

O Tableau é uma ferramenta líder em visualização de dados, mas tem uma grande limitação. Ele não consegue extrair dados em tempo real de sites de forma confiável por conta própria. O antigo Web Data Connector (WDC v2), que antes resolvia isso, foi descontinuado em 2023. Sua última versão compatível (Tableau 2022.4) chegou ao fim de vida útil, deixando os analistas sem uma solução compatível.
Este guia compara seis métodos para Scraping de dados e conexão de dados em tempo real ao Tableau. Ele também inclui um tutorial passo a passo para construir um pipeline de API para Tableau usando a API Web Scraper da Bright Data.
Resumo
O Tableau não consegue fazer Scraping de dados de forma nativa, e seu Web Data Connector (WDC v2) foi descontinuado em 2023. Você precisa de um pipeline de dados externo.
- O WDC v2 foi descontinuado; o WDC v3 é apenas para extração e complexo de construir
- O Google Sheets, o Excel e o TabPy têm, cada um, limitações críticas em escala
- Scripts Python DIY funcionam inicialmente, mas exigem manutenção constante
- Uma API de extração gerenciada lida com Proxies, CAPTCHAs e Parsing de dados automaticamente
Siga o tutorial passo a passo deste guia para construir um pipeline funcional Amazon → Bright Data → Tableau.
Por que o Tableau precisa de um pipeline de dados externo
A pilha de dados moderna requer dados da web em tempo real: preços da concorrência, métricas de redes sociais, anúncios de emprego, listagens imobiliárias e feeds financeiros. O Tableau não foi projetado para coletá-los.
Os principais desafios são:
- Os sites mudam constantemente – layouts mudam, medidas anti-bot evoluem, requisitos de renderização de JavaScript aumentam
- A escala é crítica – monitorar 10.000 SKUs de concorrentes diariamente requer lógica de repetição de tentativas, limitação de taxa e tratamento de falhas que um script de página única não precisa
- A conformidade é obrigatória – o GDPR, a CCPA e os termos das plataformas exigem práticas cuidadosas de coleta de dados
- A infraestrutura é cara – Proxy rotativo, Resolução de CAPTCHA, lógica de repetição de tentativas e gerenciamento de IP são desafios contínuos de engenharia
Os métodos a seguir preenchem essa lacuna.
6 métodos para Scraping de dados e conexão de dados em tempo real ao Tableau
Cada método equilibra escala, manutenção e confiabilidade de maneira diferente. Eles estão listados do menos viável ao mais pronto para produção.
Método 1: Tableau Web Data Connector v2 (obsoleto)
O que era: o WDC v2 permitia criar conectores baseados em JavaScript que extraíam dados de APIs da web diretamente para o Tableau.
Por que não funciona mais: Descontinuado no Tableau 2023.1. Os conectores WDC v2 não são mais suportados em todas as versões atuais do Tableau, e o Tableau pode removê-los completamente em uma versão futura. A migração para o WDC v3 é necessária, mas o v3 possui uma arquitetura fundamentalmente diferente.
Limitação crítica: O suporte foi encerrado. Se você ainda estiver usando conectores WDC v2, migre agora, pois eles podem parar de funcionar em qualquer atualização futura do Tableau.
Método 2: Google Sheets como camada intermediária
Como funciona: extraia dados para o Google Sheets (por meio do Apps Script, IMPORTXML, IMPORTDATA ou ferramentas de terceiros) e, em seguida, conecte o Tableau ao Sheets como uma fonte de dados em tempo real.
Por que usar: É gratuito, não requer programação e o Tableau se conecta ao Google Sheets por meio de seu conector do Google Drive.
Limitações críticas:
- O Google Sheets tem um limite de 10 milhões de células – Conjuntos de dados grandes atingem esse limite rapidamente
- As fórmulas
IMPORTXMLeIMPORTHTMLfalham constantemente devido a alterações na estrutura do site - O tempo de atualização não é confiável. O Google limita a execução das fórmulas de forma imprevisível
- Não há renderização em JavaScript, portanto, aplicativos modernos de página única (SPAs) retornam dados vazios (é necessário um Navegador de scraping para esses casos)
- Limites de taxa na API do Google Sheets causam falhas de sincronização durante atualizações programadas
Conclusão: funciona para pequenos protótipos. Falha em qualquer escala maior. Boa escolha para painéis pessoais que rastreiam menos de 10.000 linhas de dados que raramente mudam.
Método 3: Excel + OneDrive / SharePoint
Como funciona: use o Power Query do Excel ou o recurso “Obter dados da Web” para extrair dados de URLs e salvar no OneDrive. Em seguida, conecte o Tableau ao arquivo do Excel hospedado na nuvem.
Limitações críticas:
- É necessária atualização manual – o Power Query não atualiza automaticamente em segundo plano de maneira confiável
- Sem renderização em JavaScript, portanto, não é compatível com React, Angular ou sites baseados em SPA
- Parsing limitado. Estruturas HTML complexas frequentemente interrompem a importação
- Conflitos de sincronização do OneDrive causam problemas de integridade de dados
- A ausência de rotação de Proxy implica no bloqueio de IPs em caso de volume significativo de scraping
Conclusão: Adequado para um único relatório de uma página da web estática. Não é um pipeline de dados.
Método 4: TabPy (Python + extensões do Tableau)
Como funciona: O TabPy é o servidor Python oficial do Tableau. Ele executa scripts Python dentro dos campos calculados do Tableau usando funções como SCRIPT_REAL e SCRIPT_STR. Em teoria, a lógica de Scraping de dados é executada diretamente dentro do Tableau por meio do TabPy.
Por que usá-lo: Python possui extensas bibliotecas de scraping, e o TabPy é oficialmente suportado pelo Tableau.
Limitações críticas:
- Requer um servidor TabPy em execução – infraestrutura adicional para manutenção
- O scraping dentro dos campos calculados do Tableau é um anti-padrão. É lento, pouco confiável e bloqueia a renderização do painel
- A ausência de rotação de Proxy significa que o IP do seu servidor TabPy é banido imediatamente em alvos de alto volume
- Sem resolução de CAPTCHA, sem lógica de repetição de tentativa, sem renderização de JavaScript
- Os campos calculados têm limites de tempo de execução, portanto, tarefas complexas de scraping expiram
- A depuração é extremamente difícil porque os erros aparecem como mensagens de erro pouco claras do Tableau
Conclusão: o TabPy é ótimo para executar modelos de ML e cálculos estatísticos dentro do Tableau. Não é adequado para Scraping de dados.
Método 5: Scripts Python personalizados (requests, Scrapy, Selenium)
Como funciona: Escreva scripts Python personalizados usando bibliotecas como requests, BeautifulSoup, Scrapy ou Selenium. Execute-os em uma programação (como cron ou Airflow), gere arquivos CSV/JSON e conecte o Tableau a esses arquivos.
Por que usar: Flexibilidade máxima. Você controla tudo.
Limitações críticas:
- Alta carga de manutenção – sites mudam layouts, adicionam medidas anti-bot, alteram estruturas HTML. Seu Scraper falha sem aviso prévio, e o painel exibe dados desatualizados.
- Bloqueio de IP em grande escala – sem uma rede de Proxy, os alvos bloqueiam seu servidor em questão de horas
- Sem resolução de CAPTCHA – Cloudflare, reCAPTCHA e hCaptcha bloqueiam seu Scraper sem solução alternativa integrada (serviços como o Web Unlocker lidam com isso automaticamente)
- Custos de infraestrutura – você precisa de servidores, assinaturas de Proxy, monitoramento e alertas
- Risco de conformidade – sem a infraestrutura adequada, você pode violar o GDPR, o CCPA ou os termos da plataforma
- Não é escalável – fazer scraping de 100 URLs é diferente de fazer scraping de 100.000. A arquitetura que funciona para um falha completamente no outro.
Conclusão: o “faça você mesmo” é viável inicialmente, mas não é confiável a longo prazo. A maioria das equipes começa por aqui, e muitas têm sucesso no início. Mas o esforço de manutenção aumenta com o tempo.
Funciona bem no primeiro mês, mas depois de alguns meses você passa mais tempo consertando seletores quebrados e banimentos de IP do que criando painéis. Se você estiver fazendo scraping de um ou dois sites em baixo volume, scripts DIY podem ser tudo o que você precisa.
Método 6: API Web Scraper da Bright Data (recomendado)
Como funciona: a API Web Scraper da Bright Data lida com toda a camada de coleta de dados: rotação de proxies, Resolução de CAPTCHA, renderização de JavaScript, contorno de bloqueios anti-bot e saída de dados estruturados. Você aciona uma tarefa de coleta via API, recebe dados JSON/CSV limpos e os carrega no Tableau.
Vantagens:
| Capacidade | Bright Data | Scripts DIY |
|---|---|---|
| Rede de proxies | Mais de 150 milhões de IPs em 195 países | Compre o seu próprio (caro) |
| Scrapers prontos | Mais de 120 para as principais plataformas | Crie do zero |
| Resolução de CAPTCHA | Automático | Não incluído |
| Renderização em JavaScript | Integrado | Requer Selenium/Playwright |
| Contorno anti-bot | Automático | Requer atualizações manuais constantes |
| Tempo de atividade | 99,99% | Depende da sua infraestrutura |
| Conformidade | GDPR, CCPA, ISO 27001 | Sua responsabilidade |
| Manutenção | Mínima – a Bright Data cuida das atualizações do Scraper | Constante |
| Escala | Milhões de páginas/dia | Limitada pelos seus servidores |
| Preços | A partir de US$ 1,50/1 mil registros | Variável (servidores + Proxies + manutenção) |
Conclusão: você se concentra nos painéis do Tableau; a Bright Data cuida da infraestrutura de coleta de dados.
