

Nesta postagem do blog, você verá:
- O que é o Convex, como funciona seu modelo mental e como ele se compara a outros bancos de dados.
- Como ele funciona em detalhes e os componentes principais nos quais se baseia.
- Por que o Convex se destaca quando usado para armazenar dados da web em tempo real.
- Os principais obstáculos e desafios na obtenção de dados em tempo real da web.
- Como a Bright Data ajuda a enfrentar esses desafios, fornecendo dados da web estruturados e em tempo real, prontos para armazenamento no Convex.
- Como começar com uma demonstração completa que combina a Bright Data para recuperação de dados da web e o Convex para armazenamento de dados e atualizações contínuas da interface do usuário.
Vamos começar!
Uma introdução ao Convex
O primeiro passo é explorar o Convex para entender o que ele é, o que ele oferece e o modelo mental central por trás dele.
O que é o Convex?
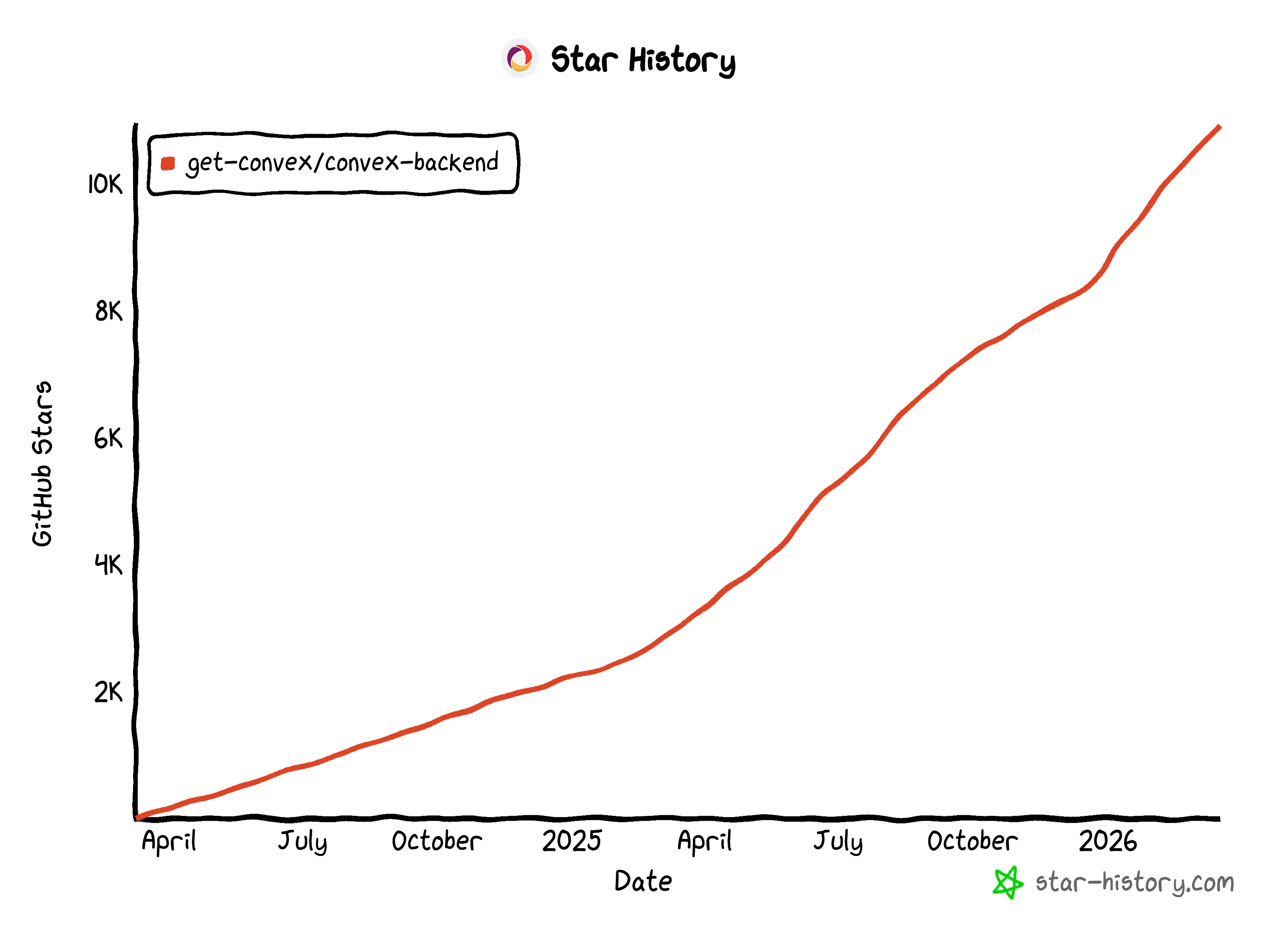
O Convex é uma plataforma de backend reativa e de código aberto projetada para manter seus aplicativos web e móveis sincronizados.
Nos bastidores, ela combina um banco de dados, funções sem servidor, autenticação e bibliotecas de cliente em um único sistema. Assim como os componentes React respondem a mudanças de estado, as consultas do Convex reagem automaticamente às atualizações do banco de dados, tornando-o ideal para aplicativos dinâmicos e em tempo real.
As consultas são escritas em TypeScript e executadas diretamente no banco de dados, simplificando o desenvolvimento e permitindo aplicativos rápidos e reativos com sobrecarga mínima de infraestrutura. A solução também oferece suporte a componentes modulares, sincronização de dados em tempo real, agendamento e geração de código assistida por IA. Ela se integra a frameworks como React, Next.js, Vue, Svelte e Nuxt, além de interoperar com aplicativos em Python, Swift (para iOS), Kotlin (para Android) e Rust.
Sua flexibilidade a tornou popular entre os desenvolvedores, conquistando mais de 10,9 mil estrelas no GitHub e mais de 400 mil downloads semanais no npm.
A ideia central por trás do Convex: compreendendo seu modelo mental
Ao contrário dos bancos de dados tradicionais, o Convex trata o banco de dados como um sistema ativo e reativo, em vez de apenas um armazenamento passivo de dados. Sempre que dados são adicionados, atualizados ou excluídos, a alteração é registrada em um log de transações imutável. Trata-se de um histórico permanente, com registro de data e hora, de todas as operações. Ao mesmo tempo, as consultas não se limitam a buscar dados. Elas rastreiam automaticamente quais partes dos dados foram lidas, conhecidas como seus “conjuntos de leitura”.
Isso permite que o Convex detecte imediatamente quando qualquer um dos dados dos quais uma consulta depende é alterado, permitindo que o sistema atualize os resultados em tempo real. Essa arquitetura suporta assinaturas em tempo real e mantém forte consistência por meio de transações determinísticas e um mecanismo de controle de concorrência otimista. Graças a essas características, vários usuários podem interagir simultaneamente com o banco de dados sem conflitos.
Convex vs. outros bancos de dados
Para entender melhor como o Convex se posiciona em relação a outros bancos de dados populares, consulte a tabela comparativa abaixo:
| Recurso | Convex | Firebase | Supabase | Bancos de dados SQL tradicionais |
|---|---|---|---|---|
| Tipo de banco de dados | Armazenamento de documentos transacional | NoSQL / Firestore | PostgreSQL | SQL relacional |
| Em tempo real | ✔️ (Integrado, assinaturas automáticas) | ✔️ (Integrado) | ➖ (Opcional, via servidor separado) | ❌ (Não nativo) |
| Transações | Sempre transacional | Limitadas | Suportado | Suportado |
| Esquema | Opcional, gradual, gerado automaticamente a partir do TypeScript | Flexível / sem esquema | Obrigatório (Postgres) | Rigoroso, manual |
| Suporte a SQL | ❌ | ❌ | ✔️ | ✔️ |
| Integração com TypeScript | Completa | Limitada | Parcial, no lado do servidor | Depende do ORM |
| Autenticação/OAuth | Padrão + nativo | Padrão + Firebase Auth | Padrão + nativo | Configuração personalizada |
| Responsabilidade pelo banco de dados | Totalmente gerenciada pela Convex | Compartilhada | Compartilhada | Totalmente gerenciada pelo desenvolvedor |
Como a Convex funciona: arquitetura, componentes e fluxo de dados
A arquitetura do Convex é baseada em uma plataforma de back-end full-stack com três componentes principais:
- Banco de dados: Um armazenamento reativo e relacional de documentos, onde objetos do tipo JSON são organizados em tabelas. O banco de dados do Convex é provisionado automaticamente na nuvem para cada projeto, sem necessidade de configuração manual de conexão ou gerenciamento de cluster.
- Funções de servidor: consultas e mutações são escritas como funções TypeScript, eliminando a necessidade de SQL ou ORMs. As consultas são puras e somente leitura, enquanto as mutações são executadas em transações totalmente gerenciadas com garantias ACID, isolamento serializável e controle de concorrência otimista.
- Bibliotecas de cliente: Bibliotecas específicas de frameworks (Next.js, React, Vue, Svelte, etc.) que assinam funções de servidor, sincronizando automaticamente os resultados e gerenciando filas de mutações. Elas garantem atualizações consistentes da interface do usuário em tempo real, sem necessidade de assinatura manual ou gerenciamento de estado.
Com esses três componentes, os dados fluem de forma reativa do banco de dados para o cliente por meio de funções de servidor. As consultas rastreiam automaticamente as dependências, sendo reexecutadas quando os dados mudam e enviando atualizações em tempo real. As mutações são executadas como transações totalmente gerenciadas, atualizando o banco de dados e as consultas dependentes, garantindo que os clientes sempre vejam o estado atualizado sem sincronização manual.
