent - Processamento de consulta")
imprimir("=" * 60)
imprimir("Usando: Google ADK + Vertex IA RAG Engine")
imprimir("=" * 60)
session_id = f"session_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
para idx, query em enumerate(queries):
imprimir(f"n📝 Consulta {idx + 1}: {query}")
imprimir("-" * 60)
tente:
resposta = adk_agent.chat(agente, consulta, session_id)
imprimir(f"n💬 Resposta do agente ADK:n{resposta}n")
imprimir(f"✓ Histórico de conversas: {len(adk_agent.rag_agent.conversation_history)} mensagens")
exceto Exception como e:
imprimir(f"❌ Erro: {str(e)}")
importar traceback
traceback.print_exc()
imprimir("-" * 60)
se idx < len(queries) - 1:
time.sleep(90)
if extracted_images:
print("n" + "=" * 60)
print("Demonstração de processamento multimodal")
print("=" * 60)
sample_table = """Recurso | Básico | Pro | Empresarial
Armazenamento | 10 GB | 100 GB | Ilimitado
Usuários | 1 | 10 | Ilimitado
Preço | $10 | $50 | Personalizado"""
table_data = adk_agent.rag_agent.process_table_content(sample_table)
print(f"n✓ Tabela processada com {table_data.get('row_count', 0)} linhas")
if all_chunks and extracted_images:
multimodal_embed = adk_agent.rag_agent.create_multimodal_embedding(
text=all_chunks[0]['text'][:500],
image_path=extracted_images[0]['image_path'] if extracted_images else None,
table_data=table_data
)
print(f"✓ Criou incorporação multimodal com {multimodal_embed['modalities']} modalidades")
print(f" - Tem imagem: {multimodal_embed['has_image']}")
print(f" - Tem tabela: {multimodal_embed['has_table']}")
imprimir("n" + "=" * 60)
imprimir(f"Sistema Google ADK RAG Agent - Concluído")
imprimir(f"✓ Arquitetura: Google ADK + Vertex IA RAG Engine")
imprimir(f"✓ Total de turnos de conversação: {len(adk_agent.rag_agent.conversation_history)}")
imprimir("=" * 60)
se __name__ == "__main__":
tentar:
main()
exceto Exception como e:
imprimir(f"n❌ Erro: {str(e)}")
importar traceback
traceback.print_exc()Execute o sistema do agente RAG:
python3 rag_agent.pyVocê verá o pipeline de processamento do agente no console à medida que ele:
- Inicializa o cliente Google ADK e a conexão Vertex IA.
- Cria o corpus RAG com a configuração do modelo de incorporação.
- Processa documentos extraindo-os, limpando-os e dividindo-os em partes.
- Carrega os arquivos no Cloud Storage e os importa para o corpus.
- Gera incorporações vetoriais e cria o índice de pesquisa.
- Executa consultas com expansão, recuperação e reclassificação.
- Produz respostas fundamentadas com citações e verificação.
- Pontua a qualidade da resposta com base na relevância, completude, precisão e clareza.