Contraponto: A Bright Data é um serviço pago de terceiros. Você depende de sua infraestrutura e modelo de preços. Para extração ocasional de um ou dois sites em baixo volume, um script DIY (Método 5) custa menos e oferece controle total.
Qual método de conexão de dados do Tableau você deve escolher?
Esta tabela compara todos os seis métodos em relação aos recursos mais importantes para pipelines de produção.
| Método | Renderização JS | Rotação de proxy | Resolução de CAPTCHA | Atualização automática | Escala | Manutenção | Status |
|---|---|---|---|---|---|---|---|
| WDC v2 | Não | Não | Não | Sim | Baixo | N/A | Obsoleto |
| Google Sheets | Não | Não | Não | Não confiável | Muito baixo | Baixo | Limites de células |
| Excel + OneDrive | Não | Não | Não | Manual | Muito baixo | Médio | Processo manual |
| TabPy | Manual/Faça você mesmo | Não | Não | Sim | Baixo | Alto | Bloqueios de IP |
| Python DIY | Via Selenium | Faça você mesmo | Não | Via cron | Médio | Muito alto | Falhas em escala |
| API da Bright Data | Sim | Sim (mais de 150 milhões de IPs) | Sim | Sim | Alta | Mínimo | Pronto para produção |
Tutorial: conectar uma API de Scraping de dados ao Tableau
Este tutorial cria um pipeline real: preços de produtos da Amazon → API da Bright Data → CSV → painel do Tableau usando a API do Amazon Scraper. Ele aborda o caso de uso “Monitoramento de preços da concorrência”, o motivo mais comum pelo qual as equipes conectam dados da web ao Tableau.
Arquitetura
O pipeline segue este fluxo:
┌─────────────────┐ ┌──────────────────────┐ ┌─────────────┐ ┌─────────────┐
│ Seu script │────▶│ Bright Data Scraper │────▶ │ CSV/JSON │────▶│ Tableau │
│ (Python/cron) │ │ API │ │ Saída │ │ Painel │
└─────────────────┘ └──────────────────────┘ └─────────────┘ └─────────────┘
│ │ │
Acionar com Lida com Proxies, Visualizar preços,
palavras-chave/URLs CAPTCHAs, renderização classificações, tendênciasPré-requisitos
Você precisará ter o seguinte instalado ou disponível antes de começar:
- Python 3.8+
- Uma conta Bright Data (versão de avaliação gratuita disponível, sem necessidade de cartão de crédito)
- Seu token de API do painel da Bright Data (instruções na Etapa 0)
- Tableau Desktop (versão de avaliação gratuita de 14 dias), Tableau Cloud ou Tableau Public (gratuito, os painéis são públicos)
Com essas ferramentas prontas, comece gerando seu token de API da Bright Data.
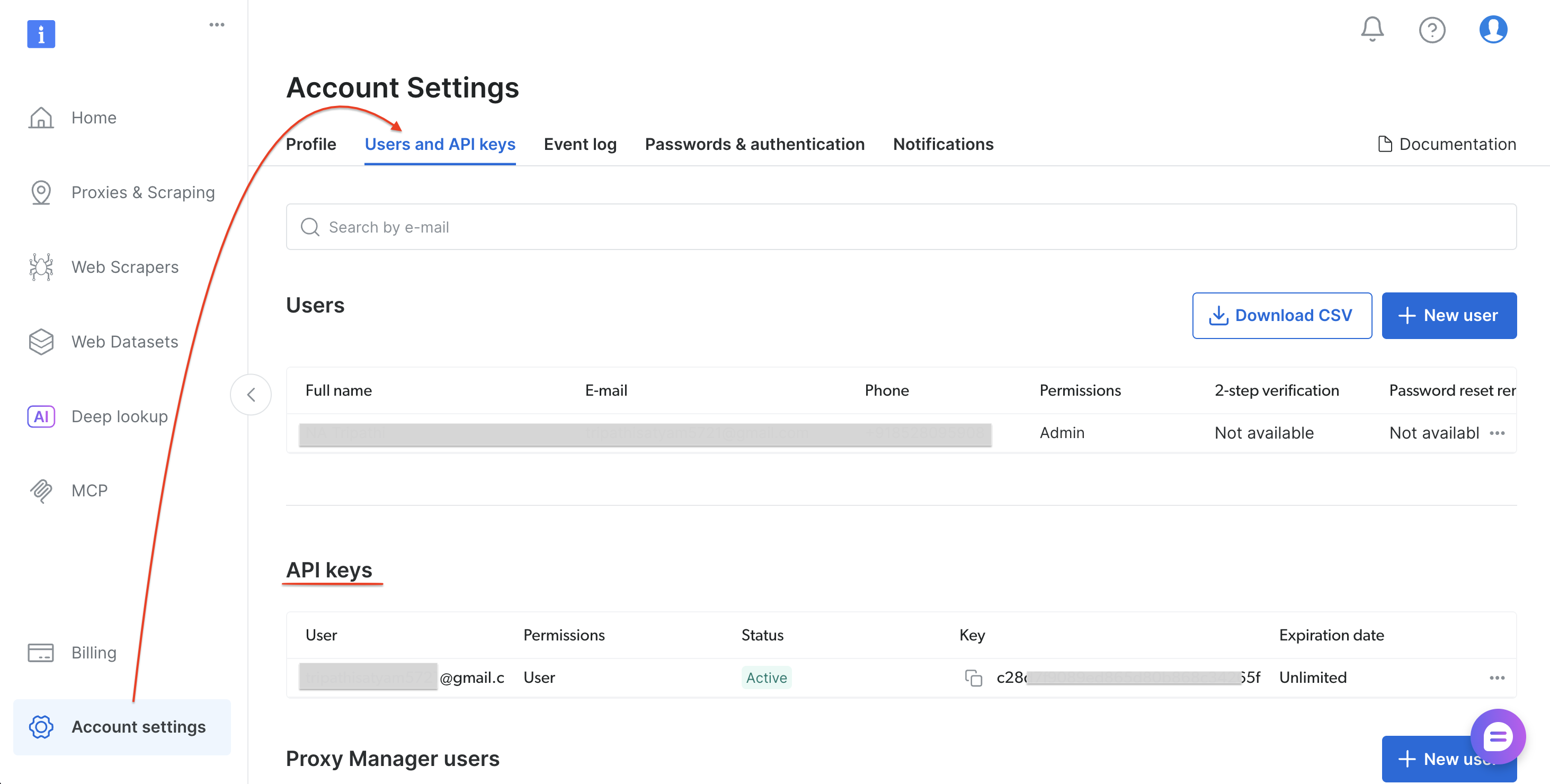
Etapa 0: Obtenha seu token de API da Bright Data
Siga estas etapas para gerar seu token de API:
- Cadastre-se ou faça login em brightdata.com/cp
- Vá para Configurações da conta → Usuários e chaves de API
- Selecione “Adicionar chave de API” (canto superior direito da seção de chaves de API)
- Defina as permissões e a validade e, em seguida, selecione Salvar
- Copie o token
Com seu token de API salvo, instale as dependências do Python.
Passo 1: Instalar dependências
Instale os pacotes Python necessários:
pip install requests pandasCom o requests e o pandas instalados, crie o script do pipeline.
Etapa 2: O script do pipeline
Crie um arquivo chamado bright_data_to_tableau.py:
"""
Pipeline Bright Data → Tableau
Extraia dados de produtos da Amazon por meio da API de Scraping de dados da Bright Data
e gere um arquivo CSV pronto para o Tableau.
Uso:
1. Substitua YOUR_API_TOKEN pelo seu token da API da Bright Data
2. Execute: python bright_data_to_tableau.py
3. Abra o CSV gerado no Tableau Desktop
"""
import requests
import time
import json
import sys
import pandas as pd
from datetime import datetime
# ─── Configuração ───────────────────────────────────────────────────────────
API_TOKEN = "YOUR_API_TOKEN" # Substitua pelo seu token da API da Bright Data
DATASET_ID = "gd_lwdb4vjm1ehb499uxs" # Pesquisa de produtos da Amazon (por palavra-chave)
OUTPUT_CSV = "amazon_products_tableau.csv"
POLL_INTERVAL = 10 # segundos entre verificações de status
POLL_TIMEOUT = 300 # tempo máximo de espera em segundos
# ─── Pontos de extremidade da API ───────────────────────────────────────────────────────────
TRIGGER_URL = (
f"https://api.brightdata.com/conjuntos_de_dados/v3/trigger"
f"?dataset_id={DATASET_ID}&include_errors=true"
)
SNAPSHOT_URL = "https://api.brightdata.com/conjuntos_de_dados/v3/snapshot"
HEADERS = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/json",
}
def trigger_collection(keyword: str) -> str:
"""Aciona uma tarefa de coleta de dados no Bright Data."""
payload = [{
"keyword": keyword,
"url": "https://www.amazon.com",
"pages_to_search": 1
}]
print(f"[1/3] Acionando a coleta para a palavra-chave: '{keyword}'...")
response = requests.post(TRIGGER_URL, headers=HEADERS, data=json.dumps(payload))
if response.status_code != 200:
print(f" ERROR {response.status_code}: {response.text}")
sys.exit(1)
result = response.json()
snapshot_id = result.get("snapshot_id")
print(f" ID do snapshot: {snapshot_id}")
return snapshot_id
def poll_snapshot(snapshot_id: str) -> list:
"""Consulta o endpoint do snapshot até que os dados estejam prontos."""
url = f"{SNAPSHOT_URL}/{snapshot_id}?format=json"
elapsed = 0
print(f"[2/3] Aguardando resultados...")