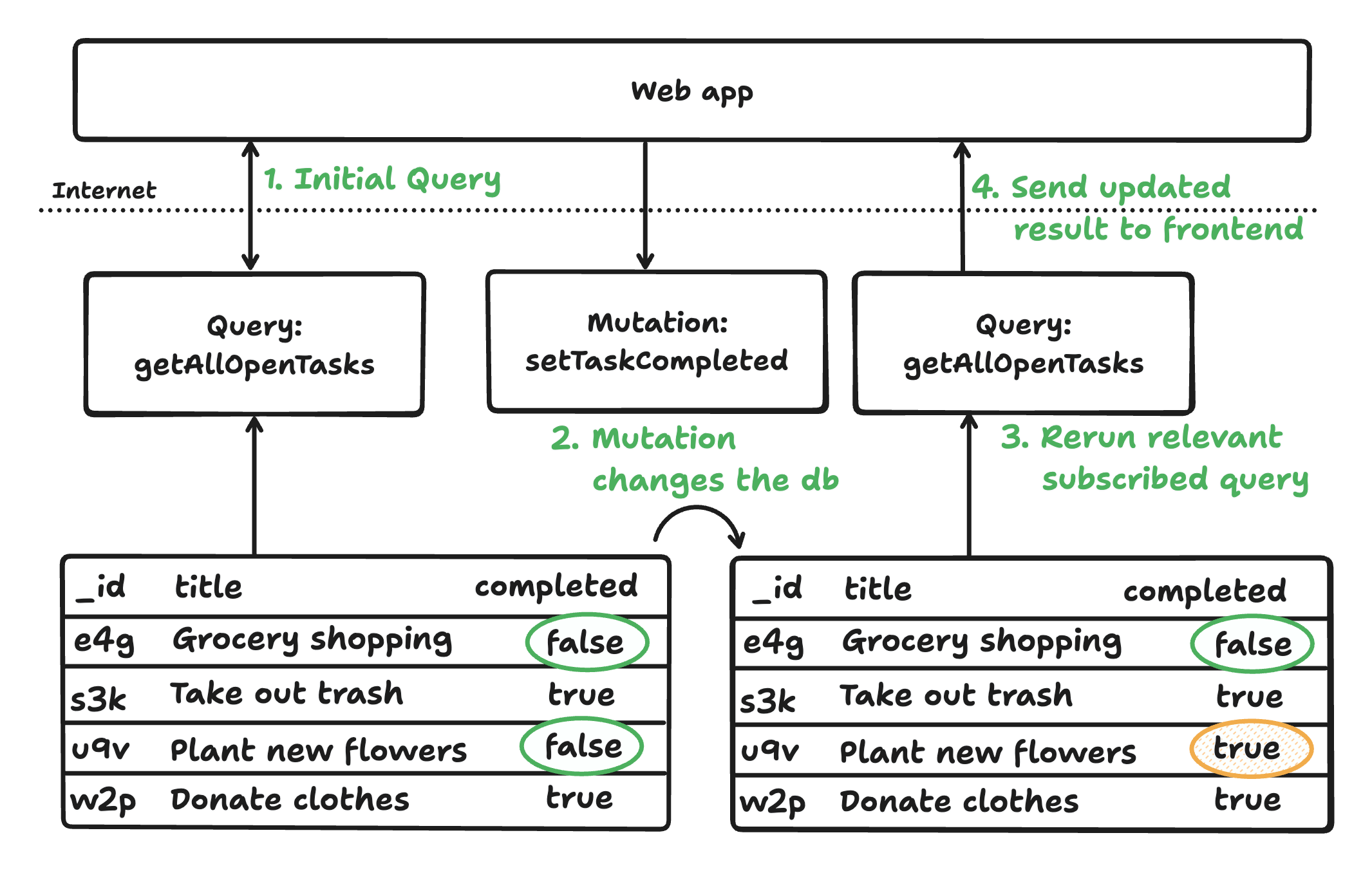
A arquitetura coesa do Convex garante aplicativos reativos, consistentes e seguros em termos de tipos, com o mínimo de código repetitivo. Ela oferece suporte ao desenvolvimento rápido tanto para código gerado por humanos quanto por IA, abstraindo o ajuste e a sincronização do banco de dados. O Convex também oferece autenticação, agendamento e muito mais.
Por que o Convex + Dados da Web em Tempo Real é a Combinação Perfeita
Um banco de dados em tempo real como o Convex só atinge todo o seu potencial quando a própria fonte de dados é em tempo real. Em outras palavras, sua arquitetura reativa é perfeita para aplicações que precisam refletir condições em tempo real (por exemplo, cotações de ações, feeds de redes sociais, atualizações de notícias ou estoques de comércio eletrônico).
Agora, qual é a maior fonte de dados dinâmicos e em constante mudança do planeta? A web! Os dados da web fluem de milhões de fontes em tempo real, tornando-os a entrada ideal para um aplicativo reativo baseado no Convex.
Ao conectar o Convex a fluxos de dados da web em tempo real, seu aplicativo pode reagir imediatamente às atualizações sem poling complexo, sincronização manual ou gerenciamento de estado. Isso elimina a latência entre as informações e a interface do usuário, criando uma experiência de usuário contínua e sempre atualizada.
Desafios na conexão de dados da web a um aplicativo Convex
Agora você entende por que os dados da web em tempo real são uma excelente combinação para uma solução como o Convex. A próxima pergunta é: como você realmente os recupera? A resposta é o Scraping de dados, o processo de extrair informações de páginas da web por meio de programação.
O scraping de dados é uma abordagem poderosa, mas apresenta vários desafios. Estes vão desde obstáculos técnicos até complexidade operacional, incluindo:
- Conteúdo dinâmico: sites modernos dependem de JavaScript, AJAX e padrões complexos de navegação e interação, tornando a extração de dados estruturados mais difícil.
- Medidas anti-bot: muitos sites utilizam CAPTCHAs, limites de taxa, impressões digitais e outras defesas para detectar e bloquear o acesso automatizado.
- Mudanças frequentes: layouts, estruturas HTML e URLs mudam com frequência, prejudicando os Scrapers e exigindo monitoramento e manutenção contínuos.
- Escalabilidade: A coleta de dados em grande escala exige uma infraestrutura sólida, integração com um provedor de Proxy confiável para rotação de IPs e um tratamento robusto de erros.
- Consistência dos dados: garantir precisão, integridade e atualidade é um desafio, especialmente para dados atualizados com frequência.
Como resultado, construir um aplicativo Convex totalmente reativo com base em dados da web é uma tarefa assustadora. Em vez de lidar com esses obstáculos sozinho, a abordagem perfeita é contar com um provedor de dados da web em tempo real pronto para uso corporativo, como a Bright Data.
Bright Data + Convex para aplicativos reativos baseados em dados da web em tempo real
Ao desenvolver aplicativos reativos alimentados por dados da web em tempo real, a combinação da Bright Data com o Convex se destaca. Juntos, eles criam uma separação clara de responsabilidades: a Bright Data se concentra na coleta de dados em grande escala, enquanto o Convex lida com a sincronização de estado em tempo real e as atualizações da interface do usuário.
A Bright Data permite que você pesquise e extraia informações da web em tempo real de forma programática. Os dados coletados são retornados como JSON estruturado, que pode ser facilmente importado para o Convex. Este, então, se encarregará de propagá-los instantaneamente a todos os clientes conectados por meio de consultas reativas.
O que torna a Bright Data particularmente atraente é sua infraestrutura de nível empresarial. Ela opera em uma das maiores redes de Proxy do mundo, com mais de 150 milhões de IPs em 195 países, alcançando concorrência ilimitada. Essa base oferece alta confiabilidade, com 99,99% de tempo de atividade, uma taxa de sucesso de 99,95% e suporte 24 horas por dia, 7 dias por semana.
Todas as soluções de recuperação de dados em tempo real da Bright Data são construídas sobre essa infraestrutura. As principais ofertas incluem:
- APIs Scraper: Endpoints de API prontos para uso para extrair dados estruturados em tempo real de sites populares.
- API Unlocker: lida automaticamente com CAPTCHAs, mecanismos de bloqueio e sistemas anti-bot, dando a você acesso ao conteúdo de páginas desbloqueadas.
- API SERP: fornece resultados de pesquisa em tempo real de vários mecanismos, com tempos de resposta de latência inferior a um segundo.
- API de rastreamento: converte sites inteiros em Conjuntos de dados estruturados.
A configuração da Convex + Bright Data permite um fluxo contínuo de dados atualizados da web para seus usuários, sem a sobrecarga operacional típica do Scraping de dados. O resultado é um sistema escalável, sustentável e totalmente reativo, construído com base em dados da web em tempo real.
Exemplo de arquitetura
Abaixo está um exemplo da arquitetura para um aplicativo web ou móvel reativo construído com o Convex, com dados da web em tempo real fornecidos pela Bright Data:
- Acionando a recuperação de dados (Bright Data): Quando um usuário realiza uma ação específica (por exemplo, clicar em um botão), o front-end envia uma solicitação ao seu back-end. O servidor então chama uma API da Bright Data para buscar dados atualizados da web. Os dados coletados podem ser preços de produtos, artigos de notícias, listas de vagas de emprego, etc.
- Processamento de back-end (Convex): Assim que os dados JSON estruturados são recebidos, eles são passados para o Convex por meio de uma mutação. Nesta etapa, os dados são capturados, normalizados, validados e armazenados no banco de dados do Convex. Você também pode enriquecer ou transformar os dados aqui com base na lógica do seu aplicativo.
- Atualizações da interface do usuário em tempo real (reatividade do Convex): O front-end assina as consultas no Convex. Assim que o banco de dados é atualizado, as consultas relevantes são executadas automaticamente. Os resultados atualizados são enviados instantaneamente ao cliente, e a interface do usuário é atualizada em tempo real sem qualquer intervenção manual.