A saída do console mostra o progresso detalhado de cada etapa.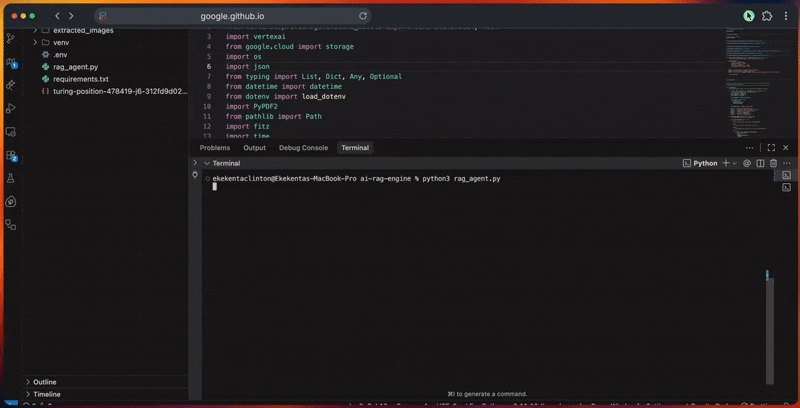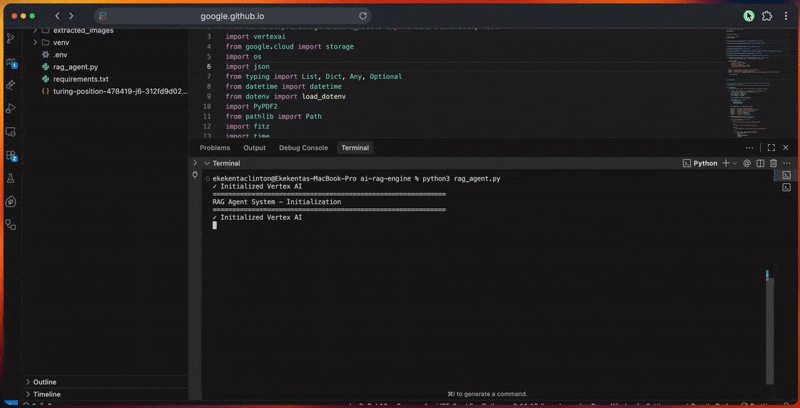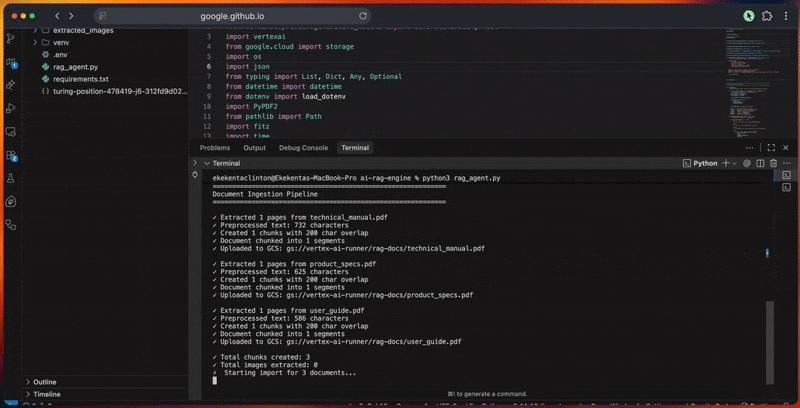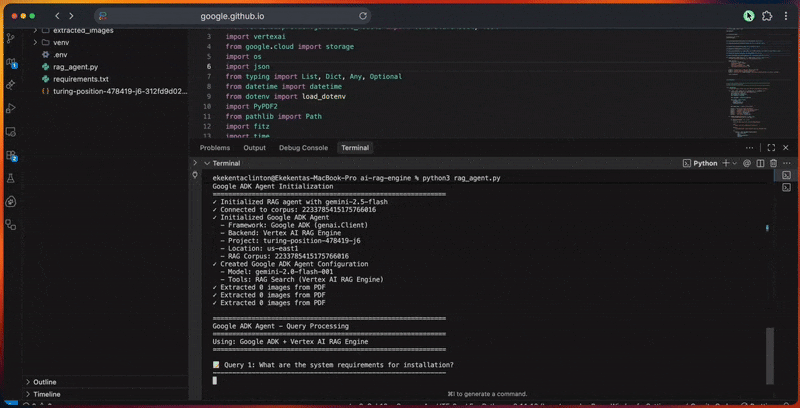
Considerações finais
Agora você tem um sistema de agente RAG pronto para produção que combina o Kit de Desenvolvimento de Agentes do Google com o Vertex IA. O sistema ingere documentos, recupera o contexto relevante por meio de pesquisa híbrida e gera respostas precisas com citações.
Aprimore-o melhorando as estratégias de segmentação, adicionando loops de feedback, integrando fontes de dados adicionais ou habilitando o monitoramento em tempo real. O design modular permite fácil personalização.
Explore fluxos de trabalho avançados de IA e a infraestrutura de IA da Bright Data para obter mais recursos.
Crie uma conta gratuita para começar a construir.