while elapsed < POLL_TIMEOUT:
response = requests.get(url, headers=HEADERS)
if response.status_code == 200:
data = response.json()
print(f" Pronto! Recebidos {len(data)} registros.")
return data
elif response.status_code == 202:
print(f" Processando... ({elapsed}s / {POLL_TIMEOUT}s)")
time.sleep(POLL_INTERVAL)
elapsed += POLL_INTERVAL
else:
print(f" ERRO {response.status_code}: {response.text}")
sys.exit(1)
print(f" TIMEOUT: Instantâneo não pronto após {POLL_TIMEOUT}s.")
print(f" Tente aumentar POLL_TIMEOUT ou verifique o painel do Bright Data.")
sys.exit(1)
def to_tableau_csv(data: list, output_path: str) -> pd.DataFrame:
"""Transforme dados brutos da API em um CSV limpo e otimizado para o Tableau."""
df = pd.DataFrame(data)
# Mapeia nomes de campos da API → nomes compatíveis com o Tableau
column_mapping = {
"title": "Nome do produto",
"seller_name": "Vendedor",
"brand": "Marca",
"initial_price": "Preço Original",
"final_price": "Preço Atual",
"currency": "Moeda",
"rating": "Avaliação",
"reviews_count": "Número de Avaliações",
"availability": "Disponibilidade",
"url": "URL do produto",
"asin": "ASIN",
"categories": "Categorias",
"delivery": "Informações de entrega",
}
# Manter apenas as colunas presentes nos dados
available = {k: v for k, v in column_mapping.items() if k in df.columns}
df = df.rename(columns=available)
df = df[list(available.values())]
# Adicionar metadados para filtragem e rastreamento no Tableau
df["Scrape Date"] = datetime.now().strftime("%Y-%m-%d")
df["Scrape Timestamp"] = datetime.now().isoformat()
df["Data Source"] = "Bright Data API"
df.to_csv(output_path, index=False)
print(f"[3/3] Salvas {len(df)} linhas → {output_path}")
return df
def print_summary(df: pd.DataFrame):
"""Imprime um resumo dos dados coletados."""
print(f"n{'─'*50}")
print(f" Resumo")
print(f"{'─'*50}")
print(f" Total de produtos : {len(df)}")
if "Preço atual" in df.columns:
preços = pd.to_numeric(df["Preço atual"], errors="coerce")
print(f" Faixa de preço : ${prices.min():.2f} – ${prices.max():.2f}")
print(f" Preço médio : ${prices.mean():.2f}")
if "Marca" in df.columns:
print(f" Marcas únicas : {df['Brand'].nunique()}")
if "Rating" in df.columns:
ratings = pd.to_numeric(df["Rating"], errors="coerce")
print(f" Avaliação média : {ratings.mean():.1f} / 5.0")
print(f"{'─'*50}n")
def run_pipeline(keyword: str):
"""Executar o pipeline completo: Trigger → Poll → CSV → Summary."""
print(f"n{'='*50}")
print(f" Bright Data → Tableau Pipeline")
print(f" Palavra-chave: '{keyword}'")
print(f"{'='*50}n")
snapshot_id = trigger_collection(keyword)
data = poll_snapshot(snapshot_id)
df = to_tableau_csv(data, OUTPUT_CSV)
print_summary(df)
return df
if __name__ == "__main__":
# Palavra-chave padrão — altere isso ou passe como argumento da CLI
keyword = sys.argv[1] if len(sys.argv) > 1 else "fones de ouvido sem fio"
run_pipeline(keyword)Etapa 3: Execute o script
Execute o script do pipeline:
python bright_data_to_tableau.pySaída esperada:
==================================================
Bright Data → Pipeline do Tableau
Palavra-chave: 'fones de ouvido sem fio'
==================================================
[1/3] Acionando a coleta para a palavra-chave: 'fones de ouvido sem fio'...
ID do snapshot: sd_mmlan9p51yycmmkd7d
[2/3] Aguardando resultados...
Processando... (0s / 300s)
Pronto! Recebidos 43 registros.
[3/3] Salvas 43 linhas → amazon_products_tableau.csv
──────────────────────────────────────────────────
Resumo
──────────────────────────────────────────────────
Total de produtos: 43
Faixa de preço: $0,00 – $169,95
Preço médio: $45,98
Marcas exclusivas: 4
Avaliação média: 4,4 / 5,0
──────────────────────────────────────────────────O CSV está pronto. Abra-o no Tableau para começar a criar painéis.
Etapa 4: Conecte-se ao Tableau
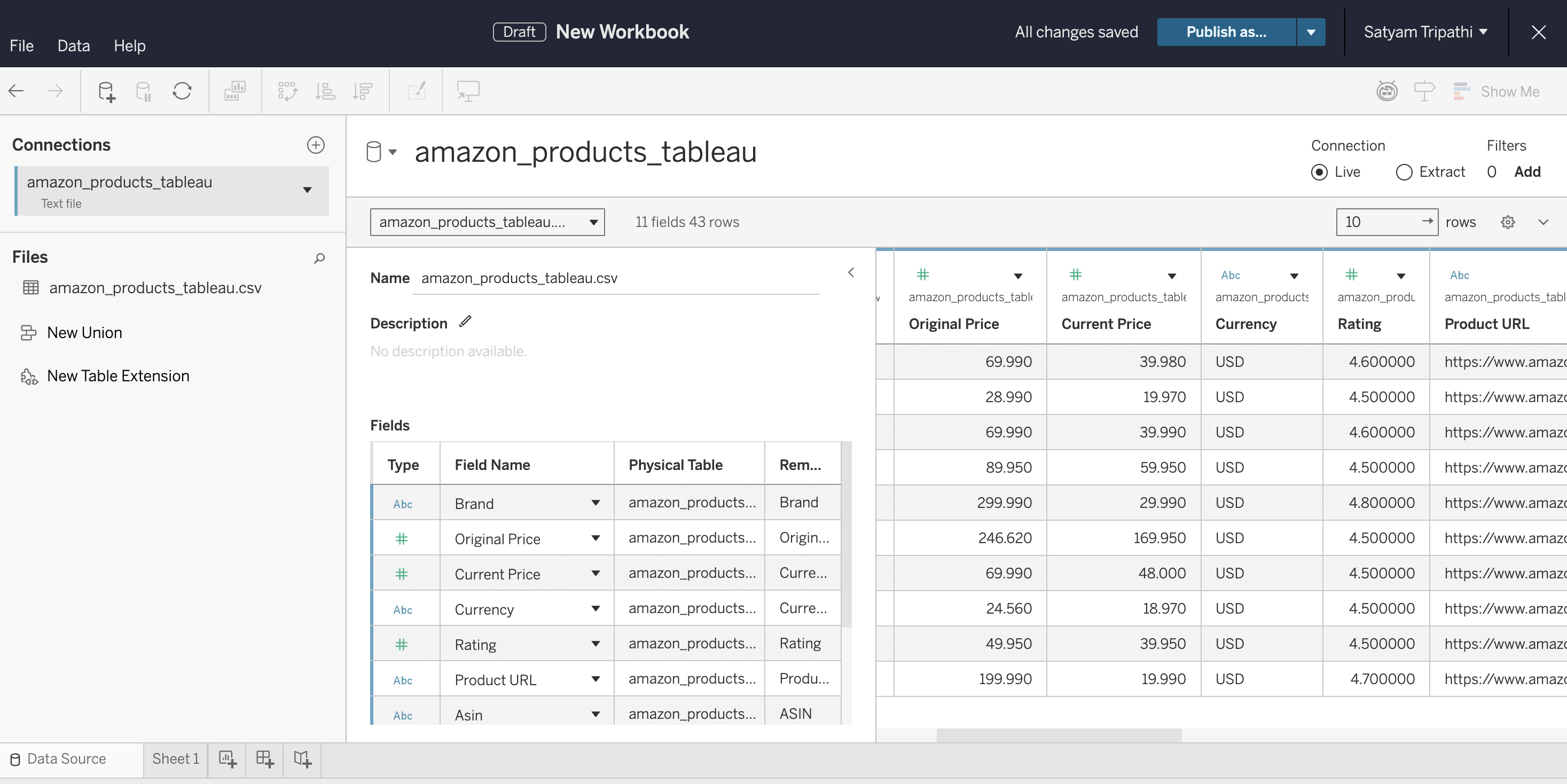
Carregue o CSV no Tableau e verifique os tipos de dados:
- Abra o Tableau Desktop, o Tableau Cloud ou o Tableau Public
- Conecte-se ao CSV: no Desktop, selecione Conectar → Arquivo de texto. No Cloud, selecione Novo → Pasta de trabalho → guia Arquivos e faça o upload do arquivo
- Verifique se
Preço atualeClassificaçãosão detectados como Número, e não como Texto - Selecione a Folha 1 para começar a criar
Visualizações recomendadas do painel:
- Distribuição de preços – histograma do
Preço atualpara identificar o posicionamento no mercado - Análise de Queda de Preço – Gráfico de barras lado a lado do
Preço Originalvs.Preço Atualpara identificar descontos - Avaliação x Preço – Gráfico de dispersão para identificar produtos de alto valor
- Comparação de marcas – Gráfico de barras agrupando produtos por
marcapara comparar preços e avaliações
Etapa 5: Automatize a atualização
Para manter seu painel atualizado, programe o script com o cron (Linux/Mac) ou o Agendador de Tarefas (Windows):
# Executar a cada 6 horas — crontab -e
0 */6 * * * cd /path/to/project && python bright_data_to_tableau.pyAtualizando o Tableau para mostrar os novos dados:
- Tableau Desktop. Após a tarefa cron atualizar o CSV, pressione F5 (Windows) ou Command+R (Mac) para recarregar. Como alternativa, selecione a fonte de dados no menu Dados e escolha Atualizar. O Tableau Desktop não atualiza automaticamente fontes baseadas em arquivos por conta própria, portanto, você precisará atualizar manualmente ou reabrir a pasta de trabalho.