Como construir um terminal de pesquisa de mercado com IA em tempo real usando o Convex e a Bright Data
Para ilustrar as possibilidades oferecidas pela integração Convex + Bright Data, vamos considerar uma demonstração do mundo real: o Terminal de Pesquisa de Mercado com IA da Bright Data.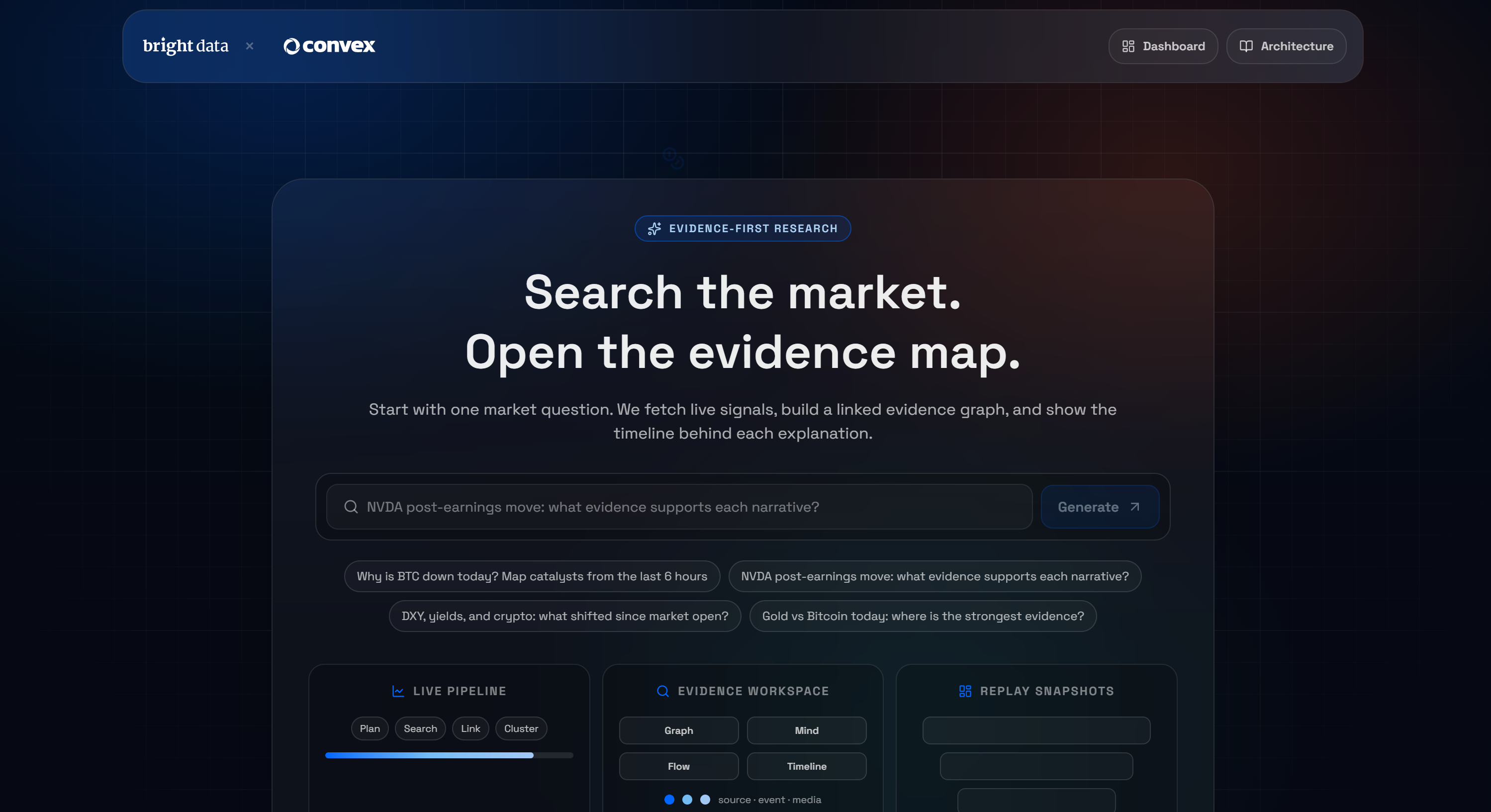
Trata-se de um aplicativo Next.js construído no Convex que permite fazer uma pergunta e receber um gráfico de evidências em tempo real, extraído por Scraping de dados. Se você não está familiarizado com esse conceito, um gráfico de evidências é uma representação estruturada que mostra as relações entre dados, alegações e evidências de apoio.
Nos bastidores, o aplicativo segue um fluxo de trabalho que consiste em oito etapas:
- Plano: Um LLM cria de 4 a 6 consultas de pesquisa focadas com base no seu tópico.
- Pesquisa: Envia de 4 a 6 solicitações da API SERP da Bright Data simultaneamente.
- Rastreamento: extrai os principais URLs para o Markdown usando a API Web Unlocker da Bright Data.
- Extração: Combina trechos da SERP e Markdown em itens de evidência estruturados.
- Resumos: O LLM extrai os principais pontos-chave, entidades, catalisadores e sentimentos para cada item.
- Artefatos: Cria nós e arestas no gráfico de conhecimento com pontuações de confiança.
- Link: Aplica enriquecimento heurístico, incluindo correções de conectividade, marcação de domínios e eventos de fita.
- Renderizar → Pronto: Transmite os artefatos finais para o cliente enquanto mantém a sessão no Convex.
É hora de explorar esta demonstração e testá-la localmente! Veja como uma aplicação real do Convex + Bright Data coleta, processa e entrega dados da web em tempo real em um fluxo de trabalho reativo.
Pré-requisitos
Para acompanhar esta seção do tutorial, certifique-se de ter:
- Node.js 20+ instalado localmente.
- Uma chave de API do OpenRouter.
- Uma conta Bright Data com as zonas SERP e Web Unlocker configuradas.
- Um projeto Convex configurado (o plano gratuito é suficiente).
- Git instalado localmente.