- Tableau Server. No Tableau Desktop, publique via Servidor → Publicar pasta de trabalho. Na caixa de diálogo de publicação, defina uma Programação de atualização da extração (por exemplo, a cada 6 horas para corresponder à sua tarefa cron). O Tableau Server atualizará automaticamente a extração nessa programação.
- Tableau Cloud. Arquivos CSV carregados pelo navegador não podem ser atualizados automaticamente. Para automatizar as atualizações, instale o Tableau Bridge na máquina que executa sua tarefa cron. O Bridge conecta seu CSV local ao Tableau Cloud e oferece suporte a atualizações programadas de extratos. Sem o Bridge, recarregue o CSV manualmente após cada execução do pipeline.
- Tableau Public. Não oferece suporte a atualizações programadas para fontes baseadas em arquivos. Para pipelines baseados em CSV, você precisará republicar a pasta de trabalho sempre que os dados forem atualizados.
Etapa 6: Use qualquer Scraper (localizando IDs de Conjuntos de dados)
O tutorial usa o conjunto de dados Amazon Products Search (gd_lwdb4vjm1ehb499uxs). Para fazer o scraping de um site diferente, troque o ID do conjunto de dados. Veja como encontrá-lo:
- Faça login no painel de controle da Bright Data
- Selecione Scrapers na barra lateral para abrir a Biblioteca de Scrapers
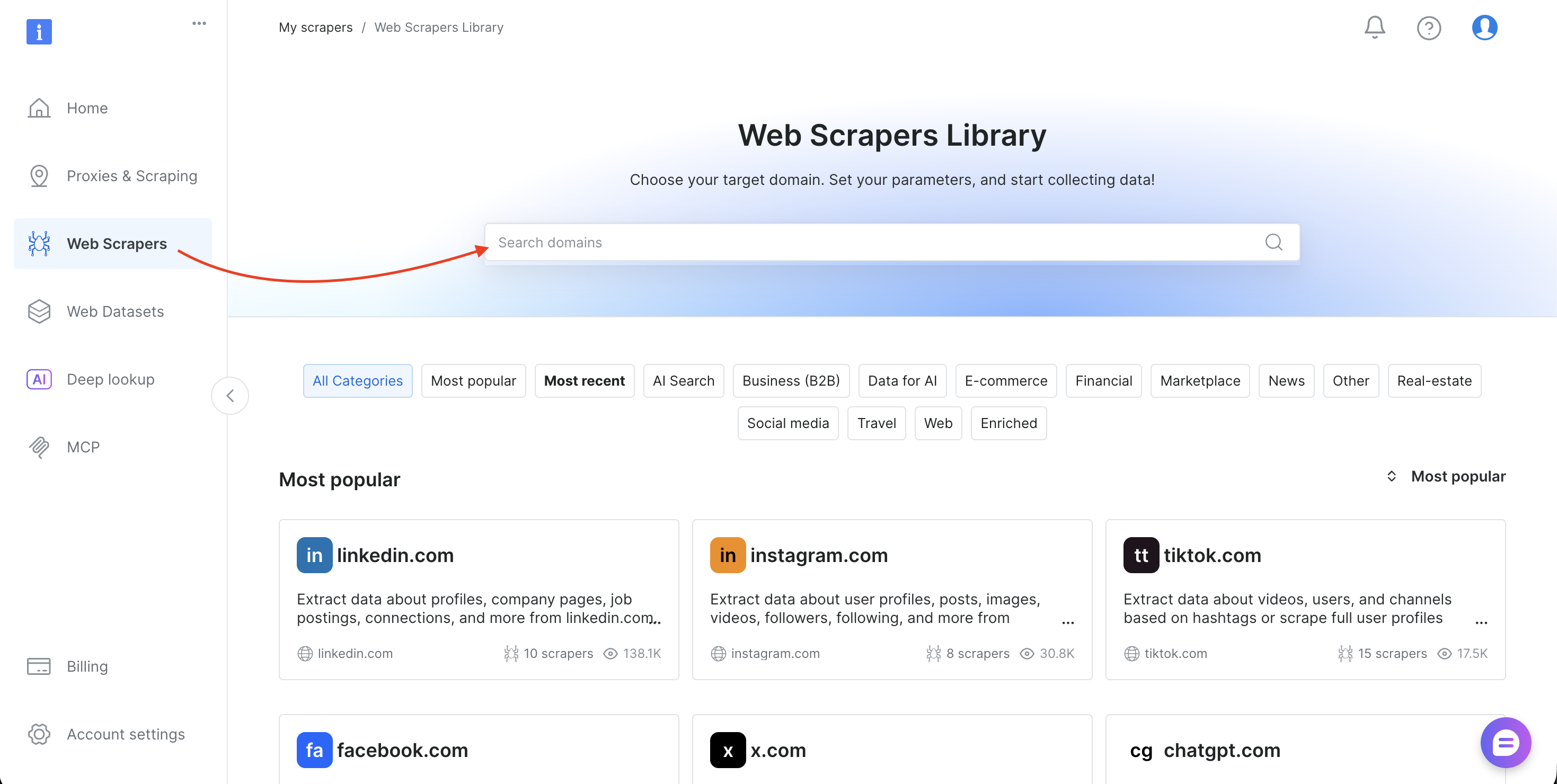
- Pesquise o domínio de destino (como amazon.com, zillow.com ou linkedin.com) e selecione-o
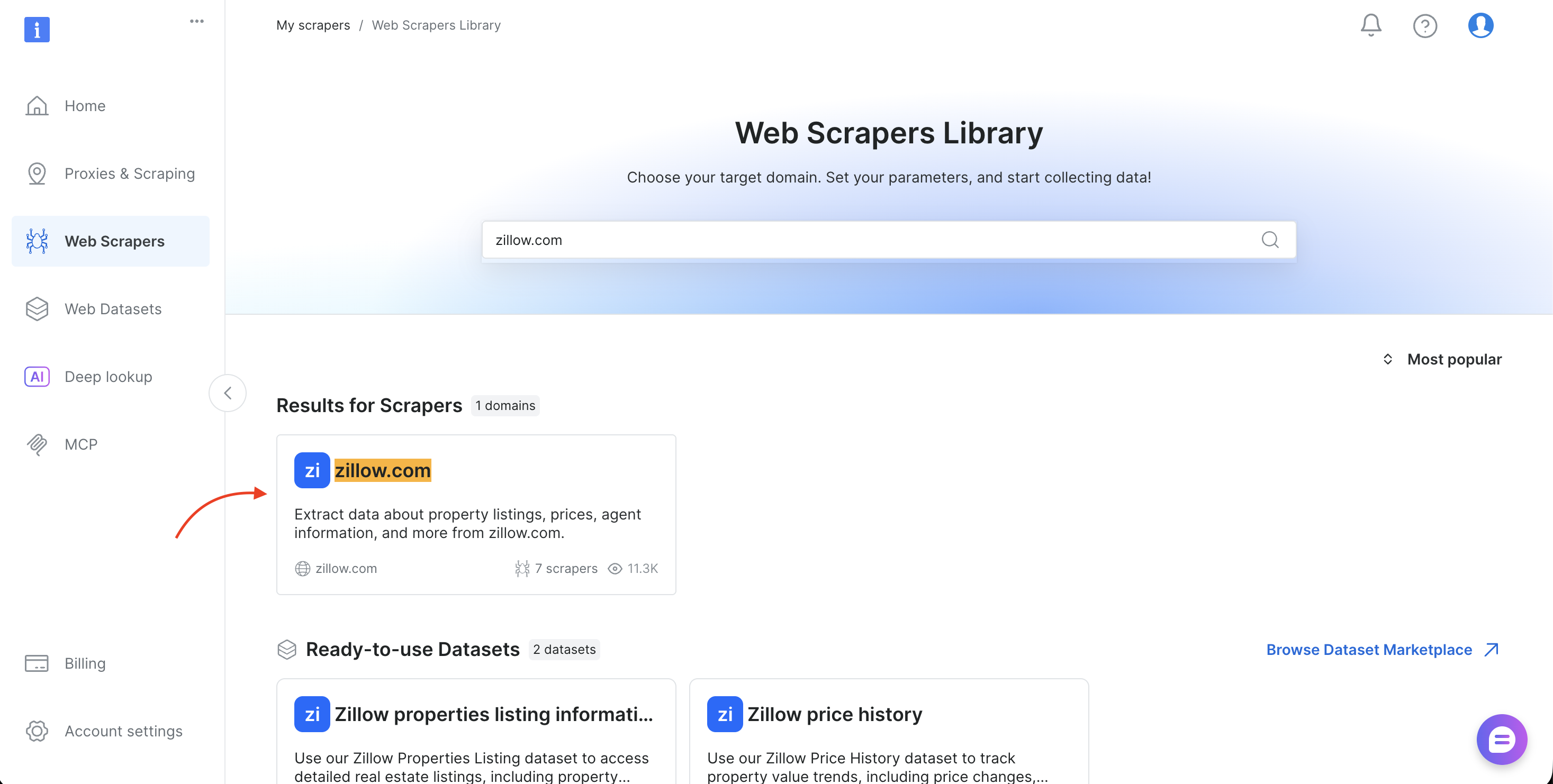
- Escolha o método de coleta (Coletar por URL ou Descobrir por palavra-chave)
- Copie o
dataset_idda barra de URL do navegador (por exemplo,brightdata.com/cp/scrapers/gd_lfqkr8wm13ixtbd8f5) ou do painel Exemplos de código
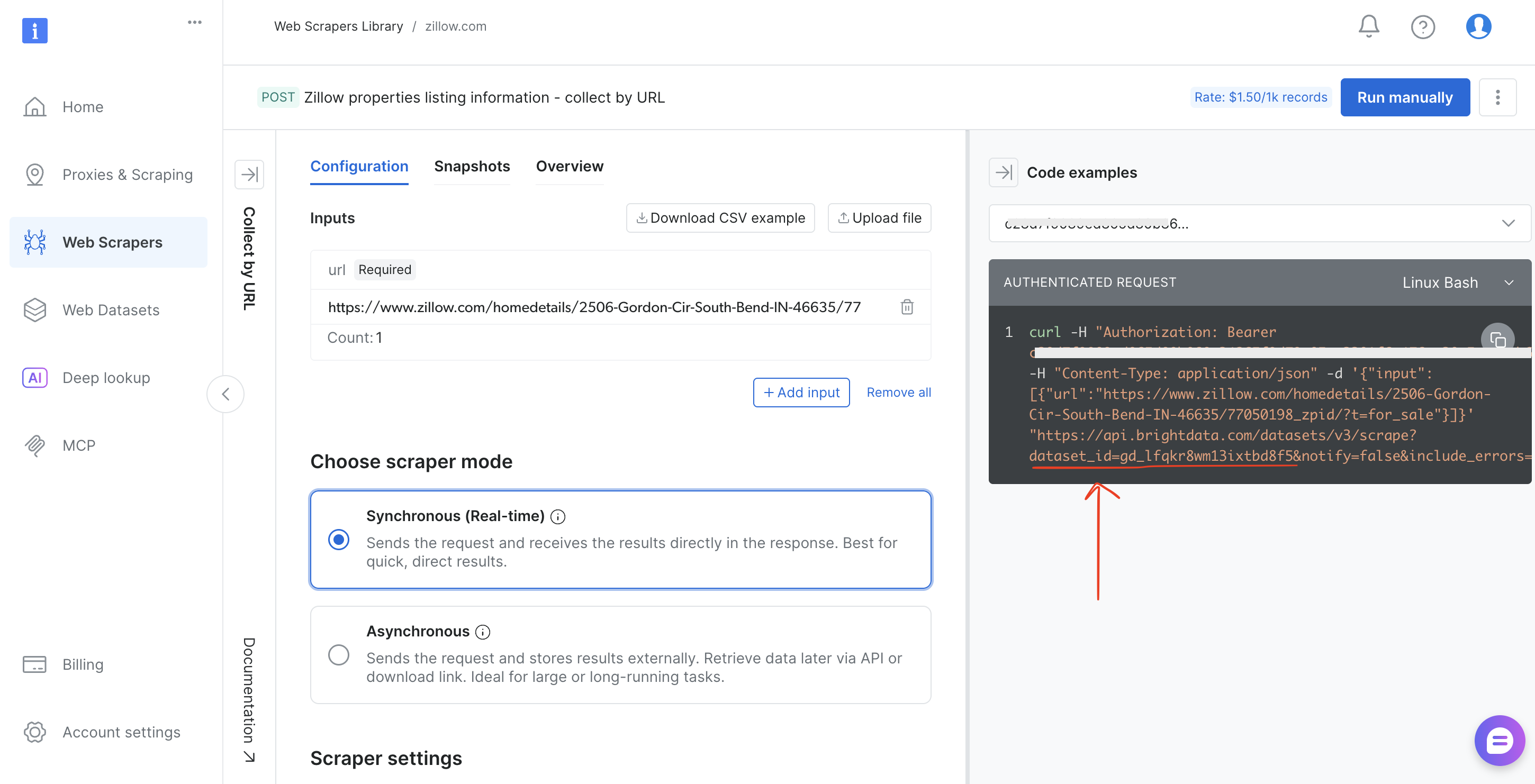
Substitua DATASET_ID no script, ajuste a carga útil, e o mesmo pipeline funciona para qualquer um dos mais de 120 Scrapers da Bright Data.
Resultados reais: como ficam os dados coletados
A captura de tela a seguir mostra a saída CSV bruta do pipeline, exatamente o que a API da Bright Data retornou para a palavra-chave “fones de ouvido sem fio”:
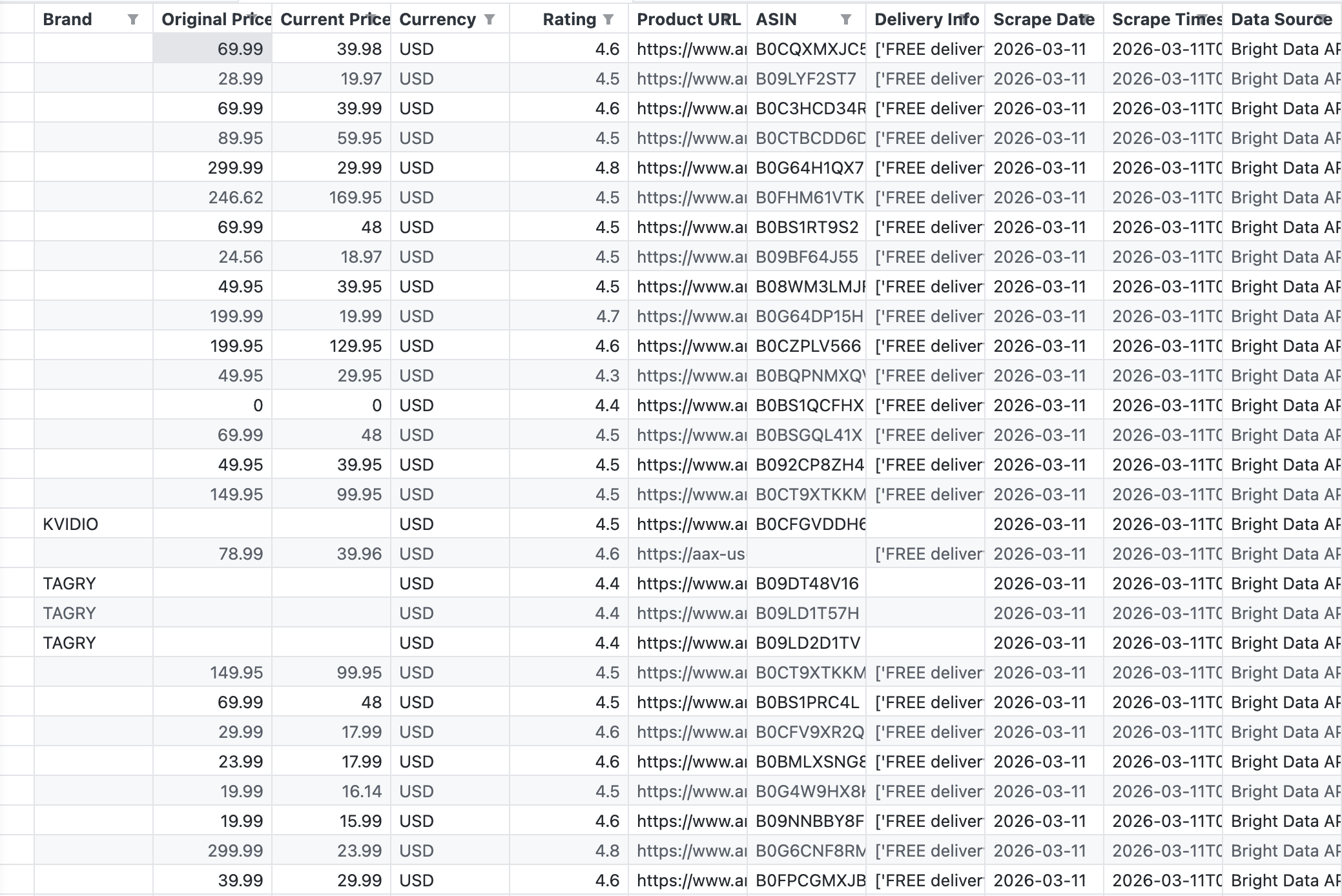
A API retornou 43 registros com campos que incluem Marca, Preço Original, Preço Atual, Avaliação, ASIN, URL do Produto e Informações de Entrega.
A API retornou 43 produtos em uma única chamada. Os dados estão estruturados e prontos para o Tableau. Sem Parsing de HTML, sem seletores quebrados, sem desafios de CAPTCHA. Para mais detalhes sobre as opções de scraping da Amazon, consulte Como fazer scraping de dados de produtos da Amazon.