Não se preocupe em configurar o Bright Data e o Convex por enquanto. Você será orientado sobre ambos em dois subcapítulos dedicados.
Passo 1: Prepare sua conta Bright Data
Conforme mencionado na introdução, o aplicativo de demonstração depende de dois produtos da Bright Data:
- API SERP
- API Web Unlocker
Abaixo, você será orientado sobre como configurá-los em sua conta. Para instruções mais detalhadas, você também pode consultar a documentação oficial da Bright Data:
Se você ainda não tem uma conta, crie uma. Caso contrário, faça login. Após o login, acesse a página “Proxies & Scraping” no painel de controle. Na seção “Minhas Zonas”, procure uma linha intitulada “API SERP” e outra para “API Web Unlocker”: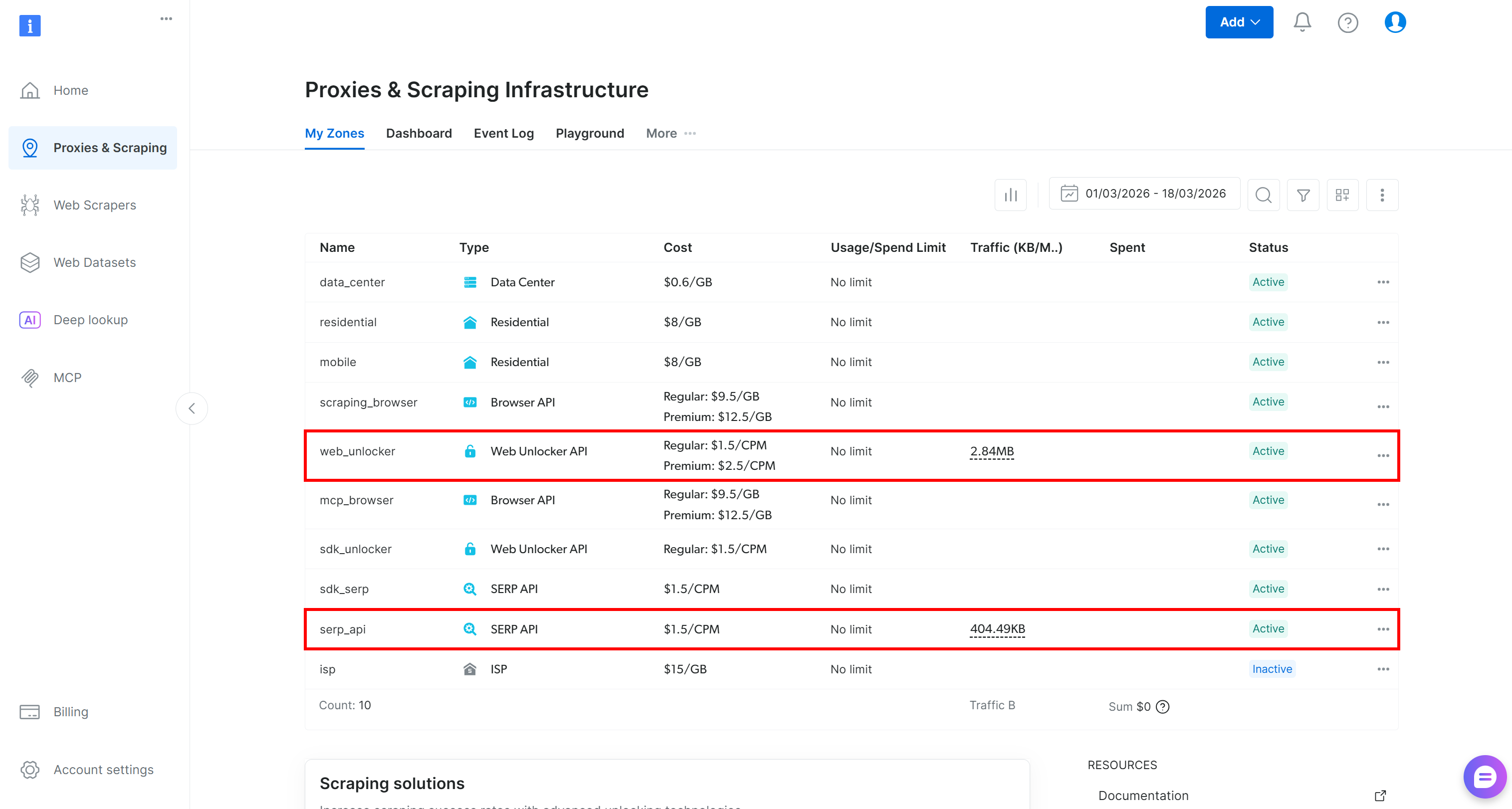
Se alguma das linhas estiver faltando, isso significa que a zona correspondente ainda não foi configurada. Por exemplo, para criar uma zona da API SERP, role a página até a seção “API SERP” e clique em “Criar zona”: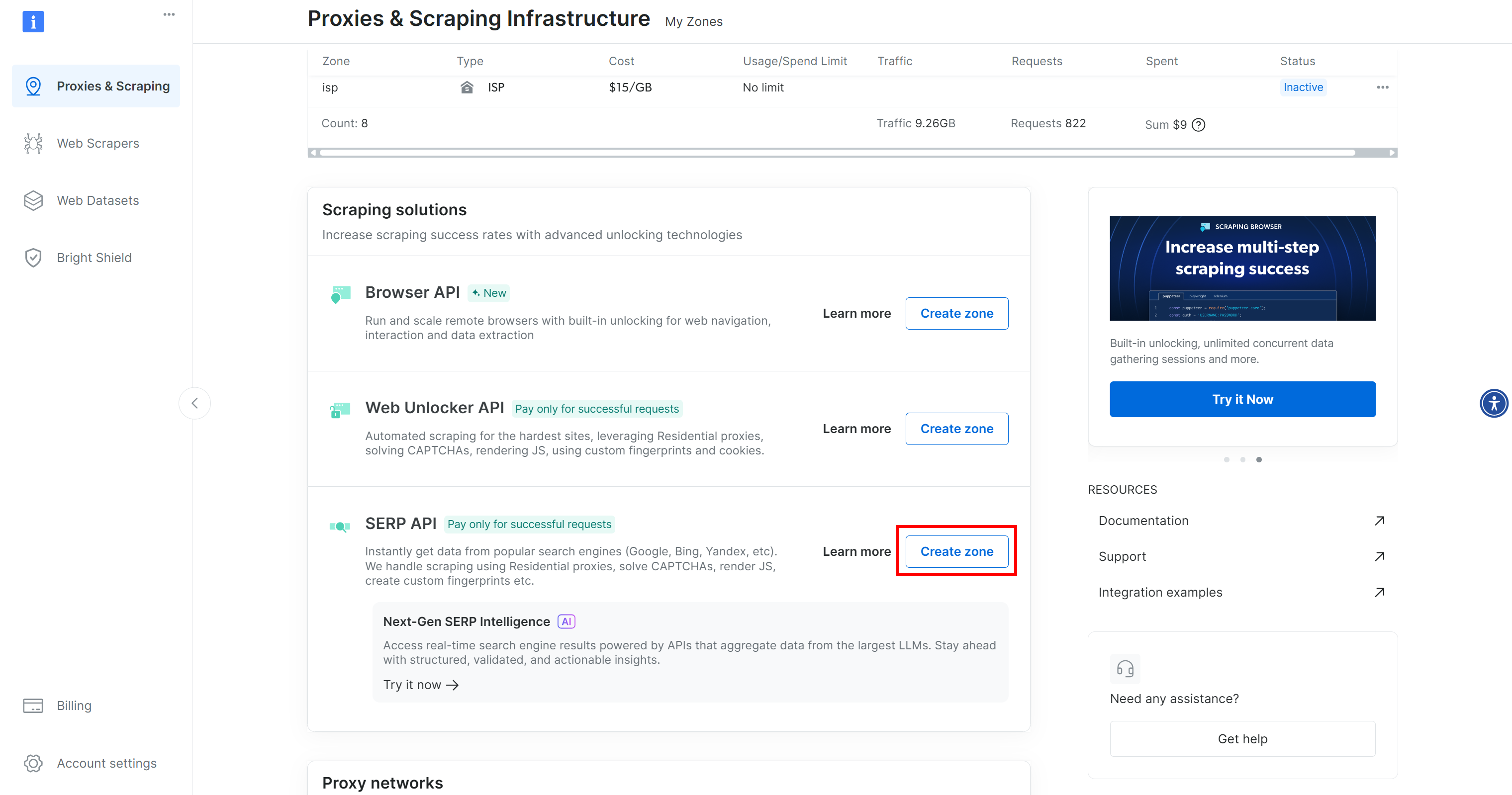
Crie uma zona API SERP e dê a ela um nome, como serp_api (ou qualquer nome de sua preferência). Anote o nome da zona, pois você precisará dele mais tarde.
Repita o mesmo processo para a Web Unlocker API. Para este tutorial, vamos supor que sua zona Web Unlocker se chama web_unlocker.
Por fim, siga o tutorial oficial para gerar sua chave de API da Bright Data. Guarde-a em local seguro, pois ela será necessária para autenticar as solicitações de API do aplicativo Next.js com tecnologia Convex para a API SERP e o Web Unlocker.
Ótimo! Sua conta Bright Data agora está totalmente configurada e pronta para ser integrada à demonstração do Terminal de Pesquisa de Mercado IA.
Passo 2: Configure sua conta Convex
Comece fazendo login no Convex ou crie uma nova conta, caso ainda não tenha feito isso. Você chegará ao seu painel do Convex:
Aqui, clique no botão “Criar projeto”. Nomeie seu projeto como “Terminal de Pesquisa de Mercado de IA” (ou qualquer nome de sua preferência) e clique em “Criar”: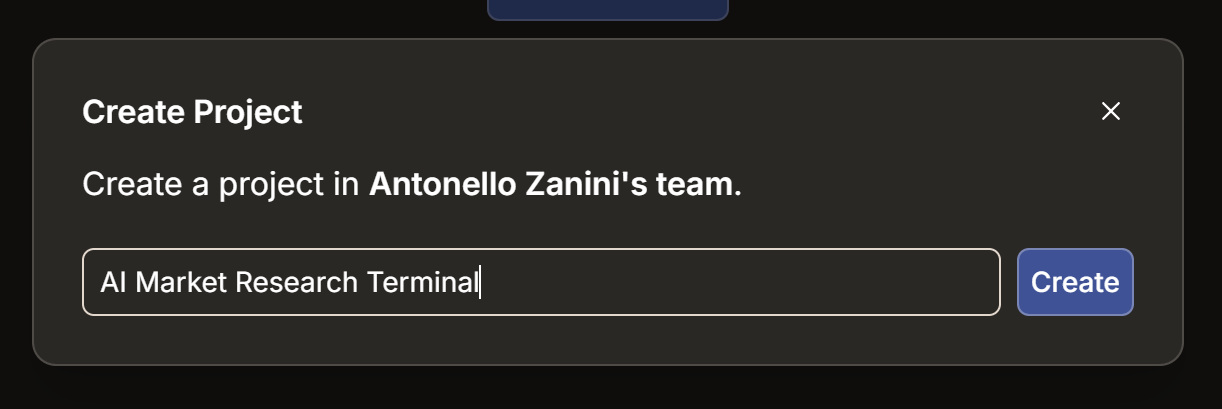