Visualizando os dados: do CSV aos insights
Essas quatro visualizações mostram o que o pipeline produz. Cada visualização é construída a partir do CSV exato gerado pelo script:
Distribuição de preços entre os produtos
Este gráfico classifica 31 produtos (aqueles com nomes analisáveis a partir de suas URLs da Amazon) por preço atual, do menor ao maior:
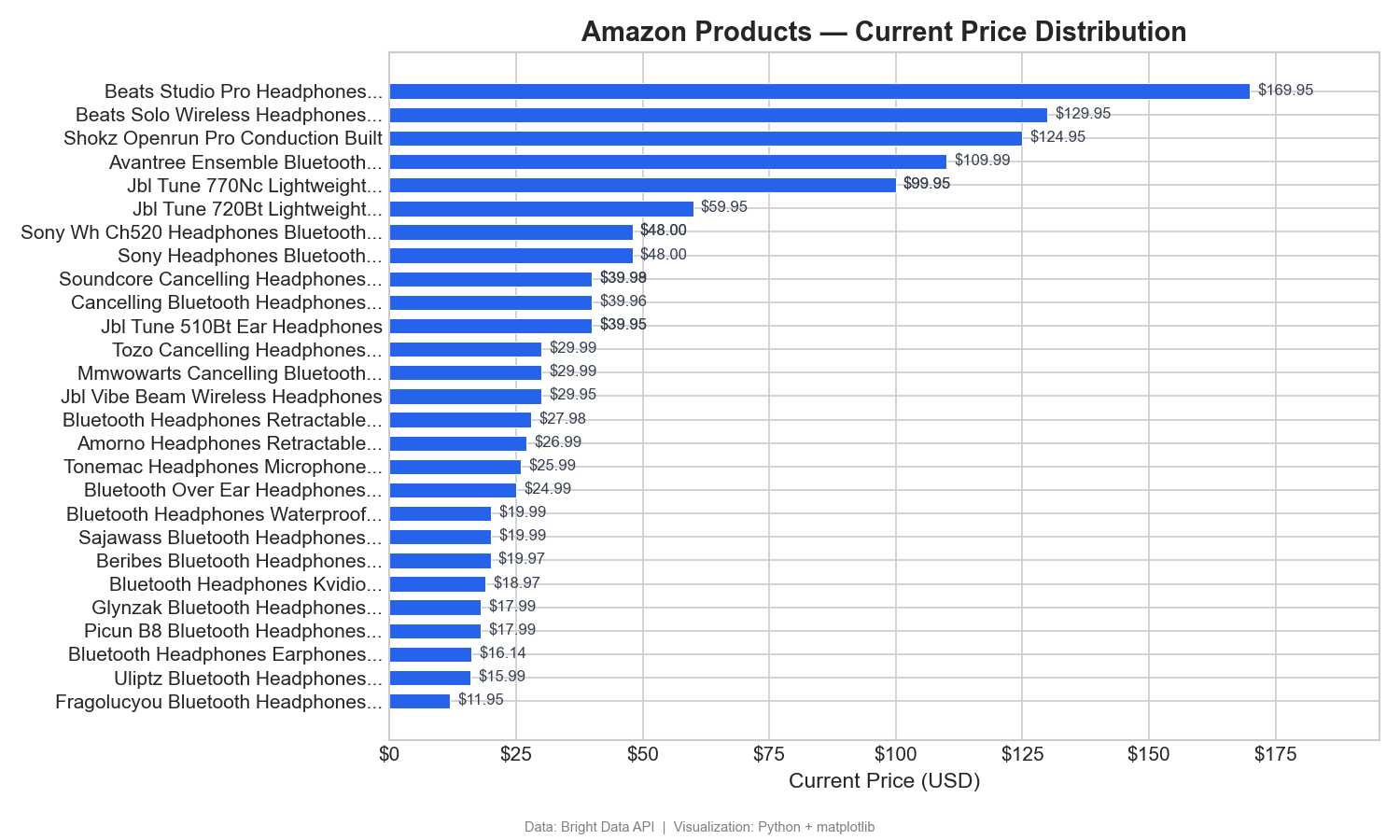
Este gráfico de barras horizontais mostra claramente a faixa de preços: a Beats domina a faixa premium (US$ 125–US$ 170), enquanto a maioria dos fones de ouvido sem fio se concentra na faixa de US$ 12–US$ 60. No Tableau, você criaria isso como um gráfico de barras ordenado com Preço atual nas colunas e Nome do produto nas linhas.
Quedas de preço: preço original x preço atual
Este gráfico de barras agrupadas compara os preços listados e atuais dos 10 principais produtos com desconto:
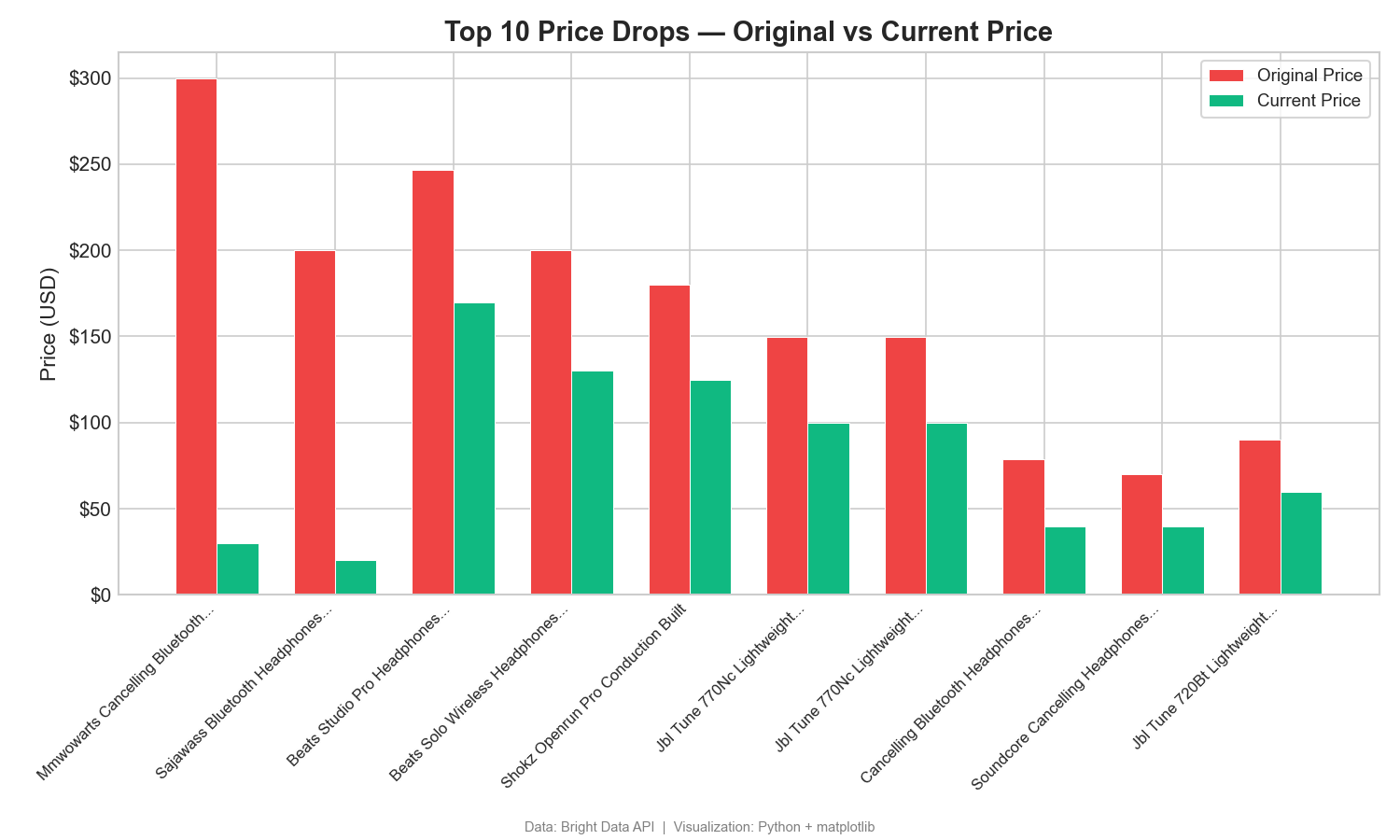
A diferença entre o preço original e o atual mostra grandes descontos. Um produto apresenta uma queda de US$ 270 em relação ao seu preço original listado (US$ 299,99 → US$ 29,99). Diferenças como essa revelam estratégias promocionais e de preços. No Tableau, use um gráfico de barras lado a lado com Nomes de medidas na cor.
Avaliação x preço: identificando valor
Este gráfico de dispersão mapeia as avaliações dos clientes em relação ao preço para identificar produtos de alto valor:
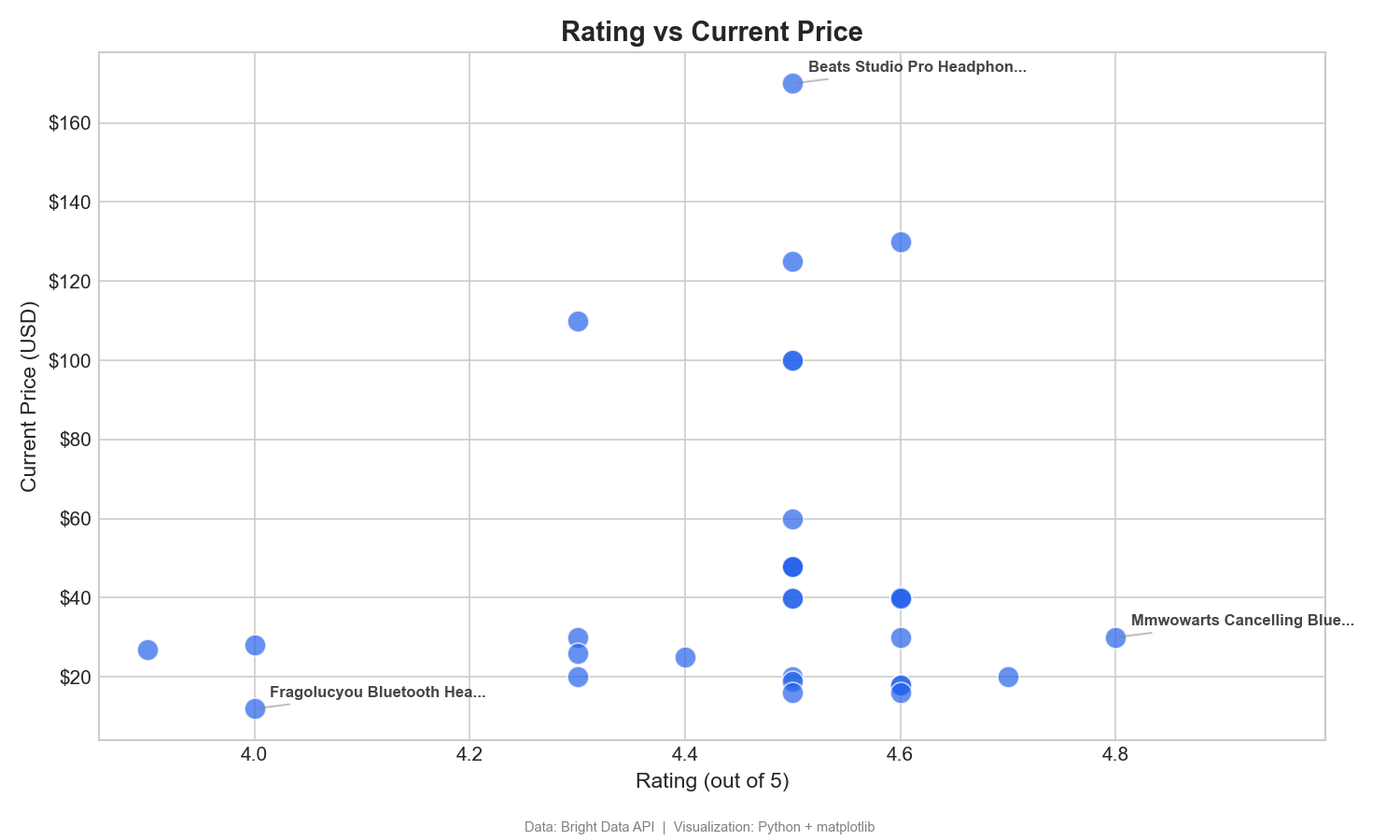
Este gráfico de dispersão ajuda a identificar produtos de alto valor, aqueles com avaliações altas e preços baixos (quadrante inferior direito). Os fones de ouvido MMWOWARTS a US$ 29,99 com uma avaliação de 4,8 são um exemplo claro. No Tableau, arraste Avaliação para Colunas, Preço atual para Linhas e Nome do produto para Detalhes.