Aguarde a inicialização do projeto e, em seguida, selecione uma região de implantação: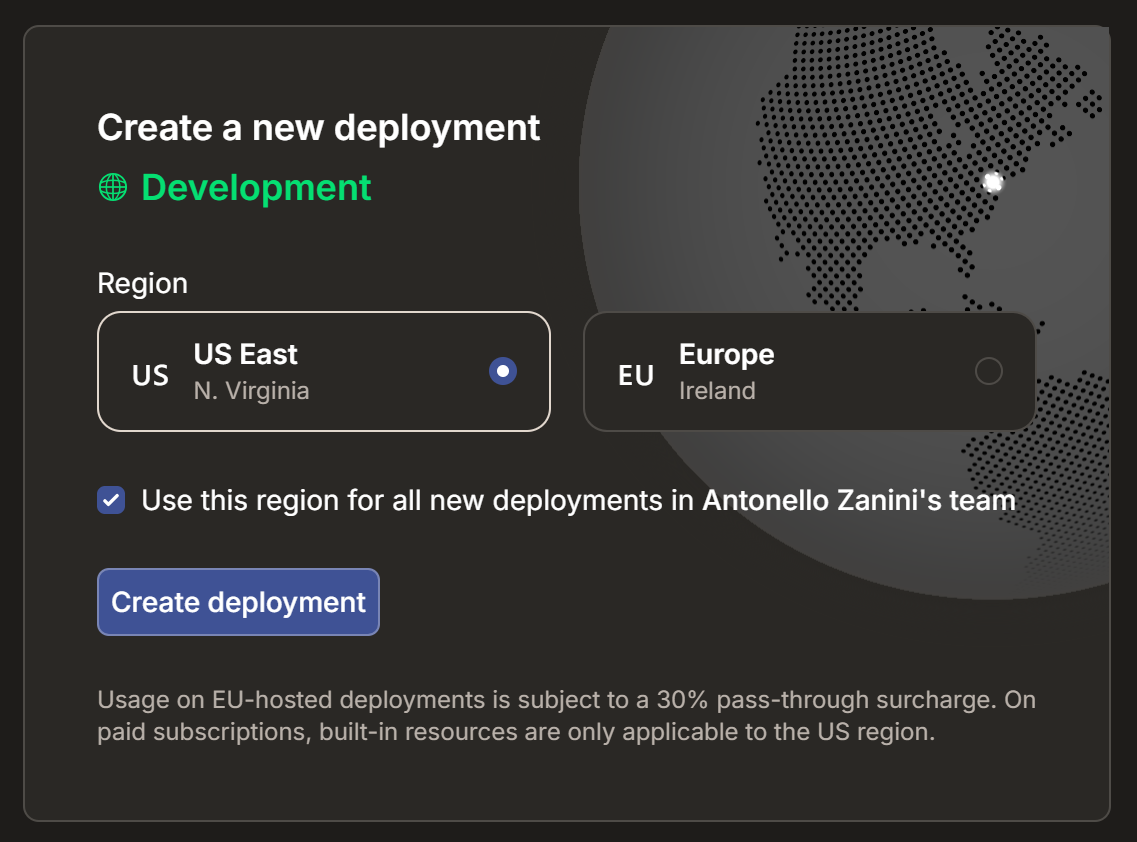
Confirme clicando em “Configurar Implantação”. Após alguns segundos, seu projeto deverá estar pronto: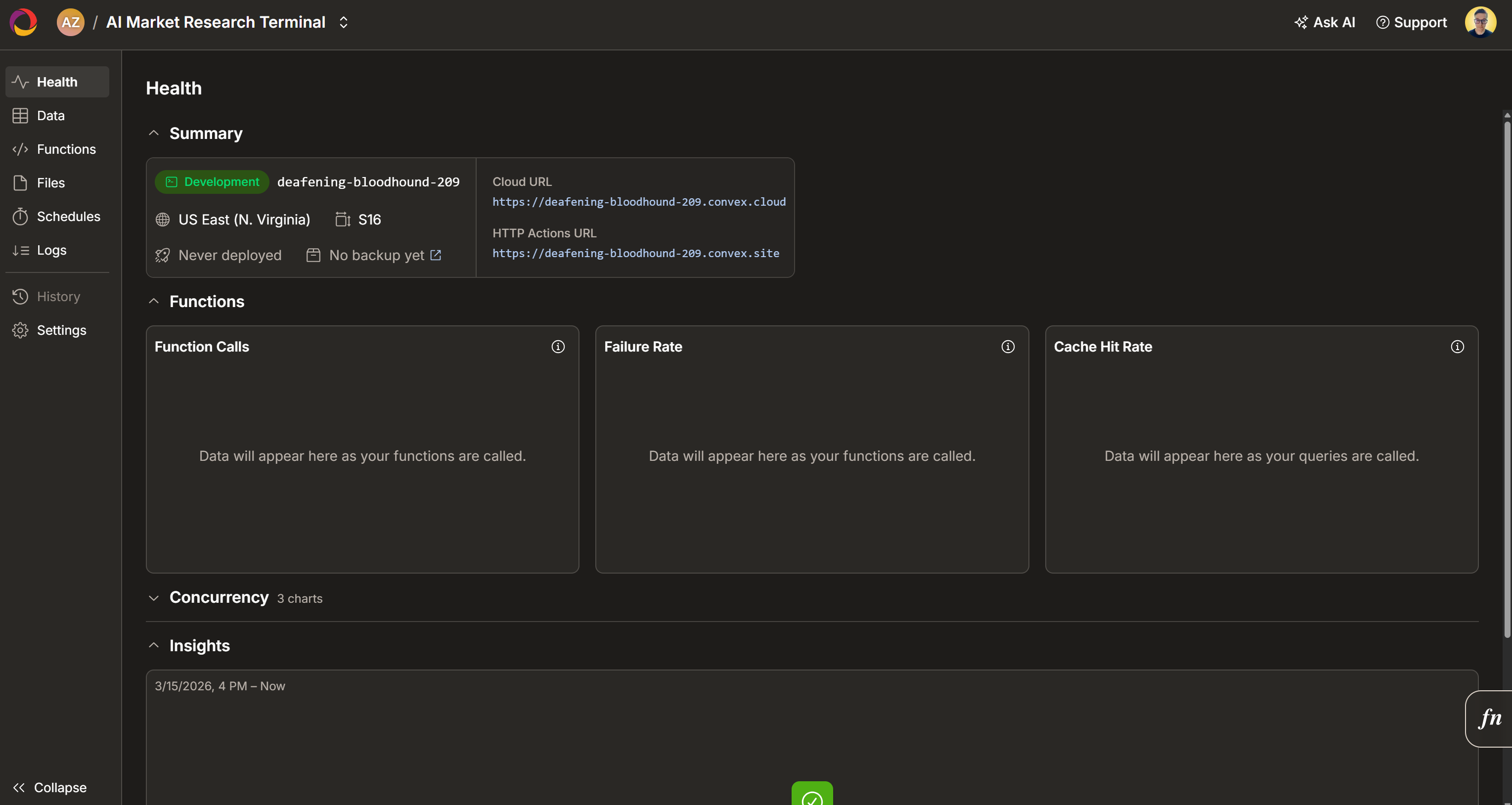
Ótimo! Agora você tem todos os componentes necessários para clonar e executar o projeto localmente.
Etapa 3: Configurar o projeto
Comece clonando o repositório de demonstração em uma pasta local chamada ai-market-research-terminal/:
git clone https://github.com/brightdata/market-terminal ai-pesquisa-de-mercado-terminalSua pasta de projeto do IA-Pesquisa de mercado deve agora conter todos os arquivos listados no repositório oficial.
Navegue até o diretório do projeto:
cd ai-pesquisa de mercado-terminalEm seguida, instale as dependências do projeto:
npm installÓtimo! Agora você pode abrir o projeto em seu IDE de JavaScript favorito, como o Visual Studio Code. Explore-o e familiarize-se com ele para ver como funciona. Para mais informações e detalhes dos bastidores, leia o artigo aprofundado dedicado no DEV.
Etapa 4: Configure o aplicativo
O aplicativo lê toda a sua configuração a partir de um arquivo .env.local. O repositório inclui um arquivo de exemplo chamado .env.local.example. Copie-o para criar seu próprio arquivo .env.local:
cp .env.local.example .env.local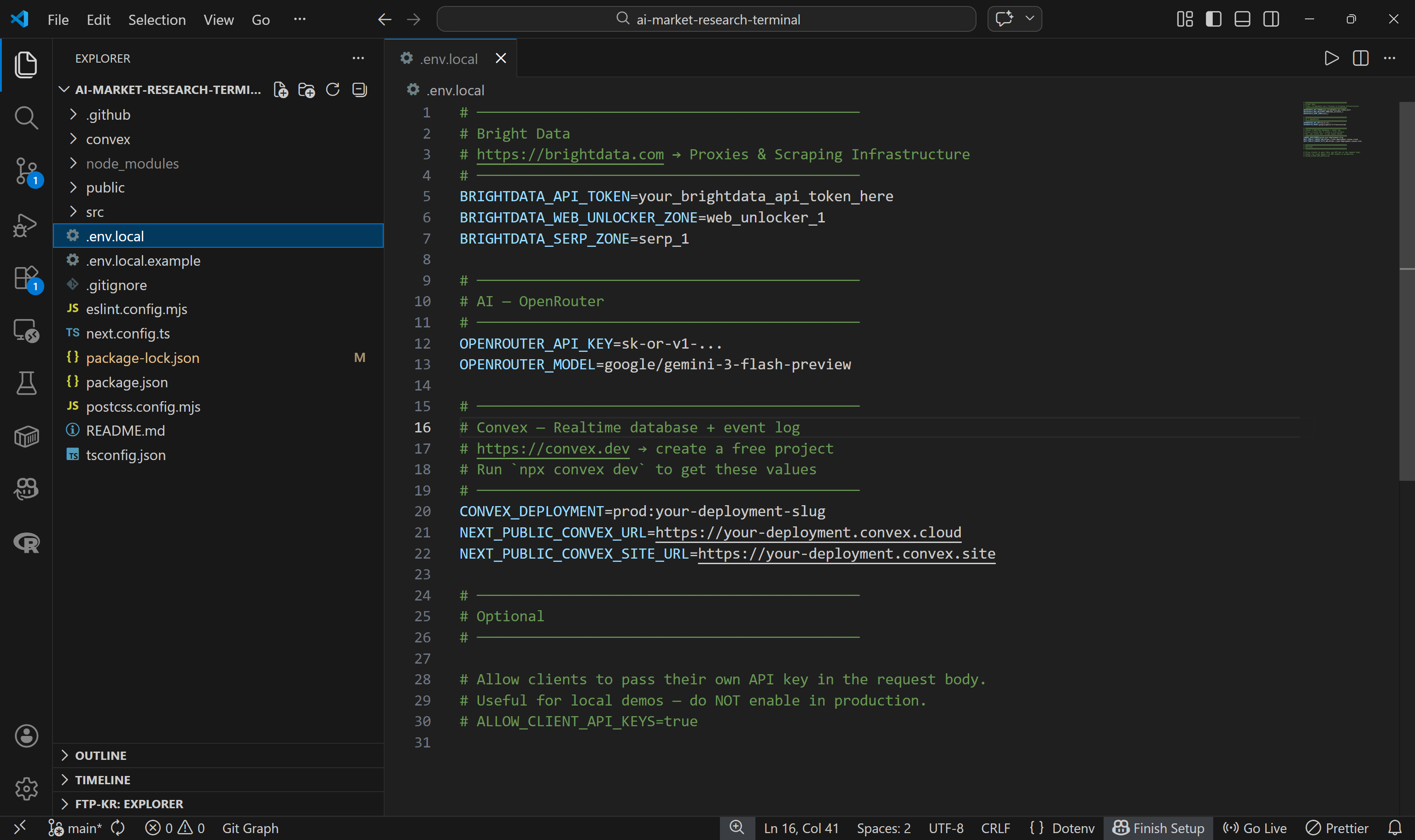
Em seguida, configure o conector Convex executando o seguinte comando na pasta raiz do seu projeto:
npx convex devSiga as instruções e conecte seu dispositivo à sua conta Convex no navegador. Em seguida, selecione o projeto “IA Pesquisa de mercado” existente que você criou na etapa #2. O Convex atualizará automaticamente seu arquivo .env.local com as variáveis de ambiente necessárias. Neste caso, ele adicionará:
CONVEX_DEPLOYMENT=dev:deafening-bloodhound-209
NEXT_PUBLIC_CONVEX_URL=https://deafening-bloodhound-209.convex.cloud
NEXT_PUBLIC_CONVEX_SITE_URL=https://deafening-bloodhound-209.convex.siteEsses valores permitem que seu aplicativo se conecte ao seu projeto Convex.
Por padrão, duas novas tabelas (sessionEnvts e session) serão adicionadas ao seu projeto Convex: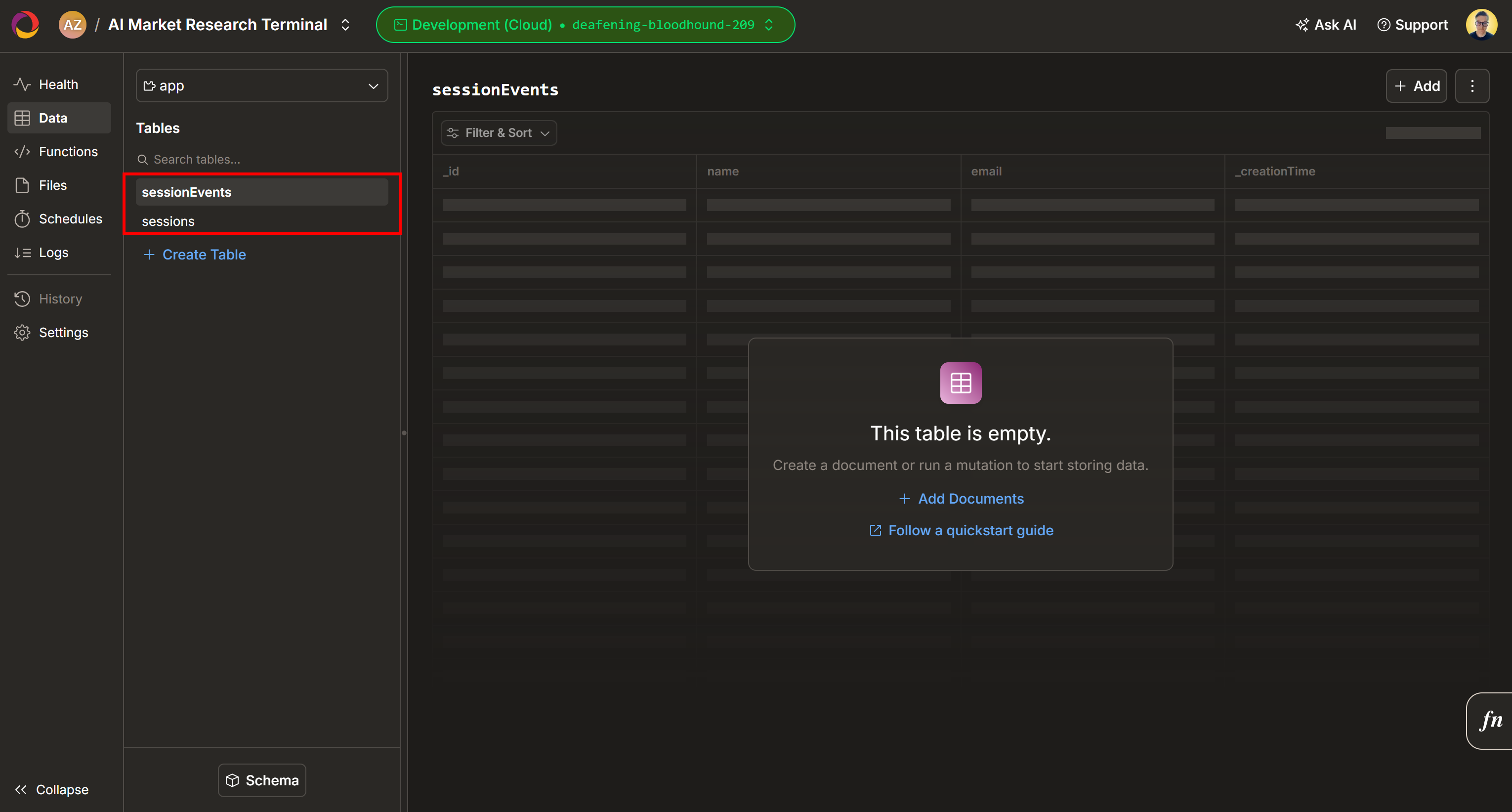
Em seguida, preencha as variáveis de ambiente restantes no arquivo .env.local:
BRIGHTDATA_API_TOKEN=<SUA_CHAVE_API_BRIGHTDATA>
BRIGHTDATA_WEB_UNLOCKER_ZONE=<NOME_DA_API_WEB_UNLOCKER_BRIGHTDATA> # por exemplo, "web_unlocker"
BRIGHTDATA_SERP_ZONE=<SEU_NOME_DA_API_SERP_DA_BRIGHTDATA> # por exemplo, "serp_api"
OPENROUTER_API_KEY=<SUA_CHAVE_DA_API_OPENROUTER>
OPENROUTER_MODEL=google/gemini-3-flash-previewSubstitua os espaços reservados pelo seu token da API da Bright Data, nome da zona do Web Unlocker, nome da zona da API SERP e chave da API do OpenRouter. Observe que o LLM padrão é o Gemini 3 Flash, mas você pode usar qualquer outro modelo compatível, se preferir.
Ótimo! Sua demonstração agora está totalmente configurada e pronta para ser executada localmente.
Etapa 5: Execute o aplicativo localmente
Inicie a demonstração localmente com:
npm run devAbra http://localhost/market-terminal no seu navegador para acessar o aplicativo local IA Pesquisa de mercado Terminal. Você deverá ver: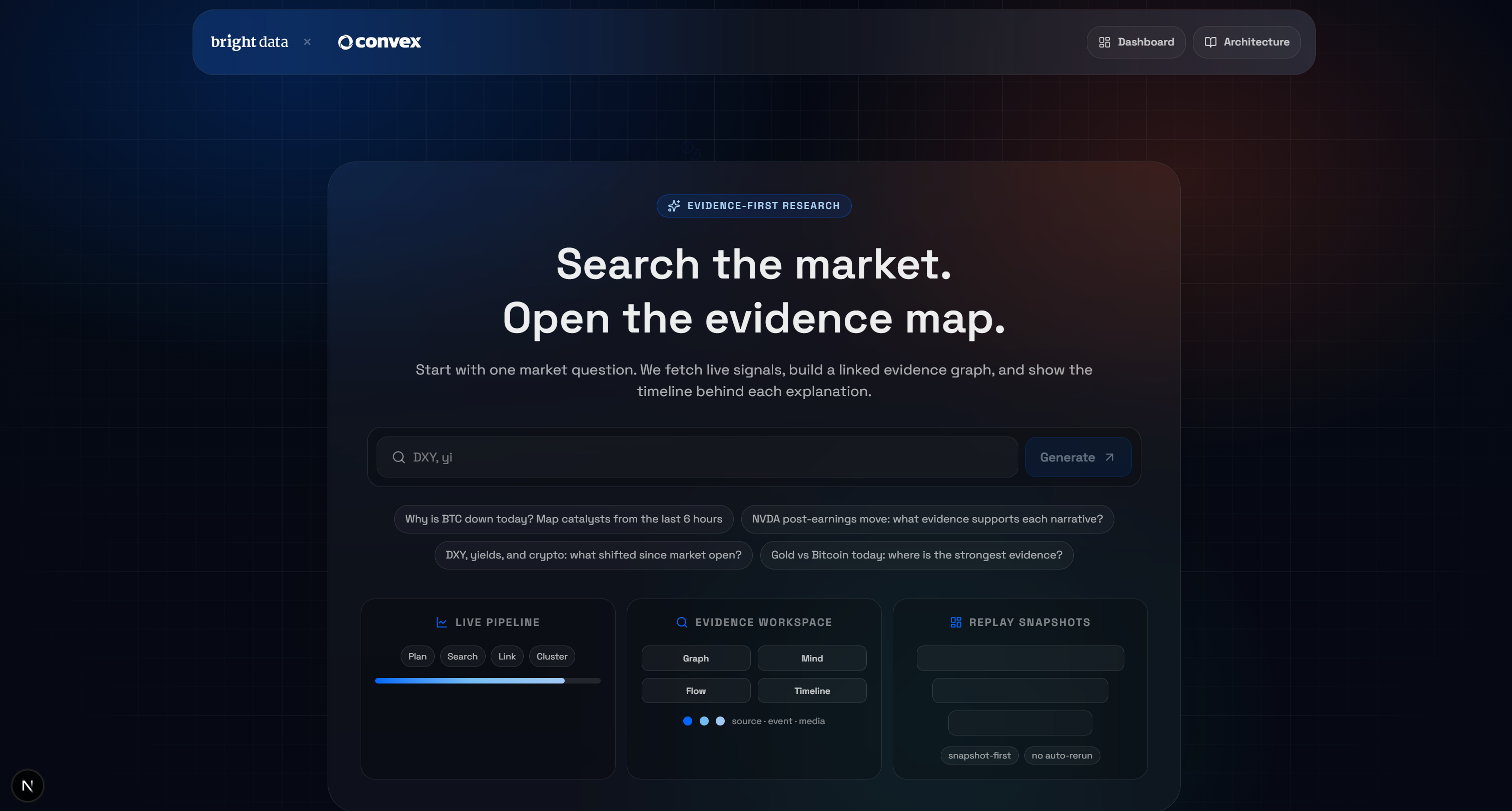
Teste o aplicativo inserindo uma consulta, por exemplo:
Por que o BTC está em baixa hoje?Clique no botão “Gerar” e você receberá um resultado como este: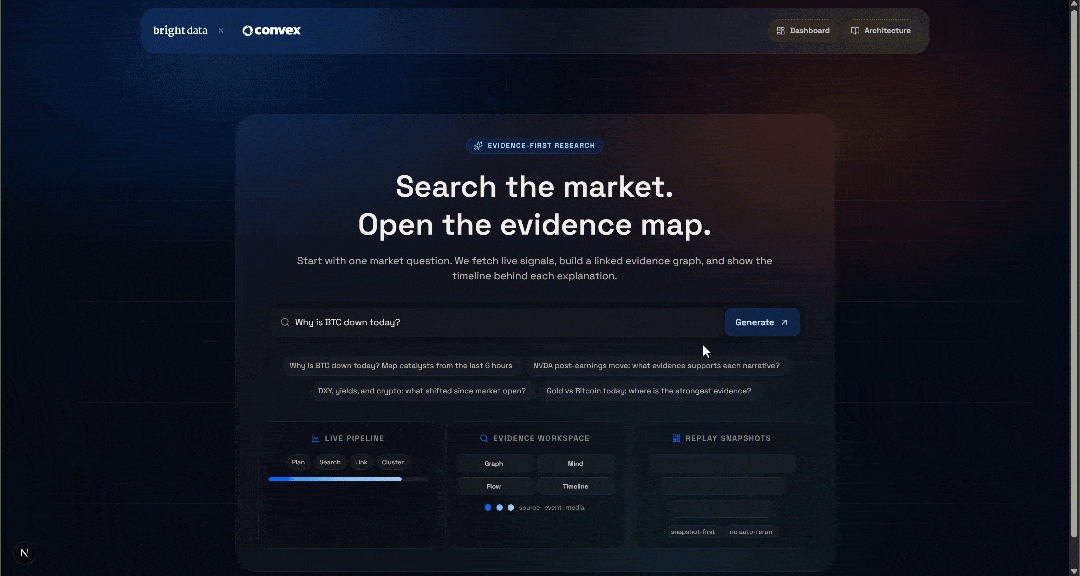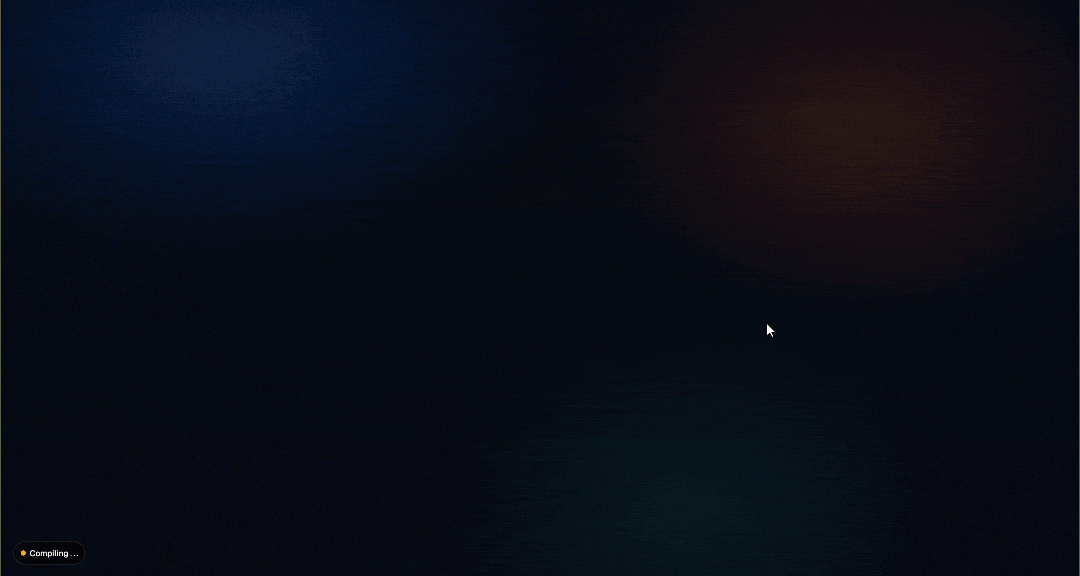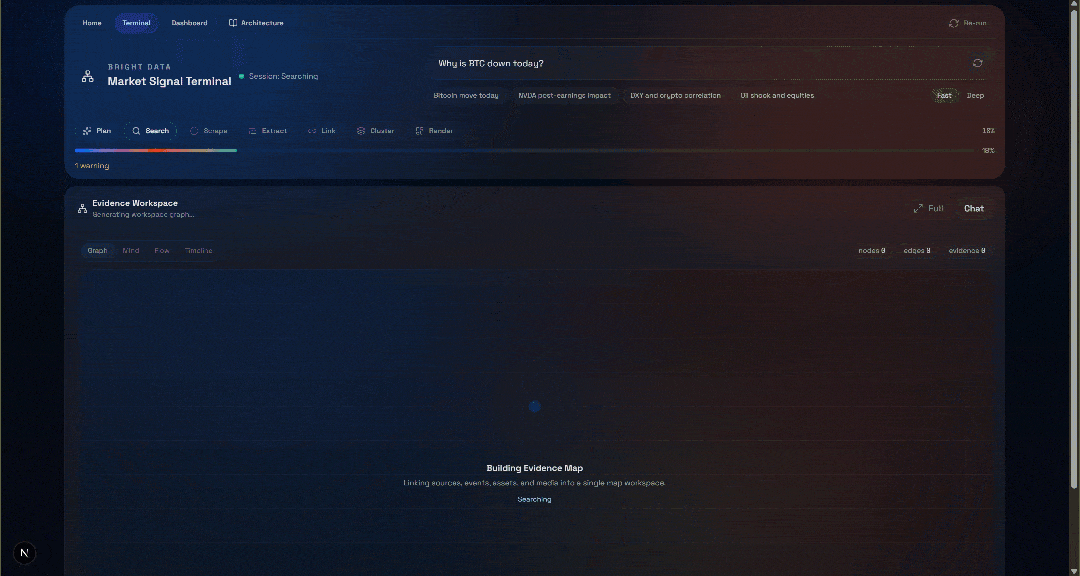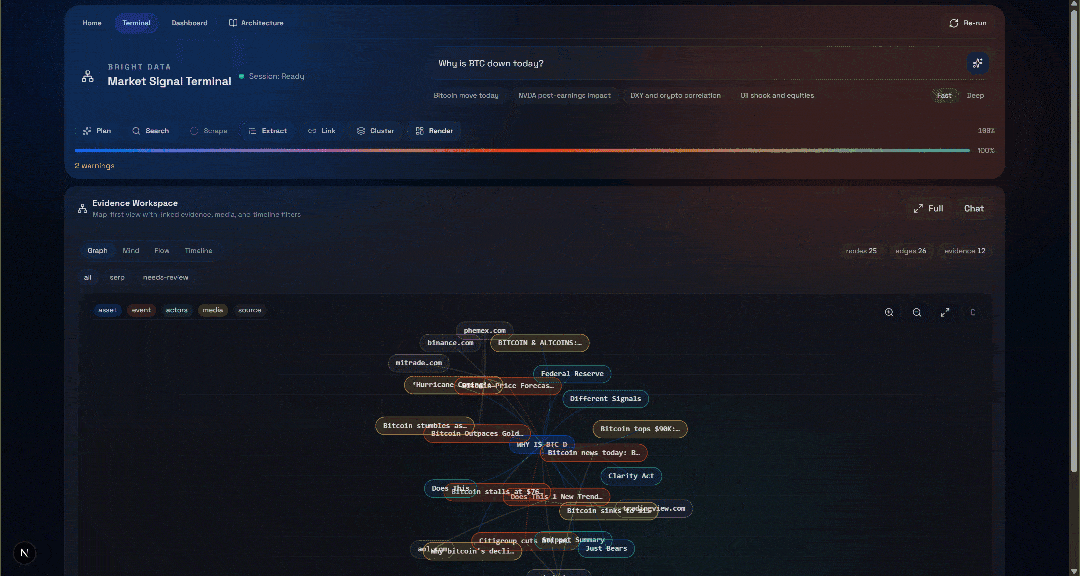
Agora, confira a seção “Espaço de Trabalho de Evidências”. Essa visualização contém todos os dados recuperados em tempo real por meio do Scraping de dados, agregados, processados e armazenados no Convex. Seu banco de dados Convex agora conterá os dados desta execução: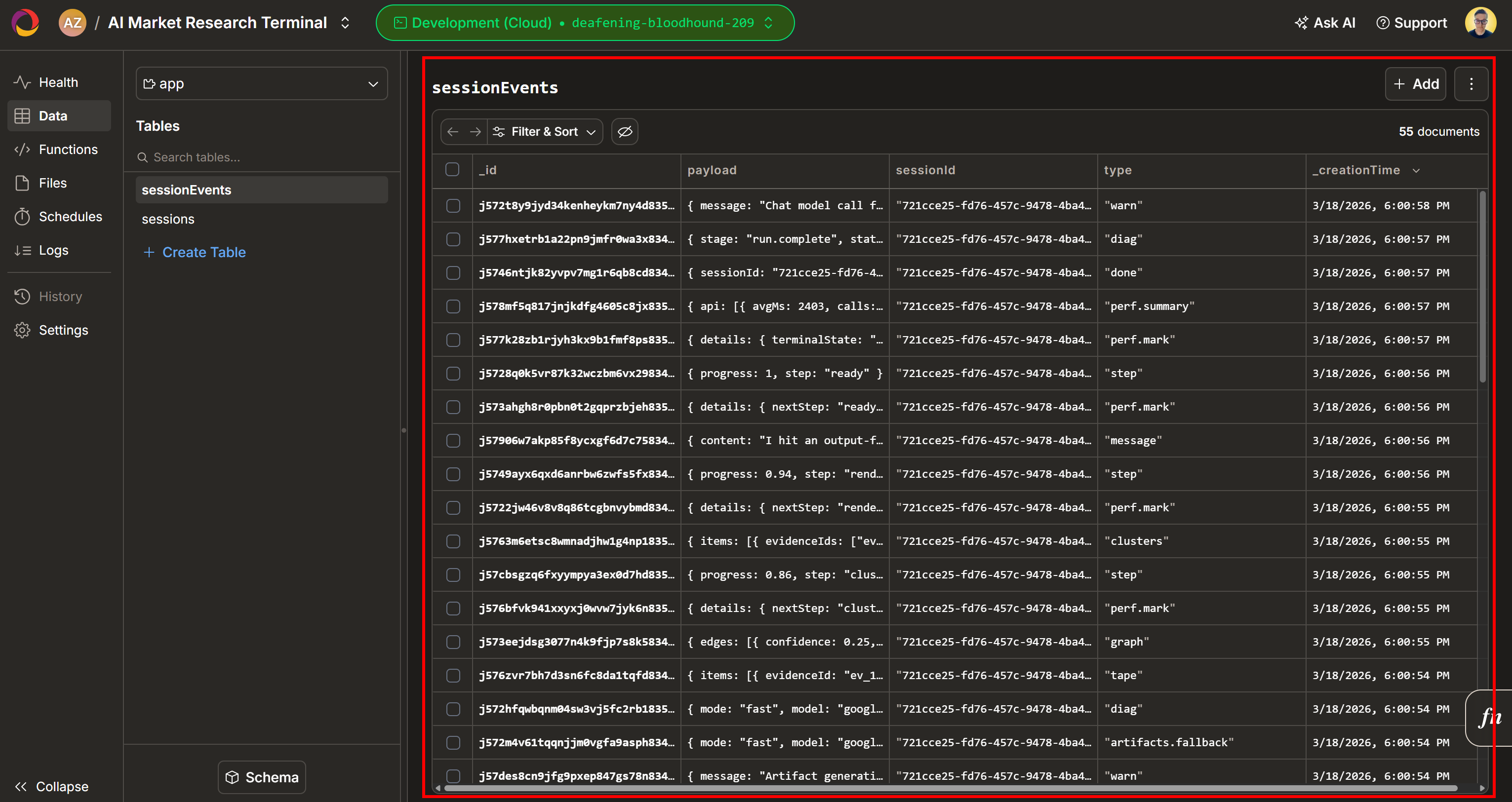
Em seguida, explore as visualizações “Gráfico”, “Mente”, “Fluxo” e “Linha do tempo”: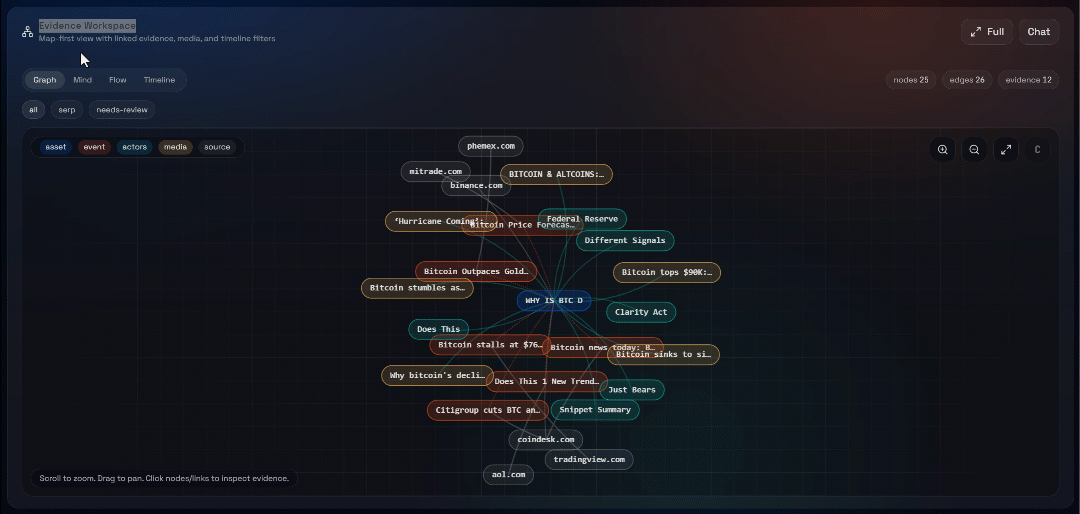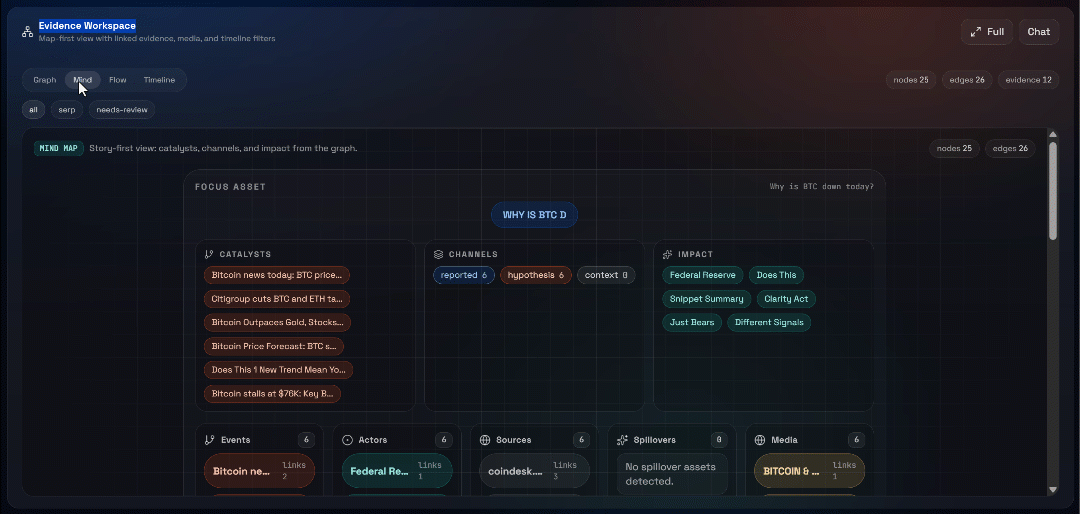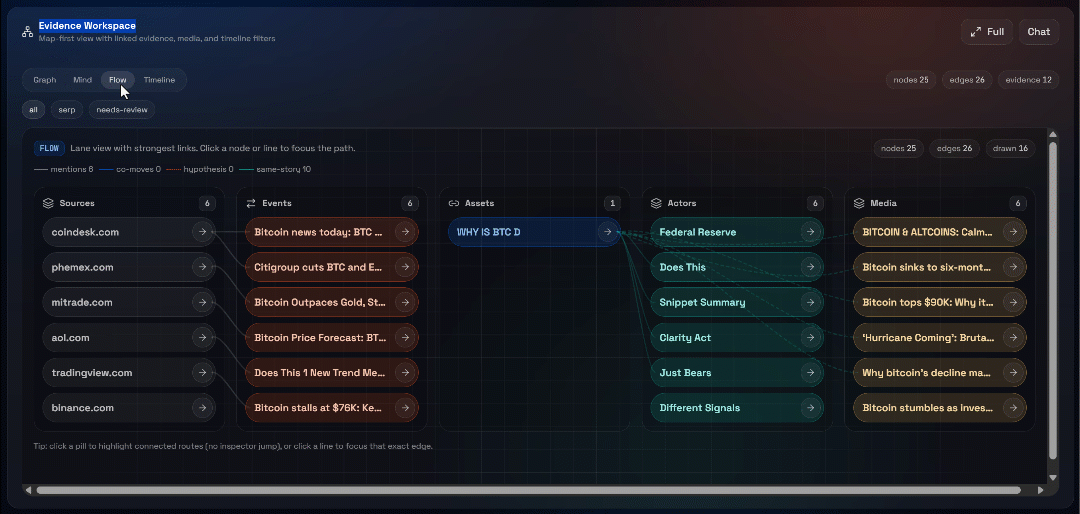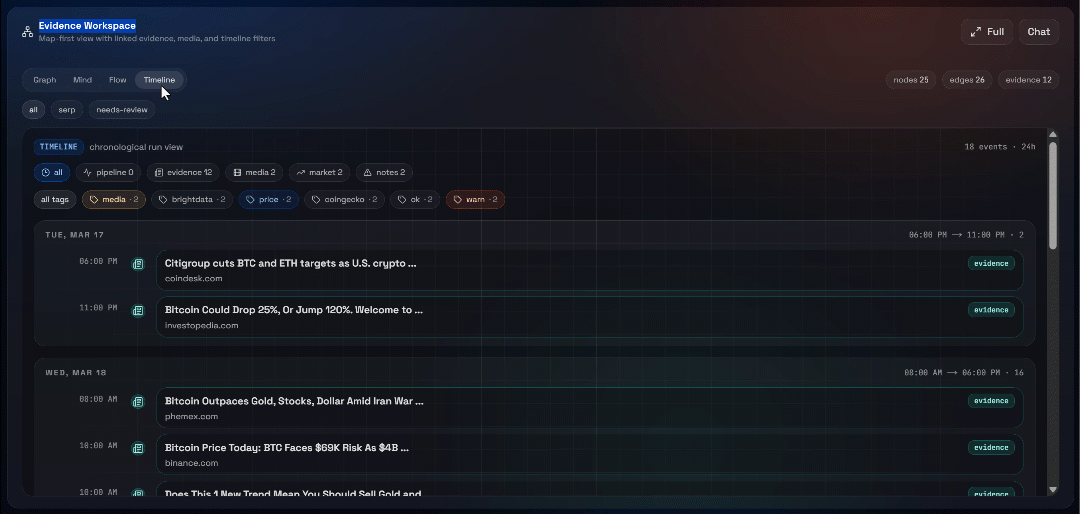
Aqui você pode ver as fontes recuperadas, filtrá-las e explorar os dados mais a fundo para obter insights mais detalhados.
Et voilà! Agora você tem um aplicativo IA de Pesquisa de mercado totalmente funcional, desenvolvido pela Bright Data com o Convex como banco de dados de back-end. É um aplicativo ao vivo e reativo que traz dados da web em tempo real diretamente para o seu espaço de trabalho.
Conclusão
Neste artigo, você aprendeu o que é o Convex, como ele funciona e como ajuda a alimentar aplicativos reativos. Essa solução se torna ainda mais poderosa quando usada para armazenar dados atualizados, extraídos ao vivo da web.
A Bright Data permite o Scraping de dados da web em tempo real por meio de uma infraestrutura de nível empresarial. Isso serve de base para uma ampla gama de serviços de Scraping de dados da web, permitindo que você colete dados da web de forma rápida e confiável, sem ser bloqueado.
Inscreva-se hoje mesmo na Bright Data gratuitamente e explore nossas soluções de coleta de dados da web em tempo real!