Segmentação de mercado por faixa de preço
Este gráfico de anel divide os produtos por faixa de preço:
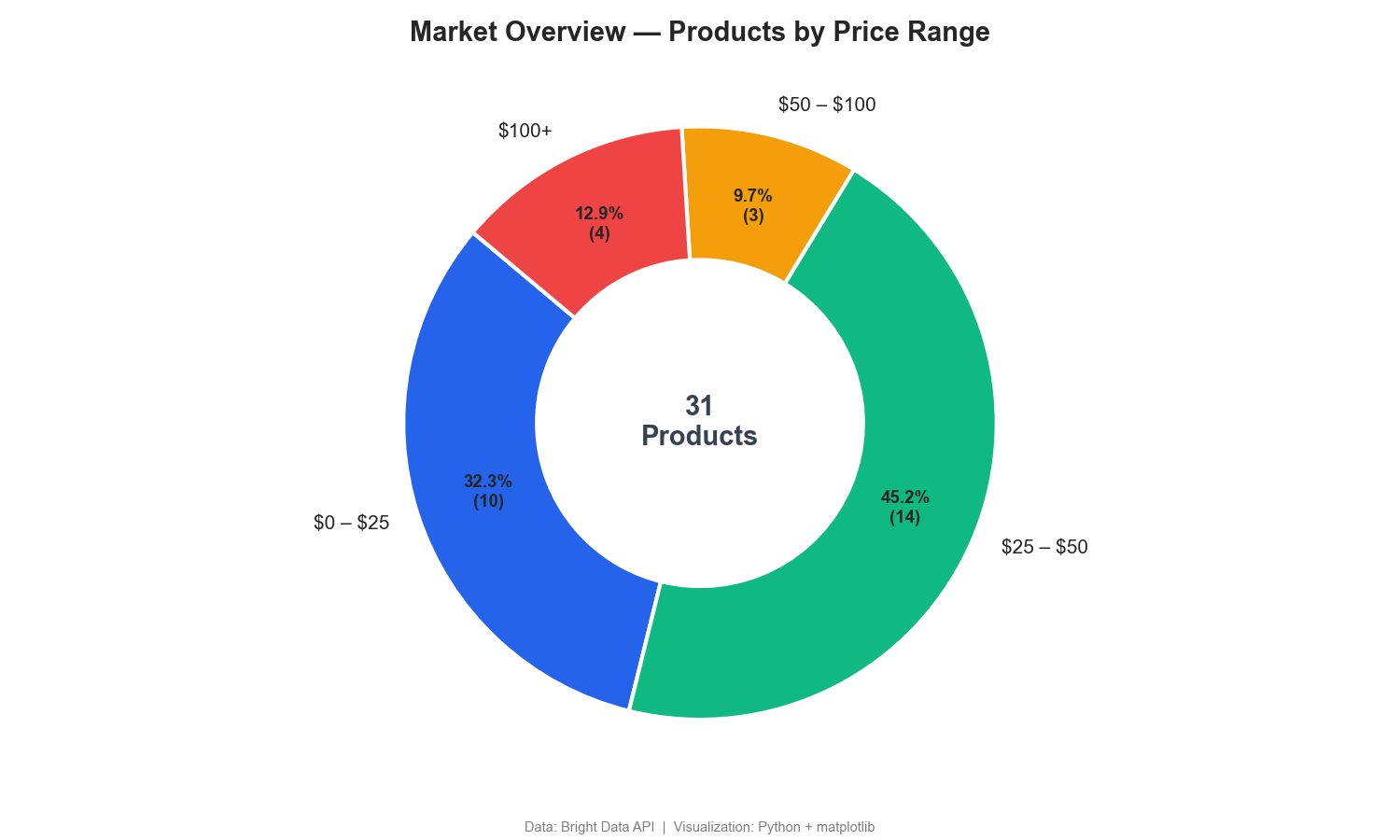
O gráfico de rosca mostra que 77% dos fones de ouvido sem fio são vendidos por menos de US$ 50, com apenas 13% no segmento premium de mais de US$ 100. Painéis de Monitoramento de preços da concorrência geralmente incluem segmentações semelhantes.
Bônus: pipeline imobiliário com o Zillow
O mesmo padrão de pipeline funciona com qualquer um dos mais de 120 Scrapers da Bright Data. O exemplo a seguir usa a API do Zillow Scraper (repositório do GitHub). Atualize duas variáveis em bright_data_to_tableau.py e o restante do pipeline será executado sem alterações:
# Substitua o ID do conjunto de dados da Amazon pelo ID do conjunto de dados do Zillow
DATASET_ID = "gd_lfqkr8wm13ixtbd8f5" # Propriedades do ZillowEm seguida, atualize a carga útil em trigger_collection() para usar uma URL de localização em vez de uma palavra-chave:
payload = [{
"url": "https://www.zillow.com/new-york-ny/"
}]Execute o script da mesma maneira. A lógica de polling e exportação para CSV funciona sem alterações.
Os campos do Zillow incluem: endereço do imóvel, preço, quartos, banheiros, metragem quadrada, tamanho do terreno, ano de construção, tipo de imóvel, status do anúncio e Zestimate.
Ideias para painéis do Tableau:
- Mapa de calor de preço por m² por CEP
- Análise da diferença entre preço de listagem e Zestimate
- Distribuição por tipo de imóvel por cidade ou CEP
- Gráfico de dispersão de ano de construção versus preço para oportunidades de reforma
O principal benefício: você aprende o padrão uma vez e depois o aplica a qualquer fonte de dados. Amazon, Zillow, vagas no LinkedIn – todos usam a mesma infraestrutura da Bright Data para enviar dados aos painéis do Tableau.
Os 6 principais casos de uso de dados da web em tempo real no Tableau
Essas são as razões mais comuns pelas quais as equipes criam pipelines de dados da web no Tableau.
1. Monitoramento de preços da concorrência
Acompanhe os preços dos concorrentes na Amazon, Walmart, Target ou qualquer plataforma de comércio eletrônico. Crie painéis do Tableau que mostrem variações diárias de preços, tendências históricas e posicionamento de preços em todo o seu mercado. Configure alertas quando os concorrentes ficarem abaixo do seu preço mínimo.
Monitore milhares de SKUs em vários marketplaces com os mais de 120 Scrapers prontos para uso da Bright Data. Não são necessários Scrapers personalizados.
Visualizações do Tableau: gráficos em cascata de preços, tendências de séries temporais por SKU, mapas de calor de preços dos concorrentes.
2. Acompanhamento de marcas nas redes sociais
Extraia menções, métricas de engajamento, contagem de seguidores e dados de comentários do Instagram, Twitter/X, TikTok e LinkedIn. Crie painéis que acompanhem a visibilidade da marca em todas as plataformas e meçam o desempenho da campanha ao longo do tempo. O Navegador de scraping lida com plataformas sociais com uso intenso de JavaScript que as solicitações HTTP padrão não conseguem renderizar.
Visualizações do Tableau: tendências de taxa de engajamento, volume de menções ao longo do tempo, gráficos de barras comparativos entre plataformas.
3. Análise do mercado de trabalho
Agregue anúncios de vagas do Indeed, Glassdoor, LinkedIn (repositório GitHub) e sites de emprego especializados. Analise tendências de contratação, referências salariais, habilidades exigidas e mudanças na demanda em diversos setores e regiões. Equipes de RH e recrutadores usam esses painéis para comparar remunerações e identificar mudanças no mercado de talentos antes dos concorrentes.
Visualizações do Tableau: mapas geográficos com bolhas de vagas em aberto, histogramas de distribuição salarial, mapas de árvore de demanda por habilidades.
4. Painéis imobiliários
Monitore anúncios de imóveis, variações de preço, níveis de estoque e tendências de bairros do Zillow, Realtor.com, Redfin e Airbnb. Investidores e analistas imobiliários criam mapas de calor geográficos no Tableau para identificar mercados subvalorizados e acompanhar tendências de rendimento de aluguel em diferentes cidades.
Visualizações do Tableau: mapas de calor por CEP, gráficos de dispersão de preço por m², séries temporais de volume de anúncios.
5. Feeds de dados financeiros
Colete preços de ações, relatórios de lucros, classificações de analistas, dados de uso de informação privilegiada e notícias financeiras do Yahoo Finance, Bloomberg e outras plataformas financeiras. Analistas quantitativos e gestores de portfólio criam painéis financeiros com atualização automática de dados para acompanhar o desempenho do portfólio e os sinais do mercado.
Visualizações do Tableau: gráficos de preços no estilo candlestick, gráficos de barras de surpresas nos lucros, painéis de rotação setorial.
6. Monitoramento da cadeia de suprimentos
Acompanhe a disponibilidade de produtos, estimativas de envio, níveis de estoque dos vendedores e preços em mercados globais. Equipes de operações criam painéis do Tableau que detectam interrupções no fornecimento, como rupturas repentinas de estoque ou picos no tempo de entrega, antes que afetem o restante da cadeia de suprimentos.
Visualizações do Tableau: matrizes de status de disponibilidade, linhas de tendência de tempo de entrega, scorecards de risco de fornecedores.
Cada um desses casos de uso segue a mesma arquitetura: API da Bright Data → Dados estruturados → Painel do Tableau. As únicas coisas que mudam são o ID do Conjunto de dados e as visualizações do Tableau que você cria.
Como funciona o pipeline da API da Bright Data
O script do tutorial lida com o acionamento e a sondagem. Veja o que acontece ao longo de todo o pipeline, desde a chamada da API até o painel do Tableau.
Fluxo de dados passo a passo
- Acionamento. Seu script Python envia uma solicitação POST para o endpoint
/triggerda Bright Data. Inclua uma palavra-chave (para descoberta) ou uma lista de URLs (para coleta direcionada). A API retorna umsnapshot_idimediatamente. - Coleta. A infraestrutura da Bright Data encaminha as solicitações por mais de 150 milhões de Proxies residenciais. Ela lida com desafios de CAPTCHA automaticamente, renderiza JavaScript quando necessário e repete solicitações com falha.
- Parsing. A Bright Data realiza o Parsing do HTML bruto em campos de dados estruturados. Para produtos da Amazon, isso pode incluir título, preço, classificação, avaliações, informações do vendedor e disponibilidade – embora os campos exatos retornados dependam dos Conjuntos de dados e do tipo de pesquisa.
- Snapshot. Assim que a coleta e o Parsing forem concluídas, a Bright Data armazena os dados como um snapshot. Seu script consulta o endpoint
/snapshotaté que o status mude de202 (em processamento)para200 (pronto). - Entrega. Você obtém o snapshot como JSON ou CSV. Como alternativa, configure a entrega para Amazon S3, Google Cloud Storage, Azure Blob, Snowflake, SFTP ou webhook. A entrega automática é útil para pipelines de produção que armazenam dados em um data warehouse.
- Transformação. Seu script (ou uma ferramenta como o pandas) renomeia colunas, filtra campos e formata os dados para que o Tableau os leia. É aqui que você adiciona colunas de metadados, como data de coleta e fonte de dados.
- Visualização. O Tableau lê o arquivo de saída (ou se conecta a um banco de dados, caso você tenha carregado os dados lá) e renderiza seu painel com os dados mais recentes.
Dimensionamento do pipeline
Para uso em produção, considere estas melhorias:
- Várias palavras-chave. Percorra uma lista de palavras-chave ou categorias de produtos em seu script para criar Conjuntos de dados abrangentes.
- Armazenamento em banco de dados. Em vez de CSV, grave em PostgreSQL ou MySQL. O Tableau se conecta nativamente a ambos, e os dados históricos se acumulam ao longo do tempo para análise de tendências.
- Orquestração. Use o Apache Airflow, o Prefect ou uma tarefa cron para agendar execuções na frequência que sua empresa exige (de hora em hora, diariamente, semanalmente).
- Entrega via webhook. Evite totalmente a sondagem configurando o Bright Data para enviar os resultados por POST ao seu servidor quando estiverem prontos.
Lista de verificação de produção
Antes de implantar o pipeline em uma programação de produção, lide com estas questões operacionais:
- Tratamento de erros. Envolva as chamadas de API em blocos try/except com lógica de repetição. Registre falhas em um arquivo ou serviço de monitoramento para que dados desatualizados sejam detectados antecipadamente.
- Desduplicação de dados. Acrescente uma chave única (como ASIN + data de coleta) e desduplique antes de carregar no Tableau. Linhas duplicadas distorcem as agregações.
- Validação do esquema. Verifique se a resposta da API contém os campos esperados antes de gravar em CSV. Alterações no site podem alterar a estrutura dos dados sem aviso prévio.
- Monitoramento e alertas. Configure alertas (e-mail, Slack ou PagerDuty) para execuções com falha, Conjuntos de dados vazios ou quedas inesperadas na contagem de linhas.
- Backups de dados. Arquive cada snapshot CSV com um carimbo de data/hora. Se uma coleta com erros corromper seu arquivo de trabalho, reverta para a versão anterior.
Por que escolher a Bright Data para pipelines do Tableau
Para fluxos de trabalho do Tableau em produção, estes fatores são importantes:
- Entrega flexível. Obtenha resultados como JSON, CSV ou NDJSON via API, webhook, Amazon S3, Google Cloud, Azure ou SFTP. Carregue os dados em seu data warehouse do Tableau.
- Personalizado ou pronto para uso. Use Serverless Functions para criar scrapers personalizados, o Scraper Studio para criar scrapers gerados e alimentados por IA, ou use Conjuntos de dados prontos para acesso instantâneo sem escrever código.
- Custo-benefício. Pague US$ 1,50 por 1.000 registros no modelo pay-as-you-go, com descontos por volume de até US$ 0,75/1.000 em níveis superiores.
Crie seu pipeline de dados da web em tempo real
A lacuna entre os dados disponíveis e os dados necessários continua a crescer, especialmente quando esses dados residem na web aberta sem API ou conector.
O WDC v2 está obsoleto e não é mais suportado. O Google Sheets atinge limites de células. O Excel exige trabalho manual. O TabPy não oferece rotação de Proxy. Scripts DIY falham em escala.
A API de Scraper Web da Bright Data fornece a camada de infraestrutura que falta nessas abordagens. A API inclui mais de 120 Scrapers prontos para uso, mais de 150 milhões de Proxies em 195 países, Resolução de CAPTCHA automática e saída de dados estruturados em formatos compatíveis nativamente com o Tableau. Os preços começam em US$ 1,50 por 1.000 registros, com 99,99% de tempo de atividade e conformidade total com GDPR, CCPA e ISO 27001.
Em vez de construir uma infraestrutura de coleta de dados, concentre-se na criação de painéis.
Perguntas frequentes
O Tableau WDC foi descontinuado?
Sim. O Web Data Connector v2 do Tableau foi oficialmente descontinuado na versão 2023.1. O Tableau 2022.4, a última versão a oferecer suporte ao WDC v2, chegou ao fim de vida útil. Os conectores WDC v2 não são mais suportados em todas as versões atuais do Tableau e podem ser removidos em qualquer atualização futura.
O que substituiu o Tableau WDC?
O Tableau lançou o WDC v3, mas ele é apenas para extração e não é compatível com o Tableau Bridge. Para dados da web em tempo real, um pipeline de API de scraping (Bright Data → CSV/JSON → Tableau) é uma alternativa prática. O tutorial neste guia cria esse pipeline.
O Tableau pode se conectar diretamente a uma API de Scraping de dados?
Não nativamente. O Tableau se conecta a bancos de dados, arquivos e serviços de nuvem específicos. Para usar uma API de scraping, você precisa de um script leve em Python ou Node.js que chame a API e receba os dados. O script então gera um formato que o Tableau lê: CSV, JSON ou uma inserção em banco de dados.
Como mantenho os dados do meu painel do Tableau atualizados?
Programe seu script de coleta de dados usando o cron (Linux/Mac), o Agendador de Tarefas (Windows) ou um orquestrador de fluxo de trabalho como o Apache Airflow. O script extrai os dados mais recentes da API da Bright Data e sobrescreve o arquivo CSV. O Tableau carrega os dados atualizados no próximo ciclo de atualização.
Quanto custa carregar dados da web no Tableau?
A API Web Scraper da Bright Data custa a partir de US$ 1,50 por 1.000 registros no modelo pré-pago, com descontos por volume que chegam a US$ 0,75/1.000. Para um painel típico de monitoramento de concorrentes que rastreia 5.000 produtos diariamente, isso representa aproximadamente US$ 7,50/dia ou cerca de US$ 225/mês.
Quais formatos de dados a Bright Data fornece para o Tableau?
A Bright Data fornece dados como JSON, CSV ou NDJSON via API. Para o Tableau, o CSV é a opção mais direta. O Tableau o lê nativamente, sem necessidade de transformação. Como alternativa, configure a entrega automática para Amazon S3, Google Cloud Storage, Azure Blob, Snowflake, SFTP ou webhook para pipelines de produção.
Posso usar a Bright Data com o Tableau Public?
Sim. A Bright Data gera arquivos CSV padrão que o Tableau Public lê nativamente. A limitação está no lado do Tableau Public: ele não oferece suporte a atualizações programadas para fontes baseadas em arquivos. Você precisa reexecutar seu script de coleta de dados e republicar a pasta de trabalho sempre que os dados forem atualizados.





